
Как посмотреть план запроса 1с
Обновлено: 04.07.2024
Описание и установка внешней обработки "Консоль запросов" для управляемого приложения
Инструмент "Консоль запросов" предназначена для отладки и просмотра результатов выполнения запросов в режиме 1С:Предприятие . Данная обработка предназначена в основном для разработчиков конфигураций и специалистов по внедрению. Данный инструмент можно использовать только в управляемом режиме. Если работа происходит в обычном режиме, то необходимо использовать "Консоль запросов" для 1C:Предприятия 8.1.
При разработке запросов в конфигураторе, как правило, требуется проводить отладку запроса на реальных данных. Данный инструмент позволяет вести разработку запроса (или пакета запросов) параллельно с просмотром результата. При работе с инструментом в толстом клиенте можно воспользоваться конструктором запросов, как и при работе в конфигураторе. Возможности по анализу результата запроса включают:
- вывод данных временных таблиц;
- замер времени выполнения запроса и числа строк;
- подсветку указанных ячеек в результате запроса;
- интерактивное сравнение двух результатов запроса (только в толстом клиенте);
- вывод результата запроса в новом окне;
- вывод плана выполнения запроса, а также SQL-текст запроса, сформированного в СУБД. Для СУБД Microsoft SQL Server план выполнения выводится в виде дерева, а для остальных СУБД – в текстовом формате технологического журнала. Для упрощения анализа запросов также предусмотрено два режима отображения текстов запросов: с именами таблиц и колонок СУБД или с именами объектов метаданных и реквизитов конфигурации (только в обработке для "1С:Предприятие" версии 8.3).
После завершения отладки текст запроса можно перенести в код (с помощью команды формирования текста запроса для конфигуратора) или в отчеты конфигурации. К сервисным возможностям относится работа сразу с несколькими запросами (пакет запросов), сохранение текста и параметров запросов в файле, автосохранение, экспорт результатов запроса в табличный документ и другое.
ВЫ МОЖЕТЕ ПРЯМО СЕЙЧАС УСТАНОВИТЬ ФАЙЛЫ ОТЧЕТОВ И ОБРАБОТОК
НА ЖЕСТКИЙ ДИСК ВАШЕГО КОМПЬЮТЕРА
Обработка КонсольЗапросов.epf для запуска в "1С:Предприятии" версии 8.2 находится в каталоге \1CITS\EXE\ExtReps\Unireps82\RequestConsoleManaged\
Обработка КонсольЗапросов.epf для запуска в "1С:Предприятии" версии 8.3 находится в каталоге \1CITS\EXE\ExtReps\Unireps83\RequestConsoleManaged\
Наверное, каждый 1С-ник задавался вопросом "что быстрее, соединение или условие в ГДЕ?" или, например, "сделать вложенный запрос или поставить оператор В()"?
После чего 1С-ник идет на форум, а там ему говорят - надо смотреть план запроса. Он смотрит, и ничего не понимая, навсегда забрасывает идею оптимизации запросов через планы, продолжая сравнивать варианты простым замером производительности.
В результате, на машине разработчика запрос начинает просто летать, а затем в боевой базе при увеличении количества записей все умирает и начинаются жалобы в стиле "1С тормозит". Знакомая картинка, не правда ли?
В данной статье я не дам вам исчерпывающих инструкций по чтению планов запроса. Но я постараюсь объяснить доходчиво - что это такое и с какой стороны к ним подойти.
Более того, я не считаю себя хорошим оптимизатором запросов, поэтому, в статье весьма вероятны фактологические косяки. Ну тут пусть гуру меня поправят в каментах. На то мы тут и сообщество, чтобы помогать друг-другу, верно?
Если вы уже умеете читать планы запросов, то, наверное, стоит пропустить статью. Тут будет самое простое и с начала начал. Статья ориентирована на тех разработчиков, которые пока еще не выяснили, что это за зверь - план запроса.
А начну я издалека. Дело в том, что компьютеры, к которым мы привыкли, они не такие уж и умные. Вы же наверняка помните первые уроки информатики, или младшие курсы ВУЗа? Помните сортировку массивов пузырьком там, или чтение файла построчно? Так вот, принципиально нового ничего не изобретено в современных реляционных СУБД.
Если на лабораторках вы считывали строчки из файла, а потом записывали их в другое место, то вы уже примерно представляете, как работает современная СУБД. Да, разумеется, там все намного (совсем намного) сложнее, но - циклы они и в Африке циклы, чтение диска все еще не стало быстрее чтения ОЗУ, а алгоритмы O(N) все еще медленнее алгоритмов O(1) при увеличении N.
Давайте представим, что к вам, простому 1С-нику пришел человек и говорит: "смотри, дружище, надо написать базу данных. Вот тут файл, в нем строчки какие-нибудь пиши. А потом оттуда читай". Представим, что отказаться вы не можете. Как бы вы решали эту задачу?
А решали бы вы ее точно так же, как решают ее ребята из Microsoft, Oracle, Postgres и 1С. Вы бы открыли файл средствами вашего языка программирования, прочитали бы оттуда строки и вывели бы их на экран. Никаких принципиально отличных алгоритмов, от тех, что я уже описал - мир не придумал.
Представьте, что у вас есть 2 файла. В одном записаны контрагенты, а в другом - договоры контрагентов. Как бы вы реализовывали операцию ВНУТРЕННЕЕ СОЕДИНЕНИЕ? Вот прямо в лоб, без каких-либо оптимизаций?
Контрагенты
IDКонтрагента
НомерДоговора
Давайте сейчас для простоты опустим нюансы открывания файлов и чтения в память. Сосредоточимся на операции соединения. Как бы вы его делали? Я бы делал так:
В примере ф-я ВывестиРезультатСоединения просто выведет на экран все колонки из переданных строк. Ее код здесь не существенен.
Итак, мы видим два вложенных цикла. Внешний по одной таблице, а потом во внутреннем - поиск ключа из внешней простым перебором. А теперь, внезапно, если вы откроете план какого-нибудь запроса с СОЕДИНЕНИЕМ в любой из 1С-ных СУБД, то с довольно высокой вероятностью увидите там конструкцию "Nested Loops". Если перевести это с языка вероятного противника на наш, то получится "Вложенные циклы". То есть, в "плане запроса" СУБД вам объясняет, что вот тут, для "соединения" она применила алгоритм, описанный выше. Этот алгоритм способен написать любой школьник примерно 7-го класса. И мощные боевые СУБД мирового уровня применяют этот алгоритм совершенно спокойно. Ибо в некоторых ситуациях - он лучшее, что есть вообще.
И вообще, чего это я сразу с "соединения" начал. Давайте предположим, что вам нужно просто найти контрагента по наименованию. Как бы вы решали эту задачу? Вот есть у вас файл с контрагентами. Напишите алгоритм. Я напишу его вот так:
Нет, ну серьезно, а как еще его можно написать? А никак по сути. Если неизвестно в каком порядке лежат записи в таблице, то придется пересмотреть ее всю, как ни крути. На языке планов запроса это называется Scan. Сканирование. Полный просмотр данных и ничего больше.
Индексы
А как же мы можем ускорить поиск данных в таблице? Ну правда, всё время пересматривать всё - это же зло какое-то.
Вспомним картотеку в поликлинике или библиотеке. Как там выполняется поиск по фамилии клиента? В деревянных шкафчиках стоят аккуратные карточки с буквами от А до Я. И пациент "Пупкин" находится в шкафчике с карточкой "П". Просматривать подряд все прочие буквы нет необходимости. Если мы отсортируем данные в нашей таблице и будем знать, где у нас (под какими номерами строк) находятся записи на букву "П", то мы существенно приблизимся к быстродействию тетеньки из регистратуры. А это уже лучше, чем полный перебор, не так ли?
Так вот, слово "Индекс" в данном контексте означает (опять же, в переводе с языка вероятного противника) "Оглавление". Чтобы быстро найти главу в книге, вы идете в оглавление, находите там название главы, потом смотрите номер страницы и идёте сразу на эту страницу.
Когда базе данных нужно найти запись в таблице, она идет в оглавление, смотрит на название контрагента, смотрит на номер записи, под которой он лежит, и идет в нужную область файла данных сразу за этой записью.
В виде кода это может выглядеть примерно так:
Известно, что чудес не бывает, поэтому, память под Соответствие "Индекс", а также поиск в самом соответствии - это небесплатные операции. Но они намного дешевле, чем прямой перебор всех данных. Ах, да, это Соответствие придется постоянно поддерживать в актуальном состоянии при добавлении или изменении основных данных.
Теперь давайте подумаем, а как бы вы реализовывали сам этот индекс? Можно хранить записи в файле данных сразу в отсортированном виде. И все бы ничего, но, во-первых, искать надо каждый раз по разным полям, а во-вторых, если в уже заполненную от А до Я таблицу пользователь захочет вставить запись на букву М? А ведь он захочет, я вас уверяю.
Вспомним, как вообще ведется запись в файл.
Если адрес position указывает куда-то в середину файла, и на этом месте есть данные, то они затираются новыми. Если нужно вставить что-то в середину файла (и массива в памяти в том числе) то нужно в явном виде "подвинуть" все, что находится после position, освободив место, а уже потом писать новые данные. Как вы понимаете, "подвижка" данных это опять же циклы и операции ввода/вывода. То есть, не так уж быстро. Ничего в компьютере "само" не происходит. Все по команде.
Вернемся к индексу. Пользователь хочет вставить что-то в середину. Хочешь не хочешь, а придется двигать данные, либо исхитряться с хранением данных в "страницах", связанных между собой в список. Физически писать в конец, или в пустое место, но как будто в середину таблицы. И потом еще обновлять в оглавлении номера записей. Они же теперь сдвинулись и индекс показывает не туда куда нужно. Вы, наверное, слышали, что индексы в БД ускоряют поиск, но замедляют вставку и удаление. Теперь, вы знаете, почему это так.
Ну так вот, мы еще не решили проблему поиска по разным полям. Мы же не можем хранить данные в файле в разном порядке. Одному пользователю по имени, а другому, скажем - по дате. Причем одновременно. Как бы вы решали эту задачу? По-моему, решение очевидно - нужно хранить отдельно данные и отдельно оглавления, отсортированные по нужным полям. Т.е. в базе данные лежат, как придется, но рядышком мы создадим файлик, где записи отсортированы по имени. Это будет индекс по полю "Имя". А еще рядышком будет другой такой же файлик, но отсортированный по полю "Дата". Для экономии места мы будем хранить в индексах не все колонки основной таблицы, а только те, по которым выполнена сортировка (чтобы быстро тут искать, находить номер записи и моментально прыгать к ней, чтоб прочитать остальные данные).
Ребята, которые пишут взрослые СУБД тоже не придумали ничего лучше. Индексы в БД устроены именно так. Все данные из таблицы лежат отсортированными рядышком в отдельной сущности. По сути, индекс, это просто еще одна таблица. И места она занимает пропорционально размеру основной таблицы, что логично. Да, там еще есть разные ухищрения, типа сбалансированных деревьев и всякого такого, но смысл не сильно меняется.
Кстати, если записывать данные в основную таблицу сразу упорядоченными, то можно не делать отдельно хранимый индекс и считать индексом саму таблицу с данными. Здорово, правда? Такой индекс называют "кластерным". Логично, что поле, по которому отсортированы записи в таблице должно стараться монотонно нарастать. Вы же помните про вставку в середину, верно?
Представьте, что у вас таблица в пять миллионов записей. И есть у нее индекс. Надо быстренько найти запись со словом "Привет". А еще представьте, что у вас такая же таблица, но с тремя записями. И тоже надо найти "Привет". Какой способ поиска выбрать? Открыть файл индекса, пробежаться по нему двоичным поиском, найти нужный номер записи, открыть файл основной таблицы, перейти к записи по ее номеру, прочитать ее? Или запустить цикл от одного до трех, проверив каждую запись на соответствие условию? Современный компьютер циклы от одного до трех выполняет просто ужас, как быстро.
Чтобы принять решение, планировщик запроса должен понимать, с чем имеет дело. Он оперирует такой штукой, как статистика. Статистика включает в себя количество записей по таблицам, распределение данных по колонкам, селективность и прочее и прочее. Это все подсказки планировщику о том, какой способ сбора данных будет быстрее. Не самым быстрым из возможных, а хотя бы достаточно быстрым с некоторой вероятностью. И у планировщика ограничено время на принятие решения. мы же хотим быстро получить данные, а не ждать, пока он там планирует себе.
Вот тут уже я бы не стал браться за работу по написанию планировщика, не защитив предварительно диссертацию. Как он там работает и как умудряется делать это вполне сносно - не знаю. Поэтому, ограничимся документацией СУБД. Из нее следует, что на основании статистики планировщик строит несколько возможных вариантов пошагового выполнения запроса, а потом выбирает из них наиболее подходящий. Например, первый попавшийся. Тоже ведь эвристика, разве нет?
"Что мне сделать сначала" - думает планировщик: "обойти всю таблицу А, отобрав записи по условию, а потом соединить с таблицей Б вложенными циклами, или же найти индексом все подходящие записи таблицы Б, а уже потом пробежаться по таблице А"? Каждый из шагов имеет определенный вес или стоимость. Чем больше стоимость, тем сложнее выполнять. В плане запросов всегда написана стоимость каждого из шагов, которые выполнил движок СУБД, чтобы собрать результаты запроса.
Устройство оператора плана
Каждый шаг плана запроса реализован в виде некоторого объекта, на вход которого подается одно множество записей, а на выходе получается другое. Если представить это в виде кода, то получится, что оператор плана запросов представляет собой реализацию абстрактного интерфейса с одним методом:
для тех кто не понял, что тут написано, поясню. Каждый оператор плана запросов имеет метод "ДайСледующуюЗапись". Движок СУБД дергает оператор за этот метод и при каждом таком дергании добавляет полученную запись к результату запроса. Например, оператор фильтрации записей на входе имеет всю таблицу, а на выходе - только те, которые удовлетворяют условию. Далее, выход этого оператора подается на оператор, например, ПЕРВЫЕ 100, а далее на оператор агрегации (СУММА или КОЛИЧЕСТВО), которые точно так же, внутри инкапсулируют всю обработку, а на выход выдают запись с результатом.
Схематично это выглядит так:
ВсеДанные ->Фильтр(Имя="Петров")->Первые(100)->Аггрегация(КОЛИЧЕСТВО)
Когда вы откроете план запроса, то увидите кубики, соединенные стрелочками. Кубики - это операторы. Стрелочки - направление потоков данных. Данные бегут по стрелочкам от одного оператора к другому, сливаясь в конце в результат запроса.

Каждый оператор имеет некие параметры: количество обработанных записей, стоимость, количество операций ввода/вывода, использование кэшей и прочее и прочее. Все это позволяет судить об эффективности выполнения запроса. Scan таблицы, пробежавший миллион записей и выдавший две на выходе - это не очень хороший план запроса. Но лучше планировщик ничего не нашел. У него не было индекса, чтобы поискать в нем. А может, наврала статистика и сказала, что в таблице три записи, а на самом деле туда успели написать миллион штук, но статистику не обновили. Все это предмет для разбирательства инженером, который изучает запрос.
План запроса - это пошаговый отладчик запроса. Вы пошагово смотрите, что именно, какой алгоритм (в буквальном смысле) применила СУБД, чтобы выдать результат. Примеры самих алгоритмов вы видели - они чрезвычайно сложны, ведь там есть циклы и условия. Даже порой несколько циклов вложены, вот ведь ужас. Важно понимать, какие процессы происходят внутри каждого оператора. Какой алгоритм применялся к массиву записей в процессе выполнения и сколько он работал.
Конкретные операторы, встречающиеся в планах запроса и их внутреннее устройство я планирую рассмотреть в следующей статье. Спасибо за то, что прочитали до конца!
Зачастую в работе возникает ситуация, когда запрос в 1С по каким-то причинам работает медленно, но анализ текста запроса не говорит нам о каких-либо проблемах.
В таком случае приходится изучать эту проблему на более низком уровне. Для этого нам нужно посмотреть текcт SQL-запроса и план запроса. Для этого можно использовать SQL Profiler.
SQL Profiler – предназначение
SQL Profiler – это программа, входящая в MS SQL Server, которая предназначена для просмотра всех событий, которые происходят в SQL-сервере. Иначе говоря, она нужна для записи трассировки.
В каких случаях данный инструмент может быть полезен 1С программисту? Прежде всего, можно получить текст запроса на языке SQL и посмотреть его план. Это также можно сделать и в технологическом журнале (ТЖ), но план запроса в ТЖ получается не таким удобным и требует наличия некоторых навыков и умений. К тому же в профайлере можно посмотреть не только текстовый, но и графический план выполнения запроса, что является более удобным.
Также профайлер позволяет узнать:
- запросы длиннее определенного времени
- запросы к определенной таблице
- ожидания на блокировках
- таймауты
- взаимоблокировки и т. д.
Анализ запросов с помощью SQL Profiler
Зачастую Profiler применяется именно для анализа запросов. И при этом нужно анализировать не все исполняемые запросы, а то, как определенный запрос на языке 1С транслируется в SQL, и обращать внимание на его план выполнения.
В частности, это бывает необходимо, чтобы понять, почему запрос выполняется медленно. Или при построении большого и сложного запроса необходимо удостовериться, что запрос на языке SQL не содержит соединений с подзапросом.
Для отслеживания запроса в трассировке выполняем следующие шаги:
1. Запускаем SQL Profiler: Пуск — Все программы — Microsoft SQL Server 2008 R2 — Средства обеспечения производительности — SQLProfiler.
2. Создаем новую трассировку: Файл – Создать трассировку (Ctrl+N).
3. Указываем сервер СУБД, на котором находится наша база данных и нажимаем Соединить:

Нам ничто не мешает выполнять трассировку сервера СУБД, находящегося на любом другом компьютере.
4. В появившемся окне Свойства трассировки переключаемся на закладку Выбор событий:

5. Далее нужно указать события и их свойства, которые мы хотим видеть в трассировке.
Так как нам нужны запросы и планы запросов, то необходимо включить соответствующие события. Для показа полного списка свойств и событий включаем флаги Показать все события и Показать все столбцы. Теперь необходимо выбрать только события, приведенные на рисунке ниже, остальные же – требуется отключить:
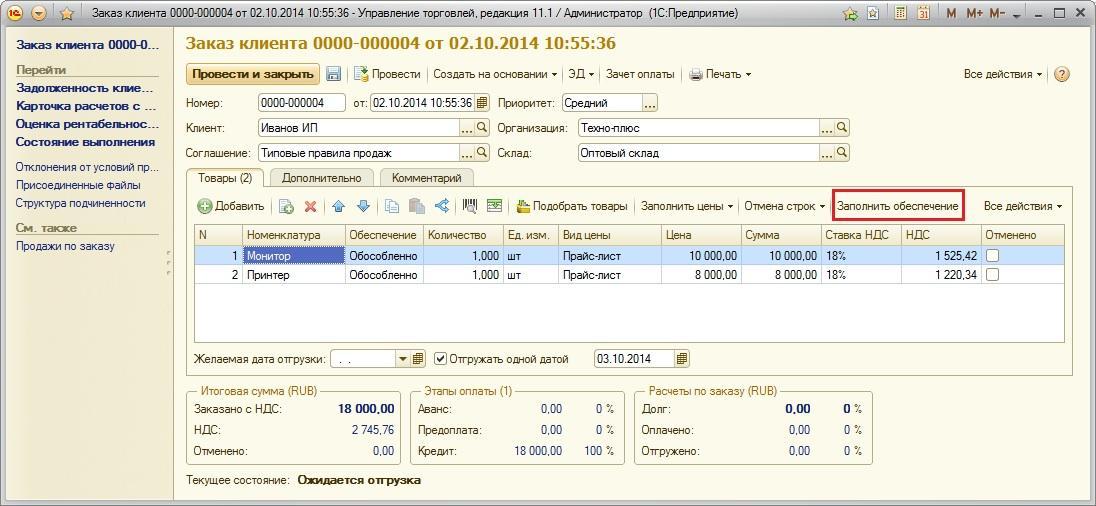
Описание этих событий:
- ShowplanStatisticsProfile– текстовый план выполнения запроса
- ShowplanXMLStatisticsProfile– графический план выполнения запроса
- RPC:Completed– текст запроса, если он выполняется как процедура (если выполняется запрос 1С с параметрами)
- SQL:BatchCompleted– текст запроса, если он выполняется как обычный запрос (если выполнялся запрос 1С без параметров)
6. На этом этапе необходима настройка фильтра для выбранных событий. Если фильтр не установлен, то мы будем видеть запросы для всех БД, расположенных на данном сервере СУБД. По кнопке Фильтры столбцов устанавливаем фильтр по имени базы данных:
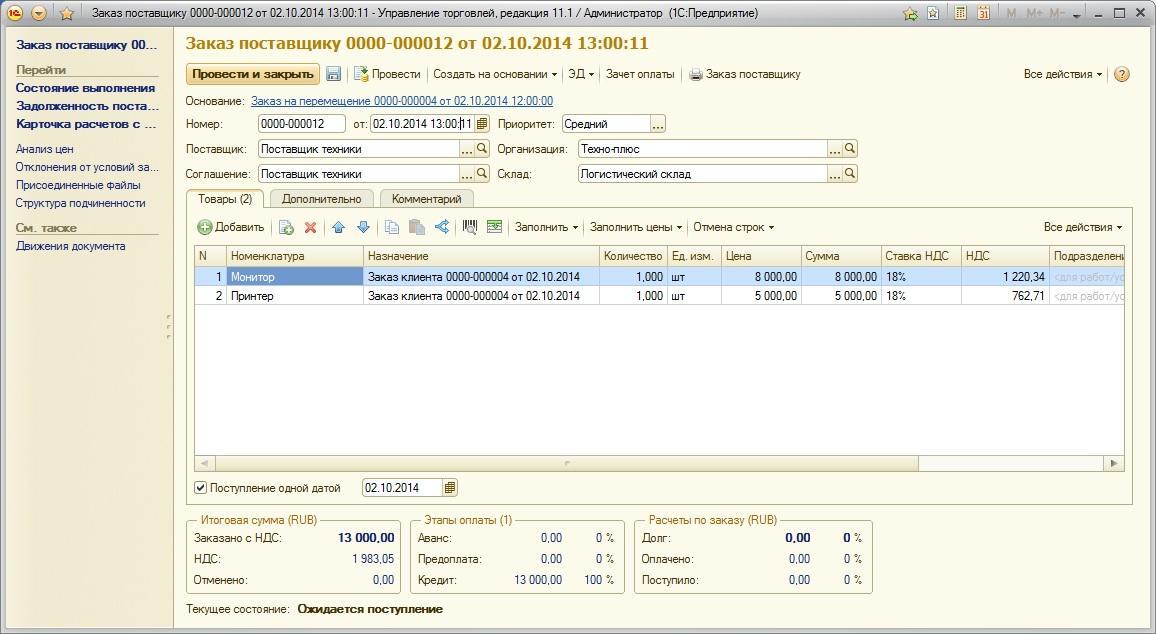
Теперь мы видим в трассировке только запросы к БД «TestBase_8_2».
Также можно поставить фильтр и по другим полям, наиболее интересные из них:
- Duration (длительность)
- TextData (обычно это текст запроса)
- RowCounts (количество строк, возвращаемых запросом)
Допустим, нам необходимо «отловить» все запросы к таблице «_InfoRg4312» длительностью более 3-х секунд в базе данных «TestBase_8_2». Для этого необходимо:
a) Установить фильтр по базе данных (см. выше)
b) Установить фильтр по длительности (устанавливается в миллисекундах):

c) Установить фильтр по тексту запроса:
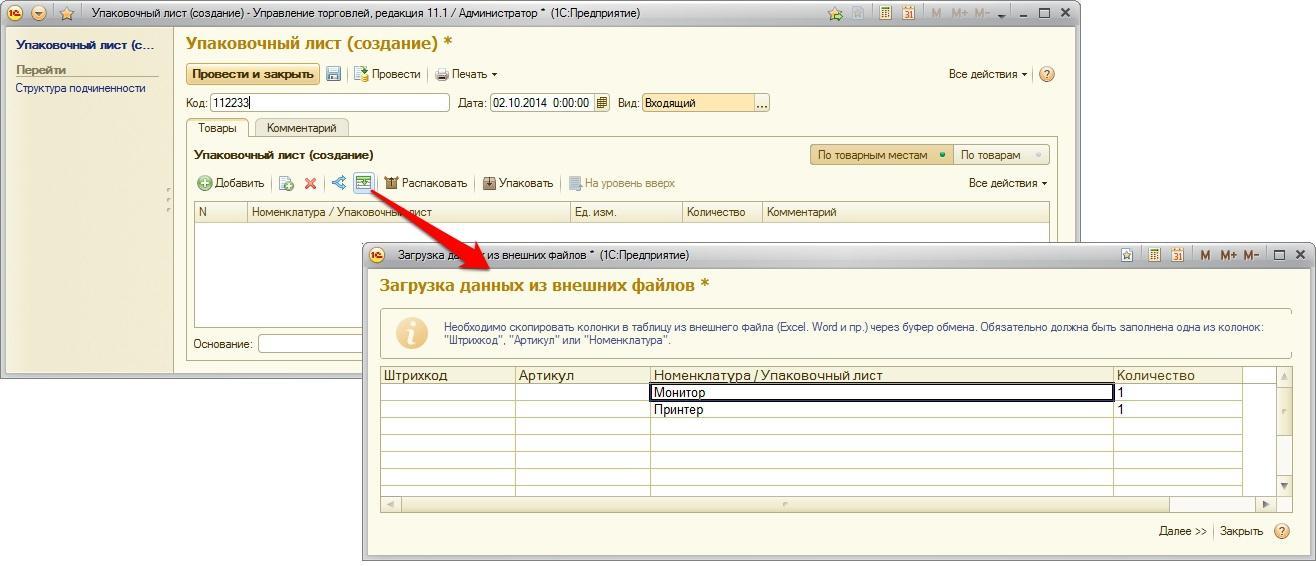
Для задания фильтра по тексту запроса используем маску. В случае необходимости отслеживать запросы, которые обращаются к нескольким таблицам, создается несколько элементов в разделе «Похоже на». Наложенные условия фильтров работают совместно.
7. Теперь запускаем трассировку с помощью кнопки Запустить в окне Свойства трассировки и наблюдаем события, попадающие под установленные фильтры, отображение которых было настроено.
Кнопки командной панели служат для управления трассировкой:

- Ластик – очищает окно трассировки
- Пуск – запускает трассировку
- Пауза – ставит трассировку на паузу, при нажатии на Пуск трассировка возобновляется
- Стоп – останавливает трассировку
8. Окно трассировки состоит из двух частей. В верхней части находятся события и их свойства, в нижней – информация, зависящая от типа событий. Для нашего примера здесь будет отображаться либо текст запроса, либо его план.
9. Запустим на выполнение запрос в консоли запросов 1С и посмотрим, как он отразится в профайлере:

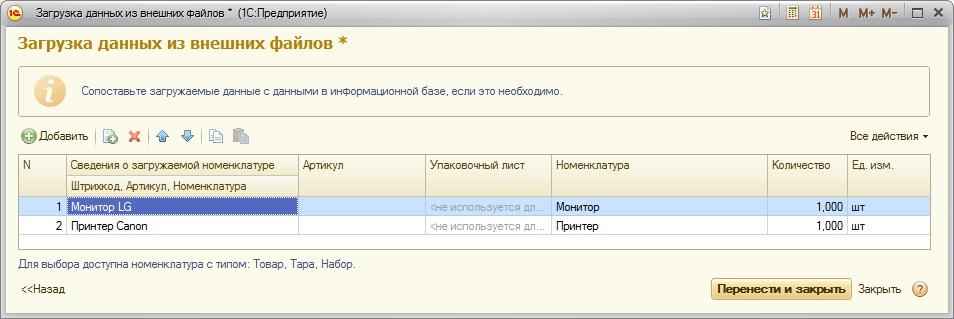
По поведению трассировки видно, что запросов в итоге получилось несколько, и только один из них нам интересен. Остальные запросы – служебные.
10. Свойства событий дают возможность оценить:
- сколько секунд выполнялся запрос (Duration)
- сколько было логических чтений (Reads)
- сколько строк запрос вернул в результате (RowCounts) и т.д.
В нашем случае запрос выполнялся 2 миллисекунды, сделал 4 логических чтения и вернул 1 строку.
11. Если взглянуть на одно событие выше, то можно увидеть план запроса в графическом виде:
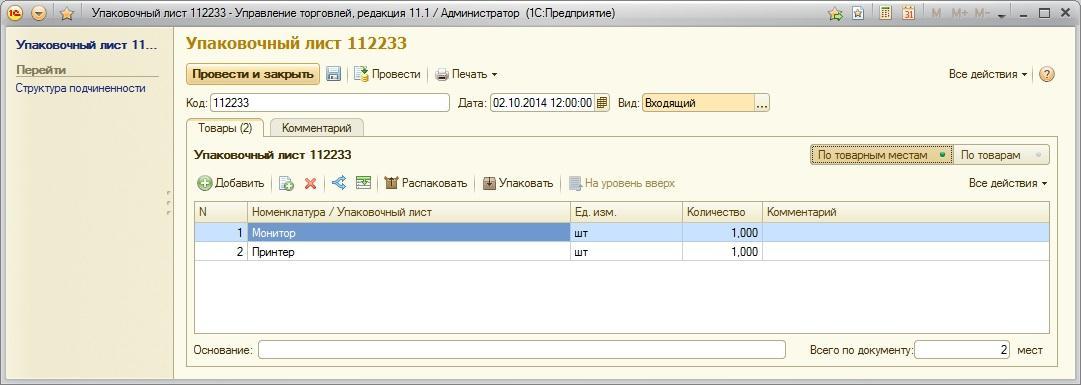
Из плана видно, что поиск осуществляется по индексу по цене, этот план нельзя назвать идеальным, так как индекс не является покрывающим, поля код и наименование получаются с помощью KeyLookup, что отнимает 50% времени.
Используя контекстное меню, полученный графический план запроса возможно сохранить в отдельный файл с расширением *.SQLPlan и открыть его в профайлере на другом компьютере или с помощью программы SQL Sentry Plan Explorer, которая является более продвинутой.
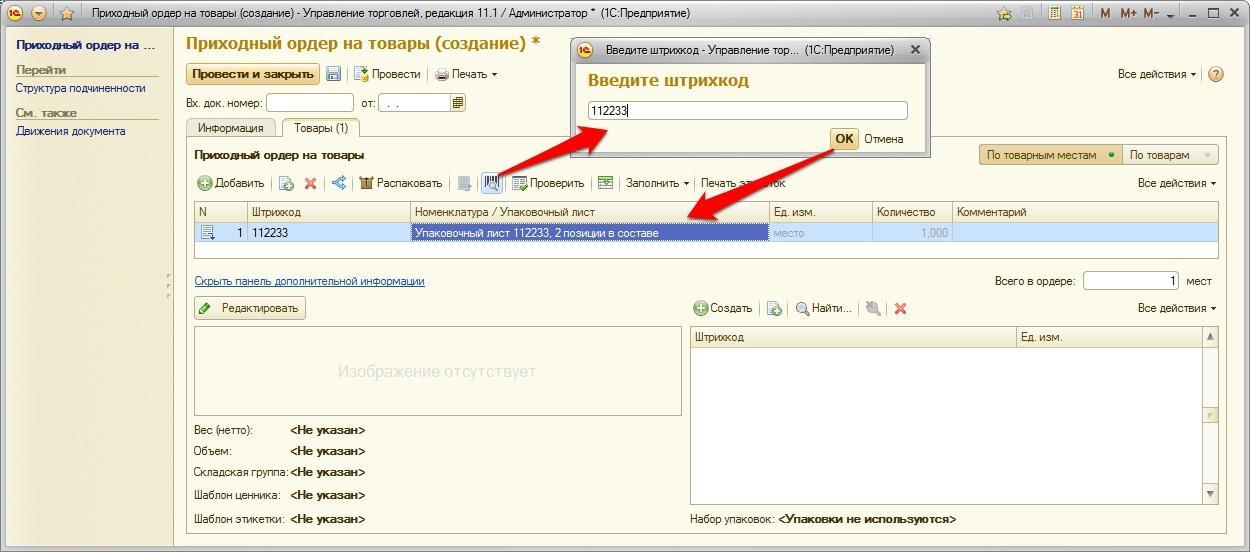
12. Если подняться еще выше, то мы увидим тот же план запроса, но уже в текстовом виде. Именно этот план отображается в ТЖ, ЦУП и прочих средствах контроля производительности 1С.
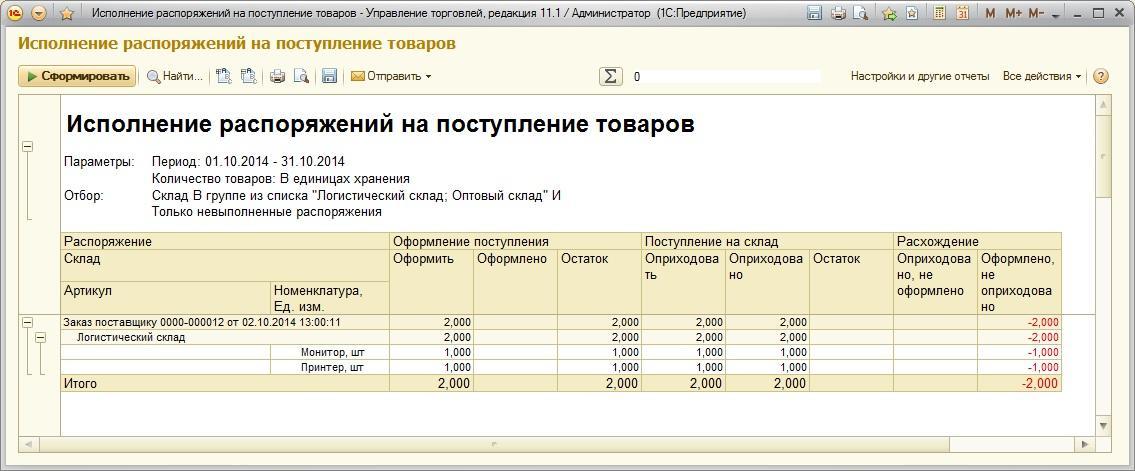
13. Через меню Файл – Сохранить как можно сохранить всю трассировку в различные форматы:
- В формат самого профайлера, то есть с расширением *.trc
- В формат xml
- Сделать из трассировки шаблон (См. следующий пункт)
- Cохранить полученную трассировку в виде таблицы базы данных. Это весьма удобный способ, когда, к примеру, нужно найти самый медленный запрос в трассировке или отфильтровать запросы по какому-либо параметру.
Используем меню Файл – Сохранить как – Таблица трассировки – Выбираем сервер СУБД и подключаемся к нему.
Затем выбираем базу данных на указанном сервере, указываем имя таблицы, куда будет сохранена трассировка. Можно использовать существующую таблицу, или дать ей новое имя, и тогда эта таблица будет создана автоматически.
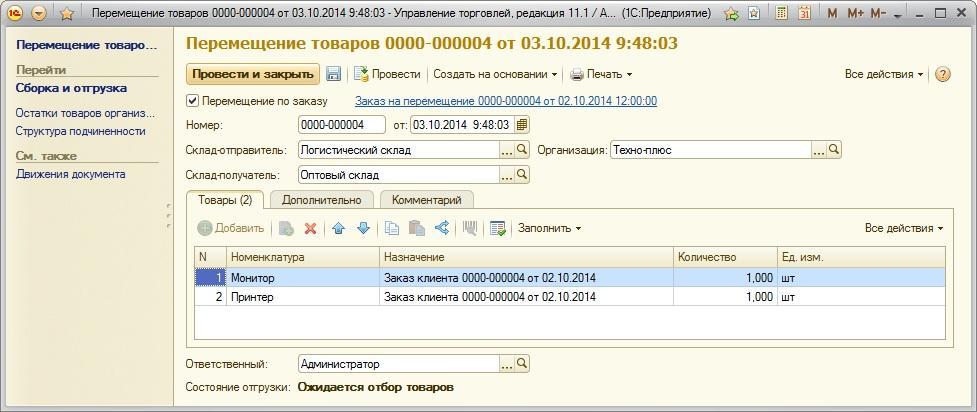
Теперь возможно строить запросы любой сложности к нашей таблице: к примеру, искать наиболее долго выполняющиеся запросы.
Также нужно помнить, что Duration сохраняется в таблицу в миллионных долях секунды, и при выводе результата нужно переводить значение в миллисекунды. Также в таблице присутствует столбец RowNumber, показывающий номер данной строки в трассировке.
14. При частом использовании профайлера для анализа запросов постоянная настройка нужных событий и фильтров будет постоянно отнимать у вас много времени.
В данном случае нам помогут шаблоны трассировок, где мы настраиваем нужные нам фильтры и порядок колонок, а далее просто используем уже имеющийся шаблон при создании новой трассировки.
Для создания шаблона используем меню Файл – Шаблоны – Новый шаблон:
На первой закладке указываем тип сервера, имя шаблона и при необходимости ставим флаг для использования данного шаблона по умолчанию.
На второй закладке делаем выбор нужных событий и осуществляем настройку фильтров (как было показано выше).
Дополнительно рекомендуется выполнить настройку порядка столбцов в трассировке, что экономит время при последующем анализе запросов. Удобным представляется следующий порядок:
При создании новой трассировки можем указать нужный шаблон, и тогда на второй закладке все фильтры и события заполнятся автоматически по созданному шаблону.
PDF-версия статьи для участников группы ВКонтакте
Статья в PDF-формате
Станьте экспертом по оптимизации 1С, изучив наш курс«Ускорение и оптимизация систем на 1С:Предприятие 8.3 (2016). Подготовка на 1С:Эксперт по технологическим вопросам»
35 учебных часов, подготовка к 1С:Эксперт, правильная настройка серверной части, оптимизация кода, мониторинг загруженности оборудования и прочие взрослые вещи.
Комментарии / обсуждение (9):
Имя индекса отображается одинаково и в MS SQL и в обработке структура хранения метаданных и начинается с 1.
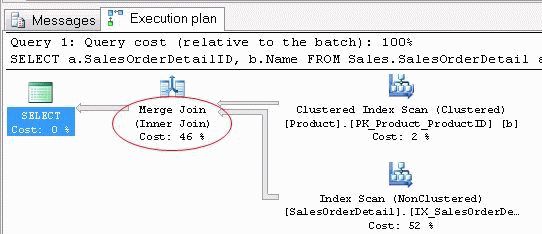
Ранее, я рассматривал, причины неоптимальной работы запросов в 1С. Однако, эти действия иногда могут не помочь в борьбе за повышение производительности системы. В этом случае, необходимо обратиться к внесистемным средствам анализа на уровне СУБД, к SQL Server Profiler.
Приложение SQL Server Profiler — это графический пользовательский интерфейс для трассировки SQL, с помощью которого программист 1С может наблюдать за экземпляром компонента Компонент Database Engine или службами Analysis Services. С помощью данной утилиты, мы может анализировать план выполнения запроса в пошаговом режиме. Приложение позволяет собирать и сохранять данные о каждом событии в файле или в таблице для последующего анализа.
Признаки выбора неоптимального плана запроса СУБД
Как правило, MS SQL подбирает для 1С оптимальный план запроса, но бывает СУБД ошибается. Связано это может быть, например, с неактуальной статистикой или высокой загруженностью системы. Программисту 1С, для того, что бы помочь оптимизатору строить правильный план запроса, необходимо проверить настройку регламентных операция на СУБД MS SQL. Среди признаков неоптимального построения плана запроса для 1С могут быть конструкции:
NESTED LOOPS
Алгоритм соединения вложенными циклами, по сути своей, это простой перебор двух таблиц и вывод удовлетворяющих соединению строк. Данный вид соединения недопустим для ведущей таблицы, с большим количество записей. Однако данный вид соединения самый простой и часто используется когда СУБД MS SQL не может подобрать другой вариант соединения. В целом, NESTED LOOPS допустим к использованию, когда в ведущей таблице не более двух записей и скорее всего он быстрее отработает в такой ситуации.
Аналог сканирования (SCAN), за тем исключением, что сканируется часть таблицы, по установленному условию.
Читайте также: