
Недоступны языковые файлы для tesseract распознавание работать не будет
Обновлено: 04.07.2024
Всем доброго времени суток! Решив изучить программы OSR на линукс, установил Cuneiform и Tesseract и словари к ним. Для Cuneiform использую GUI YAGF. Суть вопроса в том что при открытии YAGFом png картинки программа выключается, а выхлоп в консоли пишет ошибку сегментирования. Tiff тоже самое. А по teeseract ищу как правильно задавать значения.хотелось бы еще найти внятные маны по их использованию. Ах да забыл, OC GNU\Linux Debian 8 Jessie(Stable). Спасибо!


YAGF и с тессерактом работать может, но YAGF глючный несколько - при большом pdf файле у него раньше память текла рекой (мне 16 Гб оперативки не хватало).
Мне сейчас нужно только одну фотографию текста обработать.
дак в консольке скорми картинку. По мне первый получше второго.
А по teeseract ищу как правильно задавать значения
cuneiform -l ruseng -o txt.txt img.jpg
tesseract img.jpg txt -l rus
Перед тессерактом лучше фотографию сделать черно-белой (например в GIMP) и убедиться, что все читаемо.

например так (gimp): с параметрами следует поиграться в зависимости от характера шота
Благодарю! Сделаю, отпишусь! Кстати, используя gui ocrfeeder, мне нужно было распознать страницу с русскими и немецкими словами, так вот tesseract немецкие слова опознает, а вместо русских пишет какую то абракадабру. Как это побороть?

язык ему задать. Он бедный среди этой вашей кириллицы ищет похожие знаки на родной ему латинице.
ну так я ему указываю русский язык, а он его в упор не понимает. И даже на тестовой четкой фотографии опознает неверно, провертл на различных фото, результат тот же.
tesseract - штука обучаемая, ты уверен, что данные русского языка для него установлены?
Возможно я ошибаюсь,но tesserakt использует aspell, а ru, ger установлены. И что тогда не так? Finereader все прекрасно раcпознает. То что тогда не так с данными linux ocr?
Возможно tesseract и использует aspell, но не для непосредственно распознавания. Тебе нужна модель русского языка именно для тессеракта. Можешь даже сам обучить. Но быстрее скачать готовую. Лучше всего из репов твоего дистрибутива (если, конечно, оно там есть). Например в archlinux пакет называется community/tesseract-data-rus
Я усебя в synaptic посмотрел нечто подобное: tesseract-ocr-rus,eng,deu(немецкий).
Так, я скормил изображение более высокого разрешения tesseractu, он распознал таки русский, хоть и не везде но все же. А мне надо бы чтобы он в одноаременно распознал 2 языка. А в настройках GUI можно только однин язык выбрать. Как это сделать? Сейчас я использую (GUI OCRFeeder).
qwerta ★ ( 29.02.16 06:49:00 )Последнее исправление: qwerta 29.02.16 06:50:03 (всего исправлений: 1)
Мне сейчас нужно только одну фотографию текста обработать.
Если количество малое, то проще в онлайн
tesseract и cuneiform далеко по качеству до finereader. Они более-менее на совсем простых текстах, где нет смешения русского и английского, всяких формул, таблиц и прочего.
Но суть - применяет предобработку изображений перед подачей её в OCR систему
Чем мучиться с этими глюковатыми поделками, лучше finereader 8 в вайне. Ну или онлайн версию, если пару страниц надо.
Трансфер из
Tesseract, OCR (Оптическое распознавание символов, оптическое распознавание символов) с открытым исходным кодом, разработанный HP Labs, поддерживаемый Google Продолжайте совершенствовать, если команде это необходимо, вы также можете использовать его в качестве шаблона для разработки механизма распознавания, который соответствует вашим потребностям.
Далее мы установим Tesseract под Windows и осуществим простое преобразование и обучение:
Общий процесс: установка Tesseract-> открыть командную строку-> создать целевой файл
Тессеракт установка

Загрузите установочный пакет tesseract-ocr-setup-3.02.02.exe. После успешной установки на соответствующем диске будет находиться папка Tesseract-OCR, как показано на рисунке.
Откройте командную строку

Откройте командную строку, введите tesseract и нажмите Enter, общий вид tesseract следующий:
Создать объектный файл

Сначала подготовьте файл изображения, например test.jpg
Переключите командную строку в каталог целевого файла изображения, например, мы конвертируем файл в test.jpg (файл изображения поддерживает несколько форматов), расположенный в C: \ Users \ Lian \ Desktop \ test, а затем введите его в командной строке
[Синтаксис]: база данных вывода tesseract imagename [-l lang] [-psm pagesegmode] [configfile…]

imagename - это имя целевого файла изображения, и необходимо добавить суффикс формата; outputbase - имя файла результата преобразования; lang - имя языка (вы можете увидеть языковой файл eng.traineddata, начинающийся с eng, в папке tessdata в Tesseract-OCR), если не l eng по умолчанию англ.

Откройте файл output_1.txt и найдите, что tesseract успешно преобразовал изображение в152408。
Приятно показать, что старый бренд тессеракт все еще очень силен! Но это все еще недостаточно точно, так есть ли способ улучшить точность распознавания символов тессерактом? Далее мы будем использовать вспомогательные средства обученияjTessBoxEditorПриходите на тренировочные образцы, чтобы улучшить нашу точность!
Установите jTessBoxEditor
Получить образцы файлов
Мы можем использовать инструмент рисования для рисования образцов файлов. Чем больше число, тем лучше. Я сам нарисовал 5 картинок, как показано на рисунке:

[Примечание]: формат файла образца изображения должен быть в формате tif \ tiff, в противном случае во время процесса файла слияния может произойти ошибка «Не удается найти».




Пример файла слияния
Откройте jTessBoxEditor, Tools-> Merge TIFF, выберите все файлы примеров и сохраните объединенный файл как num.font.exp0.tif.
Создать файл BOX
Откройте командную строку и перейдите в каталог, где находится num.font.exp0.tif, введите сгенерированный файл с именем num.font.exp0.box
[Синтаксис]: tesseract [lang]. [Имя шрифта] .exp [num] .tif [lang]. [Имя шрифта] .exp [num] batch.nochop makebox
lang - это имя языка, fontname - это имя шрифта, а num - серийный номер, в tesseract вы должны обратить внимание на формат.
Определить профили персонажей
Создайте текстовый файл с именем font_properties в целевой папке с содержимым
[Синтаксис]: <fontname> <italic> <bold> <fixed> <serif> <fraktur>
fontname - это имя шрифта, italic - курсив, bold - жирный шрифт, fixed - шрифт по умолчанию, serif - шрифт с засечками, fraktur German - черный шрифт, 1 и 0 обозначают наличие и отсутствие, могут использоваться при точном различении.
Коррекция персонажа

Откройте jTessBoxEditor, BOX Editor-> Open, откройте num.font.exp0.tif, исправьте символы в <Char>, помните, что в <Page> много страниц!
Не забудьте сохранить после модификации.
Выполнить пакетный файл
Создать пакетный файл в целевом каталоге
Это может быть выполнено после сохранения, и результат выполнения показан на рисунке:
В последней папке будут находиться следующие файлы, как показано на рисунке:
Поместите сгенерированные обученные данные в tessdata
Наконец, скопируйте num.trainddata в папку tessdata в Tesseract-OCR.
Выполните предыдущие шаги, используйте командную строку для ввода

Мы можем видеть, что содержимое вновь сгенерированного файла output_2 - 762408, что совершенно правильно. Внимательные люди обнаружат, что в последней инструкции мы использовали инструкцию [-l num] вместо [-l eng]. Это показывает, что последнее использованное нами преобразование - это вновь сгенерированная библиотека сопоставления num языка вместо библиотеки сопоставления языка eng по умолчанию.
Интеллектуальная рекомендация

Michael.W Поговорите о Hyperledger Fabric. Проблема 20 - Подробная индивидуальная сортировка узла с пятью порядками с исходным кодом для чтения.
Michael.W Поговорите о Hyperledger Fabric. Проблема 20 - Подробная индивидуальная сортировка узла с пятью порядками с исходным кодом чтения Fabric Файл исходного кода одиночного режима находится в ord.

Мяу Пасс Матрица SDUT
Мяу Пасс Матрица SDUT Time Limit: 1000 ms Memory Limit: 65536 KiB Submit Statistic Problem Description Лянцзян получил матрицу, но эта матрица была особенно уродливой, и Лянцзян испытал отвращение. Чт.

Гессенская легкая двоичная структура удаленного вызова
Hessian - это легкая двоичная структура удаленного вызова, официальный адрес документа, в основном он включает протокол удаленного вызова Hessian, протокол сериализации Hessian, прокси-сервер клиента .

TCP Pasket и распаковка и Нетти Solutions
Основные введение TCP является ориентированным на соединение, обеспечивая высокую надежность услуг. На обоих концах (клиенты и терминалы сервера) должны иметь один или более гнезда, так что передающий.
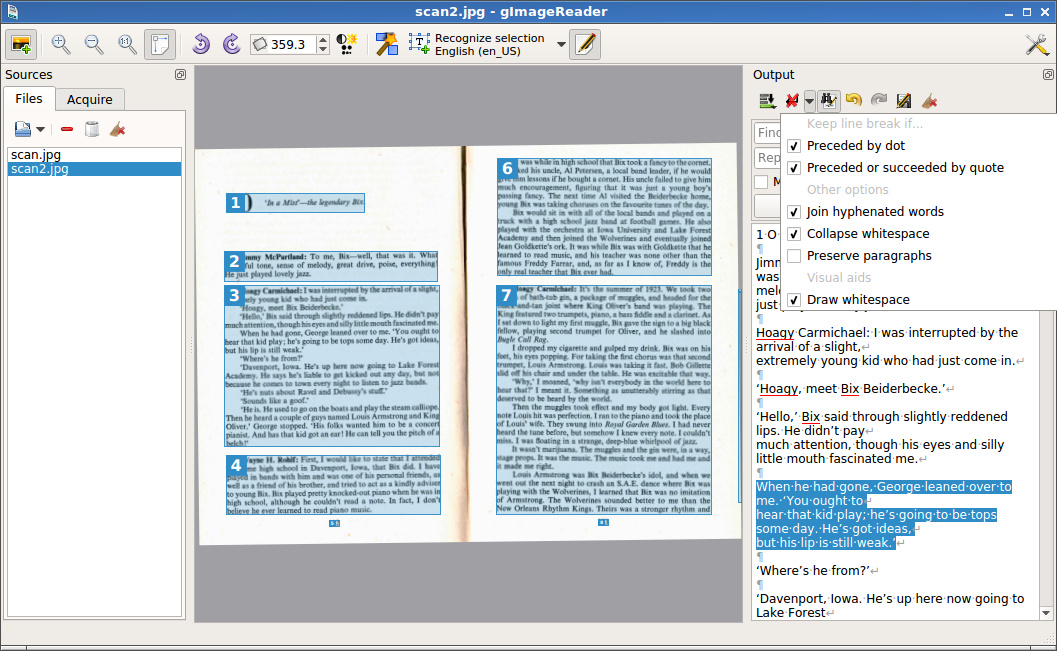
Она позволяет извлекать текст из изображений и PDF-файлов и построена как простой интерфейс для Tesseract-OCR, движка OCR для распознавания текстов и шаблонов в документах и изображениях с использованием искусственного интеллекта.
gImageReader работает путем сканирования текстов из PDF-файлов или файлов изображений на любом из нескольких языков, которые он поддерживает, благодаря наличию символов Unicode. Он имеет простой, хорошо организованный настраиваемый пользовательский интерфейс, с помощью которого вы можете выполнять задачи проверки орфографии и перевода.
Возможности gImageReader:
- Исходный код доступен на GitHub.
- Доступно на платформах GNU/Linux и Windows.
- Тематический интерфейс со знакомым макетом редактирования.
- Импортируйте PDF-документы и изображения с диска, сканирующих устройств, снимков экрана и буфера обмена.
- Создавайте документы PDF из документов hOCR.
- Ручное или автоматическое определение области распознавания.
- Обработка нескольких изображений и документов в пакетном режиме.
- Распознавать в документы hOCR или в обычный текст.
- Распознанный текст отображается рядом с изображениями.
- Постобработка распознанного текста, включая проверку орфографии.
gImageReader прост в использовании и поддерживает работу с электронными копиями документов, а также со снимками загруженных с носителей, например скриншоты. У вас даже есть возможность выбрать интересующую вас область текста и добавить только нужный вам текст. В конечном итоге gImagereader работает как программа для чтения PDF-файлов и как инструмент для извлечения текста.
Вы даже можете распознавать текст на снимках сделанных вашим телефоном. Что еще круче, так это то, что есть многоязычная поддержка.
Программа не идеальна, но уже сейчас является одним из лучших вариантов.
Установите gImageReader в Linux
Чтобы использовать gImageReader в полной мере, вы должны вручную установить языковые пакеты Tesseract, чтобы вы могли правильно анализировать изображения и файлы. Пакет называется «tesseract-ocr» и доступен в диспетчере программного обеспечения в дистрибутивах Debian и Fedora. Именно он занимается распознаванием текста.
Если вы используете Ubuntu, вы можете просто добавить PPA и запустить команду установки, используя следующие команды:
В Debian, Fedora и OpenSUSE установите его из диспетчера пакетов.
Не почувствуйте себя обделенным, если вы используете Arch Linux или любой из его производных. AUR позаботится о вас. А если вы предпочитаете собрать приложение из исходного кода, то инструкции можно найти в его Wiki-ссылке на репозитории GitHub.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Трансфер из
Tesseract, OCR (Оптическое распознавание символов, оптическое распознавание символов) с открытым исходным кодом, разработанный HP Labs, поддерживаемый Google Продолжайте совершенствовать, если команде это необходимо, вы также можете использовать его в качестве шаблона для разработки механизма распознавания, который соответствует вашим потребностям.
Далее мы установим Tesseract под Windows и осуществим простое преобразование и обучение:
Общий процесс: установка Tesseract-> открыть командную строку-> создать целевой файл
Тессеракт установка
Загрузите установочный пакет tesseract-ocr-setup-3.02.02.exe. После успешной установки на соответствующем диске будет находиться папка Tesseract-OCR, как показано на рисунке.
Откройте командную строку
Откройте командную строку, введите tesseract и нажмите Enter, общий вид tesseract следующий:
Создать объектный файл
Сначала подготовьте файл изображения, например test.jpg
Переключите командную строку в каталог целевого файла изображения, например, мы конвертируем файл в test.jpg (файл изображения поддерживает несколько форматов), расположенный в C: \ Users \ Lian \ Desktop \ test, а затем введите его в командной строке
[Синтаксис]: база данных вывода tesseract imagename [-l lang] [-psm pagesegmode] [configfile…]
imagename - это имя целевого файла изображения, и необходимо добавить суффикс формата; outputbase - имя файла результата преобразования; lang - имя языка (вы можете увидеть языковой файл eng.traineddata, начинающийся с eng, в папке tessdata в Tesseract-OCR), если не l eng по умолчанию англ.
Откройте файл output_1.txt и найдите, что tesseract успешно преобразовал изображение в152408。
Приятно показать, что старый бренд тессеракт все еще очень силен! Но это все еще недостаточно точно, так есть ли способ улучшить точность распознавания символов тессерактом? Далее мы будем использовать вспомогательные средства обученияjTessBoxEditorПриходите на тренировочные образцы, чтобы улучшить нашу точность!
Установите jTessBoxEditor
Получить образцы файлов
Мы можем использовать инструмент рисования для рисования образцов файлов. Чем больше число, тем лучше. Я сам нарисовал 5 картинок, как показано на рисунке:
[Примечание]: формат файла образца изображения должен быть в формате tif \ tiff, в противном случае во время процесса файла слияния может произойти ошибка «Не удается найти».
Пример файла слияния
Откройте jTessBoxEditor, Tools-> Merge TIFF, выберите все файлы примеров и сохраните объединенный файл как num.font.exp0.tif.
Создать файл BOX
Откройте командную строку и перейдите в каталог, где находится num.font.exp0.tif, введите сгенерированный файл с именем num.font.exp0.box
[Синтаксис]: tesseract [lang]. [Имя шрифта] .exp [num] .tif [lang]. [Имя шрифта] .exp [num] batch.nochop makebox
lang - это имя языка, fontname - это имя шрифта, а num - серийный номер, в tesseract вы должны обратить внимание на формат.
Определить профили персонажей
Создайте текстовый файл с именем font_properties в целевой папке с содержимым
[Синтаксис]: <fontname> <italic> <bold> <fixed> <serif> <fraktur>
fontname - это имя шрифта, italic - курсив, bold - жирный шрифт, fixed - шрифт по умолчанию, serif - шрифт с засечками, fraktur German - черный шрифт, 1 и 0 обозначают наличие и отсутствие, могут использоваться при точном различении.
Коррекция персонажа
Откройте jTessBoxEditor, BOX Editor-> Open, откройте num.font.exp0.tif, исправьте символы в <Char>, помните, что в <Page> много страниц!
Не забудьте сохранить после модификации.
Выполнить пакетный файл
Создать пакетный файл в целевом каталоге
Это может быть выполнено после сохранения, и результат выполнения показан на рисунке:
В последней папке будут находиться следующие файлы, как показано на рисунке:
Поместите сгенерированные обученные данные в tessdata
Наконец, скопируйте num.trainddata в папку tessdata в Tesseract-OCR.
Выполните предыдущие шаги, используйте командную строку для ввода
Мы можем видеть, что содержимое вновь сгенерированного файла output_2 - 762408, что совершенно правильно. Внимательные люди обнаружат, что в последней инструкции мы использовали инструкцию [-l num] вместо [-l eng]. Это показывает, что последнее использованное нами преобразование - это вновь сгенерированная библиотека сопоставления num языка вместо библиотеки сопоставления языка eng по умолчанию.
Интеллектуальная рекомендация
Michael.W Поговорите о Hyperledger Fabric. Проблема 20 - Подробная индивидуальная сортировка узла с пятью порядками с исходным кодом для чтения.
Michael.W Поговорите о Hyperledger Fabric. Проблема 20 - Подробная индивидуальная сортировка узла с пятью порядками с исходным кодом чтения Fabric Файл исходного кода одиночного режима находится в ord.
Мяу Пасс Матрица SDUT
Мяу Пасс Матрица SDUT Time Limit: 1000 ms Memory Limit: 65536 KiB Submit Statistic Problem Description Лянцзян получил матрицу, но эта матрица была особенно уродливой, и Лянцзян испытал отвращение. Чт.
Гессенская легкая двоичная структура удаленного вызова
Hessian - это легкая двоичная структура удаленного вызова, официальный адрес документа, в основном он включает протокол удаленного вызова Hessian, протокол сериализации Hessian, прокси-сервер клиента .
TCP Pasket и распаковка и Нетти Solutions
Основные введение TCP является ориентированным на соединение, обеспечивая высокую надежность услуг. На обоих концах (клиенты и терминалы сервера) должны иметь один или более гнезда, так что передающий.
Читайте также: