
Что такое mmu процессора
Обновлено: 07.07.2024
Интерфейс виртуальной машины, предоставляемый каждым разделом, включает в себя единицу управления памятью (ММУ). Виртуальные ММУ, предоставляемые секциями гипервизора, обычно совместимы с существующими Ммус.
Общие сведения о виртуальных ММУ
Виртуальные процессоры предоставляют виртуальную память и виртуальный TLB (буфер для поиска перевода), который кэширует переводы от виртуальных адресов до (гостевых) физических адресов. Как и в случае с TLB на логическом процессоре, виртуальный TLB является несвязанным кэшем, и эта несогласованность видна гостям. Гипервизор предоставляет операции для очистки TLB. Гости могут использовать эти операции для удаления потенциально непротиворечивых записей и преобразования виртуальных адресов в прогнозируемые.
Совместимость
Виртуальные ММУ, предоставляемые гипервизором, обычно совместимы с физическим ММУ, обнаруженным в процессоре x64. Существуют следующие отличия, наблюдаемые в гостевой системе:
Устаревшие операции управления TLB
Архитектура x64 предоставляет несколько способов управления Тлбсом процессора. Гипервизоры виртуализованы следующими механизмами:
- Инструкция ИНВЛПГ делает перевод отдельной страницы недействительным из TLB процессора. Если указанный виртуальный адрес изначально был сопоставлен как страница 4-K, перевод этой страницы удаляется из TLB. Если указанный виртуальный адрес изначально был сопоставлен как "большая страница" (2 МБ или 4 МБ в зависимости от режима ММУ), перевод всей большой страницы удаляется из TLB. Инструкция ИНВЛПГ очищает как глобальные, так и неглобальные переводы. Глобальные переводы определяются как те, которые имеют "Глобальный" набор битов в записи таблицы страниц.
- Инструкция MOV to CR3 и переключатели задач, изменяющие CR3, делают перевод недействительными для всех неглобальных страниц в TLB процессора.
- Инструкция MOV to CR4, которая изменяет CR4. Бит ПЖЕ (включение глобальной страницы), CR4. СВЕРНУТЬ (расширения размера страницы) bit или CR4. Бит PAE (расширения адресов страниц) делает недействительными все переводы (глобальные и неглобальные) в TLB процессора.
Обратите внимание, что все эти операции недействительности затрагивают только один процессор. Чтобы сделать перевод на другие процессоры недействительными, программное обеспечение должно использовать механизм "Прокрутка TLB" на основе программного обеспечения (обычно реализуется с помощью межпроцессных прерываний).
Усовершенствования виртуального TLB
Помимо поддержки устаревших механизмов управления TLB, описанных выше, гипервизор также поддерживает ряд усовершенствований, позволяющих гостевым службам более эффективно управлять виртуальным TLB. Эти расширенные операции могут быть взаимозаменяемы с помощью устаревших операций управления TLB.
Гипервизор поддерживает следующие вызовы для аннулирования Тлбс:
| Гипервызова | Описание |
|---|---|
| HvCallFlushVirtualAddressSpace | Делает недействительными все записи виртуального TLB, принадлежащие заданному адресному пространству. |
| HvCallFlushVirtualAddressSpaceEx | Как и в случае с Хвкаллфлушвиртуаладдрессспаце, в качестве входных данных принимается разреженный вице-президент. |
| HvCallFlushVirtualAddressList | Делает недействительным часть указанного адресного пространства. |
| HvCallFlushVirtualAddressListEx | Как и в случае с Хвкаллфлушвиртуаладдресслист, в качестве входных данных принимается разреженный вице-президент. |
В некоторых системах (с поддержкой виртуализации в оборудовании) устаревшие инструкции по управлению TLB могут выполняться быстрее при недействительности локального или удаленного (перекрестного процессора) TLB. Гости, заинтересованные в оптимальной производительности, должны использовать конечный 0x40000004 CPUID, чтобы определить, какие поведения следует реализовать с помощью гипервызовов:
- Усехиперкаллфораддрессспацесвитч: Если этот флаг установлен, вызывающий объект должен предположить, что быстрее использовать Хвкаллсвитчаддрессспаце для переключения между адресными пространствами. Если этот флаг снят, рекомендуется использовать инструкцию MOV to CR3.
- Усехиперкаллфорлокалфлуш. Если этот флаг установлен, вызывающий объект должен предположить, что для записи одной или нескольких страниц из виртуального TLB быстрее использовать вызовы (в отличие от ИНВЛПГ или MOV в CR3).
- Усехиперкаллфорремотефлушандлокалфлушентире. Если этот флаг установлен, вызывающий объект должен предположить, что быстрее использовать вызовы (в отличие от использования созданных гостевыми прерываний) для записи одной или нескольких страниц из виртуального TLB.
Общие сведения об элементе управления кэшем памяти
Гипервизор поддерживает параметры кэширования, определяемые гостевой системой, для страниц, сопоставленных в ГВА пространстве виртуальной машины. Подробное описание доступных параметров кэширования и их значений см. в документации по Intel или AMD.
Когда виртуальный процессор обращается к странице через ее ГВА пространство, гипервизор учитывает биты атрибутов кэша (PAT, PWT и ПКД) в записи таблицы гостевой страницы, используемой для отображения страницы. Эти три бита используются в качестве индекса в регистре "PAT" секции (тип адреса страницы) для поиска окончательной настройки кэширования для страницы.
Смешивание типов кэша между секцией и гипервизором
Гости должны знать, что гипервизор может получить доступ к некоторым страницам в области GPA. Следующий список, хотя и не является исчерпывающим, предоставляет несколько примеров:
- страница, содержащая входные или выходные параметры для вызова
- Все страницы наложения, включая страницу «вызов Синик», страницы СИЕФ и SIM, а также страницы статистики
Гипервизор всегда выполняет доступ к параметрам гипервызовов и страницам наложения с помощью настройки кэширования WB.

А блок управления памятью (MMU), иногда называемый блок управления выгружаемой памятью (PMMU), это компьютерное железо единица, имеющая все объем памяти ссылки прошли через себя, в первую очередь выполняя перевод адреса виртуальной памяти к физические адреса.
MMU эффективно выполняет виртуальная память управление, обработка одновременно защита памяти, тайник контроль автобус арбитраж и в более простых компьютерных архитектурах (особенно 8 бит системы), переключение банка.
Содержание
Обзор

Записи в таблице страниц
PTE также может включать информацию о том, была ли страница записана в ("грязный немного"), когда он использовался последний раз (" доступный бит "для наименее недавно использованный (LRU) алгоритм замены страницы), какие процессы (пользовательский режим или режим супервизора) может читать и писать, и должен ли он быть кешированный.
MMU также может создавать условия ошибки незаконного доступа или неверные ошибки страницы при незаконном или несуществующем доступе к памяти, соответственно, что приводит к ошибка сегментации или ошибка шины условия при обработке операционной системой.
Преимущества

Хотя в этой статье основное внимание уделяется современным MMU, обычно основанным на страницах, ранние системы использовали аналогичную концепцию для базовая адресация что в дальнейшем превратилось в сегментация. Иногда они также присутствуют на современных архитектурах. В архитектура x86 обеспечил сегментацию, а не разбиение на страницы, в 80286, и обеспечивает как разбиение на страницы, так и сегментацию в 80386 и более поздние версии процессоров (хотя использование сегментации недоступно в 64-битных операциях).
Примеры
Большинство современных систем делят память на страницы, которые 4-64 КБ по размеру, часто с возможностью использования так называемых огромных страниц 2 МБ или 1 ГБ по размеру (часто возможны оба варианта). Переводы страниц кешируются в резервный буфер перевода (TLB). Некоторые системы, в основном старые RISC конструкции ловушка в ОС, когда перевод страницы не найден в TLB. В большинстве систем используется аппаратный обходчик деревьев. Большинство систем позволяют отключать MMU, но некоторые отключают MMU при захвате кода ОС.
VAX страницы имеют размер 512 байт, что очень мало. ОС может обрабатывать несколько страниц, как если бы они были одной большой страницей. Например, Linux на VAX группирует восемь страниц вместе. Таким образом, система рассматривается как имеющая 4 КБ страниц. VAX делит память на четыре области фиксированного назначения, каждая 1 ГБ по размеру. Они есть:
P0 пространство Используется для универсальной памяти для каждого процесса, такой как кучи. Пространство P1 (Или контрольное пространство), которое также относится к каждому процессу и обычно используется для руководителя, руководителя, ядро, Пользователь стеки и другие структуры управления процессами, управляемые операционной системой. S0 пространство (Или системное пространство), которое является глобальным для всех процессов и хранит код и данные операционной системы, независимо от того, выгружены они или нет, включая таблицы. S1 пространство Который не используется и "Зарезервирован для Цифровой".
Таблицы страниц представляют собой большие линейные массивы. Обычно это было бы очень расточительно, если адреса используются на обоих концах возможного диапазона, но таблица страниц для приложений сама хранится в выгружаемой памяти ядра. Таким образом, получается двухуровневая дерево, позволяя приложениям иметь разреженную структуру памяти, не тратя много места на неиспользуемые записи таблицы страниц. VAX MMU отличается отсутствием доступный бит. Операционные системы, реализующие разбиение по страницам, должны найти способ имитировать доступный бит, если они хотят работать эффективно. Обычно ОС будет периодически отключать отображение страниц, чтобы можно было использовать ошибки отсутствия страницы, чтобы позволить ОС установить доступный бит.
ARM архитектурапроцессоры приложений на основе реализуют MMU, определенный архитектурой системы виртуальной памяти ARM. Текущая архитектура определяет PTE для описания 4 КБ и 64 КБ страницы, 1 МБ разделы и 16 МБ супер-разделы; устаревшие версии также определили 1 КБ крошечная страница. ARM использует двухуровневую таблицу страниц при использовании 4 КБ и 64 КБ страниц, или просто одноуровневой таблицы страниц для 1 МБ разделы и 16 МБ разделы.
IBM System / 360 Model 67, IBM System / 370 и последующие
Начиная с августа 1972 г. IBM System / 370 имеет аналогичный MMU, хотя изначально он поддерживал только 24-битное виртуальное адресное пространство, а не 32-битное виртуальное адресное пространство System / 360 Model 67. Он также хранит используемые и грязные биты вне таблицы страниц. В начале 1983 г. архитектура System / 370-XA расширила виртуальное адресное пространство до 31 бита, а в 2000 г. 64-битный z / Архитектура был представлен, с расширением адресного пространства до 64 бит; те продолжают хранить использованные и грязные биты вне таблицы страниц.
DEC Alpha
В DEC Alpha процессор делит память на 8 КБ страниц. После промаха TLB низкоуровневый прошивка машинный код (здесь называется PALcode) просматривает трехуровневую таблицу страниц с древовидной структурой. Адреса разбиты следующим образом: 21 бит не используется, 10 бит для индексации корневого уровня дерева, 10 бит для индексации среднего уровня дерева, 10 бит для индексации конечного уровня дерева и 13 бит, которые проходят через на физический адрес без изменений. Поддерживаются полные биты разрешений на чтение / запись / выполнение.
В Архитектура MIPS поддерживает от одной до 64 записей в TLB. Количество записей TLB настраивается при конфигурации ЦП перед синтезом. Записи TLB двойные. Каждая запись TLB сопоставляет номер виртуальной страницы (VPN2) с одним из двух номеров кадров страницы (PFN0 или PFN1) в зависимости от младшего бита виртуального адреса, который не является частью страницы. маска. Этот бит и биты маски страницы не хранятся в VPN2. Каждая запись TLB имеет собственный размер страницы, который может быть любым значением от 1 КБ к 256 МБ кратно четырем. Каждый PFN в записи TLB имеет атрибут кэширования, грязный и действительный бит состояния. VPN2 имеет глобальный бит состояния и идентификатор, назначенный ОС, который участвует в сопоставлении записи TLB виртуального адреса, если глобальный бит состояния установлен в ноль. PFN хранит физический адрес без битов маски страницы.
Исключение пополнения TLB генерируется, когда в TLB нет записей, соответствующих отображенному виртуальному адресу. Исключение недопустимого TLB генерируется, когда есть совпадение, но запись помечена как недопустимая. Измененное исключение TLB генерируется, когда инструкция сохранения ссылается на отображаемый адрес, а грязный статус соответствующей записи не установлен. Если при обработке исключения TLB возникает исключение TLB, исключение TLB с двойной ошибкой, оно отправляется на собственный обработчик исключений.
MIPS32 и MIPS32r2 поддерживают 32 бита виртуального адресного пространства и до 36 бит физического адресного пространства. MIPS64 поддерживает до 64 бит виртуального адресного пространства и до 59 бит физического адресного пространства.
Оригинал Вс 1 это одноплатный компьютер построенный вокруг Motorola 68000 микропроцессор и представленный в 1982 году. Он включает в себя оригинальный блок управления памятью Sun 1, который обеспечивает преобразование адресов, защиту памяти, совместное использование памяти и распределение памяти для нескольких процессов, запущенных на ЦП. Полный доступ ЦП к частной встроенной ОЗУ, внешней Multibus память, бортовая Ввод / вывод а ввод / вывод Multibus работает через MMU, где трансляция адресов и защита выполняются единообразно. MMU аппаратно реализован на плате ЦП.
MMU состоит из регистра контекста, сегмент карта и карта страницы. Виртуальные адреса ЦП преобразуются в промежуточные адреса картой сегментов, которые, в свою очередь, преобразуются в физические адреса картой страниц. Размер страницы 2 КБ а размер сегмента 32 КБ что дает 16 страниц на сегмент. Одновременно можно отображать до 16 контекстов. Максимальное логическое адресное пространство для контекста составляет 1024 страницы или 2 МБ. Максимальный физический адрес, который может отображаться одновременно, также 2 МБ.
Регистр контекста важен в многозадачной операционной системе, поскольку он позволяет процессору переключаться между процессами без перезагрузки всей информации о состоянии преобразования. 4-битный регистр контекста может переключаться между 16 разделами карты сегментов под управлением супервизора, что позволяет отображать 16 контекстов одновременно. Каждый контекст имеет собственное виртуальное адресное пространство. Совместное использование виртуального адресного пространства и межконтекстные коммуникации могут быть обеспечены записью одних и тех же значений в карты сегментов или страниц разных контекстов. Дополнительные контексты можно обрабатывать, рассматривая карту сегментов как кеш контекста и заменяя устаревшие контексты на наименее недавно использованные.
PowerPC
Другой поиск, не поддерживаемый напрямую всеми процессорами в этом семействе, осуществляется через так называемый "перевернутая таблица страниц, "который действует как хешированное расширение TLB вне кристалла. Сначала верхние четыре бита адреса используются для выбора одного из 16 сегмент регистры. Затем 24 бита из сегментного регистра заменяют эти четыре бита, создавая 52-битный адрес. Использование сегментных регистров позволяет нескольким процессам совместно использовать один и тот же хеш-таблица.
52-битный адрес хешируется, а затем используется в качестве индекса во внешней таблице. Там группа записей таблицы на восьми страницах просматривается на предмет соответствия. Если совпадений нет из-за чрезмерного хеш-коллизии, процессор пытается еще раз с немного другим хеш-функция. Если это тоже не удается, ЦП переходит в ОС (с отключенным MMU), чтобы проблема могла быть решена. ОС необходимо удалить запись из хеш-таблицы, чтобы освободить место для новой записи. ОС может сгенерировать новую запись из более нормальной древовидной таблицы страниц или из структур данных для каждого отображения, которые, вероятно, будут медленнее и эффективнее по пространству. Поддержка для не исполнять управление находится в сегментных регистрах, что приводит к 256 МБ детализация.
Основная проблема с этим дизайном - плохой местонахождение тайника вызвано хеш-функцией. В древовидном дизайне этого избегают, размещая записи таблицы страниц для соседних страниц в соседних местах. Операционная система, работающая на PowerPC, может уменьшить размер хеш-таблицы, чтобы уменьшить эту проблему.
Также несколько медленно удаляются записи таблицы страниц процесса. ОС может избежать повторного использования значений сегментов, чтобы отложить решение этой проблемы, или она может решить потерять память, связанную с хэш-таблицами для каждого процесса. Микросхемы G1 не ищут записи в таблице страниц, но они генерируют хэш, ожидая, что ОС будет искать стандартную хеш-таблицу с помощью программного обеспечения. ОС может писать в TLB. Чипы G2, G3 и ранние G4 используют оборудование для поиска в хэш-таблице. Последние чипы позволяют ОС выбирать любой метод. На чипах, которые делают это необязательным или не поддерживают его вообще, ОС может выбрать использование исключительно древовидной таблицы страниц.
IA-32 / x86
В x86 архитектура развивалась в течение очень долгого времени при сохранении полной совместимости программного обеспечения, даже для кода ОС. Таким образом, MMU чрезвычайно сложен с множеством различных возможных режимов работы. Нормальная работа традиционного 80386 CPU и его преемники (IA-32) описывается здесь.
ЦП в первую очередь делит память на 4 КБ страниц. Сегментные регистры, фундаментальные для старых 8088 и 80286 Конструкции MMU не используются в современных операционных системах, за одним важным исключением: доступ к нить-специфические данные для приложений или специфичные для ЦП данные для ядер ОС, что делается с явным использованием сегментных регистров FS и GS. Весь доступ к памяти включает в себя сегментный регистр, выбираемый в соответствии с выполняемым кодом. Сегментный регистр действует как индекс в таблице, который обеспечивает смещение, добавляемое к виртуальному адресу. За исключением случаев использования FS или GS, ОС гарантирует, что смещение будет нулевым.
После добавления смещения адрес маскируется, чтобы его длина не превышала 32 бита. Результат можно найти с помощью древовидной таблицы страниц, при этом биты адреса разделяются следующим образом: 10 бит для ветви дерева, 10 бит для листьев ветви и 12 младших битов непосредственно скопировал в результат. Некоторые операционные системы, например OpenBSD с этими W ^ X функция и Linux с Exec Shield или PaX патчи также могут ограничивать длину сегмента кода, как указано в регистре CS, чтобы запретить выполнение кода в изменяемых областях адресного пространства.
Незначительные изменения MMU, представленные в Pentium позволили очень большие 4 МБ страниц, пропуская нижний уровень дерева (остается 10 бит для индексации первого уровня иерархии страниц, а оставшиеся 10 + 12 бит напрямую копируются в результат). Незначительные изменения MMU, представленные в Pentium Pro представил расширение физического адреса (PAE), позволяющая напрямую копировать в результат 36-битные физические адреса с 2 + 9 + 9 битами для трехуровневых таблиц страниц и 12 младшими битами. Большие страницы ( 2 МБ ) также доступны при пропуске нижнего уровня дерева (что приводит к 2 + 9 битам для двухуровневой иерархии таблиц, а оставшиеся 9 + 12 младших битов копируются напрямую). В дополнение таблица атрибутов страницы позволил указать кэшируемость путем поиска нескольких старших битов в небольшой таблице на процессоре.
Не выполнять Первоначально поддержка предоставлялась только для отдельных сегментов, что делало ее очень неудобной в использовании. Более поздние чипы x86 предоставляют бит неисполнения для каждой страницы в режиме PAE. В W ^ X, Exec Shield, и PaX описанные выше механизмы эмулируют постраничную поддержку неисполнения на машинах с процессорами x86, в которых отсутствует бит NX, путем установки длины сегмента кода с потерей производительности и уменьшением доступного адресного пространства.
x86-64
Гетерогенная системная архитектура (HSA) создает единое виртуальное адресное пространство для процессоров, графических процессоров и DSP, устраняя уловки сопоставления и копирования данных.x86-64 это 64-битное расширение x86, которое почти полностью устраняет сегментацию в пользу плоская модель памяти используется почти всеми операционными системами для процессоров 386 или новее. В длинном режиме игнорируются все смещения сегментов, кроме сегментов FS и GS. При использовании с 4 КБ страниц, дерево таблицы страниц имеет четыре уровня вместо трех.
Системы Unisys MCP (Burroughs B5000)
Во-первых, при отображении адресов виртуальной памяти вместо MMU MCP системы дескриптор-на основании. Каждому выделенному блоку памяти дается главный дескриптор со свойствами блока (т. Е. Размером, адресом и наличием в памяти). Когда делается запрос на доступ к блоку для чтения или записи, оборудование проверяет его присутствие через бит присутствия (pbit) в дескрипторе.
Бит 1 указывает на наличие блока. В этом случае доступ к блоку можно получить через физический адрес в дескрипторе. Если pbit равен нулю, для MCP (операционной системы) генерируется прерывание, чтобы обеспечить наличие блока. Если поле адреса равно нулю, это первый доступ к этому блоку, и он выделяется (бит инициализации). Если адресное поле не равно нулю, это дисковый адрес блока, который ранее был развернут, поэтому блок извлекается с диска, бит устанавливается в единицу, а адрес физической памяти обновляется, чтобы указывать на блок. в памяти (еще pbit). Это делает дескрипторы эквивалентными записи в таблице страниц в системе MMU. Производительность системы можно отслеживать по количеству битов. Начальные биты указывают на начальные распределения, но высокий уровень других битов указывает на то, что система может перегружаться.
Другой способ, которым B5000 обеспечивает функцию MMU, - это защита. Поскольку все обращения осуществляются через дескриптор, аппаратное обеспечение может проверить, что все обращения находятся в установленных пределах, а в случае записи - что процесс имеет разрешение на запись. Система MCP по своей природе безопасна и, следовательно, не требует MMU для обеспечения такого уровня защиты памяти. Дескрипторы доступны только для чтения пользовательским процессам и могут обновляться только системой (аппаратным обеспечением или MCP). (Слова с тегом нечетного числа доступны только для чтения; дескрипторы имеют тег 5, а кодовые слова имеют тег 3.)
Блоки могут совместно использоваться процессами с помощью дескрипторов копирования в стеке процессов. Таким образом, некоторые процессы могут иметь разрешение на запись, а другие - нет. Сегмент кода доступен только для чтения, поэтому повторно используется и используется процессами. Дескрипторы копирования содержат 20-битное адресное поле, дающее индекс главного дескриптора в массиве главного дескриптора. Это также реализует очень эффективный и безопасный механизм IPC. Блоки можно легко перемещать, поскольку при изменении статуса блока обновляется только главный дескриптор.
Единственный другой аспект - это производительность: обеспечивают ли системы на основе MMU или без них более высокую производительность? Системы MCP могут быть реализованы поверх стандартного оборудования, у которого есть MMU (например, стандартный ПК). Даже если реализация системы каким-то образом использует MMU, это вообще не будет видно на уровне MCP.
Смотрите также
Рекомендации

Термин «память» можно определить как набор данных в определенном формате. Он используется для хранения инструкций и обработанных данных. Память состоит из большого массива или группы слов или байтов, каждое из которых имеет собственное местоположение. Основным мотивом компьютерной системы является выполнение программ. Эти программы вместе с информацией, к которой они обращаются, должны находиться в основной памяти во время выполнения. ЦП извлекает инструкции из памяти в соответствии со значением счетчика программ.
Для достижения определенной степени мультипрограммирования и правильного использования памяти важно управление памятью. Существует множество методов управления памятью, отражающих различные подходы, и эффективность каждого алгоритма зависит от ситуации.
Что такое основная память
Основная память играет центральную роль в работе современного компьютера. Основная память — это большой массив слов или байтов размером от сотен тысяч до миллиардов. Основная память — это хранилище быстро доступной информации, совместно используемой ЦП и устройствами ввода-вывода. Основная память — это место, где хранятся программы и информация, когда процессор эффективно их использует. Также основная память связана с процессором, поэтому перемещение инструкций и информации в процессор и из процессора происходит очень быстро. Основная память также известна как RAM (оперативная память). Эта память является энергозависимой. ОЗУ теряет свои данные при отключении питания.

Рисунок 1: Иерархия памяти
Что такое управление памятью
В многопрограммном компьютере операционная система находится в части памяти, а остальная часть используется несколькими процессами. Задача разделения памяти между различными процессами называется управлением памятью. Управление памятью — это метод операционной системы для управления операциями между основной памятью и диском во время выполнения процесса. Основная цель управления памятью — эффективное использование памяти.
Почему требуется управление памятью
- Выделять и освобождать память до и после выполнения процесса.
- Для отслеживания используемого пространства памяти процессами.
- Чтобы свести к минимуму проблемы фрагментации.
- Для правильного использования основной памяти.
- Сохранять целостность данных при выполнении процесса.
Теперь мы обсуждаем концепцию логического адресного пространства и физического адресного пространства:
Логическое и физическое адресное пространство
Логическое адресное пространство: адрес, генерируемый ЦП, известен как «логический адрес». Он также известен как виртуальный адрес. Логическое адресное пространство можно определить как размер процесса. Логический адрес можно изменить.
Физическое адресное пространство: адрес, видимый блоком памяти (т. Е. Тот, который загружен в регистр адреса памяти), обычно известен как «Физический адрес». Физический адрес также известен как реальный адрес. Набор всех физических адресов, соответствующих этим логическим адресам, известен как физическое адресное пространство. Физический адрес вычисляется MMU. Отображение виртуальных адресов в физические во время выполнения выполняется с помощью модуля управления памятью (MMU) аппаратного устройства. Физический адрес всегда остается постоянным.
Статическая и динамическая нагрузка
Загрузка процесса в основную память выполняется загрузчиком. Есть два разных типа загрузки:
- Статическая загрузка: — При статической загрузке загружает всю программу по фиксированному адресу. Это требует больше места в памяти.
- Динамическая загрузка: — Для выполнения процесса вся программа и все данные процесса должны находиться в физической памяти. Итак, размер процесса ограничен размером физической памяти. Для правильного использования памяти используется динамическая загрузка. При динамической загрузке подпрограмма не загружается, пока не будет вызвана. Все процедуры хранятся на диске в перемещаемом формате загрузки. Одним из преимуществ динамической загрузки является то, что неиспользуемая процедура никогда не загружается. Эта загрузка полезна, когда для ее эффективной обработки требуется большой объем кода.
Статические и динамические ссылки
Для выполнения задачи связывания используется компоновщик. Компоновщик — это программа, которая берет один или несколько объектных файлов, созданных компилятором, и объединяет их в один исполняемый файл.
- Статическая компоновка: пристатической компоновке компоновщик объединяет все необходимые программные модули в единую исполняемую программу. Таким образом, нет никакой зависимости от времени выполнения. Некоторые операционные системы поддерживают только статическое связывание, в котором библиотеки системного языка обрабатываются как любой другой объектный модуль.
- Динамическое связывание: основная концепция динамического связывания аналогична динамической загрузке. При динамической компоновке «заглушка» включается для каждой соответствующей ссылки на библиотечную подпрограмму. Заглушка — это небольшой фрагмент кода. Когда заглушка выполняется, она проверяет, находится ли нужная процедура уже в памяти или нет. Если он недоступен, программа загружает подпрограмму в память.
Обмен
Когда процесс выполняется, он должен находиться в памяти. Перекачка представляет собой процесс обмена процесс временно во вторичную память из в основной памяти, которая является быстрым, по сравнению с вторичной памятью. Подкачка позволяет запускать больше процессов и может быть помещена в память одновременно. Основная часть подкачки — это время передачи, а общее время прямо пропорционально объему подкачки памяти. Обмен также известен как развертывание, развертывание, потому что, если приходит процесс с более высоким приоритетом и ему требуется обслуживание, диспетчер памяти может заменить процесс с более низким приоритетом, а затем загрузить и выполнить процесс с более высоким приоритетом. После завершения высокоприоритетной работы,процесс с более низким приоритетом поменялись обратно в памяти и продолжал в процессе исполнения.

Непрерывное распределение памяти
Основная память должна задействовать как операционную систему, так и различные клиентские процессы. Таким образом, выделение памяти становится важной задачей операционной системы. Память обычно делится на два раздела: один для резидентной операционной системы и один для пользовательских процессов. Обычно нам нужно, чтобы несколько пользовательских процессов находились в памяти одновременно. Следовательно, нам нужно подумать о том, как выделить доступную память для процессов, которые находятся во входной очереди, ожидая ввода в память. При выделении смежной памяти каждый процесс содержится в одном непрерывном сегменте памяти.

Выделение памяти
Чтобы добиться правильного использования памяти, необходимо эффективно распределять память. Один из простейших методов распределения памяти — разделить память на несколько разделов фиксированного размера, и каждый раздел содержит ровно один процесс. Таким образом, степень мультипрограммирования определяется количеством разделов.
Распределение нескольких разделов : в этом методе процесс выбирается из входной очереди и загружается в свободный раздел. Когда процесс завершается, раздел становится доступным для других процессов.
Фиксированное распределение разделов: в этом методе операционная система поддерживает таблицу, в которой указывается, какие части памяти доступны, а какие заняты процессами. Изначально вся память доступна для пользовательских процессов и считается одним большим блоком доступной памяти. Эта доступная память известна как «отверстие». Когда процесс прибывает и ему требуется память, мы ищем достаточно большую дыру, чтобы сохранить этот процесс. Если требование выполняется, мы выделяем память для процесса, в противном случае оставляя остальную доступной для удовлетворения будущих запросов. При распределении памяти иногда возникают проблемы с динамическим распределением памяти, которые касаются того, как удовлетворить запрос размера n из списка свободных отверстий. Есть несколько решений этой проблемы:
First fit:-
При первой подгонке первое доступное свободное отверстие удовлетворяет требованиям назначенного процесса.

Здесь, на этой диаграмме, блок памяти размером 40 КБ является первым доступным свободным местом, в котором может храниться процесс A (размер 25 КБ), поскольку первые два блока не имели достаточного пространства памяти.
Best fit:-
В наиболее подходящем случае выделите наименьшее отверстие, которое достаточно велико для обработки требований. Для этого мы ищем весь список, если список не упорядочен по размеру.
Здесь, в этом примере, сначала мы просматриваем полный список и обнаруживаем, что последнее отверстие 25 КБ является наиболее подходящим отверстием для процесса A (размер 25 КБ).
В этом методе использование памяти максимально по сравнению с другими методами распределения памяти.
Worst fit:- В худшем случае выделите для обработки наибольшее доступное отверстие. Этот метод дает самое большое оставшееся отверстие.
Здесь, в этом примере, процесс A (размер 25 КБ) выделяется самому большому доступному блоку памяти, который составляет 60 КБ. Неэффективное использование памяти является серьезной проблемой в худшем случае.
Фрагментация
Фрагментация определяется как когда процесс загружается и удаляется после выполнения из памяти, он создает небольшую свободную дыру. Эти дыры не могут быть назначены новым процессам, потому что дыры не объединяются или не удовлетворяют требованиям процесса к памяти. Чтобы достичь определенной степени мультипрограммирования, мы должны уменьшить потери памяти или проблему фрагментации. В операционной системе два типа фрагментации:
Внутренняя фрагментация
Внутренняя фрагментация происходит, когда блоки памяти выделяются процессу больше, чем их запрошенный размер. Из-за этого остается некоторое неиспользуемое пространство, что создает проблему внутренней фрагментации.
Пример: предположим, что для распределения памяти используется фиксированное разделение, а размер блока в памяти различается: 3 МБ, 6 МБ и 7 МБ. Теперь приходит новый процесс p4 размером 2 МБ и требует блока памяти. Он получает блок памяти размером 3 МБ, но 1 МБ блочной памяти является пустой тратой и не может быть выделен другим процессам. Это называется внутренней фрагментацией.
Внешняя фрагментация
При внешней фрагментации у нас есть свободный блок памяти, но мы не можем назначить его процессу, потому что блоки не являются смежными.
Пример: Предположим (рассмотрим пример выше) три процесса p1, p2, p3 имеют размер 2 МБ, 4 МБ и 7 МБ соответственно. Теперь им выделяются блоки памяти размером 3 МБ, 6 МБ и 7 МБ соответственно. После выделения для процесса p1 и p2 осталось 1 МБ и 2 МБ. Предположим, что приходит новый процесс p4 и требует 3-мегабайтный блок памяти, который доступен, но мы не можем его назначить, потому что свободное пространство памяти не является непрерывным. Это называется внешней фрагментацией.
И первая, и самая подходящая системы для распределения памяти, подверженной внешней фрагментации. Для преодоления проблемы внешней фрагментации используется уплотнение. В технике уплотнения все свободное пространство памяти объединяется и образует один большой блок. Таким образом, это пространство может быть эффективно использовано другими процессами.
Другое возможное решение внешней фрагментации — позволить логическому адресному пространству процессов быть несмежным, что позволяет процессу выделять физическую память там, где последняя доступна.
Paging:
Paging — это схема управления памятью, которая устраняет необходимость непрерывного выделения физической памяти. Эта схема позволяет физическому адресному пространству процесса быть несмежным.
- Логический адрес или виртуальный адрес (представлен в битах): адрес, генерируемый ЦП.
- Логическое адресное пространство или виртуальное адресное пространство (представленное словами или байтами): набор всех логических адресов, сгенерированных программой.
- Физический адрес (представлен в битах): адрес, фактически доступный в блоке памяти.
- Физическое адресное пространство (выраженное словами или байтами): набор всех физических адресов, соответствующих логическим адресам.
- Если логический адрес = 31 бит, то логическое адресное пространство = 2 31слово = 2 G слов (1 G = 2 30 )
- Если логическое адресное пространство = 128 M слов = 2 7* 2 20 слов, то логический адрес = log 2 2 27 = 27 бит
- Если физический адрес = 22 бита, то физическое адресное пространство = 2 22слова = 4 M слов (1 M = 2 20 )
- Если физическое адресное пространство = 16 M слов = 2 4* 2 20 слов, то физический адрес = log 2 2 24 = 24 бита.
Преобразование виртуального адреса в физический выполняется блоком управления памятью (MMU), который является аппаратным устройством, и это преобразование известно как метод подкачки.
- Физическое адресное пространство концептуально разделено на несколько блоков фиксированного размера, называемых кадрами.
- Логическое адресное пространство также разделено на блоки фиксированного размера, называемые страницами.
- Размер страницы = Размер кадра
- Физический адрес = 12 бит, тогда физическое адресное пространство = 4 К слов
- Логический адрес = 13 бит, затем логическое адресное пространство = 8 К слов
- Размер страницы = размер кадра = 1 тыс. Слов (предположение)

Адрес, генерируемый ЦП, делится на
- Номер страницы (p):количество битов, необходимых для представления страниц в логическом адресном пространстве или номер страницы.
- Смещение страницы (d):количество битов, необходимых для представления определенного слова на странице или размер страницы логического адресного пространства, или номер слова страницы или смещение страницы.
Физический адрес делится на
- Номер кадра (f):количество битов, необходимых для представления кадра физического адресного пространства или кадра номера кадра.
- Смещение кадра (d):количество битов, необходимых для представления конкретного слова в кадре, или размер кадра в физическом адресном пространстве, или номер слова кадра, или смещение кадра.
Аппаратная реализация таблицы страниц может быть выполнена с использованием выделенных регистров. Но использование регистра для таблицы страниц является удовлетворительным только в том случае, если таблица страниц мала. Если таблица страниц содержит большое количество записей, мы можем использовать TLB (буфер просмотра трансляции), специальный небольшой аппаратный кеш для быстрого просмотра.
- TLB — это ассоциативная высокоскоростная память.
- Каждая запись в TLB состоит из двух частей: тега и значения.
- Когда эта память используется, то элемент сравнивается со всеми тегами одновременно. Если элемент найден, то соответствующее значение возвращается.

Время доступа к основной памяти = м
Если таблица страниц хранится в основной памяти,
Эффективное время доступа = m (для таблицы страниц) + m (для конкретной страницы в таблице страниц)

Одна из важнейших составляющих современного процессоры это IOMMU , что важно для связь процессора с система периферийными устройствами . В этой статье мы объясним, что это такое, и о функциях этого, столь неизвестного широкой публике, как важного элемента оборудования, присутствующего во всех типах компьютерных систем, от смартфона в кармане до самого мощного суперкомпьютера
Как периферийные устройства взаимодействуют с процессором? Использование ОЗУ системы в качестве общей точки для взаимной связи, но это подразумевает ряд механизмов, наиболее важным из которых является тот, который мы собираемся описать ниже.
Где находится IOMMU?
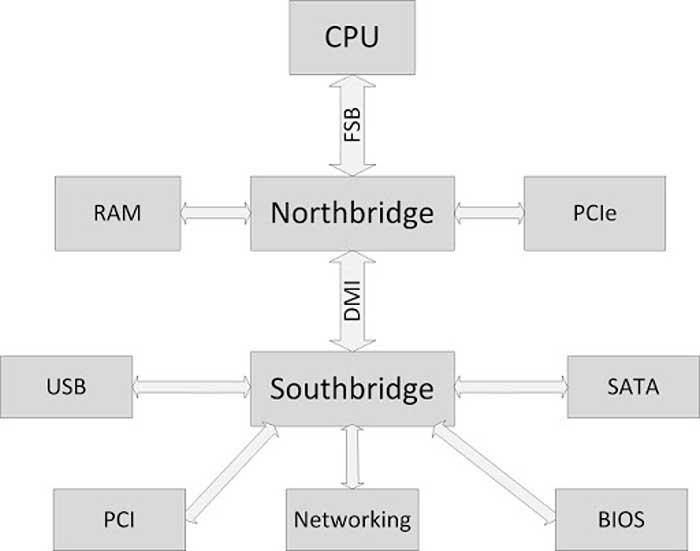
Как видно на схеме выше, периферийные устройства подключены к южному мосту или южному мосту, который, в свою очередь, подключен к северному мосту, который является концентратором, с которым, в основном, обмениваются данными интерфейс оперативной памяти и процессора. каждый. Что ж, IOMMU расположен внутри южного моста, где сосредоточены все интерфейсы ввода-вывода, такие как USB, PCI Express, SATA и т. Д.
Все эти интерфейсы должны находиться под управлением IOMMU для доступа к системной RAM. В этом случае IOMMU действует как своего рода пограничный контроль, который следит за тем, чтобы периферийные устройства не осуществляли незаконный доступ к памяти и не обращаются к той части ОЗУ, которая назначена каждому из них и никуда больше.
Таким образом, IOMMU действует как MMU, но для периферийных устройств ввода-вывода.
В чем его полезность?
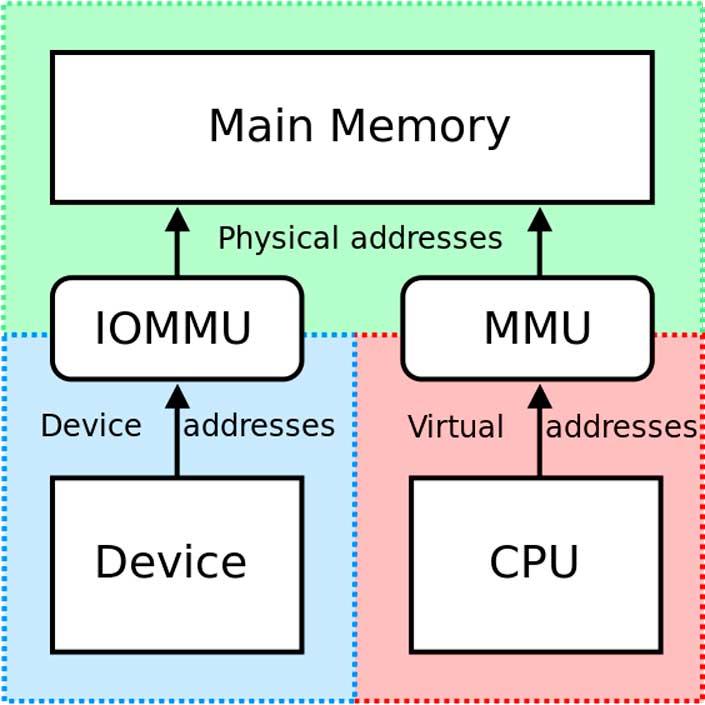
Периферийные устройства ввода-вывода не используют MMU (блок управления памятью) совместно с ЦП и, следовательно, не просматривают память так же, как центральный системный процессор. Эта проблема позволяет периферийным устройствам получать доступ к чувствительным частям системной памяти, например тем, которые зарезервированы для функций самой операционной системы, что является проблемой в многозадачных средах.
Здесь на помощь приходит IOMMU, выступающий в качестве ведомого устройства для MMU, с которым он связан через северный / северный мост системы. Благодаря этой связи периферийные устройства знают, к каким адресам RAM у них есть разрешение на доступ, а к каким - нет.
С другой стороны, IOMMU автоматически и динамически назначает адреса памяти для связи с различными периферийными устройствами, таким образом, ЦП всегда знает, на какие адреса памяти он должен указывать для связи с ними.
В более старых системах IOMMU не было доступно, и вместе с ними была предоставлена карта памяти, где программисты были проинформированы, какие адреса RAM предназначены для связи с устройствами. По этой причине разработчикам в каждой отдельной архитектуре приходилось изучать адресацию памяти, чтобы использовать периферийные устройства и другое поддерживающее оборудование в системе.
Сегодня это уже не так, и наличие IOMMU позволяет разработчикам избавиться от необходимости изучать адреса памяти для связи и расширяет возможности конфигурации и настройки наших ПК, позволяя создавать совершенно разные конфигурации.
Использование IOMMU в виртуализированных системах
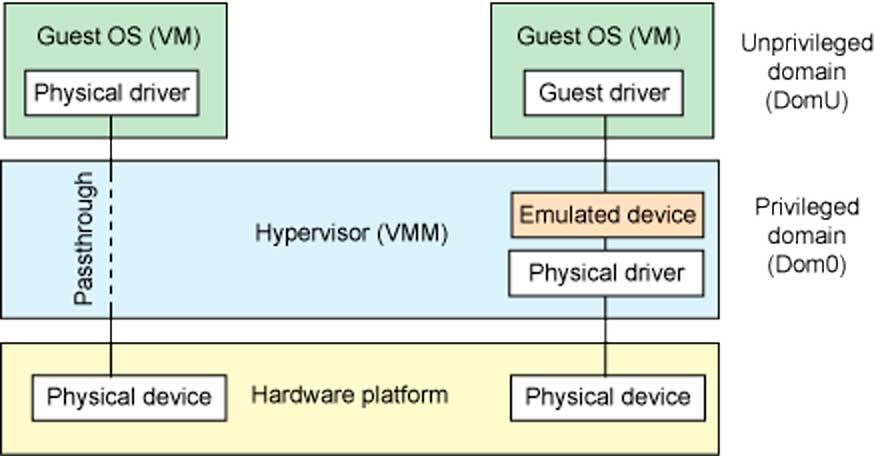
IOMMU обеспечивает безопасный доступ к физическим устройствам в виртуализированных средах посредством того, что мы называем сквозной передачей устройств. Тандем между MMU и IOMMU позволяет устройствам, подключенным к ПК, появляться в пространстве виртуальной памяти, которое выполняет функцию физической памяти для виртуальной среды, которая работает в данный момент.
Без IOMMU виртуализированные среды, которые имеют правильный доступ к оборудованию, установленному в системе, были бы невозможны, поэтому сегодня он является незаменимой частью всех процессоров, которым приходится обрабатывать виртуализированные среды.
Читайте также: