
Функция уник в excel с какой версии
Обновлено: 03.07.2024
Функция УНИК возвращает список уникальных значений в списке или диапазоне.
Возвращение уникальных значений из списка значений
Возвращение уникальных имен из списка имен
Примечание: Эта функция в настоящее время доступна только Microsoft 365 подписчикам.
=УНИКА(массив;[by_col];[exactly_once])
Аргументы функции УНИКА следующую:
Диапазон или массив, из которого возвращаются уникальные строки или столбцы
Аргумент by_col — это логическое значение, указывающее, как это сделать.
Истина сравнивает столбцы друг с другом и возвращает уникальные столбцы.
Ложь (или опущен) сравнивает строки друг с другом и возвращает уникальные строки.
[exactly_once]
Аргумент exactly_once является логическим значением, которое возвращает строки или столбцы, которые встречаются в диапазоне или массиве ровно один раз. Это уникальное понятие базы данных.
Истина возвращает все отдельные строки или столбцы, которые встречаются точно один раз из диапазона или массива.
Ложь (или опущен) возвращает все отдельные строки или столбцы из диапазона или массива.
Массив может быть частью строки или столбца со значениями или сочетанием строк и столбцов со значениями. В примерах выше массивами для наших формул УНИКА являются диапазоны D2:D11 и D2:D17 соответственно.
Функция УНИК возвращает массив, который будет рассеиваться, если это будет конечным результатом формулы. Это означает, что Excel будет динамически создавать соответствующий по размеру диапазон массива при нажатии клавиши ВВОД. Если ваши вспомогательные данные хранятся в таблице Excel, тогда массив будет автоматически изменять размер при добавлении и удалении данных из вашего диапазона массива, если вы используете Структурированные ссылки. Дополнительные сведения см. в статье Поведение рассеянного массива.
Примеры
В этом примере сортировка и УНИКА используются вместе для возврата уникального списка имен в порядке возрастания.
В этом примере exactly_once имеется аргумент ИСТИНА, а функция возвращает только тех клиентов, которым одно время была назначена услуга. Это может быть полезно, если вы хотите определить людей, которые не вернулись для получения дополнительной службы, чтобы связаться с ними.
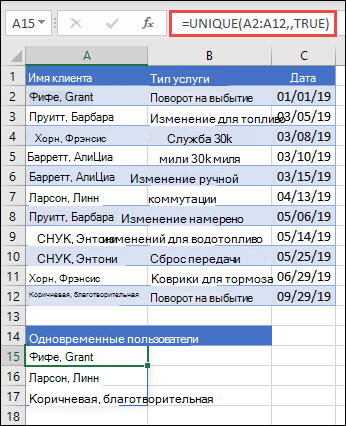
В этом примере с помощью амперанда (&) фамилия и имя совмещеются с полным именем. Обратите внимание, что формула ссылается на весь диапазон имен в диапазонах A2:A12 и B2:B12. Это позволяет Excel массив всех имен.
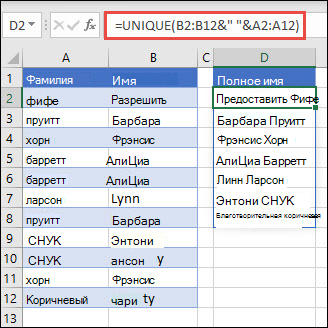
Если отформатеть диапазон имен как таблицу Excel ,формула будет автоматически обновляться при добавлении или удалите имена.
Чтобы отсортировать список имен, можно добавить функцию СОРТ:=СОРТ(УНИКА(B2:B12&" "&A2:A12))
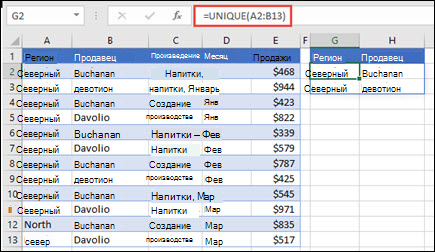
В этом примере сравнивают два столбца и возвращаются только уникальные значения между ними.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
В рамках значительного обновления языка формул Excel в целях обеспечения поддержки динамических массивов был добавлен оператор неявного пересечения. Динамические массивы обеспечивают новые существенные вычислительные операции и функциональные возможности для Excel.
Обновленный язык формул
Обновленный язык формул Excel практически идентичен старому, за исключением того, что в нем используется оператор @, который указывает, в каких случаях может происходить неявное пересечение, тогда как в старом языке это никак не отображалось. В результате вы можете заметить, что символ @ появляется в некоторых формулах при открытии в Excel с динамическим массивом. Обратите внимание, что ваши формулы будут вычисляться так же, как и раньше.
Что такое неявное пересечение?
Логика неявного пересечения сводит множество значений к одному. Это было реализовано в Excel для того, чтобы формула возвращала одно значения, т.к. ячейка может содержать одно значение. Если ваша формула возвращала одно значение, значит неявное пересечение ничего не делало (хотя технически это происходило в фоновом режиме). Этот процесс описан ниже.
Если значением является один элемент, возвращается этот элемент.
Если значением является диапазон, возвращается значение из ячейки, находящейся в той же строке или столбце, что и формула.
Если значением является массив, выберите значение слева вверху.
С появлением динамических массивов Excel больше не ограничивается возвратом отдельных значений из формул, поэтому скрытое неявное пересечение больше не требуется. Если раньше формула могла незаметно выполнять неявное пересечение, то теперь динамические массивы позволяют Excel показывать неявное пересечение при помощи символа @ в соответствующем месте.
Почему выбран именно символ @?
Символ @ уже используется в ссылках на таблицы для обозначения неявного пересечения. Рассмотрим следующую формулу в таблице =[@Column1]. Здесь символ @ указывает, что в формуле должно применяться неявное пересечение для получения значения в той же строке из [Столбец1].
Можно ли удалить @?
Зачастую это возможно. Это зависит от того, что именно возвращает часть формулы справа от символа @:
Если она возвращает одно значение (наиболее распространенный случай), от удаления @ ничего не изменится.
Если она возвращает диапазон или массив, удаление символа @приведет к переносуего в соседние ячейки.
Если удалить автоматически добавленный символ @, после чего открыть книгу в более старой версии Excel, формула будет отображаться как устаревшая формула массива (заключенная в фигурные скобки <>); это делается для того, чтобы в старой версии не выполнилось неявное пересечение.
Когда @ добавляется в старые формулы?
Как правило, функции, которые возвращают диапазоны или массивы с несколькими ячейками, будут иметь префикс @, если они были созданы в более старой версии Excel. Важно отметить, что поведение формулы при этом не меняется — просто теперь вы можете увидеть ранее невидимое неявное пересечение. К распространенным функциям, которые могут возвращать диапазоны с несколькими ячейками, относятся функции ИНДЕКС, СМЕЩЕНИЕ и пользовательские функции (UDF). Распространенным исключением является случай, когда они заключены в функцию, которая принимает массив или диапазон (например, SUM() или AVERAGE()).
Примеры
Как видно в динамическом массиве Excel
Никаких изменений — неявное пересечение произойти не могло, поскольку функция SUM ожидает диапазоны или массивы.
Никаких изменений — неявное пересечение произойти не могло.
Произойдет неявное пересечение, и Excel вернет значение, связанное со строкой, в которой находится формула.
Неявное пересечение возможно. Функция ИНДЕКС может возвращать массив или диапазон, если ее второй или третий аргумент равен 0.
Неявное пересечение возможно. Функция OFFSET может возвращать диапазон с несколькими ячейками. В этом случае может иметь место неявное пересечение.
Неявное пересечение возможно. Пользовательские функции могут возвращать массивы. В этом случае исходная формула вызвала бы неявное пересечение.
Использование оператора @ в новых формулах
При создании или редактировании в Excel с функцией динамических массивов формулы с оператором @ она может отображаться как _xlfn. SINGLE() в версии Excel без динамических массивов.
Это происходит при выполнении смешанной формулы. Смешанная формула — это формула, которая основывается как на вычислении массива, так и на неявном пересечении. Такой возможности не было до появлении Excel с динамическими массивами. В версиях без динамических массивов поддерживались только формулы, в которых выполнялось неявное пересечение i) или вычисление массива ii).
Когда Excel с функцией динамических массивов обнаруживает создание "смешанной формулы", будет предложен вариант формулы с неявным пересечением. Например, если ввести =A1:A10+@A1:A10, отобразится следующее диалоговое окно:
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Начиная с 2007-й версии функция удаления дубликатов является стандартной - найти ее можно на вкладке Данные - Удаление дубликатов (Data - Remove Duplicates) :

В открывшемся окне нужно с помощью флажков задать те столбцы, по которым необходимо обеспечивать уникальность. Т.е. если включить все флажки, то будут удалены только полностью совпадающие строки. Если включить только флажок заказчик, то останется только по одной строке для каждого заказчика и т.д.
Способ 2. Расширенный фильтр
Если у вас Excel 2003 или старше, то для удаления дубликатов и вытаскивания из списка уникальных (неповторяющихся) элементов можно использовать Расширенный фильтр (Advanced Filter) из меню (вкладки) Данные (Data) .
Предположим, что у нас имеется вот такой список беспорядочно повторяющихся названий компаний:
Выбираем в меню Данные - Фильтр - Расширенный фильтр (Data - Filter - Advanced Filter) . Получаем окно:
- Выделяем наш список компаний в Исходный диапазон (List Range) .
- Ставим переключатель в положение Скопировать результат в другое место (Copy to another location) и указываем пустую ячейку.
- Включаем (самое главное!) флажок Только уникальные записи(Uniqe records only) и жмем ОК.
Получите список без дубликатов:
Если требуется искать дубликаты не по одному, а по нескольким столбцам, то можно предварительно склеить их в один, сделав, своего рода, составной ключ с помощью функции СЦЕПИТЬ (CONCATENATE) :

Тогда дальнейшая задача будет сводиться к поиску дубликатов уже в одном столбце.
Способ 3. Выборка уникальных записей формулой
Чуть более сложный способ, чем первые два, но зато - динамический, т.е. с автоматическим пересчетом, т.е. если список редактируется или в него дописываются еще элементы, то они автоматически проверяются на уникальность и отбираются. В предыдущих способах при изменении исходного списка нужно будет заново запускать Расширенный фильтр или жать на кнопку Удаление дубликатов.
Итак, снова имеем список беспорядочно повторяющихся элементов. Например, такой:
Первая задача - пронумеровать всех уникальных представителей списка, дав каждому свой номер (столбец А на рисунке). Для этого вставляем в ячейку А2 и копируем затем вниз до упора следующую формулу:
В английской версии это будет:
Эта формула проверяет сколько раз текущее наименование уже встречалось в списке (считая с начала), и если это количество =1, т.е. элемент встретился первый раз - дает ему последовательно возрастающий номер.
Для упрощения адресации дадим нашим диапазонам (например, исходя из того, что в списке может быть до 100 элементов) имена. Это можно сделать в новых версиях Excel на вкладке Формулы - Диспетчер имен (Formulas - Name manager) или в старых версиях - через меню Вставка - Имя - Присвоить (Insert - Name - Define) :
- диапазону номеров (A1:A100) - имя NameCount
- всему списку с номерами (A1:B100) - имя NameList
Теперь осталось выбрать из списка NameList все элементы имеющие номер - это и будут наши уникальные представители. Сделать это можно в любой пустой ячейке соседних столбцов, введя туда вот такую формулу с известной функцией ВПР (VLOOKUP) и скопировав ее вниз на весь столбец:
=ЕСЛИ(МАКС(NameCount)<СТРОКА(1:1);"";ВПР(СТРОКА(1:1);NameList;2))
или в английской версии Excel:
=IF(MAX(NameCount)
Эта формула проходит сверху вниз по столбцу NameCount и выводит все позиции списка с номерами в отдельную таблицу:
Начиная с 2007-й версии функция удаления дубликатов является стандартной - найти ее можно на вкладке Данные - Удаление дубликатов (Data - Remove Duplicates) :
В открывшемся окне нужно с помощью флажков задать те столбцы, по которым необходимо обеспечивать уникальность. Т.е. если включить все флажки, то будут удалены только полностью совпадающие строки. Если включить только флажок заказчик, то останется только по одной строке для каждого заказчика и т.д.
Способ 2. Расширенный фильтр
Если у вас Excel 2003 или старше, то для удаления дубликатов и вытаскивания из списка уникальных (неповторяющихся) элементов можно использовать Расширенный фильтр (Advanced Filter) из меню (вкладки) Данные (Data) .
Предположим, что у нас имеется вот такой список беспорядочно повторяющихся названий компаний:
Выбираем в меню Данные - Фильтр - Расширенный фильтр (Data - Filter - Advanced Filter) . Получаем окно:
- Выделяем наш список компаний в Исходный диапазон (List Range) .
- Ставим переключатель в положение Скопировать результат в другое место (Copy to another location) и указываем пустую ячейку.
- Включаем (самое главное!) флажок Только уникальные записи(Uniqe records only) и жмем ОК.
Получите список без дубликатов:
Если требуется искать дубликаты не по одному, а по нескольким столбцам, то можно предварительно склеить их в один, сделав, своего рода, составной ключ с помощью функции СЦЕПИТЬ (CONCATENATE) :
Тогда дальнейшая задача будет сводиться к поиску дубликатов уже в одном столбце.
Способ 3. Выборка уникальных записей формулой
Чуть более сложный способ, чем первые два, но зато - динамический, т.е. с автоматическим пересчетом, т.е. если список редактируется или в него дописываются еще элементы, то они автоматически проверяются на уникальность и отбираются. В предыдущих способах при изменении исходного списка нужно будет заново запускать Расширенный фильтр или жать на кнопку Удаление дубликатов.
Итак, снова имеем список беспорядочно повторяющихся элементов. Например, такой:
Первая задача - пронумеровать всех уникальных представителей списка, дав каждому свой номер (столбец А на рисунке). Для этого вставляем в ячейку А2 и копируем затем вниз до упора следующую формулу:
В английской версии это будет:
Эта формула проверяет сколько раз текущее наименование уже встречалось в списке (считая с начала), и если это количество =1, т.е. элемент встретился первый раз - дает ему последовательно возрастающий номер.
Для упрощения адресации дадим нашим диапазонам (например, исходя из того, что в списке может быть до 100 элементов) имена. Это можно сделать в новых версиях Excel на вкладке Формулы - Диспетчер имен (Formulas - Name manager) или в старых версиях - через меню Вставка - Имя - Присвоить (Insert - Name - Define) :
- диапазону номеров (A1:A100) - имя NameCount
- всему списку с номерами (A1:B100) - имя NameList
Теперь осталось выбрать из списка NameList все элементы имеющие номер - это и будут наши уникальные представители. Сделать это можно в любой пустой ячейке соседних столбцов, введя туда вот такую формулу с известной функцией ВПР (VLOOKUP) и скопировав ее вниз на весь столбец:
=ЕСЛИ(МАКС(NameCount)<СТРОКА(1:1);"";ВПР(СТРОКА(1:1);NameList;2))
или в английской версии Excel:
=IF(MAX(NameCount)
Эта формула проходит сверху вниз по столбцу NameCount и выводит все позиции списка с номерами в отдельную таблицу:
Читайте также: