
Что такое блокировка конвейера в процессоре
Обновлено: 07.07.2024
Как уже неоднократно упоминалось, все х86-процессоры, решения компании Motorola и подавляющее большинство выпущенных в 1980-е годы кристаллов имели архитектуру CISC (Complex Instruction Set Computing). Совокупность всех особенностей привела к тому, что чипы стали не только сложными и дорогими в производстве, но и достигли своего потолка производительности. Для дальнейшего увеличения быстродействия требовалось наращивать количество транзисторов, однако освоенные технологические нормы не позволяли создавать более сложные решения. С этим столкнулась Intel при выпуске семейства i486. Для поднятия производительности они внесли изменения в архитектуру процессоров, добавив кэш-память, множители и конвейеры. Словом, 486-е «камни» получили некоторые «фишки» архитектуры RISC. Тем не менее к созданию RISC-платформы американская компания никакого отношения не имеет. Своим созданием архитектура обязана американскому инженеру Дэвиду Паттерсону, который руководил проектом Berkeley RISC с 1980 по 1984 годы.
Дэвид Паттерсон — отец RISC
Первоначальной идеей, которая затем воплотилась в столь масштабный проект Berkeley RISC, стало исследование работы Motorola 68000. В ходе наблюдений выяснилось, что программы попросту не использовали подавляющее большинство инструкций, заложенных в процессор. Например, система Unix при компиляции использовала лишь 30% команд. Поэтому в рамках проекта Berkeley RISC планировалось создать такой процессор, который бы содержал лишь самые необходимые инструкции.
После нескольких лет исследований и разработки было выпущено несколько образцов процессоров, название которых и дало имя всей архитектуры. Сама аббревиатура RISC расшифровывается как Restricted (Reduced) Instruction Set Computer, что переводится как «компьютер с сокращенным набором команд». «Сокращенный набор команд» вовсе не означает, что количество инструкций меньше, чем число команд CISC-кристаллов. Разница состоит в том, что любая инструкция платформы RISC является простой и выполняется за один такт (по крайней мере, должна выполняться), тогда как на выполнение CISC-инструкции могло уходить несколько десятков тактов. При этом длина команды является фиксированной. Например, 32 бита. Также у RISC имеется гораздо больше регистров общего назначения. Плюс для этой архитектуры характерна конвейеризация. Именно ее использование (вкупе с упрощенными командами) позволяет эффективно наращивать тактовую частоту процессоров RISC.
Команда проекта Berkeley RISC
Дебютными решениями стали RISC I и RISC II — детища Паттерсона и проекта Berkeley RISC. Первый содержал более чем 44 000 транзисторов и работал на частоте 4 МГц. Такой процессор при выполнении небольших программ был в среднем в два раза быстрее VAX 11/780 и примерно в четыре раза производительнее, чем «камень» Zilog Z8000. RISC II отличался от предшественника большим количеством инструкций: 39 против 32. Он был более быстрым. Его преимущество над процессором VAX достигало 200%, а Motorola 68000 в некоторых программах был медленнее примерно в четыре раза.
Нужно отметить, что Berkeley RISC был частью большого проекта под названием VLSI. Сюда также входил проект Стэнфордского университета MIPS, который стартовал в 1981 году.
Процессоры MIPS
Главой проекта MIPS был ученый Стэнфордского университета Джон Хэннесси. Как и в случае с Berkeley RISC, задачей стартапа было исследование и создание такого процессора, который использовал бы конвейер и сокращенный набор команд. Архитектура MIPS-решений также предусматривала наличие вспомогательных блоков в составе кристалла: например, модулей для работы с памятью, целочисленного АЛУ (арифметико-логическое устройство) и декодеров команд. Отличием плана MIPS от Berkeley RISC было использование удлиненного конвейера. Архитектура RISC, в принципе, предполагает использование конвейера, но Хэннесси пошел дальше и предложил максимально удлинить конвейер в процессоре, то бишь еще больше «раздробить» выполнение одной операции. Такой подход открывал еще большие просторы по наращиванию тактовой частоты. При этом удлинение конвейера обеспечивало более эффективное распараллеливание выполнения команд. В то время распараллеливание являлось отличительной чертой RISC-архитектуры, поскольку ни в одном CISC-процессоре эта функция не была реализована вплоть до появления в них конвейеров. Например, в MIPS, так же как и в RISC, выполнение одной команды могло быть еще не завершено, когда начиналась выполняться другая. В процессорах CISC для старта выполнения одной инструкции было необходимо, чтобы была окончена обработка другой.
Конвейер команд
Конвейер команд. Конвейеризация — способ обеспечения параллельности выполнения команд
Первым шагом на пути обеспечения параллельности уровня команд явилось создание конвейера команд. Идея конвейера команд была предложена в 1956 году С.А. Лебедевым. Команда подразделяется на несколько этапов, каждый из которых выполняется своей частью аппаратуры, причем, эти части могут работать параллельно. Если на выполнение каждого этапа расходуется одинаковое время (один такт), то на выходе процессора в каждый такт появляется результат очередной команды. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняется несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах. Количество этапов, на которые конструкторы разбивают выполнение процессорной команды, может быть различным (в разных моделях процессоров х86 колеблется от 2 i8088 до 20 Pentium IV).
Конвейеризация — способ обеспечения параллельности выполнения команд
Выполнение типичной команды можно разделить на следующие этапы:
- выборка команды — IF (по адресу, заданному счетчиком команд, из памяти извлекается команда);
- декодирование команды / выборка операндов из регистров — ID;
- выполнение операции / вычисление эффективного адреса памяти — EX;
- обращение к памяти — MEM;
- запоминание результата — WB.
В зависимости от типа команды и способа адресации, время выполнения команды сильно варьируется. Дольше всего выполняются этапы, связанные с обращением к памяти. На рисунках показаны блоки и конвейер команд гипотетического процессора, имеющего пять блоков исполнения команд и соответственно пять этапов (ступеней). Изображены выполняемые команды, номера тактов и этапы выполнения команд. На первом такте считывается первая команда. На втором, пока декодируется первая команда, считывается вторая. На пятом такте в процессоре одновременно находятся пять команд, каждая в своем узле.

Блоки прохождения команды в процессоре
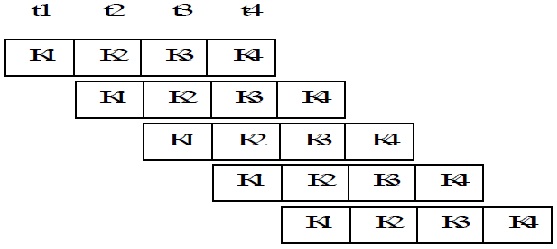
Пятиступенчатая схема конвейера
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. Имеются некоторые накладные расходы на конвейеризацию, возникающие в результате несбалансированности задержки на каждой его ступени. Частота синхронизации (такт синхронизации) не может быть выше, чем время, необходимое для работы наиболее медленной ступени конвейера. Конвейер не всегда представляет собой линейную цепочку этапов. В ряде ситуаций оказывается выгодным, когда функциональные блоки соединены между собой не последовательно, а в соответствии с логикой обработки. Отдельные блоки в цепочке могут пропускаться, а другие — образовывать циклические процедуры. Это позволяет с помощью одного конвейера вычислять более одной функции.
Поток команд — естественная последовательность команд, проходящая по конвейеру процессора. Процессор может поддерживать несколько потоков команд (суперпроцессоры 5 и 6 поколения), если для каждого потока и каждого этапа есть исполнительные элементы.
Суперконвейер команд — разбиение каждой ступени на подступени при одновременном увеличении тактовой частоты внутри конвейера; включение в состав процессора многих конвейеров, работающих с перекрытием. Дробление ступеней позволяет поднять тактовые частоты процессора. К суперконвейерным относятся процессоры, в которых число ступеней больше шести (см. таблицу).
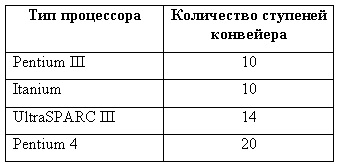
Суперконвейер

Конве́йер — это способ организации вычислений, используемый в современных процессорах и контроллерах с целью ускорения выполнения инструкций (увеличения числа инструкций, выполняемых в единицу времени). Применительно к процессорам, является приемом, используемым при разработке компьютеров и других цифровых электронных устройств для увеличения их инструкционной пропускной способности (количеству инструкций, которые могут быть выполнены за определенный временной промежуток).
Идея заключается в том, чтобы разделить обработку компьютерной инструкции на последовательности независимых шагов, с сохранением результатов в конце каждого шага. Это позволяет управляющим цепям компьютера получать инструкции со скоростью самого медленного шага обработки, но такое решение намного быстрее, чем выполнение всех этих шагов эксклюзивно для каждой инструкции.
Сам термин «конвейер» пришел из промышленности, где используется аналогичный принцип работы — материал автоматически подтягивается по ленте конвейера к рабочему, который осуществляет с ним необходимые действия, следующий за ним рабочий выполняет свои функции над получившейся заготовкой, следующий делает еще что-то, таким образом, к концу конвейера цепочка рабочих полностью выполняет все поставленные задачи, не срывая, однако, темпов производства.
Считается, что впервые конвейерные вычисления были использованы либо в проекте ILLIAC II (англ. en:ILLIAC II ), либо в проекте IBM Stretch (англ. en:IBM Stretch ). Проект IBM Stretch предложил термины «получение» (англ. «Fetch» ), «расшифровка» (англ. «Decode» ) и «выполнение» (англ. «Execute» ), которые затем стали общеупотребляемыми.
Многие современные процессоры управляются таймером. Процессор внутри состоит из логики и памяти (триггеров). Когда приходит сигнал от таймера, триггеры приобретают своё новое значение и логике требуется отрезок времени для декодирования новых значений. Затем приходит следующий сигнал от таймера, триггеры снова принимают новые значения, и так далее. Разбивая логику на более мелкие части и вставляя триггеры между частями логики, время, необходимое логике для правильного вывода, уменьшается. В этом случае, интервал сработки таймера процессора может быть соответственно уменьшен. Например, конвейер RISC-процессоров разбит на 5 шагов, с набором триггеров между шагами:
- получение инструкции (англ.Instruction Fetch );
- раскодирование инструкции (англ.Instruction Decode ) и чтение регистров (англ.Register fetch );
- выполнение(англ.Execute );
- доступ к памяти (англ.Memory access );
- запись в регистр (англ.Register write back );
Когда программист (либо компилятор) пишут ассемблерный код, они делают предположение, что каждая инструкция заканчивает выполняться до того, как начнет выполняться следующая за ней. Использование конвейера делает это предположение неверным. Ситуация, когда использование конвейера заставляет программу работать некорректно, известна как «конфликт конвейера» (англ. en:Hazard (computer architecture) ). Существуют различные техники устранения конфликтов, например, форвардинг (англ. «Forwarding» ) или пробуксовка (англ. «Stalling» ).
Неконвейерная архитектура неэффективна потому, что некоторые компоненты (модули) процессора простаивают, пока какой-то из модулей выполняет свою роль в цикле обработки инструкций. Конвейер не убирает полностью время простоя в процессорах как таковое, но заставляет модули процессора работать параллельно, за счет этого увеличивая общую производительность программ.
Процессоры с конвейером внутри устроены так, что они разделены на «этапы», которые могут полу-независимо работать над разными задачами. Каждый этап связан в «цепочку» с другими таким образом, что результаты работы каждого из этапов «скармливаются» следующему этапу в цепочке до тех пор, пока работа не будет выполнена. Подобная организация процессора позволяет значительно уменьшить время работы.
К сожалению, не все инструкции являются независимыми. В простом конвейере обработка инструкции может потребовать 5-ти этапов обработки. Для работы в полную мощность, этот конвейер должен выполнять 4 последовательные независимые инструкции, пока заканчивается обработка первой. Если же 4-х инструкций, которые не зависят от результата выполнения первой инструкции, нет, управляющая логика должна вставлять в конвейер ничего не делающую заглушку (англ. stall ) до тех пор, пока зависимость не будет разрешена. К счастью, такие техники, как форвардинг, значительно уменьшают количество случаев, где всё же необходимо вставлять заглушки (то есть заставлять процессор пробуксовывать). Хотя конвейеры в теории позволяют увеличить производительность по сравнению с бесконвейерным процессором в количество раз, равное количеству этапов (подразумевая, что частота таймера также масштабируется с количеством этапов), в реальности, большинство кода не позволяет идеального выполнения.
Содержание
Преимущества и недостатки
Конвейер помогает не во всех случаях. Существует несколько возможных минусов. Конвейер инструкций можно назвать "полностью конвейерным", если он может принимать новую инструкцию каждый машинный цикл (англ. en:clock cycle ). Иначе в конвейер должны быть вынужденно вставлены задержки, которые выравняют конвейер, при этом ухудшат его производительность.
Преимущества конвейера:
- Время цикла процессора уменьшается, таким образом увеличивая скорость обработки инструкций в большинстве случаев.
- Некоторые комбинационные логические элементы, такие как сумматоры (англ.adders ) или умножители (англ.multipliers ) могут быть ускорены путем увеличения количества логических элементов. Использование конвейера может предотвратить ненужное наращивание количества элементов.
Недостатки конвейера:
- Беcконвейерный процессор исполняет только одну инструкцию за раз. Это предотвращает задержки веток инструкций (фактически, каждая ветка задерживается), и проблемы, связанные с последовательными инструкциями, которые исполняются параллельно. Следовательно, схема такого процессора проще и он дешевле для изготовления.
- Задержка инструкций в беcконвейерном процессоре слегка ниже, чем в конвейерном эквиваленте. Это происходит из-за того, что в конвейерный процессор должны быть добавлены дополнительные триггеры.
- У беcконвейерного процессора скорость обработки инструкций стабильна. Производительность конвейерного процессора предсказать намного сложнее, и она может значительно различаться в разных программах.
Примеры
Общий конвейер

Справа изображен общий конвейер с четырьмя стадиями работы:
- Получение (англ.Fetch )
- Раскодирование (англ.Decode )
- Выполнение (англ.Execute )
- Запись результата (англ.Write-back )
Верхняя серая область — список инструкций, которые предстоит выполнить. Нижняя серая область — список инструкций, которые уже были выполнены. И средняя белая область является самим конвейером.
Выполнение происходит следующим образом:
Пузырек
Когда в выполнении по каким-либо причинам случается небольшой сбой или задержка, в конвейере получается "пузырек", в котором не происходит ничего полезного. Во втором такте обработка фиолетовой инструкции задерживается и вместо стадии расшифровки в третьем такте теперь находится пузырек. Всё, что находится «за» фиолетовой инструкцией, испытывает задержку в один такт, тогда как все, что находится «перед» фиолетовой инструкцией продолжает исполняться.
Очевидно, что наличие пузырька в конвейере дает суммарное время исполнения в 8 тактов вместо 7 на схеме исполнения, продемонстрированной выше.
Пузырьки - это как заглушки, в которых не случается ничего полезного при их прочтении, раскодировании, исполнении и записи результата. Они могут быть выражены при помощи NOP.
Пример 1
Допустим, типичная инструкция для сложения двух чисел это СЛОЖИТЬ A, B, C , которая суммирует значения, которые находятся в ячейках памяти A и B, а затем кладет результат в ячейку памяти C. В конвейерном процессоре контроллер может разбить эту операцию на последовательные задачи вида
Ячейки R1 и R2 являются регистрами процессора. Значения, которые хранятся в ячейках памяти, которые мы называем A и B, загружаются (т.е. копируются) в эти регистры, затем суммируются, и результат записывается в ячейку памяти C.
В данном примере конвейер состоит из трех уровней - загрузки, исполнения и записи. Эти шаги называются, очевидно, уровнями или шагами конвейера.
В бесконвейерном процессоре, только один шаг может работать в один момент времени, поэтому инструкция должна полностью закончиться прежде, чем следующая инструкция в принципе начнется. В конвейерном процессоре, все эти шаги могут выполняться одновременно на разных инструкциях. Поэтому когда эта инструкция находится на шаге исполнения, вторая инструкция будет на стадии раскодирования, и третья инструкция будет на стадии прочтения.
Конвейер не уменьшает время, которое необходимо для того, чтобы выполнить инструкцию, но зато он увеличивает объем (число) инструкций, которые могут быть выполнены одновременно и таким образом уменьшает задержку между выполненными инструкциями — увеличивая т.н. пропускную способность. Чем больше уровней имеет конвейер, тем больше инструкций могут выполняться одновременно и тем меньше задержка между завершенными инструкциями. Каждый микропроцессор, произведенный в наши дни, использует как минимум двухуровневый конвейер. Процессоры Intel Pentium 4 имеют 20-тиуровневый конвейер.
Пример 2
Чтобы лучше продемонстрировать идею, давайте посмотрим на теоретический трехуровневый конвейер:
| Шаг | Описание |
|---|---|
| Загрузка | Прочитать инструкцию из памяти |
| Исполнение | Исполнить инструкцию |
| Запись | Записать результат в память и/или регистры |
и на псевдоассемблерный листинг, который нужно выполнить:
Теперь как это всё будет исполняться:
Инструкция ЗАГРУЗИТЬ читается из памяти.
Инструкция ЗАГРУЗИТЬ выполняется, тогда как инструкция КОПИРОВАТЬ читается из памяти.
| Загрузка | Исполнение | Запись |
|---|---|---|
| СЛОЖИТЬ | КОПИРОВАТЬ | ЗАГРУЗИТЬ |
Инструкция ЗАГРУЗИТЬ находится на шаге записи результата, где её результат (т.е. число 40) записывается в регистр А. В это же время, инструкция КОПИРОВАТЬ исполняется. Так как она должна скопировать содержимое регистра A в регистр B, она должна дождаться окончания инструкции ЗАГРУЗИТЬ.
| Загрузка | Исполнение | Запись |
|---|---|---|
| ЗАПИСАТЬ | СЛОЖИТЬ | СКОПИРОВАТЬ |
Загружена инструкция ЗАПИСАТЬ, тогда как инструкция СКОПИРОВАТЬ прощается с нами, а по инструкции СЛОЖИТЬ в данный момент производятся вычисления.
И так далее. Следует учитывать, что иногда инструкции будут зависеть от результатов других инструкций (например, как наша инструкция СКОПИРОВАТЬ). Когда более, чем одна инструкция ссылается на определенное место, читая его (т.е. используя в качестве входного операнда) либо записывая в него (т.е. используя его в качестве выходного операнда), исполнение инструкций не в порядке, который был изначально запланирован в оригинальной программе может повлечь за собой «конфликт конвейера» (англ. en:Hazard (computer architecture) ) (о чем упоминалось выше). Существует несколько зарекомендовавших себя приемов для либо предотвращения конфликтов, либо их исправления, если они случились.
Трудности
Множество схем включают в себя конвейеры в 7, 10 или даже 20 уровней (как, например, в Intel Pentium 4). Поздние ядра Pentium 4 с кодовыми именами «Prescott» и «Cedar Mill» (и их Pentium D-производные) имеют 31-уровневый конвейер, самый длинный среди популярных процессоров. Xelerator X10q имеет конвейер длиной более, чем в тысячу шагов [1] . Обратной стороной медали в данном случае является необходимость сбрасывать полностью весь конвейер в случае, если ход программы изменился (например, по условному оператору). Эту проблему пытаются решать предсказатели переходов (англ. en:Branch predictor ). Предсказание переходов само по себе может только усугубить ситуацию, если предсказание производится плохо. В некоторых областях применения, таких как вычисления на суперкомпьютерах, программы специально пишутся так, чтобы как можно реже использовать условные операторы, поэтому очень длинные конвейеры весьма позитивно скажутся на общей скорости вычислений, так как длинные конвейеры проектируются так, чтобы уменьшить CPI (количество тактов на инструкцию). Если ветвление происходит постоянно, переорганизация таким образом, чтобы те инструкции, которые, скорее всего, понадобятся, были размещены в конвейере, может значительно уменьшить потери скорости по сравнению с необходимостью каждый раз полностью сбрасывать конвейер. Программы типа gcov могут использоваться для того, чтобы определять, как часто отдельные ветки исполняются на самом деле, используя технологию, известную как анализ покрытия кода (англ. Code coverage analysis , хотя на практике подобный анализ является последней мерой при оптимизации.
Высокая пропускная способность конвейеров оборачивается тормозами в случае, если в исполняемом коде содержится много условных переходов: процессор не знает, откуда читать следующую инструкцию, и поэтому вынужден ждать, когда закончится инструкция условного перехода, оставляя за ней пустой конвейер. После того, как ветка будет пройдена и станет известно, куда процессору необходимо переходить в дальнейшем, следующая инструкция должна будет пройти весь путь через конвейер перед тем, как результат становится доступным и процессор снова «работает». В крайнем случае, производительность конвейерного процессора может теоретически упасть до производительности безконвейерного, или даже быть хуже за счет того, что будет занят только один уровень конвейера и между уровнями присутствует небольшая задержка.
Из-за конвейера процессора, код, который загружает процессор, не будет исполнен мгновенно. Из-за этого, обновления в коде, которые находятся очень близко к текущему месту исполнения программы, могут пройти незамеченными из-за того, что код уже предзагружен в en:Prefetch Input Queue. Кэши инструкций (англ. en:Instruction cache ) еще больше усугубляют эту проблему. Стоит учитывать, что данная проблема присутствует только в самомодифицирующихся программах.
Идея конвейера, предложенная ещё Генри Фордом, состоит в том, что производительность цепочки последовательных действий определяется не сложностью этой цепочки, а лишь длительностью самой сложной операции.
Продолжение статьи об истории развития архитектур процессоров. Чтение лучше начать с первой части.
Шаг 3. Введение конвейера
Идея конвейера, давным-давно предложенная Генри Фордом, состоит в том, что производительность цепочки последовательных действий определяется не сложностью этой цепочки, а лишь длительностью самой сложной операции. Иными словами, совершенно неважно, сколько человек занимаются производством автомобиля и как долго длится его изготовление в целом, - важно то, что если каждый человек в цепочке тратит, скажем, на свою операцию одну минуту, то с конвейера будет сходить один автомобиль в минуту, ни больше и ни меньше; независимо от того, сколько операций нужно совершить с отдельным автомобилем и сколько заняла бы его сборка одним человеком. Применительно к процессорам принцип конвейера означает, что если мы сумеем разбить выполнение машинной инструкции на несколько этапов, то тактовая частота (а вернее, скорость, с которой процессор забирает данные на исполнение и выдает результаты) будет обратно пропорциональна времени выполнения самого медленного этапа. Если это время удастся сделать достаточно малым (а чем больше этапов на конвейере, тем они короче), то мы сумеем резко повысить тактовую частоту, а значит, и производительность процессора.
Процедуру выполнения практически любой инструкции можно разбить как минимум на пять непересекающихся этапов:
- Выборка инструкции (FETCH) из памяти. Из программы извлекается инструкция, которую нужно выполнить.
- Декодирование инструкции (DECODE). Процессор "соображает", что от него хотят, и переправляет запрос на нужное исполнительное устройство.
- Подготовка исходных данных для выполнения инструкции.
- Собственно выполнение инструкции (EXECUTE).
- Сохранение полученных результатов.
Конвейеризация потенциально применима к любой процессорной архитектуре, независимо от набора команд и положенных в ее основу принципов. Даже самый первый x86-процессор, Intel 8086, уже содержал своеобразный примитивный "двухстадийный конвейер" - выборка новых инструкций (FETCH) и их исполнение осуществлялись в нем независимо друг от друга. Однако реализовать что-то более сложное для CISC-процессоров оказалось трудно: декодирование неоднородных CISC-инструкций и их очень сильно различающаяся сложность привели к тому, что конвейер получается чересчур замысловатым, катастрофически усложняя процессор. Подобных трудностей у RISC-архитектуры гораздо меньше (а SPARC и MIPS, например, и вовсе были специально оптимизированы для конвейеризации), так что конвейеризированные RISC-процессоры появились на рынке много раньше, чем аналогичные x86.
Недостатки конвейера неочевидны, но, как обычно и бывает, из-за нескольких "мелочей" реализовать грамотно организованный конвейер совсем не просто. Основных проблем три.
- Необходимость наличия блокировок конвейера. Дело в том, что время исполнения большинства инструкций может очень сильно варьироваться. Скажем, умножение (и тем более деление) чисел требуют (на стадии EXECUTE) нескольких тактов, а сложение или побитовые операции - одного такта; а для операций Load и Store, которые могут обращаться к разным уровням кэш-памяти или к оперативной памяти, это время вообще не определено (и может достигать сотен тактов). Соответственно, должен быть какой-то механизм, который бы "притормаживал" выборку и декодирование новых инструкций до тех пор, пока не будут завершены старые. Методов решения этой проблемы много, но их развитие приводит к одному - в процессорах прямо перед исполнительными устройствами появляются специальные блоки-диспетчеры (dispatcher), которые накапливают подготовленные к исполнению инструкции, отслеживают выполнение ранее запущенных инструкций и по мере освобождения исполнительных устройств отправляют на них новые инструкции. Даже если исполнение займет много тактов - внутренняя очередь диспетчера позволит в большинстве случаев не останавливать подготавливающий все новые и новые инструкции конвейер[Новые инструкции тоже не каждый такт удается декодировать, так что возможна и обратная ситуация: новых инструкций за такт не появилось, и диспетчер отправляет инструкции на выполнение "из старых запасов"]. Так в процессоре возникает разделение на две независимо работающие подсистемы: Front-end (блоки, занимающиеся декодированием инструкций и их подготовкой к исполнению) и Back-end (блоки, собственно исполняющие инструкции).
- Необходимость наличия системы сброса процессора. Поскольку операции FETCH и EXECUTE всегда выделены в отдельные стадии конвейера, то в тех случаях, когда в программном коде происходит разветвление (условный переход), зачастую оказывается, что по какой из веток пойти - пока неизвестно: инструкция, вычисляющая код условия, еще не выполнена[Вот здесь-то и нужны те самые режимы выставления флагов PowerPC, о которых шла речь в сноске 2]. В результате процессор вынужден либо приостанавливать выборку новых инструкций до тех пор, пока не будет вычислен код условия (а это может занять очень много времени и в типичном цикле страшно затормозит процессор), либо, руководствуясь соображениями блока предсказания переходов, "угадывать", какой из переходов скорее всего окажется правильным.
- Наконец, конвейер обычно требует наличия специального планировщика (scheduler), призванного решать конфликты по данным. Если в программе идет зависимая цепочка инструкций (когда инструкция-2, следующая за инструкцией-1, использует для своих вычислений данные, только что вычисленные инструкцией-1), а время исполнения одной инструкции (от момента запуска на стадию EXECUTE и до записи полученных результатов в регистры) превосходит один такт, то мы вынуждены придержать выполнение очередной инструкции до тех пор, пока не будет полностью выполнена ее предшественница. К примеру, если мы вычисляем выражение вида A•B+C с сохранением результата в переменной X (XfA•B+C), то процессор, выполняя соответствующую выражению цепочку из двух команд типа R4fR1•R2; R0fR3+R4, должен вначале дождаться, пока первая инструкция сохранит результат умножения A•B, и только потом прибавлять к полученному результату число С. Цепочки зависимых инструкций в программах - скорее правило, нежели исключение, а исполнение команды с записью результата в регистры за один такт - наоборот, скорее исключение, нежели правило, поэтому в той или иной степени с проблемой зависимости по данным любая конвейерная архитектура обязательно сталкивается. Оттого-то в конвейере и появляются сложные декодеры, заранее выявляющие эти зависимости, и планировщики, которые запускают инструкции на исполнение, выдерживая паузу между запуском главной инструкции и зависимой от нее.
Ну как вам список проблем? Идея конвейера в процессоре очень красива на словах и в теории, однако реализовать ее даже в простом варианте чрезвычайно трудно. Но выгода от конвейеризации столь велика и несомненна, что приходится с этими трудностями мириться, ведь ничего лучшего до сих пор не придумано.
В 1991-92 годах корпорация Intel, освоив производство сложнейших кристаллов с более чем миллионом транзисторов, выпустила i486 - классический CISC-процессор архитектуры x86, но с пятистадийным конвейером. Чтобы вы смогли оценить этот рывок, приведу две цифры: тактовую частоту по сравнению с i386 введение конвейера позволило увеличить втрое, а производительность на единицу частоты - вдвое. В i386 многие инструкции выполнялись за несколько тактов; а в i486 среднее "время" исполнения инструкции в тактах удалось снизить почти вдвое. Правда, расплатой за это стала чудовищная сложность ядра i486; но такие "мелочи" по меркам индустрии центральных процессоров - пустяк: быстро растущие технологические возможности кремниевой технологии уже через пару лет позволили освоить производство i486 всем желающим. Но к тому моменту RISC-архитектуры сделали еще один шаг вперед - к суперскалярным процессорам.
Блок предсказания переходов
Да-да, именно так называется этот странный блок! Но "гадание на кофейной гуще" здесь ни при чем - переходы предсказываются на основе вполне научных соображений. Обычно используется очень простой способ: в процессоре ведется табличка ранее совершенных переходов - для каждого условного перехода подсчитывается, сколько раз он "сработал", а сколько - "был проигнорирован". Поэтому, скажем, когда процессор встречает переход, замыкающий какой-нибудь цикл, то он быстренько начинает считать: раз переход сработал, два сработал, три сработал - ну, значит, наверное, он всегда будет срабатывать, вот так и будем предсказывать, что переход всегда происходит. То, что мы один раз в конце цикла ошибемся, - не беда, зато ценой максимум двух ошибок мы добьемся точного предсказания во всех остальных случаях. Кстати, на простых циклах процессор, как правило, ошибается еще реже - не более одного раза: по умолчанию, когда не из чего выбирать, считается, что условный переход всегда происходит.
При неправильном предсказании конвейер обычно приходится "сбрасывать", каким-то образом восстанавливая состояние процессора, предшествующее моменту неправильного перехода. А ведь пока исполнялась неправильная ветка, там ого-го сколько всего могло случиться! Неправильный опкод (нераспознаваемая машинная инструкция), обращение к виртуальной памяти (провоцирующее исключение в процессоре), некстати распознанное деление на ноль (тоже ошибка). Все это приходится тщательно отслеживать и проверять, причем это не шутки: одно время из-за ошибки в реализации конвейера процессора AMD K5, программист, написавший конструкцию если x A 0, то y = 1/x, иначе y = 0, запросто мог получить при x @ 0 на, казалось бы, ровном месте ошибку "деление на ноль", вызванную неправильным предсказанием перехода. А в OoO-процессорах ситуация еще сложнее - пока "тормозит" не вовремя отправившаяся за операндами в оперативную память инструкция, процессор успевает пропустить вперед, выполнить и едва ли не сохранить результат вычисления десятков инструкций неправильной ветки: попробуй за всем этим уследить!
Но бороться здесь есть за что: для современных процессоров каждая ошибка предсказания - это десятки вхолостую израсходованных тактов. Сущая катастрофа, если учитывать, что за каждый такт можно было бы исполнить до трех x86-инструкций и совершить кучу вычислений. Если бы блока предсказания не было, то так "тормозил" бы каждый условный переход.
В архитектуре IA-64 техника предсказания переходов сделала значительный шаг вперед - эти процессоры умеют одновременно вычислять несколько веток программного кода. То есть, встретив инструкцию условного перехода, процессор начинает "охотиться за двумя зайцами" - просчитывать оба варианта развития событий вплоть до того момента, пока не станет ясно, какой из них правильный. Поскольку инструкции "разных вариантов" практически не зависят друг от друга, а исполнительные устройства Itanium обычно загружены далеко не полностью, то исполнять побочную ветку нередко удается практически с той же скоростью, что и основную, так что даже при неправильном предсказании условного перехода происходит не остановка процессора на пару десятков тактов, а всего лишь снижение производительности на небольшом участке кода.
Шаг 4. Суперскалярные и Out-of-Order-процессоры
У полноценной конвейеризации, более или менее эффективно обходящей перечисленные выше проблемы, есть одно несомненное достоинство: она настолько сложна, что, единожды реализованная, позволяет легко построить на ее основе целый ряд интересных новшеств. Для начала заметим, что коль уж у нас есть очереди готовых к исполнению инструкций и мы знаем взаимозависимости между ними по данным, есть техника переименования регистров, позволяющая разным инструкциям одновременно задействовать одни и те же регистры для разных целей, и, наконец, есть надежно работающая система сброса конвейера, то мы можем:
- Запускать на исполняющие устройства сразу несколько инструкций (если они не зависят друг от друга и могут быть безболезненно выполнены одновременно).
- Переупорядочивать независящие друг от друга инструкции так, как сочтем нужным.
Процессоры, использующие первую технику, называются суперскалярными. К примеру, сугубо теоретически, по числу исполнительных устройств, Pentium 4 может выполнять семь инструкций за такт, а Athlon 64 - девять. Реальные цифры, конечно, гораздо скромнее и определяются трудностью полноценной загрузки всех исполнительных устройств, однако Pentium 4 все же способен исполнять в устоявшемся режиме две (при некоторых условиях - четыре), а Athlon 64 - три инструкции за такт, одновременно производя две (A64 - три) операции по адресации и выборке данных из оперативной памяти. Может показаться, что реализация суперскалярного процессора очень проста (достаточно со стадии schedule просто распределять инструкции по разным исполнительным устройствам), однако такой лобовой подход обычно упирается в то, что Front-end процессора перестает успевать загружать исполнительные блоки работой. Поэтому на практике хорошо сделанные суперскалярные архитектуры, подобные AMD K7/K8, приходится специально "затачивать" под суперскалярность.
Процессоры, использующие вторую технику, называются процессорами с внеочередным исполнением инструкций (Out-of-Order processors, OoO). Техника переупорядочивания инструкций замечательна тем, что резко ослабляет негативные эффекты от медленной оперативной памяти и от наличия зависимых цепочек инструкций. Если, например, инструкция A обратилась к оперативной памяти, а нужных данных в кэше не оказалось или если A занимается ожиданием результатов выполнения какой-то другой инструкции, то OoO-процессор сможет пропустить вперед другие инструкции, не зависящие от результатов выполнения инструкции A. Кроме того, продвинутый планировщик OoO-процессора иногда может использоваться для реализации специфических деталей той или иной архитектуры - например, для спекулятивного исполнения по данным в случае Pentium 4 или одновременного исполнения нескольких веток программного кода в IA-64. Реализация OoO-процессоров не требует специальной оптимизации всего конвейера - это всего лишь усложнение схемы планировщиков, запускающих готовые к исполнению инструкции на исполнительные устройства в другом порядке, нежели они на планировщики поступили, плюс усложнение схем сброса конвейера и сохранения полученных результатов: результат выполнения прошедших вне очереди инструкций все равно должен сохраняться в последовательности, строго соответствующей расположению инструкций в изначальном коде[Это связано с тем, что если случится какая-то ошибка, то результаты выполнения запущенных вперед очереди инструкции придется аннулировать].
Фактически развитие собственно "архитектуры" x86-процессоров долгое время стояло на месте: что древний Pentium Pro, что новейший Pentium M - все они основаны на одной и той же старой-престарой архитектуре P6. Вылизанной, оптимизированной, но старой - ибо повода для ее смены до сих пор просто не было; "внутреннее представление" x86-кода, несмотря на все внесенные в x86 новации, с тех самых древних времен "чистой IA-32" вплоть до появления технологии AMD64 практически не изменялось.
К сожалению, нет места для рассказа об архитектуре VLIW. О Cell - ещё одном потенциальном претенденте на замену суперскалярных OoO-процессоров, мы уже рассказывали.
Читайте продолжение в четверг: MIPS, Sparc, ARM и PowerPC
Читайте также: