
Oracle nested loops outer что значит
Обновлено: 03.07.2024
Метод подключения к таблице (Nested Loop, Hash join) в Oracle для тестирования количества обращений к таблице
Часто при написании SQL встречается несколько ассоциаций таблиц, что также является одним из самых больших преимуществ реляционных баз данных. Типы соединений таблиц можно разделить на три типа: соединение с вложенными циклами, соединение по хэшу и соединение с сортировкой слиянием. У каждого типа есть свой сценарий использования.Оператор SQL генерирует план выполнения в базе данных, а оптимизатор в базе данных определяет, какой метод выбрать, исходя из стоимости. Количество обращений к таблице при объединении с сортировкой слиянием аналогично количеству обращений к таблице при объединении по хэшу. Следующее проверяет количество обращений к таблице при выполнении двух методов Nested Loop и Hash join.
①Создать таблицу test1, test2
②Вставить данные
①Метод соединения вложенных циклов
В соединении с вложенными циклами к таблице управления обращаются 0 или 1 раз, а к управляемой таблице - 0 или N. N определяется количеством наборов результатов, возвращаемых таблицей управления. Следующие тесты проводятся в 4 случаях.
Настройте некоторый контент перед тестом, измените параметр statistics_level = all, чтобы просмотреть план выполнения оператора sql. Есть много способов просмотреть план выполнения оператора sql, который здесь не будет подробно описываться; выполните команду set lineize 1000, установите lineize 1000 на dbms_xplan.display_cursor Он по-прежнему оказывает влияние. Если он не установлен, по умолчанию на выходе будет все меньше и больше столбцов, таких как БУФЕРЫ.
A. В первом случае к test2 обращаются 100 раз (к таблице управления обращаются 1 раз, а к ведомой таблице обращаются 100 раз)

/+ leading(test1) use_nl(test2) / Это означает, что test1 используется в качестве управляющей таблицы, а метод подключения - соединение вложенных циклов. Как видно из плана выполнения (start представляет количество обращений к таблице), к таблице test1 обращались 1 раз, а к таблице test2 обращались 100 раз. Поскольку test1 вернул 100 элементов данных в качестве управляющей таблицы, к управляемой таблице обращались 100 раз.
Б. Второй случай

Судя по плану выполнения, test1 был посещен один раз как управляющая таблица и вернул 2 строки, а управляемая таблица test2 была посещена дважды, и результат был аналогичен предыдущему.
С. Ситуация третья

Оператор sql, где условие добавляет test1.num = 789456123, и эти данные на самом деле не существуют. Наблюдая за планом выполнения, к test1 обращаются один раз как к таблице управления, и прогноз возвращает 1 данные, а результат возвращает 0 (E-Rows указывает строки данных, возвращенные прогнозом, A-Rows указывает фактические возвращенные строки данных), потому что таблица управления возвращает 0 строк данных, поэтому к управляемой таблице обращаются 0 раз.
D. Четвертая ситуация

Условие 1 = 2 добавляется к оператору sql. Это условие вообще неверно, поэтому доступ к таблице t1 не требуется. Хорошо получить структуру двух таблиц напрямую, обратившись к словарю данных. Наблюдая за планом выполнения, вы также можете увидеть, что test1 и test2 оба являются Не посещали.
② Метод хеш-соединения
При хэш-соединении доступ к управляющей таблице осуществляется 0 или 1 раз, а к управляемой таблице также обращаются 0 или 1. В большинстве сценариев к управляющей таблице и управляемой таблице обращаются по 1 разу.
А. Первый случай

Подсказка добавлена в оператор sql: /+ leading(test1) use_hash(test2) /. Начало указывает, что test1 используется в качестве управляющей таблицы, а use_hash указывает, что режим соединения таблицы - хэш. Из плана выполнения видно, что test1 был выполнен один раз как управляемая таблица и фактически вернул 100 фрагментов данных, а test2 также был выполнен один раз как управляемая таблица, вернув 10 000 фрагментов данных. Отсюда мы видим, что количество обращений к таблице в режиме хэш-соединения отличается от количества обращений к таблице с помощью вложенных циклов.
Б. Второй случай

В оператор sql and добавляется условие test1.num = 987654321. В test1 такой строки данных нет, поэтому возвращается строка 0. Просмотрите план выполнения, к test1 обращаются один раз как к управляющей таблице, возвращая 0 строк данных, а к управляемой таблице test2 обращаются 0 раз.
С. Ситуация третья

В оператор sql добавляется условие 1 = 2. Эта ситуация невозможна, поэтому доступ к таблице test1 не требуется. Просмотрите план выполнения, к управляющей таблице test1 обращаются 0 раз, и к управляемой таблице также обращаются 0 раз.
Nested Loops join (соединения вложенными циклами)
О чем говорят нам физические операции соединения
Каждый имеет свой метод чтения плана выполнения при настройке медленных SQL-запросов. Я вначале предпочитаю смотреть на то, какие операции соединения используются:

Эти три иконки могут не представлять собой очевидные места для начала поиска проблем в медленных запросах, однако в особенно больших планах я люблю начинать с быстрого взгляда на операторы соединения, поскольку они позволяют нам многое понять из того, что SQL Server думает о ваших данных.
Эта серия публикаций состоит из трех частей, в которых мы изучим, как работает каждый алгоритм соединения, и что они могут рассказать об операторах в восходящем потоке данных на плане выполнения нашего запроса.
Соединения вложенными циклами
Nested Loops Join работает примерно так: SQL Server берет первое значение из первой таблицы (наша "внешняя" таблица выбирается сервером по умолчанию) и сравнивает его с каждым значением во второй "внутренней" таблице в поисках совпадения.
Когда проверено каждое значение из внутренней таблицы, SQL Server переходит к следующему значению во внешней таблице, и процесс повторяется до тех пор, пока для каждого значения из внешней таблицы не будет выполнено сравнение с каждым значением из внутренней таблицы.
Это описание представляет собой пример худшего варианта использования соединения вложенными циклами с точки зрения производительности. Существует несколько оптимизационных приемов, которые делают соединение более эффективным. Например, если строки внутренней таблицы отсортированы
по значениям соединения (поскольку имеется созданный вами индекс или сервер создал спул), SQL Server может обрабатывать строки значительно быстрей. Поскольку строки внутреннего входа отсортированы, это позволяет выполнять прямой поиск необходимых строк, сокращая общее число необходимых сравнений.
За более подробным объяснением происходящего внутри сервера и оптимизации nested loops joins вы можете обратиться к статье Крейга Фридмана.
Что выявляет соединение вложенными циклами?
Знание механизма работы nested loops join позволяет нам получить информацию о том, как оптимизатор воспринимает наши данные, и восходящих потоках данных операторов соединения, что помогает нам сосредоточить усилия на настройке производительности.

Введение
В языке T-SQL существуют следующие виды соединения таблиц:
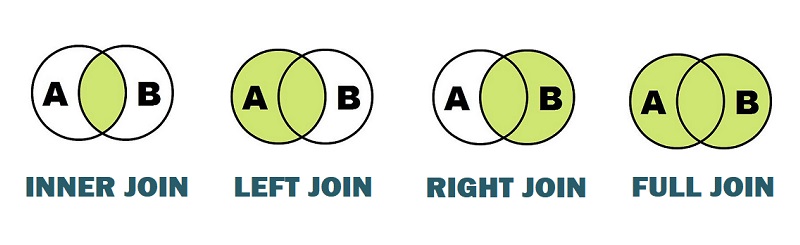
На физическом уровне в Microsoft SQL Server эти соединения реализуются с помощью специальных алгоритмов:
Какой из этих алгоритмов применить к тому или иному соединению, Microsoft SQL Server определяет в процессе построения плана выполнения запроса, так как в зависимости от условий каждый из этих алгоритмов может быть эффективнее остальных. Иными словами, в каких-то условиях эффективнее будет Nested Loops, а в каких-то Merge или Hash Match.
В плане выполнения запроса соединение таблиц обозначается с помощью следующих физических операторов, т.е. если Вы видите ту или иную иконку, значит, данные были соединены с помощью соответствующего алгоритма
Иконка
Название оператора
Какие еще существуют физические операторы и как они обозначаются в плане выполнения запроса, мы рассматривали в отдельной статье.
Ну а сейчас давайте подробно рассмотрим каждый тип физического соединения таблиц в Microsoft SQL Server.
Типы физического соединения таблиц
Некоторые могут спросить: «А зачем нам вообще знать, как работает физическое соединение таблиц в Microsoft SQL Server?». Все дело в том, что если у Вас достаточно много задач, связанных с оптимизацией, то понимание внутренних процессов, понимание того, как работает тот или иной оператор в плане выполнения запроса, поможет Вам в случае необходимости скорректировать запрос и сделать его более эффективным.
Кроме этого, на собеседованиях на позиции, которые связаны с разработкой на T-SQL, очень часто любят спрашивать, как работает физическое соединение таблиц, иными словами, если Вы идете на позицию «T-SQL разработчик», то Вас, наверное, в 95% случаях спросят про физическое соединение таблиц Nested Loops, Merge и Hash Match.
Поэтому знание и понимание того, как фактически происходит соединение данных в Microsoft SQL Server, очень полезно.
Дополнительно рекомендую почитать про архитектуру обработки запросов в Microsoft SQL Server.
Nested Loops Join
Nested Loops – это оператор вложенных циклов, который отражает тип физического соединения данных.
Принцип работы Nested Loops следующий: SQL Server для каждого значения одного набора данных (обычно, где меньше записей), ищет соответствующее значение в другом наборе данных.
Иными словами, SQL Server берет первое значение из первой таблицы (она называется внешней) и сравнивает его последовательно со всеми значениями во второй таблице (она называется внутренней), если находит соответствие, то запись включается в итоговый набор данных. Когда значение из первого набора данных сравнилось со всеми знамениями из второго набора, то берётся второе значение первого набора и снова происходит сравнение со всеми значениями из второго набора и так происходит до тех пор, пока каждое значение из первой таблицы, т.е. внешней, не будет сравнено с каждым значением из второй таблицы, т.е. внутренней.
Таким образом, у нас два цикла, внешний и внутренний, отсюда и название – вложенные циклы.
В таком виде Nested Loops работает не очень эффективно, однако эффективность повышается, если данные внутренней таблицы отсортированы по соединяемому столбцу, например, если по нему создан индекс.
Таким образом, количество сравнений уменьшается за счет того, что значения отсортированы, а общая скорость работы повышается.
Тип физического соединения таблиц Nested Loops обычно возникает, когда мы соединяем наборы данных, где один из наборов имеет небольшой размер, а другой набор данных сравнительно большой и индексирован по соединяемым столбцам. Nested Loops встречается достаточно часто, так как является самой быстрой операцией соединения на небольшом объеме данных.
Примечание! Если два набора данных имеют достаточно большие размеры, то данный способ соединения будет крайне неэффективен.
Merge Join
Merge – соединение слиянием.
Данный тип физического соединения данных является самым быстрым, однако, он требует, чтобы оба набора данных были отсортированы, например, есть индексы по соединяемым столбцам.
Merge наиболее эффективен в тех случаях, когда два набора данных достаточно велики, и как уже было отмечено, отсортированы по соединяемым столбцам.
Принцип работы данного типа соединения следующий: SQL Server получает первые строки из каждого набора входных данных и сравнивает их. Затем он продолжает сравнение следующих строк из второго набора, до тех пор, пока значения соответствуют значению из первого набора данных. Как только значения больше не совпадают, SQL Server переходит к следующей строке в наборе с меньшим значением и продолжает выполнять сравнения.
Например, для операций внутреннего соединения строки возвращаются в том случае, если они равны. Если они не равны, строка с меньшим значением не учитывается, и из этого набора входных данных берется следующая строка и снова происходит сравнение. Этот процесс повторяется, пока не будет выполнена обработка всех строк, т.е. пока этот, назовем его, курсор, не дойдет до конца.
Данный алгоритм эффективен, потому что SQL Server не должен возвращаться и читать какие-либо строки несколько раз, т.е. чтение данных происходит только один раз.
Однако алгоритм становится менее эффективен, когда в наборах существуют повторяющиеся значения, т.е. когда происходит соединение слиянием «многие ко многим».
В таких случаях SQL Server записывает любые повторяющиеся значения из второй таблицы во временную таблицу в базе данных tempdb и выполняет сравнения там. Затем, если эти значения также дублируются в первой таблице, SQL Server сравнивает их со значениями, которые уже сохранены во временной таблице.
Примечание! Если оба набора данных велики и имеют сходные размеры, но не отсортированы, то соединение слиянием с предварительной сортировкой и хэш-соединение (Hash Match) имеют примерно одинаковую производительность. Однако хэш-соединения часто выполняются быстрее, если наборы данных значительно отличаются по размеру.
Hash Match Join
Hash Match – хэш-соединение.
Алгоритм соединения включает 2 фазы:
В первой фазе «Build» строится хэш-таблица при помощи вычисления хэш-значения для каждой строки одного набора данных (обычно меньшего из двух). Эти хэши вычисляются на основе ключей соединения входных данных и затем сохраняются вместе со строкой в хеш-таблице.
После построения хэш-таблицы SQL Server начинает фазу «Probe». На этом этапе он для каждой строки другого набора данных, с помощью той же хэш-функции, вычисляет хэш-значение и осуществляет поиск совпадений по хэш-таблице. Если он находит совпадение для этого хеша, то затем он проверяет, действительно ли совпадают ключи соединения между строкой в хеш-таблице и строкой из второй таблицы (ему необходимо выполнить эту проверку из-за потенциальных хеш-коллизий).
Стоит отметить, что иногда могут возникать ситуации, когда на этапе «Build» хеш-таблица не может быть сохранена полностью в памяти. В таких случаях SQL Server сохраняет некоторую часть данных в памяти, а остальную часть перенаправляет в tempdb.
Это происходит, когда объем данных превышает размер, который может храниться в памяти, или когда SQL Server предоставляет недостаточный объем памяти, необходимый для соединения Hash Match.
Способ физического соединения данных Hash Match возникает, когда мы обрабатываем большие, несортированные и неиндексированные наборы данных, при этом он делает это достаточно эффективно.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
Я часто собеседую разработчиков и часто задаю им простой, как кувалда, вопрос — как внутри работает JOIN в SQL? В ответ я обычно слышу бессвязное мычание про волшебные деревья и индексы, которые быстрее. Когда-то мне казалось, что каждый программист специалист должен знать то, с чем работает. Впоследствии жизнь объяснила мне, что это не так. Но мне все еще не понятно, как можно годами теребить базёнку , даже не догадываясь, а что там у нее «под капотом»?
Давайте проведем ликбез и вместе посмотрим, как же работают эти джойны , и даже сами реализуем парочку алгоритмов.

Постановка задачи
Людям, которые утверждают, что много и плотно работали с SQL, я задаю на собеседованиях вот такую задачу.
Есть SQL команда
Нужно выполнить то же самое на Java, т.е. реализовать метод
Я не прошу прям закодить реализацию, но жду хотя бы устного объяснения алгоритма.
Дополнительно я спрашиваю, что нужно изменить в сигнатуре и реализации, чтобы сделать вид, что мы работаем с индексами.
- Знать теорию полезно из чисто познавательных соображений.
- Если вы различаете типы джойнов, то план выполнения запроса, который получается командой EXPLAIN, больше не выглядит для вас как набор непонятных английских слов. Вы можете видеть в плане потенциально медленные места и оптимизировать запрос переписыванием или хинтами.
- В новомодных аналитических инструментах поверх Hadoop планировщик запросов или малость туповат (см. Cloudera Impala), или его вообще нет (см. Twitter Scalding, Spark RDD). В последнем случае приходится собирать запрос вручную из примитивных операций.
Наконец, есть риск, что однажды вы попадете на собеседование ко мне или к другому зануде.Но на самом деле, статья не про собеседования, а про операцию JOIN.
Nested Loops Join
Самый базовый алгоритм объединения двух списков сейчас проходят в школах. Суть очень простая — для каждого элемента первого списка пройдемся по всем элементам второго списка; если ключи элементов вдруг оказались равны — запишем совпадение в результирующую таблицу. Для реализации этого алгоритма достаточно двух вложенных циклов, именно поэтому он так и называется.
Основной плюс этого метода — полное безразличие к входным данным. Алгоритм работает для любых двух таблиц, не требует никаких индексов и перекладываний данных в памяти, а также прост в реализации. На практике это означает, что достаточно просто бежать по диску двумя курсорами и периодически выплёвывать в сокет совпадения.
Однако ж, фатальный минус алгоритма — высокая временная сложность O(N*M) (квадратичная асимптотика, если вы понимаете, о чем я). Например, для джойна пары небольших таблиц в 100к и 500к записей потребуется сделать аж 100.000 * 500.000 = 50.000.000.000 (50 млрд) операций сравнения. Запросы с таким джойном будут выполняться невежливо долго, часто именно они — причина беспощадных тормозов кривеньких самописных CMS’ок.
Современные РСУБД используют nested loops join в самых безнадежных случаях, когда не удается применить никакую оптимизацию.
UPD. zhekappp и potapuff поправляют, что nested loops эффективен для малого числа строк, когда разворачивать какую-либо оптимизацию выйдет дороже, чем просто пробежаться вложенным циклом. Есть класс систем, для которых это актуально.
Hash Join
Если размер одной из таблиц позволяет засунуть ее целиком в память, значит, на ее основе можно сделать хеш-таблицу и быстренько искать в ней нужные ключи. Проговорим чуть подробнее.
Проверим размер обоих списков. Возьмем меньший из списков, прочтем его полностью и загрузим в память, построив HashMap. Теперь вернемся к большему списку и пойдем по нему курсором с начала. Для каждого ключа проверим, нет ли такого же в хеш-таблице. Если есть — запишем совпадение в результирующую таблицу.
Временная сложность этого алгоритма падает до линейной O(N+M), но требуется дополнительная память.
Что важно, во времена динозавров считалось, что в память нужно загрузить правую таблицу, а итерироваться по левой. У нормальных РСУБД сейчас есть статистика cardinality, и они сами определяют порядок джойна, но если по какой-то причине статистика недоступна, то в память грузится именно правая таблица. Это важно помнить при работе с молодыми корявыми инструментами типа Cloudera Impala.
Merge Join
А теперь представим, что данные в обоих списках заранее отсортированы, например, по возрастанию. Так бывает, если у нас были индексы по этим таблицам, или же если мы отсортировали данные на предыдущих стадиях запроса. Как вы наверняка помните, два отсортированных списка можно склеить в один отсортированный за линейное время — именно на этом основан алгоритм сортировки слиянием. Здесь нам предстоит похожая задача, но вместо того, чтобы склеивать списки, мы будем искать в них общие элементы.
Итак, ставим по курсору в начало обоих списков. Если ключи под курсорами равны, записываем совпадение в результирующую таблицу. Если же нет, смотрим, под каким из курсоров ключ меньше. Двигаем курсор над меньшим ключом на один вперед, тем самым “догоняя” другой курсор.
Если данные отсортированы, то временная сложность алгоритма линейная O(M+N) и не требуется никакой дополнительной памяти. Если же данные не отсортированы, то нужно сначала их отсортировать. Из-за этого временная сложность возрастает до O(M log M + N log N), плюс появляются дополнительные требования к памяти.
Outer Joins
Вы могли заметить, что написанный выше код имитирует только INNER JOIN, причем рассчитывает, что все ключи в обоих списках уникальные, т.е. встречаются не более, чем по одному разу. Я сделал так специально по двум причинам. Во-первых, так нагляднее — в коде содержится только логика самих джойнов и ничего лишнего. А во-вторых, мне очень хотелось спать. Но тем не менее, давайте хотя бы обсудим, что нужно изменить в коде, чтобы поддержать различные типы джойнов и неуникальные значения ключей.
Первая проблема — неуникальные, т.е. повторяющиеся ключи. Для повторяющихся ключей нужно порождать декартово произведение всех соответствющих им значений.
В Nested Loops Join почему-то это работает сразу.
В Hash Join придется заменить HashMap на MultiHashMap.
Для Merge Join ситуация гораздо более печальная — придется помнить, сколько элементов с одинаковым ключом мы видели.
Работа с неуникальными ключами увеличивает асимптотику до O(N*m+M*n), где n и m — среднее записей на ключ в таблицах. В вырожденном случае, когда n=N и m=M, операция превращается в CROSS JOIN.
Вторая проблема — надо следить за ключами, для которых не нашлось пары.
Для Merge Join ключ без пары видно сразу для всех направлений JOIN’а.
Для Hash Join сразу можно увидеть нехватку соответствующих ключей при джойне слева. Для того, чтобы фиксировать непарные ключи справа, придется завести отдельный флаг “есть пара!” для каждого элемента хеш-таблицы. После завершения основного джойна надо будет пройти по всей хеш-таблице и добавить в результат ключи без флага пары.
Для Nested Loops Join ситуация аналогичная, причем все настолько просто, что я даже осилил это закодить:
Морализаторское послесловие
Если вы дочитали досюда, значит, статья показалась вам интересной. А значит, вы простите мне небольшую порцию нравоучений.
Я действительно считаю, что знания РСУБД на уровне SQL абсолютно не достаточно, чтобы считать себя профессиональным разработчиком ПО. Профессионал должен знать не только свой код, но и примерное устройство соседей по стеку, т.е. 3rd-party систем, которые он использует — баз данных, фреймворков, сетевых протоколов, файловых систем. Без этого разработчик вырождается до кодера или оператора ЭВМ, и в по настоящему сложных масштабных задачах становится бесполезен.
UPD. Несмотря на это послесловие, статья, на самом деле, про JOIN'ы.
Дополнительные материалы
- Роскошная статья про устройство РСУБД
- Роскошная книга про алгоритмы. Полезно полистать перед собеседованием.
Disclaimer: вообще-то, я обещал еще одну статью про Scalding, но предыдущая не вызвала большого интереса у публики. Из-за этого тему решено было сменить.
Читайте также: