
Oracle обмен данными между сессиями
Обновлено: 15.07.2024
Oracle имеет временные таблицы, они практически бесполезны, кто думает не так, это их проблемы, я спорить тут не буду.
Приведенный ниже подход позволяет работать в рамках сессии Oracle с любым количеством переменных. Кто еще не понял, объясняю: Oracle имеет внутренний язык кроме SQL, они называют его PL/SQL и это совершенно разные вещи, то, что я описываю ниже относится именно к PL/SQL.
Основная идея, главный посыл: Oracle имеет в своем инструментарии такие вещи, как: PACKAGE и TYPE, это объекты базы данных, о них говорить можно много, но нас в данный момент интересует такое их свойство, как наличие доступных извне переменных. Объект TYPE я рассматривать не буду в данной статье, это отдельная тема разговора.
Объект: PACKAGE.
Выполните следующий код в системе, которая выполнение таких кодов разрешает (это может быть PL/SQL Developer, SQL Developer, TOAD и т.д. и т.п.):
В переводе на русский язык здесь написано следующее: создается заголовок пакета (его декларативная часть, больше вам ничего не надо), в пакете описывается запись из 15 полей по 5 полей на каждый тип: численный, символьный и тип DATETIME (до милисекунд), на основе этого типа записи декларируется таблица, которая индексируется через BINARY_INTEGER, такой тип необходим для того, чтобы с ним поддерживались операции BULK COLLECT, затем на основе этого типа создается еще один тип с типом индекса VARCHAR2(255), это техника для работы с хэш-массивами. В итоге декларируется переменная пакета на основе типа tempVar. Такой подход позволит вам иметь сколько угодно внутренних таблиц формата записи tempR к которым вы сможете обращаться через заданное имя.
Вот пример заполнения одного экземпляра таблицы через BULK COLLECT:
При таком заполнении, к сожалению, необходимо в конструкции SELECT полностью выдерживать структуру записи массива, иначе будет получена ошибка несоответствия запроса структуре его сохранения.
После того, как запрос отработает, в переменную пакета tempV будет записана таблица, ее можно получить разными способами, вот обычный блок PL/SQL:
Вот блок c Dynamic SQL:
Выше показан пример заполнения таблицы с помощью BULK COLLECT, с точки зрения скорости выполнения, этот способ наиболее оптимальный, но он не единственный, если скорость вас не интересует, то идеальным подходом может быть использование курсоров, вот так, например:
Обратите внимание на оператор DELETE, он важен, если вы будете обновлять таблицу несколько раз за сессию, то необходимо делать ее очистку, если этого требует логика, операция BULK COLLECT очищает таблицу автоматически и в этом случае DELETE выполнять не нужно.
Курсор удобен тем, что позволяет заполнить те поля, которые необходимы, не придерживаясь формата структуры записи таблицы.
Вот пример использования курсора при заполнении в Dynamic SQL:
Хочу обратить ваше внимание на ограничения в приведенном примере. Константа [tables] в приведенных кодах взята с потолка, т.е. это всего лишь значение индекса хэш-массива, что позволяет вам иметь таких таблиц сколько угодно с любыми названиями, лишь бы память сессии позволяла. Основным ограничением является структура полей записи временной таблицы, в примере имеется по 5 полей разных типов, если вам нужно больше, просто добавьте сколько считаете необходимым.
Пакет DBMS_ALERT поддерживает отправку и получение асинхронных уведомлений о событиях (alerts). Это могут быть уведомления об изменении данных в БД, отправленные триггером, или об окончании выполнения некоторой процедуры. Приложение в отдельном сеансе ожидает уведомления, на которые подписалось, и обрабатывает их тем или иным образом, например, отражая наступившие события в пользовательском интерфейсе или выполняя операции с данными, зависящие от наступления события.
Вот основные свойства уведомлений DBMS_ALERT , почерпнутые мной из официальной документации:
Во втором сеансе отправим уведомление myalert и вернемся к первому сеансу, чтобы увидеть результат.
- один сеанс посылает уведомления при помощи DBMS_ALERT.SIGNAL и COMMIT .
- другой сеанс
- подписывается на уведомления при помощи DBMS_ALERT.REGISTER ,
- ожидает уведомления при помощи DBMS_ALERT.WAITONE (или WAITANY ) и обрабатывает их,
- удаляет подписку на уведомления, когда в них больше нет необходимости.
Попробую отправлять разные уведомления из нескольких параллельных сеансов и получать эти уведомления в другом сеансе.
Для этого создам процедуру signaller , которая будет посылать 10 уведомлений bang или boom , выбирая из двух случайным образом (строка 8 ниже). Отправив уведомление, процедура спит случайное число секунд между 1 и 7, имитируя занятость, и затем отправляет следующее уведомление. Для создания процедуры текущий пользователь должен явно (не через роль) получить привилегии EXECUTE на пакеты SYS.DBMS_ALERT и SYS.DBMS_LOCK .
Для получения уведомлений bang и boom создам процедуру consumer с параметром p_sleep - числом секунд между вызовами DBMS_ALERT.WAITANY . На это время consumer будет делать паузы между ожиданиями уведомлений, что приведет к потере некоторых уведомлений, если они отправляются достаточно часто. По умолчанию p_sleep равен 0, что практически устраняет паузы между ожиданиями, и уведомления не должны теряться.
Каждый раз процедура ожидает уведомления не более 10 секунд - см. значение параметра timeout при вызове DBMS_ALERT.WAITANY в строке 11.
Теперь, с помощью DBMS_SCHEDULER , я запущу процедуру signaller параллельно в двух сеансах и процедуру consumer в текущем сеансе:
Как видим, в текущем сеансе приняты все отправленные уведомления. Повторим эксперимент, введя паузу в 10 секунд между ожиданиями уведомлений:
На этот раз часть уведомлений была потеряна, чего и следовало ожидать.
В официальной документации по СУБД Oracle 11gR2 можно подробно познакомиться со всеми процедурами и функциями DBMS_ALERT . А я перейду к экспериментам с пакетом DBMS_PIPE , удалив ненужные теперь процедуры:
Пакет DBMS_PIPE позволяет двум или более сеансам пересылать друг другу данные по именованным каналам (pipes). Вот основные сведения о DBMS_PIPE :
Следующий PL/SQL блок открывает три канала - частный явный, публичный явный и публичный неявный:
Итак, каналы были созданы. Теперь удалю созданные каналы, воспользовавшись DBMS_PIPE.REMOVE_PIPE для явных каналов и прочитав данные из неявного:
Как видим, после удаления каналы остались во вью v$db_pipes . Однако, вызов DBMS_PIPE.REMOVE_PIPE сбросил в 0 размеры каналов и изменил тип канала my_private_pipe с PRIVATE на PUBLIC . Не совсем то, чего можно было ожидать! При этом вызовы функции DBMS_PIPE.REMOVE_PIPE вернули статус 0, следовательно, выполнились без ошибок. В утешение остается заметить, что вью v$db_pipes не упоминается в документации по пакету DBMS_PIPE . И нет необходимости в него смотреть.
Завершая разговор о DBMS_PIPE , замечу, что не все мои эксперименты с этим пакетом прошли гладко и привели к ожидаемому результату. Кто заинтересовался, может подробнее познакомиться с процедурами и функциями DBMS_PIPE по официально документации по СУБД Oracle и продолжить эксперименты.
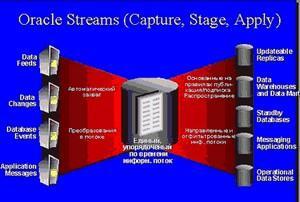
С разрастанием компаний появляется потребность в наличии возможности совместного использования информации между несколькими базами данных и приложениями. Применение разнородных технологий для совместного использования информации лишь усложняет эффективную репликацию. Технология Oracle Streams (Потоки Oracle) представляет собой единое универсальное решение для осуществления обмена информацией по всему предприятию.
В контексте Oracle Streams каждая единица информации называется событием (event), и обмен всеми такими событиями осуществляется в потоке. Поток передает указываемую информацию в указываемые пункты назначения. Oracle Streams захватывает происходящие в базе данных изменения за счет использования как активных, так и архивных журналов повторного выполнения. Он перехватывает их и сохраняет в очередях после выполнения надлежащего форматирования, а затем передает в другие базы данных и, если нужно, применяет их там. С его помощью информацию можно захватывать (собирать), передавать и применять и в пределах одной и той же базы данных Oracle, и между двумя базами данных Oracle, и между несколькими базами данных Oracle и даже между базой данных Oracle и базой данных другого типа (не Oracle).
На заметку! Oracle Streams может применяться на нескольких уровнях: на уровне базы данных, на уровне схемы и даже на уровне отдельных таблиц, и использовать для осуществления перехвата изменений на этих уровнях различные правила.
Архитектура Oracle Streams
Тремя базовыми элементами технологии Oracle Streams являются этап захвата, этап подготовки и этап потребления событий внутри базы данных Oracle.
- Сервер считывания, который считывает журналы повторного выполнения и разбивает их на разделы.
- Один или несколько серверов подготовки, которые сканируют разделы журналов параллельным образом и выполняют предварительную фильтрацию изменений.
- Сервер построения, объединяющий записи из журналов повторного выполнения, которые он получает от серверов подготовки и передает их процессу захвата.
Далее процесс захвата преобразует объединенные записи данных повторного выполнения в логические записи изменений (Logical Change Records — LCR) и передает их на этап подготовки для дальнейшей обработки. Каждая LCR-запись описывает изменения, внесенные в одну строку оператором DML. Один оператор DML может приводить к генерации нескольких LCR-записей. LCR-запись, которая представляет собой набор захваченных изменений, также называется событием (event). LCR-записи, содержащие информацию о данных таблицы, называются логическими записями изменений строк (row LCR), а те, что содержат информацию о DDL-изменениях — логическими записями изменений DDL (DDL LCR). Правила, используемые в процессе захвата, зависят от того, какие изменения захватываются. Обратите внимание, что Oracle Streams можно настраивать так, чтобы база данных могла извлекать изменения из потока данных повторного выполнения в исходном месте и затем передавать в целевое место либо отдельно только LCR-записи, либо весь поток данных повторного выполнения с последующим извлечением необходимых LCR-записей непосредственно в самом целевом месте.
На этапе подготовки (staging) процесс Oracle Streams сохраняет события в очереди. В число этих событий могут входить изменения, захваченные как явным, так и не явным образом.
На последнем этапе, этапе потребления (consumption), находящиеся в очереди события начинают использоваться в целевой базе данных. Перед использованием событие должно удаляться из очереди. Пользователи и приложения могут удалять события из очереди явным образом. Однако по большей части их удаление из очереди происходит все-таки в рамках неявного процесса применения (apply process). Удаление из очереди и обработка захваченных данных осуществляется в соответствии с правилами. В ходе процесса применения захваченные данные могут как применяться напрямую, так предварительно преобразовываться с использованием кода PL/SQL.
Настройка Oracle Streams
Ниже перечислены шаги, которые необходимо выполнить для настройки механизма Oracle Streams и администрирования осуществляемых с его помощью операций по передаче изменений между несколькими базами данных. Следует иметь в виду, что тут предлагается лишь очень краткий обзор процесса настройки Oracle Stream, чтобы у вас могло сложиться общее впечатление о том, что он собой представляет. Для настоящей настройки Oracle Streams следует обязательно использовать соответствующие инструкции, предлагаемые в руководствах по Oracle.
1. Сначала нужно внести необходимые изменения в файл init.ora или SPFILE.
- Проверить, чтобы в параметре COMPATIBLE была указана версия 10.2.0 или выше в обеих базах данных (на самом деле в нем можно даже указывать версию 9.2 или выше).
- Проверить, чтобы для параметра JOB_QUEUE_PROCESSES в исходной базе данных было установлено, как минимум, значение 2.
- Проверить, чтобы для параметра GLOBAL_NAMES как в исходной, так и в целевой базе данных было установлено значение true.
- Установить параметр LOG_ARCHIVE_DEST_n. Нужно, чтобы на сайте, отвечающего за основной процесс захвата, присутствовало хотя бы одно место для размещения архива журналов.
- Проверить, чтобы под компонент памяти STREAMS_POOL_SIZE в SGA было выделено хотя бы 200 Мбайт.
- Удостовериться в том, что табличное пространство является достаточно большим для того, чтобы удовлетворять требования параметра UNDO_RETENTION.
- Удостовериться в том, что исходная база данных функционирует в режиме архивирования журналов (ARCHIVELOG).
2. Затем необходимо создать нового пользователя для управления Oracle Streams. Перед его созданием может потребоваться создать для него новое табличное пространство:
Теперь можно создать в базе данных самого пользователя, ответственного за администрирование Oracle Streams, как показано ниже:
3. Далее нужно выдать пользователю–администратору Oracle Streams (strmadmin) привилегии CONNECT, RESOURCE и DBA:
4. Для предоставления необходимых привилегий администратору Oracle Streams следует использовать процедуру GRANT_ADMIN_PRIVILEGE из пакета DBMS_STREAMS_AUTH:
5. Затем необходимо создавать канал связи между исходной и целевой базой данных, как показано ниже:
6. Oracle Streams осуществляет перемещение данных между исходной и целевой базой данных с помощью очередей. Поэтому далее необходимо создать очередь как в исходной, так и в целевой базе данных. Для этого потребуется выполнить в той и другой следующую процедуру, которая подразумевает создание обеих очередей с принятыми по умолчанию именами.
7. Далее нужно включить дополнительную журнализацию для всех тех таблиц в исходной базе данных, для которых планируется перехватывать изменения. Делается это следующим образом:
8. И, наконец, напоследок необходимо сконфигурировать процесс захвата в исходной базе данных с использованием процедуры ADD_TABLE_RULES из пакета DBMS_STREAMS_ADM:
После настройки Oracle Streams в соответствие с перечисленными выше шагами можно тестировать настроенную конфигурацию, запустив процесс захвата и применив процесс применения для репликации данных таблицы (в данном примере — emp) из исходной базы данных в аналогичную таблицу в целевой базе данных. Для захвата изменений используется следующая процедура:
Для переноса захваченных изменений в целевую базу данных служит такая процедура:
Технология Oracle Streams была рассмотрена в этой статье моего блога очень кратко. Тем не менее, она представляет собой очень мощное и полезное средство для выполнения в базах данных операций по репликации, переносу и обновлению данных. Главным интерфейсом к Oracle Streams служит соответствующая коллекция поставляемых Oracle пакетов PL/SQL. Здесь было показано, как применять некоторые из этих пакетов для настройки и управления механизмом Oracle Streams, чтобы вы могли посмотреть, что конкретно происходит на этапе захвата и передачи изменений. Для оказания помощи пользователям в настройке, администрировании и мониторинге сред Oracle Streams компания Oracle поставляет специальный инструмент Streams в составе интерфейса OEM Console. Для удобства работы с Oracle Streams рекомендуется использовать именно его.
Я пытаюсь решить проблему, которая, на этот раз, я не создавал.
Я работаю в среде со многими веб-приложениями, поддерживаемыми различными базами данных на разных серверах.
каждая база данных довольно уникальна в своем дизайне и применении, но в каждой из них все еще остаются общие данные, которые я хотел бы абстрагировать. Каждая база данных, например, имеет таблицу поставщиков, таблицу пользователей и т. д.
Я хотел бы абстрагировать эти общие данные в один но все же пусть другие базы данных присоединяются к этим таблицам, даже имеют ключи для обеспечения ограничений и т. д. Я в среду в MSSQL.

какие варианты? Как я это вижу, у меня есть следующие варианты:
- связанные серверы
- только для чтения Логинов, чтобы дать доступ к представлениям
что-нибудь еще рассмотреть?
есть много способов решить эту проблему. Я настоятельно рекомендую либо решения 1, 2 или 3 в зависимости от ваших бизнес-потребностей:
Я использовал репликацию транзакций, чтобы вытеснить более 100 таблиц из хранилища данных для разделения нижестоящих приложений, которым необходим доступ к агрегированным данным из нескольких систем. Поскольку наше хранилище данных обновлялось ежечасно по расписанию из зеркальных и логарифмических источников данных, производственные приложения имели данные из многочисленных систем в пределах скользящего окна от 20 до 80 минут каждый час.
одноранговой репликация транзакций как тип публикации может быть лучше подходит для случая использования, который вы предоставили. Это может быть очень полезно, если вы хотите развернуть схему или репликацию изменений узла за узлом. Стандартная репликация транзакций имеет некоторые ограничения в этой области.
типы публикаций репликации моментальных снимков имеют большую задержку, чем публикации транзакций, но вы можете рассмотреть ее, если допустима степень задержки.
хотя вы упомянули Вы магазин Microsoft SQL Server, пожалуйста, имейте в виду, что другие СУБД имеют аналогичные технологии. Поскольку вы говорите о MS SQL Server конкретно, обратите внимание, что репликация транзакций также позволяет реплицироваться в базы данных Oracle. Так что если у вас есть несколько из них в вашей организации, это решение может работать.
недостатком использования репликации транзакций является то, что если вы центральный сервер идет вниз, вы можете начать испытывать задержку с данными в нижестоящих копиях реплицируемый объект. Если реплицированные объекты (статьи) действительно большие, и вам нужно повторно инициализировать таблицу, то это может занять очень много времени.
Связанные Серверы: похоже, вы уже думали об этом. Вы можете предоставить данные через связанные серверы. Я не думаю, что это хорошее решение. Если вы действительно хотите пройти этот маршрут, подумайте о настройке асинхронного зеркала из центральной базы данных на другой сервер, а затем настройте связанные подключения сервера к зеркалу. Это по крайней мере уменьшит риск того, что запрос из веб-приложений вызовет блокировку или проблемы с производительностью Центральной производственной базы данных.
IMO, связанные серверы, как правило, являются опасным методом обмена данными для приложения. Этот подход по-прежнему рассматривает данные как гражданина второго класса в вашей базе данных. Это приводит к некоторым довольно плохим привычкам кодирования, особенно потому, что ваши разработчики могут работать на разных серверах на разных языках с разными методами подключения. Вы не знаете, если кто-то напишет по-настоящему henious запрос против ваших основных данных. Если вы установили стандарт, который требует нажатия полной копии общих данных на неосновной сервер, вам не нужно беспокоиться о независимо от того, пишет ли разработчик плохой код. По крайней мере, с точки зрения того, что их плохой код не будет jeapordize производительность других хорошо написанных систем.
есть много, много ресурсов, которые объясняют, почему использование связанных серверов может быть плохим в этом контексте. Неисчерпывающий перечень причин включает: (a)учетная запись, используемая для связанного сервера, должна иметь разрешения DBCC SHOW STATISTICS, иначе запросы не смогут использовать существующую статистику, (b) подсказки запроса не могут быть uesd, если они не представлены как OPENQUERY, (c) параметры не могут быть переданы при использовании с OPENQUERY, (d) сервер не имеет достаточной статистики о связанном сервере, следовательно, создает довольно ужасные планы запросов, (e) проблемы с сетевым подключением могут вызвать сбои, (f) любой из этих пяти вопросов производительности, и (g)страшная ошибка контекста SSPI при попытке проверки подлинности учетных данных Windows active directory в двойном прыжке сценарий. Связанные серверы могут быть полезны для некоторых конкретных сценариев, но создание доступа к центральной базе данных вокруг этой функции, хотя и технически возможно, не рекомендуется.
массовый процесс ETL: если высокая степень задержки приемлема для веб-приложений, то вы можете написать массовые процессы ETL с SSIS (много хороших ссылок в этом вопросе StackOverflow) которые выполняются заданиями агента SQL Server для перемещения данных между сервера. Существуют также другие альтернативные инструменты ETL, такие как Informatica, Pentaho и т. д. используй то, что лучше для тебя.
Это не хорошее решение, если вам нужна низкая степень задержки. Я использовал это решение при синхронизации с сторонним CRM-решением для полей, которые могут переносить высокую задержку. Для полей, которые не могли выдержать высокую задержку (основные данные создания учетной записи), мы полагались на создание дубликатов записей в CRM через вызовы веб-службы в точке генерация счета.
ночное резервное копирование и восстановление: Если ваши данные могут переносить высокую степень задержки (до дня) и периоды недоступности, вы можете создавать резервные копии и восстанавливать базу данных в разных средах. Это не очень хорошее решение для веб-приложений, которым требуется 100% время работы. Идея заключается в том, что вы берете базовую резервную копию, восстанавливаете ее до отдельного имени восстановления, а затем переименовываете исходную базу данных и новую, как только новая будет готова к использованию. Я видел, как это делается для некоторых внутренних веб-приложений, но я обычно не рекомендую этот подход. Это лучше подходит для более низкой среды разработки, а не для производственной среды.
Журнал Доставки Вторичных: вы можете настроить доставку журналов между основным и любым количеством второстепенных. Это похоже на ночной процесс резервного копирования и восстановления, за исключением того, что вы можете обновлять базу данных чаще. В одном случае это решение было использовано для предоставления данных из одной из наших основных основных систем нижестоящим пользователям путем переключения между двумя получателями доставки журналов. Был еще один сервер, который указывал на две базы данных и переключался между ними, когда новая была доступна. Я действительно ненавижу это решение, но один раз я видел эту реализацию, она отвечала потребностям бизнеса.
Читайте также: