
Все виды информации в компьютере кодируются в виде последовательностей
Обновлено: 06.07.2024
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
0. Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение - процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики - базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом - не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня - табличка с надписью, знак на дороге, светофоры, и для современного мира - штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
1.1 Речь, мимика, жесты
Удивительно, но всё это - коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях. Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода - улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости.
Следуя определению, что же происходит когда мы говорим? Мысль - как форма, удобная для непосредственного использования, преобразуется в речь - форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда - человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
1.2 Чередующиеся сигналы

В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы "включено/выключено". Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме "точка-тире", что нам даёт букву "A" может звучать и так - "точка-пауза-тире" и тогда это уже две буквы "ET".

1.3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной - звук, видео, текст. Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук - череда дискретных значений о звуковом сигнале, видео - череда кадров изображений, текст - череда символов текста. Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим - час или даже пара недель.
2. Кодирование текста
От общего описания кодирования перейдём к практической части. Из условностей мы за константу примем то, что будем кодировать данные для персонального компьютера, где за единицу информации приняты - бит и байт. Бит, как атом информации, а байт - как условный блок размером в 8 бит.
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза "ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП".

2.1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
Информация бывает разных видов, таких как запах, вкус, звук; символы и знаки. В различных отраслях науки, техники и культуры применяются особые формы и методики для кодирования и записи информации.
Существует три основных способа кодирования информации:- Числовой способ — с помощью чисел.
- Символьный способ — информация кодируется с помощью символов того же алфавита, что и исходящий текст.
- Графический способ — информация кодируется с помощью рисунков или значков.

Трактовка понятий
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Двоичная методика
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит ;
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
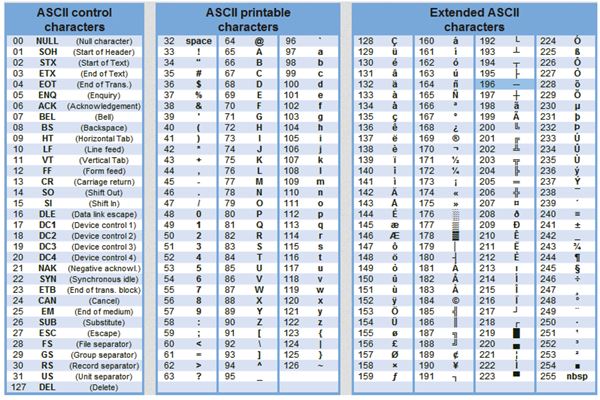
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Растровое изображение
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
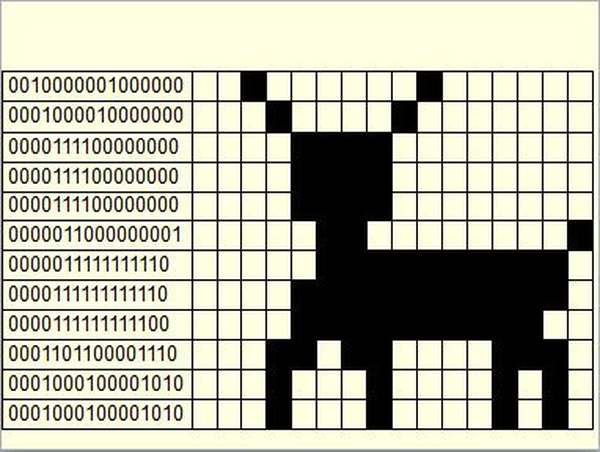
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.
Звуки и их разрядность
Человек воспринимает звуковые волны (колебания воздуха) с помощью слуха в форме звука различных громкости и тона. Чем больше интенсивность звуковой волны, тем громче звук, чем больше частота волны, тем выше тон звука. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука.
В каждом современном компьютере предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность нулей и единиц. Для этого использунтся аудиоадаптер или звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс преобразования выполняется как при вводе звуков в компьютер так и при обратном их преобразовании.
Частота дискретизации- это количество измерений уровня звукового сигнала в единицу времени. Эта характеристика показывает качество и точность процедуры двоичного кодирования. Измеряется в герцах (Гц).
Оцифрованный сигнал в виде набора последовательных значений амплитуды уже можно сохранить в памяти компьютера. В случае, когда записываются абсолютные значения амплитуды, такой формат записи называется PCM ( Pulse Code Modulation). Стандартный аудио компакт-диск (CD-DA), применяющийся с начала 80-х годов 20-го столетия, хранит информацию в формате PCM с частотой дискретизации 44.1 кГц и разрядностью квантования 16 бит.
Подробнее о свойствах звука можно прочитать в статье Звук
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК).
Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Каждая команда содержит элементы, определяющие:
- указание на то, какие действия должен сделать микропроцессор (ответ па этот вопрос дает часть команды, которая называется кодом операции (КОП));
- указание на объекты, над которыми надо провести какие-то действия (эти элементы машинной команды называются операндами);
- указание на способ действия (эти элементы называются типами операндов).
Структура машинной команды состоит из операционной и адресной части. В операционной части содержится код операции. Чем длиннее операционная часть, тем большее количество операций можно в ней закодировать.
В адресной части машинной команды содержится информация об адресах операндов. Это либо значения адресов ячеек памяти, в которых размещаются сами операнды (абсолютная адресация), либо информация, по которой процессор определяет значения их адресов в памяти (относительная адресация). Абсолютная адресация использовалась только в машинах 1 и 2-го поколений. Начиная с машин 3-го поколения, наряду с абсолютной используется относительная адресация.
Подробнее о поколениях компьютеров смотрите в статье История развития компьютеров
Заключение

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобрев в каталоге.
Получите невероятные возможности



Конспект урока "Информация. Кодирование информации"
Этот урок посвящён обобщению материала по теме. Сегодня мы с вами вспомним, что такое информация, как кодируется текстовая, графическая и звуковая информация в компьютере, а также, как представляется числовая информация в компьютере.
Начнём мы с вами с определения информации.
Информация – это сведения о предметах, событиях, явлениях и процессах окружающего мира. Она представляется и передаётся в форме знаков, рисунков, фотографий, схем; в виде световых или звуковых сигналов; в виде жестов и мимики; в виде запахов и вкусовых ощущений.

Информацию можно рассматривать с двух сторон: с точки зрения человека и с точки зрения компьютера.
Мы с вами будем рассматривать информацию с точки зрения компьютера. Для этого необходимо представить информацию в форме, понятной для компьютера, то есть в виде битов и двоичных кодов.
Минимальной единицей измерения информации принято считать 1 бит.
Разберёмся на примере.
Вычислить, какой объём информации будет занимать книга в электронном варианте, если известно, что книга содержит 16 страниц. На каждой странице – 16 строк, а в каждой строке – по 24 символа вместе с пробелами. 1 символ = 1 байту.
Для подсчёта объёма информации нам необходимо узнать количество символов в книге. Для этого умножаем количество страниц (16), на количество строк на каждой странице (также на 16), и на количество символов в каждой строке вместе с пробелами, то есть на 24.
16 · 16 · 24 = 6144 (символа).
Также мы с вами знаем, что 1 символ = 1 байту. То есть весь учебник в электронном варианте будет занимать объём, равный 6144 байтам.
6144 : 1024 = 6 (Кбайт).
А сейчас давайте вспомним единицы измерения информации:
1 Кбайт (килобайт) = 1024 байта = 2 10 байт;
1 Мбайт (мегабайт) = 1024 Кбайта = 2 20 байт;
1 Гбайт (гигабайт) = 1024 Мбайта = 2 30 байт;
1 Тбайт (терабайт) = 1024 Гбайта = 2 40 байт;
1 Пбайт (петабайт) = 1024 Тбайта = 2 50 байт;
1 Эбайт (эксабайт) = 1024 Пбайта = 2 60 байт;
1 Збайт (зеттабайт) = 1024 Эбайта = 2 70 байт.
Помимо этого, существует такой подход к измерению информации, как вероятностный. При таком подходе объём занимаемой информации при условии, что число благоприятных исходов равно 1, будет вычисляться по следующей формуле:
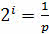
.
Давайте разберёмся на примере.
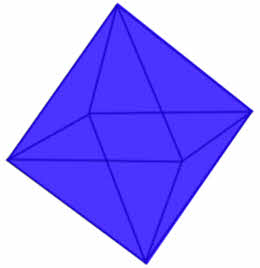
Вероятность события p будет равна:
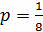
.
Т. к. вероятный благоприятный исход в данном случае может быть только один, а вот общее число исходов будет равно восьми, потому что фигура может упасть на одну из восьми сторон с одинаковой вероятностью.
Так как у нас фигура бросается один раз, то следует использовать следующую формулу:
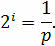
Подставим p в формулу и получим следующее:
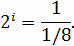
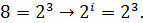
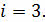
Ещё один подход, который мы с вами рассмотрим, – алфавитный. Он применяется в компьютерных системах хранения и передачи информации. Здесь используется двоичный способ кодирования информации и важен только размер (объём) хранимого и передаваемого кода. Именно поэтому алфавитный подход также называют объёмным.
Разрядность двоичного кода i и количество возможных кодовых комбинаций или мощность алфавита N связаны следующим соотношением:
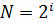
Также необходимо помнить, что 1 бит – это минимальная единица измерения информации.
А сейчас давайте разберёмся на примере. Какой объём будет занимать число F4, которое представлено в шестнадцатеричной системе счисления.
Приступим к решению.
Для начала вспомним, что:
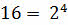
.
Из этого следует, что все символы в этой системе счисления можно закодировать четырёхразрядными двоичными кодами от 0000 до 1111. То есть 1 символ = 4 битам. Соответственно, наше число в шестнадцатеричной системе счисления будет занимать объём:
Если же рассматривать число 71 в восьмеричной системе счисления, то:
1 символ = 3 бита.
Объём информации, которое будет занимать число 71, равно 6 битам.
А сейчас переходим к видам информации, которые воспринимаются компьютером. К ним относятся текстовая, числовая, звуковая, графическая, мультимедийная. Все эти виды информации в компьютере кодируются.
Кодирование – это процесс представления информации в удобной для её хранения и/или передаче форме.
Начнём с рассмотрения текстовой информации в памяти компьютера. Каждая буква алфавита, цифра, знак препинания или любой другой символ, который нужен для записи текста, обозначается двоичным кодом, длина которого является фиксированной. Так, например, в системе кодирования Windows, таблица которого содержит 256 символов, каждый символ заменяется на восьмиразрядное целое положительное двоичное число, которое хранится в 1 байте памяти. Такое число является порядковым номером символа в кодовой таблице.
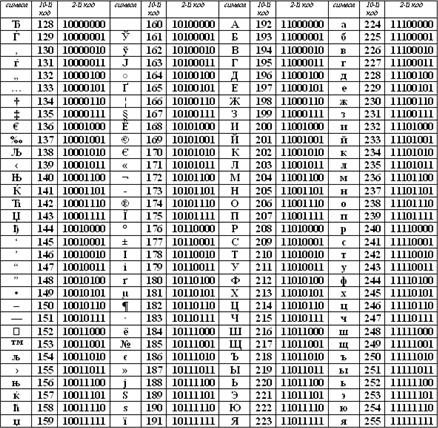
То есть под хранение 1 символа используется 8 бит или 1 байт. Также мы можем заметить, что два в восьмой степени равно двумстам пятидесяти шести.
Но такой кодировки достаточно лишь для одновременного кодирования не более чем 2 языков.
Для одновременной работы с большим количество языков в 1991 году был разработан новый стандарт кодировки символов – Юникод.

В Юникод каждый символ кодируется шестнадцатибитовым двоичным кодом. Это говорит о том, что один символ будет занимать 16 бит или 2 байта. Также следует отметить, что 2 16 = 65 536. И именно такое максимальное количество символов будет содержать таблица Юникод.
Таким образом можно сделать вывод, что в зависимости от разрядности используемой кодировки, информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 бит или 1 байт – при использовании восьмиразрядной кодировки;
• 16 бит или 2 байта – при использовании шестнадцатиразрядной кодировки.
Если же сравнивать таблицы кодировок Windows и Юникод, то можно сделать вывод, что при кодировании текста при помощи таблицы Юникод, его информационный объём будет в 2 раза больше, чем если бы мы кодировали этот же текст при помощи таблицы Windows. Но в то же время не стоит забывать, что при помощи таблицы кодировки Windows мы можем работать одновременно не более чем с 256 различными символами.
А теперь перейдём к кодированию графической информации.
Любое графическое изображение состоит из пикселей. Пиксель – это наименьший элемент изображения, получаемый с помощью компьютерного монитора или принтера. Для того, чтобы увидеть пиксель на изображении, нужно его увеличить.

А сейчас разберёмся непосредственно с кодированием графической информации.
Начнём с чёрно-белых изображений.

Каждый пиксель может иметь одно из двух состояний: чёрный или белый цвет. Для кодирования этой информации требуется 1 бит. Так, например, для кодирования чёрно-белого изображения, размер которого составляет 4 х 8 пикселей, нам понадобиться 32 бита или же 4 байта.
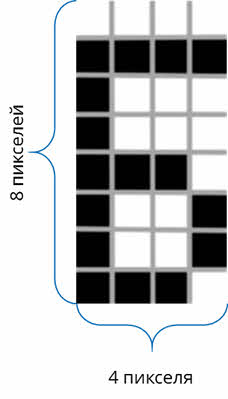
Современные компьютеры имеют просто огромные палитры цветов. Само же количество цветов в таких палитрах зависит от того, сколько двоичных разрядов отводится для кодирования цвета пикселя.
Если размер кода цвета равен b битов, то количество цветов (размер палитры) K вычисляется по формуле:
K = 2 b .
Величину b в компьютерной графике называют битовой глубиной цвета.
Глубина цвета – это величина, обозначающая то, какое количество цветов или оттенков передаёт изображение.
В настоящее время наиболее распространены значения глубины цвета 8, 16 и 24 бита.
Разберёмся на примере. Нам дано изображение размером 16 х 16 при глубине цвета в 8 бит. Найти количество цветов в палитре и объём памяти, который будет занимать изображение.
Количество цветов в палитре находится по формуле:
Для нахождения же объёма памяти, который будет занимать изображение, необходимо перемножить размеры изображения и всё это умножить на глубину цвета.
16 · 16 · 8 = 2048 (бит).
2048 : 8 = 256 (байт).
Переходим к кодированию звука в компьютере.
Для того, чтобы кодировать звуковую информацию, нужно её записать.
С помощью микрофона происходит запись звука в память компьютера, то есть преобразование непрерывных звуковых сигналов в непрерывный электрический сигнал. Но компьютер может работать только с цифровой информацией, поэтому для работы со звуком в компьютере необходимо его дискетизировать. Дискретизация – это процесс обработки информации при помощи звуковой карты или аудиоадаптера, в результате которой непрерывная информация преобразуется в прерывистую, состоящую из отдельных частей, последовательность нулей и единиц.
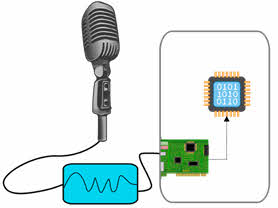
Звуковая карта – это устройство для записи и воспроизведения звука на компьютере.
То есть задача звуковой карты – с определённой частотой производить измерения уровня звукового сигнала и результаты измерения записывать в память компьютера. Этот процесс называют оцифровкой звука.
Количество измерений может лежать в диапазоне от 8000 (частота радиотрансляции) до 48 000 Гц (качество звучания аудио-CD).
То есть чем больше частота дискретизации, тем качественнее звук.
Промежуток времени между двумя измерениями называется периодом измерений – обозначается буквой t и измеряется в секундах.
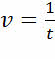
.
Таким образом на качество преобразования звука влияет несколько условий:
· частота дискретизации, то есть сколько раз в секунду будет измерен исходный сигнал;
· разрядность дискретизации – количество битов, выделяемых для записи каждого результата измерений.
При воспроизведении звукового файла цифровые данные преобразуются в электрический аналог звука. К звуковой карте подключаются наушники или звуковые колонки. С их помощью электрические колебания преобразуются в механические звуковые волны, которые воспринимают наши уши.
Таким образом, чем больше разрядность и частота дискретизации, тем точнее представляется звук в цифровой форме и тем больше размер файла, хранящего его.
Разберёмся на примере.
Определить качество звука (качество радиотрансляции или аудио-CD), если известно, что объём моноаудиофайла длительностью звучания в 10 секунд, равен 940 Кбайт. Разрядность аудиоадаптера равна 16 бит.
Рассмотрим решение. Для начала переведём 940 Кбайт в биты.
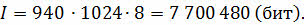
Мы знаем, что для того, чтобы найти размер цифрового аудиофайла, нужно время звучания или записи звука умножить на частоту дискретизации и умножить на разрядность регистра.
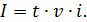
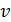
Отсюда мы можем найти . Для этого нужно размер аудиофайла разделить на произведение времени звучания и разрядности аудиоадаптера.
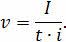
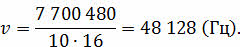
Мы получили частоту дискретизации, близкую к самой высокой. Запишем ответ: качество аудио-CD.
Нам осталось рассмотреть представление числовой информации в компьютере.
Числовая информация в компьютере может представляться в различных системах счисления. Основная же система счисления, в которой представляется информация в компьютере, – двоичная.
При выполнении каких-либо арифметических действий над числами, которые представлены в различных системах счисления, нужно перевести их в одну, например, в десятичную, а затем, после выполнения всех арифметических действий, перевести десятичное число в ту систему счисления, которая требуется по условию задания.
Для перевода числа, которое представлено в системе счисления с основанием q, в десятичную систему счисления, нужно:
1) перейти к его развёрнутой записи;
2) заменить буквы на соответствующие им числа в десятичной системе счисления, если таковые имеются;
3) вычислить значение получившегося выражения.
Для того, чтобы перевести целое десятичное число в систему счисления с основанием q, нужно:
1) последовательно выполнять деление данного числа и получаемых целых частных на основание новой системы счисления до тех пор, пока не получим частное, равное нулю;
2) полученные остатки, которые являются цифрами числа в новой системе счисления, привести в соответствии с алфавитом новой системы счисления.
3) составить число в новой системе счисления, записывая его справа налево, начиная с последнего полученного остатка.
Пришла пора подвести итоги урока. Сегодня мы с вами вспомнили, что такое информация, как кодируется текстовая, графическая и звуковая информация в компьютере, а также, как представляется числовая информация в компьютере.
Вопрос представления и кодирования информации в компьютере является очень важным вопросом компьютерной грамотности.

В статье «Пять поколений ЭВМ» перечисляется элементная база компьютеров разных поколений: электронные лампы, транзисторы, микросхемы. До сих пор ничего принципиально нового не появилось.
Перечисленные элементы четко распознают только два состояния: включено или выключено, есть сигнал или нет сигнала. Для того чтобы закодировать эти два состояния, достаточно двух цифр: 0 (нет сигнала) и 1 (есть сигнал).
Таким образом, с помощью комбинации 0 и 1 компьютер (с первого поколения и по сей день) способен воспринимать любую информацию: тексты, формулы, звуки и графику.
Иными словами, компьютеры обычно работают в двоичной системе счисления, состоящей из двух цифр 0 и 1. Все необходимые преобразования (в привычную для нас форму или, наоборот, в двоичную систему счисления) могут выполнить программы, работающие на компьютере.
Что такое бит и что такое байт
Байт (англ. byte) – число из восьми бит (различные комбинации из восьми нулей и единиц). Байт является единицей измерения информации.
Последовательностью битов можно закодировать текст, изображение, звук или какую-либо другую информацию. Такой метод представления информации называется двоичным кодированием (binary encoding).
О представлении информации в компьютере
Чтобы перевести в цифровую форму музыкальный звук, можно применить такое устройство, как аналого-цифровой преобразователь. Он из входного звукового (аналогового) сигнала на выходе дает последовательность байтов (цифровой сигнал).
Обратный перевод можно сделать с помощью другого устройства – цифро-аналогового преобразователя, и таким образом воспроизвести записанную музыку.
На самом деле роль преобразователей (аналого-цифрового и цифро-аналогового) выполняют специальные компьютерные программы. Поэтому при использовании компьютера надобности в таких устройствах нет.
Сохранить можно не только текстовую и звуковую информацию. В виде кодов хранятся и изображения. Если посмотреть на рисунок с помощью увеличительного стекла, то видно, что он состоит из точек одинаковой величины и разного цвета – это так называемый растр.
Координаты каждой точки можно запомнить в виде числа, цвет точки – это еще одно число для последующего кодирования. Эти числа могут храниться в памяти компьютера и передаваться на любые расстояния. По ним компьютерные программы способны воспроизвести рисунок на экране монитора или напечатать его на принтере. Изображение можно увеличить или уменьшить, сделать темнее или светлее. Его можно повернуть, наклонить, растянуть.
Мы считаем, что на компьютере обрабатывается изображение. Но на самом деле компьютерные программы изменяют числа, которыми отдельные точки изображения представлены (точнее, сохранены) в памяти компьютера.
Таким образом, компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть предварительно преобразована в числовую форму при помощи соответствующих компьютерных программ.
Кодирование информации вокруг нас
Не так уж давно мы пользовались телеграфом (эта услуга остается и по сей день). При этом отправляемый текст кодируется в виде последовательностей так называемых «точек» (коротких сигналов) и «тире» (длинных сигналов), отправляется по проводам. На выходе все это декодируется и печатается на ленте.
Многие люди в недавнем прошлом обязаны были знать эту кодировку, называемую иначе «Азбукой Морзе» по имени ее изобретателя.
В музыке информация много веков кодируется с помощью нотной записи (ноты). Математические формулы используются в математике. В химии применяются химические формулы. Таких примеров кодирования информации можно привести очень много.
По сравнению с приведенными примерами, кодировка, применяемая для компьютеров, выглядит намного проще, так как в ней используются только «нули» и «единицы».
Сравнительная простота кодирования обеспечивает все многообразие представляемой в компьютере информации (от простых текстов до сложнейших графических игр и видеофильмов). Это обусловлено высочайшим быстродействием компьютеров и их способностью к почти мгновенной обработке огромных массивов данных.
Вопрос представления и кодирования информации в компьютере является очень важным вопросом компьютерной грамотности.
В статье «Пять поколений ЭВМ» перечисляется элементная база компьютеров разных поколений: электронные лампы, транзисторы, микросхемы. До сих пор ничего принципиально нового не появилось.
Перечисленные элементы четко распознают только два состояния: включено или выключено, есть сигнал или нет сигнала. Для того чтобы закодировать эти два состояния, достаточно двух цифр: 0 (нет сигнала) и 1 (есть сигнал).
Таким образом, с помощью комбинации 0 и 1 компьютер (с первого поколения и по сей день) способен воспринимать любую информацию: тексты, формулы, звуки и графику.
Иными словами, компьютеры обычно работают в двоичной системе счисления, состоящей из двух цифр 0 и 1. Все необходимые преобразования (в привычную для нас форму или, наоборот, в двоичную систему счисления) могут выполнить программы, работающие на компьютере.
Что такое бит и что такое байт
Байт (англ. byte) – число из восьми бит (различные комбинации из восьми нулей и единиц). Байт является единицей измерения информации.
Последовательностью битов можно закодировать текст, изображение, звук или какую-либо другую информацию. Такой метод представления информации называется двоичным кодированием (binary encoding).
О представлении информации в компьютере
Чтобы перевести в цифровую форму музыкальный звук, можно применить такое устройство, как аналого-цифровой преобразователь. Он из входного звукового (аналогового) сигнала на выходе дает последовательность байтов (цифровой сигнал).
Обратный перевод можно сделать с помощью другого устройства – цифро-аналогового преобразователя, и таким образом воспроизвести записанную музыку.
На самом деле роль преобразователей (аналого-цифрового и цифро-аналогового) выполняют специальные компьютерные программы. Поэтому при использовании компьютера надобности в таких устройствах нет.
Сохранить можно не только текстовую и звуковую информацию. В виде кодов хранятся и изображения. Если посмотреть на рисунок с помощью увеличительного стекла, то видно, что он состоит из точек одинаковой величины и разного цвета – это так называемый растр.
Координаты каждой точки можно запомнить в виде числа, цвет точки – это еще одно число для последующего кодирования. Эти числа могут храниться в памяти компьютера и передаваться на любые расстояния. По ним компьютерные программы способны воспроизвести рисунок на экране монитора или напечатать его на принтере. Изображение можно увеличить или уменьшить, сделать темнее или светлее. Его можно повернуть, наклонить, растянуть.
Мы считаем, что на компьютере обрабатывается изображение. Но на самом деле компьютерные программы изменяют числа, которыми отдельные точки изображения представлены (точнее, сохранены) в памяти компьютера.
Таким образом, компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть предварительно преобразована в числовую форму при помощи соответствующих компьютерных программ.
Кодирование информации вокруг нас
Не так уж давно мы пользовались телеграфом (эта услуга остается и по сей день). При этом отправляемый текст кодируется в виде последовательностей так называемых «точек» (коротких сигналов) и «тире» (длинных сигналов), отправляется по проводам. На выходе все это декодируется и печатается на ленте.
Многие люди в недавнем прошлом обязаны были знать эту кодировку, называемую иначе «Азбукой Морзе» по имени ее изобретателя.
В музыке информация много веков кодируется с помощью нотной записи (ноты). Математические формулы используются в математике. В химии применяются химические формулы. Таких примеров кодирования информации можно привести очень много.
По сравнению с приведенными примерами, кодировка, применяемая для компьютеров, выглядит намного проще, так как в ней используются только «нули» и «единицы».
Сравнительная простота кодирования обеспечивает все многообразие представляемой в компьютере информации (от простых текстов до сложнейших графических игр и видеофильмов). Это обусловлено высочайшим быстродействием компьютеров и их способностью к почти мгновенной обработке огромных массивов данных.
Читайте также: