
Архитектура процессора pentium pro какой способ обработки данных противоречит принципам фон неймана
Обновлено: 07.07.2024
Презентация на тему: " Принципы фон Неймана Логические узлы Системная шина и модули Материнская плата Процессор Выполнение программы Монитор Клавиатура, манипуляторы Принтеры," — Транскрипт:
1 Принципы фон Неймана Логические узлы Системная шина и модули Материнская плата Процессор Выполнение программы Монитор Клавиатура, манипуляторы Принтеры, сканеры Другие устройства
2 1 Архитектура компьютера – это его логическая организация, структура и ресурсы. В основу архитектуры большинства электронных вычислительных машин положены принципы, сформулированные в 1945 г. Джоном фон Нейманом, развившим идеи Чарльза Беббиджа: 1. Принцип программного управления (программа состоит из набора команд, которые выполняются процессором автоматически друг за другом в заданной последовательности). 2. Принцип однородности памяти (программы и данные хранятся в одной и той же памяти; над командами можно выполнять такие же действия, как и над данными). 3. Принцип адресности (основная память структурно состоит из пронумерованных ячеек). ЭВМ, построенные на этих принципах, имеют классическую архитектуру (архитектуру фон Неймана). В истории развития компьютерной техники выделяют несколько поколений. Есть компьютеры с неклассической архитектурой – нейрокомпьютеры. В них моделируется работа нейронов, из которых состоит мозг человека. Джон фон Нейман Чарльз Беббидж Принципы фон Неймана
3 2 Каждый логический узел выполняет свои функции. Функции процессора: обработка данных по заданной программе (выполнение над ними арифметических и логических операций); программное управление работой устройств компьютера. Программа состоит из команд – элементарных операций. Команда содержит код выполняемой операции; адреса операндов; адрес размещения результата. Архитектура определяет принцип работы, информационные связи и взаимодействие основных логических узлов компьютера: процессора; оперативной памяти; внешней памяти; периферийных устройств (устройств ввода/вывода). Логические узлы
4 3 В состав процессора входят регистры (процессорная память). Регистры выполняют две функции: кратковременное хранение числа или команды; выполнение над ними некоторых операций. Важнейшие регистры: счетчик команд (служит для автоматической выборки команд программы из последовательных ячеек памяти, в нем хранится адрес выполняемой команды); регистр команд и состояний (служит для хранения кода команды). Функции памяти: приём информации от других устройств; запоминание информации; передача информации по запросу в другие устройства компьютера. Логические узлы
5 4 счетчик команд регистр команд регистры операндов сумматор Выполнение команды разбивается на следующие этапы: из ячейки памяти выбирается команда (при этом содержимое счётчика команд увеличивается); команда передаётся в устройство управления (в регистр команд); устройство управления процессора расшифровывает адрес команды; по сигналам устройства управления операнды выбираются из памяти в арифметико-логическое устройство; устройство управления расшифровывает код операции и выдаёт сигнал арифметико-логическому устройству выполнить операцию; результат операции остаётся в процессоре, либо возвращается в оперативную память. Оперативная память Программа Процессор Устройство управления Арифметико- логическое устройство Выполнение программы
6 6 В основе компьютеров классической архитектуры лежит магистрально- модульный принцип. Модульность выражается в том, что компьютер, как сборный конструктор, комплектуется из отдельных модулей, представляющих логические узлы компьютера. Магистральность означает, что отдельные модули соединены с процессором общей системной шиной (магистралью), состоящей из шины данных, шины адреса и шины управления. Системная шина предназначена для обеспечения передачи данных между периферийными устройствами, центральным процессором, оперативной памятью. Физически шина может представлять собой набор проводящих линий, вытравленных на печатной плате, провода припаянные к выводам разъемов (слотов), в которые вставляются печатные платы, либо плоский кабель. Компоненты компьютерной системы физически расположены на одной или нескольких печатных платах, причем их число и функции зависят от конфигурации системы, её изготовителя, а часто и от поколения микропроцессора. Основные характеристики шин : разрядность передаваемых данных (количество одновременно передаваемых бит); скорость передачи данных. Системная шина и модули
7 7 Компьютер в настольном исполнении Компьютер в компактном исполнении (notebook) В системном блоке находятся основные логические узлы компьютера: материнская плата; электронные схемы (процессор, контроллеры устройств и т.д.); блок питания; дисководы (накопители). Компьютер карманный Системная шина и модули
8 К системному блоку некоторые модули подключаются через соответствующие разъемы на задней панели: – питание; – клавиатура; – мышь; – принтер, Flash-память, внешний HDD, web-камера и цифровая видеокамера, цифровой фотоаппарат, диктофон и др. устройства; – сетевой кабель для выхода в Интернет; – колонки, наушники, микрофон (к встроенной звуковой карте и дополнительной звуковой карте), – монитор. Системная шина и модули
9 USB-порты и разъемы для подключения устройств к звуковой карте могут быть выведены на переднюю или боковую панель системного блока: – подключение принтера, Flash-памяти, внешнего HDD, Web-камеры и видео камеры, цифрового фотоаппарата, диктофона и др. устройств – подключение колонок, наушников, микрофона (к звуковой карте) Системная шина и модули
10 10 Подключение основных устройств к системному блоку. Системная шина и модули
11 – разъемы для оперативной памяти (RAM) – процессор – разъем для блока питания – разъем для видеокарты – разъем для звуковой карты – разъем дисковода для гибких дисков – разъемы дисководов компакт-диска и жесткого диска (винчестера) Материнская плата
12 Логическая схема материнской (системной) платы 12 Материнская плата Процессор (CPU) Северный Мост- контроллер оперативной памяти Южный Мост- контроллер периферийных устройств AGP (Accelerated Graphic Port) Звуковая карта, Сетевая карта, Модем (внутренний) Монитор Шина памяти Память (RAM) Системная шина (FSB) Hub Interface COM USBPCI UDMA Жесткие диски, CD-ROM, DVD-ROM Сканер, Принтер, Web-камера, Цифровая камера, и фотоаппарат Внешний HDD LPT PS/2 Мышь Клавиатура Модем (внешний) КлавиатураПринтер
13 Материнская (системная, главная) плата является центральной частью любого компьютера, на которой размещаются центральный процессор, контроллеры, обеспечивающие связь центрального процессора с периферийными устройствами, оперативная память, кэш- память (сверх-быстрая память), элемент постоянной памяти BIOS (базовой системы ввода/вывода), аккумуляторная батарея, кварцевый генератор тактовой частоты и слоты (разъемы) для подключения других устройств. Такт – промежуток времени между двумя импульсами генератора тактовой частоты (специальной микросхемы, которая синхронизирует работу логических узлов компьютера). На выполнение элементарных операций нужно определенное количество тактов. Тактовая частота – количество таких тактов в секунду (измеряется в МГц, ГГц). Общая производительность материнской платы определяется не только тактовой частотой, но и количеством (разрядностью) данных, обрабатываемых в единицу времени центральным процессором, а также разрядностью шины обмена данных между различными устройствами материнской платы. 13 Материнская плата ASUS K8S-MX Материнская плата AsRock K8U Материнская плата
15 Пример технических характеристик материнской платы 15
16 16 Процессор (CPU) – центральное процессорное устройство, обладающее способностью выбирать, декодировать и выполнять команды а также передавать и принимать информацию от других устройств. Проще говоря, процессор – это электронная схема, выполняющая обработку информации. Производство современных персональных компьютеров началось тогда, когда процессор был выполнен в виде отдельной микросхемы. Количество фирм, разрабатывающих и производящих процессоры для IBM-совместимых компьютеров, невелико. В настоящее время известны: Intel, Cyrix, AMD и т.д. Кроме процессоров, которые составляют основу IBM-совместимых персональных компьютеров, существует целый класс процессоров, составляющих параллельную платформу (среди самых известных – персональные компьютеры американской фирмы Apple, для которых используются процессоры типа Power PC, имеющие принципиально другую архитектуру, выпускаемые фирмой Motorola и др.). Процессоры AMD Процессор
17 Производительность CPU характеризуется следующими основными параметрами: степенью интеграции; внутренней и внешней разрядностью; тактовой частотой; памятью, к которой может адресоваться CPU. Степень интеграции микросхемы показывает, сколько транзисторов (самый простой элемент любой микросхемы) может поместиться на единице площади. Для процессора Pentium Intel эта величина составляет приблизительно 3 млн. на 3,5 кв.см, у Pentium Pro – 5 млн. Тактовая частота указывает, сколько элементарных операций (тактов) микропроцессор выполняет за одну секунду (измеряется в МГц). Тактовая частота определяет быстродействие процессора. Для процессора различают внутреннюю (собственную) тактовую частоту процессора (с таким быстродействием могут выполняться внутренние простейшие операции) и внешнюю (определяет скорость передачи данных по внешней шине). Количество адресов ОЗУ, доступное процессору, определяется разрядностью адресной шины. 17 Процессоры intel pentium 4 Процессор
18 Внутренняя разрядность процессора определяет, какое количество битов он может обрабатывать одновременно при выполнении арифметических операций (в зависимости от поколения процессоров – от 8 до 32 битов). Внешняя разрядность процессора определяет сколько битов одновременно он может принимать или передавать во внешние устройства (от 16 до 64 и более в современных процессорах). С бурным развитием мультимедиа-приложений перед разработчиками процессоров возникли проблемы увеличения скорости обработки огромных массивов данных, содержащих графическую, звуковую или видео информацию. В результате возникли дополнительно устанавливаемые специальные процессоры DSP, а затем появились разработанные на базе процессоров Pentium так называемые MMX-процессоры (первый из них – Pentium P55C). Пример технических характеристик процессора и устройства для его охлаждения (кулера) на следующих слайдах. 18 Процессор Cyrix Процессор
19 19 Пример технических характеристик процессора
20 20 Пример технических характеристик вентилятора
21 Клавиатура (Keyboard) является основным устройством ввода информации в компьютер. Клавиатура преобразует механическое нажатие клавиши в так называемый скэн-код, который передается в контроллер клавиатуры на материнской плате. Контроллер в свою очередь инициализирует аппаратное прерывание, которое обслуживается специальной программой, входящей в состав ROM- BIOS. При поступлении скэн-кода от клавиш сдвига ( / ) или переключателя (, ) изменение статуса клавиатуры записывается в оперативную память. Для того чтобы на экране монитора отображался символ, набранный с помощью клавиатуры, необходим драйвер клавиатуры, который обычно является составной частью любой операционной системы. Во всех остальных случаях скэн-код трансформируется в ASCII- коды или расширенные коды, которые уже обрабатываются прикладной программой. По конструктивному исполнению различают следующие виды клавиатуры: клавиатуры с пластмассовыми штырями, клавиатуры со щелчком, клавиатуры на микропереключателях или герконах, сенсорные клавиатуры. Клавиатуры различаются также количеством и расположением клавиш. В настоящее время существуют и такие виды клавиатур: эргономические клавиатуры, промышленные, со считывающим устройством штрихового кода, для слепых, инфракрасные (беспроводные) и т.п. 32 Эргономическая клавиатура Обычные клавиатуры Клавиатура
22 33 Пример технических характеристик клавиатуры Клавиатура
23 34 Мышь A4 BW-35 optical (800dpi) Мышь A4 BW-5 optical (800dpi) Руль Logitech Джойстики Мышь, трекбол, руль, джойстик – устройства управления объектами на экране монитора. Вращение шарика преобразуется в электрические сигналы, которые по кабелю передаются в компьютер. В некоторых мышках есть оптический датчик, с помощью которого регистрируются перемещения устройства относительно нарисованной координатной сетки. Оптические мышки постепенно вытесняют мышки с шариком. Трекбол Logitech Манипуляторы
24 35 Мышь можно подключать к портам COM или PS/2, или USB. Для подключения к любому из этих портов есть специальные переходники Манипуляторы Подключение мыши через переходник.
25 36 Манипуляторы Пример технических характеристик мыши
26 Монитор – основное устройство отображения информации, которая хранится в памяти видеокарты. Основные типы мониторов: на основе электронно-лучевой трубки, которая управляется сигналами, поступающими от видеокарты. Принцип работы электронно-лучевой трубки монитора такой же, как у телевизионной трубки: изображение на экране создается пучком электронов, испускаемых электронной пушкой. Этот пучок падает на внутреннюю поверхность экрана, покрытого люминофором и вызывает его свечение. жидкокристаллические (LSD – Liquid Crystal Display). Экран такого монитора состоит из двух стеклянных пластин, между которыми находится масса, содержащая жидкие кристаллы. Принцип работы основан на том, что молекулы жидких кристаллов под воздействием электрического поля меняют свою ориентацию и изменяют свойства проходящего через них светового луча. При выборе мониторов следует обращать особое внимание на его характеристики, т.к. низкое качество мониторов может негативно сказаться на зрении. 37 LG Монитор 17 Монитор
27 38 Пример технических характеристик мониторов Монитор
28 Принтер – устройство для вывода на бумагу текстов и графических изображений. Типы принтеров: матричные принтеры (дешёвые, качество печати невысокое, скорость печати 1 страница/мин., не цветные); струйные принтеры (средние цены, качество печати высокое, скорость печати около 10 страниц/мин., цветные и монохромные), заправляются картриджами с жидкими чернилами; лазерные принтеры (высокие цены, качество печати высокое, скорость печати 4–15 страниц/мин., цветные и монохромные), заправляются картриджами с красящим порошком. 39 Графопостроитель (плоттер) – устройство для вывода на бумагу чертежей, плакатов. Обычный плоттер использует листы форматом А1. Скорость печати примерно 4 лист/час. Лазерные принтеры Струйные принтеры картридж Плоттер Принтеры
29 40 Пример технических характеристик принтеров Принтеры
30 Сканер – это устройство ввода цветного и черно-белого изображения с бумаги, пленки и т.п. Сканер последовательно преобразует оптический сигнал, получаемый при сканировании изображения световым лучом, в электрический, а затем в цифровой код.. Размеры сканируемых изображений зависят от размера сканера и могут достигать размеров большого чертежного листа (А0). Специальная слайд-приставка позволяет сканировать слайды и негативные пленки. 41 Сканер HP ScanJet 2400Сканер Epson Perfection 1270 Сканер BENQ 5250C Сканер Mustek Bear Paw 2400 CU Сканеры
31 42 Пример технических характеристик сканеров Сканеры
32 Цифровые фото- и видеокамеры подключаются к компьютеру через USB-порт, что позволяет считывать с них фото и видеоизображения для просмотра и сохранения на жестком диске компьютера или на СD и DVD дисках. 51 Видеокамера Canon MV-830i Видеокамера Sony DCR-HC19E. Фотокамера Creative Другие устройства
33 52 Цифровой диктофон Также подключается к компьютеру через USB- порт, что позволяет считывать с него звуковые файлы и с помощью специальной, прилагающейся к нему программы, прослушивать их на компьютере и сохранять в разных звуковых форматах. Цифровой диктофон SamsungПодключение к системному блоку Другие устройства
34 53 Мобильный телефон может подключается к компьютеру через инфракрасный порт, что позволяет считывать с него файлы и сохранять на разных устройствах памяти компьютера. Мобильный телефон с инфракрасным портом Подключение к системному блоку Инфракрасный порт компьютера Другие устройства
35 Мультимедийный проектор подключается к компьютеру также, как подключается монитор. Современные проекторы позволяют проецировать на большой экран изображение и даже с коротких расстояний получать изображение с диагональю до 12 м. С помощью новой функции ручной корректировки цвета стены можно адаптировать цветовые характеристики изображения к цвету поверхности экрана. Поэтому в школах изображение можно проецировать прямо на зеленую классную доску, как если бы это была белая стена. 54 Проектор BenQ PB2250 Проектор Acer PD100 Проектор NEC LT245 Другие устройства
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Прерывания
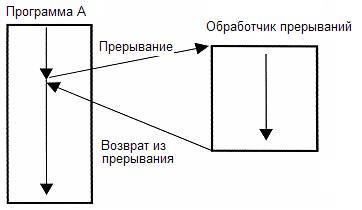
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно
1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Конвейер ЦП 80486. Какой блок и почему был добавлен в конвейер ЦП 80486?
Конвейерная организация процессора означает, что многие сложные действия разбиваются на этапы с небольшим временем выполнения. Каждый этап выполняется в отдельном устройстве (блоке).
Конвейеризация позволяет нескольким внутренним блокам МП работать одновременно, совмещая дешифрование команды, операции АЛУ, вычисление эффективного адреса и циклы шины нескольких команд.
В составе МП 80286 есть 4 конвейерных устройства:
BU (Bus Unit) – шинный блок (считывание из памяти и портов ввода/вывода);
IU (Instruction Unit) – командный блок (дешифрация команд);
EU (Executive Unit) – исполнительный блок (выполнение команд);
AU (Address Unit) – адресный блок (вычисляет все адреса, формирует физический адрес).
Конвейеризация команд в МП 80286
Считывание 0 команды
Считывание 1 команды
Считывание 2 команды
Считыва-ние 3 команды
Дешифрация -1 команды
Дешифрация 0 команды
Дешифрация 1 команды
Дешиф-рация 2 команды
Исполнение - 2 команды
Исполнение - 1 команды
Исполнение 0 команды
Исполне-ние 1 команды
Адрес 1 команды
Адрес 2 команды
Адрес 3 команды
Адрес 4 команды
В ЦП 80486 – пятиступенчатый конвейер для обработки данных:
предвыборка команд (PF –Perfect);
декодирование команды (D1 – Instruction Decode);
формирование адреса (D2 – Address Generate);
выполнение команды в АЛУ и доступ к кэш-памяти (EX – Execute);
обратная запись (WB – Write Back).
Можно выделить два наиболее важных проявления конвейерной организации процессора:
прохождение инструкции (операции) от момента считывания из кэша инструкций до полного завершения (отставки),
прохождение операции через функциональное устройство.
Первое проявление обычно называют «конвейером процессора» либо «конвейером непредсказанного перехода» (что более правильно). Длина этого конвейера влияет на производительность только в случае неправильного предсказания перехода в программе, когда происходит отмена работы, выполненной во всех этапах, начиная с этого перехода (сброс конвейера).
Длина конвейера функционального устройства, в свою очередь, определяет время ожидания результатов операции другой операцией, использующей эти результаты в качестве операндов.
Такое старт-стопное время выполнения операции в функциональном устройстве называют латентностью.
Обращение к кэшам всех уровней и к оперативной памяти также производится конвейерным образом. Большинство простых операций целочисленной арифметики и логики имеют латентность, равную единице — то есть они выполняются в функциональных устройствах синхронно, без конвейеризации.
Базовая архитектура процессоров семейства Pentium.
Новая микроархитектура процессоров Pentium (рис. 5.1) и более поздних базируется на идее суперскалярной обработки. Под суперскалярностью подразумевается наличие более одного конвейера для обработки команд (в отличие от скалярной - одноконвейерной архитектуры). В МП Pentium команды распределяются по двум независимым исполнительным конвейерам (U и V).
Конвейер U может выполнять любые команды семейства IA-32, включая целочисленные команды и команды с плавающей точкой.
Конвейер V предназначен для выполнения простых целочисленных команд и некоторых команд с плавающей точкой.
Команды могут направляться в каждое из этих устройств одновременно, причем при выдаче устройством управления в одном такте пары команд более сложная команда поступает в конвейер U, а менее сложная - в конвейер V (табл. 5.2).
Однако, такая попарная обработка команд (спаривание) возможна только для ограниченного подмножества целочисленных команд. Команды вещественной арифметики не могут запускаться в паре с целочисленными командами. Одновременная выдача двух команд возможна только при отсутствии зависимостей по регистрам.
Таблица 5.2. Конвейеризация команд в МП Pentium
Основные отличия ЦП Pentium
Увеличен размер страничной памяти. Механизм страничной организации памяти позволяет работать одновременно со страницей 4 Мбайт.
Конвейеризация машинного цикла.
Контроль четности адреса и данных.
Раздельные блоки кэш-памяти для данных и кода.
Блок прогнозирования ветвлений.
Средства управления питанием (снижение мощности потребления).
Суперскалярная архитектура. Спаренные команды.
Суперскалярная архитектура – это способ построения процессора с двумя или более конвейерами, позволяющий выполнять параллельно 2 или более выбранные команды.
U – конвейер основной (команды целочисленные и с плавающей точкой).
V – конвейер (команды, которые выполняются за один такт).
Спаривание – это процесс параллельного выполнения 2-х команд, независящих по данным или ресурсам.
Термин «динамическое исполнение программы».
Термин динамическое исполнение программы определил 3 способа обработки данных :
Глубокое предсказание ветвлений (с вероятностью > 90% можно предсказать 10 - 15 ближайших переходов).
Анализ потока данных (на 20-30 шагов вперед посмотреть программу и определить зависимость команд по данным или ресурсам).
Опережающее (внеочередное) исполнение команд.
В чем состоит внутренняя RISC-архитектура ЦП Pentium Pro?
Внутренняя организация МП Pentium Pro соответствует архитектуре RISC , поэтому блок выборки команд, считав поток инструкций IA-32 из L1 кэша инструкций, декодирует их в серию микроопераций.
Блок исполнительных устройств способен выбирать инструкции из пула в любом порядке.
Блок удаления подтверждает выполнение инструкций (до трех микроопераций за такт) в порядке их следования в программе, принимая во внимание прерывания, исключения, точки останова и промахи предсказания переходов.
В работе какого процессора наблюдается отклонение от принципов фон Неймана? В чем это проявляется?
Двойная независимая шина: определение, преимущества использования.
Двойная независимая шина (300-разрядная) - 2 независимых канала передачи данных:
для связи ЦП с кэш II уровня;
для связи ЦП с оперативной памятью.
В процессоре Pentium II впервые реализована высокопроизводительная архитектура двойной независимой шины (системная шина и шина кэш), обеспечивающая повышение пропускной способности и производительности, а также масштабируемость при использовании будущих технологий.
В Pentium II реализована двойная независимая шина , содержащая отдельную шину для обращения к кэш-памяти 2-го уровня (выполняется с тактовой частотой процессора) и системную шину для обращения к памяти и внешним устройствам (выполняется с тактовой частотой системной платы).
Особенности архитектуры Net-Burst.
Для достижения высшей производительности в Pentium 4 использовали 2 подхода :
совершенствование микроархитектуры процессора,
увеличение тактовой частоты.
Микроархитектура процессора Pentium 4 получила название NetBurst.
Основной задачей архитектуры NetBurst было обеспечение возможности дальнейшего роста тактовой частоты.
Изменение последовательности выполнения команд .
Буфер предсказания переходов – 4Кб (вероятность удачного предсказания 93-94%).
Окно команд (можно выбирать 126 команд для внеочередного выполнения).
Трассирующий КЭШ – команд I уровня находится после дешифратора и содержит микрокоманды готовые к исполнению (объем кэша - 12000 микрокоманд).
АЛУ работает на удвоенной частоте ЦП .
Применена Quad-pumped 400 МГц системная шина, обеспечивающая пропускную способность 3,2 Гбайта/с.
Кэш L2 – 256 Кбайт работает на частоте процессора.
В чем состоит отличие кэш-команд ЦП Pentium IV от всех предыдущих?
Иерархия памяти в ПК. Какая память в ПК является самой быстрой? Имеет самую большую емкость?
Сверхоперативные ЗУ (регистры)
Быстродействующее буферное ЗУ (кэш)
Оперативное (основное) ЗУ
Внешние ЗУ (массовая память)
Регистры процессора составляют его контекст и хранят данные, используемые исполняющимися в конкретный момент командами процессора. Обращение к регистрам процессора происходит, как правило, по их мнемоническим обозначениям в командах процессора.
Кэш используется для согласования скорости работы ЦП и основной памяти. В вычислительных системах используют многоуровневый кэш: кэш I уровня (L1), кэш II уровня (L2) и т.д. В настольных системах обычно используется двухуровневый кэш, в серверных - трехуровневый. Кэш хранит команды или данные, которые с большой вероятностью в ближайшее время поступят процессору на обработку. Работа кэш-памяти прозрачна для программного обеспечения, поэтому кэш-память обычно программно недоступна.
Оперативная память хранит, как правило, функционально-законченные программные модули (ядро операционной системы, исполняющиеся программы и их библиотеки, драйверы используемых устройств и т.п.) и их данные, непосредственно участвующие в работе программ, а также используется для сохранения результатов вычислений или иной обработки данных перед пересылкой их во внешнее ЗУ, на устройство вывода данных или коммуникационные интерфейсы.
Каждой ячейке оперативной памяти присвоен уникальный адрес. Организационные методы распределения памяти предоставляют программистам возможность эффективного использования всей компьютерной системы. К таким методам относят сплошную ("плоскую") модель памяти и сегментированную модель памяти. При использовании сплошной модели (flat model) памяти программа оперирует единым непрерывным адресным пространством линейным адресным пространством, в котором ячейки памяти нумеруются последовательно и непрерывно от 0 до 2n-1, где n - разрядность ЦП по адресу. При использовании сегментированной модели (segmented model) для программы память представляется группой независимых адресных блоков, называемых сегментами. Для адресации байта памяти программа должна использовать логический адрес, состоящий из селектора сегмента и смещения. Селектор сегмента выбирает определенный сегмент, а смещение указывает на конкретную ячейку в адресном пространстве выбранного сегмента.
Организационные методы распределения памяти позволяют организовать вычислительную систему, в которой рабочее адресное пространство программы превышает размер фактически имеющейся в системе оперативной памяти, при этом недостаток оперативной памяти заполняется за счет внешней более медленной или более дешевой памяти (винчестер, флэш-память и т.п.) Такую концепцию называют виртуальной памятью. При этом линейное адресное пространство может быть отображено на пространство физических адресов либо непосредственно (линейный адрес есть физический адрес), либо при помощи механизма страничной трансляции. Во втором случае линейное адресное пространство делится на страницы одинакового размера, которые составляют виртуальную память. Страничная трансляция обеспечивает отображение требуемых страниц виртуальной памяти в физическое адресное пространство.
Кроме реализации системы виртуальной памяти внешние ЗУ используются для долговременного хранения программ и данных в виде файлов.
Принцип временной и пространственной локальности программы.
Кэш-память представляет собой быстродействующее ЗУ, размещенное на одном кристалле с ЦП или внешнее по отношению к ЦП. Кэш служит высокоскоростным буфером между ЦП и относительно медленной основной памятью. Идея кэш-памяти основана на прогнозировании наиболее вероятных обращений ЦП к оперативной памяти . В основу такого подхода положен принцип временной и пространственной локальности программы .
Если ЦП обратился к какому-либо объекту оперативной памяти , с высокой долей вероятности ЦП вскоре снова обратится к этому объекту. Примером этой ситуации может быть код или данные в циклах. Эта концепция описывается принципом временной локальности , в соответствии с которым часто используемые объекты оперативной памяти должны быть "ближе" к ЦП (в кэше ).
Способы согласования содержимого кэш-памяти и основной памяти.
Для согласования содержимого кэш-памяти и ОП используют 3 метода записи :
Сквозная – одновременно с кэш-памятью обновляется ОП.
Буферизованная сквозная запись – информация задерживается в кэш-буфере перед записью в ОП и переписывается в ОП в те циклы, когда ЦП к ней не обращается.
Обратная запись – используется бит изменения в поле тега, и строка переписывается в ОП только в том случае, если бит изменения равен 1.
В структуре кэш-памяти выделяют два типа блоков данных:
память отображения данных (сами данные, дублированные из оперативной памяти);
память тегов (признаки, указывающие на расположение кэшированных данных в оперативной памяти).
Пространство памяти отображения данных в кэше разбивается на строки - блоки фиксированной длины (например, 32, 64 или 128 байт). Каждая строка кэша может содержать непрерывный выровненный блок байт из оперативной памяти . Какой именно блок оперативной памяти отображен на данную строку кэша , определяется тегом строки и алгоритмом отображения.
По алгоритмам отображения оперативной памяти в кэш выделяют три типа кэш-памяти:
полностью ассоциативный кэш;
кэш прямого отображения;
множественный ассоциативный кэш.
Кэш прямого отображения :
адрес памяти однозначно определяет строку кэша, в которую будет помещен блок информации.
Полностью ассоциативный кэш:
любой блок ОЗУ может быть отображен на любую строку кэш-памяти, в буфер должен быть записан полный адрес каждого блока и непосредственно сам блок.
Множественный ассоциативный кэш:
В этом типе буфера строки разбиваются на группы, в которые могут входить 2, 4, … строк. В соответствии с их количеством различают двухвходовый и четырехвходовый множественный ассоциативный кэш.
Кэш Гарвардской архитектуры – раздельные кэш-команд и кэш-данных.
Кэш Принстонской архитектуры (Джона фон Неймана) – смешанные кэш-команд и кэш-данных.
Как различаются кэши инструкций по своей организации?
Большинство современных процессоров имеют отдельные кэши 1-го уровня (L1-кэши) для инструкций и данных , и общий кэш 2-го уровня (L2-кэш) увеличенного размера .
Кэши инструкций различаются по своей организации:
В процессорах Intel P-III, P-M, P-M2, P8 и IBM PPC970 в них хранятся исходные машинные инструкции в неизменённом виде .
В процессорах AMD K8 — исходные инструкции вместе с информацией об их разметке ( предекодировании ),
В процессоре Intel P-4 — полностью декодированные микрооперации (МОПы) , организованные в виде трасс.
Основным отличительным признаком является момент времени, когда в кэш следующего уровня переписывается вытесняемый модифицированный блок данных — то есть такой блок, в который с момента загрузки его в кэш произошла запись (и содержимое которого изменилось).
Перечислите и объясните механизмы вытеснения блоков из кэшей.
Запись модифицированных данных в кэш более высокого уровня (L2-кэш) может происходить либо одновременно с их записью в L1-кэш, либо позднее, в момент вытеснения блока из L1-кэша.
На практике встречаются следующие разновидности кэшей:
Writethrough — со сквозной (немедленной) записью модифицированных данных в L2-кэш;
Writeback — с отложенной записью модифицированных данных из L1-кэша в L2-кэш;
Exclusive — эксклюзивный, с отложенной записью из L1-кэша в L2-кэш как модифицированных, так и не модифицированных (чистых) данных.
В процессорах P-4 и PPC970 используется L1-кэш со сквозной записью, в P-III, P-M, P-M2 и P8 — L1-кэш с отложенной записью, а в K8 — эксклюзивный кэш.
Каждый из двух основных механизмов (со сквозной и с отложенной записью) имеет свои преимущества и недостатки. Сквозная запись увеличивает нагрузку на L2-кэш, так как при каждой записи данных в L1-кэш производится их немедленное копирование в L2. С другой стороны, при необходимости освободить место в L1-кэше такой модифицированный блок может быть немедленно удалён из него, так как в L2-кэше уже имеется его копия.
При отложенной записи копирование в L2-кэш производится только в момент вытеснения модифицированного блока — что позволяет избегать лишних пересылок данных, но приводит к усложнению кэшей и необходимости создания очереди для буферизации вытесняемых блоков.
В 1946 году Д. фон Нейман, Г. Голдстайн и А. Беркс в своей совместной статье изложили новые принципы построения и функционирования ЭВМ. В последствие на основе этих принципов производились первые два поколения компьютеров. В более поздних поколениях происходили некоторые изменения, хотя принципы Неймана актуальны и сегодня.
По сути, Нейману удалось обобщить научные разработки и открытия многих других ученых и сформулировать на их основе принципиально новое.
Принципы фон Неймана
- Использование двоичной системы счисления в вычислительных машинах. Преимущество перед десятичной системой счисления заключается в том, что устройства можно делать достаточно простыми, арифметические и логические операции в двоичной системе счисления также выполняются достаточно просто.
- Программное управление ЭВМ. Работа ЭВМ контролируется программой, состоящей из набора команд. Команды выполняются последовательно друг за другом. Созданием машины с хранимой в памяти программой было положено начало тому, что мы сегодня называем программированием.
- Память компьютера используется не только для хранения данных, но и программ. При этом и команды программы и данные кодируются в двоичной системе счисления, т.е. их способ записи одинаков. Поэтому в определенных ситуациях над командами можно выполнять те же действия, что и над данными.
- Ячейки памяти ЭВМ имеют адреса, которые последовательно пронумерованы. В любой момент можно обратиться к любой ячейке памяти по ее адресу. Этот принцип открыл возможность использовать переменные в программировании.
- Возможность условного перехода в процессе выполнения программы. Не смотря на то, что команды выполняются последовательно, в программах можно реализовать возможность перехода к любому участку кода.
Самым главным следствием этих принципов можно назвать то, что теперь программа уже не была постоянной частью машины (как например, у калькулятора). Программу стало возможно легко изменить. А вот аппаратура, конечно же, остается неизменной, и очень простой.
Для сравнения, программа компьютера ENIAC (где не было хранимой в памяти программы) определялась специальными перемычками на панели. Чтобы перепрограммировать машину (установить перемычки по-другому) мог потребоваться далеко не один день. И хотя программы для современных компьютеров могут писаться годы, однако они работают на миллионах компьютеров после несколько минутной установки на жесткий диск.
Как работает машина фон Неймана
Машина фон Неймана состоит из запоминающего устройства (памяти) - ЗУ, арифметико-логического устройства - АЛУ, устройства управления – УУ, а также устройств ввода и вывода.
Программы и данные вводятся в память из устройства ввода через арифметико-логическое устройство. Все команды программы записываются в соседние ячейки памяти, а данные для обработки могут содержаться в произвольных ячейках. У любой программы последняя команда должна быть командой завершения работы.
Команда состоит из указания, какую операцию следует выполнить (из возможных операций на данном «железе») и адресов ячеек памяти, где хранятся данные, над которыми следует выполнить указанную операцию, а также адреса ячейки, куда следует записать результат (если его требуется сохранить в ЗУ).
Арифметико-логическое устройство выполняет указанные командами операции над указанными данными.
Из арифметико-логического устройства результаты выводятся в память или устройство вывода. Принципиальное различие между ЗУ и устройством вывода заключается в том, что в ЗУ данные хранятся в виде, удобном для обработки компьютером, а на устройства вывода (принтер, монитор и др.) поступают так, как удобно человеку.
УУ управляет всеми частями компьютера. От управляющего устройства на другие устройства поступают сигналы «что делать», а от других устройств УУ получает информацию об их состоянии.
Управляющее устройство содержит специальный регистр (ячейку), который называется «счетчик команд». После загрузки программы и данных в память в счетчик команд записывается адрес первой команды программы. УУ считывает из памяти содержимое ячейки памяти, адрес которой находится в счетчике команд, и помещает его в специальное устройство — «Регистр команд». УУ определяет операцию команды, «отмечает» в памяти данные, адреса которых указаны в команде, и контролирует выполнение команды. Операцию выполняет АЛУ или аппаратные средства компьютера.
В результате выполнения любой команды счетчик команд изменяется на единицу и, следовательно, указывает на следующую команду программы. Когда требуется выполнить команду, не следующую по порядку за текущей, а отстоящую от данной на какое-то количество адресов, то специальная команда перехода содержит адрес ячейки, куда требуется передать управление.
Читайте также: