
Orm фреймворк для чего нужен
Обновлено: 03.07.2024
Что такое ORM? ORM дословно Object Relational Mapping - объектно-реляционное связывание - комплекс программ, позволяющих работать с базами данных, как если бы они были объектами языка программирования, в данном случае Python.
Использовать ORM в ваших проектах или нет - решать Вам, однако я настоятельно рекомендую ознакомиться с этой технологией, так как она широко используется во многих сферах, в том числе в Java Enterprise.
На сегодняшний момент существует несколько ORM для Python, среди них:
Наиболее популярной является 1 и 2, однако 3 и 4 являются хорошей альтернативой.
Системы ORM 1 и 2 - это два больших монстра, хотя и позволяют выполнить многое, но как говорит гугл, в этом случае производительность по сравнению с обычным SQL-запросом падает до 3 раз.
Системы 3 и 4 позиционируются как легковесные, не обладают полным функционалом 1 и 2, но его достаточно для выполнения большинства сложных запросов. Стоит отметить, что их производительность по сравнению с 1 или 2 выше.
Для простоты рассмотрим особенности работы с PeeWee.
Для установки пакета с командной строке наберите pip install peewee .
Определение модели
Классы модели, поля и экземпляры сущности все отображаются на концепцию базы данных.
| Термин | Соответствие |
|---|---|
| Класс модели | таблица в БД |
| Экземпляр поля | столбец в таблице |
| Экземпляр сущности | строка в таблице |
При создании проекта с peewee , можно начать с определения модели.
В этом примере мы создаем подключение к базе данных SQLite (файл people.db) и определяем класс модели Person . В этом же классе в подклассе Meta расположена database - переменная соединения с БД.
Внимание! мы назвали нашу модель Person вместо People . Вы должны придерживаться этого правила, даже если таблица будет содержать множество людей, мы всегда назовем класс существительным в единственном числе.
В PeeWee определено много типов столбцов:
| Field Type | Sqlite | Postgresql | MySQL |
| CharField | varchar | varchar | varchar |
| FixedCharField | char | char | char |
| TextField | text | text | longtext |
| DateTimeField | datetime | timestamp | datetime |
| IntegerField | integer | integer | integer |
| BooleanField | integer | boolean | bool |
| FloatField | real | real | real |
| DoubleField | real | double precision | double precision |
| BigIntegerField | integer | bigint | bigint |
| SmallIntegerField | integer | smallint | smallint |
| DecimalField | decimal | numeric | numeric |
| PrimaryKeyField | integer | serial | integer |
| ForeignKeyField | integer | integer | integer |
| DateField | date | date | date |
| TimeField | time | time | time |
| TimestampField | integer | integer | integer |
| BlobField | blob | bytea | blob |
| UUIDField | text | uuid | varchar(40) |
| BareField | untyped | not supported | not supported |
Чтобы открыть соединение с БД нужно написать
и хотя в мануале пишут, что это не обязательно, тем не менее это хорошая практика, так как позволяет обнаружить ошибки при соединении.
Определение связей происходит при помощи внешнего ключа
в этом примере создается таблица содержащая внешний ключ, который указывает на первичный ключ таблицы Person . Кроме того, в модель Person добавляется новое поле pets , которое отвечает за выборку всех объектов типа Pet , у которых внешний ключ равен первичному в таблице Person .
создание таблиц в БД происходит следующим образом:
db . create_tables ([ Person , Pet ])
сохранение экземпляра класса в БД происходит по команде:
grandma = Person . create ( name = 'Grandma' , birthday = date ( 1935 , 3 , 1 ), is_relative = True )
Подробная документация находится здесь
Прежде чем бросаться и писать ORM обертку для таблиц сущностей, сначала надо спроектировать логическую структуру БД или ХД. Установить все зависимости и способы взаимодействия между сущностями.
ORM SQLAlchemy
Работа с этой ORM начинается с импорта элементов из пакета sqlalchemy.
Для подключения к БД мы создаем объект Engine, который создает связку пула подключения и диалекта конкретной БД.
Далее нужно создать базовый класс для объявления сущностей наших данных
Потом мы описываем связываемые таблицы через наследование от класса Base .
В этом примере мы определили связку сущности User и таблицы users .
Для создания экземпляра сущности просто создайте объект класса User .
u = User ( name = 'Isac' , fullname = 'Newton' , password = '123' )
Указывать параметры при вызове конструктора не обязательно, присвоить значения полям экземпляра сущности можно и после.
Для того, чтобы связаться с базой данных и начать с ней диалог, создадим класс сессия.
теперь мы можем сохранять наши экземпляры сущностей в базу.
Обратите внимание, что после commit() поле id примет автоматически инициализированного значения. (id - первичный ключ, автоинкрементный)
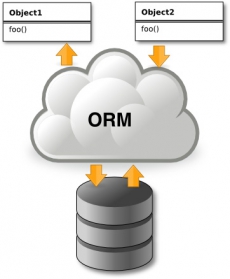
Любой, кто имеет опыт разработки web приложений или использования какого-либо PHP фреймворка, безусловно, сталкивался с реляционными базами данных, такими как MySQL или PostgreSQL. Работа с SQL напрямую, может быть достаточно сложной, особенно при работе с данными сразу из нескольких таблиц и при применении различных фильтров. А это как раз та сфера, где на сцену выходит ORM.
Так, что же такое ORM?
ORM – это аббревиатура для Object Relational Mapping (Объектно-реляционное отображение). Это такая методика или техника программирования, предназначенная для преобразования между несовместимыми типами данных в объектно-ориентированных языках программирования. Суть этого достаточно сложного определения заключается в том, что создается некая абстракция - “виртуальная объектная база”, запросы к которой, преобразуются в SQL команды, т.е. больше не нужно писать SQL-запросы к базе данных вручную (хотя в некоторых, достаточно нетривиальных случаях, писать запрос вручную все-таки придется, благо таких случаев не так много).
ORM фреймворк может быть написан на каком-либо объектно-ориентированном языке ( PHP, Python, Ruby ) и представлять обертку над некой реляционной базой данных. Классы будут соответствовать таблицам в базе, а экземпляры этих классов – конкретным строкам таблицы.
Преимущества
Далее обсудим преимущества концепции ORM. Стоит также отметить, что не все библиотеки, реализующие данную концепцию, обладают всеми рассмотренными здесь преимуществами.
Независимость от вида базы данных
Это, пожалуй, главнейшая особенность и преимущество использования ORM в приложении. Так как нет необходимости писать специфический код под конкретный вид базы данных. Поэтому, вы можете начать проект с использования SQLite, затем можете поменять ее на MySQL или PostgreSQL. И все это делается редактированием пары строчек кода в настройках адаптера базы данных.
Моделирование предметной области
При использовании ORM для построения приложения, бизнес-логика приложения работает с объектами языка, а не с самой структурой базы данных. Это возможно благодаря соответствию между бизнес-моделью и самой базой данных.
Меньше кода и больше эффективности
ORM добавляет дополнительный слой абстракции, который позволяет разработчикам сконцентрироваться на их бизнес-логике, не отвлекаясь на создание сложных запросов к базе данных. Это приводит к сокращению количества необходимого для написания кода и увеличивает продуктивность разработчика.
Развитый интерфейс запросов к базе
В ORM предусмотрен богатый интерфейс, освобождающий разработчика от сложной семантики SQL.
Управление зависимостями
ORM предоставляет свободное управление зависимостями в базе данных. Связанные объекты загружаются автоматически, когда вызов методов преобразуется в соответствующий SQL запрос.
Параллелизм, кэширование и транзакции
ORM поддерживает возможность параллельной работы, позволяя нескольким пользователям одновременно изменять один и тот же объект.
Другая особенность – объекты могут быть сохранены в кэше, сокращая нагрузку на базу и вцелом увеличивая скорость работы приложения.
Изменения, вносимые в объект могут быть ограничены в рамках данной транзакции, которая может быть сохранена или возвращена обратно в первоначальное состояние. В каждый момент времени могут быть активными множество транзакций, но все эти транзакции изолированы друг от друга.
Накладные расходы
ORM фреймворк добавляет слой абстракции, ускоряющий процесс разработки и снижающий сложность создания конечного продукта. Однако, ничто не проходит даром – приложение начинает потреблять больше памяти и нагрузка на процессор также увеличивается.
Кривая изучения
Применение ORM в PHP приложении предполагает, что у разработчика есть опыт работы с каким либо PHP фреймворком. И поэтому здесь без дополнительных знаний будет обойтись нелегко. Хотя вы можете значительно сократить время изучения ORM в PHP, если воспользуетесь моим курсом Фреймворк Yii 2.0 с нуля. Пример создания сайта. Там, в уроке номер 3 “Создание моделей”, я как раз рассказываю о создании объектов базы данных с помощью шаблона проектирования ActiveRecord.
Производительность
Некоторые операции, такие как массовая вставка, обновление, удаление и т.д., медленнее, когда выполняются посредством ORM. Поэтому, в таких случаях лучше использовать чистый SQL.
Поверхностное знание SQL
Несмотря на то, что ORM облегчает жизнь, это часто приводит к тому, что разработчики не очень стремятся учить SQL или разбираются в нем слабо.
На сегодня все. Всего доброго!

Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
Она выглядит вот так:
Комментарии ( 0 ):
ORM (Object-Relational Mapping) – технология программирования, которая связывает базы данных с концепциями объектно-ориентированных языков программирования, создавая «виртуальную объектную базу данных». Существуют как проприетарные, так и свободные реализации этой технологии.
Библиотеки ORM существуют для самых разных языков программирования. В общих чертах, технология ORM позволяет проектировать работу с данными в терминах классов, а не таблиц данных. Она позволяет преобразовывать классы в данные, пригодные для хранения в базе данных, причем схему преобразования определяет сам разработчик. Кроме того, ORM предоставляет простой API- интерфейс для CRUD-операций над данными. Благодаря технологии ORM нет необходимости писать SQL-код для взаимодействия с локальной базой данных. [Источник 1]
Содержание
Достоинства
Среди достоинств ORM выделяют:
- наличие явного описания схемы БД, представленное в терминах какого-либо языка программирования, которое находится и редактируется в одном месте;
- возможность оперировать элементами языка программирования, т.е. классами, объектами, атрибутами, методами, а не элементами реляционной модели данных;
- возможность автоматического создания SQL-запросов, которая избавляет от необходимости использования языка для описания структуры БД (Data Definition Language) и языка манипулирования данными (Data Manipulation Language) при проектировании БД и изменении её схемы соответственно;
- не нужно создавать новые SQL-запросы при переносе на другую систему управления базами данных, поскольку за это отвечает низкоуровневый драйвер ORM.
- ORM избавляет от необходимости работы с SQL и проработки значительного количества программного кода, который зачастую однообразен и подвержен ошибкам.
- код, генерируемый ORM гипотетически проверен и оптимизирован, следовательно не нужно беспокоиться о его тестировании;
- развитые реализации ORM поддерживают отображение наследования и композиции на таблицы;
- ORM дает возможность изолировать код программы от подробностей хранения данных.
Недостатки
Среди недостатков ORM выделяются:
- Дополнительная нагрузка на программиста, которому, в случае использования ORM необходимо изучать этот некий «дополнительный слой» между программной и базой данных, который к тому же создает дополнительный уровень абстракции — объекты ORM. В связи с этим могут возникнуть вопросы соответствия особенностям ООП и соответствующим реляционным операциям. Эту проблему называют impedance mismatch, а сама реализация ORM ведет к увеличению объема программного кода и снижению скорости работы программы. Однако, с другой стороны, ORM наглядно и в одном месте концентрирует различие между реляционной и объектно-ориентированной парадигмами, что нельзя назвать недостатком;
- Появление трудно поддающихся отладке ошибок в программе, если присутствуют ошибки в реализации ORM, например, ошибки в реализации кэширования ORM, такие как согласование изменений в разных сессиях.
- Недостатки реализаций, которые могут иметь определенные ограничения и выдвигать определенные требования, например, требование собственной схемы базы данных и ограничение на средства создания базы данных. Также может отсутствовать возможность написать в явном виде SQL-запрос.
- Требуются отдельные таблицы в случае прямого отображения классов в таблицы и необходимости отображения атрибутов множественного характера.
Если говорить о главном минусе ORM, снижении производительности, то причина этого состоит в том, что большинство из ORM нацелены на обработку значительного большего количества различных сценариев использования данных, чем в случае отдельного приложения. В случае небольших проектов, которые не сталкиваются с высокой нагрузкой, применение ORM очевидно, особенно, если учесть такой важный критерий разработки, как время. «То, что с легкостью пишется с использованием ORM за неделю, можно реализовывать ни один месяц собственными усилиями». [Источник 2]
Альтернативы
Касательно альтернатив технологии ORM, то среди них выделяются:
- сознательное нарушение нормализации таблиц в реляционной модели, которое, хотя и приводит к избыточности данных наряду с появлением необходимости их синхронизации, обеспечивает преимущество ускорения доступа к данным;
- подход CoRM (Collection-Relational Mapping — реляционное отображение коллекций), при котором осуществляется объединение разрозненных коллекций объектов с помощью хорошо определенных реляционных взаимоотношений между коллекциями и прототипом которого могут служить документ-ориентированные СУБД (например, MongoDB);
В случае CoRM отсутствует ограничение на возможность хранить состояние разных объектов одного класса в разных коллекциях и ограничение на одновременное хранение в коллекции объектов, которые принадлежат разным классам.
От обычного ORM-подхода реляционное отображение коллекций отличает то, что коллекция напрямую не привязана к классу и, в теории, может включать в себя любой объект, в случае соблюдения некоторых минимальных требований к данному объекту, например, требование наличия способности к сериализации). Однако к этим требованиям не относятся ограничения на структуру объекта либо использование особых типов данных.
ORM — это инструмент решения проблемы семантического провала между реляционной и объектной моделями данных. Имеющий, однако, определенные проблемы, которых должны быть лишены его альтернативы, позволяющие вывести объектную сущность приложения из ограничений, накладываемых реляционным хранилищем. [Источник 3]
Пример с использованием FlexORM
Вам нужно хранить экземпляры классов во встроенной базе данных с возможностью читать их из нее.
Используйте библиотеку FlexORM. Это проект с открытым кодом, предоставляющий технологию ORM (Object Relational Mapping, реляционное отображение объектов) разработчикам AIR-приложений.
Определение отображения объектов
Библиотека FlexORM позволяет вам использовать метаданные в модельных классах для определения отображения ваших классов на таблицы базы данных. Одно из преимуществ такого подхода над другими решениями состоит в том, что вам не приходится расширять классы платформы. Ваша модель может оставаться неизменённой, если не считать метаданные, которые игнорируются компилятором, если вы их не используете.
В следующем примере имеется один класс, определяющий закладку браузера. Он имеет свойства id, name, url и notes:
Тег метаданных [Bindable] уже знаком вам, поскольку определен в ядре плат- формы Flex. Однако теги [Table] , [Column] и [Id] специфичны для библиотеки FlexORM. Тег метаданных [Table] указывает, что помеченный им класс управляется с помощью библиотеки FlexORM. Вы можете указать имя таблицы в качестве аргумента тега метаданных, но это, вообще говоря, необязательно. Тег [Id] определяет поле, используемое в качестве первичного ключа объекта. Библиотека FlexORM предоставляет средства генерирования первичного ключа, так что вам не нужно беспокоиться по поводу определения этого значения. Наконец, тег метаданных [Column] позволяет вам указать имя столбца для соответствующего ему свойства. В большинстве случаев необходимость в этом теге отсутствует. Если он опущен, в качестве имени столбца по умолчанию берется имя свойства.
Использование класса EntityManager
В библиотеке FlexORM определен класс EntityManager, который управляет всеми CRUD-операциями для всех классов, находящихся под управлением библиотеки. Этот класс существенно облегчает операции создания, чтения, обновления и удаления экземпляров классов, снабженных тегом [Table] .
Первое, что вы должны сделать, — это корректно настроить класс Entity- Manager. Прежде чем он сможет выполнять какие-либо операции, вы должны будете передать ему экземпляр класса SQLConnection:
В этом коде класс EntityManager конфигурируется на использование файла базы данных bookmarks.db, размещенного в том же каталоге, что и приложение. После установки свойства sqlConnection вы можете выполнять над данными операции CRUD. [Источник 4]
Класс EntityManager позволяет без труда читать элементы указанного типа. Достаточно передать класс, который вы хотите прочитать, методу findAll() класса EntityManager:
Сохранить экземпляр класса с помощью класса EntityManager столь же просто:
Процедура удаления экземпляра выполняется аналогичным образом, но требует от вас указания класса, а также свойства id удаляемого экземпляра:
Создание законченного приложения
Объединив приведенные ранее фрагменты кода, вы можете создать законченное приложение, выполняющее операции CRUD исключительно с использованием класса EntityManager. В следующем примере браузер сохраняет закладки (как бы- ло показано выше). В дополнение к приведенному здесь MXML-файлу вам потре- буется SWC-файл библиотеки FlexORM (поместите его в каталог построения) и класс Bookmark, определенный ранее в этом рецепте (разместите его в пакете vo): [Источник 5]
Кто-то предложил мне использовать ORM для проекта, который я разрабатываю, но у меня возникают проблемы с поиском информации о том, что это такое и как это работает.
Кто-нибудь может дать мне краткое объяснение, что такое ORM и как он работает, и как мне начать использовать его?
ОТВЕТЫ
Ответ 1
Вступление
Объектно-реляционное отображение (ORM) - это метод, который позволяет запрашивать и манипулировать данными из базы данных с использованием объектно-ориентированной парадигмы. Говоря об ORM, большинство людей ссылаются на библиотеку, которая реализует технику объектно-реляционного сопоставления, отсюда и фраза "ORM".
Библиотека ORM - это совершенно обычная библиотека, написанная на выбранном вами языке, которая инкапсулирует код, необходимый для манипулирования данными, поэтому вы больше не используете SQL; вы взаимодействуете непосредственно с объектом на том же языке, который используете.
Например, вот совершенно воображаемый случай с псевдоязыком:
У вас есть класс книг, вы хотите получить все книги, автором которых является "Линус". Вручную, вы бы сделали что-то вроде этого:
С библиотекой ORM это будет выглядеть так:
Механическая часть автоматически обрабатывается с помощью библиотеки ORM.
Плюсы и минусы
Использование ORM экономит много времени, потому что:
- СУХОЙ: вы пишете свою модель данных только в одном месте, и вам будет проще обновлять, поддерживать и повторно использовать код.
- Многое делается автоматически, от обработки базы данных до I18N.
- Это заставляет вас писать код MVC, что в итоге делает ваш код немного чище.
- Вам не нужно писать плохо сформированный SQL (большинство веб-программистов действительно отстой, потому что SQL трактуется как "вспомогательный" язык, хотя на самом деле он очень мощный и сложный).
- Санобработка; использование подготовленных операторов или транзакций так же просто, как вызов метода.
Использование библиотеки ORM более гибко, потому что:
- Это соответствует вашему естественному способу кодирования (это ваш язык!).
- Он абстрагирует систему БД, поэтому вы можете изменить ее, когда захотите.
- Модель слабо связана с остальной частью приложения, поэтому вы можете изменить ее или использовать где-либо еще.
- Это позволяет вам использовать ООП, как наследование данных без головной боли.
Но ORM может быть болью:
- Вы должны изучить это, и библиотеки ORM не являются легкими инструментами;
- Вы должны настроить это. Та же проблема.
- Производительность нормальная для обычных запросов, но мастер SQL всегда будет лучше с собственным SQL для больших проектов.
- Абстрагирует БД. Хотя это нормально, если вы знаете, что происходит за кулисами, это ловушка для новых программистов, которые могут писать очень жадные операторы, как тяжелый удар в цикле for .
Как узнать об ORM?
Ну, используйте один. Какую бы библиотеку ORM вы ни выбрали, все они используют одни и те же принципы. Здесь много библиотек ORM:
Если вы хотите попробовать библиотеку ORM в веб-программировании, вам лучше использовать весь стек фреймворков, например:
- Symfony (PHP, использующий Propel или Doctrine).
- Django (Python, использующий внутренний ORM).
Не пытайтесь написать свой собственный ORM, если вы не пытаетесь чему-то научиться. Это гигантский кусок работы, а старым потребовалось много времени и работы, прежде чем они стали надежными.
Ответ 2
Кто-нибудь может дать мне краткое объяснение.
ORM означает "объект для реляционного сопоставления", где
Объект - это тот, который вы используете с вашим языком программирования (в этом случае python)
Реляционная часть - это система реляционных баз данных (база данных), есть другие типы баз данных, но наиболее популярной является реляционная (вы знаете таблицы, столбцы, pk fk и т.д. например, Oracle MySQL, MS-SQL)
И наконец, Сопоставление - это место, где вы соединяете свои объекты с вашими таблицами.
В приложениях, где вы не используете структуру ORM, вы делаете это вручную. Использование структуры ORM позволит вам уменьшить шаблон, необходимый для создания решения.
Итак, скажем, у вас есть этот объект.
Использование структуры ORM позволит вам автоматически сопоставить этот объект с записью db и написать что-то вроде:
И добавьте сотрудника в БД.
К сожалению, это было не так, но я надеюсь, что это достаточно просто, чтобы поймать другие прочитанные статьи.
Ответ 3
ORM (Object Relational Mapper) - это часть/слой программного обеспечения, который помогает отображать объекты кода в вашу базу данных.
Некоторые обрабатывают больше аспектов, чем другие. но цель состоит в том, чтобы взять часть веса слоя данных со стороны разработчиков.
Ответ 4
Как и все аббревиатуры, это двусмысленно, но я предполагаю, что они означают объектно-реляционный картограф - способ закрыть глаза и убедить нет SQL под ним, а скорее все объекты;-). Не совсем верно, конечно, и не без проблем - всегда красочный Джефф Этвуд описал ORM как Вьетнам CS;-). Но, если вы мало знаете или не имеете SQL, и имеете довольно простую/мелкомасштабную проблему, они могут сэкономить ваше время! -)
Ответ 5
Первая глава книги Hibernate Java Persistence with Hibernate (3-е изд.) имеет отличный обзор общих концепций ORM и обсуждает мотивацию и дизайн ORM. Очень рекомендуется, даже если вы не работаете с Java.
Ответ 6
Это огромная тема. Возьмите хорошую книгу для спящего режима, и она должна подробно объяснить ORM, прежде чем перейти к ничтожному суровому спящему материалу.
Ответ 7
Storm - отличный вариант для тех, кто использует python.
Ответ 8
Объектная модель связана со следующими тремя концепциями Абстракция данных Инкапсуляция наследование Реляционная модель использовала базовую концепцию отношения или таблицы. Объектно-реляционное сопоставление (OR mapping) продукты объединяют возможности языка программирования объектов с реляционными базами данных.
Зачем это нужно
Для разработчиков программного обеспечения не является секретом, что в мире хранения данных доминируют реляционные СУБД, тогда как объектный подход к проектированию и программированию - в мире обработки данных. В рамках статьи мы не будем обсуждать, почему так произошло и хороша ли сложившаяся ситуация, мы примем ее за данность и постараемся найти средства разрешения. Для этого проблему нужно вначале сформулировать, ведь, как известно, правильно поставленная задача уже половина решения.
Объектная и реляционная модели ортогональны. Это значит, что они моделируют одну и ту же сущность, но с разных сторон, под разными, я бы сказал перпендикулярными углами зрения. Реляционная модель акцентирует свое внимание на структуре и связях сущностей, объектная - на их свойствах и поведении. Цель использования реляционной модели - информационное моделирование, выделение существенных для нас атрибутов, сохранение их значений и последующего поиска, обработки и анализа. Цель использования объектной - моделирование поведения, выделение существенных для нас функций и последующего их использования. Между моделями есть пересечение - структурные сущности, которые по-разному в этих моделях отражаются. Для того, чтобы отобразить артефакты реляционной модели в артефакты же объектной в наших программах и требуется средство объектно-реляционной проекции - ОРП или широко распространенное англоязычное обозначение - ORM (Object Relational Mapping).
Выражаясь более простым языком, объектно-реляционный проектор - ОРП - теоретически позволяет программисту работать с таблицами, полями и связями реляционной БД, как с объектами, свойствами и коллекциями (массивами), не отвлекаясь на подробности более низкого уровня, такими, например, как порядок выборки и сохранения модифицированных данных, вопросы переносимости и особенностей диалекта SQL конкретной СУБД, генерации уникальных первичных ключей, заполнения полей ссылок для моделирования связей.
Преимущества подобного подхода очевидны:
- рутинный код манипуляции данными в программах уменьшается в среднем на треть по сравнению с работой через классические табличные DataSet
- в архитектуре приложения можно четко разделить слой хранения данных, обеспечиваемый СУБД, и слой прикладных объектов (или "бизнес-объектов", business objects layer).
Разумеется, за все нужно платить. ОРП является дополнительным слоем абстракций и создает накладные расходы по использованию процессора и памяти, а работа с реляционной СУБД становится в некоторых случаях неоптимальной или даже неудобной по сравнению с SQL-командами. Не следует также забывать, что SQL - это промышленный стандарт, тогда как внутренние языки запросов, используемые в ОРП, таковым не являются. Поэтому кроме объектно-ориентированной работы с данными большинство ОРП поддерживают возможность прямого использования SQL и вызовов хранимых процедур, а некоторые могут даже отображать объекты на хранимые процедуры. Данные возможности следует отнести к разряду оптимизации, сейчас мы не будем их рассматривать подробно, но если ваша БД содержит миллионы записей при одновременном доступе множества пользователей, то с большой вероятностью вам они понадобятся.
Из уже названных различий между целями использования реляционной и объектной моделей следует в частности, что если в вашей системе основной упор делается на многокритериальный поиск и массированное извлечение информации (класс информационно-поисковых систем, OLAP, генерация отчетности), то использование объектов для доступа к данным не является оправданным, а попросту излишне. Никакого различия между табличным представлением информации в базе данных, внутри вашей программы и на экране пользователя или в отчете нет, промежуточная обработка сводится к соединениям все тех таблиц и простым пересчетам значений их полей. Другое дело, если ваша система осуществляет транзакционную обработку (OLTP), сложные расчеты, оповещения о событиях, диспетчеризацию, моделирует поведение - здесь преимущества использования ОРП наибольшие.
Портрет "идеального" ОРП с точки зрения разработчика
Давайте отвлечемся немного от рутины и попытаемся сформулировать основные требования к инструменту, который бы мог нам облегчить решение задач.
Я оставил за рамками требования к качеству генерируемого кода, ресурсоемкости, скоростным характеристикам, особенностям "ленивой" загрузки объектов и кэширования, поскольку удовлетворительные ответы на них можно получить только создав и опробовав прототип с использованием данного ОРП в применении к вашим конкретным условиям задачи. Обобщению результатов каждого такого теста можно посвятить целую отдельную статью.
А мы тем временем взглянем, что нам предлагает рынок.
Краткий обзор ОРП
Длинный список ОРП (на англ.языке) вы можете увидеть на странице sharptoolbox.com и на многих других, которые можно найти посредством поиска в Интернет (google, yandex) с ключевыми словами "ORM .NET". К сожалению практически вся найденная вами информация будет на английском языке, поэтому если не хотите лишний раз напрягаться, то расслабьтесь и продолжайте чтение статьи.
Продукт французской фирмы представляет собой полное решение, обеспечивающее как интеграцию с существующими БД, так и создание новых на основе объектной модели. Качественная презентация, обширная документация и описание методики использования. Интегрируется с Visual Studio: отдельная закладка в project explorer служит для управления моделью. Интегрируется с существующими CASE на уровне XMI. Схема проекции описывается в виде XML, то есть при необходимости интеграции с существующей БД вы имеете возможность изменять параметры вручную. Требуется наследование от базовых классов фреймворка. Основным недостатком является схема лицензирования, при которой нужно платить за каждую установку приложения у клиента. Таким образом, данный продукт может представлять интерес скорее для внутрикорпоративных приложений, чем для тиражируемых.
Приятно увидеть в этом ряду продукцию отечественного производителя. ОРП поддерживает прямую и обратную разработку и весьма интересные дополнительные возможности, такие как полнотекстовый поиск (на основе MS Search для MS SQL Server или DotLucene - независимой от конкретной СУБД системы), систему безопасности схожую по принципам с NTFS, возможность выгрузки в т.н. offline layer - временное хранилище для обеспечения работы приложения вне сети с последующей синхронизацией, версионность объектов, поддержка более одного языка для значений атрибутов. Документация достаточно полная, однако презентация из 140 слайдов, которая рассчитана по словам самих разработчиков на 2 часа просмотра вряд ли может быть названа удачной находкой. Продукт нельзя отнести только к классу ОРП: по причине широкого функционала он ближе к каркасу разработки корпоративных приложений. Соответственно, если ваша задача умещается в рамки ОРП, то фреймворк такого уровня может оказаться излишне "тяжелым". Также в руководстве ничего не удалось найти на тему интеграции с CASE и UML.
Продукт поддерживается небольшой командой разработчиков, начальная версия была создана в 2003 году в процессе работы над программой для энергетической компании, развернутой позже во множестве филиалах, в ссылках указывается цифра 50 тысяч одновременно используемых объектов в памяти (С.Т.: видимо, имеется в виду кэш). Основной процесс разработки состоит в создании описания модели в виде XML-файла, но основе которого может быть сгенерированы как слой прикладных объектов, так и схема базы данных. К такому процессу напрашивается использование CASE вместо ручного кодирования, но никаких упоминаний об интеграции не было найдено, а своих инструментов моделирования не поставляется. Соответственно, возможен и обратный инжиниринг на основе существующей базы данных. К числу интересных возможностей также следует отнести наличие работы в отсоединенном от сети режиме, то есть поддерживается временное хранилище объектов, как и в DataObjects.NET. Декларированная работа с любой СУБД, имеющей ADO.NET-провайдер, с одной стороны является плюсом ввиду универсальности подхода. С другой стороны, по сравнению с продуктами, которые поддерживают несколько СУБД на основе абстрактного слоя и специфичных стратегий или адаптеров, взаимодействие с СУБД будет неоптимальным (фактически, это работа с чистыми DataSet вместо диалекта SQL) и не учитывающим специфику конкретной СУБД. Вдобавок, имея достаточный опыт оптимизации, я всегда настороженно отношусь к заявлениям вроде "поддержки любой СУБД".
На самом деле, это не ОРП, а среда моделирования на основе UML, которая генерирует схему БД и схему отображения (mapping) для ОРП NHibernate, NPersist и Borland ECO II. Продукт пока "сырой", поддерживаются только MSSQL и Access, основной разработчик тоже один (Mats Helander). Пожалуй, это единственное на сегодня доступное средство моделирования для ОРП на .NET, поэтому выбор может стоять между "сырым", но бесплатным для внутренней разработки, ObjectMapper и совсем недешевыми CASE. В потенциале продукт может поддерживать все СУБД, которые поддерживают перечисленные выше ОРП, для которых он служит моделирующей надстройкой.
В качестве недостатков следует отметить незрелость продукта, которая проявляется в скудной документации (рекомендуется читать ее полную версию для Java-аналога), плохой поддержке, отсутствии четкой и стабильной методики разработки. Весь опыт и "база знаний" пока концентрируются в нескольких разбросанных по сети статьях разработчиков, использовавших NHibernate, и паре не вполне наглядных примеров. Создание тестового приложения напоминало постоянное "хождение по граблям", при этом найти решение очередной проблемы занимало большое количество времени (многие часы поисков в сети). Никаких средств моделирования не поставляется, но в дополнительном пакете (contribution) есть утилита командной строки, которая по XML-файлу описания отображения генерирует либо схему БД, либо слой прикладных объектов.
Нельзя обойти вниманием и очевидные достоинства продукта: полный спектр поддерживаемых СУБД, язык запросов. близкий к SQL по синтаксису, отсутствие необходимости наследования от общего предка, четкое разделение кода, схемы отображения и схемы БД. Например, если вы уже имеете иерархию классов, то для отображения ее на базу данных вам не придется что-то в них изменять: NHibernate аккуратно сопоставит схему отображения с вашими классами и сохранит их в БД. При этом код уровня IL также остается нетронутым. NHibernate также отлично справляется с задачей генерации уникальных идентификаторов объектов: алгоритм (их доступно несколько) задается на уровне описания, разработчику не нужно ничего дополнительно программировать. По моему мнению, NHibernate имеет хороший потенциал для развития и через год может стать одним из лидеров рынка.
Выводы
Приложение 1. Стратегии отображения, основные понятия и термины
Можно выделить три основные стратегии отображения объектов на реляционную схему БД. Подробнее см. статью А.Усова "ООП о реляционной модели"
- Хранение всех атрибутов в одной таблице
- Группировка общих атрибутов в одной таблице и разнесение уникальных атрибутов (подклассов) по связанным таблицам
- Представление каждого класса в виде отдельной таблицы
Стратегия 1 не относится собственно к реляционной модели и может рассматриваться разве что как средство оптимизации. Стратегии 2 и 3 используются CASE-средствами проектирования базы данных (ErWin, PowerDesigner) и обозначаются как "complete/incomplete subtyping" со схемой "roll-up" (стратегия 2, атрибуты подкласса в новой таблице) и "roll-down" (стратегия 3, наследуемые атрибуты добавляются к таблице суперкласса).
В ОРП, обеспечивающих выбор стратегии генерации схемы БД (например, JDO) обозначения несколько иные. Стратегия 1 называется "плоским отображением" (flat mapping), остальные стратегии реализуются либо при помощи "вертикального отображения" (стратегия 2, vertical mapping), либо "смешанного отображения" (стратегии 2 и 3, mixed mapping).
Читайте также: