
Замена диска в сервере hp
Обновлено: 06.07.2024
В данной статье рассмотрим процесс увеличения размера Raid массива HPE Smart Array P420i, заменив диски на большие по размеру. После этого расширим хранилище данных (Expand Datastore) на Hypervisor Esxi 6 и Esxi 7
Содержание
Введение
Все чаще стали возникать задачи, связанные с нехваткой места на сервере. Когда файловое хранилище создано на базе Synology, увеличить размер относительно простая задача. Об этом Вы можете прочитать в нашей статье "Как увеличить размер массива на Synology, замена диска".
Но когда мы говорим про увеличение места на серверах Гипервизорах, например Esxi или Hyper-V, процесс немного усложняется. Давайте разберем случай, когда у нас есть сервер HP dl360 gen8, на нем создан Raid массив 1 (зеркало) из двух дисков по 1TB.
На этом сервере на флэшку установлен гипервизор Esxi 6.7 (HPE Customized image). Как и зачем это сделано, Вы можете прочитать в нашей статье Установка Esxi на флэшку или SD карту HPE
В Esxi создано хранилище данных (Datastore) на весь размер Raid-массива, т.е. 1 TB. На сервере Esxi работают виртуальные машины, которые находятся на этом Datastore.
Нам нужно заменить два диска 1TB на два диска 4TB. После этого расширить существующее Datastore (хранилище данных).
Естественно, основная задача системного администратора обеспечить сохранность данных и минимальный простой оборудования (не забываем, что на Esxi работают виртуальные машины).
Описание тестового стенда
- Сервер HP dl360 gen8
- Raid - контроллер Smart Array P420i
- ОС-гипервизор Esxi 6.7 (HPE Customized image)
- Диски: WD Red Raid edition 1TB - 2шт. и WD Red Raid edition 4TB - 2шт.
План работ. Краткое описание действий
- На включенном сервере меняем диск с 1TB на 4 TB (горячая замена). Ждем, пока восстановится массив Raid1
- На включенном сервере меняем второй 1 TB диск (горячая замена) на второй 4 TB и ждем пока снова восстановится массив Raid1
- Проверяем через iLo, что все восстановилось
- Расширяем через hpssacli логический раздел с 1TB до 4 TB
- Проверяем через hpssacli, что логический диск расширился
- Перезагружаем сервер
- Расширяем Хранилище данных (Expand Datastore) в Esxi
Увеличение размера Raid1 (зеркало) Smart Array P420i . Замена дисков на большие по размеру.
На этом шаге главное не торопиться. Если массивы восстановятся некорректно, можно потерять данные на дисках.
Для начала заменим первый диск размером 1 TB на диск размером 4TB. Это можно делать, не выключая сервер "горячая замена".
После этого ждем и наблюдаем. Нам важно:
- Состояние массива в iLo
- Индикация на салазках жёстких дисков
Состояние в iLo будет меняться следующим образом.
После отключения первого диска, до замены его на 4TB, мы увидим:
После подключения (замены) 4TB диска:
Через некоторое время статус изменится на:
После завершения восстановления Raid-массива:
Состояние индикаторов на салазках HPE Gen8, Gen9, Gen10 будет меняться следующим образом.
После отключения первого диска, до замены его на 4TB, мы увидим:
- "Не снимайте" - Насыщенный белый (диск на 1TB)
- "Активное кольцо" - диск работает (диск на 1TB)
После подключения (замены) 4TB диска:
- "Не снимайте" - Насыщенный белый (диск на 1TB)
- "Активное кольцо" - Вращается по кругу зеленым. Диск работает (диск на 1TB)
- "Состояние привода" - мигает зелёным - Привод выполняет восстановление (Диск на 4TB)
- "Активное кольцо" - Вращается по кругу зеленым. Диск работает (диск на 4TB)
После завершения восстановления Raid-массива:
- "Состояние привода" - горит зелёным (на обоих дисках)
- "Активное кольцо" - Вращается по кругу зеленым (на обоих дисках)
После того как Raid-массив восстановился и его статус стал "OK", аналогичным образом меняем второй диск объёмом 1TB на диск объёмом 4 TB
После замены обоих дисков массива на 4TB переходим к расширению логического диска с помощью утилиты hpssacli
Расширение логического раздела через утилиту hpssacli
Перед тем как расширять логический диск Обязательно убедитесь, что Raid-массив восстановился и находится в состоянии "ОК"
Для расширения логического диска Raid-массива подключимся по ssh к серверу Esxi. Если Вы не знаете, как это сделать, прочитайте нашу статью Как подключиться к серверу ESXI по SSH
Для расширения логического диска нам понадобится информация:
- Номер слота Raid-контроллера slot
- Номер логического диска ld
Эту информацию можно получить выполнив команды:
В нашем случае slot=0, а ld=1
Для большего понимания можете изучить другие команды утилиты hpssacli в нашей статье Команды для ssacli hpssacli для работы с RAID на ESXI
Переходим к расширению логического диска. Для этого выполняем команду
В параметре size можно указать конкретный размер. Мы же расширяем диск на весь возможный объём (size=max).
После выполнения команды проверяем, что все прошло успешно. Логический диск увеличился в размерах и стал 4 TB
Если после этих действий подключиться к Esxi и попробовать расширить хранилище данных (Datastore), Вы увидите, что место не увеличилось.

esxi expand datastore failure
Для того чтобы гипервизор Esxi увидел, что логический диск увеличился, нужно перезагрузить сервер. Не забудьте корректно завершить работу виртуальных машин.
Перезагружаем сервер
Расширение хранилища данных (Expand Datastore)
После перезагрузки заходим в Esxi через веб. интерфейс и переходим в раздел Storage.
Выбираем нужное нам хранилище данных (Datastore) и нажимаем "Increase capacity".
В открывшемся мастере "Increase datastore capacity" выбираем "Expand an existing VMFS datastore extent". Нажимаем "Next".
На следующем шаге видим, что у нас появился диск на котором можно расширить хранилище данных (Datastore). Выбираем его и нажимаем "Next".

esxi expand datastore
На шаге 3 "Select partitioning options" выбираем на сколько нужно расширить хранилище данных (Datastore) и нажимаем "Next".

esxi expand datastore partition
Проверяем все ли верно и нажимаем "Finish"

esxi expand datastore partition finish
После этого хранилище данных (Datastore) будет увеличено. В нашем случае с 1 TB до 4 TB.

Сегодня не самый обычный пост, я еду в ЦОД менять и устанавливать диски. Любопытно, что все диски разные, оборудование тоже разное. Для мониторинга состояния дисков потребуется самые разные инструменты. Вроде бы всего 4 диска, а подходы самые разные. Поехали.
Диск 1. Сервер Supermicro
Первый диск будем менять в сервере Supermicro. Сервер Supermicro 4U: CSE-846BE16-R920B. Когда-то давно на нём собирали массивы:
Диск HDD 6ТБ, форм-фактор 3.5'. Вот так выглядит сбойный диск, красный светодиод манит админа.

Перед заменой диска необходимо убедиться, что проблема именно с диском. Сервер работает, выключить его нельзя. Соответственно, в утилиту Avago Config Utility для управления SAS-контроллером войти не удастся. На сервере работает операционная система Ubuntu. Для мониторинга состояния массива будем использовать утилиту storcli. Пример работы у меня уже есть, правда в Oracle Linux, но в данном случае это не принципиально:
Посмотрим, что у нас там с диском. Диск в состоянии "UBad-Unconfigured Bad". Всё понятно, нужно менять.
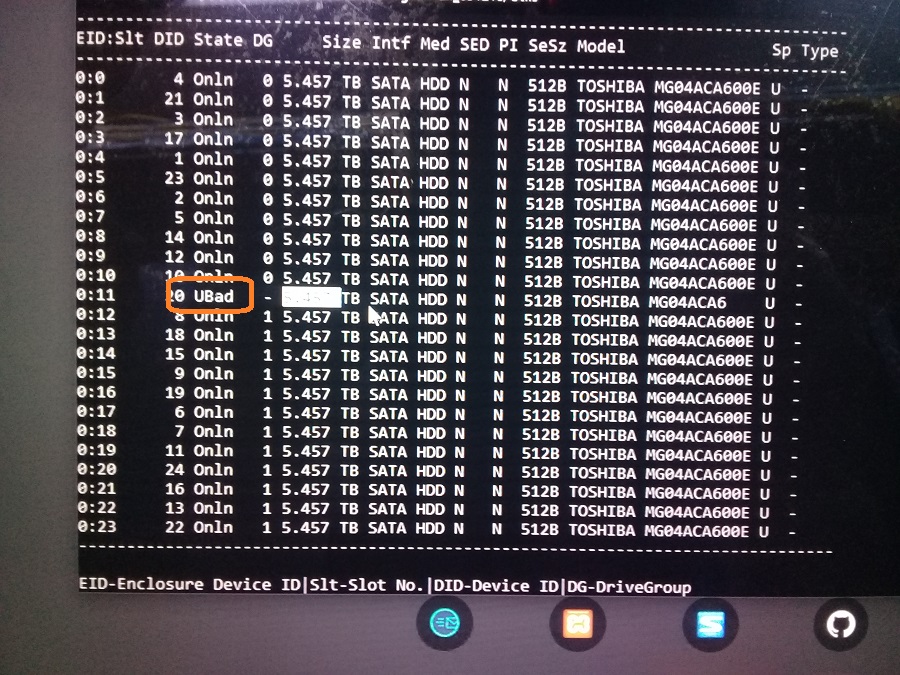
Данный сервер поддерживает горячую замену дисков, мне же проще. Выдергиваем старый диск.

Красный светодиод продолжает гореть на дисковой корзине. Перекручиваем салазки на новый диск.

Устанавливаем диск в слот.

После установки диска загорится синий диод, красный начнёт мигать.

Начинается перестроение массива. Перестроение займёт много времени, больше суток.

Потом, через пару дней проверил, массив в порядке:

Замена диска прошла без проблем.
Диск 2. СХД HP MSA 2040
Второй диск меняю в СХД MSA 2040. Ранее уже менял подобные диски:
Диск HDD 900ГБ, форм-фактор 2.5', поставляется с салазками для MSA. Для управления дисками используется утилита Storage Management Utility, вот так там выглядит дохлый диск:

Он же на MSA с оранжевым светодиодом:

Извлекаю старый диск.


Распаковываю новый диск.

Устанавливаю новый диск.


Теперь нужно зайти в Storage Management Utility и добавить этот диск как Global Spare.

Сразу скажу, что после этого новый диск вышел из строя. Жду ответа техподдержки, замена диска оказалась неуспешной.
Диск 3. Сервер HP ProLiant DL360 Gen9
Третий диск меняю в сервере HP ProLiant DL360 Gen9. Не первый раз меняю диски в этих серверах:
Диск HDD 1ТБ, форм-фактор 2.5', поставляется с салазками. Битый диск светится оранжевым:

Для мониторинга состояния дисков в серверах ProLiant девятого поколения используется утилита iLO 4. Скриншоты не делал. но там тоже видно какой диск вышел из строя.
Извлекаю битый диск.

Устанавливаю новый диск.

Всё просто, салазки перекручивать не нужно, операция быстрая. На всех дисках массива горит индикатор "не извлекать", начинается перестроение массива.
Диск 4. Сервер HPE ProLiant DL360 Gen9. NVMe.
Четвёртый диск не получится установить в работающий сервер. Диск представляет собой PCIe плату NVMe.

Устанавливаем в сервер HPE ProLiant DL360 Gen9. Выключаем сервер, выдвигаем на салазках, снимаем крышку.

В данный сервер можно установить одну полноразмерную PCIe плату и две низкопрофильные. Второй и третий слоты я уже занял, диск будет устанавливаться в первый полноразмерный слот. Снимаю райзер, понадобится отвертка torx.

Кручу-верчу. В райзер устанавливается две PCIe платы. Одна уже установлена, устанавливаю вторую.

Диск в райзере. Устанавливаю райзер в сервер.

Закрываю крышку, включаю сервер. NVMe платы нельзя собрать в RAID через имеющийся RAID контроллер, у меня они собраны с помощью mdadm в операционной системе Ubuntu. Два диска были в RAID1, третий диск позволит увеличить объём массива в два раза, с преобразованием RAID1 в RAID5.
Потом
Забегая вперёд можно сказать, что три из четырёх дисков встали нормально, массивы работают в штатном режиме. А вот четвёртый диск HP MSA 2040 подкачал, новый и не заработал. Техподдержка пока молчит.
Потом-потом
Прислали новый диск для HP MSA 2040, со второй попытки диск встал успешно, пришлось ехать в ЦОД ещ1 раз.
Замена неисправного физического диска в СХД HP 3PAR 7200

Подозреваю, что в штатной обстановке СХД HP 3PAR 7200 должна автоматически перестраивать свой дисковый массив после физической замены диска в состоянии failed на новый диск. Но в некоторых случаях, спровоцированных самим администратором, обслуживающим СХД, может получиться так, что такое перестроение не отработает корректно. В таком случае потребуется выполнить ряд манипуляций по ручному выведению неисправного диска в Offline с последующим подключением нового диска. Здесь описан пример такой процедуры.
Подключаемся к СХД HP 3PAR 7200 по протоколу SSH, используя для аутентификации учётную запись 3paradm
Получаем список неисправных дисков:
В данном случае мы видим, что неисправен диск с идентификатором Id 31 и размещением: дисковая полка 1 , диск 7 (то есть восьмой дисковый слот в полке, так как отсчёт дисков в полке начинается с 0)
Убеждаемся в том, что не выполняется никаких сервисных операций:
Запускаем режим обслуживания диска с идентификатором 31 (на вопрос о запуске servicemag отвечаем утвердительно):
Операция перевода диска в Offline будет запущена в фоновом режиме. Чтобы посмотреть текущий статус операции выполним:
Здесь мы увидим примерное рассчётное время до завершения операции. Дожидаемся пока операция не завершится.
Видим, что команда перевода проблемного диска в Offline выполнена успешно и завершена в нашем примере в 17:04:16 .
Теперь давайте посмотрим то, как изменился статус диска (servicing - насколько я понимаю, признак того, что диск выведен в обслуживание):
На данном этапе физически извлекаем неисправный диск из СХД и устанавливаем новый сменный диск.
Теперь вызываем процедуру вывода дискового слота из обслуживания, указав номер полки и номер слота в полке. При этом автоматически запустится процедура восстановления диска в массиве.
В некоторых случаях, как в моём примере, на данном шаге может возникнуть ошибка, однако при этом процедура восстановления всё же запустится. Подтверждение информации о том, что утилита servicemag не всегда ведёт себя адекватно можно найти и в других источниках, например в статье Storage Exploration - HP 3PAR disk replacement.
Проверить статус запущенной нами задачи можно ранее упомянутой командой (причём лучше делать это не сразу, а через несколько минут, так как планируемое время выполнения операции начинает отображаться не сразу):
Дожидаясь завершения процесса выполнения, посмотрим как изменился статус диска:
Обратите внимание на то, что новый диск имеет Id отличный от того, с каким был старый диск ( 48 вместо 31 ) То есть при установке ранее неизвестного СХД диска идентификатор Id присваивается следующий по счётчику с учётом всех имеющихся в СХД дисков.
Дожидаемся завершения процедуры восстановления…
…до тех пор, пока задание восстановления не завершится и не перестанет отображаться в статусе servicemag:
Осталось удостоверится в том, что неисправных дисков в СХД нет:
А также убедимся в том, что новый диск, который имел идентификатор 48 , теперь изменил свой идентификатор на 31 , то есть «встал на своё место»:
В завершении хочу обратить Ваше внимание на то, что выполнять подобные процедуры на СХД, имеющей контракт технической поддержки нежелательно, а лучше всё-же доверить эту работу специально обученным гражданам из HPE. Как говорится, на Ваш страх и риск :)
Дополнительные источники информации:
Проверено на следующих конфигурациях:

Автор первичной редакции:
Алексей Максимов
Время публикации: 14.03.2018 11:07
В этой статье, я хочу рассказать о том, как нужно работать с сервером ProLiant DL380p G8, как создать и настроить RAID, используя внутреннюю программу HP Smart Storage Administrator. Как работать с этим массивом и, при необходимости, восстанавливать данные с его поврежденных носителей.

HPE Smart Storage Administrator – это специальное встроенное программное обеспечение, с помощью которого можно быстро настроить и управлять контроллером хранения информации на серверах HP ProLiant. У нее довольно простой, удобный, а также интуитивно понятный графический интерфейс. Если вы раньше собирали RAID, то вам не составит труда быстро разобраться в этой утилите. Это ПО пришло на смену HP Array Configuration Utility (ACU), она имеет обновленную базу, которая значительно расширяет возможности хранения информации.
Наш сервер имеет встроенный контроллер на 8 носителей, и поддерживает уровни RAID 0, 1, 5, 10, 50, 60.
Далее я покажу как с его помощью создать массив 5-го уровня из 3 накопителей. Для более наглядного примера мы рассмотрим, как его настроить с помощью новой программы, а затем установим новую ОС.
\
Создаем RAID в новом графическом интерфейсе.

Перезагрузите или включите сервер, во время загрузки после завершения вывода конфигурации iLO, при отображении информации о контроллере, нажмите клавишу F5 для запуска графического интерфейса HP Smart Storage Administrator.
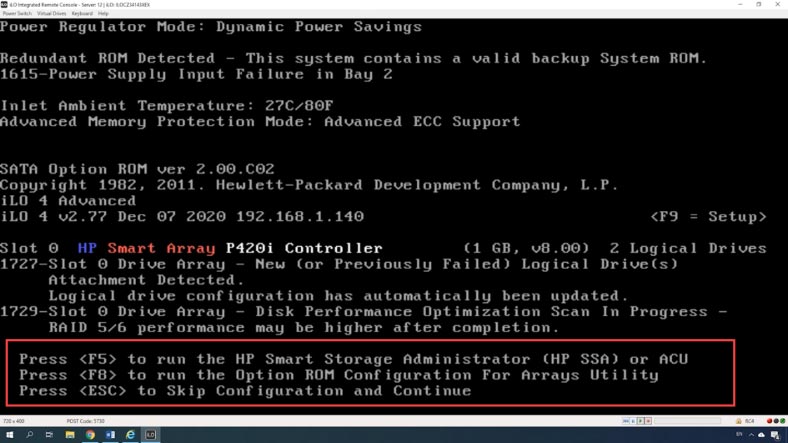
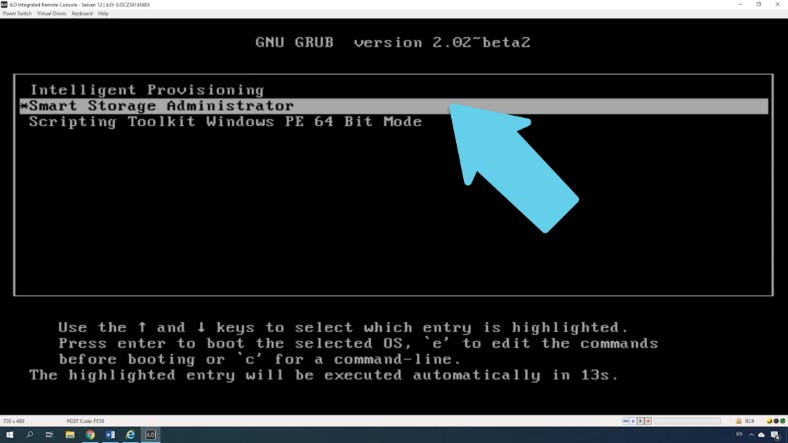
В окне GRUB выберите его из списка, далее нажмите Enter. Ждем пока загрузится утилита, на главном экране кликаем «Контроллер» (Smart Array).
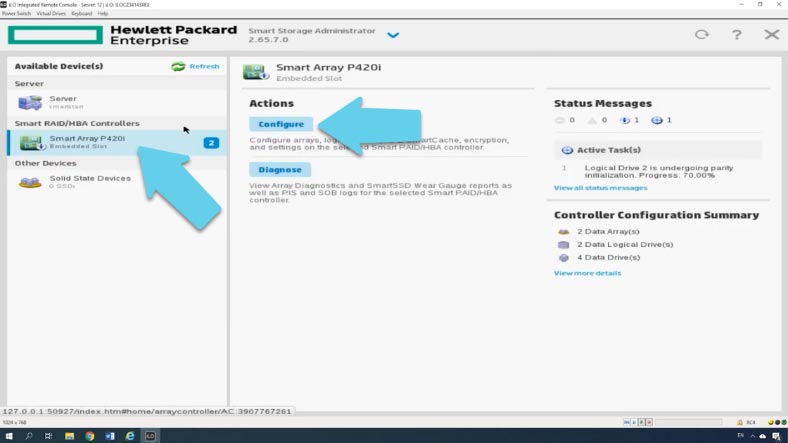
В меню Smart Array – Actions выберите опцию «Configure», а затем «Create Array».
Если данные носители уже состояли в другом RAID, то кнопка «Create» будет недоступна, сперва нужно будет удалить ранее созданный массив. Для этого нужно открыть пункт «Logical Devices», отметить RAID, который требуется удалить и нажать «Delete Array», а затем «Yes» для подтверждения и «Finish».
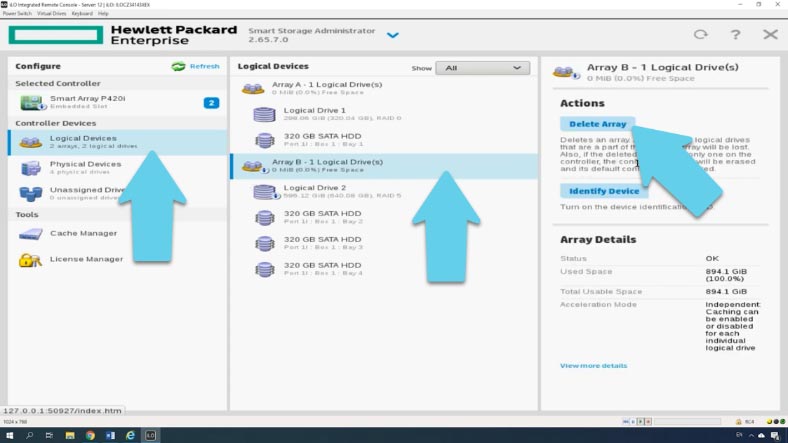
Если нужно, накопители, которые ранее использовались можно затереть нулями. Для этого откройте раздел (не назначенные) «Unassigned Drive», отметьте нужный накопитель и внизу выберите (стереть) «Erase Drive», укажите тип очистки и нажмите Ок и Yes для подтверждения.
Теперь можно создать новый массив, сделать это можно либо с этого пункта меню просто отметив все носители и нажать «Create Array». Или откройте раздел «Smart Array», а затем нажмите «Create Array».
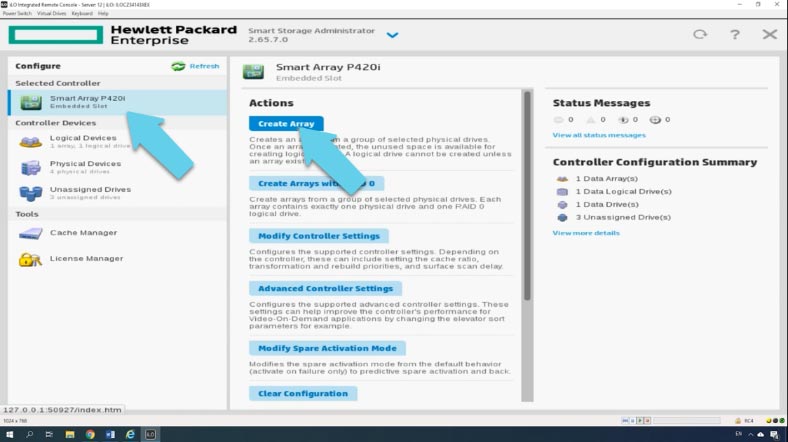
Отмечаем носители, из которых будет состоять будущий массив и кликаем «Create Array».
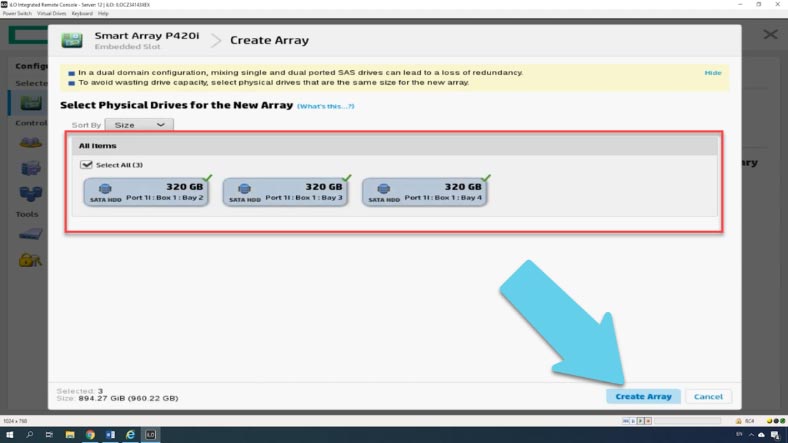
Далее указываем уровень RAID, размер блока, объём – использовать все пространство или задать нужное значение.
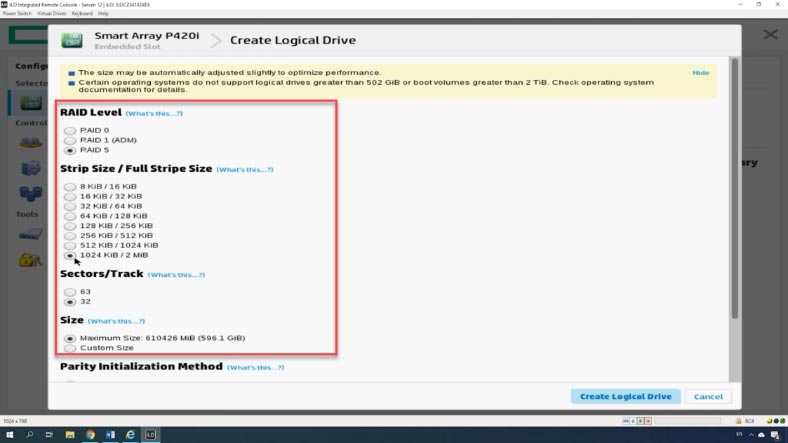
Параметр «Sectors\track» указывает количество секторов, составляющих каждую дорожку, значение 32 отключает MaxBoot, 63 включает его (что снижает производительность логического тома).
Кэширование – повышает производительность за счет записи данных в кэш-память, а не напрямую на логические диски.
Затем выберите метод инициализации, быстрый по умолчанию или долгий, с перезаписью блоков нулями.
Указав все параметры жмем «Create logical Drive», в итоговом окне проверяем параметры, а затем жмем кнопку финиш для завершения процесса.
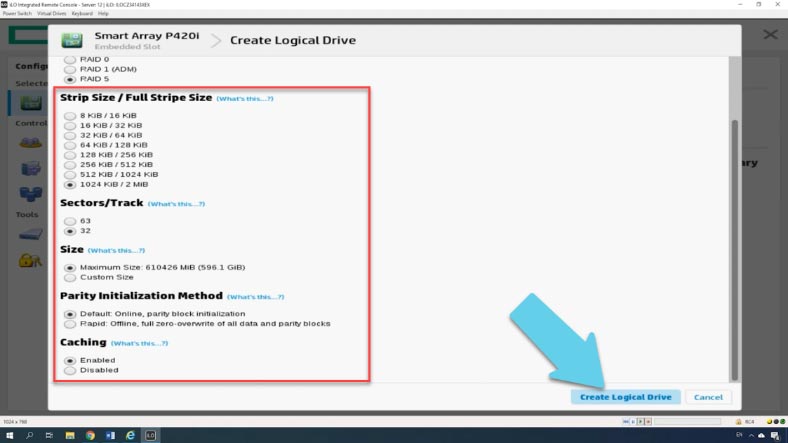
Теперь новый массив должен появиться на левой панели главного окна.
Как добавить запасной диск в RAID массиве?
Для обеспечения бесперебойной работы в случае поломки одного носителя, перед завершением есть возможность добавить запасной накопитель.
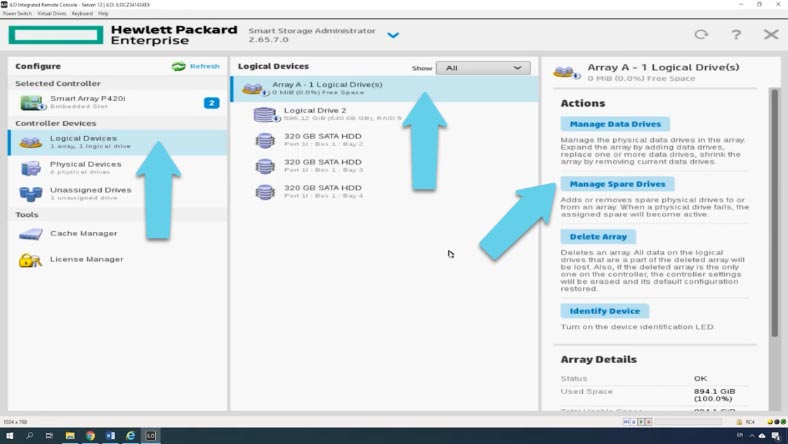
Чтобы добавить запасной накопитель, откройте «менеджер запасных дисков», в следующем окне отметьте диск и нажмите «Сохранить», запасной диск добавлен. На скриншоте видно все 3 носителя из которых собран RAID, а ниже четвертый – запасной.
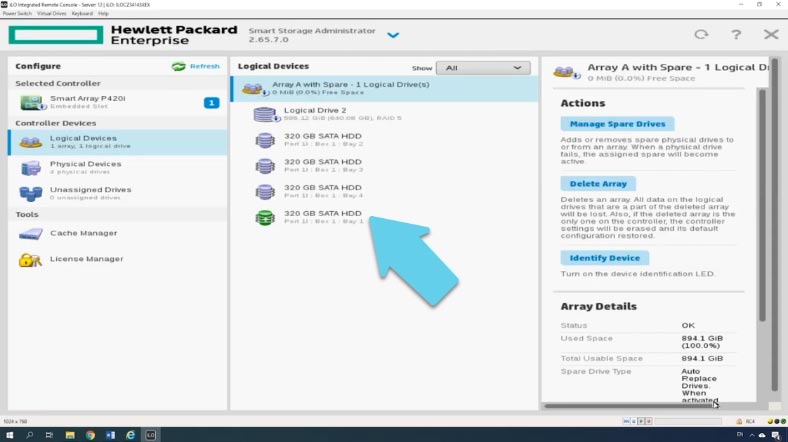
Теперь при поломке одного из накопителей, контроллер перестроит RAID с запасным накопителем, а также выведет уведомление, что один из накопителей нуждается в замене.
Чтобы выйти из приложения, нажмите кнопку «Закрыть» «х», после чего вы будете перенаправлены на экран «Intelligent Provisioning». В этом окне нажмите кнопку питания в правом верхнем углу, а затем кнопку перезагрузки.
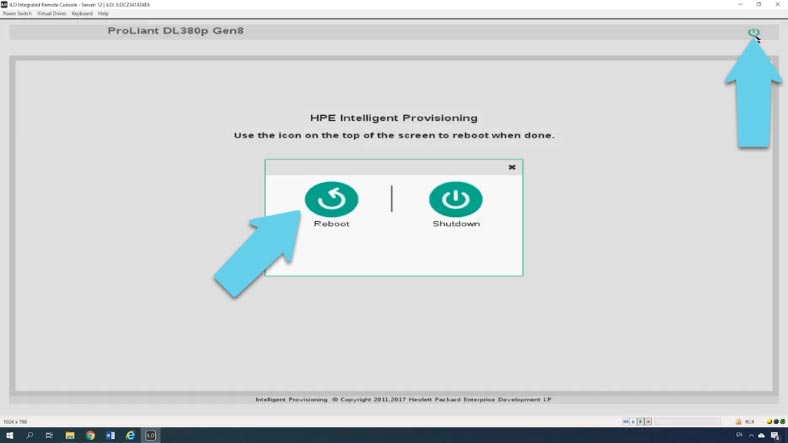
Далее нужно загрузить операционную систему и разметить диск.
Как установить операционную систему на RAID массив
Если вам нужно установить операционную систему стоит воспользоваться другой встроенной утилитой Intelligent Provisioning Preferences. Для ее запуска при загрузке сервера нажмите клавишу F10.
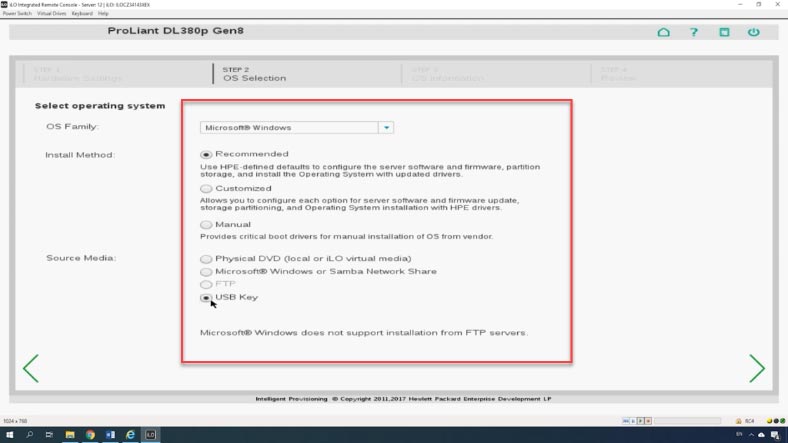
Выбираем Configure and Install – Continue, из выпадающего списка выбираем семейство будущей операционной системы, выбираем метод установки, и указываем ресурс с установочным диском.
Указываем путь к образу операционной системы – Continue – устанавливаем нужные параметры – Указываем логин и пароль администратора. Продолжить, система предупредит что все данные будут утеряны, жмем «Продолжить» и ждем завершения процесса установки.
Из меню данной программы вы сможете запустить Smart Storage Administrator, обновить версию программного обеспечения контроллера и установить систему. Далее идет стандартная установка системы, просто следуем шагам инсталлятора.
Полную версию статьи со всеми дополнительными видео уроками смотрите в источнике. А также зайдите на наш Youtube канал, там собраны более 400 обучающих видео.
Читайте также: