
Oracle сохранить изменения в бд
Обновлено: 06.07.2024
Добрый день, участники сообщества!
По многочисленным просьбам сегодня я расскажу как можно создать и поднять бэкап Terrasoft на СУБД Oracle.
Сделать это очень просто, все делается автоматически -- нужно лишь запустить командный файл и ввести названия базы данных.
Создание бэкапа
- Распаковываем содержимое архива Backup.zip на сервер, где установлен сервер Oracle.
- Запускаем BackupDatabase.cmd.
- Указываем: название схемы, ее пароль (схемы-пользователя) и название файла дампа базы.
- В результате получаем два файла: Grant.sql -- скрипт по созданию розданных прав и собственно сам дамп базы Oracle.
Поднятие бэкапа
- Распаковываем содержимое архива Restore.zip на сервер, где установлен сервер Oracle.
- Сюда же обязательно подкладываем два файла (Grant.sql и дамп), которые были созданы при создании бэкапа.
- Запускаем RestoreDatabase.cmd.
- Указываем: пароль пользователя SYS, название файла дампа базы (backup db file name), старое название схемы с которой делался дамп (old user schema), название новой схемы (new user schema) и пароль пользователя новой схемы (new user password).
- Дальше все выполнится автоматически: создастся новая схема, раздадутся нужные права, создадутся нужные типы, подымется бэкап базы под указанной схемой, заменятся завязки объектов в системных таблицах Terrasoft на новые, раздадутся нужные права ролям на таблицы и представления.
В инсталляции Terrasoft уже идут в комплекте похожие скрипты, но там все завязано на то, что база создавалась со схемы TSAUTOBUILD. Мои скрипты дополнительно запрашивают название старой схемы.
Описал коротко, только самое нужное. Если будут вопросы - с удовольствием отвечу.
Отмечу, что выложенную информацию необходимо рассматривать как пример, который каждый можете менять под свои потребности. Эти скрипты применимы для Oracle установленного на ОС Windows и запуск командного файла нужно производить на самом сервере. Для всех остальных вариантов (другая ОС, запуск с клиентской машины) можете дописать сами.
Ключевым моментом при создании бекапа является скрипт Grant.sql (см. Backup.zip), который создает "слепок" розданных прав для модели, которая применена в Terrasoft CRM.
UPD: Спасибо Саше Котенко за найденный недочет в файле BackupDatabase.cmd. Исправил.
Большое спасибо, Саша.
Саша, спасибо за удобный инструмент! С твоего позволения беру в эксплуатацию!
И да +1 :wink:
Саша, огромное спасибо! Данная инструкция и материал очень помогут всем, кто сталкивается с Oracle-версией продукта.
Указывайте пожалуйста требования к использованию скриптов.
Здесь:
1. скрипт для Windows (чаще для поддержки Oracle используются другие ОС),
2. вне скрипта определена переменная среды ORACLE_SID.
Согласно документации рекомендованно:
1. формат авторизации sqlplus из командной строки (например BackupDatabase.cmd строка 12) определяется как sqlplus login/password@sid, а в Вашем случае (без указания сида) получим ERROR: ORA-12560: TNS:ошибка адаптера протокола
2. Использование команды без логирования тоже не лучший вариант.
ihmo статья скорее вредна, очень удивили оставленные комментарии :(
to alexk
Ничего удивительного в этом нет. Для кого-то информация полезна, например для тех, кто не часто сталкивается с Oracle. А для того, кто имеет больше опыта работы с Oracle, что-то может показаться очевидным. В любом случае, спасибо за комментарии. Внесем необходимые корректировки.
Здравствуйте.У меня возник вопрос.Мне предстоит установить сервер Terrasoft и интегрировать террасофт в существующую структуру.но никогда не работал с базой даннх оракл.
Как я понимаю пункт 1 надо делать, если существует старая база данных?Или как? В руководстве описано по другому.Но в руководстве как я понял предполагается что сервер базы данных оракл и сервер террасофт это один физический компьютер.А мне надо разнести их по разным ролям.в руководстве написано:
Для восстановления БД на сервере необходимо:
1. Запустить файл RestoreDatabase.cmd, который находится в
директории \DB>, нажав
на клавишу [Enter].
Какой сервер иммется ввиду?Наверно сервер баз данных оракл?Но там этого пути не будет если сам софт будет стоять отдельно!Помогите разобраться пожалуйста!
Такого понятия как "сервер Террасофт" - не существует. Вы устанавливаете БД Oracle на машине, которую назначите в роли сервера БД. Далее Вы устанвливаете клиентские приложения Террасофт и соединение с БД соглагласно руководству.
Terrasoft Support Team.
Есть ли изменения в инструкции(по созданию/поднятию бекапа) для версий 3.4.0+ ?
Немного подкорректировал скрипт SysGrants.sql из инструментария восстановления бекапа версии 3.3.2.
Ранее там было указано:
В результате чего приходилось вручную заменять TSAUTOBUILD на имя вашей схемы, откуда происходил экспорт. Теперь это название будет автоматически подтягивать имя из введенной вами информации при запуске RestoreDatabase.cmd.
Исправленный restore_3_3_2.zip обновлен.
Клиенты часто спрашивают, почему при поднятии резервной копии Oracle выдает предупреждения, а также почему некоторые объекты после импорта в невалидном состоянии.
Попытаюсь ответить на эти вопросы.
Тип объекта "SCHEMA_NAME"."t_FieldInfo" уже существует с другим идентификатором
В нашей системе используются объектные типы БД Oracle, OBJECT TYPE.
Дело в том, что Oracle жестко связывает объектные типы с их идентификаторами, OID.
При этом если на сервере был однажды восстановлен бекап схемы Terrasoft, там создадутся все используемые типы ("t_GetLoginInfo", "tbl_GetLoginInfo" и др.).
Но из-за жесткой привязки к OID, эти типы создадутся с OID, который прописан в дампе.
Первый раз все будет нормально. Но при поднятии того же, либо другого бекапа схемы Terrasoft на том же сервере, он опять будет создавать типы с теми же OID – в результате возникнет ошибка: объект с таким OID уже существует. В результате после поднятия бекапа ни один из типов не создастся.
Из-за этой особенности Oracle, мы сделали в скриптах поднятия наших схем обходное решение:
- Перед поднятием бекапа скриптом CreateTypes.sql явно создаются все необходимые типы, при создании Oracle сгенерирует им новые OID.
- При поднятии Oracle пытается создать типы из бекапа c их старыми OID, при этом выдается ошибка IMP-00061: Внимание: Тип объекта "Схема"."Тип" уже существует с другим идентификатором
При возникновении такой ошибки, создание типа пропускается.
Но в нашем случае это не является ошибкой, т.к. это сделано специально в качестве обходного решения. Все необходимые объектные типы создадутся нашим скриптом непосредственно перед поднятием бекапа.
После поднятия бекапа некоторые объекты невалидны
Это также не является ошибкой, а просто предупреждением.
При импортировании схемы вначале переносятся таблицы и представления, затем триггеры и уже после этого хранимые процедуры и функции.
Если в одном из триггеров используется вызов какой-либо хранимой процедуры - после импорта он будет невалидным.
Переходим от теории к практике. В нашей системе у многих таблиц есть строчный триггер BEFORE INSERT OR UPDATE, например такой:
Как видим по коду, этот триггер вызывает функцию fn_CreateGUID, которой на момент переноса триггера просто нет. Она создастся позже, со всеми остальными ХП. Из-за этого триггер остается невалидным.
Но это абсолютно нормальная ситуация. Дело в том, что любой объект БД Oracle, находящийся в невалидном состоянии будет автоматически скомпилирован СУБД "на лету", при первом обращении кнему. В этот момент уже будут доступны и валидны все зависимые объекты (ХП, Типы и т.д.) и триггер скомпилируется корректно и станет валидным.
Подробнее об этом в документации Oracle.
Система администрирования Oracle в версии 341 существенно изменилась. В связи с этим, изменился также и механизм создания и восстановления резервных копий.
Что изменилось в новых скриптах работы с бекапами для 341
- Появилась возможность указывать инстанс Oracle для разворачивания бекапа
- Можно указать отдельное табличное пространство для разворачивания схемы
- Исправлена ситуация с экспортом пустых таблиц (Oracle 11)
В новой системе администрирования практически все права пользователю назначаются через роли. Поэтому при восстановлении резервной копии появилось 3 опции - режимы переноса прав пользователей. Остановлюсь на этом более подробно.
Опция № 0 - Перепривязать пользователей в новую схему (по умолчанию)
При этом все пользователи Terrasoft, создадутся и им будут розданы и назначены по-умолчанию роли для доступа к новой схеме (к той которую вы разворачиваете). У пользователей автоматически заберется доступ на старую схему. Этот вариант подходит для первоначального поднятия бекапа на новом инстансе либо для перенос боевой схемы в новую схему.
Опция № 1 - Создать пользователей с перименованием
Этот вариант предполагает, что все пользователи Terrasoft будут созданы как новые пользователи Oracle c префиксами 'U' и им будет розданы все соответствующие права. Например в старой схеме был пользователь User1, после поднятия резервной копии новый пользователь будет User1U. Таким образом старый пользователь User1 будет продолжать нормально работать со старой схемой, а новый будет иметь все те же права в отношении новой схемы на одном инстансе. Этот вариант удобен при поднятии тестовой схемы на том же инстансе, где уже работает боевая схема. При этом пользователи будут абсолютно независимы.
Опция № 2 - Не создавать пользователей
В этом случае, при восстановлении резервной копии создастся только пользователь-схема Terrasoft. Ему назначаются права администратора Terrasoft и под ним нужно зайти для самостоятельного заведения нужных пользователей и заказа лицензий для них.
Приветствую всех! Часто на просторах интернета встречал вопрос, как сохранить изменения в базе данных. Тут все легко вызываем на адаптере метод Update(); и передаем ему в качестве параметров таблицу либо, DataSet. Выглядеть это может следующим образом:
Однако ситуация меняется кардинально если у нас DataGridView связан с БД и допустим с TextBox в котором мы производим изменения, для последующего сохранения данных. Связка происходит по средствам BindingSource.
Рассмотрим простой пример привязки данных DataGridView к БД и TextBox c БД для изменения информации и сохранения ее.
Как видите я разместил на форме Button, все остальные компоненты будут добавлены позже. Так же нам необходимо создать БД в проекте, в которой создадим таблицу, а в ней две колонки ID и Имя. Внесем несколько записей в БД. У меня получилось следующее:
После создания и внесение данных обновляем, сохраняем все. На этом этапе мы имеет БД с информацией, и приложение с компонентами на форме. Следующим этапом будет привязка компонента DataGridView к БД.
Далее у нас откроется мастер настройки источника данных. Повторяем все действия показанные на изображения ниже:
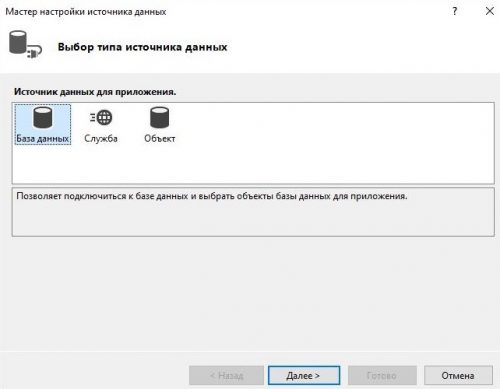
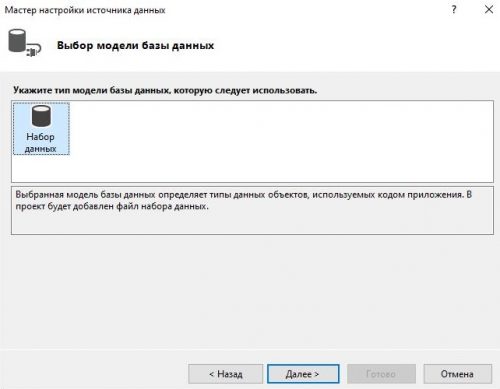
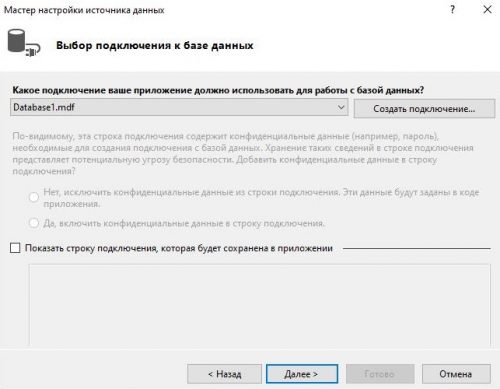
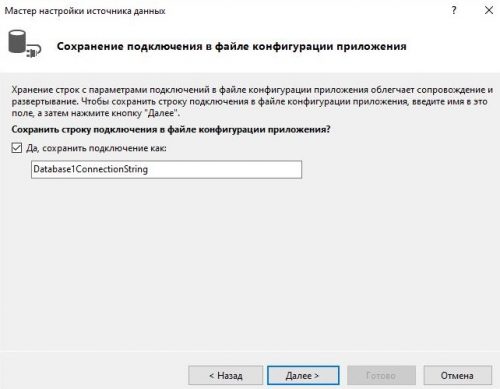
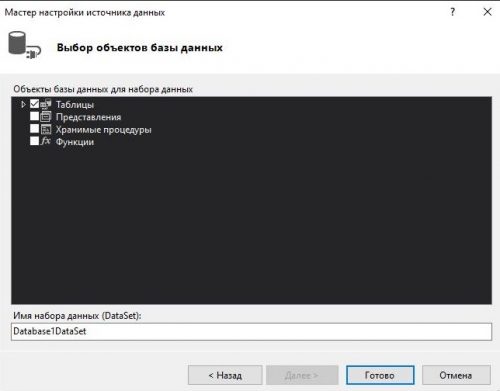
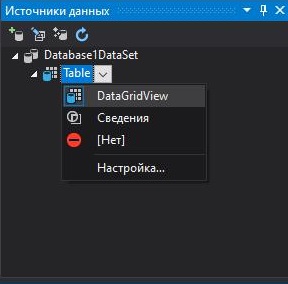
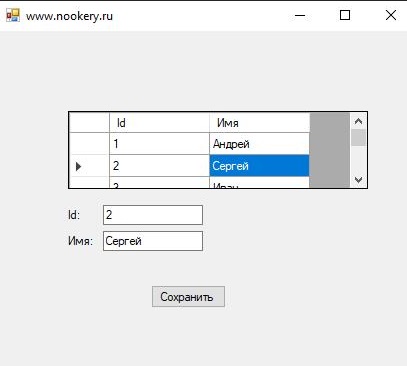
Теперь выбирая имя в DataGridView у нас выводит информацию в TextBox. В которой мы хотим реализовать возможность редактирования информации. Перейдя к событию мыши Click напишем следующий код:
Стоит так же отметить что у нас с генерировался и дополнительный код, в том числе и в главной форме.
Однако, есть ряд сценариев, когда необходимо обрабатывать изменения оперативно или в реальном времени. Это может быть нужно для немедленной передачи изменений удаленному клиенту, или для отправки уведомлений об изменениях заинтересованным лицам по электронной почте, или для отправки документа по назначению при изменении его статуса. В этом случае наиболее универсальным средством захвата изменений будет триггер на исходной таблице, записывающий изменения в таблицу изменений.
Поскольку захват изменений в таблицах БД и предоставление их клиентам для обработки задача достаточно распространенная, имеет смысл решить ее в общем виде и создать механизм для быстрой реализации частных решений. Такой механизм включает:
- таблицы изменений и триггеры, вставляющие в них строки при изменении исходных таблиц,
- реестр клиентов, обрабатывающих захваченные изменения,
- сервисы изменений, связанные с конкретным клиентом и использующие таблицу изменений,
- протокол получения изменений клиентом.
Таблица изменений в обязательном порядке должна содержать столбцы первичного ключа исходной таблицы, а также столбцы oper (операция) и when (время изменения). Кроме этого, она может содержать другие столбцы, соответствующие столбцам исходной таблицы - для сохранения изменяемых данных.
В таблице изменений можно регистрировать
- каждое изменение строк исходной таблицы,
- факты изменения строк исходной таблицы.
В варианте 1 в таблицу изменений последовательно записываются все случаи изменений исходной таблицы. Если одна и та же строка изменилась несколько раз, то в таблице изменений будет по одной записи для каждого изменения. Такой режим работы имеет смысл, когда в таблице изменений сохраняются изменяемые значения интересующих нас столбцов: получаем историю всех изменений. Например, история изменений полей status и amount для строки с первичным ключом 1012 :
В варианте 2 регистрируются факты изменений каждой отдельной строки, но не вся история изменений и не измененные данные. При этом в таблице изменений имеется максимум одна запись для одной строки исходной таблицы, а значения в столбцах oper и when отражают, какая команда DML была выполнена последней для данной строки и время ее выполнения:
Для каждой из трех строк исходной таблицы в приведенном примере могли быть выполнены одно или несколько изменений, однако таблица изменений хранит только данные последнего изменения.
Такой режим подходит для передачи изменений в исходной таблице внешнему клиенту через интерфейсное вью (представление). Строки исходной таблицы при этом соединяются со строками таблицы изменений по первичному ключу, чтобы получить только измененные строки. Строки, удаленные из исходной таблицы, представлены в таблице изменений первичным ключом, и передаются клиенту с признаком удаления. Ниже будет приведен детальный пример передачи изменений клиенту через интерфейсное вью.
В зависимости от решаемой задачи, триггер может захватывать не все, а только особые, представляющие интерес, изменения исходной таблицы. Например, только изменения поля статуса, или только операции update, после которых выполняется определенное условие с участием нескольких полей. Тогда записи в таблице изменений могут выглядеть как-то так:
В столбце oper вместо вида команды DML регистрируется тип наступившего события. В зависимости от решаемой задачи, многократное наступление события для одной и той же строки исходной таблицы может регистрироваться в отдельных записях таблицы изменений (по варианту 1) или приводить к обновлению единственной записи (по варианту 2).
Для одной исходной таблицы можно создать несколько триггеров, например, триггер для захвата специальных изменений и триггер для захвата фактов изменений строк.
В другом сценарии исходная таблица может иметь дочерние таблицы, ссылающиеся на ее первичный ключ, и вместе с дочерними таблицами описывать единую сущность предметной области. Тогда, для захвата изменений сущности, нужно создать триггеры как на родительской, так и на дочерних таблицах; все эти триггеры будут записывать изменения в общую таблицу изменений.
Таблица изменений имеет особенность, которая позволяет организовать выборку из нее в порядке внесения изменений в БД. Таблица изменений создается в режиме rowdependencies , что обеспечивает сохранение номера SCN для отдельных строк таблицы в момент завершения транзакции (см. Два кейса для ora_rowscn в Oracle 11g). Псевдостолбец ora_rowscn таблицы изменений, таким образом, содержит числовое значение, которое непрерывно возрастает с каждой завершенной транзакцией.
Номер изменения в псевдостолбце ora_rowscn таблицы изменений можно с успехом использовать для организации обработки изменений несколькими клиентами. Для этого клиент должен каждый раз обрабатывать изменения с номерами, большими, чем обработанный в прошлый раз. В специальной таблице будем хранить связку (таблица изменений, клиент, последний обработанный номер ora_rowscn ). Назовем такие связки сервисами, дадим каждой связке имя, так, чтобы сочетание (клиент, сервис) было уникальным, и предоставим клиентам возможность получать и изменять последний обработанный номер изменения для данного сервиса.
Полезным побочным эффектом от хранения номера последнего обработанного изменения на стороне БД-источника (а не на стороне клиента) является возможность автоматически удалять из таблицы изменений строки, уже обработанные всеми клиентами.
Протокол получения и обработки клиентом последних изменений будет выглядеть так:
- получить номер последнего обработанного клиентом изменения и текущий максимальный номер изменения для сервиса А ,
- обработать строки из соответствующей таблицы изменений (или интерфейсного вью) с номерами ora_rowscn , большими, чем номер последнего обработанного изменения и меньшими или равными текущему максимальному номеру изменения из п. 1,
- обновить номер последнего обработанного изменения для сервиса A , присвоив ему текущий максимальный номер изменения из п. 1.
Следующие две таблицы и пакет at_delta предоставляют инфраструктуру для реализации вышеописанного механизма захвата изменений для передачи клиентам:
Таблица at_cdc_ (от английского change data capture) хранит имена и типы созданных таблиц изменений. В частности, доступность списка всех таблиц изменений позволяет организовать их автоматическую очистку. (Столбец cdс_type определяет, каким образом захватываются изменения, - с помощью триггера и таблицы изменений или с помощью псевдостолбца ora_rowscn самой исходной таблицы. В последнем случае не нужны триггер и таблица изменений, но невозможно регистрировать удаление строк из исходной таблицы; можно получить только новые и измененные строки при условии, что исходная таблица была создана в режиме rowdependencies .)
Таблица at_svs_ хранит параметры сервисов, созданных для клиентов, и позволяет реализовать протокол получения изменений клиентом (получения дельты клиентом).
Приведу спецификацию пакета at_delta :
Пакет at_delta содержит процедуры для
- создания таблицы изменений,
- удаления таблицы изменений,
- создания клиента,
- удаления клиента,
- создания сервиса,
- удаления сервиса,
- очистки таблиц изменений.
Для иллюстрации того, как работает предложенное решение, создам простую сущность - таблицу itemz , изменения в которой будут регистрироваться (по варианту 2) и предоставляться двум клиентам:
Захват изменений и их предоставление клиенту организуется за три шага:
- создание таблицы изменений, триггера и интерфейсного вью,
- создание клиента (если ранее не создан),
- создание сервиса изменений.
Создам таблицу изменений с помощью пакета at_delta :
Созданная таблица изменений содержит только два обязательных столбца, oper и when . Другие столбцы, специфичные в каждом конкретном случае, необходимо добавить. Добавлю столбец id для значений первичного ключа исходной таблицы; одновременно, этот столбец будет первичным ключом таблицы изменений:
В столбце oper будет храниться буква m для операций insert и update , и буква d для операции delete на исходной таблице.
Создам триггер, регистрирующий изменения в исходной таблице по варианту 2:
И, наконец, создам интерфейсное вью, из которого клиент будет забирать изменения исходной таблицы:
Интерфейсное вью не является обязательным для предоставления изменений клиентам - ведь клиент может самостоятельно выполнять соединение таблицы изменений с исходной таблицей и делать необходимую обработку. Однако с интерфейсным вью работать удобнее и клиентам и БД-источнику, где оно позволяет настроить гибкий доступ к изменениям для внешних клиентов. (Кроме того, оказалось удобным давать сервисам такие же имена, как интерфейсным вью, см. ниже.)
Теперь, когда созданы таблица изменений и интерфейсное вью, мы готовы определить клиентов и сервисы, с помощью которых клиенты будут получать изменения. Продемонстрирую, как это делается, не углубляясь в детали реализации пакета at_delta .
Пусть клиенты ABC и XYZ заинтересованы в получении изменений сущности itemz . Зарегистрирую клиентов и сервисы для них:
При создании клиента для него создается сервисное вью at_svs_<client> (на базе таблицы at_svs_ ) и триггер instead of update на этом вью. С помощью сервисного вью клиент видит все сервисы, с которыми работает, и может получить и обновить номер последнего обработанного изменения в столбце last_scn . (Само изменение столбца таблицы at_svs_ выполняется процедурой пакета at_delta2 , вызываемой триггером.)
Теперь выполню от имени клиента ABC сеанс получения последних изменений сущности itemz :
Пока неинтересно, так как никаких изменений в itemz не было; таблица itemz вообще пуста. Добавлю в нее строки и снова получу изменения от имени клиента ABC :
Итак, клиент ABC получил изменившиеся строки сущности itemz и отразил это в сервисном вью:
Клиент XYZ , работающий по своему расписанию, пока не получил изменений:
Внесу еще пару изменений в itemz . Затем получу изменения от имени каждого из двух клиентов:
Вот так это работает.
Нужно ли напоминать, что это только базовая демонстрация? При реальной работе внешних клиентов с БД, каждый клиент будет подключаться к отдельной схеме, в которой ему будут доступны только его сервисное вью at_svs_<client> , пакет at_delta2 (обновляет для клиента номер последнего обработанного изменения в таблице at_svs_ ) и интерфейсное вью. Внутренние клиенты, например, выполняемые по расписанию задачи в БД, могут пользоваться сервисом обработки изменений наравне с внешними клиентами.
Если описанное решение показалось вам неоправданно сложным, то примите во внимание эффект масштаба: когда у вас в БД множество сущностей, изменения в которых нужно отслеживать и так или иначе обрабатывать, то стандартное решение, охватывающее все случаи, оказывается очень выгодным. Попутно поддерживается актуальный список всех клиентов, сервисов и таблиц изменений.
Процедура at_delta.purge_cdc очищает таблицы изменений уже обработанных клиентами строк:
Удалю объекты, с которыми экспериментировал:
В заключение объясню, почему таблица изменений использует псевдостолбец ora_rowscn , а не обычный числовой столбец, заполняемый из некоторой непрерывно возрастающей последовательности (sequence). Потому что изменения в таблицы БД вносятся конкурентно в рамках разных транзакций. Числовой столбец, заполняющийся из последовательности, получит значение в момент срабатывания триггера, регистрирующего изменения в исходной таблице - то есть, до завершения транзакции. Возможно, задолго до завершения транзакции. Тем временем другие пользователи внесут другие изменения, которые будут помечены большими номерами изменений, и завершат свои транзакции, после чего клиент может обработать эти изменения и обновить максимальный номер обработанного изменения. А поскольку этот номер будет больше номера изменения из еще не завершенной транзакции, то клиент не увидит этого изменения даже после завершения транзакции! Ведь он всегда забирает изменения с номерами изменения большими, чем уже полученные ранее. Благодаря тому, что значение псевдостолбца ora_rowscn изменяется при завершении транзакции, а не во время выполнения команды DML, описанной проблемы не возникает.
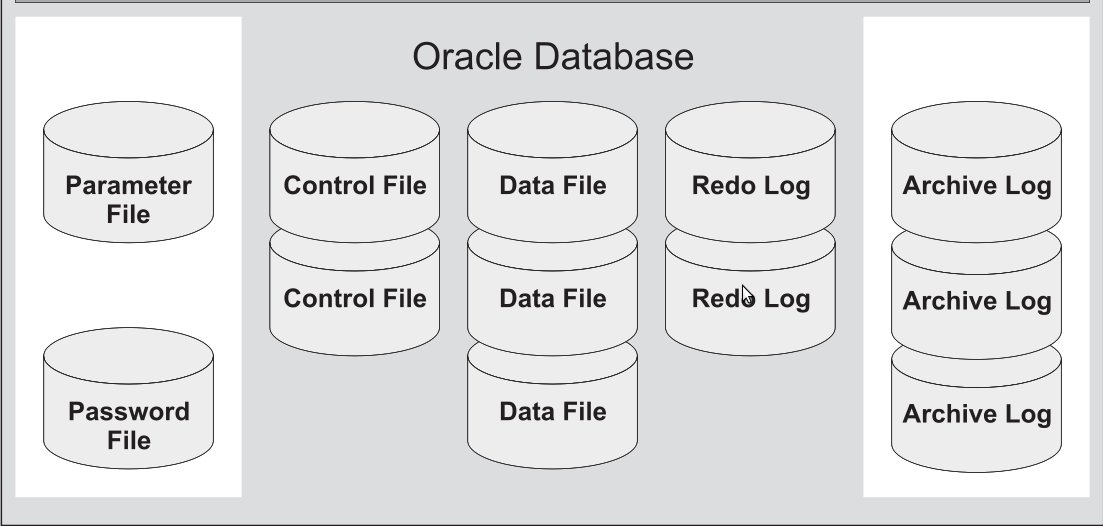
Предполагается, что вы инсталлировали базу данных, согласно документа.
Обязательные файлы:
Необязательные файлы:
-
(необязательные в том смысле, что база может быть настроена для работы без данных файлов) (Alertlog - если нет необходимости в изучении данных по ошибкам, можно удалить. Трассировочные файлы по умолчанию не создаются. Чтобы создавались, нужно включать трассировку и потом не забыть отключить) (По умолчанию не используются. Нужно специально создавать специальными командами.)
Файлы данных (Data Files)
Все данные в базе данных Oracle сохраняются в файлах данных. Все таблицы, индексы, триггеры, последовательности, программы на PL/SQL, представления - все это находится в файлах данных. И хотя эти и другие объекты базы данных логически содержатся в табличных пространствах, в действительности они сохраняются в файлах на жестком диске компьютера.
В каждой базе данных Oracle имеется по крайней мере один файл данных (но обычно их бывает больше). Если вы создаете в Oracle таблицу и заполняете ее строками, Oracle помещает эту таблицу и строки в файл данных. Каждый файл данных может быть связан только с одной базой данных.
У каждого файла данных имеется специальный формат, внутренний для программного обеспечения Oracle. Важно отдавать себе отчет в том, что файл данных состоит из заголовка и совокупности блоков. Заголовок файла данных Oracle содержит несколько структур, в том числе и идентификатор базы данных, номер и имя файла, тип файла, SCN создания и состояния файла.
Данные в файлы вносятся исключительно средствами Oracle.
Следующий запрос, покажет, где находятся файлы данных.
Оперативные файлы журналов повтора (Online Redo Log Files)
Оперативные файлы журналов повтора - предназначены для записи всех изменений, выполненных над данными базы данных Oracle. Используется для хранения на диске информации для повторного выполнения операций.
Для компьютера выполнить задачи повторно - означает выполнить ее точно так, как она выполнялась в предыдущий раз. Поэтому назначение оперативного файла журнала повтора заключается в сохранении информации об изменениях в базе данных таким, образом, чтобы позже их можно было повторить.
Каждая база данных должна иметь не менее двух оперативных файлов журналов повтора. Текущий файл постепенно заполняется, после его заполнения (или переключения некоторыми командами), база данных приступает к записи в следующий файл. Эта операция называется переключением журналов.
Поскольку файлы повтора необходимы для выполнения восстановления базы данных и являются критичными, их объединяют в группы. Запись происходит одновременно в файлы одной группы.
Управляющие файлы (Control Files)
Поскольку база данных Oracle является физическим набором связанных файлов данных, то для их синхронизации и контроля требуется особые методы. Для этих целей используются управляющие файлы.
База данных Oracle может иметь один или несколько управляющих файлов. Если имеется несколько управляющих файлов, все они должны быть абсолютно идентичными. При каждом запуске базы данных Oracle читает информацию управляющего файла, а при каждом изменении размещения или добавления новых файлов данных и журналов базы данных обновляет управляющий файл.
Файлы параметров pfile, spfie (Parameter Files)
Файлы параметров используются для конфигурирования действий Oracle предже всего при старте. Для того, чтобы запустить экземпляр базы данных, Oracle должен прочесть файл параметров и определить, какие параметры инициализации установлены для этого экземпляра. В файле параметров содержатся многочисленные параметры и их установленные значения. Oracle считывает файл параметров при запуске базы данных. Можно создать несколько файлов параметров, каждый будет соответствовать различным конфигурациям экземпляра.
- spfile - бинарный файл, который используется сервером Oracle при старте.
- pfile - текстовый файл с параметрами, будет использоваться при старте, если не будет найден spfile.
При старте, Oracle считает файл spfileora112.ora. (файл серверных параметров). Преимущество spfile заключается в том, что при работе с базой данных, любые изменения в базе касающиеся изменения параметра системы, автоматически записываются в данный файл.
Если используется pfile, для сохранения изменений, необходимо либо “руками вносить эти изменения” в текстовый файл, либо в консоли выполнять команды для создания данных файлов Ораклом.
Как я могу узнать, что моя база данных использует PFILE или SPFILE?
Выполните следующий запрос, чтобы увидеть какой файл параметров был использован:
Архивные файлы журналов повтора (Archive Log Files)
Как только оперативный файл журнала повтора (Redolog) оказывается заполнен, программное обеспечение сервера Oracle начинает запись в следующий файл. Эта операция повторяется, как следствие информация в оперативных файлах журнала (Redolog) многократно перезаписывается.
Если необходимо сохранить историю изменений, нужно, чтобы после переключения журналов сохранялась их копия. Для этого достаточно перевести работу базы данных в режим работы ARCHIVELOG.
Архивные файлы журналов повтора жизненно важны при восстановлении. Если часть базы данных потеряна или повреждена, то для устранения повреждений обычно требуется несколько архивных журналов или туева хуча этих журналов. Файлы журналов повтора должны применяться к базе данных последовательно. Если один из архивных файлов журналов повтора пропущен, то остальные архивные файлы журналов не могут использоваться. Храните все свои архивные файлы журналов повтора с момента выполнения последней резервной копии. Файлы журналов постепенно накапливаются и разрастаются. Иногда необходимо их удалять. Все операции с данными файлами по применению их к базе выполняются исключительно средствами базы данных. А копировать и переносить их при желании можно как угодно. Бездумно удалять их руками не рекомендуется.
Alert log и трассировочные файлы (trace file)
При работе базы данных события и ошибки регистрируются в текстовых файлах на сервере базы данных. Файл журнала предупреждений (alert log) нужен администратору базы данных для отслеживания важнейших действий с базой данных - наподобие открытия и закрытия базы данных, установления параметров загрузки базы данных и переключения оперативных журналов повтора. Также в эти файлы записываются многие ошибки базы данных для последующего расследования их причин. Любые структурные изменения базы данных также регистрируются в файле журнала предупреждений.
Когда возникает ошибка базы данных, может генерироваться файл трассировки (trace file). Они содержит подробную информацию о возникновении ошибки.
Файлы паролей (Password File)
Необязательный файл, используется для защиты информации о подключениях привилегированных пользователей. Если отсутствует, то вы можете выполнять администрирование своей базы данных, только локально. Кроме того, с его помощью контролируется количество привилегированных подключений для управления в одно и то же время.
Tags: Oracle Database, Файлы базы данных Oracle,
Oracle DBA
Лучше потратить какое-то количество времени, чтобы записать успешный опыт, чем потом повторно воспроизводить его по памяти.
Все материалы обновляются по мере нахождения лучших практик и апгрейда знаний. Если будут желающие добавлять свои знания или исправлять ошибки и неточности, пишите в телеграм чате. Если будет учавствовать больше людей, качество материалов будет улучшаться и обновляться быстрее. Ссылки на ваши профили в соц. сетях будут добавлены в статьях, в которых вы учавствуете.
Читайте также: