
Table access full oracle что значит
Обновлено: 06.07.2024
Шесть тысяч слов помогут вам понять статистику Oracle и план выполнения
Источник | JiekeXu Road (ID: JiekeXu_IT)
Свяжитесь с авторизацией для перепечатки | (WeChat ID: xxq1426321293)
Всем привет, я JiekuXu, я очень рад снова встретиться с вами, поделитесь этим сегодня Статистика Oracle и план выполнения. Эта статья была впервые опубликована в общедоступном аккаунте WeChat [JiekeXu Road], пожалуйста, нажмите на синюю букву выше, чтобы подписаться на меня!
Предисловие
Несколько дней назад я получил приглашение от г-на Ян Цзяньжун, автора «Рабочих заметок Oracle DBA» и «MySQL DBA Work Notes» и соучредителя сообщества DBAplus на WeChat, и сказал, что поделится технической, на рабочем месте и идеи в его группе QQ От таких статей я сразу почувствовал искренность и ужас.Мне было честью, что обмен опытом - это тоже процесс обучения, поэтому я с радостью согласился на приглашение Учителя Яна. Думая, что вы также изучаете в последнее время вещи, связанные с оптимизацией, вы можете обобщить и поделиться во время обучения.Если в статье есть другие недостатки, сообщите об этом.
1. Статистика
Статистическая информация в основном описывает тип информации, такой как размер, масштаб и статус распределения данных таблиц и индексов в базе данных. Например, количество строк в таблице, количество блоков, средний размер каждой строки, листовые блоки индекса, количество строк в индексном поле и размер различных значений являются статистическими. Информация. Начиная с Oracle11G, автоматический сбор статистики базы данных был интегрирован в задачи автоматического обслуживания, которые в основном выполняются автоматически по умолчанию, что также в большинстве случаев соответствует требованиям эксплуатации, но также может быть собрано вручную.Поговорим об этом вместе.
Использоватьgather_stats_job Автоматический сбор данных создается автоматически, когда база данных создается и управляется планировщиком. Он собирает статистику для всех объектов в базе данных, для которых отсутствует или устаревшая статистика оптимизатора.
Использоватьdbms_stats Пакет вручную собирает системную статистику.
Просмотр статуса задач автоматического сбора статистики
Имя задачи автоматического сбора статистической информации в oracle 11g - автоматический сбор статистики оптимизатора. Окно времени выполнения по умолчанию для автоматических задач в 11g (введение в временное окно Oracle):
С понедельника по пятницу начинается в 22:00 и заканчивается в 14:00.
Выходные - шесть часов утра и продолжаются 20 часов.
В этот период нагрузка на сервер, как правило, относительно невелика. Ресурсы сервера можно оставить для сбора статистической информации, а сбор статистической информации более ресурсоемкий. Это можно увидеть в следующем утверждении:

Как и выше, задача сбора статистической информации выполняется каждый день, но если нагрузка на сервер базы данных велика, а нагрузка высока ночью, эта задача может не выполняться. Вам нужно скорректировать эту задачу и время. Его можно отключить или изменить, но, как правило, он не отключен. Вам необходимо изменить временное окно на определенное время
- Остановить и запустить отдельную задачу (то есть остановить задачу в определенный день)
Связанные просмотры:
Вот и все, что касается автоматического сбора. Для получения дополнительной информации проверьте официальные документы или Doc ID 1300313.1
How to Create an Own Maintenance Window for Autotask Jobs in 11g (Doc ID1300313.1) . Позволь мне поговорить об этом dbms_stats Связанный с пакетом.
dbms_stats
Пакет DBMS_STATS в основном предоставляет методы для сбора (сбора), удаления (удаления), экспорта (экспорта), импорта (импорта) и изменения (установки) статистической информации. Говоря оdbms_stats Тогда нужно поговорить о команде анализа.
Разница между dbms_stats и анализировать: Dbms_stats - это пакет, используемый для сбора статистики в Oracle9i и более поздних версиях.Хотя команда анализа была всегда доступна, больше не рекомендуется использовать команду анализа для сбора статистики. Вместо этого используйте dbms_stats. Между ними существует большая разница. Dbms_stats может правильно собирать статистику таблицы разделов, что означает, что он может собирать глобальную статистику, в то время как анализ может собирать статистику только объектов нижнего уровня, а затем выводить и суммировать более высокие -уровневые объекты.Статистика: если таблица разделов собирает только статистику разделов, то суммирует статистику всех разделов, чтобы получить статистику на уровне таблицы. По сути, Analyze устарел. Он использовался более семи или восьми лет назад. Oracle и эксперты рекомендуют пакет dbms_stats.
Пакет dbms_stats может собирать статистику о базах данных, словарях данных, индексах, таблицах и т. Д.

dbms_stats.gather_table_ststs параметр
1、 cascade:
true: указывает, что статистика собирается вместе с индексом при подсчете
2、 no_invalidate:
true: после сбора статистики исходный план выполнения не становится недействительным.
false: после сбора статистики исходный план выполнения становится недействительным.
По умолчанию DBMS_STATS.AUTO_INVALIDATE, Oracle решает, когда сделать недействительным план выполнения.
3、 method_opt:
FOR ALL [INDEXED | HIDDEN] COLUMNS[size_clause]
FOR COLUMNS [size clause] column[size_clause] [,column [size_clause]. ]
Когда данные поля распределены неравномерно, создайте гистограмму (гистограмму):
Статистика гистограммы: значения столбца индексного поля для создания статистики
Многоколоночная статистика: статистика создания столбца составного индекса
Статистика выражений: создание статистики по клавишам индекса функций
Примечание. Случай двух приведенных выше строк отличается, при использовании exec его нужно записать в одну строку. Анонимные блоки могут быть записаны в несколько строк. Кроме того, значение Size равно 1-254, но после 12c значение становится 1-2048.
Просмотр статистики:

Примечание. Обычные пользователи могут проверить user_tab_col_statistics, а пользователи DBA могут проверить dba_tab_col_statistics. Конечно, вы также можете использовать dba_tab_statistics для просмотра времени последнего сбора статистической информации.

Вот и все статистические данные, давайте перейдем к сегодняшней теме: План реализации 。
2. План реализации
План выполнения: описание пути доступа или процесса выполнения оператора SQL в базе данных.Oracle через оптимизатор Optimizer (Оптимизатор здесь относится к оптимизатору на основе затрат [Cost Based Optimizer, CBO]) для поиска оптимального плана выполнения для выполнения. Затем мы сначала понимаем, как выполняется следующий SQL: обычно он проходит через три этапа: синтаксический анализ (Parse), выполнение (Execute) и получение (Fetch), которые выполняются различными компонентами Oracle. Подробная информация должна быть быть объясненным из архитектуры Oracle. Я не буду говорить об этом здесь.

rowsource Источник строки: в запросе подходящим набором данных, возвращенным предыдущей операцией, может быть вся таблица или ее часть.Конечно, также можно выполнить операцию соединения для двух таблиц. Что касается жесткого анализа, можно просмотреть мягкий анализПредыдущая статья。
В-третьих, просмотрите план выполнения
Часть SQL выполняется в базе данных и возвращает результат. Что происходит в середине и какие пути были доступны. Это требует проверки плана выполнения. Оптимизатор выберет наиболее разумный и наиболее эффективный метод выполнения, который, по его мнению, является наиболее разумный и эффективный метод выполнения для выполнения возврата SQL.Набор результатов предоставляется клиенту, поэтому давайте взглянем на общие методы проверки плана выполнения, включая, помимо прочего, следующие семь методов.
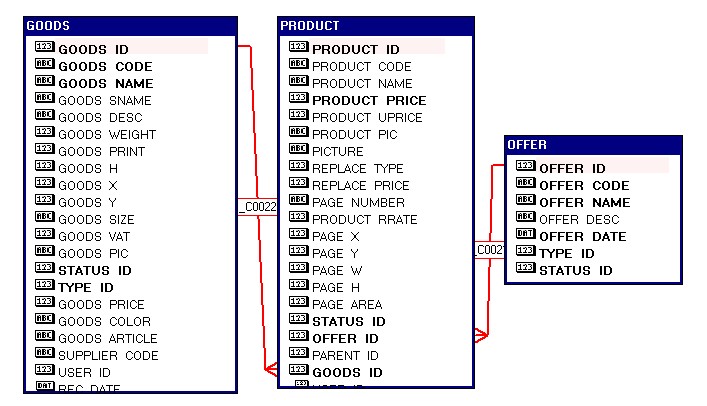
Данные рекомендации взяты мной из руководства Oracle по настройке базы данных, со временем они практически не меняются, посмотреть их можно здесь, это глава 11.5. Ссылка может не работать, все зависит от того, как долго Oracle решит хранить этот фрагмент документации в интернете.
Не используйте SQL-функции в предикатах. Любое выражение в котором используется колонка (expression), например функция, использующая колонку, как аргумент, приведет к тому, что индекс для данной колонки (если он есть) использоваться не будет, даже если это уникальный индекс. Хотя, если для колонки имеется составной индекс (function-based) на основе применяемой в предикате функции, то он может быть использован.
где numexpr выражение числового типа, то Oracle преобразует ваше условие в:
и индекс использован не будет.
Где по числовой колонке numcol построен индекс.
План запроса.
Практически любую задачу по получению каких-либо результатов из базы данных можно решить несколькими способами, т.е. написать несколько разных запросов, которые дадут один и тот же результат. Это, однако не означает, что база данных эти запросы будет выполнять по-разному. Также неверно мнение о том, что структура запроса может повлиять на то, как Oracle будет его выполнять, это касается порядка временных таблиц, JOINS и условий отбора в WHERE. Решение о том, как построить запрос принимает оптимизатор Oracle. Алгоритм получения сервером данных для конкретного запроса называют планом запроса.
Практически все продукты для работы с базой данных Oracle позволяют просмотреть план конкретного запроса. Так как слушатели этих лекций используют PL/SQL Developer, то для получения плана запроса в нем необходимо сделать следующее:
Существует стандартный механизм получения плана запроса. Для этого используется конструкция (команда) EXPLAIN PLAN FOR:
План запроса будет выведен в виде таблицы с одним полем, выглядит он так:
Важно ! Во всех планах запросов, первостепенное значение имеют колонки операций и названия объектов над которыми эти операции производятся. Все остальные колонки имеют оценочный характер, часть из них формируется на основе статистики, которая может устареть или вообще отсутствовать. При анализе плана запроса вы должны представлять объемы записей в таблицах, а также примерный алгоритм соединения таблиц.
В приведенном выше примере показан план запроса, полученный с помощью EXPLAIN PLAN FOR, более наглядную картину дает окно плана запроса в PL/SQL Developer:
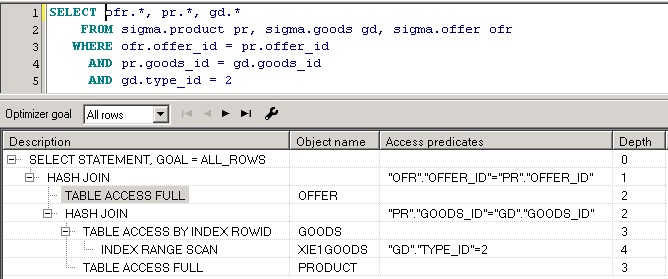
План всегда имеет иерархическую структуру. Операция соединения результирующих наборов оперирует парами дочерних операций. Операция получения данных может использовать вспомогательную операцию, такую, например, как сканирование индекса.
Данные результирующих наборов получаются в порядке следования этих наборов в плане запроса. Операция получения данных результирующего набора может состоять из нескольких шагов, которые характеризуются глубиной операции (колонка Depth).
При анализе плана в первую очередь необходимо обращать внимание на способы, с помощью которых получены данные результирующих наборов.
Некоторые термины в плане запроса.
План запроса имеет форму таблицы, один из столбцов которой описывает тип производимых сервером операций. Вот некоторые из них, которые встречаются наиболее часто:
Анализ плана запроса.
При анализе плана запроса вам необходимо примерно представлять объемы записей в таблицах и наличие у них индексов, которые могут пригодиться при фильтрации записей. Для доступа к данным Oracle использует несколько стратегий, какие из них выбраны для каждой из таблиц можно понять из плана запроса. При просмотре плана, вам необходимо решить, правильная ли выбрана стратегия в том или ином случае. Ниже приведены краткие описания способов доступа и механизмов отбора записей при соединениях результирующих наборов.
Full Table Scan (Table Access Full).
Может показаться, что доступ к данным таблицы быстрее осуществлять через индекс, но это не так. Иногда дешевле прочитать всю таблицу целиком, чем прочитать, например, 80% записей таблицы через индекс, так как чтение индекса тоже требует ресурсов. Очень не желательна ситуация, когда эта операция стоит первой в объединении наборов записей и таблица, которая читается полностью, большая. Еще хуже ситуация с большой таблицей на второй позиции в объединении, это означает, что она также будет прочитана полностью, как минимум, один раз, а если объединение производится через NESTED LOOPS, то таблица будет читаться несколько раз, поэтому запрос будет работать очень долго.
Nested Loops.
Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей (стоит первым в плане запроса) объединяется с помощью условия, позволяющего эффективно выбрать записи из второго набора. Важным условием успешного использования такого соединения является наличие связи между основным и второстепенным набором записей. Если такой связи нет, то для каждой записи в первом наборе, из второго набора будут извлекаться одни и те же записи, что может привести к значительному увеличению времени запроса. Если вы видите, что в плане запроса применен NESTED LOOPS, а соединяемые наборы не удовлетворяют этому условию, то налицо ошибка.
Hash Joins.
Используется при соединении больших наборов данных. Оптимизатор использует наименьший из наборов данных для построения в памяти хэш-таблицы по ключу соединения. Затем он сканирует большую таблицу, используя хэш-таблицу для нахождения записей, которые удовлетворяют условию объединения.
Оптимизатор использует HASH JOIN, если наборы данных соединяются с помощью операторов и ключевых слов эквивалентности (=, AND) и если присутствует одно из условий:
■ Необходимо соединить наборы данных большого объема.
■ Большая часть небольшого набора данных должна быть использована в соединении.
Sort Merge Join.
Данное соединение может быть применено для независимых наборов данных. Обычно Oracle выбирает такую стратегию, если наборы данных уже отсортированы ранее, и если дальнейшая сортировка результата соединения не требуется. Обычно это имеет место для наборов, которые соединяются с помощью операторов , >=. Для этого типа соединения нет понятия главного и вспомогательного набора данных, сначала оба набора сортируются по общему ключу, а затем сливаются в одно целое. Если какой-то из наборов уже отсортирован, то повторная сортировка для него не производится.
Cartesian Joins.
Это соединение используется, когда одна и более таблиц не имеют никаких условий соединения с какой-либо другой таблицей в запросе. В этом случае произойдет объединение каждой записи из одного набора данных с каждой записью в другом. Такое соединение может быть выбрано между двумя небольшими таблицами, а в дальнейшем этот набор данных будет соединен с другой большой таблицей. Наличие такого соединения может обозначать присутствие серьезных проблем в запросе, особенно, если соединяемые таблицы по MERGE JOIN CARTESIAN. В этом случае, возможно, упущены дополнительные условия соединения наборов данных.
Хинты.
Использование хинтов.
Хинт ставится после ключевого слова, которое определяет некую цельную конструкцию запроса, в данном разделе речь пойдет о хинтах в запросах к данным, т.е. тех, которые оформляются оператором SELECT и ключевых словах, используемых в сочетании с ним. Хинт указывается в закрытом комментарии после оператора:
В данном примере используется хинт RULE.
FIRST_ROWS.
Данный хинт дает указание оптимизатору выбрать такой план запроса при котором первые записи результатов будут получены максиально быстрым способом. Хорош при отладке запроса, чтобы убедиться, что выдается то, что необходимо. Если предполагается, что запрос вернет много записей, то при использовании такого хинта он может работать дольше.
ORDERED / LEADING.
При использовании этого хинта оптимизатор соединяет наборы данных в том порядке, в каком они следуют после оператора FROM. Вот пример разных последовательностей:
Порядок наборов данных необходимо выбирать аккуратно, чтобы соединяемые объекты имели какое-то условие связи в WHERE или после ключевого слова ON. Например в приведенном выше примере 4 версия списка во FROM приведет к перемножению таблиц GOODS и OFFER, так как они не связаны друг с другом условиями.
Данный хинт часто бывает полезен, если статистика по таблицам не собрана, план запроса не верный, и вам точно известно, как должны соединяться таблицы. При использовании данного хинта старайтесь выстроить порядок соединения так, чтобы тяжесть обработки данных следовала в сторону увеличения, т.е. сначала соедините наборы поменьше или с хорошими условиями отбора, чтобы результат их соединения был наименьшим по количеству записей, затем подключайте наборы данных большего размера.
Более удобен в использовании хинт LEADING. Он позволяет соединить наборы данных в порядке перечисления их (или их алиасов) в списке аргументов хинта:
Порядок связи в этом примере будет такой: product -> offer -> goods. Использование этого хинта предпочтительнее при отладке, если список наборов данных большой.
MATERIALIZE.
Дает указание оптимизатору построить временную таблицу (материализовать результаты) для запроса, к которому этот хинт применяется, работает только в конструкции WITH. Очень полезен при обработке больших объемов данных, так как позволяет разбить запрос на части, в этом случае улучшается читабельность запроса, а также может быть получен правильный план. Пример использования:
План запроса выглядит так:
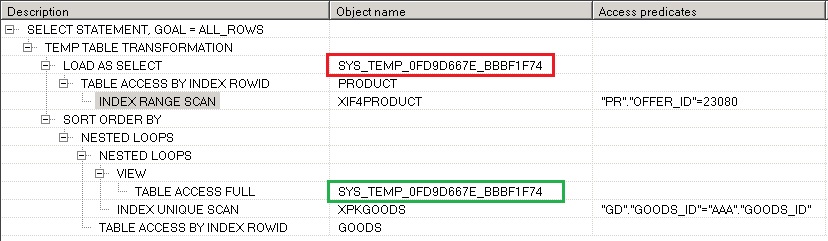
Красным цветом помечена таблица при ее создании, зеленым ее использование в соединении.
INDEX.
Дает указание оптимизатору использовать индекс при чтении данных из таблицы. Полезен тем, что может предотвратить чтение всего содержимого таблицы, если вы считаете, что этого делать не нужно. Пример использования:
Этот хинт сработает в том случае, если у таблицы есть указываемый индекс, и его можно использовать на основе одного или нескольких условий при получении данных таблицы. В приведенном примере в составе индекса есть поле OFFER_ID на второй позиции и он может быть использован, план запроса выглядит в этом случае так:

Комбинации хинтов.
Использование комбинации хинтов допустимо. Нужный эффект можно получить, если хинты в одном запросе не протеворечат друг другу. При записи хинты разделяются пробелами:
В данном примере используется хинт для установки порядка соединения наборов данных и способа доступа к таблице, противоречия в их использовании нет.
Не найдя на хабре статьи, объединяющей в удобном для чтения виде информацию о методах доступа к данным, используемых СУБД Oracle, я решил совершить «пробу пера» и написать эту статью.
Общая информация
Не углубляясь в детали, можно утверждать что Oracle хранит данные в таблицах, вместе с которыми могут существовать особые структуры данных – индексы, призванные ускорить запросы к таблицам. При выполнении запросов Oracle по-разному обращается к таблицам и индексам – способы доступа к данным в различных ситуациях и являются предметом этой статьи.
Для примеров мы будем использовать следующую таблицу и данные в ней:
Для анализа плана выполнения запроса будем пользоваться следующими средствами:
После создания индекса и использования его в примерах и перед созданием следующего индекса, он должен быть удален. Это можно сделать с помощью следующего запроса:
TABLE FULL SCAN
Данный метод доступа, как следует из названия, подразумевает перебор всех строк таблицы с исключением тех, которые не удовлетворяют предикату where (если таковой есть). Применяется он либо в случае, когда условия предиката отсутствуют в индексе, либо когда индекса нет в принципе. Примеры:
TABLE ACCESS BY ROWID, он же ROWID
- Мы указали идентификатор строки в предикате where;
- ROWID запрошенной записи был найден в индексе;
INDEX FULL SCAN
Данный метод доступа просматривает все листовые блоки индекса для поиска соответствий условиям предиката. Для того чтобы Oracle мог применить этот метод доступа, хотя бы одно из полей ключа должно иметь ограничение NOT NULL, т.к. только в этом случае соответствующая строка таблицы попадет в индекс. Этот метод обычно быстрее чем TABLE FULL SCAN, но медленнее, чем INDEX RANGE SCAN (см. ниже).
INDEX FAST FULL SCAN
Этот метод доступа применяется, когда выполнены все требования для INDEX FULL SCAN, а также все данные, выбираемые запросом, содержатся в индексе и таким образом доступ к самой таблице не требуется. В отличие от INDEX FULL SCAN этот метод может читать блоки индекса в несколько параллельных потоков и таким образом порядок возвращаемых значений не регламентирован. Oracle также не может использовать этот метод для bitmap-индексов.
INDEX RANGE SCAN
Данный метод доступа используется Oracle в том случае, если в предикат where входят столбцы индекса с условиями = (в случае если индексированные значения неуникальны), >, <, а также like ‘pattern%’, причем wildcard-символы должны стоять после искомой подстроки. В отличие от TABLE FULL SCAN, при использовании этого метода доступа Oracle не перебирает все листовые блоки и поэтому в большинстве случаев INDEX RANGE SCAN быстрее.
Пример:
INDEX UNIQUE SCAN
Данный метод доступа применяется когда в силу ограничений UNIQUE/PRIMARY KEY, а также условия предиката, запрос должен вернуть ноль или одно значение.
Пример:
INDEX SKIP SCAN
Этот метод доступа используется в случае, если в предикате where не используется первый столбец индекса.
Для примера использования этого метода доступа нам потребуется другая таблица (обратите внимание, что количество строк, данные и т.д. будут зависеть от того, что есть в используемой схеме, и поэтому данный пример может не воспроизвестись сразу):
Новая версия Oracle database 12c предлагает разработчикам значительно улучшенный "умный" SQL оптимизатор. Множество доработок и новых возможностей позволяют правильно использовать статистику, оценивать действительное число возвращаемых строк и учитывать фактическое распределение данных в столбцах.
При этом все предыдущие версии SQL оптимизатора, основанного на относительной стоимости операций, периодически ошибались, позволяя первому запросу "пойти в разнос" за счёт выбора неудачного плана. Последующие выполнения того же SQL могли пройти более успешно если оптимизатор мог учесть допущенные ошибки. Но первое выполнение всегда могло быть отработано неоптимальным образом, что было особенно ощутимо в системах хранилищ данных, где зачастую каждый запрос уникален и выполняется однократно.
В предлагаемой заметке я привожу пример использования одной из важных принципиально новых возможностей Оракла 12c изменять SQL план первого запроса "на лету" непосредственно во время его исполнения, приводя к значительному сокращению времени обработки данных. Так называемые "адаптивные" планы могут буквально спасти ситуацию, позволяя правильно и эффективно выполнить даже уникальный неповторяющийся SQL.
Прежде чем мы продолжим, я хотел бы привести строки из Евангелия:
. == Книга пророка Исаии == .
=== Глава 12, Стих 1 ===
1 И скажешь в тот день: славлю Тебя, Господи; Ты гневался на меня, но
отвратил гнев Твой и утешил меня.
2 Вот, Бог - спасение мое: уповаю на Него и не боюсь; ибо Господь - сила моя,
и пение мое - Господь; и Он был мне во спасение.
3 И в радости будете почерпать воду из источников спасения,
4 и скажете в тот день: славьте Господа, призывайте имя Его; возвещайте
в народах дела Его; напоминайте, что велико имя Его;
5 пойте Господу, ибо Он соделал великое, - да знают это по всей земле.
Лично для вас благая весть - Единородный Сын Божий Иисус Христос любит вас, Он взошёл на крест за ваши грехи, был распят и на третий день воскрес, сел одесную Бога и открыл нам дорогу в Царствие Небесное.
Мы все живём в те самые последние времена, когда брат идёт войной на брата, сердца людские ожесточились и каждый обороняет своё, не внимая голосу рассудка и зову сердца. Сатана запутал нас в бесконечном лабиринте жадности и мирских похотей - и, казалось бы, нет выхода из этого тупика.
Но ведь каждому из нас открыта дорога к спасению от этих окружающих нас повседневных бед - уповай на Господа, прославляй имя Его и ищи в Нём силы для борьбы со злом. Такое вот простое и незатейливое, казалось бы, решение. И тем не менее, уже много тысяч лет Господь спасает взывающих к Нему. И сегодня, на очередном витке нашего с вами безумия именуемого "историей", нам как никогда нужно Божие прощение и милость. Ибо наши страшные душевные раны могут быть омыты только той самой водой из источников спасения - остальным же уготована жажда на пустынной дороге самолюбия и зла, ведущей прямо в ад.
Задумайтесь над этими словами, серьёзно задумайтесь - выбор между спасительной верой и осуждающим для ада неверием неизбежен, и вполне возможно, дорогой брат, что именно сейчас решается ваша судьба - и не на год или десятилетие, а навсегда.
Покайтесь, примите Иисуса как вашего Спасителя, ибо наступают последние времена и время близко - стоит Судья у ворот.
Пожалуйста, в своих каждодневных трудах, какими бы занятыми вы себе ни казались - находите время для Бога, Его заповедей и Библии.
На главной странице этого сайта вы найдете программу для чтения Библии в командной строке - буду очень рад если программа окажется полезной. Пожалуйста, читайте Библию, на экране или в печатном виде - вы будете искренне удивлены как много там сказано лично про вас и ваши обстоятельства.
Вернёмся к нашим техническим деталям.
Прочитать подробно об изменяемых планах ("adaptive plan") можно в документации Оракла 12 - смотрите "Concept" и "SQL Tuning Guide".
Я же скажу вкратце так - при первом "разборе" SQL выражения оптимизатор начинает строить план его выполнения, опираясь на имеющиеся данные о количестве записей и числе уникальных значений в каждой колонке таблиц, участвующих в запросе. При определённых обстоятельствах оптимизатор замечает "неясность" в эффективности способа "сведения" таблиц - и вот в этот момент в план вставляется "ветвление" - кусок кода, выполняющийся позже, уже вместе с самим запросом. На данный момент код "ветвления" может сгенерировать только "Hash Join" или "Nested Loops", но я уверен - вскоре появятся новые варианты.
Непосредственно во время первого выполнения запроса при достижении "ветвления" процесс, исполняющий запрос по динамическому плану, оценивает количество уже обработанных фактически строк и сравнивает с числом строк, "предсказанных" планом. Если число отличается не сильно - ветвление просто игнорируется (и фактически выбрасывается, так что последующие выполнения SQL по этому адаптивному плану уже не будут изменяться - т.е. план превращается из адаптивного в обычный "фиксированный") и запрос "сводит" таблицы способом, предложенным в плане изначально.
Если же разница в числе строк велика - код "ветвления" выполняется и генерирует другой способ сведения таблиц - например, если изначально оптимизатор предсказал всего 20 строк в каждой таблице и решил использовать "Nested Loops", то теперь, когда вместо 20 строк мы уже обработали 2 тысячи, становится ясным что NL будет работать долго и нудно - и это же самое первое выполнение запроса "на лету" переходит на "Hash Join". И таким же образом, код ветвления удаляется из плана, превращая изменяемый план в его фиксированный эквивалент, но теперь уже содержащий HJ вместо NL.
Такой подход позволяет выполнить запрос оптимально с первой попытки, даже при неточностях в собранной статистике. При этом код ветвления либо не выполняется вообще, либо выполняется только один раз, сводя на нет возможные потери производительности при обработке последующих запросов по этому же плану.
"Внутренние" служебные запросы самой БД
Сам по себе, Оракл является одним из основных пользователей адаптивных планов. Сбор статистики, Automated Workload Repository и прочие "maintenance jobs" извлекают значительную выгоду из этой новой особенности продукта. Распознать запросы, выполненные по адаптивному плану, очень легко используя колонку V$SQL.IS_RESOLVED_ADAPTIVE_PLAN:
Мы видим, что запрос с sql_id "fuqs31uwjmbkz" был выполнен дважды - первый раз это происходило по "начальному" плану, который был "адаптирован" и в конце второго выполнения уже превратился в "фиксированный" план. Колонка IS_RESOLVED_ADAPTIVE_PLAN говорит нам именно о том, что код ветвления присутствовал в начальном плане, был выполнен и удалён.
Всё же возникает сомнение - а действительно ли план выполнения был адаптивным и вообще, не являются ли две строки выше просто двумя записями обработки одного и того же плана разными сессиями?
Замена Hash Join на Nested Loops
Я скажу сразу - изменения в версии 12c, связанные с "адаптивными" запросами и статистикой настолько кардинальны, что во многих случаях ответ просто неясен :-) Методом проб и ошибок, выполнением простых запросов на известных наборах данных получается добраться до реальной картины происходящего - но это требует усилий и времени. Попробуем посмотреть внимательнее:
Совпадение времени окончания выполнения и хэшей планов показывает нам, что наше предположение оказалось верным - мы говорим об адаптивном плане. Что же именно делал SQL запрос 'fuqs31uwjmbkz' и как менялся "адаптивный" план? Посмотрим (и я заранее извиняюсь за выступающий за поля текст плана):
План для "child 1" будет таким же самым. Действия в плане, помеченные дефисом, не выполнялись, именно как результат работы кода ветвления (обозначенного на плане "STATISTICS COLLECTOR", который тоже был помечен "-" после первого обращения и не является активным для последующих сессий).
В этом запросе процесс, выполняющий план с хэшем 4259802813, решил не использовать Hash Join и полное сканирование таблицы WRH$_EVENT_NAME, вместо этого был использован индекс WRH$_EVENT_NAME_PK с последующим Nested Loops Join. Также заметьте наличие Bind Variables - без них план вероятнее всего не был бы адаптивным и колонка v$sql.IS_RESOLVED_ADAPTIVE_PLAN содержала бы NULL.
Замена Nested Loops на Hash Join
Теперь посмотрим на обратное действие - похожий запрос от того же модуля AWR, только выполнялся он 4 раза, и все разы использовал адаптивный план, в котором вместо NL использовался HJ и полное сканирование таблицы WRH$_EVENT_NAME. Даты и количество END_OF_FETCH_COUNT показывают нам, что Child 0 был принят к обработке, но не закончил выполнения. Child 1 был полностью выполнен 4 раза.
Обратите внимание, что "код ветвления" был вставлен в этот план дважды.
Простой пример с двумя таблицами пользователя
Настало время оценить полезность изменяемых планов для нас, пользователей, на наших собственных данных. Сгенерируем простой набор в виде таблиц клиентов и их визитов к нам. Распределение записей по клиентам специально подобрано так, чтобы оптимизатор не мог быть уверен в количестве строк.
Создание набора данных пользователя
Используя приведенные ниже команды, создайте в своей базе подобные объекты в какой-нибудь из схем. Используйте "локального" пользователя с минимальным набором привилегий в одной из "подключаемых" PDB баз. Как я говорил в своей заметке про PDB/CDB, для удобства подключения установите переменную окружения среды TWO_TASK.
После сбора статистики Оракл построил для нас частотную гистограмму для колонки CUST_ID таблицы VISITS:
Существуют параметры, определяющие эффект адаптивных планов, по умолчанию оптимизатор запросов будет их создавать и использовать:
Итак, данные созданы - пора перейти к запросу.
Запрос пользователя и начальный план его выполнения
Запрос очень простой и предсказуемый, посмотрим какой план Оракл нам предложит до его исполнения:
За исключением создания адаптивного плана, ничего выдающегося. Оптимизатор решил не использовать Hash Join ввиду малого числа ожидаемых строк (всего одна).
Hint "gather_plan_statistics" нам понадобится во всех тестах, наравне с другим полезным хинтом "monitor". Почитайте в документации про них. Не забудьте проверить ваше лицензирование вообще, в том числе если используете "management pack".
Запускаем запрос и проверяем действительный план выполнения
Вы наверняка помните, что "explain plan" более не является полностью надежной утилитой - он может показать одно, а на самом деле запрос будет выполнен иначе. Запустим SQL и после его завершения проверим план по "sql_id".
Итак, оптимизатор был неправ - наш запрос не вернул строк вообще. Определим sql_id запроса и проверим как же он был выполнен.
Итак, при выполнении использовался слегка другой план (сравните hash плана в предыдущем подразделе и этого) - оптимизатор решил использовать индексы для обеих таблиц. Но этот план тоже был адаптивным, при этом оптимизатор не был уверен надо ли делать Hash Join или Nested Loops до тех пор, пока не начал получать (отсутствующие) результаты.
Обратили ли вы внимание на привязку запроса к текущей дате? С тем же самым значением переменной :custid (равному 2) через 24 часа этот же запрос вернёт миллионы строк и оптимизатор решит "переключиться" во время исполнения на Hash Join. Правда, при этом необходимо очистить library cache или дождаться естественного устаревания и исчезновения уже ставшего постоянным плана с хэшем 865602956 (об этом свидетельствует IS_RESOLVED_ADAPTIVE_PLAN=Y в результате запроса вверху). Так что, по-прежнему, ещё есть возможность "обмануть" оптимизатор. Надо отметить, что другие средства оптимизации могут заставить Оракл сгенерировать новый фиксированный план даже при уже имеющемся адаптивном плане (например, обновление или устаревание статистики) - но в нашем случае привязки к дате вполне вероятна ситуация, когда миллионы строк будут возвращаться через Nested Loops. Я оставляю этот случай для вас в качестве упражнения.
Скрипт для тестирования
Используйте этот скрипт для тестирования разных условий и планов. Результаты должны показать, что внесение потенциальной "неясности" сразу же приводит к генерации изменяемого плана. Соответственно, ясно выраженные условия, при наличии гистограммы и правильной статистики, приводят к использованию простого фиксированного постоянного плана с самого начала.
В конце тестирования, измените степень параллельного выполнения на таблицах и повторите тесты в приведенном выше скрипте. Изменятся ли полученные планы?
Смогли ли вы добиться адаптивных планов при параллельном выполнении запросов?
Моё тестирование показало, что в текущей версии Оракла 12.1.0.1 адаптивные планы используются только когда возможна ошибка оптимизации. Они используются почти всегда при наличии условий с неравенством и однопоточного выполнения запроса. В случае параллельного выполнения адаптивные планы почти никогда не генерируются. Также для создания изменяемых планов используйте PDB, подключаясь к ней как локальный пользователь - во многих случаях оптимизатор не генерирует адаптивные планы при подключении к контейнеру CDB$ROOT или не-CDB базе данных.
Пример, использующий схему "OE"
Поставляемая с Оракл схема Order Entry (загрузите и установите "Oracle Database 12c Release 1 Examples") тоже генерирует адаптивные планы. Используем простой запрос:
Какой план нам "предскажет" оптимизатор до выполнения запроса?
Похоже, оптимизатор угадал число возвращаемых строк (13) - а это значит, что изначальная версия адаптивного плана окажется приемлемой, план не должен измениться, код ветвления не будет выполнен ни разу и план просто превратится в постоянный в конце первого запуска запроса. Проверим это:
Всё оказалось именно так - даже хэш плана до и после выполнения остался неизменным. Что ещё раз показывает исключительную важность правильной статистики для SQL оптимизатора версии Oracle 12c. Кстати, статистика теперь тоже стала адаптивной, как и планы - но это уже другая история.
Читайте также: