
Установка юпитер ноутбук без анаконды
Обновлено: 07.07.2024
В своей известной презентации “Я не люблю блокноты” ( видео и слайды ) Джоэль Грус критикует Jupyter Notebook — вероятно, самую популярную среду разработки для машинного обучения. Для меня эта презентация несёт поучительный характер: когда все думают, что продукт хорош, нужны люди, которые раскритикуют его, чтобы мы не останавливались на достигнутом. На самом деле, я думаю, что проблема не в самом блокноте, а в том, как он используется: как и любой другой инструмент, Jupyter Notebook может неправильно применяться, что и происходит.
По этой причине я хочу немного переиначить название презентации Груса и сказать: “Я не люблю беспорядочные, непонятные блокноты без названия и без комментариев или других пояснений”. Jupyter Notebook приспособлен для грамотного программирования — соединения кода, текста, результатов, изображений и пояснений в один цельный документ. Однако, я довольно часто вижу пренебрежение этим предназначением. Это заканчивается вот такими блокнотами, захламляющими репозитории на GitHub:
Проблемы достаточно очевидны:
- Нет названия
- Нет описания кода: как он работает и для чего предназначен
- Ячейки расположены не в порядке запуска
- Код работает с ошибками
Jupyter Notebook может быть невероятно мощным инструментом для обучения, исследований и общения ( пример ). Несмотря на это, встречаются и такие блокноты, как выше. В нём сложно разобраться, провести дебаггинг или даже понять, что делает код. Как минимум, каждый блокнот должен содержать понятное название, краткое вступление, описание и заключение; ячейки должны располагаться в порядке их запуска. К тому же, перед публикованием блокнота необходимо удостовериться в том, что код выполняется без ошибок.
Решение: использование расширений для Jupyter Notebook
Вместо того, чтобы жаловаться на проблему, я решил посмотреть, что можно изменить при помощи расширений. В результате у меня получилось расширение, которое при создании нового блокнота автоматически:
- Создаёт шаблон для документации
- Импортирует часто используемые библиотеки
- Просит ввести название блокнота
Преимущества расширения в том, что оно меняет настройки блокнота, установленные по умолчанию. Так, например, новый блокнот в Jupyter Notebook не содержит ячеек с разметкой, назван как “Untitled” и в нём не импортирована ни одна библиотека. Мы знаем, что люди на удивление редко меняют настройки по умолчанию, так почему бы не сделать так, чтобы сами настройки заставляли людей делать блокноты лучше? Думайте об этом расширении как о пинке, который ненавязчиво подталкивает к созданию более удобных блокнотов.
Для использования этого расширения:
- Установите Jupyter Notebook Extensions
- Скачайте с GitHub папку setup (в ней должно быть 3 файла)
- Выполните команду pip show jupyter_contrib_nbextensions для того, чтобы узнать, где установлены расширения. У меня на Windows с установленным пакетом Anaconda их расположение таково:
При этом на Mac без Anaconda путь к расширениям такой:
4. Переместите папку setup в nbextensions/ :
5. Выполните команду jupyter contrib nbextensions install для установки нового расширения
6. Запустите Jupyter Notebook и включите Setup во вкладке nbextensions (если вы не можете найти эту вкладку, то откройте блокнот и зайдите в edit > nbextensions config)
Теперь создайте новый блокнот и начинайте работу! Шаблон по умолчанию можно изменить в main.js. Шаблон по умолчанию довольно незамысловатый, но его можно персонализировать.
Если вы откроете старый блокнот, то шаблон не появится, но каждый раз, когда вы будете запускать ячейку, среда будет просить изменить имя с Untitled:
Просьба изменить название будет появляться до тех пор, пока название блокнота не станет отличным от Untitled Просьба изменить название будет появляться до тех пор, пока название блокнота не станет отличным от UntitledИногда настойчивость — ключ к успеху.
Напутственные размышления
Давайте с этого момента стараться создавать блокноты лучше. Это не требует большого количества времени или усилий, но при этом сделает лучше в будущем и вам, и тем, кто будет использовать ваш код. Вот несколько правил, которым стоит следовать при создании блокнотов:
- Давайте название каждому блокноту. Это полезно, особенно, если у вас их десятки.
- Давайте краткое и понятное объяснение тому, как код работает, что он делает, каковы результаты работы над ним и выводы из этого. Я использую это как шаблон для блокнота, чтобы выработать в вас эту привычку.
- Перед публикацией блокнота запустите каждую ячейку заново, чтобы убедиться в том, что код выполняется без ошибок.
Расширение Setup, конечно же, не решит все проблемы с использованием Jupyter Notebook. Однако, оно даст основу для приобретения полезных привычек. Для выработки хорошей привычки требуется много времени, зато, выработавшись, они остаются надолго. Надеюсь, что благодаря этим усилиям следующая презентация о блокнотах будет называться “Мне нравятся качественные блокноты Jupyter”.
Из этой статьи вы узнаете, как установить Jupyter Notebook с пользовательскими ядрами PySpark (для Python) и Apache Spark (для Scala) с помощью магических команд Spark, а затем подключить эту записную книжку к кластеру HDInsight.
Для установки Jupyter и подключения к Apache Spark в HDInsight необходимо выполнить четыре основных шага.
- Настроить кластер Spark.
- Установить Jupyter Notebook.
- Установите ядра PySpark и Spark с помощью волшебной команды Spark.
- Настройте волшебную команду Spark для доступа к кластеру Spark в HDInsight.
Дополнительные сведения о пользовательских ядрах и магических командах Spark см. в разделе Ядра, доступные для Jupyter Notebook с кластерами Apache Spark Linux в HDInsight.
Предварительные требования
Кластер Apache Spark в HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark. Локальная записная книжка подключается к кластеру HDInsight.
Опыт работы с записными книжками Jupyter с Spark в HDInsight.
Установка Jupyter Notebook на компьютер
Перед установкой Jupyter Notebook необходимо установить Python. Дистрибутив Anaconda установит как Python, так и Jupyter Notebook.
Скачайте установщик Anaconda для своей платформы и запустите программу установки. В мастере установки укажите параметр для добавления Anaconda в переменную PATH. См. также Установка Jupyter с помощью Anaconda.
Установка магических команд Spark
Введите команду pip install sparkmagic==0.13.1 , чтобы установить магические команды Spark для кластеров HDInsight версии 3.6 и 4.0. См. также документацию по sparkmagic.
Убедитесь, что мини-приложение ipywidgets установлено правильно. Для этого выполните следующую команду:
Установка ядер PySpark и Spark
Определите место установки sparkmagic с помощью следующей команды:
Затем измените рабочий каталог на расположение, определенное с помощью команды выше.
В новом рабочем каталоге введите одну или несколько из приведенных ниже команд, чтобы установить требуемые ядра:
Необязательный элемент. Введите следующую команду, чтобы включить расширение сервера:
Настройка волшебной команды Spark для подключения к кластеру HDInsight Spark
В этом разделе вы настроите подключение магической команды Spark, установленной ранее, к кластеру Apache Spark.
Запустите оболочку Python с помощью следующей команды:
Сведения о конфигурации Jupyter обычно хранятся в домашнем каталоге пользователей. Введите следующую команду, чтобы определить домашний каталог, и создайте папку с именем .sparkmagic. Будет выведен полный путь.
В папке .sparkmagic создайте файл config.json и добавьте в него следующий фрагмент кода JSON.
Внесите в файл следующие изменения:
Полный пример файла можно просмотреть в образце config.json.
Сигналы пульса отправляются, чтобы предотвратить утечку сеансов. При переходе в спящий режим или завершении работы компьютера пульс не отправляется, что приводит к очистке сеанса. Если вы хотите отключить такое поведение для кластеров версии 3.4, то можете настроить для параметра Livy livy.server.interactive.heartbeat.timeout значение 0 с помощью пользовательского интерфейса Ambari. Если для кластеров версии 3.5 не настроить соответствующую конфигурацию, приведенную выше, то сеанс не будет удален.
Запустите Jupyter. Выполните следующую команду из командной строки.
Убедитесь, что вы можете использовать магическую команду Spark, доступную вместе с ядрами. Выполните следующие шаги.
а. Создайте новую записную книжку. В правом верхнем углу щелкните Создать. Должны отобразиться ядро по умолчанию Python 2 или Python 3 и установленные ядра. Фактические значения могут отличаться в зависимости от выбранных вариантов установки. Выберите PySpark.

b. Запустите следующий фрагмент кода.
Если вы успешно получили выходные данные, подключение к кластеру HDInsight работает.
Если вы хотите обновить конфигурацию записной книжки для подключения к другому кластеру, измените файл config.json, указав новый набор значений, как показано на шаге 3.
Зачем устанавливать Jupyter на моем компьютере?
Причины, по которым требуется установить на компьютер Jupyter и подключить к кластеру Apache Spark в HDInsight.
Если Jupyter установлен на локальном компьютере, несколько пользователей могут одновременно запустить одну и ту же записную книжку в одном кластере Spark. В такой ситуации создаются несколько сеансов Livy. Если вы столкнетесь с проблемами и начнете их отладку, вам будет сложно определить, какой сеанс Livy какому пользователю принадлежит.
Jupyter Notebook — это мощный инструмент для разработки и представления проектов Data Science в интерактивном виде. Он объединяет код и вывод все в виде одного документа, содержащего текст, математические уравнения и визуализации.
Такой пошаговый подход обеспечивает быстрый, последовательный процесс разработки, поскольку вывод для каждого блока показывается сразу же. Именно поэтому инструмент стал настолько популярным в среде Data Science за последнее время. Большая часть Kaggle Kernels (работы участников конкурсов на платформе Kaggle) сегодня созданы с помощью Jupyter Notebook.
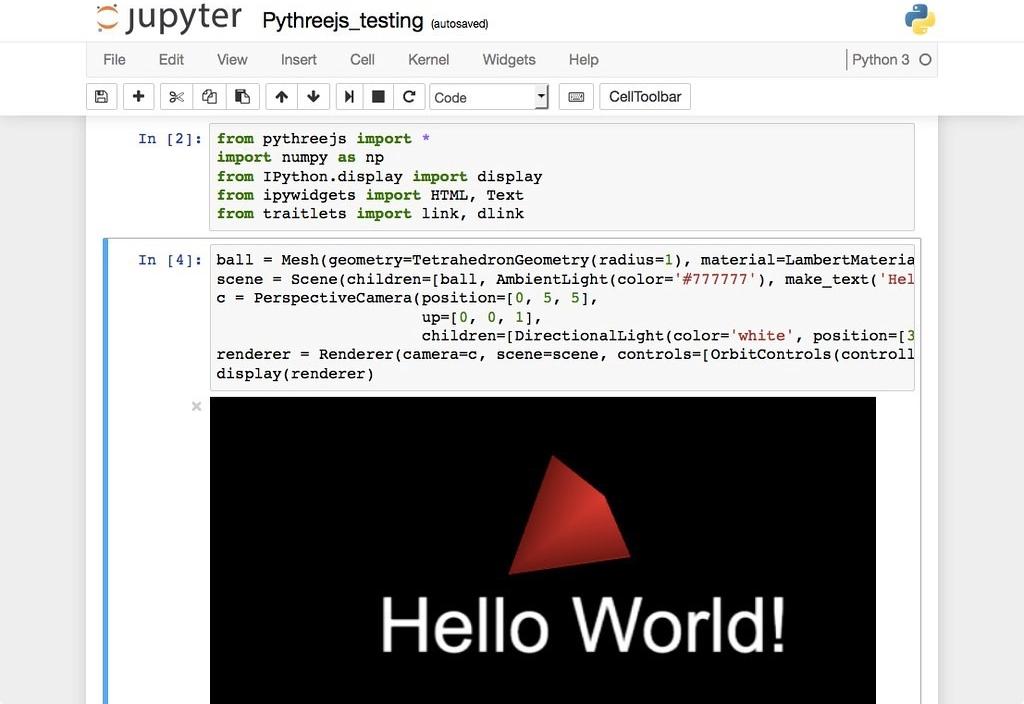
Этот материал предназначен для новичков, которые только знакомятся с Jupyter Notebook, и охватывает все этапы работы с ним: установку, азы использования и процесс создания интерактивного проекта Data Science.
Настройка Jupyter Notebook
Чтобы начать работать с Jupyter Notebook, библиотеку Jupyter необходимо установить для Python. Проще всего это сделать с помощью pip:
Лучше использовать pip3 , потому что pip2 работает с Python 2, поддержка которого прекратится уже 1 января 2020 года.
Теперь нужно разобраться с тем, как пользоваться библиотекой. С помощью команды cd в командной строке (в Linux и Mac) в первую очередь нужно переместиться в папку, в которой вы планируете работать. Затем запустите Jupyter с помощью следующей команды:

Отлично. Сервер Jupyter работает. Теперь пришло время создать первый notebook и заполнять его кодом.
Основы Jupyter Notebook
Для создания notebook выберите «New» в верхнем меню, а потом «Python 3». Теперь страница в браузере будет выглядеть вот так:

Обратите внимание на то, что в верхней части страницы, рядом с логотипом Jupyter, есть надпись Untitled — это название notebook. Его лучше поменять на что-то более понятное. Просто наведите мышью и кликните по тексту. Теперь можно выбрать новое название. Например, George's Notebook .
Теперь напишем какой-нибудь код!
Перед первой строкой написано In [] . Это ключевое слово значит, что дальше будет ввод. Попробуйте написать простое выражение вывода. Не забывайте, что нужно пользоваться синтаксисом Python 3. После этого нажмите «Run».

Вывод должен отобразиться прямо в notebook. Это и позволяет заниматься программированием в интерактивном формате, имея возможность отслеживать вывод каждого шага.
Также обратите внимание на то, что In [] изменилась и вместе нее теперь In [1] . Число в скобках означает порядок, в котором эта ячейка будет запущена. В первой цифра 1 , потому что она была первой запущенной ячейкой. Каждую ячейку можно запускать индивидуально и цифры в скобках будут менять соответственно.
Рассмотрим пример. Настроим 2 ячейки, в каждой из которых будет разное выражение print . Сперва запустим вторую, а потом первую. Можно увидеть, как в результате цифры в скобках меняются.

Если есть несколько ячеек, то между ними можно делиться переменными и импортами. Это позволяет проще разбивать весь код на связанные блоки, не создавая переменную каждый раз. Главное убедиться в запуске ячеек в правильном порядке, чтобы переменные не использовались до того, как были созданы.
Добавление описания к notebook
В Jupyter Notebook есть несколько инструментов, используемых для добавления описания. С их помощью можно не только оставлять комментарии, но также добавлять заголовки, списки и форматировать текст. Это делается с помощью Markdown.
Первым делом нужно поменять тип ячейки. Нажмите на выпадающее меню с текстом «Code» и выберите «Markdown». Это поменяет тип ячейки.
Сделать текст курсивным можно с помощью символов * с двух сторон текста. Если с каждой стороны добавить по два * , то текст станет полужирным. Список создается с помощью тире и пробела для каждого пункта.

Интерактивная наука о данных
Соорудим простой пример проекта Data Science. Этот notebook и код взяты из реального проекта.
Следом идет первая ячейка, в которой происходит импорт библиотек. Это стандартный код для Python Data Science с одним исключение: чтобы прямо видеть визуализации Matplotlib в notebook, нужна следующая строчка: %matplotlib inline .

Следом нужно импортировать набор данных из файла CSV и вывести первые 10 пунктов. Обратите внимание, как Jupyter автоматически показывает вывод функции .head() в виде таблицы. Jupyter отлично работает с библиотекой Pandas!

Теперь нарисуем диаграмму прямо в notebook. Поскольку наверху есть строка %matplotlib inline , при написании plt.show() диаграмма будет выводиться в notebook!
Также обратите внимание на то, как переменные из предыдущих ячеек, содержащие данные из CSV-файла, используются в последующих ячейках в том случае, если по отношению к первым была нажата кнопка «Run».

Это простейший способ создания интерактивного проекта Data Science!
На сервере Jupyter есть несколько меню, с помощью которых от проекта можно получить максимум. С их помощью можно взаимодействовать с notebook, читать документацию популярных библиотек Python и экспортировать проект для последующей демонстрации.
Файл (File): отвечает за создание, копирование, переименование и сохранение notebook в файл. Самый важный пункт в этом разделе — выпадающее меню Download , с помощью которого можно скачать notebook в разных форматах, включая pdf, html и slides для презентаций.
Редактировать (Edit): используется, чтобы вырезать, копировать и вставлять код. Здесь же можно поменять порядок ячеек, что понадобится для демонстрации проекта.
Вид (View): здесь можно настроить способ отображения номеров строк и панель инструментов. Самый примечательный пункт — Cell Toolbar , к каждой ячейке можно добавлять теги, заметки и другие приложения. Можно даже выбрать способ форматирования для ячейки, что потребуется для использования notebook в презентации.
Вставить (Insert): для добавления ячеек перед или после выбранной.
Ячейка (Cell): отсюда можно запускать ячейки в определенном порядке или менять их тип.
Помощь (Help): в этом разделе можно получить доступ к важной документации. Здесь же упоминаются горячие клавиши для ускорения процесса работы. Наконец, тут можно найти ссылки на документацию для самых важных библиотек Python: Numpy, Scipy, Matplotlib и Pandas.
Существует много информации для запуска Jupyter Notebook с Anaconda, но не удалось найти никакой информации для запуска Jupyter без Anaconda.
Любой указатель будет высоко ценится!
3 ответа
В основном процесс выглядит следующим образом:
Запустите определенный блокнот:
Используя собственный IP или порт:
Нет браузера:
Помогите:
Ответ из следующих источников:
См. Gupon Ball 's Jupyter PPA, наиболее активно поддерживаемый Jupyter PPA на момент написания этой статьи с поддержкой Ubuntu 16.04 и 18.04 (LTS).
Установка: это мяч
Благодаря бесстрашным усилиям Гордона, установка Jupyter под Ubuntu упрощается до:
При этом устанавливается jupyter метапакет, обеспечивающий:
- Стандартная коллекция пакетов Jupyter, опубликованная этим PPA, включая:
- Ядро Jupyter и клиентские библиотеки.
- Консольный интерфейс Jupyter.
- Сетевой блокнот Jupyter.
- Инструменты для работы и конвертации файлов ноутбуков (ipynb).
- Вычислительное ядро Python3.
Как W.Dodge pip На основе деталей решения на основе браузера пользовательский интерфейс Jupyter Notebook может затем запускаться из терминала следующим образом - где '/home/my_username/my_notebooks' должен быть заменен абсолютным путем к каталогу верхнего уровня, содержащему все файлы вашего ноутбука Jupyter:
Почему не Аканаконда или Пип?
Для дистрибутивов Linux на основе Debian оптимальным решением является личный архив пакетов на основе Debian (PPA). Все остальные ответы предлагают Debian-независимые решения (например, Anaconda, pip ), которые обходят общесистемный диспетчер пакетов APT и, следовательно, не идеальны.
Установка Jupyter через этот или другой PPA гарантирует автоматическое обновление как Jupyter, так и его совокупности зависимостей. Установка Jupyter через Анаконду или pip требует ручного обновления обоих на постоянной основе - постоянная шип в сторону, без которой вы, вероятно, можете обойтись.
Одним словом, PPA >>>> Анаконда >> pip ,
Читайте также: