
1с получить имя сервера sql
Обновлено: 07.07.2024
Если запустить эту обработку в первой и второй базе ( обе одной конфигурации УПП 1.3 (1.3.38.4)), то имеем для первой базы имя таблицы SQL = Reference131, для второй имя таблицы SQL = Reference162. Если смотреть структуру полей таблиц, то видим, что имена полей различны.
Вопрос: подтвердите или опровергните вывод: таблицы SQL создаются динамически и могут иметь различные имена (имена полей в том числе). При создании новой базы загрузкой конфигурации из *.cf –файла, получим таблицы новой базы с именами, отличными от имен таблиц базы, из которой был выгружен файл конфигурации *.cf .
cf это метаданные 1С к sql отношения не имеют. из того же cf можно вообще сделать файловую базу.
а вообще - проводлжайте наблюдать, вас столько открытий ждет
В базе1 удалил справочник, таблица _Reference131 удалилась.
В базе1 добавили новый справочник, появилась таблица _Reference132
На базу2 накатили обновление из базы1. в базе2 появился справочник с таблицей _Reference131
но если загрузить в 2 разных базы чистых одинаковый Цф - то и структура с большой долей вероятности будет одинакова
>но если загрузить в 2 разных базы чистых одинаковый Цф - то и структура с большой долей вероятности будет одинакова
одинаковы будут id по которым происходит "быстрая" сверка. также это будет гарантировать что данные не отвалятся при нахлабучивании изменений одной конфы на другую через "загрузить"
(7) это понятно, я про стуртуру таблиц ы скуле, она тоже совпасть должна
Ребята. Всем СПАСИБО!!
НЕОБХОДИМО из SQL-таблиц получать информацию для другого программного продукта (НЕ 1С). получается, что надо создавать таблицу соответствий что ли, чтооб не изменять код при чтении данных 1С из таблиц в другом программном продукте(базу 1С планируем обновлять. ведь можно разными способами получить базу данных обновленную чистую для учета с нового года, например).
Кто-нибудь решал такую проблему? Может кто подскажет оптимальное решение.
(15) Образение через com в 1с и получение структуры оттуда.
Но обычно более эффективным считается работа от обратного, когда 1с отдает в нужном виде.
(15)
я решал при обнослении config
в случае необходимости пересоздается view
с именами метаданных.
+(17) Ащета лицензионное соглашение 1С запрещает лезть своими грязными пальцАми в 1Совские БД
(15) Другой продукт каждый раз при коннекте каким то образом инициирует ПолучитьСтруктуруХраненияБазыДанных(МассивИменМетаданных)
в конфиге и дальше работает через этот мапинг до конца коннекта.
Как реализовать вызов этой процедуры - уже технические формальности
(21) это легко оспорить в суде и вертеть потом на вертеле. Другое дело, что это не разумно и не безопасно. Вот это уже вертеть чревато
(24) если данные только получать для отчетов и сверок- то это ничем не чревато. а вот если писать в базу то тут существует опасность.
(25)
какие опасности существуют при записи в таблицы (представления) ?
(16) а чем чревато создание собственных функций, процедур, вьюшек etc в одинесовской базе?
(25) ему придется отдать насторону огин и пароль к кишкам, из которых получить можно что угодно и ни кто не знает, что потом будет по факту получаться и куда передаваться. Это все равно, что голую задницу в интернет выставить
(28) всё-равно побаиваюсь. Создать другую базу и в ней создаю всё это хозяйство
(30) Ничего не будет. Я индексами игрался, функции и вьюхи создавал - всё работало как часы
(29) Можно ведь создать еще одно юзера к кишкам с доступом на ридонли
данные из 1С читать надо только, обрабатываться будут в другой системе
(31) единственное, наверно, если создавать архив средствами 1С, то потеряется. Но, это не страшно
Создай базу данных в которой будут вьюхи и процедуры(которые будут читать данный из рабочий базы)-как уже сказали зверя создать только на чтение.
я не рискнул вьюхи и процедуры создавать в рабочей базе. данные получал в другую базу во вьюхи.
(33) есть штатный безопасный механизм, дающий любой необходимый программный интерфейс к чему угодно. Вебсервисы. Надо научиться ими пользоваться, а не городить велосипеды с квадратными колесами.
(39) так я думаю это самое верное решение. т.к. на этапе проектирования не один пуд соли съел)))
все-таки, еще раз вопрос - что в 1С не хватает ? (38) + - изобретать велосипид, БД зависимый. Типа, круто, на asm ваять, а vb - отстой
(38) прямые (Ровные запросы, а не оптимизированные кривым оптимизатором 1С) запросы гораздо быстрее выполняются напрямую-если важна скорость
(34) Значит все средства интеграции, которые предлагает 1С штатно, мы вертели на вертеле? Или просто лень почитать?
(43) прямыми (Ровные запросы, а не оптимизированные кривым оптимизатором 1С) сделаешь базу кривой. В резюме, потом напиши, что сделал суперские оптимизированные запросы
(47) абсолютно не при чем. "За державу обидно".
Меня устраивает "оптимизатор запросов 1С", хоть и не фан. Как, говорилось на этом форуме не раз, готовить запросы надо уметь.
Почему-то все адепты прямых запросов не учитывают вероятности получить несогласованные данные.
данные из 1С попадают в систему весовых терминалов. обрабатываются там. затем обратно в 1С. кто работает с весовым оборудованием. средства 1С дают хорошие возможности.
(51) Часть блокировок живет в памяти сервера. Сторонне приложение о них не в курсе.
(56) Например у тебя больше чем 1 кластер ( рабочих процессов) как ты их блокировать то будешь?v8: Разделяемый или Исключительный режим блокировки
(55) в продолжение темы для "адептов":
Для чего надо делать так (0):
ускорить шибко тугой запрос на уровне СУБД, или, запудрить тех, кто будет это хозяйство разбирать
Для чего не надо делать так:
3. даются средства высокого уровня, зачем лезть в кору
4. потом, после реализатора "нетленки" долго нужно разбираться - из прямых запросов к БД, т.к. это уровень не бизнес-логики
(61) Как другой кластер (рабочий процесс) об этом узнает? Проще использовать блокировки БД
(60)
запудрить тупых рисовальщиков формочек и отчётов
0 что значит бд зависимо? 1с примерно одинаково гененрирут названия полей для разных субд (всего 3 варианта)
2 с учетом оговорок смысла не имеет. тк практически любой объект бд- метаданных можно привести к состоянию требующему разрешённому и рекомендованному фирмой 1с вмешательству.
3. вот тут верно. тк 1с8 на риалтайм систему не тянет.
лучше через коннектор.
мне через саповский коннектор в 10 раз удобней было работать с САП
чем на прямую в скл сервер писать.
4. если делать через view с именами метаданных - то все равно.
(64) Рабочие процессы это реально разные процессы со всоей виртуальной памятью.
Другой кластер это другой компьютер а база у всех одна.
Так как ты будешь хранить эти блокировки? Неужто это будет эффективнее чем хранить блокировки в самой БД?
Меня интересует технический процесс.
(17) чтобы этого не случалось в SQL есть роль db_datareader
(65) (66) Народ, желтые книжки почитайте, я с них цитирую. Конечно я в исходниках платформы не копался, но оснований не верить нет.
Блокировок БД бывает недостаточно, поэтому вводятся блокировки прикладного уровня. Сам не раз реализовывал, в других системах. Некоторые СУБД предоставляют механизмы для того, чтобы и прикладные блокировки жили в БД. Грубо говоря API к своему менеджеру блокировок. Но в случае 1С кроссплатформенность и кросс-СУБД диктует свои правила. Поэтому прикладные блокировки живут в памяти сервера 1С. Очевидно они не могут быть свои у каждого рабочего процесса, поэтому в памяти менеджера кластера.
И не путайте "рабочий процесс" и "кластер".
(69)
"желтые книжки почитайте" -
- какую главу. если Вы сами не использовали что-то
то к ЖК лучше не аппилировать, тк это 1с.
В ней заявленое может не работать, рабочее может быть не декларированным.
поэтому и интересно, можете ли Вы точнее чем общий отсыл к
ЖК или интернет подтвердить работу кластера с разными бд.
(70 >подтвердить работу кластера с разными бд.
Не понял
Главу постараюсь найти.
(71) Нашел.
Клиент-серверный вариант. Руководство администратора. 2.1.3. Сервисы кластера
На ИТС тоже есть.
Мало того в 8 ке применяется оптимистическая блокировка. Управляемые блокировки используют хинты SERIALIZABLE,REPEATABLEREAD
Оптимистическая блокировка осуществляется на уровне поля ._Version v8: Кэши разные нужны, кэши нужные важны.
Пессимистическая на уровне блокировок в транзакции. Нет смысла городить огород там, где он не нужен. Но вот если будут реальные примеры объектных блокировок осообенно в контексте нескольких серверов приложений.
(76) Так и объектные блокировки имеют смысл без транзакции.
Управляемые блокировки только на уровне транзакции и на уровне БД. Не управляемы это уже уровень изоляции REPEATABLE READ. Но тогда и на уровне блокировок запросов нет смысла в объектных блокировках для клиент сервера. Для Локальных баз на уровне LockFile
(78) Давай прежде всего не путать объектные блокировки и управляемые. Первые с танзакциями не связаны, они чисто прикладные.
Вот про это я и говорю зачем мешать объектные блокировки и транзакционными блокировками бд. Объектные блокировки так или иначе не взаимодействуют с блокировками БД. Тогда какой в них смысл? Управляемые блокировки это блокировки БД в режиме изоляции Read Commited с помощью хинтов SERIALIZABLE,REPEATABLEREAD. Автоматические это уже на уровне Изоляции REPEATABLE READ.
(81) Давай ты прочитаешь (82), с терминологией и общей концепцией все устаканится, потом продолжим.
Правда, там в тексте упоминается 8.1, кое-что могло и устареть.
(81) > Управляемые блокировки это блокировки БД в режиме изоляции Read Commited с помощью хинтов SERIALIZABLE,REPEATABLEREAD.
Это неправда, при наложении управляемой блокировки никакие блокировки в БД не накладываются.
(84)
раньше
(до 14 релиза)
накладывались блокировки субд.
сейчас может исправили.
(88) Внутри одного из менеджеров кластера (процесс) запускается служба (в терминах 1С) транзакционных блокировок, конечно, это маршалинг, но если рабочих процессов больше одного, то без этого управляемые блокировки не организовать. Если рабочий процесс один то в предыдущих версиях этот механизм блокировок размещался в рабочем процессе, с тех пор рекомендация, на х64 запускать один рабочий процесс, если нет веских причин поступить по-другому.
(88) Так и сказано управляемые блокировки используют Read Commited (или Snapshot Isolation в 8.3), а блокировки в разрезе объектов 1С держит менеджер блокировок.
(89) Так это и есть официально объяснение лицензионного запрета, вы там наулучшаете, а мы в свою очередь всё переделаем внутри в новой версии и в неё уже автоматом ничего не сконвертируется при обновлении, и могут обвинить в этом не улучшателя, а производителя.
(90) Объясни зачем городить огород если все это можно решить на уровне БД, для рабочих процессов больше 1?
Могут быть кластеры на нескольких серверах. Где выигрыш если рабочих процессов больше чем 1?
(91) Зачем в запрсах применять хинты
FROM _AccRg5523 T3 WITH(SERIALIZABLE)
LEFT OUTER JOIN _Acc6_ExtDim5518 T4 WITH(REPEATABLEREAD)
(91) Глупо изобретать велосипед, там где он уже эффективно работает. Snapshot Isolation хорорша при чтении данных снимка данных до начала транзакции. Если же ты хочешь, что бы данные не изменялись до конца транзакции нужно накладывать блокировки явно.
Менеджер блокировок просто запишет в своих структурах: Пространство блокировок (РБ.Хозрасчетный), Субконто, Его значение. И будет держать его до конца транзакции.
Всё дело в том, что, именно, сервер 1С хранит в себе бизнес модель на предметном уровне. Например, меня огорчает, что журнал регистрации не хранится в БД, но у производителя свои взгляды на продукт.
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
go
SELECT spid, blocked FROM master..sysprocesses WHERE blocked > 0 AND lastwaittype LIKE 'LCK_%'
go
BEGIN TRANSACTION
go
.2 так это ради Оракла, который версионник, а не блокировочник как MS SQL, поэтому все блокировки они решили делать сами с учётом внутренней природы бизнес объектов (справочники, документы и тд.) и не объектов (регистры). А работать должно везде одинаково!
(96) Для автоматического режима хинт REPEATABLEREAD не имеет смысла.
(97) Для Оракла есть FOR UPDATE и DBMS_LOCK. Но не являюсь хоть каким то знатоком Оракула.
Блокировки могут быть еще в режиме 4 (разделяемая блокировка таблицы share mode, генерируется, например, оператором lock table <…> in share mode) и 5 (разделяемая блокировка таблицы и монопольная блокировка строк share row exclusive; генерируется, например, оператором lock table <…..> in share row exclusive mode). Но эти режимы встречаются крайне редко.
Есть какая-то стандартная функция, возвращающая соединение к SQL собственной базы? Надо UPDATE запустить. Типовая вещь должна быть вроде.
Но для этого нужны 5 секунд поиска и 1 примитивнейший запрос в поисковик
(0) С чего это типовая вещь и почему она должна быть? 1С в клиент-сервере - это трехзвенка, доступ до СУБД никто не обещал.
В общем за все эти годы одинэсники даже самое простое не написали.
(7) Ага. Извини, пожалуйста - придется тебе самому. Справишся?
(7) Они написали самое простое. То, что обычно не читают. Называется "лицензионное соглашение".
(11) И что тебе в этой статье не понятно? Там же всё черным по белому расписано.
(11) Готовой функции ПолучитьЗначениеИзБазы нет в статье. Написано что есть ADODB или SQLOLEDB или. А готового нет.
Зачем понятия подменять? при чем тут "понятно" и "есть готовое"?
Там написано "Учимся получать доступ к СУБД из 1С." Чем оно готовое? Как раз наоборот.
В статье тоже не готовое. Хотя на готовое ПолучитьЗначениеИзБазы в примерах ссылает.
Как это связано с тем, что ПолучитьЗначениеИзБазы нет?
Штаны тоже можно научиться шить самому, все разжевано. Бурда моден а не среда.
"Есть какая-то стандартная функция, возвращающая соединение к SQL собственной базы?" - и каждый как обычно разговаривает что-то свое. А по теме нечего сказать?
864666 попытка завести тематическую ветку.
"Видимо, место здесь такое" (с) Жмурки
(21) Значит автор и ему подобные врут про ПолучитьЗначениеИзБазы(ТекстЗапросаSQL)?
+(23) есть в открытой публикации хоть одна такая функция?
(24) Не Жужжите.
(0) Доступ к БД иначе как средствами 1С запрещен лицензионным соглашением. А 1С не предоставляет прямого доступа к базе, потому что 90% 1Сников положат базу, будь у них такая возможность. Запускать UPDATE при работающем серверном процессе - вообще за гранью добра и зла. У сервера есть свой кеш, и он не рассчитан на то, что кто-то будет запускать UPDATE в базе.
(26) В соседней ветке один друг пытается 470 000 пачек сигарет отгрузить одной фурой и у каждой пачки своя марка. А после этого ему надо базу 1С свернуть по прошлым периодам. Что же будет делать 1С в связи с этим?
(27) Доработает интерфейс программы, чтобы коробки лучше продавались.
(28) Какой интерфейс? Будут блокнотики и карандашик в коробку вкладывать? Скажут "работайте на мягких регистрах".
(31) ну иди в фузину. Зачем в 1с пришел? Изначально же понятно, что это тормоза?
(27) 1С тут не лимитирующий фактор. Ведь эти коды надо еще сосканировать каждый ;)
(0) Чего сложного через ADODB.Connection порубиться, и делай что хочешь.
(35) Да, давно пора перевести на rfid. А потом заказать в Китае сканеры, которые полмиллиона кодов за раз берут. Кетайцы оху@ют и пришлют две деревни крестьян в контейнере.
(36) Чего сложного написать свою ОС на ассемблере.
были люди в наше время, Не то, что нынешнее племя: Богатыри — не вы! Плохая им досталась доля:
(37) Да, Вася. Тебе до твоего тёзки - как Маску до Альфы Кассиопеи в позе гордого моллюска.
(37)обычно говорят я делал то-то и то-то.Что не получилось. А ты ничего не сделал, не попробовал, а просто требуешь готовое. "А кушать вы за меня тоже будете?" Ага!
(38) Одинэсу до консоли скуля видимо ближе.
(39) Кто кому говорят? В смысле чтобы функция появилась нужно позаклинать?
Человеку нужно соединение с БД на прямую, для которого и через ADODB.Connection нужены Логин/Пароль на SQL, не говоря уже о адресе сервера и имени БД, которые можно получить средствами 1С.
Логин/Пароль нельзя получить из снеговика.
(39) Точно.
(40) Нет, заклинанание не надо. Надо миллион долларов и личная встреча с братьями Нуралиевмыи, чтобы они за эти деньги дали команду своим наемным работникам добавить в платформу "1С:Предприятие 8" ту функциональность, что тебе нужно.
ПыСы: сумма взята с потолка, реальная сумма выяснится после того, как сторгуешься с братьями Нуралиевмыи
+(42) Читать: братья Нуралиевы. Это была опечатка, а не коверкание.
(41) У снеговика оно все уже есть. Иначе как он в скуль ходит?
(44) Сестры сделали матрицу, а у этих сплошное дежавю. Все чего-то меняют.
(45) Ни разу пока.
(47) Нет, их в муках рожают.
(48) Не подсказывай.
(48) восхищённый зритель видит чудо, и радуется
а где-то в сторонке кто-то читает заклинание. потому и магия.
(50) А где функция-то? Расскажите подробнее чего Нуралиевы читают.
У майкрософта консоль, у оракла SQL*Plus, а у 1С - лицензионное соглашение.
(52) У 1са тоже есть консоль. И не одна. Для своего языка.
Который за 100 часов делает то, что напрямую выполняется за 25 секунд..
(54) А напрямую ты все обработчики Перед и При записи вызвал? А подписки?
(60) Пруф на что? На то, что 1с работает через объектную модель и у каждой записи могут быть обработчики событий? Так это тебе в книжки для начинающих.
(61) В книжках есть про внешний источник данных (ВИД). Там никаких событий вроде нет, но ограничения на изменение данных. Никакой объектной модели. Как раз чтобы её не обошли и не построили на ВИД свои быстрые регистры и прочее введено ограничение, а так же Лицензионным соглашением. Не может одинэска конкурировать с другими решениями по скорости.
(62) Совсем запутал. Ты же вроде хотел получить программный доступ до таблиц самой базы, а теперь говоришь о внешних источниках данных. Чего в итоге-то ты хочешь? Или ты просто стебешься тут на форуме?
(62) Вот интересно. А почему ты не хочешь записать в базу SQL напрямую, редактируя секторы на диске? Это ж какая скорость получается!
Всем привет! Сегодня мы с Вами рассмотрим несколько способов определения имени экземпляра Microsoft SQL Server на языке T-SQL, а также с использованием других программных средств.

Способы определения имени экземпляра Microsoft SQL Server
Существует несколько способов узнать, какое имя экземпляра у SQL Server. Мы рассмотрим способы, которые подразумевают обращение к определенным системным функциям на языке T-SQL, а также способ, с помощью которого мы можем узнать имена всех экземпляров SQL Server, которые установлены на конкретном сервере.
Кроме этого я покажу способ определения имени экземпляра SQL Server без выполнения SQL инструкций, например, для случаев, когда нет возможности подключиться к SQL Server. Данный способ предполагает выполнение определённой инструкции на языке PowerShell.
Таким образом, для того чтобы определить имя экземпляра Microsoft SQL Server, Вы можете использовать тот способ, который будет удобнее в Вашем конкретном случае.
Способ 1 – функция @@SERVERNAME
Первый способ предполагает использование системной функции @@SERVERNAME, которая возвращает имя локального сервера, на котором работает SQL Server.
Функция @@SERVERNAME возвращает следующие данные:
| Исходные данные | Данные, которые возвращает функция |
| Если используется экземпляр по умолчанию | «Имя_сервера» |
| Если используется именованный экземпляр | «Имя_сервера\Имя_экземпляра» |
| Если используется экземпляр по умолчанию отказоустойчивого кластера | «Сетевое_имя_экземпляра_отказоустойчивого_ кластера_windows_server» |
| Если используется именованный экземпляр отказоустойчивого кластера | «Сетевое_имя_экземпляра_отказоустойчивого_ кластера_windows_server\имя_экземпляра» |
Пример использования функции
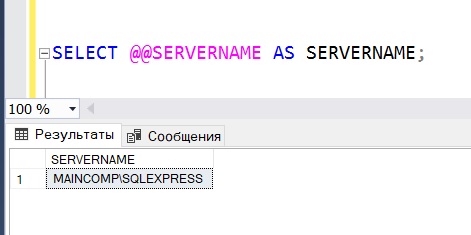
В моем случае используется именованный экземпляр Microsoft SQL Server, поэтому функция вернула соответствующие данные, где SQLEXPRESS и есть имя экземпляра SQL Server.
Способ 2 – функция @@SERVICENAME
Второй способ определения имени экземпляра Microsoft SQL Server предполагает использование функции @@SERVICENAME, которая возвращает имя раздела реестра, согласно которому запущен SQL Server.
Если текущий экземпляр является экземпляром по умолчанию, то данная функция возвращает «MSSQLSERVER», однако если же текущий экземпляр является именованным экземпляром, то эта функция возвращает имя этого экземпляра.
Пример использования функции
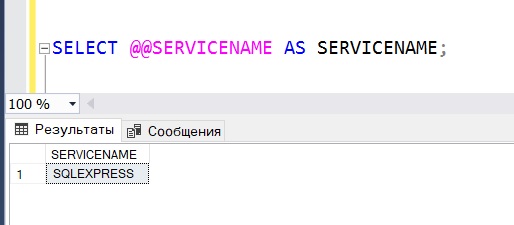
В данном случае, так как у меня именованный экземпляр, функция @@SERVICENAME вернула имя экземпляра.
Способ 3 – функция SERVERPROPERTY
Следующий способ определения имени экземпляра SQL Server предполагает использование системной функции SERVERPROPERTY, которая возвращает много различных сведений о свойствах экземпляра Microsoft SQL Server.
Данная функция принимает один параметр, и если мы передадим значение «InstanceName», то она нам вернет имя экземпляра.
Однако здесь стоит учитывать, что если используется экземпляр по умолчанию, то функция вернет NULL.
Пример использования функции
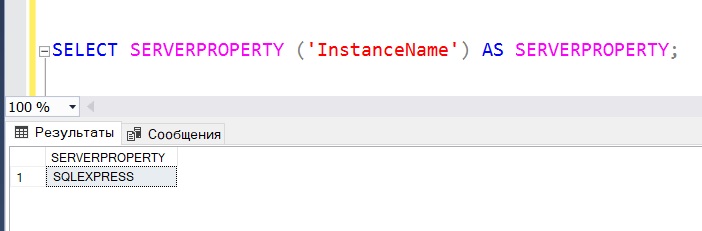
У меня именованный экземпляр, поэтому функция вернула имя экземпляра.
Способ 4 – процедура xp_regread
Если Вам необходимо узнать имена всех экземпляров SQL Server, которые установлены на конкретном сервере, то для этого Вы можете использовать системную хранимую процедуру xp_regread, которая умеет считывать параметры реестра Windows, в котором как раз и можно найти всю интересующую нас информацию об экземплярах Microsoft SQL Server.
Пример использования процедуры
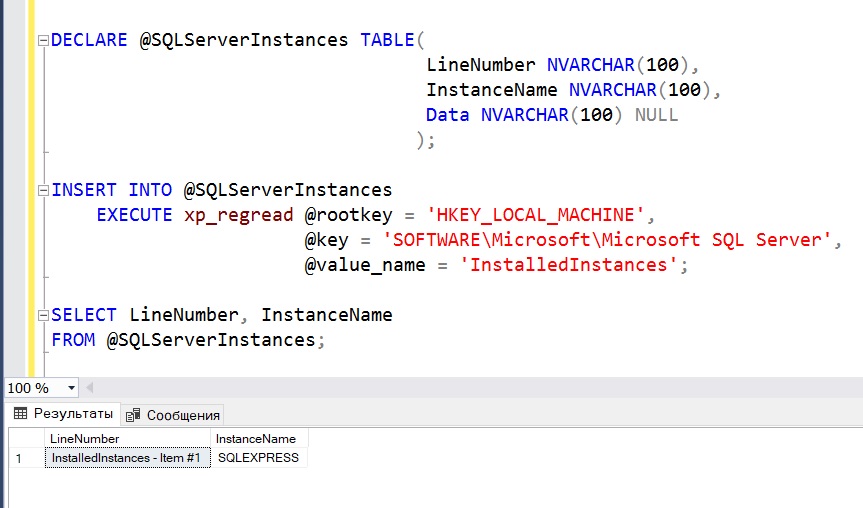
У меня установлен только один экземпляр, поэтому инструкция вернула одну строку данных.
Как узнать имя экземпляра Microsoft SQL Server на PowerShell
Способ предполагает простое считывание названия службы Microsoft SQL Server, т.е. мы с помощью определенной инструкции на PowerShell ищем название службы по префиксу «MSSQL$» (данный префикс имеет «Имя службы, а не «Отображаемое имя службы»).
Пример инструкции на PowerShell
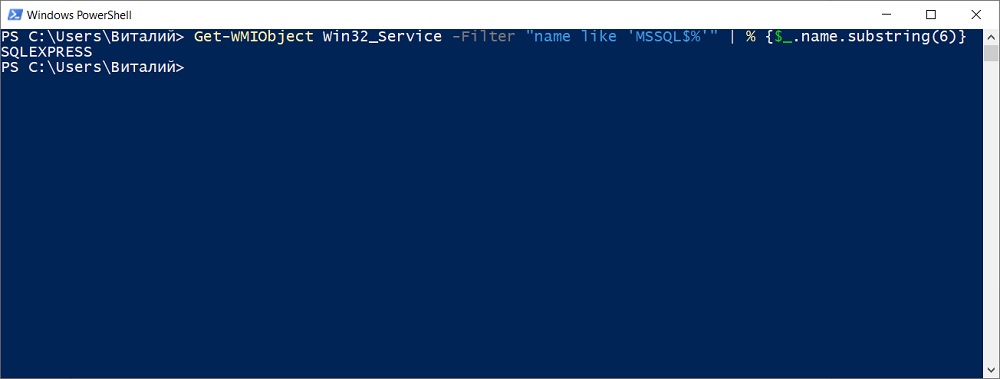
Кроме этого, узнать имя экземпляра Microsoft SQL Server можно, если зайти в оснастку «Службы» в Windows и посмотреть, какое имя указано в названии службы SQL Server.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
Вы можете использовать тот способ, который Вам будет удобнее в той или иной ситуации, я со своей стороны дам несколько рекомендаций.

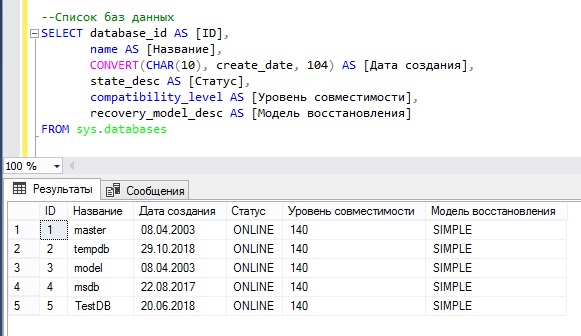
Получаем список баз данных с помощью представления sys.databases
Сейчас мы напишем SQL запрос с использованием системного представления sys.databases, который покажет нам список баз данных на экземпляре Microsoft SQL Server.
На мой взгляд, данный способ предпочтительней, так как представление sys.databases выводит детальную информацию о параметрах базы данных, которая может быть очень полезна.
В данном случае для примера мы выведем следующие параметры баз данных:
- Идентификатор базы данных;
- Название базы данных;
- Дату создания базы данных;
- Состояние базы данных;
- Уровень совместимости;
- Модель восстановления.
Более детально посмотреть обо всех параметрах, которые возвращает представление sys.databases, можете посмотреть в официальной документации по Transact-SQL – Системное представление sys.databases
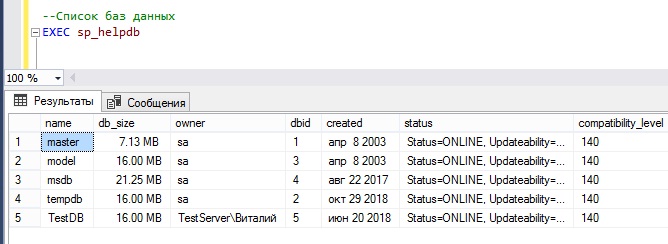
Выводим список баз данных с помощью процедуры sp_helpdb
Хранимая процедура sp_helpdb выводит меньше информации о параметрах баз данных, однако она показывает дополнительную полезную информацию, например, размер базы данных. Также данный способ предпочтительней, если список баз данных необходим клиентскому приложению, т.е. из клиента лучше вызывать хранимую процедуру, чем посылать SQL запрос SELECT.
Процедура sp_helpdb возвращает следующие данные:
Теперь Вы знаете, как можно вывести список баз данных в Microsoft SQL Server. Если Вы начинающий программист и у Вас нет базовых знаний языка SQL, то я Вам рекомендую почитать книгу «SQL код» – это самоучитель по данному языку. Книга написана мной, в ней я очень подробно рассказываю о языке SQL.
Заметка! Для комплексного изучения языка SQL и T-SQL рекомендую пройти наши онлайн-курсы по T-SQL, на которых используется последовательная методика обучения специально для начинающих.
Читайте также: