
Сжимаются ли файлы prg
Обновлено: 07.07.2024
This file is saved in a binary format, which requires a specific program to read its contents.
Что такое PRG файл?
Программный файл, используемый различными приложениями; может быть исполняемой функцией или скриптом, который может быть запущен в другой программе; также может быть текстовым файлом, который содержит исходный код, который может быть скомпилирован в исполняемую программу.
Тип файла2 PC-DMIS Part Program File
| Разработчик | Hexagon Metrology |
| Категория | Файлы САПР |
| Формат | Binary |
Binary
This file is saved in a binary format, which requires a specific program to read its contents.
.PRG вариант № 2
САПР-файл, созданный PC-DMIS, программное обеспечение для метрологии, используемое для программирования координатно-измерительных машин (CMM); сохраняет «программу обработки детали», которая содержит инструкции по перемещению машины вокруг физической части, чтобы выполнить ее измерения.
Программные части PC-DIMS позволяют разработчикам сохранять программу в автономном режиме и запускать их в 3D-программной среде, прежде чем запускать их с помощью реальной системы координат.
Тип файла3 xBase Program File
| Разработчик | dBASE Intelligence |
| Категория | Файлы разработчиков |
| Формат | Text |
This file is saved in a binary format, which requires a specific program to read its contents.
.PRG вариант № 3
Программный файл, используемый старыми версиями DOS вариантов dBASE и xBase; сохранен как скрипт, который может быть запущен с помощью интерпретатора dBASE или xBase; может быть запущена без компиляции, что обеспечивает разработчикам более быстрый поворот при тестировании.
Тип файла4 Akai MPC2000 Program File
| Разработчик | Akai Professional |
| Категория | Аудио файлы |
| Формат | Binary |
Binary
This file is saved in a binary format, which requires a specific program to read its contents.
.PRG вариант № 4
Программный файл, используемый сэмплерами серии Akai MPC, такими как MPC2000; содержит один или несколько образцов звука, включая имя образца и информацию MIDI, используемую для сопоставления образцов с конкретными ключами.
Тип файла5 GEM Application
| Разработчик | Digital Research |
| Категория | Исполняемые файлы |
| Формат | Binary |
Binary
This file is saved in a binary format, which requires a specific program to read its contents.
.PRG вариант № 5
Файл приложения, используемый GEM Desktop (Graphic Environment Manager), старая операционная система, выпущенная в 1988 году; также используется системами Atari ST, которые использовали GEM Desktop; хранит программу, похожую на то, как файл .EXE хранит программу в Windows.
Тип файла6 RAPID Program File
This file is saved in a binary format, which requires a specific program to read its contents.
.PRG вариант № 6
Программа, написанная на языке программирования RAPID для робототехники; содержит инструкции для автоматизированных роботов; может быть создано в ABB RobotStudio, симуляторе и автономном приложении для программирования роботов; также можно назвать программой S4.
Тип файла7 WAVmaker Patch File
| Разработчик | Polyhedric Software |
| Категория | Аудио файлы |
| Формат | Binary |
Binary
This file is saved in a binary format, which requires a specific program to read its contents.
.PRG вариант № 7
Файл, используемый WAVmaker, программой, используемой для передачи MIDI-данных в аудиофайлы .WAV ; также используемый Mellosoftron, виртуальной программой сэмплера; сохраняет «патч», в котором хранятся точно настроенные параметры воспроизведения инструмента для создания выходного аудиосигнала.
Тип файла8 RPG Toolkit Program File
This file is saved in a binary format, which requires a specific program to read its contents.
.PRG вариант № 8
Файл исходного кода, созданный с использованием RPG Toolkit, среды разработки для создания ролевых игр Windows; содержит код, написанный с использованием синтаксиса RPG Toolkit; используется для сценариев событий, когда действия проводятся в игре.
Тип файла9 Visual FoxPro Program File
This file is saved in a binary format, which requires a specific program to read its contents.
.PRG вариант № 9
Текстовый программный файл, используемый Visual FoxPro, инструментом разработки, используемым для создания приложений баз данных Windows; содержит одну или несколько команд, которые часто инструктируют FoxPro загружать форму или окно, разработанные в программном обеспечении; часто содержит команду «DO».
Файлы PRG позволяют запускать программы в среде Visual FoxPro. Однако они не являются исполняемыми файлами Windows. Поэтому сначала вы должны скомпилировать программу в исполняемый файл Windows, чтобы запустить ее за пределами Visual FoxPro.
ПРИМЕЧАНИЕ. FoxPro, предшественник Visual FoxPro, является вариантом xBase, поэтому файлы FoxPro FoxG могут быть аналогичные тем, которые содержатся в других средах программирования xBase, таких как Clipper, dBFast и более старые версии dBASE.
CAD-файл, созданный PC-DMIS, метрологическим программным обеспечением, используемым для программирования координатно-измерительных машин (CMM); сохраняет «программу обработки детали», которая содержит инструкции по перемещению станка вокруг физической детали для проведения измерений.
Программы обработки детали PC-DIMS позволяют разработчикам сохранять программы в автономном режиме и запускать их в трехмерная программная среда, прежде чем запускать их на реальной координатно-измерительной машине.
Тип файла 2 Программный файл.
Программный файл, используемый различными приложениями; может быть исполняемой функцией или скриптом, который может быть запущен в другой программе; также может быть текстовым файлом, содержащим исходный код, который может быть скомпилирован в исполняемую программу.
Тип файла 2 Программный файл.
Программный файл, используемый различными приложениями; может быть исполняемой функцией или скриптом, который может быть запущен в другой программе; также может быть текстовым файлом, содержащим исходный код, который может быть скомпилирован в исполняемую программу.Тип файла 3 xBase Программный файл.
Тип файла 2 Программный файл.
Программный файл, используемый различными приложениями; может быть исполняемой функцией или скриптом, который может быть запущен в другой программе; также может быть текстовым файлом, содержащим исходный код, который может быть скомпилирован в исполняемую программу.Тип файла 3 xBase Программный файл.
Тип файла 2 Программный файл.
Программный файл, используемый различными приложениями; может быть исполняемой функцией или скриптом, который может быть запущен в другой программе; также может быть текстовым файлом, содержащим исходный код, который может быть скомпилирован в исполняемую программу.Тип файла 3 xBase Программный файл.
Тип файла 2 Программный файл.
Программный файл, используемый различными приложениями; может быть исполняемой функцией или скриптом, который может быть запущен в другой программе; также может быть текстовым файлом, содержащим исходный код, который может быть скомпилирован в исполняемую программу.Тип файла 3 xBase Программный файл.
Тип файла 2 Программный файл.
Программный файл, используемый различными приложениями; может быть исполняемой функцией или скриптом, который может быть запущен в другой программе; также может быть текстовым файлом, содержащим исходный код, который может быть скомпилирован в исполняемую программу.Тип файла 3 xBase Программный файл.
Тип файла 2 Программный файл.
Программный файл, используемый различными приложениями; может быть исполняемой функцией или скриптом, который может быть запущен в другой программе; также может быть текстовым файлом, содержащим исходный код, который может быть скомпилирован в исполняемую программу.Тип файла 3 xBase Программный файл.
Тип файла 2 Программный файл.
Программный файл, используемый различными приложениями; может быть исполняемой функцией или скриптом, который может быть запущен в другой программе; также может быть текстовым файлом, содержащим исходный код, который может быть скомпилирован в исполняемую программу.Тип файла 3 xBase Программный файл.
Тип файла 2 Программный файл.
Программный файл, используемый различными приложениями; может быть исполняемой функцией или скриптом, который может быть запущен в другой программе; также может быть текстовым файлом, содержащим исходный код, который может быть скомпилирован в исполняемую программу.Тип файла 3 xBase Программный файл.
Доброго времени суток.
Сегодня я хочу коснуться темы сжатия данных без потерь. Несмотря на то, что на хабре уже были статьи, посвященные некоторым алгоритмам, мне захотелось рассказать об этом чуть более подробно.
Я постараюсь давать как математическое описание, так и описание в обычном виде, для того, чтобы каждый мог найти для себя что-то интересное.
В этой статье я коснусь фундаментальных моментов сжатия и основных типов алгоритмов.
Сжатие. Нужно ли оно в наше время?
Разумеется, да. Конечно, все мы понимаем, что сейчас нам доступны и носители информации большого объема, и высокоскоростные каналы передачи данных. Однако, одновременно с этим растут и объемы передаваемой информации. Если несколько лет назад мы смотрели 700-мегабайтные фильмы, умещающиеся на одну болванку, то сегодня фильмы в HD-качестве могут занимать десятки гигабайт.
Конечно, пользы от сжатия всего и вся не так много. Но все же существуют ситуации, в которых сжатие крайне полезно, если не необходимо.
- Пересылка документов по электронной почте (особенно больших объемов документов с использованием мобильных устройств)
- При публикации документов на сайтах, потребность в экономии трафика
- Экономия дискового пространства в тех случаях, когда замена или добавление средств хранения затруднительно. Например, подобное бывает в тех случаях, когда выбить бюджет под капитальные расходы непросто, а дискового пространства не хватает
Конечно, можно придумать еще множество различных ситуаций, в которых сжатие окажется полезным, но нам достаточно и этих нескольких примеров.
Все методы сжатия можно разделить на две большие группы: сжатие с потерями и сжатие без потерь. Сжатие без потерь применяется в тех случаях, когда информацию нужно восстановить с точностью до бита. Такой подход является единственно возможным при сжатии, например, текстовых данных.
В некоторых случаях, однако, не требуется точного восстановления информации и допускается использовать алгоритмы, реализующие сжатие с потерями, которое, в отличие от сжатия без потерь, обычно проще реализуется и обеспечивает более высокую степень архивации.
| Сжатие с потерями |
| Лучшие степени сжатия, при сохранении «достаточно хорошего» качества данных. Применяются в основном для сжатия аналоговых данных — звука, изображений. В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человеческого уха или глаза в большинстве практических применений. |
| Сжатие без потерь |
| Данные восстанавливаются с точностью до бита, что не приводит к каким-либо потерям информации. Однако, сжатие без потерь показывает обычно худшие степени сжатия. |
Итак, перейдем к рассмотрению алгоритмов сжатия без потерь.
Универсальные методы сжатия без потерь
В общем случае можно выделить три базовых варианта, на которых строятся алгоритмы сжатия.
Первая группа методов – преобразование потока. Это предполагает описание новых поступающих несжатых данных через уже обработанные. При этом не вычисляется никаких вероятностей, кодирование символов осуществляется только на основе тех данных, которые уже были обработаны, как например в LZ – методах (названных по имени Абрахама Лемпеля и Якоба Зива). В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
Вторая группа методов – это статистические методы сжатия. В свою очередь, эти методы делятся на адаптивные (или поточные), и блочные.
В первом (адаптивном) варианте, вычисление вероятностей для новых данных происходит по данным, уже обработанным при кодировании. К этим методам относятся адаптивные варианты алгоритмов Хаффмана и Шеннона-Фано.
Во втором (блочном) случае, статистика каждого блока данных высчитывается отдельно, и добавляется к самому сжатому блоку. Сюда можно отнести статические варианты методов Хаффмана, Шеннона-Фано, и арифметического кодирования.
Общие принципы, на которых основано сжатие данных
Все методы сжатия данных основаны на простом логическом принципе. Если представить, что наиболее часто встречающиеся элементы закодированы более короткими кодами, а реже встречающиеся – более длинными, то для хранения всех данных потребуется меньше места, чем если бы все элементы представлялись кодами одинаковой длины.
Точная взаимосвязь между частотами появления элементов, и оптимальными длинами кодов описана в так называемой теореме Шеннона о источнике шифрования(Shannon's source coding theorem), которая определяет предел максимального сжатия без потерь и энтропию Шеннона.
Немного математики

Если вероятность появления элемента si равна p(si), то наиболее выгодно будет представить этот элемент — log2p(si) битами. Если при кодировании удается добиться того, что длина всех элементов будет приведена к log2p(si) битам, то и длина всей кодируемой последовательности будет минимальной для всех возможных методов кодирования. При этом, если распределение вероятностей всех элементов F =
Это значение называют энтропией распределения вероятностей F, или энтропией источника в заданный момент времени.
Однако обычно вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от каких-то факторов. В этом случае, для каждого нового кодируемого элемента si распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F= Fk и H= Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей pk(si) для всех элементов si.

Поэтому, учитывая эту поправку, можно выразить среднюю длину кодов как
Где Pk — вероятность нахождения источника в состоянии k.
Итак, на данном этапе мы знаем, что сжатие основано на замене часто встречающихся элементов короткими кодами, и наоборот, а так же знаем, как определить среднюю длину кодов. Но что же такое код, кодирование, и как оно происходит?
Кодирование без памяти
Коды без памяти являются простейшими кодами, на основе которых может быть осуществлено сжатие данных. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
На мой взгляд, не самое понятное определение. Рассмотрим эту тему чуть более подробно.

Пусть задан некоторый алфавит , состоящий из некоторого (конечного) числа букв. Назовем каждую конечную последовательность символов из этого алфавита (A=a1, a2,… ,an) словом, а число n — длиной этого слова.

Пусть задан также другой алфавит. Аналогично, обозначим слово в этом алфавите как B.
Введем еще два обозначения для множества всех непустых слов в алфавите. Пусть — количество непустых слов в первом алфавите, а — во втором.
Пусть также задано отображение F, которое ставит в соответствие каждому слову A из первого алфавита некоторое слово B=F(A) из второго. Тогда слово B будет называться кодом слова A, а переход от исходного слова к его коду будет называться кодированием.
Поскольку слово может состоять и из одной буквы, то мы можем выявить соответствие букв первого алфавита и соответствующих им слов из второго:
a1 <-> B1
a2 <-> B2
…
an <-> Bn
Это соответствие называют схемой, и обозначают ∑.
В этом случае слова B1, B2,…, Bn называют элементарными кодами, а вид кодирования с их помощью — алфавитным кодированием. Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Итак, мы определились с понятиями алфавит, слово, код, и кодирование. Теперь введем понятие префикс.
Пусть слово B имеет вид B=B'B''. Тогда B' называют началом, или префиксом слова B, а B'' — его концом. Это довольно простое определение, но нужно отметить, что для любого слова B, и некое пустое слово ʌ («пробел»), и само слово B, могут считаться и началами и концами.
Итак, мы подошли вплотную к пониманию определения кодов без памяти. Последнее определение, которое нам осталось понять — это префиксное множество. Схема ∑ обладает свойством префикса, если для любых 1≤i, j≤r, i≠j, слово Bi не является префиксом слова Bj.
Проще говоря, префиксное множество – это такое конечное множество, в котором ни один элемент не является префиксом (или началом) любого другого элемента. Простым примером такого множества является, например, обычный алфавит.
Одним из канонических алгоритмов, которые иллюстрируют данный метод, является алгоритм Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана использует частоту появления одинаковых байт во входном блоке данных, и ставит в соответствие часто встречающимся блокам цепочки бит меньшей длины, и наоборот. Этот код является минимально – избыточным кодом. Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
Для лучшей иллюстрации, рассмотрим небольшой пример.
Пусть у нас есть алфавит, состоящий из всего четырех символов — < a1, a2, a3, a4>. Предположим также, что вероятности появления этих символов равны соответственно p1=0.5; p2=0.24; p3=0.15; p4=0.11 (сумма всех вероятностей, очевидно, равна единице).
Итак, построим схему для данного алфавита.
- Объединяем два символа с наименьшими вероятностями (0.11 и 0.15) в псевдосимвол p'.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Объединяем два символа с наименьшей вероятностью (0.24 и 0.26) в псевдосимвол p''.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Наконец, объединяем оставшиеся два символа, и получаем вершину дерева.
Если сделать иллюстрацию этого процесса, получится примерно следующее:

Как вы видите, при каждом объединении мы присваиваем объединяемым символам коды 0 и 1.
Таким образом, когда дерево построено, мы можем легко получить код для каждого символа. В нашем случае коды будут выглядить так:
Поскольку ни один из данных кодов не является префиксом какого-нибудь другого (то есть, мы получили пресловутое префиксное множество), мы можем однозначно определить каждый код в выходном потоке.
Итак, мы добились того, что самый частый символ кодируется самым коротким кодом, и наоборот.
Если предположить, что изначально для хранения каждого символа использовался один байт, то можно посчитать, насколько нам удалось уменьшить данные.
Пусть на входу у нас была строка из 1000 символов, в которой символ a1 встречался 500 раз, a2 — 240, a3 — 150, и a4 — 110 раз.
Изначально данная строка занимала 8000 бит. После кодирования мы получим строку длинной в ∑pili = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 бит. Итак, нам удалось сжать данные в 4,54 раза, потратив в среднем 1,76 бита на кодирование каждого символа потока.
Напомню, что согласно Шеннону, средняя длина кодов составляет . Подставив в это уравнение наши значения вероятностей, мы получим среднюю длину кодов равную 1.75496602732291, что весьма и весьма близко к полученному нами результату.
Тем не менее, следует учитывать, что помимо самих данных нам необходимо хранить таблицу кодировки, что слегка увеличит итоговый размер закодированных данных. Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Заключение
Итак, в этой статье я постарался рассказать об общих принципах, по которым происходит сжатие без потерь, а также рассмотрел один из канонических алгоритмов — кодирование по Хаффману.
Если статья придется по вкусу хабросообществу, то я с удовольствием напишу продолжение, так как есть еще множество интересных вещей, касающихся сжатия без потерь; это как классические алгоритмы, так и предварительные преобразования данных (например, преобразование Барроуза-Уилира), ну и, конечно, специфические алгоритмы для сжатия звука, видео и изображений (самая, на мой взгляд, интересная тема).
Сжатие файлов позволяет быстрее передавать, получать и хранить большие файлы. Оно используется повсеместно и наверняка хорошая вам знакомо: самые популярные расширения сжатых файлов — ZIP, JPEG и MP3. В этой статье кратко рассмотрим основные виды сжатия файлов и принципы их работы.
Что такое сжатие?
Сжатие файла — это уменьшение его размера при сохранении исходных данных. В этом случае файл занимает меньше места на устройстве, что также облегчает его хранение и передачу через интернет или другим способом. Важно отметить, что сжатие не безгранично и обычно делится на два основных типа: с потерями и без потерь. Рассмотрим каждый из них по отдельности.
Сжатие с потерями
Такой способ уменьшает размер файла, удаляя ненужные биты информации. Чаще всего встречается в форматах изображений, видео и аудио, где нет необходимости в идеальном представлении исходного медиа. MP3 и JPEG — два популярных примера. Но сжатие с потерями не совсем подходит для файлов, где важна вся информация. Например, в текстовом файле или электронной таблице оно приведёт к искажённому выводу.
MP3 содержит не всю аудиоинформацию из оригинальной записи. Этот формат исключает некоторые звуки, которые люди не слышат. Вы заметите, что они пропали, только на профессиональном оборудовании с очень высоким качеством звука, поэтому для обычного использования удаление этой информации позволит уменьшить размер файла практически без недостатков.
3–5 декабря, Онлайн, Беcплатно
Аналогично файлы JPEG удаляют некритичные части изображений. Например, в изображении с голубым небом сжатие JPEG может изменить все пиксели на один или два оттенка синего вместо десятков.
Чем сильнее вы сжимаете файл, тем заметнее становится снижение качества. Вы, вероятно, замечали такое, слушая некачественную музыку в формате MP3, загруженную на YouTube. Например, сравните музыкальный трек высокого качества с сильно сжатой версией той же песни.
Сжатие с потерями подходит, когда файл содержит больше информации, чем нужно для ваших целей. Например, у вас есть огромный файл с исходным (RAW) изображением. Целесообразно сохранить это качество для печати изображения на большом баннере, но загружать исходный файл в Facebook будет бессмысленно. Картинка содержит множество данных, не заметных при просмотре в социальных сетях. Сжатие картинки в высококачественный JPEG исключает некоторую информацию, но изображение выглядит почти как оригинал.
При сохранении в формате с потерями, вы зачастую можете установить уровень качества. Например, у многих графических редакторов есть ползунок для выбора качества JPEG от 0 до 100. Экономия на уровне 90 или 80 процентов приводит к небольшому уменьшению размера файла с незначительной визуальной разницей. Но сохранение в плохом качестве или повторное сохранение одного и того же файла в формате с потерями ухудшит его.
Посмотрите на этот пример.
Оригинальное изображение, загруженное с Pixabay в формате JPEG. 874 КБ:

Результат сохранения в формате JPEG с 50-процентным качеством. Выглядит не так уж плохо. Вы можете заметить артефакты по краям коробок только при увеличении. 310 КБ:

Исходное изображение, сохранённое в формате JPEG с 10-процентным качеством. Выглядит ужасно. 100 КБ:

Где используется сжатие с потерями
Как мы уже упоминали, сжатие с потерями отлично подходит для большинства медиафайлов. Это крайне важно для таких компаний как Spotify и Netflix, которые постоянно транслируют большие объёмы информации. Максимальное уменьшение размера файла при сохранении качества делает их работу более эффективной.
Сжатие без потерь
Сжатие без потерь позволяет уменьшить размер файла так, чтобы в дальнейшем можно было восстановить первоначальное качество. В отличие от сжатия с потерями, этот способ не удаляет никакую информацию. Рассмотрим простой пример. На картинке ниже стопка из 10 кирпичей: два синих, пять жёлтых и три красных.

Вместо того чтобы показывать все 10 блоков, мы можем удалить все кирпичи одного цвета, кроме одного. Используя цифры, чтобы показать, сколько кирпичей каждого цвета было, мы представляем те же данные используя гораздо меньше кирпичей — три вместо десяти.
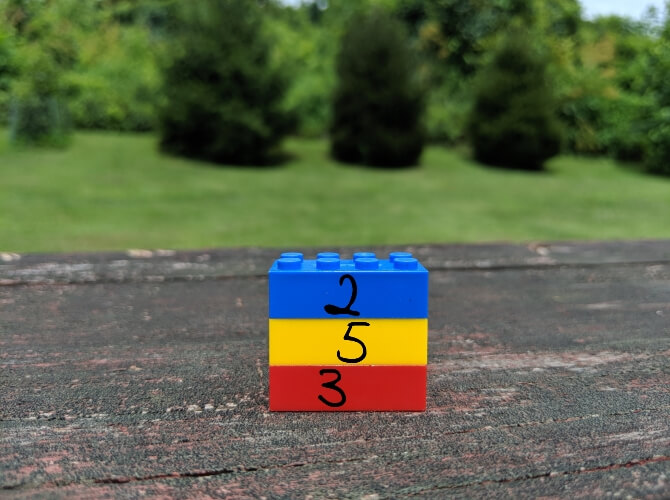
Это простая иллюстрация того, как осуществить сжатие без потерь. Та же информация сохраняется более эффективным способом. Рассмотрим реальный файл: mmmmmuuuuuuuoooooooooooo. Его можно сжать до гораздо более короткой формы: m5u7o12. Это позволяет использовать 7 символов вместо 24 для представления одних и тех же данных.
Где используется сжатие без потерь
ZIP-файлы — популярный пример сжатия без потерь. Хранить информацию в виде ZIP-файлов более эффективно, при этом когда вы распаковываете архив, там присутствует вся оригинальная информация. Это актуально для исполняемых файлов, так как после сжатия с потерями распакованная версия будет повреждена и непригодна для использования.
Другие распространённые форматы без потерь — PNG для изображений и FLAC для аудио. Форматы видео без потерь встречаются редко, потому что они занимают много места.
Сжатие с потерями vs сжатие без потерь
Теперь, когда мы рассмотрели обе формы сжатия файлов, может возникнуть вопрос, когда и какую следует использовать. Здесь всё зависит от того, для чего вы используете файлы.
Скажем, вы только что откопали свою старую коллекцию компакт-дисков и хотите оцифровать её. Когда вы копируете свои компакт-диски, имеет смысл использовать формат FLAC, формат без потерь. Это позволяет получить мастер-копию на компьютере, которая обладает тем же качеством звука, что и оригинальный компакт-диск.
Позже вы, возможно, захотите загрузить музыку на телефон или старый MP3-плеер. Здесь не так важно, чтобы музыка была в идеальном качестве, поэтому вы можете конвертировать файлы FLAC в MP3. Это даст вам аудиофайл, который по-прежнему достаточно хорош для прослушивания, но не занимает много места на мобильном устройстве. Качество MP3, преобразованного из FLAC, будет таким же, как если бы вы создали сжатый MP3 с оригинального CD.
Тип данных, представленных в файле, также может определять, какой вид сжатия подходит больше. В PNG используется сжатие без потерь, поэтому его хорошо использовать для изображений, в которых много однотонного пространства. Например, для скриншотов. Но PNG занимает гораздо больше места, когда картинка состоит из смеси множества цветов, как в случае с фотографиями. В этом случае с точки зрения размера файлов лучше использовать JPEG.
Проблемы во время сжатия файлов
Бесполезно конвертировать формат с потерями в формат без потерь. Это пустая трата пространства. Скажем, у вас есть MP3-файл весом в 3 МБ. Преобразование его в FLAC может привести к увеличению размера до 30 МБ. Но эти 30 МБ содержат только те звуки, которые имел уже сжатый MP3. Качество звука от этого не улучшится, но объём станет больше.
Также стоит иметь в виду, что преобразовывая один формат с потерями в аналогичный, вы получаете дальнейшее снижение качества. Каждый раз, когда вы применяете сжатие с потерями, вы теряете больше деталей. Это становится всё более и более заметно, пока файл по существу не будет разрушен. Помните также, что форматы с потерями удаляют некоторые данные и их невозможно восстановить.
Заключение
Мы рассмотрели как сжатие файлов с потерями, так и без потерь, чтобы увидеть, как они работают. Теперь вы знаете, как можно уменьшить размер файла и как выбрать лучший способ для этого.
Алгоритмы, которые определяют, какие данные выбрасываются в методах с потерями и как лучше хранить избыточные данные при сжатии без потерь, намного сложнее, чем описано здесь. На эту тему можно почитать больше информации здесь, если вам интересно.
Главной целью этой статьи является выбор наиболее оптимального архиватора с высокой степенью сжатия различных реальных данных большого объёма. В тестировании принимали участие: самый распространенный и один из старейших ZIP, популярные архиваторы ACE, RAR, 7-zip. Кроме того, были протестированы некоторые перспективные архиваторы. Большинство из них являются экспериментальными, обладают низкой скоростью архивирования и разархивирования, требуют много оперативной памяти, имеют ошибки. Например, не удалось сжать все тестовые данные при помощи Slim 0.021 (ошибка приложения), показавшего очень хорошие результаты, скорость PAQ6 v2 достигала 15 КБ/с. В итоге были выбраны Compressia 1.0b, EPM r9, PAQ6 v2, RKC 1.02, которые на данный момент являются одними из лучших.
Каждый из протестированных архиваторов обладает рядом настроек, изменяя которые, можно управлять степенью сжатия и скоростью в широких пределах. Тестирование производилось в режимах norm и max. RAR дополнительно тестировался в режиме fastest (максимальной скорости). Compressia, EPM, RKС, PAQ6 - только в режиме max. Для режима norm выбирались предлагаемые средние установки, для режима max – дающие максимальную степень сжатия. Все дополнительные настройки устанавливались в значения, дающие в среднем лучшее сжатие на тестовой системе, или, если возможно, в авто. В частности, 7-zip, EPM r9, RKC 1.02, PAQ6 v2 настраивались на использование около 400 МБ оперативной памяти в max режимах. Для режима fastest все настройки устанавливались на максимальную скорость, фильтры отключались, параметр Solid=on (на скорость не влияет). Несмотря на то, что для каждого вида данных существуют свои оптимальные настройки, которые иногда дают существенный прирост степени сжатия, тестирование проводилось с едиными настройками. Это сделано для отражения реальных ситуаций, при которых бывает необходимо заархивировать папку с различными типами данными.
Поиск оптимального соотношения между степенью сжатия и скоростью – это предмет отдельного исследования. Кроме того, это соотношение не имеет четких границ и сильно зависит как от системы, на которой производится архивирование, так и от исходных данных. Можно привести такой пример: в max режиме при архивировании "Инсталляция Office XP" скорость 7-zip в 3 раза выше Compressia, а при архивировании "База данных 1С:Предприятие" скорость 7-zip в 9 раз ниже Compressia. В данной статье основной упор сделан на степень сжатия.
В качестве тестовых данных использовались большие объемы реальных неоднородных данных. Исключение составляет "Документы Word, Excel". Больше 9 МБ реальных "средних" документов найти не удалось, а тестировать документы по 13 МБ, в основном состоящие из отсканированных и несжимаемых изображений, неправильно. Дополнительно была добавлена книга TICSharp.DOC (11 МБ) с небольшими иллюстрациями.
Тестировались следующие архиваторы:
ZIP. Является старейшим и самым распространённым архиватором. Это почти стандарт. Преимущества – высокая скорость, распространённость, совместимость и бесплатность. Недостатки – низкий уровень сжатия, ограниченная функциональность.
Использовался встроенный в Total Commander 6.0 архиватор. Несмотря на то, что Total Commander является shareware, сам формат ZIP бесплатный. Существует много бесплатных программ, которые архивируют в формат ZIP, например 7-zip. Стоит отметить, что каждая реализация ZIP может иметь скорость и степень сжатия, отличающуюся от реализации ZIP в Total Commander 6.0. Например, 7-zip архивирует в ZIP с более высокой степенью сжатия, но значительно медленнее.
В Total Commander 6.0 также есть поддержка формата TGZ (настройка Packer TGZ) который является своеобразным Solid (непрерывным архивом) вариантом ZIP (GZIP). Использование TGZ может дать значительное улучшение сжатия на большом количестве небольших файлов (на тестовых данных "Текст в формате HTML" - 60% от ZIP norm), но обладает таким недостатком - Total Commander 6.0 видит архив TGZ как заархивированный TAR, в результате для распаковки необходимо сначала распаковать TAR, а затем уже содержимое архива. По скорости и степени сжатия одного файла TGZ равен ZIP norm.
Настройки для тестирования:
- ZIP norm – настройка normal compression (6).
- ZIP max – настройка maximum compression (9).
Использовался WinACE 2.5. Настройки для тестирования:
- ACE norm – настройка Level=normal, Solid=on, V2.0=on, Dictionary=4096 КБ.
- ACE max – настройка Level=best, Solid=on, V2.0=on, Dictionary=4096 КБ.
Использовался WinRAR 3.30 beta 5. По сравнению с предыдущей версией 3.11 степень сжатия незначительно увеличилась на всех видах данных, для текста прирост немного больше (вероятно, из-за улучшения в автоматическом определении параметров сжатия).
Настройки для тестирования:
- RAR fastest – настройка Compression method=fastest, Solid=on, Advanced compression parameters=все выключено, Dictionary=64 КБ.
- RAR norm – настройка Compression method=normal, Solid=on, Advanced compression parameters=все включено или авто, Dictionary=4096 КБ.
- RAR max – настройка Compression method=best, Solid=on, Advanced compression parameters=все включено или авто, Text compression memory to use=128 МБ, Dictionary=4096 КБ.
Использовался 7-zip 3.12. Настройки для тестирования:
- 7zip norm – настройка Compression level=normal, Compression method=LZMA, Dictionary=2 МБ, Word size=32, Solid=on.
- 7zip max – настройка Compression level=ultra, Compression method=LZMA, Dictionary=32 МБ, Word size=255, Solid=on.
- 7zip PPMd – настройка Compression level=ultra, Compression method=PPMd, Dictionary=384 МБ, Word size=20, Solid=on.
Использовался Compressia v1.0 beta. Настройки для тестирования:
- Compressia – настройки Use solid blocks=on, Maximum compression=on, Use English option=off, Block size=15 МБ.
Использовался EMP r9. EMP r9 - это не полноценный архиватор, а экспериментальная версия для отработки алгоритмов, сжимает только один файл. Для тестирования использовались тестовые данные, скомпонованные в один файл при помощи 7-zip store. Из-за этого степень сжатия могла немного ухудшиться по сравнению с полноценной реализацией Solid режима (в пределах пары процентов).
Настройки для тестирования:
Использовался RKC 1.02. RKC 1.02 - это не полноценный архиватор, а экспериментальная версия для отработки алгоритмов, сжимает только один файл. Для тестирования использовались тестовые данные, скомпонованные в один файл при помощи 7-zip store. Из-за этого степень сжатия могла немного ухудшиться по сравнению с полноценной реализацией Solid режима (в пределах пары процентов). Опция analysis выключена, т.к. при её включении на некоторых данных программа не работает.
Настройки для тестирования:
- RKC max – параметры командной строки -M420m -mxx -o16 -n+ -r+ -a-.
mmahoney/compression. Преимущества – один из самых лучших по степени сжатия архиваторов. Недостатки – очень низкая скорость, скорость и требования к оперативной памяти одинаковы во время архивирования и разархивирования, для высокой степени сжатия необходимо относительно много оперативной памяти.
Использовался PAQ6 v2. PAQ6 v2 - это не полноценный архиватор, а экспериментальная версия для отработки алгоритмов, может сжимать несколько файлов. Для тестирования использовались тестовые данные, скомпонованные в один файл при помощи 7-zip store. Из-за этого степень сжатия могла немного ухудшиться по сравнению с полноценной реализацией Solid режима (в пределах пары процентов).
Настройки для тестирования:
Для тестирования использовались следующие хорошо сжимающиеся данные:
- Документы Word, Excel – набор небольших документов (договоры, акты – 9 МБ) и книга TICSharp (11 МБ). Книга TICSharp является "неудобной" для архиваторов. Это обусловлено характерной структурой DOC файла - текстовые блоки чередуются с несжимаемыми картинками. Всего 20 МБ, 138 файлов.
- Текст в формате HTML – содержимое JAVA SDK 1.3.1. Представляет собой большое количество небольших файлов HTML, поэтому ZIP, не поддерживающий Solid режим, показал почти в 2 раза худший результат. Этот набор данных не является полноценным текстом, т. к. содержит много тэгов HTML и пару мегабайт несжимаемых файлов. Всего 109 МБ, 6226 файлов.
- Инсталляция Office XP – содержимое инсталляционного файла CAB. Около 120 МБ занимают файлы EXE, DLL, OCX. Всего 391 МБ, 1865 файлов
- Игра Counter-Strike – содержимое папки Half-Life с установленным Counter-Strike. Всего 770 МБ, 3113 файлов.
- База данных 1С: Предприятие – содержимое резервной копии базы данных (DBF-формат без индексов, с конфигурацией). Всего 189 МБ, 340 файлов.
Тестирование производилось на системе: CPU Athlon 2000 МГц, MB nForce2, RAM 512 МБ, HDD WD400JB, OS Windows 2000. Следует учитывать, что на аналогичных Pentium системах скорость сжатия может сильно отличаться.
Что можно архивировать?
Хорошо сжимаются почти все предварительно не сжатые данные, например, программные файлы, тексты, базы данных, простые несжатые изображения. Ограниченно сжимаются несжатый звук (WAV), сложные несжатые изображения (BMP). Не сжимаются (сжатие в пределах пары процентов за счет служебных тэгов и, возможно, небольшой избыточности) почти все уже сжатые данные, например, архивы (ZIP, CAB), сжатая графика и видео (JPG, GIF, AVI, MPG), сжатый звук (MP3).
Для примера можно рассмотреть папку с игрой Prince Of Persia. Из общего объема 1400 МБ, 550 МБ - это несжимаемое видео, 330 МБ - ограниченно сжимаемый звук. Игра сжимается до 1008 МБ. При сжатии разными архиваторами, разница будет только за счет сжимаемых 520 МБ, в меньшей степени за счет 330 МБ звука. Таким образом, относительные результаты будут "смазаны" несжимаемым видео.
Для сжатия некоторых специфических данных (текст, несжатые изображения, несжатый звук) существуют специализированные архиваторы, которые обеспечивают несколько лучшую степень сжатия и значительно более высокую скорость, чем универсальные архиваторы.
Результаты тестов:
Несмотря на низкую степень сжатия, ZIP norm обладает самой высокой скоростью (быстрее RAR fastest в 2 раза). Его можно использовать на медленных машинах или для оперативного архивирования.
RAR и ACE приблизительно равны, с небольшим преимуществом у RAR. Их можно рекомендовать только из-за дополнительной функциональности (например, разбивка архива на части, запись дополнительной информации для восстановления при повреждении архива). По степени сжатия они уступают 7-zip. На некоторых наборах данных разница значительна. В max режиме размер архива RAR больше 7-zip от 5% до 34%, в среднем на 18%.
7-zip не является лидером в степени сжатия и имеет низкую скорость в max режиме. По сравнению с PAQ6, размер архива 7-zip больше от 2% до 23%, в среднем на 13%. Разница с результатами Compressia, EPM, RKC незначительна или даже отличается в лучшую сторону. В отличие от этих архиваторов, скорость разархивирования 7-zip (за исключением режима PPMd) значительно выше скорости архивирования. Требования к оперативной памяти во время разархивирования небольшие. Низкая скорость в max режиме все же значительно выше, чем скорость PAQ6 (в 10 раз). 7-zip может работать, используя 2 потока, что даёт значительное повышение скорости на мультипроцессорных системах или на системах с Hyper-Threading. С учетом регулярного обновления и бесплатности, 7-zip является наиболее оптимальным выбором для современных систем. В списке ближайших его изменений – разбивка архива на части, запись дополнительной информации для восстановления при повреждении архива.
Дальнейшее увеличение степени сжатия архиваторов сильно ограничено возможностью современных компьютеров. Даже успехи 7-zip на фоне RAR достигнуты за счет уменьшения скорости. Более того, практическая реализация эффективных PPM алгоритмов, используемых RKC, PAQ, EPM, была обусловлена существенным повышением производительности компьютеров в последние годы. Поэтому не следует в ближайшее время ждать появления архиваторов, которые при высокой скорости показывали бы степень сжатия значительно выше рассмотренных.
Читайте также: