
Excel выбрать уникальные значения из столбца
Обновлено: 04.07.2024
Функция УНИК возвращает список уникальных значений в списке или диапазоне.
Возвращение уникальных значений из списка значений
Возвращение уникальных имен из списка имен
Примечание: Эта функция в настоящее время доступна только Microsoft 365 подписчикам.
=УНИКА(массив;[by_col];[exactly_once])
Аргументы функции УНИКА следующую:
Диапазон или массив, из которого возвращаются уникальные строки или столбцы
Аргумент by_col — это логическое значение, указывающее, как это сделать.
Истина сравнивает столбцы друг с другом и возвращает уникальные столбцы.
Ложь (или опущен) сравнивает строки друг с другом и возвращает уникальные строки.
[exactly_once]
Аргумент exactly_once является логическим значением, которое возвращает строки или столбцы, которые встречаются в диапазоне или массиве ровно один раз. Это уникальное понятие базы данных.
Истина возвращает все отдельные строки или столбцы, которые встречаются точно один раз из диапазона или массива.
Ложь (или опущен) возвращает все отдельные строки или столбцы из диапазона или массива.
Массив может быть частью строки или столбца со значениями или сочетанием строк и столбцов со значениями. В примерах выше массивами для наших формул УНИКА являются диапазоны D2:D11 и D2:D17 соответственно.
Функция УНИК возвращает массив, который будет рассеиваться, если это будет конечным результатом формулы. Это означает, что Excel будет динамически создавать соответствующий по размеру диапазон массива при нажатии клавиши ВВОД. Если ваши вспомогательные данные хранятся в таблице Excel, тогда массив будет автоматически изменять размер при добавлении и удалении данных из вашего диапазона массива, если вы используете Структурированные ссылки. Дополнительные сведения см. в статье Поведение рассеянного массива.
Примеры
В этом примере сортировка и УНИКА используются вместе для возврата уникального списка имен в порядке возрастания.
В этом примере exactly_once имеется аргумент ИСТИНА, а функция возвращает только тех клиентов, которым одно время была назначена услуга. Это может быть полезно, если вы хотите определить людей, которые не вернулись для получения дополнительной службы, чтобы связаться с ними.
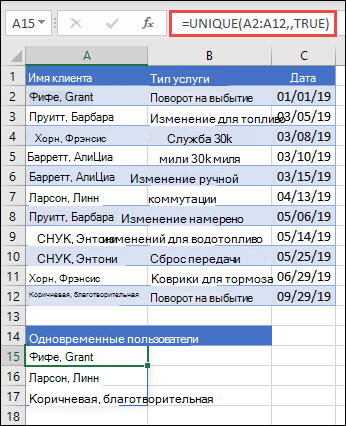
В этом примере с помощью амперанда (&) фамилия и имя совмещеются с полным именем. Обратите внимание, что формула ссылается на весь диапазон имен в диапазонах A2:A12 и B2:B12. Это позволяет Excel массив всех имен.
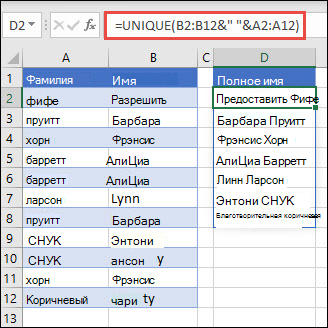
Если отформатеть диапазон имен как таблицу Excel ,формула будет автоматически обновляться при добавлении или удалите имена.
Чтобы отсортировать список имен, можно добавить функцию СОРТ:=СОРТ(УНИКА(B2:B12&" "&A2:A12))
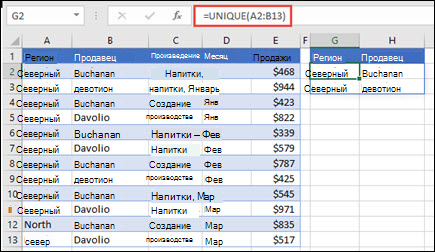
В этом примере сравнивают два столбца и возвращаются только уникальные значения между ними.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Начиная с 2007-й версии функция удаления дубликатов является стандартной - найти ее можно на вкладке Данные - Удаление дубликатов (Data - Remove Duplicates) :

В открывшемся окне нужно с помощью флажков задать те столбцы, по которым необходимо обеспечивать уникальность. Т.е. если включить все флажки, то будут удалены только полностью совпадающие строки. Если включить только флажок заказчик, то останется только по одной строке для каждого заказчика и т.д.
Способ 2. Расширенный фильтр
Если у вас Excel 2003 или старше, то для удаления дубликатов и вытаскивания из списка уникальных (неповторяющихся) элементов можно использовать Расширенный фильтр (Advanced Filter) из меню (вкладки) Данные (Data) .
Предположим, что у нас имеется вот такой список беспорядочно повторяющихся названий компаний:
Выбираем в меню Данные - Фильтр - Расширенный фильтр (Data - Filter - Advanced Filter) . Получаем окно:
- Выделяем наш список компаний в Исходный диапазон (List Range) .
- Ставим переключатель в положение Скопировать результат в другое место (Copy to another location) и указываем пустую ячейку.
- Включаем (самое главное!) флажок Только уникальные записи(Uniqe records only) и жмем ОК.
Получите список без дубликатов:
Если требуется искать дубликаты не по одному, а по нескольким столбцам, то можно предварительно склеить их в один, сделав, своего рода, составной ключ с помощью функции СЦЕПИТЬ (CONCATENATE) :

Тогда дальнейшая задача будет сводиться к поиску дубликатов уже в одном столбце.
Способ 3. Выборка уникальных записей формулой
Чуть более сложный способ, чем первые два, но зато - динамический, т.е. с автоматическим пересчетом, т.е. если список редактируется или в него дописываются еще элементы, то они автоматически проверяются на уникальность и отбираются. В предыдущих способах при изменении исходного списка нужно будет заново запускать Расширенный фильтр или жать на кнопку Удаление дубликатов.
Итак, снова имеем список беспорядочно повторяющихся элементов. Например, такой:
Первая задача - пронумеровать всех уникальных представителей списка, дав каждому свой номер (столбец А на рисунке). Для этого вставляем в ячейку А2 и копируем затем вниз до упора следующую формулу:
В английской версии это будет:
Эта формула проверяет сколько раз текущее наименование уже встречалось в списке (считая с начала), и если это количество =1, т.е. элемент встретился первый раз - дает ему последовательно возрастающий номер.
Для упрощения адресации дадим нашим диапазонам (например, исходя из того, что в списке может быть до 100 элементов) имена. Это можно сделать в новых версиях Excel на вкладке Формулы - Диспетчер имен (Formulas - Name manager) или в старых версиях - через меню Вставка - Имя - Присвоить (Insert - Name - Define) :
- диапазону номеров (A1:A100) - имя NameCount
- всему списку с номерами (A1:B100) - имя NameList
Теперь осталось выбрать из списка NameList все элементы имеющие номер - это и будут наши уникальные представители. Сделать это можно в любой пустой ячейке соседних столбцов, введя туда вот такую формулу с известной функцией ВПР (VLOOKUP) и скопировав ее вниз на весь столбец:
=ЕСЛИ(МАКС(NameCount)<СТРОКА(1:1);"";ВПР(СТРОКА(1:1);NameList;2))
или в английской версии Excel:
=IF(MAX(NameCount)
Эта формула проходит сверху вниз по столбцу NameCount и выводит все позиции списка с номерами в отдельную таблицу:
Начиная с 2007-й версии функция удаления дубликатов является стандартной - найти ее можно на вкладке Данные - Удаление дубликатов (Data - Remove Duplicates) :
В открывшемся окне нужно с помощью флажков задать те столбцы, по которым необходимо обеспечивать уникальность. Т.е. если включить все флажки, то будут удалены только полностью совпадающие строки. Если включить только флажок заказчик, то останется только по одной строке для каждого заказчика и т.д.
Способ 2. Расширенный фильтр
Если у вас Excel 2003 или старше, то для удаления дубликатов и вытаскивания из списка уникальных (неповторяющихся) элементов можно использовать Расширенный фильтр (Advanced Filter) из меню (вкладки) Данные (Data) .
Предположим, что у нас имеется вот такой список беспорядочно повторяющихся названий компаний:
Выбираем в меню Данные - Фильтр - Расширенный фильтр (Data - Filter - Advanced Filter) . Получаем окно:
- Выделяем наш список компаний в Исходный диапазон (List Range) .
- Ставим переключатель в положение Скопировать результат в другое место (Copy to another location) и указываем пустую ячейку.
- Включаем (самое главное!) флажок Только уникальные записи(Uniqe records only) и жмем ОК.
Получите список без дубликатов:
Если требуется искать дубликаты не по одному, а по нескольким столбцам, то можно предварительно склеить их в один, сделав, своего рода, составной ключ с помощью функции СЦЕПИТЬ (CONCATENATE) :
Тогда дальнейшая задача будет сводиться к поиску дубликатов уже в одном столбце.
Способ 3. Выборка уникальных записей формулой
Чуть более сложный способ, чем первые два, но зато - динамический, т.е. с автоматическим пересчетом, т.е. если список редактируется или в него дописываются еще элементы, то они автоматически проверяются на уникальность и отбираются. В предыдущих способах при изменении исходного списка нужно будет заново запускать Расширенный фильтр или жать на кнопку Удаление дубликатов.
Итак, снова имеем список беспорядочно повторяющихся элементов. Например, такой:
Первая задача - пронумеровать всех уникальных представителей списка, дав каждому свой номер (столбец А на рисунке). Для этого вставляем в ячейку А2 и копируем затем вниз до упора следующую формулу:
В английской версии это будет:
Эта формула проверяет сколько раз текущее наименование уже встречалось в списке (считая с начала), и если это количество =1, т.е. элемент встретился первый раз - дает ему последовательно возрастающий номер.
Для упрощения адресации дадим нашим диапазонам (например, исходя из того, что в списке может быть до 100 элементов) имена. Это можно сделать в новых версиях Excel на вкладке Формулы - Диспетчер имен (Formulas - Name manager) или в старых версиях - через меню Вставка - Имя - Присвоить (Insert - Name - Define) :
- диапазону номеров (A1:A100) - имя NameCount
- всему списку с номерами (A1:B100) - имя NameList
Теперь осталось выбрать из списка NameList все элементы имеющие номер - это и будут наши уникальные представители. Сделать это можно в любой пустой ячейке соседних столбцов, введя туда вот такую формулу с известной функцией ВПР (VLOOKUP) и скопировав ее вниз на весь столбец:
=ЕСЛИ(МАКС(NameCount)<СТРОКА(1:1);"";ВПР(СТРОКА(1:1);NameList;2))
или в английской версии Excel:
=IF(MAX(NameCount)
Эта формула проходит сверху вниз по столбцу NameCount и выводит все позиции списка с номерами в отдельную таблицу:

В Excel есть несколько способов отфильтровать уникальные значения или удалить повторяющиеся значения:
Чтобы выделить уникальные или повторяющиеся значения, используйте команду Условное форматирование в группе Стиль на вкладке Главная.
Узнайте, как фильтровать уникальные значения или удалять повторяющиеся значения.Фильтрация уникальных значений и удаление повторяюющихся значений — две похожие задачи, так как их цель — представить список уникальных значений. Однако существует критическое различие: при фильтрации уникальных значений повторяющиеся значения скрываются только временно. Однако удаление повторяюющихся значений означает, что повторяющиеся значения удаляются окончательно.
Повторяютая строка — это значение, в котором все значения хотя бы в одной строке совпадают со всеми значениями в другой строке. Сравнение повторяюющихся значений зависит от того, что отображается в ячейке, а не от значения, хранимого в ячейке. Например, если в разных ячейках есть одно и то же значение даты в формате "08.03.2006", а в другом — "8 марта 2006 г.", значения будут уникальными.
Прежде чем удалять дубликаты, проверьте: Прежде чем удалять повторяющиеся значения, сначала попробуйте отфильтровать уникальные значения (или отформатировать их с условием), чтобы достичь нужного результата.
Вы выберите диапазон ячеек или убедитесь, что активная ячейка находится в таблице.
Щелкните > дополнительные данные (в группе Фильтр & сортировки).
Во всплывающее окно Расширенный фильтр сделайте следующее:
Чтобы отфильтровать диапазон ячеек или таблицу на месте:
Щелкните Фильтровать список на месте.
Чтобы скопировать результаты фильтра в другое место:
В поле Копировать в введите ссылку на ячейку.
Вы также можете нажать кнопку Свернуть , чтобы временно скрыть всплывающее окно, выбрать ячейку на этом сайте и нажать кнопку Развернуть .
Проверьте только уникальные записии нажмите кнопку ОК.
Уникальные значения из диапазона копируются в новое место.
При удалите повторяющиеся значения, только на значения в диапазоне ячеек или таблице. Другие значения за пределами диапазона ячеек или таблицы не изменяются и не перемещаются. При удалении дубликатов первое вхождение значения в списке будет сохранено, а другие одинаковые значения будут удалены.
Так как данные удаляются окончательно, перед удалением повторяюющихся значений лучше скопировать исходный диапазон ячеек или таблицу на другой.
Вы выберите диапазон ячеек или убедитесь, что активная ячейка находится в таблице.
На вкладке Данные нажмите кнопку Удалить дубликаты (в группе Инструменты для работы с данными).
Выполните одно или несколько из указанных ниже действий.
В области Столбцывыберите один или несколько столбцов.
Чтобы быстро выбрать все столбцы, нажмите кнопку Выбрать все.
Чтобы быстро очистить все столбцы, нажмите кнопку Отклоните все.
Если диапазон ячеек или таблицы содержит много столбцов и нужно выбрать только несколько столбцов, вам может быть проще нажать кнопку Отобрать все,а затем в столбцах выберите эти столбцы.
Примечание: Данные будут удалены из всех столбцов, даже если на этом этапе не выбраны все столбцы. Например, если выбрать Столбец1 и Столбец2, но не Столбец3, то ключом, используемым для поиска дубликатов, будет значение BOTH Column1 & Column2. Если в этих столбцах найдено повторяющиеся записи, удаляется вся строка, включая другие столбцы в таблице или диапазоне.
Чтобы отменить изменение, нажмите кнопку Отменить (или нажмите клавиши CTRL+Z на клавиатуре).
Проблемы с удалением дубликатов из структурных или вычитающихся данныхПовторяющиеся значения невозможно удалить из структурных данных или с суммами. Чтобы удалить дубликаты, необходимо удалить структуру и подытогов. Дополнительные сведения см. в таблицах Структурная схема данных на листе и Удаление подытогов.
Условное форматирование уникальных или повторяюных значенийПримечание: Нельзя условно отформатировать поля в области значений отчета отчетов данных по уникальным или повторяемым значениям.
Быстрое форматирование
Выделите одну или несколько ячеек в диапазоне, таблице или отчете сводной таблицы.

На вкладке Главная в группе Стиль щелкните маленькую стрелку для условного форматирования ,а затем выберите правила выделения ячеек ищелкните Повторяющиеся значения.
Введите нужные значения и выберите формат.
Расширенное форматирование
Выделите одну или несколько ячеек в диапазоне, таблице или отчете сводной таблицы.
На вкладке Главная в группе Стили щелкните стрелку для команды Условное форматирование ивыберите управление правилами, чтобы отобразить всплывающее окно Диспетчер правил условного форматирования.
Выполните одно из следующих действий:
Чтобы добавить условное форматирование, нажмите кнопку Новое правило, чтобы отобразить всплывающее окно Новое правило форматирования.
Чтобы изменить условное форматирование, начните с того, что в списке Показать правила форматирования для выбран соответствующий лист или таблица. При необходимости выберите другой диапазон ячеек, нажав кнопку Свернуть во всплывающее окно Применяется к временно скрыть его. Выберите новый диапазон ячеек на этом сайте, а затем снова разширив всплывающее окно, . Выберите правило и нажмите кнопку Изменить правило, чтобы отобразить всплывающее окно Изменение правила форматирования.
В группе Выберите тип правила выберите параметр Форматировать только уникальные или повторяющиеся значения.
В списке Форматировать все выберите изменить описание правила, выберите уникальный или дубликат.
Выберите формат числа, шрифта, границы или заливки, который вы хотите применить, когда значение ячейки удовлетворяет условию, а затем нажмите кнопку ОК. Можно выбрать несколько форматов. Выбранные форматы отображаются на панели предварительного просмотра.
В Excel в Интернете можно удалить повторяющиеся значения.
Удаление повторяющихся значений
При удалите повторяющиеся значения, только на значения в диапазоне ячеек или таблице. Другие значения за пределами диапазона ячеек или таблицы не изменяются и не перемещаются. При удалении дубликатов первое вхождение значения в списке будет сохранено, а другие одинаковые значения будут удалены.
Важно: Вы всегда можете нажать кнопку Отменить, чтобы вернуть данные после удаления дубликатов. При этом перед удалением повторяюющихся значений лучше скопировать исходный диапазон ячеек или таблицу на другой рабочий или другой.
Вы выберите диапазон ячеек или убедитесь, что активная ячейка находится в таблице.
На вкладке Данные нажмите кнопку Удалить дубликаты.
В диалоговом окне Удаление дубликатов снимите с нее все столбцы, в которых не нужно удалять повторяющиеся значения.
Примечание: Данные будут удалены из всех столбцов, даже если на этом этапе не выбраны все столбцы. Например, если выбрать Столбец1 и Столбец2, но не Столбец3, то ключом, используемым для поиска дубликатов, будет значение BOTH Column1 & Column2. Если в столбцах "Столбец1" и "Столбец2" найдено повторяющиеся данные, удаляется вся строка, включая данные из столбца "Столбец3".
Примечание: Если вы хотите вернуть данные, просто нажмите кнопку Отменить (или нажмите клавиши CTRL+Z на клавиатуре).
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Читайте также: