
Excel выбор из базы данных
Обновлено: 07.07.2024
Мало пользователей, да и начинающих программистов, которые знают о возможности Excel подключаться к внешним источникам, и в частности к SQL серверу, для загрузки данных из этих источников. Эта возможность достаточно полезна, поэтому сегодня мы займемся ее рассмотрением.
Функционал Excel получения данных из внешних источников значительно упростит выгрузку данных с SQL сервера, так как Вам не придется просить об этом программиста, к тому же данные попадают сразу в Excel. Для этого достаточно один раз настроить подключение и в случае необходимости получать данные в Excel из любых таблиц и представлений Views, из базы настроенной в источнике, естественно таких источников может быть много, например, если у Вас несколько баз данных.
Задача для получения данных в Excel
И для того чтобы более понятно рассмотреть данную возможность, мы это будем делать как обычно на примере. Другими словами допустим, что нам надо выгрузить данные, одной таблицы, из базы SQL сервера, средствами Excel, т.е. без помощи вспомогательных инструментов, таких как Management Studio SQL сервера.
Примечание! Все действия мы будем делать, используя Excel 2010. SQL сервер у нас будет MS Sql 2008.
И для начала разберем исходные данные, допустим, есть база test, а в ней таблица test_table, данные которой нам нужно получить, для примера будут следующими:
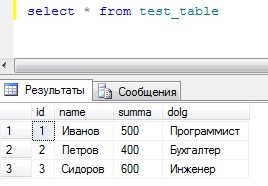
Эти данные располагаются в таблице test_table базы test, их я получил с помощью простого SQL запроса select, который я выполнил в окне запросов Management Studio. И если Вы программист SQL сервера, то Вы можете выгрузить эти данные в Excel путем простого копирования (данные не большие), или используя средство импорта и экспорта MS Sql 2008. Но сейчас речь идет о том, чтобы простые пользователи могли выгружать эти данные.
Заметка! Если Вас интересует SQL и T-SQL, рекомендую посмотреть мои видеокурсы по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать с использованием языка T-SQL в Microsoft SQL Server.
Настройка Excel для получения данных с SQL сервера
Настройка, делается достаточно просто, но требует определенных навыков и консультации администратора SQL сервера. Вы, конечно, можете попросить программиста настроить Excel на работу или сделать это сами, просто спросив пару пунктов, а каких мы сейчас узнаем.
И первое что нам нужно сделать, это конечно открыть Excel 2010. Затем перейти на вкладку «Данные» и нажать на кнопку «Из других источников» и выбрать «С сервера SQL Server»
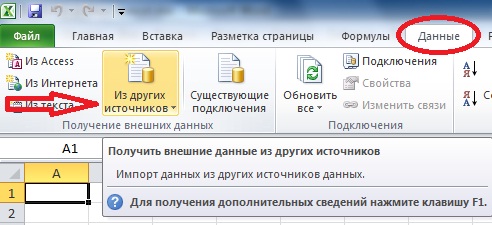
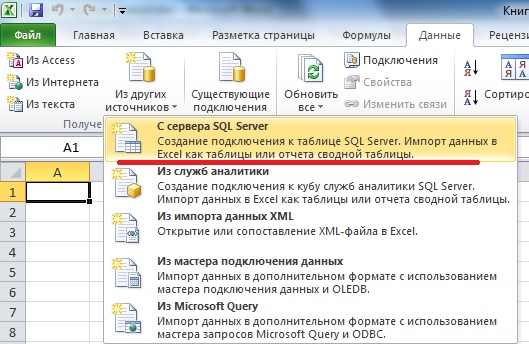
Затем у Вас откроется окно «Мастер подключения данных» в котором Вам необходимо, указать на каком сервере располагается база данных и вариант проверки подлинности. Вот именно это Вам придется узнать у администратора баз данных, а если Вы и есть администратор, то заполняйте поля и жмите «Далее».
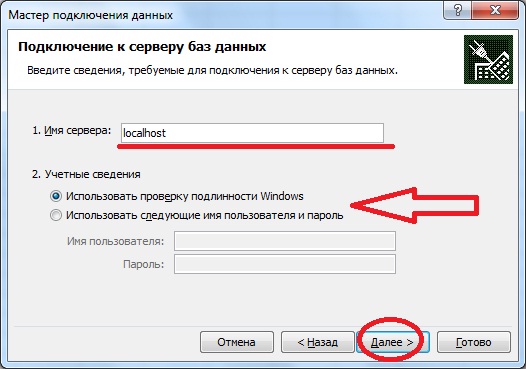
- Имя сервера – это адрес Вашего сервера, здесь можно указывать как ip адрес так и DNS имя, в моем случае сервер расположен на этом же компьютере поэтому я и указал localhost;
- Учетные данные – т.е. это логин и пароль подключения к серверу, здесь возможно два варианта, первый это когда в сети Вашей организации развернута Active directory (Служба каталогов или домен), то в этом случае можно указать, что использовать те данные, под которыми Вы загрузили компьютер, т.е. доступы доменной учетки, и в этом случае никаких паролей здесь вводить не надо, единственное замечание что и на MSSql сервере должна стоять такая настройка по проверки подлинности. У меня именно так и настроено, поэтому я и выбрал этот пункт. А второй вариант, это когда администратор сам заводит учетные данные на SQL сервере и выдает их Вам, и в этом случае он должен их Вам предоставить.
Далее необходимо выбрать базу, к которой подключаться, в нашем примере это база test. Также это подключение можно настроить сразу на работу с определенной таблицей или представлением, список таблиц и представлений у Вас будет отображен, давайте мы сделаем именно так и настроем подключение сразу на нашу таблицу test_table. Если Вы не хотите этого, а хотите чтобы Вы подключались к базе и потом выбирали нужную таблицу, то не ставьте галочку напротив пункта «Подключаться к определенной таблице», а как я уже сказал, мы поставим эту галочку и жмем «Далее».
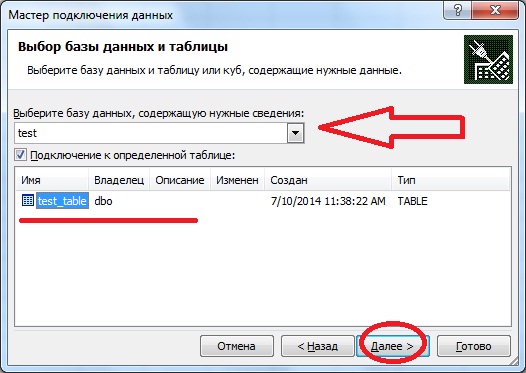
В следующем окне нам предложат задать имя файла подключения, название и описание, я например, написал вот так:

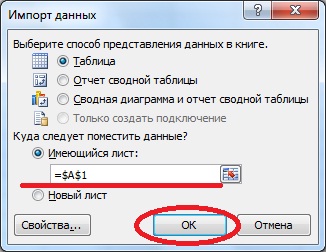
После того как Вы нажмете «Готово» у Вас откроется окно импорта этих данных, где можно указать в какие ячейки копировать данные, я например, по стандарту выгружу данные, начиная с первой ячейки, и жмем «ОК»:
В итоге у меня загрузятся из базы вот такие данные:
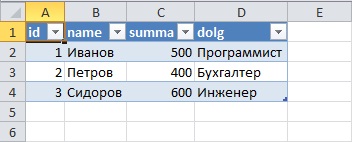
Т.е. в точности как в базе. Теперь когда, например, изменились данные в этой таблице, и Вы хотите выгрузить их повторно Вам не нужно повторять все заново, достаточно в excel перейти на вкладку «Данные» нажать кнопку «Существующие подключения» и выбрать соответствующее, т.е. то которое Вы только что создали.
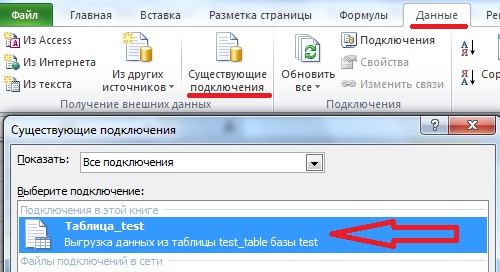
Вот собственно и все, как мне кажется все достаточно просто.
Таким способом получать данные в Excel из базы SQL сервера очень удобно и главное быстро, надеюсь, Вам пригодятся эти знания полученные в сегодняшнем уроке. Удачи!
Представьте себе ситуацию, Вы получили целевую выборку из одной базы данных, но для полноты картины, как всегда, нужны дополнительные данные. Проблема может быть в том, что нужная информация хранится в другой базе данных и возможности создать на ней свою таблицу нет, подключиться используя link тоже нельзя, да и количество элементов, по которым нужно получить данные, несколько больше, чем допустимое на данном источнике. Вот и получается, что возможность написать SQL запрос и получить нужные данные есть, но написать придется не один запрос, а потом потратить время на объединение полученных данных.
Выйти из подобной ситуации поможет Excel.
Уверен, что ни для кого не секрет, что MS Excel имеет встроенный модуль VBA и надстройки, позволяющие подключаться к внешним источникам данных, то есть по сути является мощным инструментом для аналитики, а значит идеально подходит для решения подобных задач.
Для того чтобы обойти проблему, нам потребуется таблица с целевой выборкой, в которой содержатся идентификаторы, по которым можно достаточно корректно получить недостающую информацию (это может быть уникальный идентификатор, назовем его ID, или набор из данных, находящихся в разных столбцах), ПК с установленным MS Excel, и доступом к БД с недостающей информацией и, конечно, желание получить ту самую информацию.
Создаем в MS Excel книгу, на листе которой размещаем таблицу с идентификаторами, по которым будем в дальнейшем формировать запрос (если у нас есть уникальный идентификатор, для обеспечения максимальной скорости обработки таблицу лучше представить в виде одного столбца), сохраняем книгу в формате *.xlsm, после чего приступаем к созданию макроса.
Через меню «Разработчик» открываем встроенный VBA редактор и начинаем творить.
Sub job_sql() — Пусть наш макрос называется job_sql.
Пропишем переменные для подключения к БД, записи данных и запроса:
Dim cn As ADODB.Connection Dim rs As ADODB.Recordset Dim sql As StringОпишем параметры подключения:
Объявим процедуру свойства, для присвоения значения:
Set cn = New ADODB.Connection cn.Provider = " SQLOLEDB.1" cn.ConnectionString = sql cn.ConnectionTimeout = 0 cn.OpenВот теперь можно приступать непосредственно к делу.
Как вы уже поняли конечное значение i=1000 здесь только для примера, а в реальности конечное значение соответствует количеству строк в Вашей таблице. В целях унификации можно использовать автоматический способ подсчета количества строк, например, вот такую конструкцию:
Тогда открытие цикла будет выглядеть так:
Как я уже говорил выше MS Excel является мощным инструментом для аналитики, и возможности Excel VBA не заканчиваются на простом переборе значений или комбинаций значений. При наличии известных Вам закономерностей можно ограничить объем выгружаемой из БД информации путем добавления в макрос простых условий, например:
Итак, мы определились с объемом и условиями выборки, организовали подключение к БД и готовы формировать запрос. Предположим, что нам нужно получить информацию о размере ежемесячного платежа [Ежемесячный платеж] из таблицы [payments].[refinans_credit], но только по тем случаям, когда размер ежемесячного платежа больше 0
sql = "select [Ежемесячный платеж] from [PAYMENTS].[refinans_credit] " & _ "where [Ежемесячный платеж]>0 and [Номер заявки] ='" & Cells(i, 1) & "' "Если значений для формирования запроса несколько, соответственно прописываем их в запросе:
"where [Ежемесячный платеж]>0 and [Номер заявки] = '" & Cells(i, 1) & "' " & _ " and [Дата платежа]='" & Cells(i, 2) & "'"В целях самоконтроля я обычно записываю сформированный макросом запрос, чтобы иметь возможность проверить его корректность и работоспособность, для этого добавим вот такую строчку:
Совсем недавно мне была поставлена задача, написать сервис, который будет заниматься всего лишь одной, но очень емкой задачей – собирать большой объем данных из базы, агрегировать и заполнять все это в Excel по определенному шаблону. В процессе поиска лучшего решения было опробовано несколько подходов, решены проблемы, связанные с памятью и производительностью. В этой статье я хочу поделиться с вами основными моментами и этапами реализации данной задачи.
1. Постановка задачи
В связи с тем, что мне нельзя разглашать подробности ТЗ, сущности, алгоритмы сбора данных и т. д. Пришлось придумать что-то аналогичное:
У нас есть 3 таблицы:
User. Хранит имя пользователя и его некий рейтинг (не важно откуда он берется и как считается)
Состав колонок будет следующим:

В Excel Заказчик хочет видеть 4 колонки 1) message_date. 2) name. 3) rating. 4) text. Ограничение по количеству строк 1 млн. Надо заполнить этими данными excel, а дальше заказчик уже будет работать с этими данными в екселе самостоятельно.
2. Задача понятна, начнем поиск решения
Так как в компании все стараются придерживаться единого стиля в разработке приложений, то и мне пришлось начать с самого обычного подхода, который используется во всех остальных микросервисах – это Spring + Hibernate для запуска приложения и работы с БД. В качестве БД используется Oracle, хотя использование любой другой СУБД будет плюс минус похожим.
Для старта приложения нам понадобится зависимость spring-boot-starter-data-jpa, которая объединяет в себе сразу Spring Data, Hibernate и JPA, все это нам понадобится для удобства работы с БД и нашими сущностями.
Для тестирования добавим spring-boot-starter-test
И еще нам нужен сам драйвер для подключения к БД
Далее нам нужно добавить некоторые настройки конфигурации. У нас будет один метод, который будет ходить в таблицу TASK, искать задачу в статусе “CREATED” и, если такая задача существует, то запускать генерацию отчета с параметрами. Предполагается, что генерация отчета может быть долгой, поэтому наш метод будет запускаться по расписанию в два потока асинхронными процессами. Так же для Spring Data укажем наш репозиторий для поиска соответствующих сущностей. Класс конфигурации будет выглядеть следующим образом:
Класс генерации отчетов содержит в себе @Scheduled метод, который раз в минуту ищет Task и, если находит, то запускает генерацию отчета с параметрами из этой таски.
Класс стартер приложения не имеет ничего примечательного, весь код можно посмотреть на GitHub.
3. Выборка данных из БД
Т.к. в компании повсеместно используется Hibernate было решено использовать его. Добавлено entity MessageData с необходимым набором полей (id, name, rating, messageDate, test). Первой попыткой выбрать необходимые данные была попытка в лоб – выгрузить все в List<Message> с помощью простого метода:
А дальше уже в цикле создавать объекты MessageData и обогащать их недостающими данными. Было очевидно, что данных подход в корне не верный и выгружать сразу миллион записей в List как минимум медленно. Но для эксперимента и замера скорости работы проверить хотелось, чтобы потом сравнить с другими вариантами. Но в результате данный набор записей выгружался около 30 минут после чего было получено OutOfMemoryError и на этом эксперимент завершился.
Даже если бы пользователь задал узкие рамки в параметрах и нам бы удалось выбрать все в один List, то дальше мы бы столкнулись со следующей проблемой – для заполнения всех необходимых колонок нужно было бы собирать id пользователей, идти снова в базу, получать их имена и рейтинги, и заполнить уже с полными данными. Сложность такого алгоритма вырастала в разы. Было понятно, что выборку надо производить по частям и переложить все возможные действия с данными на сторону бд. Чтобы не выбирать все разом и, чтобы не городить велосипедов, было решено использовать ScrollableResults. Это позволяет нам получить ссылку на курсор и итерироваться по результатам с определенным шагом. Далее пришлось переписать запрос так, чтобы он возвращал сразу все необходимые данные уже после всех джойнов, объединений, группировок и т. д.
Следующий вопрос – где хранить сам текст запроса. Это был не простая ситуация т.к. в действительности количество таблиц, которые участвовали в запросе было около десяти, количество джойнов и всяческих группировок было огромным, в результате чего текст запроса вышел на 200+ строк после ревью всевозможных коллег и утверждении самим тех лидом. Хранить такой запрос в java коде не хотелось, плюс в нем были захардкожены некоторые константы в условиях и светить ими в общем репозитории было бы неправильно. Для решения всех этих вопросов мне на помощь пришла идея использовать view. Весь текст запроса прекрасно туда вписывался, плюс на выходе мы получаем готовую сущность, с которой может работать hibernate как с обычной entity.
По началу все выглядело нормально, запрос на выборку 1 млн таких строк выполнялся за разумные 10 мин. или около того. Немного больше, чем хотелось бы, но заказчика это устраивало. Однако в процессе тестирования обнаружился серьезный минус такого подхода – когда мы выбираем 1 млн записей, запрос выполняется 10 минут, но когда мы хотим отчет по короче и указываем в параметрах границы даты поуже – у нас запрос так же выполняется 10 минут, но в результате мы можем получить хоть 1 запись, хоть миллион. Суть в том, что внутрь запроса view нельзя передавать параметры, мы можем только выполнить статический запрос и уже на результат наложить параметры. Поэтому не важно сколько будет в результате строк, в первую очередь будет выбрано все, что найдется в бд, а только потом будет применены параметры. Заказчику было все равно, его устраивало и то, что отчет с одной строкой будет формироваться практически за такое же время, что и отчет с 1 млн строк. Однако это излишне нагружало бд и было решено отказаться от этого варианта.
Оставался всего один вариант, который нам подходил – это хранимая в бд функция. В нее можно передавать параметры, она может вернуть ссылку на курсор и ее результат можно удобно маппить на нашу entity. Таким образом была описана функция, которая принимала на вход несколько параметров, и возвращала sys_refcursor, весь скрипт занял около 300 строк в реальности, а в упрощенном варианте здесь она выглядит так:
Теперь как ее использовать? Для этого отлично подходит @NamedNativeQuery. Запрос для вызова функции выглядит следующим образом: "< ? = call message_ref(?, ?) >", callable = true дает понять, что запрос представляет собой вызов функции, cacheMode = CacheModeType.IGNORE для указания не использовать кэш, т. к. скорость работы нам не так критична, как затрачиваемая память, ну и в конце resultClass = MessageData.class для маппинга результата на нашу entity. Класс MessageData выглядит следующим образом:
Для того чтобы не использовать кэш было решено выполнять запрос в StatelessSession. Однако есть важная особенность: если попытаться вызвать namedQuery то hibernate при попытке установить CacheMode выдаст UnsupportedOperationException. Чтобы этого избежать необходимо установить два хинта:
В итоге наш метод генерации имеет следующий вид:
4. Запись данных в Excel
На данном этапе вопрос с выборкой данных из БД был решен и возник следующий вопрос – как теперь все это писать в excel так, чтобы это было быстро и не затратно по памяти. Первая попытка была самой очевидной – это использование библиотеки org.apache.poi. Тут все просто: подключаем зависимость
Создаем XSSFWorkbook далее XSSFSheet, из него уже row и так далее. Ничего примечательного, примерный код ниже:
Но такой подход оказался не очень оптимальным. Примерно 3 минуты потребовалось на выборку 1 млн строк из бд и запись их в excel. И в итоге приводил к OutOfMemoryError. Вот пример:
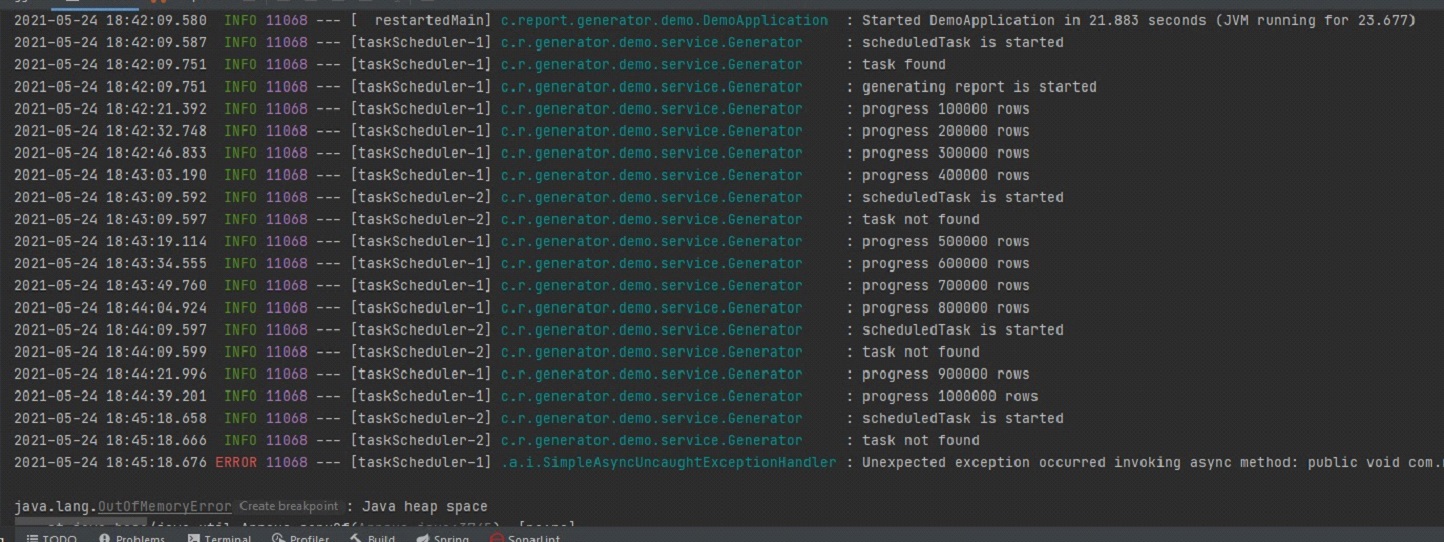
А когда я выполнял его на терминалке с выделенной оперативной памятью в 2Gb, то падал он с OutOfMemoryError примерно на 30% прогресса.
Грузить весь миллион строк в память в excel было так же плохой идеей, как и выгружать весь запрос в List, очевидно, здесь надо было использовать некий stream, но хоть какой-то годный пример google тогда мне не дал. Была попытка написать свое подобие I/O Stream для работы с excel, но мысль о том, что я пишу велосипед не давала мне покоя. В результате я стал изучать библиотеку org.apache.poi пристальней и оказалось, что там уже есть пакет streaming. В этом пакете уже есть весь необходимый набор классов для работы с большим объемом данных в excel. Оставалось только заменить все ключевые классы на аналогичные из пакета streaming и все:
Теперь сравним скорость обработки данных с этой библиотекой:

Вся обработка заняла пол минуты и, самое главное, никаких OutOfMemoryError.
Хотя действия Excel могут обрабатывать большинство сценариев автоматизации Excel, запросы SQL могут более эффективно извлекать значительные объемы данных Excel и работать с ними.
Предположим, поток должен изменить только те реестры Excel, которые содержат определенное значение. Чтобы реализовать эту функциональность без SQL-запросов, вам потребуются циклы, условные выражения и несколько действий Excel.
Напротив, вы можете реализовать эту функциональность с помощью SQL-запросов, используя только два действия: действие Открыть SQL-подключение и действие Выполнять инструкции SQL.
Откройте SQL-подключение к файлу Excel
Перед запуском SQL-запроса вы должны открыть подключение с файлом Excel, к которому вы хотите получить доступ.
Чтобы установить подключение, создайте новую переменную с именем %Excel_File_Path% и инициализируйте его, указав путь к файлу Excel. При желании вы можете пропустить этот шаг и использовать жестко заданный путь к файлу позже в потоке.

Теперь разверните действие Открыть SQL-подключение и заполните следующую строку подключения в его свойствах.
Provider=Microsoft.ACE.OLEDB.12.0;Data Source=%Excel_File_Path%;Extended Properties="Excel 12.0 Xml;HDR=YES";
Для успешного использования представленной строки подключения вам необходимо скачать и установить Распространяемый пакет ядра СУБД Microsoft Access 2010.

Откройте SQL-подключение к файлу Excel, защищенному паролем
Другой подход требуется в сценариях, где вы запускаете SQL-запросы к файлам Excel, защищенным паролем. Действие Открыть SQL-подключение не может подключиться к файлам Excel, защищенным паролем, поэтому вам необходимо снять защиту.
Для этого запустите файл Excel с помощью действие Запустить Excel. Файл защищен паролем, поэтому введите соответствующий пароль в поле Пароль.

Затем разверните соответствующие действия автоматизации пользовательского интерфейса и перейдите к Файл > Информация > Защита книги > Зашифровать паролем. Дополнительные сведения об автоматизации пользовательского интерфейса и о том, как использовать соответствующие действия можно найти в Автоматизировать классические потоки.

После выбора Зашифровать паролем заполните пустую строку во всплывающем диалоговом окне, используя действие Заполнить текстовое поле в окнах. Чтобы заполнить пустую строку, используйте следующее выражение: %""%.

Чтобы нажать на ОК в диалоговом окне и применить изменения, разверните действие Нажать кнопку в окне.
Наконец, разверните действие Закрыть Excel, чтобы сохранить незащищенную книгу как новый файл Excel.

После сохранения файла следуйте инструкциям в Открытие SQL-подключения к файлам Excel, чтобы открыть к нему подключение.
Когда работа с файлом Excel будут завершена, используйте действие Удалить файлы для удалению незащищенной копии файла Excel.

Чтение содержимого электронной таблицы Excel
Хотя действие Считать с листа Excel может считывать содержимое листа Excel, циклы могут занять значительное время для итерации полученных данных.
Более эффективный способ получения определенных значений из электронных таблиц — это рассматривать файлы Excel как базы данных и выполнять на них SQL-запросы. Этот подход быстрее и увеличивает производительность потока.
Чтобы получить все содержимое электронной таблицы, вы можете использовать следующий SQL-запрос в действие Выполнять инструкции SQL.

Чтобы применить этот SQL-запрос в ваших потоках, замените заполнитель SHEET именем электронной таблицы, к которой вы хотите получить доступ.
Чтобы получить строки, содержащие определенное значение в определенном столбце, используйте следующий запрос SQL:
Чтобы применить этот SQL-запрос в ваших потоках, замените:
- SHEET именем электронной таблицы, к которой вы хотите получить доступ
- COLUMN NAME столбцом, содержащим значение, которое вы хотите найти
- VALUE значением, которое вы хотите найти
Удалить данные из строки Excel
Хотя Excel не поддерживает SQL-запрос DELETE, вы можете использовать запрос UPDATE, чтобы установить для всех ячеек определенной строки значение NULL.
Точнее, вы можете использовать следующий SQL-запрос:

При разработке потока вы должны заменить заполнитель SHEET именем электронной таблицы, к которой вы хотите получить доступ.
Заполнители COLUMN1 а также COLUMN2 представляют имена всех существующих столбцов. В этом примере столбцов два, но в реальном сценарии количество столбцов может быть другим.
Часть запроса [COLUMN1]='VALUE' определяет строку, которую вы хотите обновить. В вашем потоке используйте имя столбца и значение в зависимости от того, какая комбинация однозначно описывает строки.
Получить данные Excel, кроме определенной строки
В некоторых сценариях может потребоваться получить все содержимое электронной таблицы Excel, кроме определенной строки.
Удобный способ добиться этого результата — установить для значений нежелательной строки значение NULL, а затем получить все значения, кроме нулевых.
Чтобы изменить значения определенной строки в электронной таблице, вы можете использовать SQL-запрос UPDATE, представленный в Удалить данные из строки Excel:
Затем выполните следующий SQL-запрос, чтобы получить все строки электронной таблицы, не содержащие значений NULL:
Заполнители COLUMN1 а также COLUMN2 представляют имена всех существующих столбцов. В этом примере столбцов два, но в реальной таблице количество столбцов может быть другим.
Читайте также: