
Для запуска игры необходимо чтобы процессор поддерживал инструкции avx
Обновлено: 03.07.2024
Чтобы убедиться в работоспособности AVX кода лучше написать к нему Unit-тесты. Однако встаёт вопрос: как запустить эти Unit-тесты, если ни один ныне продаваемый процессор не поддерживает AVX? В этом вам поможет специальная утилита от Intel — Software Development Emulator (SDE). Всё, что умеет SDE — это запускать программы, на лету эмулируя новые наборы инструкций. Разумеется, производительность при этом будет далека от таковой на реальном железе, но проверить корректность работы программы таким образом можно. Использовать SDE проще простого: если у вас есть unit-тест для AVX кода в файле avx-unit-test.exe и его нужно запускать с параметром «Hello, AVX!», то вам просто нужно запустить SDE с параметрами
sde -- avx-unit-test.exe "Hello, AVX!"
При запуске программы SDE сэмулирует не только AVX инструкции, но также и инструкции XGETBV и CPUID, так что если вы используете предложенный ранее метод для детектирования поддержки AVX, запущенная под SDE программа решит, что AVX действительно поддерживается. Кроме AVX, SDE (вернее, JIT-компилятор pin, на котором SDE построен) умеет эмулировать SSE3, SSSE3, SSE4.1, SSE4.2, SSE4a, AES-NI, XSAVE, POPCNT и PCLMULQDQ инструкции, так что даже очень старый процессор не помешает вам разрабатывать софт под новые наборы инструкций.
Оценка производительности AVX кода
Некоторое представление о производительности AVX кода можно получить с помощью другой утилиты от Intel — Intel Architecture Code Analyzer (IACA). IACA позволяет оценить время выполнения линейного участка кода (если встречаются команды условных переходов, IACA считает, что переход не происходит). Чтобы использовать IACA, нужно сначала пометить специальными маркерами участки кода, которые вы хотите проанализировать. Маркеры выглядят следующим образом:
; Начало участка кода, который надо проанализировать
%macro IACA_START 0
mov ebx, 111
db 0x64, 0x67, 0x90
%endmacro
- -32 — означает, что входной объектный файл (MS COFF) содержит 32-битный код. Для 64-битного кода нужно указывать -64. Если на вход IACA подаётся не объектный файл (.obj), а исполняемый модуль (.exe или .dll), то этот аргумент можно не указывать.
- -arch AVX — показывает IACA, что нужно анализировать производительность этого кода на будущем процессоре Intel с поддержкой AVX (т.е. Sandy Bridge). Другие возможные значения: -arch nehalem и -arch westmere.
- -cp DATA_DEPENDENCY просит IACA показать, какие инструкции находятся на критическом путе для данных (т.е. какие инструкции нужно соптимизировать, чтобы результат работы этого кода вычислялся быстрее). Другое возможное значение: -cp PERFORMANCE просит IACA показать, какие инструкции «затыкают» конвеер процессора.
- -mark 0 говорит IACA проанализировать все помеченные маркерами участки кода. Если задать -mark n, IACA будет анализировать только n-ый размеченный участок кода.
- -o avx-sample задаёт имя файла, в который будут записаны результаты анализа. Можно опустить этот параметр, тогда результаты анализа будут выведены в консоль.
Analysis Report
---------------
Total Throughput: 2 Cycles; Throughput Bottleneck: FrontEnd, Port2_ALU, Port2_DATA, Port4
Total number of Uops bound to ports: 6
Data Dependency Latency: 14 Cycles; Performance Latency: 15 Cycles
N - port number, DV - Divider pipe (on port 0), D - Data fetch pipe (on ports 2 and 3)
CP - on a critical Data Dependency Path
N - number of cycles port was bound
X - other ports that can be used by this instructions
F - Macro Fusion with the previous instruction occurred
^ - Micro Fusion happened
* - instruction micro-ops not bound to a port
@ - Intel(R) AVX to Intel(R) SSE code switch, dozens of cycles penalty is expected
! - instruction not supported, was not accounted in Analysis
| Num of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | |
------------------------------------------------------------
| 1 | | | | 1 | 2 | X | X | | | CP | vmovups ymm0, ymmword ptr [ecx]
| 2^ | | | | X | X | 1 | 1 | | 1 | | vbroadcastss ymm1, dword ptr [edx]
| 1 | 1 | | | | | | | | | CP | vmulps ymm0, ymm0, ymm1
| 2^ | | | | 1 | | X | | 2 | | CP | vmovups ymmword ptr [ecx], ymm0
| 0* | | | | | | | | | | | vzeroupper
Самыми важными метриками здесь являются Total Throughput и Data Dependency Latency. Если код, который вы оптимизируете, это небольшая подпрограмма, и в программе есть зависимость по данным от её результата, то вам нужно стараться сделать Data Dependency Latency как можно меньше. В качестве примера может служить приведённый выше листинг подпрограммы vec4_dot_avx. Если же оптимизируемый код — это часть цикла, обрабатывающего большой массив элементов, то ваша задача — уменьшать Total Throughput (вообще-то эта метрика должна была бы называться Reciprocal Throughput, ну да ладно).
Использование AVX в коде на C/C++
- Microsoft C/C++ Compiler начиная с версии 16 (входит в Visual Studio 2010)
- Intel C++ Compiler начиная с версии 11.1
- GCC начиная с версии 4.4
- /arch:AVX — для Microsoft C/C++ Compiler и Intel C++ Compiler под Windows
- -mavx — для GCC и Intel C++ Compiler под Linux
- /QxAVX — для Intel C++ Compiler
- /QaxAVX — для Intel C++ Compiler
Определение поддержки AVX системой
- Windows 7
- Windows Server 2008 R2
- Linux с ядром 2.6.30 и выше
Нетрудно заметить, что маски XSTATE_MASK_* соответствуют аналогичным битам регистра XFEATURE_ENABLED_MASK.
В дополнение к этому, в Windows DDK есть описание функции RtlGetEnabledExtendedFeatures и констант XSTATE_MASK_XXX, как две капли воды похожих на GetEnabledExtendedFeatures и XSTATE_MASK_* из WinNT.h. Т.о. для определения поддержки AVX со стороны Windows можно воспользоваться следующим кодом:
int isAvxSupportedByWindows() const DWORD64 avxFeatureMask = XSTATE_MASK_LEGACY_SSE | XSTATE_MASK_GSSE;
return GetEnabledExtendedFeatures( avxFeatureMask ) == avxFeatureMask;
>
Если ваша программа должна работать не только в Windows 7 и Windows 2008 R2, то функцию GetEnabledExtendedFeatures нужно подгружать динамически из kernel32.dll, т.к. в других версиях Windows этой функции нет.
В Linux, насколько мне известно, нет отдельной функции, чтобы узнать о поддержке AVX со стороны ОС. Но вы можете воспользоваться тем фактом, что поддержка AVX было добавлена в ядро 2.6.30. Тогда остаётся только проверить, что версия ядра не меньше этого значения. Узнать версию ядра можно с помощью функции uname.
Использование AVX-инструкций
Тестирование AVX кода
Если вы используете набор инструкций AVX посредством intrinsic-функций, то, кроме запуска этого кода под эмулятором SDE, у вас есть ещё одна возможность — использовать специальный заголовочный файл, эмулирующий 256-битные AVX intrinsic-функции через intrinsic-функции SSE1-SSE4.2. В этом случае у вас получится исполняемый файл, который можно запустить на процессорах Nehalem и Westmere, что, конечно, быстрее эмулятора. Однако учтите, что таким методом не получиться обнаружить ошибки генерации AVX-кода компилятором (а они вполне могут быть).
Оценка производительности AVX кода
Использование IACA для анализа производительности AVX кода, созданного C/C++ компилятором из intrinsic-функций почти ничем не отличается от анализа ассемблерного кода. В дистрибутиве IACA можно найти заголовочный файл iacaMarks.h, в котором описаны макросы-маркеры IACA_START и IACA_END. Ими нужно пометить анализируемые участки кода. В коде подпрограммы маркер IACA_END должен находиться до оператора return, иначе компилятор «соптимизирует», выкинув код маркера. Макросы IACA_START/IACA_END используют inline-ассемблер, который не поддерживается Microsoft C/C++ Compiler для Windows x64, поэтому если для него нужно использовать специальные варианты макросов — IACA_VC64_START и IACA_VC64_END.
Заключение
В этой статье было продемонстрировано, как разрабатывать программы с использованием набора инструкций AVX. Надеюсь, что это знание поможет вам радовать своих пользователей программами, которые используют возможности компьютера на все сто процентов!
Оригинал и другие материалы на AlexseevDenis.blog .
Всем приветы ! Купленный ПК стареет с каждым днем, а программы и игры установленные на нем имеют свойство обновляться, ровно как и просто выходит что-то новое. И в один прекрасный момент можно столкнуться с тем, что программа или игра не запустится, ругаясь на то, что процессор не имеет поддержку каких-то инструкций, либо система не подходит под минимальные системные требования. Что с этим делать ? Погнали !
Внимание ! Есть риск повреждения вашего оборудования. Все действия производите на свой страх и риск !
Если вкратце, то проблема не решаема, без замены процессора. Новые инструкции в него не добавить.
1. Работать не будет вообще.
2. Работать будет в полу-аварийном режиме, при старте будет ругань о том, что установлен не поддерживаемый процессор и будет работать на низкой частоте и возможно без части инструкций. Хотя может и ругаться, а работать нормально.
3. Работать будет на свежей версии BIOS и без проблем.
4. Работать будет на модифицированной версии BIOS.
5. Работать на любых версиях будет как попало.
1. Не работает проц - тут все понятно.
2. Тут как пойдет, если все нормально пашет, пусть ругается. Но возможно отчасти поможет прошивка BIOS.
3. Тут все понятно, шьем последнюю версию и радуемся.
4. Модифицированная версия берется на просторах сети и в основном под конкретную материнку или семейство материнок.
5. Бывает, что все вроде опознается. Модель процессора правильная. Частота и количество ядер в норме. Инструкции задействованы, сон работает. Но мучают BSOD, оишбки в играх, ошибки при установке игр и программ и прочая нечисть. Тут скорее всего ничего не сделать, кроме замены камня.
Но это все больше про поддержку процессора материнской платой. Если требуется инструкция SSE4.2, а проц не знает ее, то ничего не поможет.
Но есть костыль под названием SDE или Software Development Emulator от корпорации Intel.
Свежая версия от марта 2020 года.
Есть адекватная и понятная инструкция на русском. Есть инструкция написанная чужими для хищников . Обе вроде рабочие, в том плане, что есть шанс, что поможет.
Но костыль он на то и костыль, он может не заработать или заработать но медленно. Попытка не пытка.
Чтобы убедиться в работоспособности AVX кода лучше написать к нему Unit-тесты. Однако встаёт вопрос: как запустить эти Unit-тесты, если ни один ныне продаваемый процессор не поддерживает AVX? В этом вам поможет специальная утилита от Intel — Software Development Emulator (SDE). Всё, что умеет SDE — это запускать программы, на лету эмулируя новые наборы инструкций. Разумеется, производительность при этом будет далека от таковой на реальном железе, но проверить корректность работы программы таким образом можно. Использовать SDE проще простого: если у вас есть unit-тест для AVX кода в файле avx-unit-test.exe и его нужно запускать с параметром «Hello, AVX!», то вам просто нужно запустить SDE с параметрами
sde -- avx-unit-test.exe "Hello, AVX!"
При запуске программы SDE сэмулирует не только AVX инструкции, но также и инструкции XGETBV и CPUID, так что если вы используете предложенный ранее метод для детектирования поддержки AVX, запущенная под SDE программа решит, что AVX действительно поддерживается. Кроме AVX, SDE (вернее, JIT-компилятор pin, на котором SDE построен) умеет эмулировать SSE3, SSSE3, SSE4.1, SSE4.2, SSE4a, AES-NI, XSAVE, POPCNT и PCLMULQDQ инструкции, так что даже очень старый процессор не помешает вам разрабатывать софт под новые наборы инструкций.
Оценка производительности AVX кода
Некоторое представление о производительности AVX кода можно получить с помощью другой утилиты от Intel — Intel Architecture Code Analyzer (IACA). IACA позволяет оценить время выполнения линейного участка кода (если встречаются команды условных переходов, IACA считает, что переход не происходит). Чтобы использовать IACA, нужно сначала пометить специальными маркерами участки кода, которые вы хотите проанализировать. Маркеры выглядят следующим образом:
; Начало участка кода, который надо проанализировать
%macro IACA_START 0
mov ebx, 111
db 0x64, 0x67, 0x90
%endmacro
- -32 — означает, что входной объектный файл (MS COFF) содержит 32-битный код. Для 64-битного кода нужно указывать -64. Если на вход IACA подаётся не объектный файл (.obj), а исполняемый модуль (.exe или .dll), то этот аргумент можно не указывать.
- -arch AVX — показывает IACA, что нужно анализировать производительность этого кода на будущем процессоре Intel с поддержкой AVX (т.е. Sandy Bridge). Другие возможные значения: -arch nehalem и -arch westmere.
- -cp DATA_DEPENDENCY просит IACA показать, какие инструкции находятся на критическом путе для данных (т.е. какие инструкции нужно соптимизировать, чтобы результат работы этого кода вычислялся быстрее). Другое возможное значение: -cp PERFORMANCE просит IACA показать, какие инструкции «затыкают» конвеер процессора.
- -mark 0 говорит IACA проанализировать все помеченные маркерами участки кода. Если задать -mark n, IACA будет анализировать только n-ый размеченный участок кода.
- -o avx-sample задаёт имя файла, в который будут записаны результаты анализа. Можно опустить этот параметр, тогда результаты анализа будут выведены в консоль.
Analysis Report
---------------
Total Throughput: 2 Cycles; Throughput Bottleneck: FrontEnd, Port2_ALU, Port2_DATA, Port4
Total number of Uops bound to ports: 6
Data Dependency Latency: 14 Cycles; Performance Latency: 15 Cycles
N - port number, DV - Divider pipe (on port 0), D - Data fetch pipe (on ports 2 and 3)
CP - on a critical Data Dependency Path
N - number of cycles port was bound
X - other ports that can be used by this instructions
F - Macro Fusion with the previous instruction occurred
^ - Micro Fusion happened
* - instruction micro-ops not bound to a port
@ - Intel(R) AVX to Intel(R) SSE code switch, dozens of cycles penalty is expected
! - instruction not supported, was not accounted in Analysis
| Num of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | |
------------------------------------------------------------
| 1 | | | | 1 | 2 | X | X | | | CP | vmovups ymm0, ymmword ptr [ecx]
| 2^ | | | | X | X | 1 | 1 | | 1 | | vbroadcastss ymm1, dword ptr [edx]
| 1 | 1 | | | | | | | | | CP | vmulps ymm0, ymm0, ymm1
| 2^ | | | | 1 | | X | | 2 | | CP | vmovups ymmword ptr [ecx], ymm0
| 0* | | | | | | | | | | | vzeroupper
Самыми важными метриками здесь являются Total Throughput и Data Dependency Latency. Если код, который вы оптимизируете, это небольшая подпрограмма, и в программе есть зависимость по данным от её результата, то вам нужно стараться сделать Data Dependency Latency как можно меньше. В качестве примера может служить приведённый выше листинг подпрограммы vec4_dot_avx. Если же оптимизируемый код — это часть цикла, обрабатывающего большой массив элементов, то ваша задача — уменьшать Total Throughput (вообще-то эта метрика должна была бы называться Reciprocal Throughput, ну да ладно).
Использование AVX в коде на C/C++
- Microsoft C/C++ Compiler начиная с версии 16 (входит в Visual Studio 2010)
- Intel C++ Compiler начиная с версии 11.1
- GCC начиная с версии 4.4
- /arch:AVX — для Microsoft C/C++ Compiler и Intel C++ Compiler под Windows
- -mavx — для GCC и Intel C++ Compiler под Linux
- /QxAVX — для Intel C++ Compiler
- /QaxAVX — для Intel C++ Compiler
Определение поддержки AVX системой
- Windows 7
- Windows Server 2008 R2
- Linux с ядром 2.6.30 и выше
Нетрудно заметить, что маски XSTATE_MASK_* соответствуют аналогичным битам регистра XFEATURE_ENABLED_MASK.
В дополнение к этому, в Windows DDK есть описание функции RtlGetEnabledExtendedFeatures и констант XSTATE_MASK_XXX, как две капли воды похожих на GetEnabledExtendedFeatures и XSTATE_MASK_* из WinNT.h. Т.о. для определения поддержки AVX со стороны Windows можно воспользоваться следующим кодом:
int isAvxSupportedByWindows() const DWORD64 avxFeatureMask = XSTATE_MASK_LEGACY_SSE | XSTATE_MASK_GSSE;
return GetEnabledExtendedFeatures( avxFeatureMask ) == avxFeatureMask;
>
Если ваша программа должна работать не только в Windows 7 и Windows 2008 R2, то функцию GetEnabledExtendedFeatures нужно подгружать динамически из kernel32.dll, т.к. в других версиях Windows этой функции нет.
В Linux, насколько мне известно, нет отдельной функции, чтобы узнать о поддержке AVX со стороны ОС. Но вы можете воспользоваться тем фактом, что поддержка AVX было добавлена в ядро 2.6.30. Тогда остаётся только проверить, что версия ядра не меньше этого значения. Узнать версию ядра можно с помощью функции uname.
Использование AVX-инструкций
Тестирование AVX кода
Если вы используете набор инструкций AVX посредством intrinsic-функций, то, кроме запуска этого кода под эмулятором SDE, у вас есть ещё одна возможность — использовать специальный заголовочный файл, эмулирующий 256-битные AVX intrinsic-функции через intrinsic-функции SSE1-SSE4.2. В этом случае у вас получится исполняемый файл, который можно запустить на процессорах Nehalem и Westmere, что, конечно, быстрее эмулятора. Однако учтите, что таким методом не получиться обнаружить ошибки генерации AVX-кода компилятором (а они вполне могут быть).
Оценка производительности AVX кода
Использование IACA для анализа производительности AVX кода, созданного C/C++ компилятором из intrinsic-функций почти ничем не отличается от анализа ассемблерного кода. В дистрибутиве IACA можно найти заголовочный файл iacaMarks.h, в котором описаны макросы-маркеры IACA_START и IACA_END. Ими нужно пометить анализируемые участки кода. В коде подпрограммы маркер IACA_END должен находиться до оператора return, иначе компилятор «соптимизирует», выкинув код маркера. Макросы IACA_START/IACA_END используют inline-ассемблер, который не поддерживается Microsoft C/C++ Compiler для Windows x64, поэтому если для него нужно использовать специальные варианты макросов — IACA_VC64_START и IACA_VC64_END.
Заключение
В этой статье было продемонстрировано, как разрабатывать программы с использованием набора инструкций AVX. Надеюсь, что это знание поможет вам радовать своих пользователей программами, которые используют возможности компьютера на все сто процентов!

Предупреждение отображается в cmd
Что вызывает это предупреждение?
После TensorFlow 1.6 двоичные файлы теперь используют инструкции AVX, которые могут больше не работать на старых процессорах. Таким образом, старые процессоры не смогут запускать AVX, в то время как для более новых ЦП пользователь должен построить тензорный поток из источника для своего ЦП. Ниже приведена вся информация, которую вам нужно знать об этом конкретном предупреждении. Также есть способ избавления от этого предупреждения для дальнейшего использования.
Что делает AVX?
В частности, AVX представил FMA (Fused multiply-add); которая является операцией умножения-сложения с плавающей точкой, и эта операция выполняется за один шаг. Это помогает ускорить многие операции без каких-либо проблем. Это делает вычисления алгебры более быстрыми и простыми в использовании, а также точечное произведение, умножение матриц, свертку и т. Д. И это все наиболее используемые и основные операции для любого обучения машинному обучению. Процессоры, которые поддерживают AVX и FMA, будут намного быстрее, чем старые. Но в предупреждении говорится, что ваш процессор поддерживает AVX, так что это хороший момент.
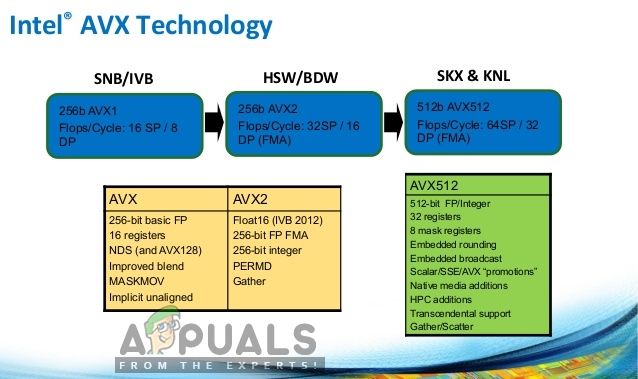
Технология Intel AVX
Почему он не используется по умолчанию?
Это связано с тем, что дистрибутив по умолчанию TensorFlow создается без расширений ЦП. Из-за расширений ЦП указываются AVX, AVX2, FMA и т. Д. Инструкции, которые вызывают эту проблему, не включены по умолчанию в доступных сборках по умолчанию. Причина, по которой они не включены, состоит в том, чтобы сделать это более совместимым с максимально возможным количеством процессоров. Также, чтобы сравнить эти расширения, они гораздо медленнее в процессоре, чем в графическом процессоре. Процессор используется в маломасштабном машинном обучении, в то время как использование ГПУ ожидается, когда он используется для обучения в среднем или крупномасштабном машинном обучении.
Исправление Предупреждение!
Если на вашем компьютере установлен графический процессор, вы можете игнорировать эти предупреждения от поддержки AVX. Потому что самые дорогие будут отправлены на устройстве с графическим процессором. И если вы хотите больше не видеть эту ошибку, вы можете просто проигнорировать ее, добавив:
импортировать Модуль ОС в коде вашей основной программы, а также установить объект сопоставления для него
Но если вы на Юникс, затем используйте команду экспорта в оболочке bash
Но если у вас нет графического процессора и вы хотите максимально использовать свой процессор, вам следует собрать TensorFlow из источника, оптимизированного для вашего процессора, с включенными здесь AVX, AVX2 и FMA.
Читайте также: