
Создать копию схемы oracle
Обновлено: 06.07.2024
Администраторы баз данных Oracle Database постоянно обновляют разрабатываемые и тестируемые базы данных, и иногда им бывает нужно клонировать базы данных для того, чтобы протестировать стратегии резервного копирования и восстановления. Если база данных имеет небольшой размер, простой процедуры Data Pump Export/Import вполне хватит, но большинство баз данных ей не поддается. Клонировать базы данных Oracle можно тремя различными способами:
- с применением RMAN-команды DUPLICATE;
- с использованием интерфейса OEM Database Control;
- выполняя копирование базы данных вручную с помощью SQL*Plus.
На заметку! Создание обходной (failover) базы данных на случай кризиса не является главной целью клонирования баз данных — для этого применяются резервные (standby) базы данных.
Применение RMAN для клонирования базы данных
В RMAN предлагается команда DUPLICATE, которая позволяет создавать новую базу данных из резервных копий RMAN. Файлы резервных копий восстанавливаются в целевой базе данных, после чего выполняется процедура неполного восстановления, завершающаяся открытием новой базы данных с помощью команды OPEN RESETLOGS. Преимущество подхода с применением RMAN состоит в том, что все перечисленные выше шаги выполняются автоматически, без участия со стороны пользователя. Дублированная база данных может как представлять собой точную копию исходной базы данных, так и содержать только какое-то ее подмножество.
Ниже перечислены шаги, необходимые для выполнения такого вида клонирования базы данных.
1. Создайте новый файл init.ora для вспомогательной базы данных. Этот файл должен содержать следующие параметры, изменяющие имя файлов данных и файлов журналов, чтобы для новой базы данных не использовались файлы исходной базы данных:
- DB_FILE_NAME_CONVERT — преобразует имена файлов данных целевой базы данных в имена файлов данных дублированной базы данных;
- DB_FILE_NAME_CONVERT — преобразует имена файлов журналов повторного выполнения, принадлежащие исходной базе данных, в имена файлов журналов повторного выполнения, принадлежащие дублированной базе данных.
2. Запустите экземпляр исходной базы данных, причем обязательно в режиме NOMOUNT.
3. Подключите каталог восстановления к исходной и вспомогательной базе данных:
4. Выполните RMAN-команду DUPLICATE, как показано ниже:
Прежде чем выполнять команду DUPLICATE DATABASE, нужно обязательно делать хранящиеся на диске резервные копии доступными для дублированного экземпляра, либо перенеся их на целевой сервер вручную, либо применив для этого NFS или разделяемые диски.
Перечисленные выше шаги являются очень упрощенной иллюстрацией процесса дублирования базы данных с помощью RMAN; более подробное описание этого процесса можно найти в документации Oracle. При выполнении команды DUPLICATE TARGET DATABASE TO. , как показывалось выше, утилита RMAN будет останавливать вспомогательную базу данных и запускать ее заново, а затем выполнять следующие шаги.
- Восстанавливать все файлы с резервными копиями, принадлежащие целевой базе данных, во вспомогательной базе данных с использованием всех доступных архивных журналов повторного выполнения.
- Открывать дублированную базу данных с применением параметра RESETLOGS.
На заметку! Какое бы дублирование базы данных не выполнялось — основанное на использовании резервных копий или активное — утилите RMAN всегда требуется проводить неполное восстановление. Объясняется это тем, что утилита RMAN не делает резервную копию оперативных журналов повторного выполнения, принадлежащих исходной базе данных. Она создает дублированные файлы данных во вспомогательном экземпляре и восстанавливает их с помощью архивных журналов повторного выполнения.
В предыдущем примере было показано, как дублировать базу данных за счет использования файлов резервных копий исходной базы данных. Тем не менее, базу данных можно дублировать и без участия всяких резервных копий за счет применения нового приема, называемого активным дублированием базы данных (active database duplication). Этот прием позволяет копировать файлы активной базы данных по сети прямо во вспомогательный экземпляр. Именно поэтому его еще также называют сетевым дублированием (network-enabled duplication). Далее приводится краткое описание этого приема.
В случае создания дубликата базы данных на другом хосте при дублировании базы данных, для дубликата и исходной базы данных может использоваться одинаковая структура каталогов и идентичные имена файлов данных. То есть переименовывать файлы в дублированной базе данных в такой ситуации не потребуется. Однако вместо этого вместе с командой DUPLICATE DATABASE необходимо указать конструкцию NOFILENAMECHECK, во избежание выполнения ненужных проверок на предмет того, чтобы на одном и том же хосте не использовались одинаковые имена файлов.
В следующем примере предполагается, что дубликат базы данных необходимо создать на том же сервере, а раз так, значит, для целевой и дублированной базы должны применяться разные имена файлов.
Сначала нужно создать файл паролей Oracle, поскольку выполнение активного дублирования базы данных без него не возможно. Пароль SYSDBA в файле паролей дублированной базы данных должен выглядеть точно так, как и в исходной базе данных. При желании можно просто заставлять RMAN скопировать файл паролей исходной базы данных на целевой хост, указав в команде DUPLICATE DATABASE значение для параметра PASSWORD FILE. Команда, которую можно использовать для создания файла паролей, выглядит так:
Как уже было сказано выше, вместо того, чтобы применять такую команду, можно просто добавить к команде DUPLICATE DATABASE конструкцию PASSWORD FILE и заставить утилиту RMAN скопировать файл паролей исходной базы данных в целевую.
Хотя в этом примере дубликат и создается на том же самом сервере, из-за того, что применяется метод активного дублирования, необходимо обязательно позаботиться о том, чтобы обе базы данных использовали Oracle Net. Для этого достаточно добавить имя дублированной базы данных в файл listener.ora на хост-сервере, как показано ниже:
После внесения этого изменения потребуется перезапустить службу слушателя. Еще необходимо внести следующее изменение в файл tnsnames.ora:
Далее следует создать для вспомогательного экземпляра файл параметров инициализации. Из-за того, что в рассматриваемом примере для именования файла дублированной базы данных будет использоваться прием с параметром SPFILE, в этом файле параметров потребуется добавить только один параметр — DB_NAME:
Реальные имена файлов можно будет указать в значениях параметров DB_FILE_NAME_CONVERT и LOG_FILE_NAME_CONVERT прямо в самой команде DUPLICATE DATABASE.
Далее понадобится запустить вспомогательный экземпляр в режиме NOMOUNT:
Показанный здесь вспомогательный экземпляр использует простой файл параметров инициализации, в котором содержится только параметр DB_NAME. Однако позже в команде DUPLICATE DATABASE будет указана конструкция SPFILE, что приведет к копированию файла SPFILE исходной базы данных в стандартный каталог вспомогательного экземпляра.
Далее необходимо запустить утилиту RMAN и подключиться к исходной базе данных, вспомогательной базе данных и каталогу восстановления, как показано ниже:
Теперь осталось только выполнить команду DUPLICATE DATABASE, как показано ниже, чтобы создать дублированную базу данных за счет использования файлов активной базы данных по сети:
Указание в команде DUPLICATE DATABASE конструкции SPFILE вынуждает утилиту RMAN копировать файл SPFILE исходной базы данных на сервер, обслуживающий вспомогательную базу данных, а параметры, задаваемые в этой конструкции — вносить в него соответствующие изменения. После этого RMAN останавливает вспомогательный экземпляр и запускает его снова с использованием уже нового отредактированного файла SPFILE.
В частности, в настоящем примере утилита RMAN сначала обновляет файл SPFILE исходной базы данных с помощью значений, которые были указаны в конструкциях PARAMETER_NAME_CONVERT и SET, а затем останавливает вспомогательный экземпляр и перезапускает его снова с использованием уже нового SPFILE. После этого утилита RMAN начинает копировать файлы исходной базы данных по сети. По завершении процесса копирования утилита RMAN, прежде чем открывать дублированную базы данных, выполняет для нее процедуру RECOVER. В ходе процесса дублирования базы данных RMAN делает следующее.
- Копирует файлы данных, но не файлы, находящиеся в области быстрого восстановления.
- Копирует необходимые файлы архивных журналов повторного выполнения.
- Поскольку была указана конструкция SPFILE, копирует файл SPFILE исходной базы данных в целевую.
- Копирует файл паролей, если указывалась конструкция PASSWORDFILE.
- Воссоздает файлы оперативных журналов повторного выполнения.
- Воссоздает управляющие файлы для целевой базы данных.
- Воссоздает временные файлы в каталоге, который указан в параметре DB_CREATE_FILE_DEST.
Прием активного дублирования базы данных является самым простым способом для дублирования базы данных, поскольку не требует использования предыдущих резервных копий RMAN.
Применение Database Control для клонирования базы данных
В OEM Database Control предлагается специальный мастер — Clone Database Wizard (Мастер клонирования базы данных), который помогает проходить процесс клонирования базы данных шаг за шагом. Ниже перечислены основные функциональные возможности этого механизма клонирования.
- Клонировать допускается любую базу данных Oracle версии 8.1.7 или выше.
- Исходная база данных может находиться как в режиме ARCHIVELOG, так и в режиме NOARCHIVELOG.
- Выполнять клонирование базы данных можно и когда она находится в открытом состоянии. Для осуществления операции клонирования в Database Control на внутреннем уровне применяется утилита RMAN.
- Database Control будет делать резервную копию файлов данных и восстанавливать их из нее в новом месте, а затем проводить процедуру RECOVER с использованием архивных журналов повторного выполнения.
- Database Control будет создавать новый экземпляр, файл паролей, любые необходимые сетевые файлы, а также файлы init.ora и SPFILE.
- Database Control будет автоматически запускать новый экземпляр в открытом режиме.
Ниже описаны шаги, требуемые для выполнения клонирования базы данных с помощью Database Control.

Клонирование базы данных вручную
Для выполнения клонирования базы данных вручную сначала нужно воспользоваться утилитами операционной системы для копирования всех файлов исходной базы данных в целевое место. Если это место находится на том же сервере, тогда еще потребуется изменить имя базы данных, а если на другом, тогда можно оставить и то же самое имя. Сначала делается резервная копия управляющего файла исходной базы данных в файл трассировки (с помощью оператора ALTER DATABASE BACKUP CONTROLFILE TO TRACE), а затем с использованием содержимого этого файла трассировки создается новый управляющий файл, который поможет создать новый клон базы данных.
Ниже приведен краткий перечень шагов, требуемых для выполнения клонирования базы данных вручную. Процедура выглядит довольно просто, причем большую часть времени отнимает само копирование файлов базы данных из исходного в целевое место. Предполагается, что исходная база данных носит имя prod, а целевая — test.
1. Скопируйте файлы базы данных prod в целевое место.
2. Подготовьте текстовый файл для создания управляющего файла для новой базы данных:
3. В целевом месте создайте все необходимые каталоги для различных файлов.
4. Скопируйте из производственной (исходной) базы данных в целевую четыре следующих набора файлов: файлы параметров, управляющие файлы, файлы данных и файлы журналов повторного выполнения.
5. Во всех файлах клона базы данных измените имя базы данных на test.
6. Выполните оператор CREATE DATABASE, который был подготовлен с помощью оператора ALTER DATABASE BACKUP CONTROLFILE TO TRACE.
7. Создайте управляющий файл для базы данных test с помощью следующего оператора:
Это приведет к получению новой базы данных по имени test и нового управляющего файла, указывающего на скопированную (целевую) версию производственной базы данных.
8. Как только появится приглашение после выполнения предыдущей команды, запустите такую команду:
9. И, наконец, измените глобальное имя созданной только что базы данных с помощью следующей команды:
Привет, сейчас мы с Вами рассмотрим технологию Oracle Data Pump, с помощью которой мы можем экспортировать данные в дамп и импортировать данные из дампа в СУБД Oracle. Эта технология подразумевает использование утилит expdp и impdp, которые заменяют традиционные exp и imp, и сегодня мы с Вами научимся использовать их для создания дампа базы данных и импорта данных из этого дампа.
Как Вы, наверное, уже догадались, сейчас речь пойдет о СУБД Oracle, а именно о технологии Oracle Data Pump и начнем мы, конечно же, с обзора данной технологии.
Что такое Oracle Data Pump?

Oracle Data Pump – это технология позволяющая экспортировать и импортировать данные и метаданные в СУБД Oracle Database в специальный формат файлов дампа.
Данная технология впервые появилась в версии 10g и включается во все последующие версии Oracle Database. Для экспорта и импорта данных до Oracle Data Pump, т.е. до версии 10g, использовались традиционные утилиты exp и imp, возможности которых в 10 и выше версиях сохранены в целях совместимости. Особенностью Oracle Data Pump является то, что экспорт и импорт данных происходит на стороне сервера, dmp-файл формируется на файловой системе сервера, а также главным преимуществом Oracle Data Pump перед традиционным способом экспорта и импорта данных является более быстрая выгрузка и загрузка данных.
В Oracle Data Pump для экспорта и импорта данных созданы новые серверные утилиты expdp и impdp. Формат файлов дампа (dmp) используемый в этих утилитах, несовместим с форматом, который используется в exp и imp.
Expdp – утилита для экспорта данных в СУБД Oracle Database в дамп.
Impdp – утилита для импорта данных в СУБД Oracle Database из дампа.
Утилиты expdp и impdp поддерживают несколько режимов работы:
Для того чтобы посмотреть подробную справку (описание параметров) по этим утилитам запустите их с параметром help=y, например
Примечание! Запуск утилит в операционной системе Windows запускается из командной строки. В случае если системный каталог bin СУБД Oracle не добавлен в переменную среды Path, то запускать утилиты нужно из данного каталога, т.е. предварительно перейдя в него (например, с помощью команды cd). Для демонстрации примеров ниже я использую Oracle Database Express Edition 11g Release 2 установленный на операционной системе Windows 7.
Пример создания дампа базы данных Oracle с помощью expdp
Для того чтобы создавать дампы в Oracle с помощью утилиты expdp предварительно необходимо определится с логической директорией, в которую Вы будете экспортировать дампы, т.е. где они будут храниться. Можно использовать стандартную директорию DATA_PUMP_DIR, но Вы, если хотите, можете создать новую, конкретно для Ваших целей отдельную директорию. Давайте создадим отдельный каталог для наших задач с экспортом и импортом данных, заодно и научимся создавать такие директории.
Сначала создаем каталог в файловой системе, например, я создал D:\OracleEX\ExportImport.
Затем уже создаем директорию в Oracle, для этого открываем SQL*Plus или SQLDeveloper и запускаем следующую команду (я запустил в SQL*Plus и директорию назвал ExportImport).
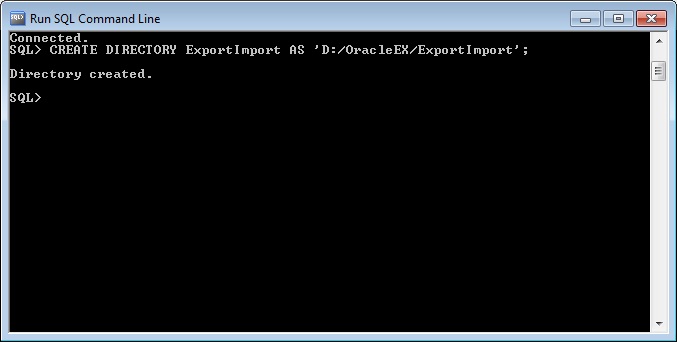
Чтобы посмотреть, какие директории уже созданы, можете использовать следующий запрос.
Теперь давайте перейдем непосредственно к экспорту. Я все действия выполнял от имени системного пользователя Oracle.
Создание дампа всей базы данных
Для того чтобы создать полный дамп базы данных выполните следующую команду в командной строке
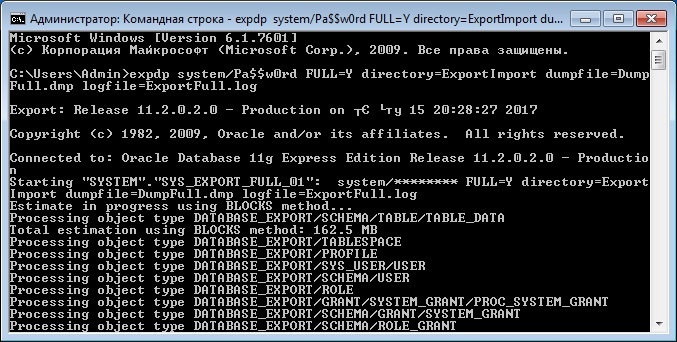
- system/Pa$$w0rd – это логин и пароль пользователя в СУБД;
- FULL=Y – параметр, который указывает, что мы делаем полный экспорт базы данных;
- directory=ExportImport – параметр указывает директорию, в которую мы будем выгружать дамп файл;
- dumpfile=DumpFull.dmp – параметр для указания названия дамп файла;
- logfile=ExportFull.log – параметр для указания названия лог файла экспорта данных.
Создание дампа на основе отдельной схемы базы данных
В большинстве случае все-таки, наверное, понадобится экспортировать отдельную, выбранную схему базы данных, а не всю БД. Для того чтобы выгрузить схему, указываем параметр SCHEMAS.
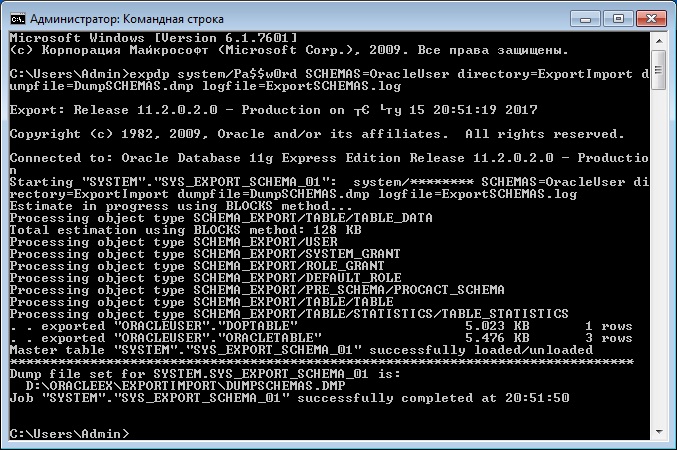
SCHEMAS=OracleUser – параметр, в котором мы указываем схему для экспорта, в нашем случае OracleUser.
Создание дампа на основе отдельных таблиц базы данных
Иногда нужно экспортировать только одну или несколько таблиц, для этого мы можем использовать параметр TABLES. В примере ниже мы экспортируем таблицу OracleTable в схеме OracleUser.
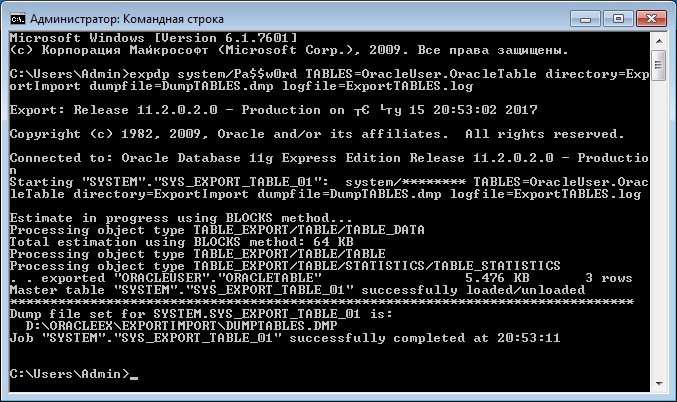
TABLES=OracleUser.OracleTable – это параметр, в котором мы указываем таблицу для экспорта (или несколько таблиц через запятую).
Пример импорта данных из дампа Oracle с помощью impdp
Сейчас давайте перейдем к импорту данных из дампа. Как Вы помните, для этих целей у нас существует утилита impdp.
Импорт схемы из дампа
Для импорта всей схемы запускаем утилиту impdp с параметром SCHEMAS. В случае если у Вас уже создана схема, которую Вы собираетесь импортировать, то ее предварительно нужно удалить. Для удаления схемы используйте следующий запрос в SQL*Plus или SQLDeveloper
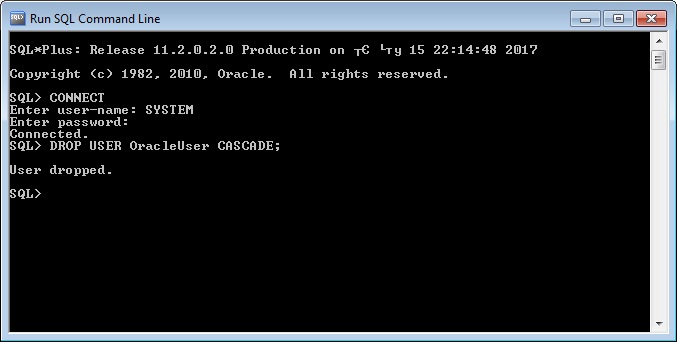
После этого, для того чтобы импортировать схему, запускаем утилиту impdp со следующими параметрами
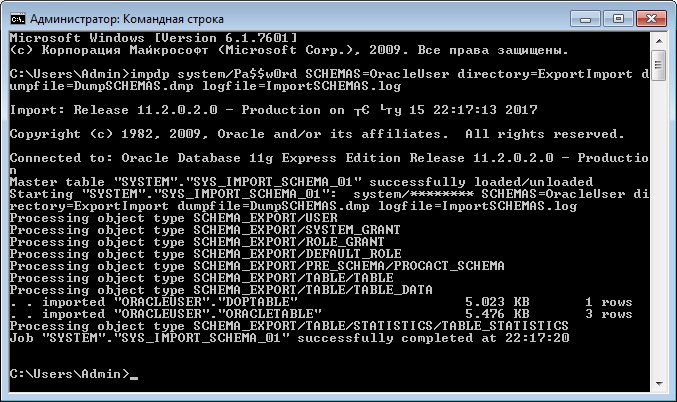
- system/Pa$$w0rd – это логин и пароль пользователя в СУБД;
- SCHEMAS=OracleUser – параметр, который указывает, что мы хотим импортировать конкретную схему (в нашем случае OracleUser);
- directory=ExportImport – параметр указывает директорию, в которой расположен файл дампа данных;
- dumpfile=DumpSCHEMAS.dmp – параметр для указания названия дамп файла;
- logfile=ImportSCHEMAS.log – параметр для указания названия лог файла импорта данных.
Импорт таблиц из дампа
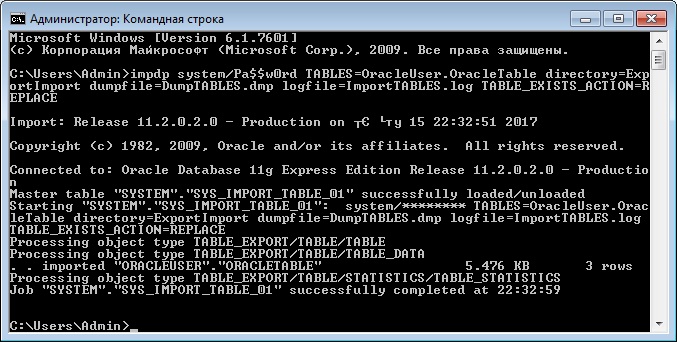
Если Вы хотите импортировать одну или несколько таблиц, то можете использовать параметр TABLES, также как и при экспорте. В случае если таблица или таблицы уже созданы, т.е. существуют, то их необходимо или удалить вручную (DROP TABLE) или указать параметр TABLE_EXISTS_ACTION, который может принимать следующие значения:
Для примера давайте запустим impdp с параметром TABLE_EXISTS_ACTION=REPLACE, для того чтобы перезаписать существующую таблицу.
Заметка! Для изучения языка SQL как стандарта, чтобы его можно было использовать в любой СУБД, рекомендую почитать книгу «SQL код», в ней рассматриваются конструкции SQL, которые будут работать везде и не привязаны к какой-то конкретной СУБД.
Читайте также: