
Бывает ли так что программа скомпилировалась с первого раза и без ошибок
Обновлено: 07.07.2024
Освоить работу с встроенным отладчиком, изучить категории ошибок, способы их обнаружения и устранения.
Тестирование и отладка программы
Чем больше опыта имеет программист, тем меньше ошибок в коде он совершает. Но, хотите верьте, хотите нет, даже самый опытный программист всё же допускает ошибки. И любая современная среда разработки программ должна иметь собственные инструменты для отладки приложений, а также для своевременного обнаружения и исправления возможных ошибок. Программные ошибки на программистском сленге называют багами (англ. bug - жук), а программы отладки кода - дебаггерами (англ. debugger - отладчик). Lazarus, как современная среда разработки приложений, имеет собственный встроенный отладчик, работу с которым мы разберем на этой лекции.
Ошибки, которые может допустить программист, условно делятся на три группы:
- Синтаксические
- Времени выполнения (run-time errors)
- Алгоритмические
Синтаксические ошибки

Рис. 27.1. Найденная компилятором синтаксическая ошибка - нет объявления переменной i
Подобные ошибки могут возникнуть при неправильном написании директивы или имени функции (процедуры); при попытке обратиться к переменной или константе, которую не объявляли ( рис. 27.1); при попытке вызвать функцию (процедуру, переменную, константу) из модуля, который не был подключен в разделе uses ; при других аналогичных недосмотрах программиста.
Ошибки времени выполнения
Ошибка времени выполнения может возникнуть не только при загрузке программы, но и во время её работы. Например, если бы попытка чтения несуществующего файла была сделана не при загрузке программы, а при нажатии на кнопку, то программа бы нормально запустилась и работала, пока пользователь не нажмет на эту кнопку.
В данном примере программист допустил типичную для начинающих ошибку - не освободил класс TStringList . Это не приведет к сбою или аварийному завершению программы, но в итоге можно бесполезно израсходовать очень много памяти. Конечно, эта память будет освобождена после выгрузки программы (за этим следит операционная система ), но утечка памяти во время выполнения программы тоже может привести к неприятным последствиям, потребляя все больше и больше ресурсов и излишне нагружая процессор . В подобных случаях после работы с объектом программисту нужно не забывать освобождать память :
Однако ошибки времени выполнения могут случиться и во время работы с объектом. Если есть такой риск, программист должен не забывать про возможность обработки исключительных ситуаций. В данном случае вышеприведенный код правильней будет оформить таким образом:
Итак, во избежание ошибок времени выполнения программист должен не забывать делать проверку на правильность ввода пользователем допустимых значений, заключать опасный код в блоки try…finally…end или try…except…end , делать проверку на существование открываемого файла функцией FileExists и вообще соблюдать предусмотрительность во всех слабых местах программы. Не полагайтесь на пользователя, ведь недаром говорят, что если в программе можно допустить ошибку, пользователь эту возможность непременно найдет.
Алгоритмические ошибки
Если вы не допустили ни синтаксических ошибок, ни ошибок времени выполнения, программа скомпилировалась, запустилась и работает нормально, то это еще не означает, что в программе нет ошибок. Убедиться в этом можно только в процессе её тестирования.
Тестирование - процесс проверки работоспособности программы путем ввода в неё различных, даже намеренно ошибочных данных, и последующей контрольной проверке выводимого результата.Если программа работает правильно с одними наборами исходных данных, и неправильно с другими, то это свидетельствует о наличии алгоритмической ошибки. Алгоритмические ошибки иногда называют логическими, обычно они связаны с неверной реализацией алгоритма программы: вместо "+" ошибочно поставили "-", вместо "/" - "*", вместо деления значения на 0,01 разделили на 0,001 и т.п. Такие ошибки обычно не обнаруживаются во время компиляции , программа нормально запускается, работает, а при анализе выводимого результата выясняется, что он неверный. При этом компилятор не укажет программисту на ошибку - чтобы найти и устранить её, приходится анализировать код, пошагово "прокручивать" его выполнение, следя за результатом. Такой процесс называется отладкой.
Работа с отладчиком
Давайте от теории перейдем к практике. Загрузите Lazarus с новым проектом, установите на форму простую кнопку и сохраните проект в папку 27-01. Имена проекта, формы, модуля и кнопки изменять не нужно, оставьте имена, данные по умолчанию.
Далее, сгенерируйте событие OnClick для кнопки, в котором напишите следующий код:
Что мы тут делаем? Целочисленную переменную i используем в качестве счетчика для цикла for . Цикл производим от -3 до 3, то есть, 7 раз, включая ноль. В теле цикла мы делим 10 на значение i , результат оформляем в виде строки и добавляем к списку строк st . Выше говорилось, что подобные действия нужно заключать в блок обработки исключительных ситуаций try-finally-end , что мы и сделали.
Если вы внимательно изучали курс, то невооруженным глазом видите, что при четвертом проходе цикла произойдет ошибка времени выполнения - деление 10 на ноль. Такой очевидный пример больше всего подходит для знакомства с встроенным отладчиком, так как вы уже знаете, где будет ошибка, и сможете проанализировать работу отладчика. Поэтому притворимся, что не подозреваем об ошибке.
Ну что, ничего криминального тут нет, почему же произошла ошибка? Код верный и должен был нормально выполняться… Когда вы заходите в подобный тупик , помочь вам может здравый смысл и встроенный отладчик. Здравый смысл говорит, что ошибка произошла где-то в теле цикла for . А чтобы воспользоваться отладчиком, нужно приостановить выполнение программы на этом цикле, чтобы потом построчно его продолжить. Для остановки работы программы служат так называемые точки останова (англ. breakpoints).
Точки останова - это строки, перед выполнением которых отладчик приостанавливает выполнение программы, и ждет ваших дальнейших действий.Вы можете установить одну такую точку или несколько, в различных частях кода. Поскольку ошибка возникает в 42-й строке, разумней будет приостановить выполнение на предыдущей, 41-й строке. Переведите курсор на эту строку, на любое её место .
Установить точку останова можно разными способами:
- Командой главного меню "Запуск -> Добавить точку останова -> Точка останова в исходном коде". В открывшемся окне "Параметры точки останова" нажать "ОК".
- Щелкнуть по строке правой кнопкой, и в всплывающем меню выбрать "Отладка -> Переключить точку останова".
- Нажать "горячую клавишу" <F5>.
- Щелкнуть по нужной строке в левой части Редактора кода, где указаны номера строк.
Последние два способа наиболее удобны, но выбирать вам. В любом случае, строка с установленной точкой останова окрасится красным цветом:

Снять точку останова удобней также последними двумя способами. Точка останова у нас есть, снова нажимаем кнопку "Запустить". Программа начинает свою работу, нажимаем кнопку "Button1".
Теперь программа не вывела ошибку, а приостановила свою работу и вывела на передний план Редактор кодов с выделенной серым цветом строкой, которая в данный момент готовится к выполнению:

Тут очень важно понимать, что программа была остановлена ДО выполнения этой строки, а не ПОСЛЕ неё. То есть, в настоящий момент переменной i еще не присвоено значение -3. Далее, мы можем выполнять с отладчиком различные действия, которые собраны в разделе главного меню "Запуск". Обычно требуется пошаговое выполнение программы. Для этого можно использовать команду "Запуск -> Шаг в обход" (или <F8>), "Запуск -> Шаг с входом" (или <F7>) или "Запуск -> Шаг с выходом" (или <Shift+F8>). "Шаг в обход" означает, что если в коде будет встречен вызов какой-нибудь функции или процедуры, отладчик выполнит их и остановится на следующей после вызова строке. При выборе "Шаг со входом", отладчик также пошагово будет выполнять и вызываемые функции-процедуры. "Шаг с выходом" подразумевает, что если в строке нет вызовов функций, то остановки происходят, как при "Шаг в обход". Если в строке есть выражение , то остановка происходит вначале перед строкой, затем перед вычислением каждой функции, чтобы мы имели возможность просмотреть значения параметров, передаваемых в функцию.
У нас вызовов функций нет, поэтому мы можем воспользоваться как <F7>, так и <F8> (чаще всего используют <F8> - Шаг в обход).
Итак, нажмем <F8>, и отладчик выполнит строку с точкой останова, и выделит серым следующую строку. Снова нажмем <F8>, и снова будет выделена эта строка - был выполнен шаг цикла . Нажав несколько раз <F8>, мы добьемся появления на экране всё той же ошибки, которая заблокирует дальнейшее выполнение программы. Становится понятно, что цикл нормально выполняется несколько проходов, после чего всё же возникает ошибка. Включаем логику: внутри цикла у нас изменяется только переменная i, значит, ошибка как-то связана с ней. А как узнать, как именно?
Здесь нам на помощь приходит еще один полезный инструмент отладчика - наблюдение за значениями переменных. Сбросьте программу командой "Запуск -> Сбросить отладчик". Теперь снова нажмите кнопку "Запустить", а потом снова кнопку "Button1". Отладчик снова приостановил выполнение программы на строчке с циклом, однако не спешите нажимать <F8>. Для начала, добавим наблюдение над переменной i. Делается это командой "Запуск -> Добавить наблюдение", которая была недоступна, пока программа не начала выполняться. В строке "Выражение" укажите переменную i, и нажмите "ОК":

Теперь отладчик наблюдает за значениями переменной i , но нам от этого не легче - мы то не видим этих значений! Чтобы их увидеть, нужно вывести на экран окно Списка наблюдений. Делается это командой "Вид -> Окна отладки -> Окно наблюдений" или "горячими клавишами" <Ctrl+Alt+W>.
которое у нас должно вычисляться внутри цикла . В окне Списка наблюдения вы увидите и переменную i , и выражение , а также их значения:

Поскольку переменной i еще не было присвоено значения -3, то в колонке значений вы, скорее всего, увидите 1, которым по умолчанию была проинициализирована наша переменная . Соответственное значение будет и у выражения. Теперь мы готовы двигаться дальше. Нажимаем <F8>. В Списке наблюдений сразу же изменилась картина - i теперь равно -3, а выражение -3,3333…
Нажимаем <F8> ещё раз. Снова значения изменились, теперь i = -2 , а выражение = -5. Мы понимаем, что цикл работает, и два его шага были сделаны. Нажимаем <F8> еще два раза. Сейчас переменная содержит ноль, а значение выражения указывает " inf ". Однако строка с вычислением еще не была выполнена, не забываем об этом. Снова нажимаем <F8>, и снова получаем ошибку. А в значениях переменной и выражения видим слово " evaluating ", что переводится, как "оценка". Теперь мы наглядно видим, что в строке
возникает ошибка, когда переменная i равна нулю. И тут уже несложно догадаться, почему эта ошибка возникает - потому что происходит попытка деления 10 на 0.
Как видите, вычисление , где i равна нулю, было пропущено.
Встроенный отладчик имеет и другие инструменты, с которыми вы сами сможете со временем освоиться, экспериментируя с ними.

Итак, разобрались со средой разработки, теперь можно загрузить первую прошивку. Можно загрузить пустую прошивку, чтобы просто убедиться, что все драйвера установились и платы вообще прошиваются. Рекомендуется делать это с новой платой, к которой никогда не подключались датчики и модули, чтобы исключить выход платы из строя по вине пользователя.
1. Плата подключается к компьютеру по USB, на ней должны замигать светодиоды. Если этого не произошло:
- Неисправен USB кабель
- Неисправен USB порт компьютера
- Неисправен USB порт Arduino
- Попробуйте другой компьютер, чтобы исключить часть проблем из списка
- Попробуйте другую плату (желательно новую), чтобы исключить часть проблем из списка
- На плате Arduino сгорел входной диод по линии USB из-за короткого замыкания, устроенного пользователем при сборке схемы
- Плата Arduino сгорела полностью из-за неправильного подключения пользователем внешнего питания или короткого замыкания
2. Компьютер издаст характерный сигнал подключения нового оборудования, а при первом подключении появится окошко “Установка нового оборудования”. Если этого не произошло:
- См. предыдущий список неисправностей
- Кабель должен быть data-кабелем, а не “зарядным”
- Кабель желательно втыкать напрямую в компьютер, а не через USB-хаб
- Не установлены драйверы Arduino (во время установки IDE или из папки с программой), вернитесь к установке.
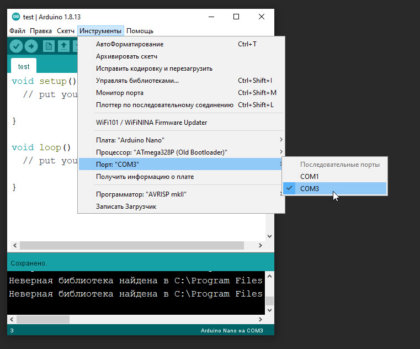
3. В списке портов (Arduino IDE/Инструменты/Порт) появится новый порт, обычно COM3. Если этого не произошло:
- См. предыдущий список неисправностей
- Некорректно установлен драйвер CH341 из предыдущего урока
- Если список портов вообще неактивен – драйвер Arduino установлен некорректно, вернитесь к установке
- Возникла системная ошибка, обратитесь к знакомому компьютерщику
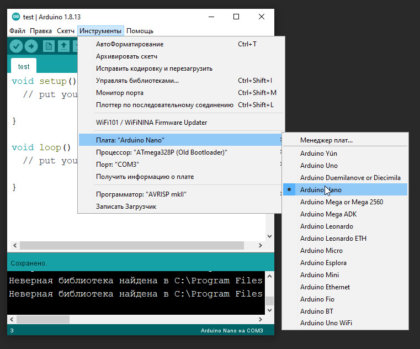

4. Выбираем свою плату. Если это Arduino Nano, выбираем в Инструменты\Плата\Arduino Nano. Если другая – выбираем другую. Нажимаем стрелочку в левом верхнем углу (загрузить прошивку). Да, загружаем пустую прошивку.
- [Только для Arduino Nano] В микроконтроллер китайских нанок зашит “старый” загрузчик, поэтому выбираем Инструменты\Процессор\ATmega328p (Old Bootloader). Некоторые китайцы зашивают в свои платы новый загрузчик, поэтому если прошивка не загрузилась (загрузка идёт минуту и вылетает ошибка avrdude: stk500_getsync()) – попробуйте сменить пункт Процессор на ATmega328p
Если появилась надпись “Загрузка завершена” – значит всё в порядке и можно прошивать другие скетчи. В любом случае на вашем пути встретятся другие два варианта событий, происходящих после нажатия на кнопку “Загрузка” – это ошибка компиляции и ошибка загрузки. Вот их давайте рассмотрим более подробно.
Ошибки компиляции
Возникает на этапе сборки и компиляции прошивки. Ошибки компиляции вызваны проблемами в коде прошивки, то есть проблема сугубо софтварная. Слева от кнопки “загрузить” есть кнопка с галочкой – проверка. Во время проверки производится компиляция прошивки и выявляются ошибки, если таковые имеются. Ардуино в этом случае может быть вообще не подключена к компьютеру.
- В некоторых случаях ошибка возникает при наличии кириллицы (русских букв) в пути к папке со скетчем. Решение: завести для скетчей отдельную папочку в корне диска с английским названием.
- В чёрном окошке в самом низу Arduino IDE можно прочитать полный текстошибки и понять, куда копать
- В скачанных с интернета готовых скетчах часто возникает ошибка с описанием название_файла.h no such file or directory. Это означает, что в скетче используется библиотека <название файла>, и нужно положить её в Program Files/Arduino/libraries/. Ко всем моим проектам всегда идёт папочка с использованными библиотеками, которые нужно установить. Также библиотеки всегда можно поискать в гугле по название файла.
- При использовании каких-то особых библиотек, методов или функций, ошибкой может стать неправильно выбранная плата в “Инструменты/плата“. Пример: прошивки с библиотекой Mouse.h или Keyboard.h компилируются только для Leonardo и Micro.
- Если прошивку пишете вы, то любые синтаксические ошибки в коде будут подсвечены, а снизу в чёрном окошке можно прочитать более детальное описание, в чём собственно косяк. Обычно указывается строка, в которой сделана ошибка, также эта строка подсвечивается красным.
- Иногда причиной ошибки бывает слишком старая, или слишком новая версия Arduino IDE. Читайте комментарии разработчика скетча
- Ошибка недостаточно свободного места возникает по вполне понятным причинам. Если в проекте используется плата Nano на процессоре 328p, а вы сэкономили три рубля и купили на 168 процессоре – скупой платит дважды. Оптимизация: статическая память – память, занимаемая кодом (циклы, функции). Динамическая память занята переменными.
Частые ошибки в коде, приводящие к ошибке компиляции
- expected ‘,’ or ‘;’ – пропущена запятая или точка запятой на предыдущей строке
- stray ‘\320’ in program – русские символы в коде
- expected unqualified-id before numeric constant – имя переменной не может начинаться с цифры
- … was not declared in this scope – переменная или функция используется, но не объявлена. Компилятор не может её найти
- redefinition of … – повторное объявление функции или переменной
- storage size of … isn’t known – массив задан без указания размера
Ошибки загрузки
Возникают на этапе, когда прошивка собрана, скомпилирована, в ней нет критических ошибок, и производится загрузка в плату по кабелю. Ошибка может возникать как по причине неисправностей железа, так и из-за настроек программы и драйверов.
- USB кабель, которым подключается Arduino, должен быть Data-кабелем, а не кабелем только для зарядки. Нужным нам кабелем подключаются к компьютеру плееры и смартфоны.
- Причиной ошибки загрузки являются не установленные/криво установленные драйвера CH340, если у вас китайская NANO.
- Также будет ошибка avrdude: ser_open(): can’t open device, если не выбран COM порт, к которому подключена Arduino. Если кроме COM1 других портов нет – читай два пункта выше, либо попробуй другой USB порт, или вообще другой компьютер.
- Большинство проблем при загрузке, вызванных “зависанием” ардуины или загрузчика, лечатся полным отключением ардуины от питания. Потом вставляем USB и по новой прошиваем.
- Причиной ошибки загрузки может быть неправильно выбранная плата в “Инструменты/Плата”, а также неправильно выбранный процессор в “Инструменты/Процессор”. Также в свежих версиях IDE нужно выбирать ATmega328P (Old Bootloader) для китайских плат NANO.
- Если у вас открыт монитор COM порта в другом окне Arduino IDE или плата общается через СОМ порт с другой программой (Ambibox, HWmonitor, SerialPortPlotter и т.д.), то вы получите ошибку загрузки, потому что порт занят. Отключитесь от порта или закройте другие окна и программы.
- Если у вас задействованы пины RX или TX – отключите от них всё! По этим пинам Arduino общается с компьютером, в том числе для загрузки прошивки.
- Если в описании ошибки встречается bootloader is not responding и not in sync, а все предыдущие пункты этого списка проверены – с вероятностью 95% сдох загрузчик. Второй неприятный исход – загрузчик “слетел”, и его можно прошить заново.
Предупреждения
Помимо ошибок, по причине которых проект вообще не загрузится в плату и не будет работать, есть ещё предупреждения, которые выводятся оранжевым текстом в чёрной области лога ошибок. Предупреждения могут появиться даже тогда, когда выше лога ошибок появилась надпись “Загрузка завершена“. Это означает, что в прошивке нет несовместимых с жизнью ошибок, она скомпилировалась и загрузилась в плату. Что же тогда означают предупреждения? Чаще всего можно увидеть такие:
Завершая раздел Введение в Arduino поговорим о вопросах, которые очень часто возникают у новичков:
- Ардуину можно прошить только один раз? Нет, несколько десятков тысяч раз, всё упирается в ресурс flash памяти. А он довольно большой.
- Как стереть/нужно ли стирать старую прошивку при загрузке новой? Память автоматически очищается при прошивке, старая прошивка автоматически удаляется.
- Можно ли записать две прошивки, чтобы они работали вместе? Нет, при прошивке удаляются абсолютно все старые данные. Из двух прошивок нужно сделать одну, причём так, чтобы не было конфликтов.
- Можно ли “вытащить” прошивку с уже прошитой Ардуины? Теоретически можно, но только в виде нечитаемого машинного кода, в который преобразуется прошивка на С++ при компиляции, т.е. вам это НИКАК не поможет, если вы не имеете диплом по низкоуровневому программированию.
- Зачем это нужно? Например есть у нас прошитый девайс, и мы хотим его “клонировать”. В этом случае да, есть вариант сделать дамп прошивки и загрузить его в другую плату на таком же микроконтроллере.
- Если есть желание почитать код – увы, прошивка считывается в виде бинарного машинного кода, превратить который обратно в читаемый Си-подобный код обычному человеку не под силу
- Вытащить прошивку, выражаясь более научно – сделать дамп прошивки, можно при помощи ISP программатора, об этом можно почитать здесь
- Снять дамп прошивки можно только в том случае, если разработчик не ограничил такую возможность, например записав лок-биты, запрещающие считывание Flash памяти, или вообще отключив SPI шину. Если же разработчик – вы, и есть желание максимально защитить своё устройство от копирования – гуглите про лок-биты и отключение SPI
Видео
9 сентября 2013 Мария (admin)В этом уроке мы создадим нашу первую программу на языке Java.
Создание приложения на языке Java состоит из трех следующих шагов:Создание исходного файла
![lesson2_save]()
Если вы пользуетесь Notepad++ то нужно выбрать Тип файла:Java source file (*.java)
Обратите также внимание на кодировку в которой сохраняете файл. Должно быть выбрано ANSI . В Notepad++ кодировку можно установить в меню Кодировки.
Компиляция исходного файла
Исходный файл с кодом программы создан, теперь перейдем к компиляции. Для компиляции Java предназначен компилятор javac, который входит в состав установленного нами в первом уроке пакета JDK.
Для того, чтобы скомпилировать исходный файл, открываем командную строку. Для этого в меню Windows Пуск в строке поиска вводим команду cmd и жмем Enter. После этого откроется командное окно.
Теперь в нем нужно изменить текущий каталог на тот, в котором находится наш исходный файл (например C:\studyjava\). Для этого вводим следующую команду:
и нажимаем Enter.
После того, как директория изменилась, вводим команду компиляции
После этого, окно командной строки должно выглядеть следующим образом (рис 2.2):
![lesson2_compil]()
То есть, мы не получим никакого подтверждения, о том, что программа скомпилировалась успешно. Однако, в папке с нашим исходным файлом, должен появиться файл HelloWorld.class. Это можно проверить с помощью команды
Эта команда выводит на экран список всех файлов, находящихся в выбранной директории (рис 2.3).
![lesson2_dir]()
Если файл HelloWorld.class присутствует в этом списке, то это значит, что программа скомпилировалась успешно.
Если в коде программы есть ошибка, то компилятор Java при компиляции нам об этом сообщит.
![lesson2_error]()
Запуск программы
Вводим в командном окне:
![Рис 2.5.]()
Еще раз обратите внимание на чувствительность к регистру в Java. Если вы напишете helloworld вместо HelloWorld, то программа запущена не будет, потому что Java попросту не найдет файл с таким именем.
Конечно, для написания, компилирования и запуска программ на языке Java существуют более удобный инструмент, нежели Блокнот и командная строка . Этот так называемая Интегрированная среда обработки IDE. Об этом мы поговорим в следующем уроке.
Категория: Уроки Java![]()
Надоели нестабильные баги в многопоточном коде? Попробуй воспользоваться модел-чекерами! Ведь больше не надо бояться неверифицированных модел-чекеров, работающих либо за экспоненциальное время, либо неоптимально. Все это в прошлом: в Max Planck Institute for Software Systems разработали новый алгоритм под названием TruSt, который решает эти проблемы и, кроме того, верифицирован на Coq.
Меня зовут Владимир Гладштейн. Этим летом я проходил стажировку в MPI-SWS в группе, которая придумала алгоритм нового модел-чекера для поиска багов в многопоточных программах. Этот алгоритм является оптимальным и truly stateless (вследствие чего работает с линейными затратами по памяти). В этом посте я расскажу, как работают модел-чекеры, в каких случаях их можно использовать, и что за алгоритм придумали мои коллеги. А еще как я проверял доказательства его корректности на Coq.
![]()
О себе
Я учусь на 4-ом курсе программы «Математика, алгоритмы и анализ данных» факультета математики и компьютерных наук СПбГУ, а также работаю в Лаборатории языковых инструментов JetBrains Research. Я больше двух лет изучаю формальную верификацию программ и в основном пишу на языке Coq.
О стажировке
Этим летом мне посчастливилось пройти стажировку в Max Planck Institute for Software Systems. Попал я туда неслучайно. Дело в том, что Лаборатория языковых инструментов JBR тесно сотрудничает с этим институтом. В частности, руководитель моей группы Антон Подкопаев был постдоком у профессора MPI Виктора Вафеядиса. Поэтому с рекомендацией от Антона на меня быстро обратили внимание и устроили собеседование с Виктором. В итоге меня зачислили стажером на два месяца — с июля по август 2021 года. Стажировка проходила дистанционно.
О проекте, в котором я работал
В начале лета команда в MPI-SWS, к которой я присоединился, готовилась к подаче статьи на конференцию POPL. Если вкратце, они придумали алгоритм нового модел-чекера (далее МС) для поиска багов в многопоточных программах и предложили мне формально проверить доказательства его корректности на Coq. Этой задачей я и занимался.
Но давайте обо всем по порядку. Начнем с Coq.
O Coq
Coq — это функциональный язык программирования с очень мощной системой зависимых типов. С помощью нее по соответствию Карри-Говарда в Coq удается формулировать и на специальном языке записывать доказательства теорем, которые он сможет проверить. Примеры формулировок теорем в Coq у нас еще будут, а пока, чтобы представлять о чем речь, можно почитать начало мягкого введения. Главное, что тут надо понять — на этом языке можно написать доказательство теоремы, и он его проверит. Среди CS сообщества считается, что теоремы, проверенные на Coq, не содержат ошибок в доказательствах.
О багах в многопоточном коде
Давайте разберем пример такой программы. Пример довольно объемный, но он поможет понять, в каких случаях разумно использовать модел-чекеры. Если хотите пропустить пример, жмите сюда.
Представьте себе любимый банк. А теперь представьте, что вас назначили программистом в этом банке и попросили написать код для обслуживания очередей. Человек приходит в банк, берет номерок и ждет своей очереди.
Условно ваша программа должна уметь:
Хранить номер билетика, который будет выдан следующему человеку;
Хранить номер билета человека, которого сейчас обслуживают;
Выдавать новые билеты;
Менять номер обслуживающегося билета.
Давайте попробуем написать такое на C, используя многопоточность. Сначала заведем структуру, описывающую память нашего автомата по выдаче билетов:
Так как мы будем писать многопоточный код, в котором поля данной структуры будут шариться между потоками, нам необходимо сделать их не просто int, a atomic_int.
Теперь давайте опишем процедуру выдачи билета человеку с его последующим ожиданием своей очереди:
Теперь можно описать процедуру перехода очереди от одного человека к другому:
Для простоты будем считать, что обслуживание человека заключается в том, что он кладет одну денежку на некоторый счет x, а потом происходит проверка, что значение x действительно увеличилось на один:
Однако наш банк должен обслуживать много людей, поэтому, чтобы смоделировать его работу, надо запустить процедуру thread в нескольких потоках одновременно:
Как мы хотим, чтобы работала наша программа? Рассмотрим на примере двух потоков (N_THREADS = 2).
Будем придерживаться модели памяти Sequential Consistency (то есть можно считать, что при запуске программы инструкции разных потоков перемешиваются, сохраняя свой порядок внутри одного потока, и запускается однопоточный код).
Допустим в банк пришли Петя (первый поток) и Вася (второй поток). В нормальной ситуации они находятся сначала на строке:
Предположим, что сначала работает первый поток (то есть Петя первый взял билетик):
Он получает билет номер 0, и следующий билет будет уже иметь номер 1. Потом, например, сюда может встроиться Васин (второй) поток и оттуда выполнится три строчки (Вася возьмет свой билет и сядет в очередь):
Наконец встраивается первый поток: Петя спокойно перескакивает бесконечный цикл (а не садится туда ждать), потому что номер его билета совпадает с номером билета, который будут обслуживать.
Далее первый поток выходит из ticket_lock и начинается обслуживание Пети:
Тут Васин поток не может никуда встроиться до того, как мы выполним ticketlock_unlock(&lock) , потому что пока в Петином потоке не выполнится ticketlock_unlock(&lock) , номер Васиного билета (1) не совпадет с номером обслуживаемого человека (0), и Вася не сможет выйти из цикла . Также ясно, что assert не нарушится, потому что сначала Петя увеличит значение x (там будет 1, а в y — 0), потом то же самое сделает Вася.
Это хорошее поведение программы, так как хоть потоки и исполняются параллельно, мы не можем начать обслуживать Васю, пока не закончим обслуживать Петю.
Теперь вопрос: может ли когда-то нарушится проверяемый assert ? И ответ: к сожалению, да. На самом деле этот assert нарушается ровно тогда, когда в процесс обслуживания одного клиента встраивается обслуживание другого. Давайте посмотрим, как это может произойти в случае, если у нас два потока.
Предположим теперь, что сначала в первом потоке выполняется первая инструкция ticketlock_lock :
Потом сразу вмешивается второй поток, и там выполняются первые две инструкции:
Наконец, выполняется следующая инструкция первого потока:
Далее ни один из потоков не зависает в цикле while, и они оба выходят из ticketlock_lock . Это плохо, потому что теперь мы можем случайно начать обслуживать их одновременно, а это иногда приводит к разного рода ошибкам (в частности, нарушения assert ’a).
События могут развиваться как-то так: сначала, первый поток продолжает
Тут сразу встроился Вася:
И в итоге в первом потоке в y находится 0, а х уже равен 2, что ведет к невыполнению assert ’a.
Ясно, что тут возникла проблема, потому что Вася получил свой билет до того, как наша программа успела до конца обработать получение билета Петей. Поэтому чтобы ее решить, надо просто сделать так, чтобы один поток не мог влезть между двумя инструкциями, отвечающими за выдачу билета, пока их исполняет другой поток. А именно:
Для этого можно их объединить в одну атомарную инструкцию:
«Плохой» способ выполнения программы происходит достаточно редко, так что тестами его отловить непросто. Именно поэтому тут нужен какой-нибудь другой путь проверки ее корректности.
О Model Checker
Чтобы ловить такие баги, можно использовать MC. Что они делают? Это специальные программы, которые на вход берут ваш многопоточный код и стараются некоторым способом обойти все возможные сцены его исполнения (может быть по модулю некоторой эквивалентности). Для того чтобы понять, как они работают, давайте обратимся к семантике многопоточных программ.
О семантике многопоточных программ
Каждой многопоточной программе можно поставить в соответствие некоторый «граф исполнения». Каждый такой граф описывает определенное множество исполнений программы, ведущих к одному и тому же результату. То есть если у вас есть на руках такой граф, вы можете «почти» сказать, как исполнилась программа, но этого «почти» хватает, чтобы например понять, нарушались ли какие-то assert’ы или нет.
Пример: рассмотрим программу на неком псевдоязыке:
Тут мы сначала записываем в x 0, потом в двух разных потоках пишем 1 и 2, и в конце читаем из x .
Этой программе соответствует несколько «графов исполнения». Например, такой:
![]()
В этом графе есть два типа вершин, они называются событиями:
W(x,i) — запись в переменную x числа i (например, инструкции x := 0 соответствует W(x,0) );
R(x,j) — чтение из переменной x числа j (например, если мы в r := x прочитали 2, то этому будет соответствовать R(x,2)).
И два типа ребер:
Серые — program order. Они соответствуют порядку инструкций (например x:=1 идет после x:=0, поэтому между ними стоит стрелка);
Зеленые — reads from. Они показывают, откуда событие чтения берет свое значение (в данном случает r := x читает из x:= 2).
Смотря на этот граф, легко понять, что assert не срабатывает.
О моделях памяти
Запуская один и тот же код на разных языках или на разных процессорах, мы можем наблюдать разные поведения. Почему так происходит? Дело в том, что над вашим кодом компилятор, а потом и сам процессор могут проявлять разного рода оптимизации. Эти оптимизации изначально были написаны для однопоточного кода, поэтому они могут привести к тому, что программа поведет себя совсем не так как вы хотите (подробнее тут). Ну и отличия в поведениях программ как раз обуславливаются тем, что при разных энвайронментах эти оптимизации разные. Модели поведения многопоточных программ называются моделями памяти (далее MM). Самая простая и известная MM — это Sequential Consistency.
Если мы хорошо изучим конкретную ММ, то сможем по графу исполнения программы говорить, допустим он или нет при данной ММ. Поэтому ММ часто моделируются просто предикатами на графах.
О проблемах model checker
Итак, задача MC заключается в переборе всех возможных графов соответствующих данной программе.
MC можно оценивать по большому количеству параметров, вот три из них:
Оптимальность: так как MC занимается обходом графов, можно говорить, что он оптимален если обходит каждый граф соответствующий программе ровно один раз
Stateless/explicit-state: MC может хранить какие-то данные о графах, которые он уже обошел. Если он вообще никакой информации не хранит, то будем называть его Stateless.
Параметричность по MM: будем говорить, что МС параметричен по MM, если он работает для различных MM. Математически это моделируется так, что MC принимает на вход некоторый предикат на графах исчисления cons и дальше исследует графы, соответствующие этому предикату.
Самые успешные существующие MC являются параметричными по модели памяти, оптимальными и почти Stateless. То есть они не посещают одни и те же графы несколько раз, однако, хранят какую-то информацию о своей предыдущей работе, что ведет к экспоненциальным затратам по памяти.
О TruSt
Наконец, новый алгоритм, который был разработан в MPI-SWS, является первым оптимальным, параметричным по модели памяти и в то же время Stateless (вследствие чего имеет линейные затраты по памяти). Поэтому он и называется TruSt (Truly Stateless).
Tут, однако, стоит отметить, что он работает не для всех моделей памяти, а лишь для тех, которые удовлетворяют некоторым условиям. Сюда подходят такие модели памяти, как Sequential consistency (SC), Total store ordering (TSO) (еще про эту модель можно почитать тут), Partial store ordering (PSO), а также фрагмент модели памяти языка С/С++ (RC11).
MC ищет ошибки в многопоточной программе, но кто гарантирует, что в самом алгоритме МС нет ошибок? Ведь если они есть, model checker может ввести пользователя в заблуждение. Поэтому важно формально верифицировать МС. Как раз этим я и занимался. Я взял псевдокод, на котором алгоритм был представлен в статье, закодировал это в Coq и формально проверил некоторые теоремы о корректности этого алгоритма.
К сожалению, сам алгоритм устроен довольно сложно, и я не смогу его здесь описать. Все подробности можно найти в статье. А сейчас я расскажу достаточно общую схему того, как он был закодирован на языке Coq.
Зафиксируем для начала некоторый предикат модели памяти на графах сons :
Примерно так этот алгоритм и реализован. Посмотрим, как его кодировать в Coq.
Будем говорить, что граф G1 связан отношением ⇒ с графом G2 (и писать G1 ⇒ G2) если Visit(P, G1) вызовет Visit(P, G2) на верхнем уровне рекурсии. Далее введем некоторые обозначения:
G1 ⇒k G2 будет значить, что G1 ⇒ ..k раз. ⇒ G2
G1 ⇒* G2 будет значить, что существует некоторый k такой, что G1 ⇒k G2
О том, что я проверил на Coq
Корректность
Theorem TruSt_Correct : forall G, G0 ⇒* G -> cons G
Эта теорема говорит о том, что если мы за какое-то количество шагов можем дойти из начального графа в граф G, то граф G является консистентным. Эта теорема доказывается тривиально, так как алгоритм явно на каждом шаге проверяет графы на консистентность.
Терминируемость
Theorem TruSt_Terminate : exists B, forall G, G0 ⇒k G -> k < B
Есть некоторая оценка на количество вложенных вызовов рекурсии алгоритма. Тут надо пояснить, что весь этот метод работает только для конечных программ. То есть это должны быть программы без бесконечных циклов и рекурсий (если в нашей программе есть потенциально бесконечный цикл, то мы просто разворачиваем его на наперед заданную глубину и верификация происходит по модулю этой глубины). Далее можно доказать, что есть некоторые события, которые никогда не удаляются (а только добавляются) в ходе рекурсивных вызовов алгоритма. Из этого легко следует терминируемость.
Полнота
Theorem TruSt_Complete : forall G, cons G /\ p_sem G -> G0 ⇒* G
Тут написано, что если
cons G — граф G консистентен
p _sem G — граф G кодирует некоторое исполнение нашей программы,
то мы этот граф встретим на каком-то рекурсивном вызове. То есть эта теорема гарантирует, что мы точно проверим все возможные исходы.
Это одна из самых сложных теорем. Для ее доказательства пришлось построить обратный алгоритм для Visit: Prev . То есть Prev каждому консистентному графу (относительно cons ) сопоставляет его непосредственного предка относительно ⇒ (если он существует). Prev получается записать намного проще, чем Visit, более того, он будет детерминированным, так что доказывать теоремы для него проще. Далее показываются две вещи:
если Prev G = G’ , то G’ ⇒ G
если cons G и p_sem G , то последовательно применяя Prev к G мы всегда придем к пустому графу.
Из этого легко следует теорема.
Оптимальность
В Coq ее сформулировать не очень просто, поэтому покажу схематично. Пусть
G0 ⇒ G1 ⇒ G2 ⇒ … ⇒ Gn есть последовательность шагов из пустого графа в некоторый Gn
G0 ⇒ H1 ⇒ H2 ⇒ … ⇒ Hn есть последовательность шагов из пустого графа в некоторый Hn и
Тогда и все промежуточные графы тоже будут равны. То есть мы не посетим один и тот же граф два раза.
Эта теорема тоже очень непростая и следует из того, что обратная процедура к Visit детерминирована.
Итоги
В итоге я проверил на Coq полный набор теорем про корректность представленного алгоритма. В ходе этой проверки было:
Найдена куча ошибок и неточностей в доказательствах на бумажке. Некоторые леммы не доказывались в том виде, в котором они были сформулированы, и пришлось придумывать новые формулировки.
Некоторые теоремы (например, теорема об оптимальности) были переформулированы, чтоб точнее ухватить суть вещи, которую мы хотим доказать.
Также в ходе формализации я заметил, что одно место в алгоритме является избыточным, и его убрали. Если вкратце, то в этом месте делалась проверка, которая следовала из других проверок. Так как на корректность алгоритма это не влияло, то понять, что оно лишнее, было непросто. Я заметил, что в доказательствах оно не играет роли, и предложил его убрать.
Заключение
В этом проекте мне пришлось во многом выйти из своей зоны комфорта: я писал его на новом для себя диалекте языка Coq, общался с людьми на английском, пользовался GitLab’ом и т.д. Это однозначно ценный опыт, но самое главное, что мне удалось поработать с мега крутыми специалистами в области Weak Memory. Надеюсь, что я смогу продолжить сотрудничать с ними в будущем. Это была очень крутая стажировка!
Читайте также:







