
Raid 5 замена жесткого диска
Обновлено: 04.07.2024
Чтобы компенсировать «врожденную» медлительность там, где она вообще не к месту (речь идет в первую очередь о серверах и высокопроизводительных ПК) придумали использовать так называемый дисковый массив RAID — некую «связку» из нескольких одинаковых винчестеров, работающих параллельно. Такое решение позволяет значительно поднять скорость работы вкупе с надежностью.
Что такое RAID массив и зачем он вам нужен
В первую очередь, RAID массив позволяет обеспечить высокую отказоустойчивость для жестких дисков (HDD) вашего компьютера, за счет объединения нескольких жестких дисков в один логический элемент. Соответственно, для реализации данной технологии вам понадобятся как минимум два жестких диска. Кроме того, RAID это просто удобно, ведь всю информацию, которую раньше приходилось копировать на резервные источники (флешки, внешние винчестеры), теперь можно оставить «как есть», ибо риск её полной потери минимален и стремится к нулю, но не всегда, об этом чуть ниже.
RAID переводится примерно так: защищенный набор недорогих дисков. Название пошло еще с тех времен, когда объемные винчестеры стоили сильно дорого и дешевле было собрать один общий массив из дисков, объемом поменьше. Суть с тех пор не поменялась, в общем-то как и название, только теперь можно сделать из нескольких HDD большого объема просто гигантское хранилище, либо сделать так, что один диск будет дублировать другой. А еще можно совместить обе функции, тем самым получить преимущества одной и второй.
Все эти массивы находятся под своими номерами, скорее всего вы о них слышали — рейд 0, 1. 10, то есть массивы разных уровней.
Разновидности RAID
Скоростной Рейд 0
Рейд 0 не имеет ничего схожего с надежностью, ведь он только повышает скорость. Вам необходимо как минимум 2 винчестера и в этом случае данные будут как бы «разрезаться» и записываться на оба диска одновременно. То есть вам будет доступен полностью объем этих дисков и теоретически это значит, что вы получаете в 2 раза более высокую скорость чтения/записи.
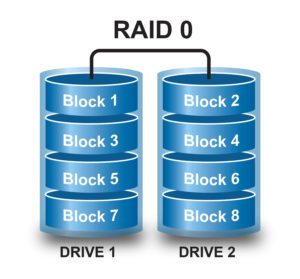
Но, давайте представим, что один из этих дисков сломался — в этом случае неизбежна потеря ВСЕХ ваших данных. Иначе говоря, вам все равно придется регулярно делать бекапы, чтобы иметь возможность потом восстановить информацию. Здесь обычно используется от 2 до 4 дисков.
Рейд 1 или «зеркало»
Тут надежность не снижается. Вы получаете дисковое пространство и производительность только одного винчестера, зато имеете удвоенную надежность. Один диск ломается — информация сохранится на другом.

Массив уровня RAID 1 не влияет на скорость, однако объем — тут в вашем распоряжении лишь половина от общего пространства дисков, которых, к слову, в рейд 1 может быть 2, 4 и т.д., то есть — четное количество. В общем, главной «фишкой» рейда первого уровня является надежность.
Рейд 10
Совмещает в себе все самое хорошее из предыдущих видов. Предлагаю разобрать — как это работает на примере четырех HDD. Итак, информация пишется параллельно на два диска, а еще на два других диска эти данные дублируются.

Как результат — увеличение скорости доступа в 2 раза, но и объем только лишь двух из четырех дисков массива. Но вот если любые два диска сломаются — потери данных не произойдет.
Рейд 5
Этот вид массива очень схож с RAID 1 по своему назначению, только теперь уже надо минимум 3 диска, один из них будет хранить информацию, необходимую для восстановления. К примеру, если в таком массиве находится 6 HDD, то для записи информации будут использованы всего 5 из них.

Из-за того, что данные пишутся сразу на несколько винчестеров — скорость чтения получается высокая, что отлично подойдет для того, чтобы хранить там большой объем данных. Но, без дорогущего рейд-контроллера скорость будет не сильно высокой. Не дай БОГ один из дисков поломается — восстановление информации займет кучу времени.
Рейд 6
Этот массив может пережить поломку сразу двух винчестеров. А это значит, что для создания такого массива вам потребуется как минимум четыре диска, при всем при том, что скорость записи будет даже ниже, нежели у RAID 5.

Учтите, что без производительного рейд-контроллера такой массив (6) собрать вряд ли удастся. Если у вас в распоряжении всего 4 винчестера, лучше собрать RAID 1.
Как создать и настроить RAID массив

Рейд массив можно сделать путем подключения нескольких HDD к материнской плате компьютера, поддерживающей данную технологию. Это означает, что у такой материнской платы есть интегрированный контроллер, который, как правило, встраивается в южный мост чипсета. Но, контроллер может быть и внешний, который подключается через PCI или PCI-E разъем. Каждый контроллер, как правило, имеет свое ПО для настройки.
Рейд может быть организован как на аппаратном уровне, так и на программном, последний вариант — наиболее распространен среди домашних ПК. Встроенный в материнку контроллер пользователи не любят за плохую надежность. Кроме того в случае повреждения материнки восстановить данные будет очень проблематично. На программном уровне роль контроллера играет центральный процессор, в случае чего —можно будет преспокойно перенести ваш рейд массив на другой ПК.
Аппаратный
Как же сделать RAID массив? Для этого вам необходимо:
- Достать где-то материнскую плату с поддержкой рейда (в случае аппаратного RAID);
- Купить минимум два одинаковых винчестера. Лучше, чтобы они были идентичны не только по характеристикам, но и одного производителя и модели, и подключались к мат. плате при помощи одного интерфейса.
- Перенесите все данные с ваших HDD на другие носители, иначе в процессе создания рейда они уничтожатся.
- Далее, в биосе потребуется включить поддержку RAID, как это сделать в случае с вашим компьютером — подсказать не могу, по причине того, что биосы у всех разные. Обычно этот параметр называется примерно так: «SATA Configuration или Configure SATA as RAID».
- Затем перезагрузите ПК и должна будет появиться таблица с более тонкими настройками рейда. Возможно, придется нажать комбинацию клавиш «ctrl+i» во время процедуры «POST», чтобы появилась эта таблица. Для тех, у кого внешний контроллер скорее всего надо будет нажать «F2». В самой таблице жмем «Create Massive» и выбираем необходимый уровень массива.
После создания raid массива в BIOS, необходимо зайти в «управление дисками» в ОС Windows 7–10 и отформатировать не размеченную область — это и есть наш массив.
Программный
Для создания программного RAID ничего включать или отключать в BIOS не придется. Вам, по-сути, даже не нужна поддержка рейда материнской платой. Как уже было упомянуто выше, технология реализовывается за счет центрального процессора ПК и средств самой винды. Ага, вам даже не нужно ставить никакое стороннее ПО. Правда таким способом можно создать разве что RAID первого типа, который «зеркало».
Жмем правой кнопкой по «мой компьютер»—пункт «управление»—«управление дисками». Затем щелкаем по любому из жестких, предназначенных для рейда (диск1 или диск2) и выбираем «Создать зеркальный том». В следующем окне выбираем диск, который будет зеркалом другого винчестера, затем назначаем букву и форматируем итоговый раздел.
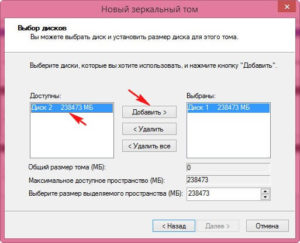
В данной утилите зеркальные тома подсвечиваются одним цветом (красным) и обозначены одной буквой. При этом, файлы копируются на оба тома, один раз на один том, и этот же файл копируется на второй том. Примечательно, что в окне «мой компьютер» наш массив будет отображаться как один раздел, второй раздел как бы скрыт, чтобы не «мозолить» глаза, ведь там находятся те же самые файлы-дубли.
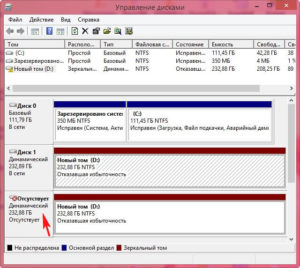
Если какой то винчестер выйдет из строя, появится ошибка «Отказавшая избыточность», при этом на втором разделе все останется в сохранности.
Подытожим
RAID 5 нужен для ограниченного круга задач, когда гораздо большее (чем 4 диска) количество HDD собрано в огромные массивы. Для большинства юзеров рейд 1 — лучший вариант. К примеру, если есть четыре диска емкостью 3 терабайта каждый — в RAID 1 в таком случае доступно 6 терабайт объема. RAID 5 в этом случае даст больше пространства, однако, скорость доступа сильно упадет. RAID 6 даст все те же 6 терабайт, но еще меньшую скорость доступа, да еще и потребует от вас дорогого контроллера.
Добавим еще RAID дисков и вы увидите, как все поменяется. Например, возьмем восемь дисков все той же емкости (3 терабайта). В RAID 1 для записи будет доступно всего 12 терабайт пространства, половина объема будет закрыта! RAID 5 в этом примере даст 21 терабайт дискового пространства + можно будет достать данные из любого одного поврежденного винчестера. RAID 6 даст 18 терабайт и данные можно достать с любых двух дисков.
В общем, RAID — штука не дешевая, но лично я бы хотел иметь в своем распоряжении RAID первого уровня из 3х-терабайтных дисков. Есть еще более изощренные методы, вроде RAID 6 0, или «рейд из рейд массивов», но это имеет смысл при большом количестве HDD, минимум 8, 16 или 30 — согласитесь, это уже далеко выходит за рамки обычного «бытового» использования и пользуется спросом по большей части в серверах.
Вот как-то так, оставляйте комментарии, добавляйте сайт в закладки (для удобства), будет еще много интересного и полезного, и до скорых встреч на страницах блога!
Допустим, у сервера 2 диска: /dev/sda и /dev/sdb . Эти диски собраны в софтверный RAID1 с помощью утилиты mdadm --assemble .
Один из дисков вышел из строя, например, это /dev/sdb . Повержденный диск нужно заменить.
Примечание: перед заменой диска желательно убрать диск из массива.
Удаление диска из массива
Проверьте, как размечен диск в массиве:
В данном случае массив собран так, что md0 состоит из sda2 и sdb2 , md1 — из sda3 и sdb3 .
На этом сервере md0 — это /boot , а md1 — своп и корень.
Удалите sdb из всех устройств:
Если разделы из массива не удаляются, то mdadm не считает диск неисправным и использует его, поэтому при удалении будет выведена ошибка, что устройство используется.
В этом случае перед удалением пометьте диск как сбойный:
Снова выполните команды по удалению разделов из массива.
После удаления сбойного диска из массива запросите замену диска, создав тикет с указанием s/n сбойного диска. Наличие downtime зависит от конфигурации сервера.
Определение таблицы разделов (GPT или MBR) и ее перенос на новый диск
После замены поврежденного диска нужно добавить новый диск в массив. Для этого надо определить тип таблицы разделов: GPT или MBR. Для этого используется gdisk .
Где /dev/sda — исправный диск, находящийся в RAID.
Для MBR в выводе будет примерно следующее:
Для GPT примерно следующее:
Перед добавлением диска в массив на нем нужно создать разделы в точности такие же, как и на sda . В зависимости от разметки диска это делается по-разному.
Копирование разметки для GPT
Для копирования разметки GPT:
Обратите внимание! Здесь первым пишется диск, на который копируется разметка, а вторым — с которого копируется (то есть с sda на sdb ). Если перепутать их местами, то разметка на изначально исправном диске будет уничтожена.
Второй способ копирования разметки:
После копирования присвойте диску новый случайный UUID:
Копирование разметки для MBR
Для копирования разметки MBR:
Обратите внимание! Здесь первым пишется диск, с которого копируется разметка, а вторым — на который копируется.
Если разделы не видны в системе, то можно перечитать таблицу разделов командой:
Добавление диска в массив
Если на /dev/sdb созданы разделы, то можно добавить диск в массив:
После добавления диска в массив должна начаться синхронизация. Скорость зависит от размера и типа диска (ssd/hdd):
Установка загрузчика
После добавления диска в массив нужно установить на него загрузчик.
Если сервер загружен в нормальном режиме или в infiltrate-root , то это делается одной командой:
Если сервер загружен в Recovery или Rescue-режиме (т.е. с live cd), то для установки загрузчика:
Смонтируйте корневую файловую систему в /mnt :
Смонтируйте /dev , /proc и /sys :
Выполните chroot в примонтированную систему:
Установите grub на sdb :
Затем попробуйте загрузиться в нормальный режим.
Как заменить диск, если он сбойный
Диск в массиве можно условно сделать сбойным с помощью ключа --fail (-f) :
Сбойный диск можно удалить с помощью ключа --remove (-r) :
Добавить новый диск в массив можно с помощью ключей --add (-a) и --re-add :
>>
Когда происходит выход из строя (полный или частичный) одного из дисков группы типа RAID-5, то RAID-группа переходит в состояние degraded, но наши данные остаются доступными, так как недостающая часть их может быть восстановлена за счет избыточной информации того самого «дополнительного объема, размером в один диск». Правда обычно быстродействие дисковой группы резко падает, так как при чтении и записи выполняются дополнительные операции вычислений избыточности и восстановления целостности данных. Если мы вставим вместо вышедшего из строя новый диск, то умный RAID-контроллер начнет процедуру rebuild, «перестроения», для чего начнет считывать со всех дисков оставшиеся данные, и, на основании избыточной информации, заполнит новый, ранее пустой диск недостающей, пропавшей вместе со сдохшим диском частью.
Если вы еще не сталкивались с процессом ребилда RAID-5, вы, возможно, будете неприятно поражены тем, насколько длительным этот процесс может быть. Длительность эта зависит от многих факторов, и, кроме количества дисков в RAID-группе, и их заполненностью, что очевидно, в значительной степени зависит от мощности процессора RAID-контроллера и производительности диска на чтение/запись. А также от рабочей нагрузки на дисковый массив во время проведения ребилда, и от приоритета процесса ребилда по сравнению с приоритетом рабочей нагрузки.
Если вам не посчастливилось потерять диск в разгар рабочего дня или рабочей недели, то процесс ребилда, и так небыстрый, может удлинниться в десятки раз.
А с выходом все более и более емких дисков, уровни быстродействия которых, как мы помним, почти не растут, в сравнении с емкостью, время ребилда растет угрожающими темпами, ведь, как уже писалось выше, скорость считывания с дисков, от которой напрямую зависит скорость прохождения ребилда, растет гораздо медленнее, чем емкость дисков и объем, который нужно считать.
Так, в интернете легко можно найти истории, когда сравнительно небольшой 4-6 дисковый RAID-5 из 500GB дисков восстанавливал данные на новый диск в течении суток, и более.
С использованием же терабайтных и двухтерабайтных дисков приведенные цифры можно смело умножать в 2-4 раза!
И вот тут начинаются страсти.
Дело в том, и это надо себе трезво уяснить, что на время ребилда RAID-5 вы остаетесь не просто с RAID лишенным отказоустойчивости. Вы получаете на все время ребилда RAID-0
RAID-5 в состоянии "degraded" эквивалентна отсутствию RAID вообще.
Поэтому лучшей стратегий будет забрать оттуда остатки информации, т.е. сделать бэкап.
Это будет медленно, но это ещё возможно.
Ребилд массива повысит вероятность выхода из строя оставшихся дисков и тогда вы не сможете сделать бэкап даже медленно.
Продолжим цитирование
>>
Так, например, для 6-дискового RAID-5 с дисками 1TB величина отказа по причине BER оценивается в 4-5%, а для 4TB дисков она же будет достигать уже 16-20%.
Эта холодная цифра означает, что с 16-20-процентной вероятностью вы получите отказ диска во время ребилда (и, следовательно, потеряете все данные на RAID). Ведь для ребилда, как правило, RAID-контроллеру придется прочитать все диски, входящие в RAID-группу, для 6 дисков по 1TB объем прочитанного RAID-контроллером потока данных с дисков достигает 6TB, для 4TB он уже станет равным 24TB.
24TB это, при BER 10^15, четверть от 110TB.
Но даже и это еще не все.
Как показывает практика, примерно 70-80% данных, хранимых на дисках, это так называемые cold data. Это файлы, доступ к которым сравнительно редок. С увеличением емкости дисков их объем в абсолютном исчислении также растет. Огромный объем данных лежит, зачастую, нетронутый никем, даже антивирусом (зачем ему проверять гигабайтные рипы и mp3?), месяцами, а возможно и годами.
Ошибка данных, пришедшаяся на массив cold data обнаружится только лишь в процессе полного чтения содержимого диска, на процесс ребилда.
>>
Итак, ребилд массива с вероятностью 20% приведёт к ошибке и развалу всего RAID.
Из-за чтения дурацких "cold data" вы с вероятностью 20% потеряете ценнейшие "hot data".
3. Повышенная нагрузка на диски в период восстановления потенциально еще повышает вероятность сбоя. (14) При попытке сделать бэкап произойдет ровно то же самое.
Чем раньше будет выявлена ошибка или нестабильность в данных, тем лучше. Конечно, лучше при бэкапе, чем при ребилде.
С другой стороны, если бэкап грамотный, он холодные данные не будет читать, только изменившиеся.
Поэтому для особо важных данных еще отдельно scrubbing делают.
А вообще, BER - это чисто маркетологический параметр. Делают одинаковые диски, в них заливают немного разные прошивки - и вуаля: у одного диска BER 10e14, а у другого - 10e16. В реальности вероятность ошибки гораздо ниже, при этом совсем не факт что она вообще будет обнаружена. НЯП, изначально эта цифра рассчитывалась как вероятность ошибке при "безошибочном" чтении. Т.е. вероятность того, что ошибка будет пропущена, и считанные данные будут неверными. Т.е. это вероятность искажения данных, а не read error.
Вероятность отказа дисков при ребилде вычисляется исходя из MTBF. Т.е., например, если 6-дисковый массив ребилдится сутки - наработка составит 6*24 часа, что, например, при 1,2 млн. часов MTBF дает вероятность 0,012%. Если бы это было не так - в датацентрах требовалась бы куча админов для жонглирования дисками.
хочу заменить все винты в RAID массиве на более емкие, но никогда не делал этого раньше. Не могли бы вы посоветовать как это сделать?
Перечитал кучу информации, но остались не ясные моменты.
Можете написать последовательность действий?
Имеется сервер FreeBSD 6.2 (32-bit), RAID контроллер 3ware 9650SE-4LPML (4ех портовый, SATA). Работает в режиме RAID5. Стоят 4 одинаковых винта по 400Гб (общий объем массива чуть больше 1Тб). Все порты контроллера задействованы. Файловая система юнита подмонтирована в папку /data.
Как я понял для системы используется отдельный диск не подключенный к 3ware. Хочу поменять эти 4 диска на другие 4 диска по 2 Тб каждый. Вроде бы смотрел в инете, что эта версия FreeBSD, файловая система UFS2 и контроллер поддерживают тома более 2 Tb. Они будут использоваться только для хранения данных, а не для зарузки. Но непонятно, что насчет юзеров, использующих, Windows 7 Pro (32-bit) смогут ли они увидеть этот сетевой диск (размер как я понимаю будет около
На передней панели корпуса сервера 4 корзины с индикаторами. Как понять какой диск подключен к какому порту не разбирая корпус, чтобы не вытащить не тот диск?
И еще: то есть после того как командой отсоединили диск от массива, его можно сразу физически вынимать из корпуса? Как понять поддерживатся ли hot spare? это должно быть в спецификации корзинки для дисков?
Rebuild сам должен сделаться когда вставлю физически диск и сделаю rescan? или самому каждый раз делать?
Извиняюсь за свои вопросы, но повторю раньше этого никогда не делал.
Желательно подробней напишите как проделать эту процедуру. В инете в основном теория написана.
Какие могут быть подводные камни?
| Конфигурация компьютера | |
| Процессор: Intel(R) Core(TM) i5-4278U CPU @ 2.60GHz | |
| Память: PC3-12800 2x4Gb | |
| HDD: APPLE SSD SM0256F 250GB | |
| Видеокарта: Intel(R) Iris 5100 | |
| Блок питания: MAGSafe 2 60W | |
| Ноутбук/нетбук: MacBook Pro MGX82RS/A | |
| ОС: OS X 10.10.1 Yosemite |
Не выйдет такой фокус. На каждом из 2Тбайтников будет использоваться только 400Гб, остальное пространство останется незадействованным и в итоге вы останетесь с массивом старого размера. Да и зачем вся эта катавасия, если будет сделан бекап?? Предлагаю такую последовательность действий:
1. Забекапить все на внешний USB-винт, остановив предварительно все сервисы, могущие писать на заменяемый массив, предупредив юзеров о простое.
1a. UPD (забыл, а это важно, иначе система завалится в панику на следующем этапе) Отмонтировать /data
2. Удалить массив при помощи утилиты менеджмента и снять старые диски.
3. Поставить новые диски и создать из них новый массив.
4. Создать на новом массиве таблицу разделов GPT (>2Тб ведь том теперь), сам раздел, отформатировать и смонтировать его. Не забыть отредактировать fstab.
5. Развернуть бекап с внешнего носителя на свежесозданный раздел.
6. Запустить сервисы, упомянутые в п.1 и дать отмашку юзерам.

Сегодня не самый обычный пост, я еду в ЦОД менять и устанавливать диски. Любопытно, что все диски разные, оборудование тоже разное. Для мониторинга состояния дисков потребуется самые разные инструменты. Вроде бы всего 4 диска, а подходы самые разные. Поехали.
Диск 1. Сервер Supermicro
Первый диск будем менять в сервере Supermicro. Сервер Supermicro 4U: CSE-846BE16-R920B. Когда-то давно на нём собирали массивы:
Диск HDD 6ТБ, форм-фактор 3.5'. Вот так выглядит сбойный диск, красный светодиод манит админа.

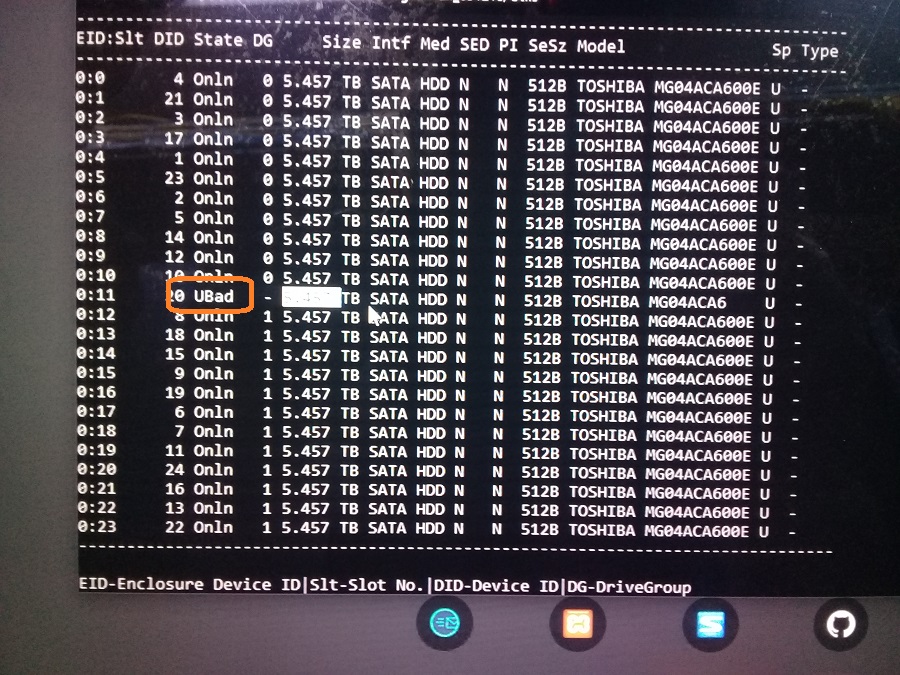
Перед заменой диска необходимо убедиться, что проблема именно с диском. Сервер работает, выключить его нельзя. Соответственно, в утилиту Avago Config Utility для управления SAS-контроллером войти не удастся. На сервере работает операционная система Ubuntu. Для мониторинга состояния массива будем использовать утилиту storcli. Пример работы у меня уже есть, правда в Oracle Linux, но в данном случае это не принципиально:
Посмотрим, что у нас там с диском. Диск в состоянии "UBad-Unconfigured Bad". Всё понятно, нужно менять.
Данный сервер поддерживает горячую замену дисков, мне же проще. Выдергиваем старый диск.

Красный светодиод продолжает гореть на дисковой корзине. Перекручиваем салазки на новый диск.

Устанавливаем диск в слот.

После установки диска загорится синий диод, красный начнёт мигать.

Начинается перестроение массива. Перестроение займёт много времени, больше суток.

Потом, через пару дней проверил, массив в порядке:

Замена диска прошла без проблем.
Диск 2. СХД HP MSA 2040
Второй диск меняю в СХД MSA 2040. Ранее уже менял подобные диски:
Диск HDD 900ГБ, форм-фактор 2.5', поставляется с салазками для MSA. Для управления дисками используется утилита Storage Management Utility, вот так там выглядит дохлый диск:

Он же на MSA с оранжевым светодиодом:

Извлекаю старый диск.


Распаковываю новый диск.

Устанавливаю новый диск.


Теперь нужно зайти в Storage Management Utility и добавить этот диск как Global Spare.

Сразу скажу, что после этого новый диск вышел из строя. Жду ответа техподдержки, замена диска оказалась неуспешной.
Диск 3. Сервер HP ProLiant DL360 Gen9
Третий диск меняю в сервере HP ProLiant DL360 Gen9. Не первый раз меняю диски в этих серверах:
Диск HDD 1ТБ, форм-фактор 2.5', поставляется с салазками. Битый диск светится оранжевым:

Для мониторинга состояния дисков в серверах ProLiant девятого поколения используется утилита iLO 4. Скриншоты не делал. но там тоже видно какой диск вышел из строя.
Извлекаю битый диск.

Устанавливаю новый диск.

Всё просто, салазки перекручивать не нужно, операция быстрая. На всех дисках массива горит индикатор "не извлекать", начинается перестроение массива.
Диск 4. Сервер HPE ProLiant DL360 Gen9. NVMe.
Четвёртый диск не получится установить в работающий сервер. Диск представляет собой PCIe плату NVMe.

Устанавливаем в сервер HPE ProLiant DL360 Gen9. Выключаем сервер, выдвигаем на салазках, снимаем крышку.

В данный сервер можно установить одну полноразмерную PCIe плату и две низкопрофильные. Второй и третий слоты я уже занял, диск будет устанавливаться в первый полноразмерный слот. Снимаю райзер, понадобится отвертка torx.

Кручу-верчу. В райзер устанавливается две PCIe платы. Одна уже установлена, устанавливаю вторую.

Диск в райзере. Устанавливаю райзер в сервер.

Закрываю крышку, включаю сервер. NVMe платы нельзя собрать в RAID через имеющийся RAID контроллер, у меня они собраны с помощью mdadm в операционной системе Ubuntu. Два диска были в RAID1, третий диск позволит увеличить объём массива в два раза, с преобразованием RAID1 в RAID5.
Потом
Забегая вперёд можно сказать, что три из четырёх дисков встали нормально, массивы работают в штатном режиме. А вот четвёртый диск HP MSA 2040 подкачал, новый и не заработал. Техподдержка пока молчит.
Потом-потом
Прислали новый диск для HP MSA 2040, со второй попытки диск встал успешно, пришлось ехать в ЦОД ещ1 раз.
Читайте также: