
Как посчитать gini в excel
Обновлено: 04.07.2024
В прошлой статье я описал использование когортного анализа для выяснения причин динамики клиентской базы. Сегодня пришло время поговорить про трюки подготовки данных для когортного анализа.
Легко рисовать картинки, но для того, чтобы они считались и отображались правильно “под капотом” нужно проделать немало работы. В этой статье мы поговорим о том, как реализовать когортный анализ. Я расскажу про реализацию при помощи Excel, а в другой статье при помощи R.
Хотим мы этого или нет, но по факту Excel это инструмент анализа данных. Более “высокомерные” аналитики будут считать, что это слабый и не удобный инструмент. С другой стороны по факту сотни тысяч людей делают анализ данных в Excel и в этом отношении он легко побьет R / python. Конечно, когда мы говорим о advances analytics и машинном обучении, мы будем работать на R / python. И я был бы за то, чтобы большая часть аналитики делалась именно этими инструментами. Но стоит признать факты, в Excel обрабатывают и представляют данные подавляющее большинство компаний и именно этим инструментом пользуются обычные аналитики, менеджеры и product owners. Вдобавок Excel трудно победить в части простоты и наглядности процесса, т.к. вы мастерите свои расчеты и модельки буквально руками.
И так, как же нам сделать когортный анализ в Excel? Для того, чтобы решать подобные задачи нужно определить 2 вещи:
Какие данные у нас в начале процесса
Как должны выглядеть наши данные в конце процесса.
Чтобы собрать когортный анализ нам не будет достаточно только оборотный данных по датам и подразделениям. Нам нужны данные на уровне отдельных клиентов. В начале процесса нам понадобится:
Дата регистрации клиента
Объем продаж этого клиента в эту календарную дату
Первая сложность, которую предстоит преодолеть — это получить эти данные. Если у вас правильное хранилище, то они уже должны быть у вас. С другой стороны, если пока реализовали только запись данных о совокупных продажах по дням, то данные по клиентам у вас есть только на “проде”. Для когортного анализа вам придется реализовать ETL и сложить в ваше хранилище данные в разрезе клиентов, иначе у вас ничего не выйдет. И лучше всего если вы разделите “прод” и аналитику в разные базы, т.к. У аналитических задач и задач функционирования вашего продукта разные цели конкуренция за ресурсы. Аналитикам нужны быстрые агрегаты и расчеты на по многим пользователям, продукту нужно быстро обслужить конкретного пользователя. Об организации хранилища я напишу отдельную статью.
Итак, вы имеете стартовые данные:

Первое, что нам нужно сделать это преобразовать их в “лесенки”. Для этого нужно над этой таблицей построить сводную таблицу, по строкам — дата регистрации, по столбцам — календарная дата, в качестве значений — кол-во id клиентов. Если вы верно извлекли данные, то у вас должен получится вот такой треугольник/лесенка:

В целом лесенка это наш когортный график, в котором каждая строка отображает динамику отдельной когорты. Клиенты во времени в этой отображении двигаются только внутри одной строки. Таким образом динамика когорты отображает развитие отношений с группой клиентов пришедший в один период времени. Часто для удобства и без потери качества, можно объединить когорты в “блоки” строк. Например, вы можете сгруппировать их по неделям и месяцам. Точно так же вы можете сгруппировать и колонку, т.к. Возможно ваш темп развития продукта не требует детализации до дней.
На основе этой лесенки вы можете влоб построить график из моей статьи (я правда указывал, что сгруппировал несколько строк в одну, чтобы когорт было поменьше):

Это график с накопительными областями, где каждый ряд — это строка, по горизонтали даты.
Чуть сложнее логика для реализации графика “потоков”. Для потоков мы должны сделать некоторые дополнительные вычисления. В логике потоков каждый клиент прибывает в различных состояниях:
- Новый — любой клиент, у кого разница между датой регистрации и календарной дате <7 дней
- Реактивированный — любой клиент, кто уже не новый, но в прошлом календарном месяце не генерировал выручку
- Действующий — любой клиент, кто не новый, но в в календарном месяце генерировал выручку
- Ушедший — любой клиент, кто не генерирует выручку 2 месяца подряд
Во-первых вам стоит в компании закрепить эти определения, чтобы вы могли корректно реализовать эту логику и автоматически рассчитывать состояния. Эти 4 определения имеют далеко идущие последствия в целом и для маркетинга. Ваши стратегии по привлечению, удержанию и возвращению будут базироваться на том, в каком состоянии вы считаете находится клиент. А если вы начнете внедрять модели машинного обучения в прогнозировании ухода клиентов, то определения станут вашим краеугольным камнем успешности этих моделей. Вообще про организацию работы и важность аналитической методологии я напишу отдельную статью. Выше я привел просто пример того, какими могут быть эти определения.
В Excel вам нужно создать дополнительную колонку, куда вписать описанную выше логику. В нашей случае нам придется “попотеть”. У нас есть 2 типа критериев:
- Разница между датой регистрацией и календарной датой — эти данные есть у каждой строки и тут просто нужно ее посчитать (вычитание дат в Excel просто дает разницу в днях)
- Данные о выручке в текущем и прошлом месяце. Эти данные нам не доступны в строке. Более того, с учетом того, что в нашей таблице не гарантирован порядок, то вы не можете точно сказать, где у вас данные по другим дням месяца для этого клиента.
Решить проблему 2 типа критериев можно 2 способами:
- Попросите сделать это в базе данных. SQL позволяет при помощи аналитической функции вычислить для каждого клиента сумму выручки за текущий и прошлый месяц (для текущего месяца SUM(revenue) OVER (PARTITION BY client_id, calendar_month, а потом LAG, чтобы получить смещение по прошлому месяцу):
- В экселе вам придется реализовать это так:
- Для текущего месяца: СУММЕСЛИ(), критериями будет id клиента и месяц ячейки календарного дня
- Для прошлого месяца: СУММЕСЛИ(), критериями будет id клиента и месяц ячейки календарного дня минус ровно 1 календарный месяц. При этом обращу внимание, что вы должны вычесть именно календарный месяц, а не 30 дней. Иначе вы рискуете получить смазанную картину из-за неодинакового числа дней в месяцах. Также используйте функцию ЕСЛИОШИБКА, чтобы заменить ошибочные значения для клиентов у кого не было прошлого месяца.
Добавив колонки выручки текущего месяца, прошлого месяца вы можете построить вложенное условие ЕСЛИ, учитывающие все факторы (разницу дат и суммы выручки в текущем/прошлом месяце):
ЕСЛИ( разница дат <7; “новый”;
ЕСЛИ( И (выручка прошлого месяца = 0; выручка текущего месяца > 0); “реактивация”;
ЕСЛИ( И (выручка прошлого месяца > 0; выручка текущего месяца > 0); “действующий”
ЕСЛИ( И (выручка прошлого месяца = 0; выручка текущего месяца = 0); “ушедший”; “ошибка”))))
У вас должно получится вот так:

Теперь эту таблицу можно пересобрать при помощи сводной таблицы в таблицу для построения графика. Вам нужно трансформировать ее в таблицу:
Календарная дата (колонки)
Состояние (строки)
Кол-во id клиентов (значения в ячейках)
Далее мы просто должны на основе данных построить диаграмму столбчатую диаграмма с накоплениями, по оси Х календарная дата, ряды это состояния, кол-во клиентов это высота столбцов. Вы можете поменять порядок состояний на графике, изменив порядок рядов в меню “выбрать данные”. В итоге мы получим такую картину:

Термин «коэффициент Джини» нации относится к измерению распределения доходов по населению нации. Другими словами, его можно рассматривать как меру неравенства распределения доходов в обществе, и его значение лежит в диапазоне от 0 до 1, где значение 1 указывает на более высокую степень неравенства в доходах. Формула для коэффициента Джини включает вычисление совокупного балла, который представляет собой сложную функцию вклада дохода (доли дохода) для другой части населения (доли населения). Затем коэффициент Джини рассчитывается путем вычитания совокупного балла из 1. Математически формула коэффициента Джини представляется как
Gini Coefficient = 1 – Aggregate Score
Примеры формулы коэффициента Джини (с шаблоном Excel)
Давайте рассмотрим пример, чтобы лучше понять расчет коэффициента Джини.
Вы можете скачать этот шаблон формулы формулы коэффициента Джини здесь - Шаблон коэффициента формулы Джини Excel
Коэффициент Джини - формула № 1
Давайте возьмем простой пример из 20 человек, чтобы понять концепцию коэффициента Джини. Согласно предоставленной информации, первые 5 человек получали 50 долларов в месяц на человека, следующие 10 человек получали 100 долларов в месяц на человека, а последние 5 человек получали 300 долларов в месяц на человека. Рассчитайте коэффициент Джини для населения.
Решение:
Общий доход рассчитывается как

- Общий доход = (5 * $ 50) + (10 * $ 100) + (5 * $ 300)
- Общий доход = 2750 долларов
Доля дохода рассчитывается как

Первые 5 человек
- Доля дохода = (5 * 50 долларов США) / 2750 долларов США
- Доля дохода = 0, 09
Следующие 10 человек
- Доля дохода = (10 * 100 долларов США) / 2750 долларов США
- Доля дохода = 0, 36
Последние 5 человек
- Доля дохода = (5 * 300 долл. США) / 2750 долл. США
- Доля дохода = 0, 55
Доля населения рассчитывается как

Первые 5 человек
- Доля населения = 5/20
- Доля населения = 0, 25
Следующие 10 человек
- Доля населения = 10/20
- Доля населения = 0, 50
Последние 5 человек
- Доля населения = 5/20
- Доля населения = 0, 25
Доля более богатого населения рассчитывается как

Первые 5 человек
- Доля более богатого населения = 1 - 0, 25
- Доля более богатого населения = 0, 75
Следующие 10 человек
- Доля более богатого населения = 1 - 0, 25 - 0, 50
- Доля более богатого населения = 0, 25
Последние 5 человек
- Доля более богатого населения = 1 - 0, 25 - 0, 50 - 0, 25
- Доля более богатого населения = 0, 00
Оценка рассчитывается по формуле, приведенной ниже
Оценка = доля дохода * (доля населения + 2 * доля более богатого населения)

Первые 5 человек
- Оценка = 0, 09 * (0, 25 + 2 * 0, 75)
- Оценка = 0, 159
Следующие 10 человек
- Оценка = 0, 36 * (0, 50 + 2 * 0, 25)
- Оценка = 0, 364
Последние 5 человек
- Оценка = 0, 55 * (0, 25 + 2 * 0, 00)
- Оценка = 0, 136
Совокупный балл рассчитывается как

- Совокупный балл = 0, 159 + 0, 364 + 0, 136
- Совокупный балл = 0, 659
Коэффициент Джини рассчитывается по приведенной ниже формуле
Коэффициент Джини = 1 - Совокупный балл

- Коэффициент Джини = 1 - 0, 659
- Коэффициент Джини = 0, 341
Таким образом, коэффициент Джини населения составляет 0, 341.
Формула коэффициента Джини - пример № 2
Давайте возьмем пример двух стран (Страна X и Страна Y) и проверим, в какой стране наблюдается более высокое неравенство в доходах. Основываясь на следующей информации, рассчитайте их коэффициент Джини.

Решение:
Доля более богатого населения рассчитывается как

Группа 1
- Доля более богатого населения = 1 - 0, 30
- Доля более богатого населения = 0, 70
Группа 2
- Доля более богатого населения = 1 - 0, 30 - 0, 60
- Доля более богатого населения = 0, 10
Группа 3
- Доля более богатого населения = 1 - 0, 30 - 0, 60 - 0, 10
- Доля более богатого населения = 0, 00
Для страны X
Оценка рассчитывается по формуле, приведенной ниже
Оценка = доля дохода * (доля населения + 2 * доля более богатого населения)

Группа 1
- Оценка = 0, 03 * (0, 30 + 2 * 0, 70)
- Оценка = 0, 051
Группа 2
- Оценка = 0, 45 * (0, 60 + 2 * 0, 10)
- Оценка = 0, 360
Группа 3
- Оценка = 0, 52 * (0, 10 + 2 * 0, 00)
- Оценка = 0, 052
Совокупный балл рассчитывается как

- Совокупный балл = 0, 051 + 0, 360 + 0, 052
- Совокупный балл = 0, 463
Коэффициент Джини рассчитывается по приведенной ниже формуле
Коэффициент Джини = 1 - Совокупный балл

- Коэффициент Джини = 1 - 0, 463
- Коэффициент Джини = 0, 537
Для страны Y
Оценка рассчитывается по формуле, приведенной ниже
Оценка = доля дохода * (доля населения + 2 * доля более богатого населения)

Группа 1
- Оценка = 0, 08 * (0, 30 + 2 * 0, 70)
- Оценка = 0, 136
Группа 2
- Оценка = 0, 37 * (0, 60 + 2 * 0, 10)
- Оценка = 0, 296
Группа 3
- Оценка = 0, 55 * (0, 10 + 2 * 0, 00)
- Оценка = 0, 055
Совокупный балл рассчитывается как

- Совокупный балл = 0, 136 + 0, 296 + 0, 055
- Совокупный балл = 0, 487
Коэффициент Джини рассчитывается по приведенной ниже формуле
Коэффициент Джини = 1 - Совокупный балл

- Коэффициент Джини = 1 - 0, 487
- Коэффициент Джини = 0, 513
Таким образом, можно видеть, что Страна Y имеет более низкое неравенство в доходах, чем Страна X.
объяснение
Формула для коэффициента Джини может быть получена с помощью следующих шагов:
Шаг 1: во- первых, собрать информацию о доходах для всего населения и упорядочить набор данных в порядке возрастания доходов.
Шаг 2: Затем сгруппируйте население в разные сегменты в зависимости от уровня дохода.
Шаг 3: Затем рассчитайте вклад каждой группы в общий доход, то есть общий доход группы, деленный на доход всего населения, и он известен как доля дохода .
Шаг 4: Затем рассчитайте вклад каждой группы в общую популяцию, то есть популяцию группы, поделенную на всю популяцию, и она известна как Фракция населения .
Шаг 5: Затем вычислите долю более богатого населения для каждой группы, которая равна единице минус совокупная доля населения (от группы с низким доходом к группе с более высоким доходом).
Шаг 6: Затем, оценка для каждой группы может быть рассчитана с использованием доли дохода, доли населения и доли более богатого населения, как показано ниже.
Оценка = доля дохода * (доля населения + 2 * доля более богатого населения)
Шаг 7: Затем суммируйте баллы каждой группы, чтобы получить совокупный балл.
Шаг 8: Наконец, формула для коэффициента Джини может быть получена 1 минус совокупный балл, как показано ниже.
Коэффициент Джини = 1 - Совокупный балл
Актуальность и использование формулы коэффициента Джини
Очень важно понять концепцию коэффициента Джини, поскольку он является одним из наиболее важных экономических инструментов, используемых для анализа богатства или распределения доходов в стране. Более низкое значение с более низким коэффициентом Джини указывает на экономическое благосостояние и процветание, адекватно распределяемое среди населения, в то время как более высокое значение указывает на концентрацию богатства для отдельных избранных, что не рассматривается как признак национального процветания.
Коэффициент формулы Джини
Вы можете использовать следующий калькулятор коэффициента Джини
| Совокупный балл |
| Коэффициент Джини |
| Коэффициент Джини = | 1 - Совокупный балл |
| знак равно | 1 - 0 = 0 |
Рекомендуемые статьи
Это руководство по формуле коэффициента Джини. Здесь мы обсуждаем, как рассчитать коэффициент Джини вместе с практическими примерами. Мы также предоставляем Калькулятор коэффициента Джини с загружаемым шаблоном Excel. Вы также можете посмотреть следующие статьи, чтобы узнать больше -

Давайте разберемся, как рассчитать P-Value в Excel, используя несколько примеров.
Вы можете скачать этот шаблон Excel P-Value здесь - Шаблон Excel P-Value
P-значение в Excel - пример № 1
В этом примере мы рассчитаем P-значение в Excel для заданных данных.
- Что касается скриншота, мы можем видеть ниже, мы собрали данные некоторых игроков в крикет против прогонов, которые они сделали в определенной серии.

- Теперь, для этого нам нужен еще один хвост, мы должны получить ожидаемые пробеги, которые должен был забить каждый игрок с битой.
- Для столбца ожидаемых пробегов мы найдем средние пробеги для каждого игрока, разделив нашу сумму подсчетов на сумму пробегов следующим образом.

- Здесь мы нашли ожидаемое значение, разделив нашу сумму отсчетов на сумму прогонов. В основном средний и в нашем случае это 63, 57 .
- Как видно из таблицы, мы добавили столбец для ожидаемых прогонов, перетащив формулу, использованную в ячейке C3.
Теперь, чтобы найти P-значение для этого конкретного выражения, формулой для этого является TDIST (x, deg_freedom, tails).
- х = диапазон наших данных, которые запускаются
- deg_freedom = диапазон данных наших ожидаемых значений.
- tails = 2, так как мы хотим получить ответ для двух хвостов.

- На изображении выше мы видим, что полученные результаты составляют почти 0.
- Таким образом, для этого примера мы можем сказать, что у нас есть веские доказательства в пользу нулевой гипотезы.
P-значение в Excel - пример № 2
- Здесь для давайте предположим некоторые значения, чтобы определить поддержку против квалификации доказательств.
- Для нашей формулы = TDIST (x, deg_freedom, tails).
- Здесь, если мы возьмем x = t (тестовая статистика), deg_freedom = n, tail = 1 или 2.

- Здесь, как мы можем видеть результаты, если мы видим в процентах, это 27, 2%.
Точно так же вы можете найти P-значения для этого метода, когда предоставляются значения x, n и tails.
P-значение в Excel - пример № 3
Здесь мы увидим, как рассчитать P-значение в Excel для корреляции.
- В то время как в Excel нет формулы, которая дает прямое значение P-значения, связанного с корреляцией.
- Таким образом, мы должны получить P-значение из корреляции, корреляция - это r для P-значения, как мы уже обсуждали ранее, чтобы найти P-Valuepvalue, которое мы должны найти после получения корреляции для заданных значений.
- Чтобы найти корреляцию, формула является CORREL (массив1, массив2)

- Из уравнения корреляции мы найдем тестовую статистику r. Мы можем найти т для P-значения.
- Чтобы вывести t из r, формула t = (r * sqrt (n-2)) / (sqrt (1-r ^ 2)
- Теперь предположим, что n (№ наблюдения) равно 10 и r = 0, 5

- На изображении выше мы нашли t = 1.6329…
- Теперь, чтобы оценить значение значимости, связанное с t, просто используйте функцию TDIST.
= t.dist.2t (т, степень_свободы)

- Таким образом, P-значение, которое мы нашли для данной корреляции, составляет 0, 1411.
- С помощью этого метода мы можем найти P-значение из корреляции, но после нахождения корреляции мы должны найти t и затем после того, как мы сможем найти P-значение.
A / B тестирование:
- A / B-тестирование - это скорее обычный пример, чем превосходный пример P-Value.
- Здесь мы рассмотрим пример запуска продукта, организованного телекоммуникационной компанией:
- Мы собираемся классифицировать данные или привлекать людей с историческими данными и данными наблюдений. Исторические данные в смысле ожидаемых людей согласно прошлым событиям запуска.
Тест: 1 Ожидаемые данные :
Всего посетителей: 5000
Тест: 2 Наблюдаемые данные :
Всего посетителей: 7000
- Теперь, чтобы найти х 2, мы должны использовать формулу хи-квадрат, в математическом отношении ее сложение (наблюдаемые данные - ожидаемые) 2 / ожидаемые
- Для наших наблюдений его х 2 = 1000

- Теперь, если мы проверим наш результат с помощью диаграммы хи-квадрат и просто пробежимся, наш счет хи-квадрат 1000 со степенью свободы 1.
- В соответствии с приведенной выше таблицей хи-квадрат, и идея в том, что мы будем двигаться слева направо, пока не найдем счет, соответствующий нашим оценкам. Наше приблизительное значение P - это значение P в верхней части таблицы, выровненное по столбцу.
- Для нашего теста оценка очень высока, чем самое высокое значение в данной таблице 10, 827. Таким образом, мы можем предположить, что значение P для нашего теста составляет не менее 0, 001.
- Если мы проведем наш счет через GraphPad, мы увидим, что его значение составляет менее 0, 00001.
Что нужно помнить о P-Value в Excel
- P-Value включает в себя измерение, сравнение, тестирование всего, что составляет исследование.
- P-значения - это далеко не все исследования, они только помогают вам понять вероятность того, что ваши результаты окажутся случайными и измененными условиями.
- Это на самом деле не говорит вам о причинах, величине или для определения переменных.
Рекомендуемые статьи
Это было руководство по P-Value в Excel. Здесь мы обсудили, как рассчитать P-Value в Excel вместе с практическими примерами и загружаемым шаблоном Excel. Вы также можете просмотреть наши другие предлагаемые статьи -
Предположим, что в некоторой стране N проживают три группы населения: бедные, средний класс и богатые. Группы равны по численности жителей, но различаются по уровню дохода: средний класс зарабатывает в два раза больше, чем бедные, а богатые зарабатывают в два раза больше, чем средний класс. Внутри групп доходы распределены равномерно. Совокупный доход всех жителей страны равен Y. Нарисуйте график кривой Лоренца и рассчитайте индекс Джини.
Решение:
Третья часть населения, по условию задачи, бедные. Их доходы обозначим через х.
Тогда 2х – величина доходов среднего класса,
4х - величина доходов богатых.
Следовательно, совокупный доход всех жителей страны Y состоит из 7 одинаковых частей.
1/7 – доля доходов бедных,
2/7 – доля доходов среднего класса,
4/7 – доля доходов богатых.
Представим условие задачи в табличной форме:
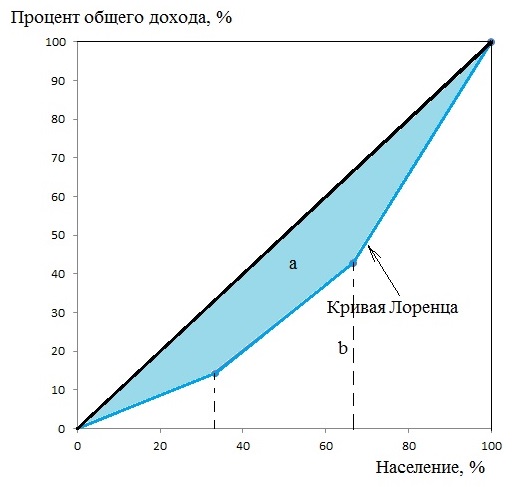
Индекс Джини рассчитаем двумя способами.
1) Способ аналитический. Коэффициент Джини рассчитывается по формуле:

xi – доля населения, принадлежащая к i-й социальной группе в общей численности населения;
уi – доля доходов, сосредоточенная у i-й социальной группы населения;
n – число социальных групп;
cum yi – кумулятивная доля дохода.

2) Способ геометрический. Коэффициент Джини определяется как отношение площади фигуры, образуемой кривой Лоренца и линией равномерного распределения (Sa), к площади треугольника ниже линии равномерного распределения (Sa+b):

Площадь фигуры, образуемой кривой Лоренца и линией равномерного распределения (Sa) легко найти вычитанием из площади треугольника (Sa+b) площадь фигуры, лежащей ниже кривой Лоренца.
Площадь фигуры b, лежащей ниже кривой Лоренца можно разбить на треугольник и две трапеции:


Площадь фигуры a будет равна:


Индекс Джини будет равен:

Оба способа дали одинаковый результат.
Как видно из таблицы, наиболее обеспеченная группа населения сконцентрировала 57,14% доходов, а доля наименее обеспеченной группы в общем доходе составила 14,29%.
Читайте также: