
Способы обновления кэш памяти
Обновлено: 07.07.2024
Когда вы открываете любые сайты, открытки, картинки, видео, их копии остаются в памяти браузера. Это происходит, даже если вы не скачиваете контент, а просто просматриваете. Как раз эти копии и называются кэшем. Он нужен для того, чтобы сократить количество запросов к сайтам. Например, через некоторое время вы вновь решите посмотреть страницу, которую открывали раньше. Кэш моментально загрузит ее с жесткого диска.
Кэширование работает практически во всех программах и приложениях. Некоторые данные очищаются автоматически, а другие копятся на жестком диске. Это создает дополнительную нагрузку на память устройства. Замедляется работа смартфона, ноутбука, компьютера. Интернет «зависает». Некоторые уверены: дело — в провайдере. Но даже если вы подключите самую высокую скорость (например, 1 Гб/с от МТС ), сайты все равно не будут грузиться быстрее, пока вы не очистите кэш.
Как чистить кэш, сколько раз в месяц это нужно делать
Самый простой способ очистить кэш — перезагрузить устройство. Речь идет не только о компьютерах и смартфонах, но и о wi-fi роутерах, и его модель не имеет значения. Даже самые современные и мощные маршрутизаторы от Ростелеком или Билайн нуждаются в регулярной перезагрузке (примерно, раз в месяц).
Рассказываем, как чистить кэш на Android:
- Откройте настройки смартфона.
- Перейдите в раздел «Устройство».
- Выберите вкладку «память» или «хранилище» (в зависимости от модели смартфона).
- Кликните на «данные кэша» или «cache».
- Нажмите «Очистить» либо «clear cache».
- Подтвердите действие.
Как очистить кэш на iOS:
- Откройте настройки.
- Найдите вкладку браузера Safari.
- Нажмите на вкладку и выберите «Очистить историю и данные».
- Подтвердите действие.
Имейте в виду: вместе с кэшем в айфоне удалится вся история посещений.
Как очистить кэш на компьютере или ноутбуке
Кэш на компьютере обычно чистят через данные локального диска:
- Откройте системный диск (как правило это локальный диск C).
- Кликните по нему правой кнопкой мышки и выберите вкладку «Свойства».
- В разделе «Общие» есть пункт «Очистка диска». Нажмите на эту кнопку.
- Выберите «Очистить системные файлы». Поставьте галочки напротив основных разделов, где хранится кэш:
— временные файлы интернета;
— файлы для отчетов об ошибках;
- Нажмите «Ок» и дождитесь, пока система удалит ненужные данные.
Процесс может занять некоторое время.
Есть еще один вариант: очистить кэш не в самом устройстве, а в браузере. Зайдите в тот, которым обычно пользуетесь (Mozilla Firefox, Google Chrome, Opera). Нажмите в правом верхнем углу на три точки или три горизонтальные полоски (в разных браузерах разные значки). Откроются настройки. Найдите вкладку «История» и нажмите «Очистить». Хотите, чтобы некоторые сайты сохранились в памяти? Добавьте их в закладки (для этого зайдите на страницу и нажмите комбинацию клавиш Ctrl+D).
Если статья оказалась полезной, не забывайте ставить лайк. Подписывайтесь на наш канал и узнавайте еще больше полезного о домашнем и мобильном интернете.
Меня зовут Виктор Пряжников, я работаю в SRV-команде Badoo. Наша команда занимается разработкой и поддержкой внутреннего API для наших клиентов со стороны сервера, и кэширование данных — это то, с чем мы сталкиваемся каждый день.
Существует мнение, что в программировании есть только две по-настоящему сложные задачи: придумывание названий и инвалидация кэша. Я не буду спорить с тем, что инвалидация — это сложно, но мне кажется, что кэширование — довольно хитрая вещь даже без учёта инвалидации. Есть много вещей, о которых следует подумать, прежде чем начинать использовать кэш. В этой статье я попробую сформулировать некоторые проблемы, с которыми можно столкнуться при работе с кэшем в большой системе.

Я расскажу о проблемах разделения кэшируемых данных между серверами, параллельных обновлениях данных, «холодном старте» и работе системы со сбоями. Также я опишу возможные способы решения этих проблем и приведу ссылки на материалы, где эти темы освещены более подробно. Я не буду рассказывать, что такое кэш в принципе и касаться деталей реализации конкретных систем.
При работе я исхожу из того, что рассматриваемая система состоит из приложения, базы данных и кэша для данных. Вместо базы данных может использоваться любой другой источник (например, какой-то микросервис или внешний API).
Деление данных между кэширующими серверами
Если вы хотите использовать кэширование в достаточно большой системе, нужно позаботиться о том, чтобы можно было поделить кэшируемые данные между доступными серверами. Это необходимо по нескольким причинам:
- данных может быть очень много, и они физически не поместятся в память одного сервера;
- данные могут запрашиваться очень часто, и один сервер не в состоянии обработать все эти запросы;
- вы хотите сделать кэширование более надёжным. Если у вас только один кэширующий сервер, то при его падении вся система останется без кэша, что может резко увеличить нагрузку на базу данных.
Есть разные алгоритмы для реализации этого. Самый простой — вычисление номера сервера как остатка от целочисленного деления численного представления ключа (например, CRC32) на количество кэширующих серверов:
Такой алгоритм называется хешированием по модулю (англ. modulo hashing). CRC32 здесь использован в качестве примера. Вместо него можно взять любую другую хеширующую функцию, из результатов которой можно получить число, большее или равное количеству серверов, с более-менее равномерно распределённым результатом.
Этот способ легко понять и реализовать, он достаточно равномерно распределяет данные между серверами, но у него есть серьёзный недостаток: при изменении количества серверов (из-за технических проблем или при добавлении новых) значительная часть кэша теряется, поскольку для ключей меняется остаток от деления.
Я написал небольшой скрипт, который продемонстрирует эту проблему.
В нём генерируется 1 млн уникальных ключей, распределённых по пяти серверам с помощью хеширования по модулю и CRC32. Я эмулирую выход из строя одного из серверов и перераспределение данных по четырём оставшимся.
В результате этого «сбоя» примерно 80% ключей изменят своё местоположение, то есть окажутся недоступными для последующего чтения:
Total keys count: 1000000
Shards count range: 4, 5
| ShardsBefore | ShardsAfter | LostKeysPercent | LostKeys |
|---|---|---|---|
| 5 | 4 | 80.03% | 800345 |
Самое неприятное тут то, что 80% — это далеко не предел. С увеличением количества серверов процент потери кэша будет расти и дальше. Единственное исключение — это кратные изменения (с двух до четырёх, с девяти до трёх и т. п.), при которых потери будут меньше обычного, но в любом случае не менее половины от имеющегося кэша:

Я выложил на GitHub скрипт, с помощью которого я собрал данные, а также ipynb-файл, рисующий данную таблицу, и файлы с данными.
Для решения этой проблемы есть другой алгоритм разбивки — согласованное хеширование (англ. consistent hashing). Основная идея этого механизма очень простая: здесь добавляется дополнительное отображение ключей на слоты, количество которых заметно превышает количество серверов (их могут быть тысячи и даже больше). Сами слоты, в свою очередь, каким-то образом распределяются по серверам.
При изменении количества серверов количество слотов не меняется, но меняется распределение слотов между этими серверами:
- если один из серверов выходит из строя, то все слоты, которые к нему относились, распределяются между оставшимися;
- если добавляется новый сервер, то ему передаётся часть слотов от уже имеющихся серверов.

На картинке начального разбиения все слоты одного сервера расположены подряд, но в реальности это не обязательное условие — они могут быть расположены как угодно.
Основное преимущество этого способа перед предыдущим заключается в том, что здесь каждому серверу соответствует не одно значение, а целый диапазон, и при изменении количества серверов между ними перераспределяется гораздо меньшая часть ключей ( k / N , где k — общее количество ключей, а N — количество серверов).
Если вернуться к сценарию, который я использовал для демонстрации недостатка хеширования по модулю, то при той же ситуации с падением одного из пяти серверов (с одинаковым весом) и перераспределением ключей с него между оставшимися мы потерям не 80% кэша, а только 20%. Если считать, что изначально все данные находятся в кэше и все они будут запрошены, то эта разница означает, что при согласованном хешировании мы получим в четыре раза меньше запросов к базе данных.
Код, реализующий этот алгоритм, будет сложнее, чем код предыдущего, поэтому я не буду его приводить в статье. При желании его легко можно найти — на GitHub есть rendezvous hashing), но они гораздо менее распространены.
Вне зависимости от выбранного алгоритма выбор сервера на основе хеша ключа может работать плохо. Обычно в кэше находится не набор однотипных данных, а большое количество разнородных: кэшированные значения занимают разное место в памяти, запрашиваются с разной частотой, имеют разное время генерации, разную частоту обновлений и разное время жизни. При использовании хеширования вы не можете управлять тем, куда именно попадёт ключ, и в результате может получиться «перекос» как в объёме хранимых данных, так и в количестве запросов к ним, из-за чего поведение разных кэширующих серверов будет сильно различаться.
Чтобы решить эту проблему, необходимо «размазать» ключи так, чтобы разнородные данные были распределены между серверами более-менее однородно. Для этого для выбора сервера нужно использовать не ключ, а какой-то другой параметр, к которому нужно будет применить один из описанных подходов. Нельзя сказать, что это будет за параметр, поскольку это зависит от вашей модели данных.
В нашем случае почти все кэшируемые данные относятся к одному пользователю, поэтому мы используем User ID в качестве параметра шардирования данных в кэше. Благодаря этому у нас получается распределить данные более-менее равномерно. Кроме того, мы получаем бонус — возможность использования multi_get для загрузки сразу нескольких разных ключей с информацией о юзере (что мы используем в предзагрузке часто используемых данных для текущего пользователя). Если бы положение каждого ключа определялось динамически, то невозможно было бы использовать multi_get при таком сценарии, так как не было бы гарантии, что все запрашиваемые ключи относятся к одному серверу.
Параллельные запросы на обновление данных
Посмотрите на такой простой кусочек кода:
Что произойдёт при отсутствии запрашиваемых данных в кэше? Судя по коду, должен запуститься механизм, который достанет эти данные. Если код выполняется только в один поток, то всё будет хорошо: данные будут загружены, помещены в кэш и при следующем запросе взяты уже оттуда. А вот при работе в несколько параллельных потоков всё будет иначе: загрузка данных будет происходить не один раз, а несколько.
Выглядеть это будет примерно так:

На момент начала обработки запроса в процессе №2 данных в кэше ещё нет, но они уже читаются из базы данных в процессе №1. В этом примере проблема не такая существенная, ведь запроса всего два, но их может быть гораздо больше.
Количество параллельных загрузок зависит от количества параллельных пользователей и времени, которое требуется на загрузку необходимых данных.
Предположим, у вас есть какой-то функционал, использующий кэш с нагрузкой 200 запросов в секунду. Если на на загрузку данных нужно 50 мс, то за это время вы получите 50 / (1000 / 200) = 10 запросов.
То есть при отсутствии кэша один процесс начнёт загружать данные, и за время загрузки придут ещё девять запросов, которые не увидят данные в кэше и тоже станут их загружать.
Эта проблема называется cache stampede (русского аналога этого термина я не нашёл, дословно это можно перевести как «паническое бегство кэша», и картинка в начале статьи показывает пример этого действия в дикой природе), hit miss storm («шторм непопаданий в кэш») или dog-pile effect («эффект собачьей стаи»). Есть несколько способов её решения:
Блокировка перед началом выполнения операции пересчёта/ загрузки данных
Суть этого метода состоит в том, что при отсутствии данных в кэше процесс, который хочет их загрузить, должен захватить лок, который не даст сделать то же самое другим параллельно выполняющимся процессам. В случае memcached простейший способ блокировки — добавление ключа в тот же кэширующий сервер, в котором должны храниться сами закэшированные данные.
При этом варианте данные обновляются только в одном процессе, но нужно решить, что делать с процессами, которые попали в ситуацию с отсутствующим кэшем, но не смогли получить блокировку. Они могут отдавать ошибку или какое-то значение по умолчанию, ждать какое-то время, после чего пытаться получить данные ещё раз.
Кроме того, нужно тщательно выбирать время самой блокировки — его гарантированно должно хватить на то, чтобы загрузить данные из источника и положить в кэш. Если не хватит, то повторную загрузку данных может начать другой параллельный процесс. С другой стороны, если этот временной промежуток будет слишком большим и процесс, получивший блокировку, умрёт, не записав данные в кэш и не освободив блокировку, то другие процессы также не смогут получить эти данные до окончания времени блокировки.
Вынос обновлений в фон
Основная идея этого способа — разделение по разным процессам чтения данных из кэша и записи в него. В онлайн-процессах происходит только чтение данных из кэша, но не их загрузка, которая идёт только в отдельном фоновом процессе. Данный вариант делает невозможными параллельные обновления данных.
Этот способ требует дополнительных «расходов» на создание и мониторинг отдельного скрипта, пишущего данные в кэш, и синхронизации времени жизни записанного кэша и времени следующего запуска обновляющего его скрипта.
Этот вариант мы в Badoo используем, например, для счётчика общего количества пользователей, про который ещё пойдёт речь дальше.
Вероятностные методы обновления
Суть этих методов заключается в том, что данные в кэше обновляются не только при отсутствии, но и с какой-то вероятностью при их наличии. Это позволит обновлять их до того, как закэшированные данные «протухнут» и потребуются сразу всем процессам.
Для корректной работы такого механизма нужно, чтобы в начале срока жизни закэшированных данных вероятность пересчёта была небольшой, но постепенно увеличивалась. Добиться этого можно с помощью алгоритма XFetch, который использует экспоненциальное распределение. Его реализация выглядит примерно так:
В данном примере $ttl — это время жизни значения в кэше, $delta — время, которое потребовалось для генерации кэшируемого значения, $expiry — время, до которого значение в кэше будет валидным, $beta — параметр настройки алгоритма, изменяя который, можно влиять на вероятность пересчёта (чем он больше, тем более вероятен пересчёт при каждом запросе). Подробное описание этого алгоритма можно прочитать в white paper «Optimal Probabilistic Cache Stampede Prevention», ссылку на который вы найдёте в конце этого раздела.
Нужно понимать, что при использовании подобных вероятностных механизмов вы не исключаете параллельные обновления, а только снижаете их вероятность. Чтобы исключить их, можно «скрестить» несколько способов сразу (например, добавив блокировку перед обновлением).
«Холодный» старт и «прогревание» кэша
Нужно отметить, что проблема массового обновления данных из-за их отсутствия в кэше может быть вызвана не только большим количеством обновлений одного и того же ключа, но и большим количеством одновременных обновлений разных ключей. Например, такое может произойти, когда вы выкатываете новый «популярный» функционал с применением кэширования и фиксированным сроком жизни кэша.
В этом случае сразу после выкатки данные начнут загружаться (первое проявление проблемы), после чего попадут в кэш — и какое-то время всё будет хорошо, а после истечения срока жизни кэша все данные снова начнут загружаться и создавать повышенную нагрузку на базу данных.
От такой проблемы нельзя полностью избавиться, но можно «размазать» загрузки данных по времени, исключив тем самым резкое количество параллельных запросов к базе. Добиться этого можно несколькими способами:
- плавным включением нового функционала. Для этого необходим механизм, который позволит это сделать. Простейший вариант реализации — выкатывать новый функционал включённым на небольшую часть пользователей и постепенно её увеличивать. При таком сценарии не должно быть сразу большого вала обновлений, так как сначала функционал будет доступен только части пользователей, а по мере её увеличения кэш уже будет «прогрет».
- разным временем жизни разных элементов набора данных. Данный механизм можно использовать, только если система в состоянии выдержать пик, который наступит при выкатке всего функционала. Его особенность заключается в том, что при записи данных в кэш у каждого элемента будет своё время жизни, и благодаря этому вал обновлений сгладится гораздо быстрее за счёт распределения последующих обновления во времени. Простейший способ реализовать такой механизм — умножить время жизни кэша на какой-то случайный множитель:
Если по какой-то причине не хочется использовать случайное число, можно заменить его псевдослучайным значением, полученным с помощью хеш-функции на базе каких-нибудь данных (например, User ID).
Пример
Я написал небольшой скрипт, который эмулирует ситуацию «непрогретого» кэша.
В нём я воспроизвожу ситуацию, при которой пользователь при запросе загружает данные о себе (если их нет в кэше). Конечно, пример синтетический, но даже на нём можно увидеть разницу в поведении системы.
Вот как выглядит график количества hit miss-ов в ситуации с фиксированным (fixed_cache_misses_count) и различным (random_cache_misses_count) сроками жизни кэша:

Видно, что в начале работы в обоих случаях пики нагрузки очень заметны, но при использовании псевдослучайного времени жизни они сглаживаются гораздо быстрее.
«Горячие» ключи
Данные в кэше разнородные, некоторые из них могут запрашиваться очень часто. В этом случае проблемы могут создавать даже не параллельные обновления, а само количество чтений. Примером подобного ключа у нас является счётчик общего количества пользователей:

Этот счётчик — один из самых популярных ключей, и при использовании обычного подхода все запросы к нему будут идти на один сервер (поскольку это всего один ключ, а не множество однотипных), поведение которого может измениться и замедлить работу с другими ключами, хранящимися там же.

Чтобы решить эту проблему, нужно писать данные не в один кэширующий сервер, а сразу в несколько. В этом случае мы кратно снизим количество чтений этого ключа, но усложним его обновления и код выбора сервера — ведь нам нужно будет использовать отдельный механизм.
Мы в Badoo решаем эту проблему тем, что пишем данные во все кэширующие серверы сразу. Благодаря этому при чтении мы можем использовать общий механизм выбора сервера — в коде можно использовать обычный механизм шардирования по User ID, и при чтении не нужно ничего знать про специфику этого «горячего» ключа. В нашем случае это работает, поскольку у нас сравнительно немного серверов (примерно десять на площадку).
Если бы кэширующих серверов было намного больше, то этот способ мог бы быть не самым удобным — просто нет смысла дублировать сотни раз одни и те же данные. В таком случае можно было бы дублировать ключ не на все серверы, а только на их часть, но такой вариант требует чуть больше усилий.
Если вы используете определение сервера по ключу кэша, то можно добавить к нему ограниченное количество псевдослучайных значений (сделав из total_users_count что-то вроде t otal_users_count_1 , total_users_count_2 и т. д.). Подобный подход используется, например, в Etsy.
Если вы используете явные указания параметра шардирования, то просто передавайте туда разные псевдослучайные значения.
Главная проблема с обоими способами — убедиться, что разные значения действительно попадают на разные кэширующие серверы.
Сбои в работе
Система не может быть надёжной на 100%, поэтому нужно предусмотреть, как она будет вести себя при сбоях. Сбои могут быть как в работе самого кэша, так и в работе базы данных.
При сбоях в работе базы данных и отсутствии кэша мы можем попасть в ситуацию cache stampede, про которую я тоже уже рассказывал раньше. Выйти из неё можно уже описанными способами, а можно записать в кэш заведомо некорректное значение с небольшим сроком жизни. В этом случае система сможет определить, что источник недоступен, и на какое-то время перестанет пытаться запрашивать данные.
Кэш приложений может быть спорной темой на Android. Многие люди постоянно чистят кэш приложений, веря в то, что это позволит смартфону работать быстрей. Другие говорят, что это, в первую очередь, сводит на нет всю цель кэширования и просто увеличивает время запуска приложений и выполняемых действий. Истина, как обычно, где-то посередине. Некоторые приложения могут не использовать кэширование эффективно, из-за чего используются излишне большие объемы памяти. Иногда кэш может вызывать проблемы после выхода обновления и надо его сбрасывать. А еще некоторые приложения могут начинать работать медленнее, когда их кэш становится очень большим. Сказать однозначно, надо ли его удалять, нельзя. Но сейчас рассмотрим эту тему подробнее, чтобы вы понимали, когда это делать и как?

Надо ли чистить кэш телефона?
Что такое кэш на Андройд
Кэширование в компьютерном мире это то, что позволяет приложениям, таким, как браузеры, игры и потоковые сервисы хранить временные файлы, которые считаются актуальными для уменьшения времени загрузки и увеличения скорости работы. YouTube, Карты, музыкальные сервисы и множество других приложений сохраняют информацию в виде данных кэша. Это могут быть миниатюры видео, история поиска или временно сохраненные фрагменты видео. Кэширование может сэкономить много времени, так как качество и скорость Интернета не везде одинаковы. Но по иронии судьбы, когда приложения выгружают много данных на ваш телефон, это в конечном итоге замедляет его работу, особенно, когда остается мало места на встроенной памяти.
Наш Иван Кузнецов не так давно писал о том, что никогда не чистит кэш и считает это не нужным. Многие из вас, возможно, с ним не согласны. Да я и сам переодически провожу эту процедуру. Тем не менее, для полноты картины можете ознакомиться с его мнением.
Очистка кэша и данных на Android
Хотя мы часто упоминаем очистку кэша и данных в одном ключе, на Android это два совершенно разных действия. Например, музыкальные сервисы часто сохраняют в кэш информацию, относящуюся к исполнителям, которых вы слушали, но которые не входят в вашу библиотеку. Когда кэш приложения очищается, все упомянутые данные стираются.

Очистка лишней не будет? Не факт.
Более существенные данные включают в себя пользовательские настройки, базы данных и данные для входа в систему. Когда вы очистите кэш, это все удалится и будет не очень приятно. Если говорить грубо, можно сказать, что очистка кэша придает приложению тот вид, который был сразу после его установки, но у вас останутся данные, которые вы сами осознанно сохранили (загруженные песни, видео в оффлайн, карты и так далее). Если вы удалите и эти данные, то приложение будет вообще нулевым. Если чистите и кэш, и данные, проще тогда и приложение переустановить, чтобы вообще все красиво было.
Как очистить память смартфона. Пять простых шагов.
Когда надо чистить кэш
В чем-то я согласен с Иваном и с его мнением, которое я приводил в начале статьи. Нет смысла чистить кэш часто. После того, как вы его очистили, приложение все равно его создаст заново. Только в это время оно будет работать еще медленнее.
Тут важно найти баланс и понять, действительно ли ваш смартфон тормозит из-за кэша или, например, он просто старый и уже не тянет. Если не вникать в это, то можно посоветовать чистить кэш один раз в 3-6 месяцев, но быть готовым, что первые несколько дней скорость работы будет чуть ниже. В итоге, вы как бы освежите приложение, удалив лишний мусор и заново собрав только то, что нужно.
Google Play рассылает пустые обновления приложений. Что делать?
Как очистить кэш и данные на Android
Точную инструкцию для каждого смартфона дать не получится, так как все зависит от производителя и версии ОС, но общие правила будут следующими.
Шаг 1: Запустите «Настройки» и перейдите в раздел «Хранилище» (или найдите его поиском). Так вы сможете узнать, сколько памяти вашего смартфона занято и чем.
Шаг 2. В разделе «Хранилище» найдите «Приложения» (или «Другие приложения») и выберите его. В нем будут перечислены все приложения, а также то, сколько места каждое из них занимает. В некоторых версиях ОС можно найти сортировку приложений по алфавиту или размеру.
Шаг 3: Зайдите внутрь приложения и удалите кэш или данные. Только надо понимать, что это действие необратимо.
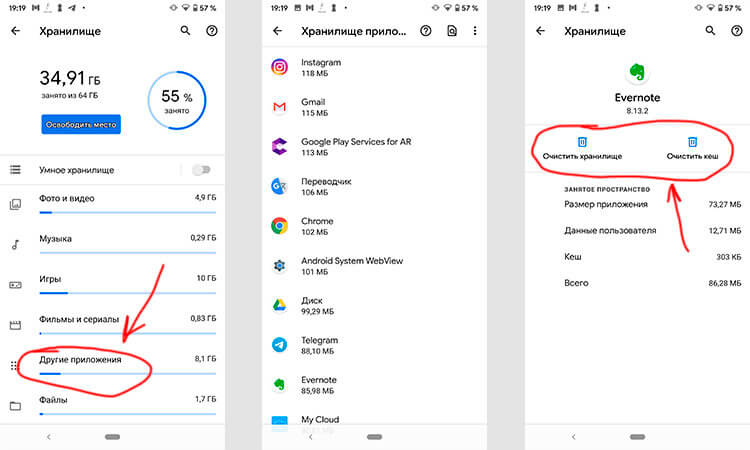
Три простых шага для очистки кэша.
В отношении специальных приложений для очистки я очень категоричен и не рекомендую ими пользоваться. Несмотря на их обещания ускорить систему чуть ли не в разы, в лучшем случае они просто сделают то же, что я только что описал. Так почему бы не сделать это самому без установки сомнительных приложений, которые еще и будут собирать ваши данные? Единственное приложение-оптимизатор, которому я доверяю, это Google Файлы, но работает оно именно с хранилищем и чистит в первую очередь мусор. Хотя, на него тоже нельзя слепо полагаться, но оно сделано Google, а к ней доверия куда больше, чем к каким-то левым разработчикам.
Если вы все еще хотите установить подобное приложение, просто помните о том, что они работают в фоновом режиме и используют системные ресурсы. Даже если они что-то ускорят, то сразу замедлят обратно.
Надо ли чистить кэш Android-приложений
Еще больше полезных советов и рассуждения в нашем Telegram-канале.
Еще раз: очистка кэша не испортит ваш смартфон, но приложение потеряет часть сохраненных данных и оптимизированных под вас настроек. Некоторое время придется накапливать их заново, зато так можно убрать действительно лишнее. Раньше можно было одной кнопкой очистить кэш всех приложений, теперь только по одному, но, наверное, это к лучшему.
Чего точно не стоит делать с кэшем, так это чистить его каждый день или каждую неделю. Так вы точно не сделаете лучше никому.
Если результат обновления блоков кэш-памяти не возвращать в основную память, то содержимое ОП становится неадекватным вычислительному процессу – нарушается когерентность(согласованность копий)памяти. Чтобы избежать этого, предусмотрены методы обновления ОП, которые можно разделить на две большие группы: методы сквозной записи и методы обратной записи.
При сквозной записи (write through, store through) информация записывается одновременно в кэш-строку и в блок основной памяти. При обратной записи (записи с обратным копированием, write back, copy back) информация записывается только в кэш-строку. Модифицированная кэш-строка записывается в основную память, только когда она замещается на другой блок ОП. Для сокращения частоты копирования блоков при замещении обычно с каждой кэш-строкой связывается так называемый бит модификации (dirty bit). Этот бит состояния показывает, была ли модифицирована кэш-строка. Если она не модифицировалась, то обратное копирование отменяется, поскольку более низкий уровень содержит ту же самую информацию, что и кэш-память.
Оба подхода к организации записи имеют свои преимущества и недостатки. При записи с обратным копированием операции записи выполняются со скоростью кэш-памяти, и несколько записей в один и тот же блок требуют только одной записи в основную память. Поскольку в этом случае обращения к основной памяти происходят реже, вообще говоря, требуется меньшая полоса пропускания памяти, что очень привлекательно для многопроцессорных систем. Сквозная запись проще для реализации, чем запись с обратным копированием. Сквозная запись имеет также преимущество в том, что основная память имеет наиболее свежую копию данных, что может быть важно в некоторых случаях при совместной работе нескольких процессоров. Подробнее этот вопрос освещается в разделе «Параллельные вычислительные системы».
Когда процессор ожидает завершения записи при выполнении сквозной записи, то говорят, что он приостанавливается для записи (write stall).Общий прием минимизации остановов по записи связан с использованием буфера записи (write buffer), который позволяет процессору продолжить выполнение команд во время обновления содержимого памяти. Следует отметить, что остановы по записи могут возникать и при наличии буфера записи.
При промахе во время записи имеются две дополнительные возможности:
· Разместить записываемый блок в кэш-памяти (write allocate) (называется также выборкой при записи, fetch on write). Блок загружается в кэш-память, вслед за чем выполняются действия, аналогичные выполняющимся при выполнении записи с попаданием.
· Не размещать записываемый блок в кэш-памяти (называется также записью в окружение, write around). Блок модифицируется в ОП и не загружается в кэш-память.
Обычно в кэш-памяти со сквозной записью используется запись в окружение (поскольку последующая запись в этот блок все равно пойдет в память), а в кэш-памяти с обратной записью используется выборка при записи (в надежде, что последующая запись в этот блок будет перехвачена). Если используется выборка при записи, следует учитывать тот факт, что для размещения в кэш-памяти записываемого блока может не быть свободного места, и, скорее всего, придется применять ту или иную стратегию замещения.
При возникновении промаха чтения, контроллер кэш-памяти должен выбрать подлежащий замещению блок. Наиболее простая стратегия замещения используется при прямом распределении. На попадание проверяется только одна кэш-строка, и только эта кэш-строка может быть замещена. При полностью ассоциативной или множественно-ассоциативной организации кэш-памяти необходимо выбрать, какая именно кэш-строка подлежит замещению.
Для замещения кэш-строк применяются три основных стратегии: случайная, FIFO и LRU. В первом случае замещаемая кэш-строка выбирается случайно или псевдослучайно. По методу FIFO («первым пришел – первым вышел», First Input First Output) среди всех кэш-строк, являющихся объектами замещения, выбирается та, которая была переслана в кэш-память самой первой. При стратегии LRU (Last Recently Used, «последняя использованная») замещению подлежит та кэш-строка, к которой дольше всего не было обращения. Наиболее простой в реализации является стратегия со случайным замещением, наиболее сложной – стратегия FIFO. Наибольшую же эффективность на практике демонстрирует метод LRU.
При реализации этого метода манипуляции с замещаемыми кэш-строками производятся с помощью LRU-стека. При загрузке кэш-строка помещается в этот стек, для замены используется кэш-строка, хранящаяся в наиболее глубокой позиции стека. Именно эта кэш-строка удаляется из стека.
При обращении к определенной кэш-строки она удаляется из стека и заново помещается в него. Таким образом, чем дольше не было доступа к кэш-строке, тем в более глубокой позиции стека она располагается. Реализация LRU-стека, позволяющего с высокой скоростью выполнять манипуляции с кэш-строками, усложняется по мере увеличения числа блоков кэш-памяти и становится дорогой. При множественно-ассоциативном распределении стековым механизмом должна быть оснащена каждая группа кэш-строк, что также ведет к увеличению стоимости аппаратуры.
Читайте также:
- Не удается продолжить выполнение кода поскольку система не обнаружила virtualizersdk64 dll
- Выполнить масштабирование на гп или дисплее что лучше
- Плагины в фаерфокс где находится
- Как найти человека в ок по номеру телефона через компьютер
- Ведомость объемов работ как правильно составить образец в экселе