
Как построить таблицу сопряженности в excel
Обновлено: 04.07.2024
Корреляционный анализ – это распространённый метод исследования, применяемый для определения уровня зависимости 1-й величины от 2-й. В табличном процессоре есть особый инструмент, который позволяет реализовать данный тип исследования.
Суть корреляционного анализа
Он необходим для определения зависимости между двумя разными величинами. Иными словами, происходит выявление того, в какую сторону (меньшую/большую) меняется величина в зависимости от изменений второй.
Назначение корреляционного анализа
Зависимость устанавливается тогда, когда начинается выявление коэффициента корреляции. Этот метод отличается от анализа регрессии, так как здесь только один показатель, рассчитываемый при помощи корреляции. Интервал изменяется от +1 до -1. Если она плюсовая, то повышение первой величины способствует повышению 2-й. Если минусовая, то повышение 1-й величины способствует понижению 2-й. Чем выше коэффициент, тем сильнее одна величина влияет на 2-ю.
Важно! При 0-м коэффициенте зависимости между величинами нет.
Расчет коэффициента корреляции
Разберем расчёт на нескольких образцах. К примеру, есть табличные данные, где по месяцам описаны в отдельных столбцах траты на рекламное продвижение и объём продаж. Исходя из таблицы, будем выяснять уровень зависимости объема продаж от денег, затраченных на рекламное продвижение.
Способ 1: определение корреляции через Мастер функций
- Необходимо произвести выделение ячейки, в которой планируется выводить итог расчета. Нажать «Вставить функцию», находящуюся слева от текстового поля для ввода формулы.
- Открывается «Мастер функций». Здесь необходимо найти КОРРЕЛ, кликнуть на нее, затем на «ОК».
- Открылось окошко аргументов. В строку «Массив1» необходимо ввести координаты интервалы 1-го из значений. В рассматриваемом примере — это столбец «Величина продаж». Нужно просто произвести выделение всех ячеек, которые находятся в этой колонке. В строку «Массив2» аналогично необходимо добавить координаты второй колонки. В рассматриваемом примере — это столбец «Затраты на рекламу».
- После введения всех диапазонов кликаем на кнопку «ОК».
Коэффициент отобразился в той ячейке, которая была указана в начале наших действий. Полученный результат 0,97. Этот показатель отображает высокую зависимость первой величины от второй.

4
Способ 2: вычисление корреляции с помощью Пакета анализа
Существует еще один метод определения корреляции. Здесь используется одна из функций, находящаяся в пакете анализа. Перед ее использованием нужно провести активацию инструмента. Подробная инструкция:
Вывелись итоговые показатели. Результат такой же, как и в первом методе – 0,97.
Определение и вычисление множественного коэффициента корреляции в MS Excel
Для выявления уровня зависимости нескольких величин применяются множественные коэффициенты. В дальнейшем итоги сводятся в отдельную табличку, именуемую корреляционной матрицей.
Коэффициент парной корреляции в Excel
Разберем, как правильно проводить коэффициент парной корреляции в табличном процессоре Excel.
Расчет коэффициента парной корреляции в Excel
К примеру, у вас есть значения величин х и у.
12
Х – это зависимая переменна, а у – независимая. Необходимо найти направление и силу связи между этими показателями. Пошаговая инструкция:
Матрица парных коэффициентов корреляции в Excel
Разберем, как проводить подсчет коэффициентов парных матриц. К примеру, есть матрица из четырех переменных.

22
Функция КОРРЕЛ для определения взаимосвязи и корреляции в Excel
КОРРЕЛ – функция, применяемая для подсчета коэффициента корреляции между 2-мя массивами. Разберем на четырех примерах все способности этой функции.
Примеры использования функции КОРРЕЛ в Excel
Первый пример. Есть табличка, в которой расписана информация об усредненных показателях заработной платы работников компании на протяжении одиннадцати лет и курсе $. Необходимо выявить связь между этими 2-умя величинами. Табличка выглядит следующим образом:

24
Алгоритм расчёта выглядит следующим образом:

25
Отображенный показатель близок к 1. Результат:

26
Определение коэффициента корреляции влияния действий на результат
Второй пример. Два претендента обратились за помощью к двум разным агентствам для реализации рекламного продвижения длительностью в пятнадцать суток. Каждые сутки проводился социальный опрос, определяющий степень поддержки каждого претендента. Любой опрошенный мог выбрать одного из двух претендентов или же выступить против всех. Необходимо определить, как сильно повлияло каждое рекламное продвижение на степень поддержки претендентов, какая компания эффективней.

27
Используя нижеприведенные формулы, рассчитаем коэффициент корреляции:

28
Из полученных результатов становится понятно, что степень поддержки 1-го претендента повышалась с каждыми сутками проведения рекламного продвижения, следовательно, коэффициент корреляции приближается к 1. При запуске рекламы другой претендент обладал большим числом доверия, и на протяжении 5 дней была положительная динамика. Потом степень доверия понизилась и к пятнадцатым суткам опустилась ниже изначальных показателей. Низкие показатели говорят о том, что рекламное продвижение отрицательно повлияло на поддержку. Не стоит забывать, что на показатели могли повлиять и остальные сопутствующие факторы, не рассматриваемые в табличной форме.

29
Теперь необходимо провести определение наличия связи между 2-мя показателями по нижеприведенной формуле:
Если полученный коэффициент выше 0,7, то целесообразней применять функцию линейной регрессии. В рассматриваемом примере делаем:

30
Теперь производим построение графика:

31
Применяем это уравнение, чтобы определить число просматриваний при 200, 500 и 1000 репостов: =9,2937*D4-206,12. Получаем следующие результаты:

32

33
Особенности использования функции КОРРЕЛ в Excel
Данная функция имеет нижеприведенные особенности:
Оценка статистической значимости коэффициента корреляции
При проверке значимости корреляционного коэффициента нулевая гипотеза состоит в том, что показатель имеет значение 0, а альтернативная не имеет. Для проверки применяется нижеприведенная формула:

34
Заключение
Корреляционный анализ в табличном процессоре – это простой и автоматизированный процесс. Для его выполнения необходимо знать всего лишь, где находятся нужные инструменты и как их активировать через настройки программы.
В предыдущей заметке таблицы и диаграммы применялись для представления числовых данных. Однако часто данные носят не числовой, а категориальный характер. В этой заметке изучаются способы организации и представления категорийных данных в виде таблиц и диаграмм. [1]
Вернемся к анализу доходности взаимных фондов. Кроме среднегодовой доходности фонды характеризуются риском, связанном с инвестированием в эти фонды. Взаимные фонды могут иметь очень низкий, низкий, средний, высокий и очень высокий риск. При работе с категорийными переменными данные сначала заносятся в сводную таблицу, а затем графически представляются в виде гистограмм, круговых диаграмм или диаграмм Парето.
Сводная таблица
По внешнему виду сводная таблица для категорийных данных напоминает распределение частот для числовых данных. Чтобы проиллюстрировать процесс ее построения, рассмотрим данные о классификации взаимных фондов по уровню риска (рис. 1).
Рис. 1. Уровень риска 259 взаимных фондов. Частоты и процентные доли
Линейчатая диаграмма
Информацию, содержащуюся в таблице (рис. 1), можно представить в виде линейчатой диаграммы (рис. 2), в которой каждая категория элементов изображается в виде столбца. Высота столбца равна частоте или процентной доле элементов выборки, относящихся к данной категории.

Рис. 2. Линейчатая диаграмма, отображающая уровень риска фондов
Круговая диаграмма
Существует еще один весьма популярный способ отображения информации, содержащейся в сводной таблице, — круговая диаграмма (рис. 3). При построении круговых диаграмм используется тот факт, что угол окружности равен 360°. Круг разделяется на секторы, углы которых соответствуют процентным долям каждой категории. Например, на рис. 3 показан сектор, соответствующий доле взаимных фондов с низким риском, которая равна 29,3%. При построении круговой диаграммы величина 360° умножается на 0,293. В результате образуется сектор, угол которого равен 105,6°. Как видим, круговая диаграмма позволяет отразить долю каждой категории в общем «пироге».

Рис. 3. Круговая диаграмма, отображающая уровень риска фондов
Цель графического представления данных — точность и ясность. Например, рис. 2 и 3 отображают одинаковую информацию. Какой из двух видов диаграмм предпочесть — дело вкуса. В частности, некоторые исследования показывают, что люди труднее воспринимают круговые диаграммы. Оказывается, человеку намного проще интерпретировать разницу между высотами столбцов в линейчатых диаграммах, чем углы секторов в круговых диаграммах. Обратите внимание на то, что по рис. 3 нелегко определить, какая из категорий фондов больше — с низким, средним или высоким уровнем риска. В то же время по линейчатой диаграмме легко определить, что доля фондов со средним уровнем риска больше, чем доли фондов с высоким и низким уровнями риска.
С другой стороны, круговые диаграммы четко демонстрируют, что сумма долей всех категорий равна 100%. Таким образом, выбор диаграммы является субъективным и часто зависит от предпочтений пользователя. Если необходимо сравнивать доли категорий, лучше применять линейчатые диаграммы. Если важно продемонстрировать вклад долей отдельных категорий в общий «пирог», лучше использовать круговые диаграммы.
Диаграмма Парето
Существует более информативный способ графического изображения категорийных данных — диаграмма Парето. Она особенно полезна, если количество категорий велико. Диаграмма Парето — это особая разновидность вертикальной диаграммы, в которой категории приводятся в порядке убывания их частот одновременно с полигоном накопленных частот. Это позволяет выделить наиболее важные категории из большого количества менее значимых групп. Диаграмма Парето получила широкое распространение при анализе производственных процессов и контроле качества (см., например, АВС-анализ и принцип Парето для бизнеса).
Например, для построения Диаграммы Парето на основе данных рис. 1, необходимо отсортировать строки по убыванию, и одновременно отобразить как количество фондов в каждой категории, так и интегральный процент (рис. 4).

Рис. 4. Диаграмма Парето, отображающая специфику фондов
Надо отметить, что в Excel2013 предоставляется стандартная возможность построения таких комбинированных диаграмм (рис. 5). Если же у вас Excel2007, то вам придется помучиться (см., например, Диаграмма Excel с двумя осями ординат).

Рис. 5. Построение комбинированной диаграммы
Представление двумерных категорийных данных
Довольно часто необходимо анализировать пары категорийных переменных. Для этого используют таблицы сопряженности признаков и нормированные диаграммы.
Таблица сопряженности признаков. Чтобы можно было одновременно анализировать две категорийные переменные, образующие пару, используются таблицы перекрестной классификации с двумя входами, или таблицы сопряженности признаков (их также называют факторными таблицами). Например, может возникнуть вопрос: существует ли зависимость между уровнем риска и платой, взимаемой фондами за осуществление продаж своих акций (рис. 6)?

Рис. 6. Таблица сопряженности признаков, содержащая данные об уровне риска и плате, взимаемой фондами за осуществление продаж своих акций
Чтобы выявить возможную зависимость между специализацией фонда и прейскурантом его комиссионных сборов, эти результаты сначала преобразуют в процентные доли, используя следующие три базиса:
- общую сумму (259 взаимных фондов);
- сумму по строкам (фонды, взимающие плату за продажу своих акций, и фонды без брокерской комиссии);
- сумму по столбцам (пять уровней риска).
Удобную возможность построения таблиц сопряжения дает опция Excel Сводные таблицы. Для начала нужно представить исходные данные в виде строк, в каждой из которых содержатся все исследуемые параметры (рис. 7). Далее выделяем область В3:D13, и проходим по меню Вставка → Сводная таблица. В открывшемся окне Создание сводной таблицы указываем на существующий лист и в поле Диапазон кликаем на ячейку, где мы хотели расположить левый верхний угол сводной таблицы, кликаем Ok. (Если вы хотите разместить сводную таблицу на отдельном листе, сразу после открытия окна Создание сводной таблицы, кликните Ok.)

Рис. 7. Построение сводной таблицы
Для настройки сводной таблицы просто перетащите строки из верхней части области Поля сводной таблицы в нижнюю, как указано на рис. 8.

Рис. 8. Настройка полей сводной таблицы
Логично расположить строки в сводной таблицы в порядке возрастания (или убывания) степени риска. Для этого надо по очереди выбрать каждую строку, выбрав ячейку в области Название строк (например, Очень высокий), кликнуть правой кнопкой мыши, и выбрать в контекстном меню Переместить, указав, куда именно переместить выбранную строку (рис. 9).

Рис. 9. Перетаскивание строк сводной таблицы
И, наконец, мы можем выбрать базис для анализа процентных долей. Встаньет в любую ячейку в области значений (рис. 10), кликните правой кнопкой мыши, и в открывшемся контекстном меню выберите Параметры полей значений.

Рис. 10. Параметр поля значений
В окне Параметры полей значений перейдите на закладку Дополнительные вычисления, и выберите одну из опций (рис. 11):
- % от общей суммы
- % от суммы по столбцу
- % от суммы по строке

Рис. 11. Выбор базиса процентной доли
Поскольку нас интересует корреляция между степенью риска и наличием комиссии, уместно выбрать опцию % от суммы по строке. Мы увидим, подчиняется ли закономерности доля фондов, взимающих комиссию, при переходе от фондов с очень высоким риском к фондам с очень низким риском (рис. 12). Явной тенденции обнаружить не удалось. [2]

Рис. 12. Доля фондов, взимающих комиссию по уровням риска
Нормированные диаграммы
Для визуализации двумерных категорийных данных часто строят нормированные диаграммы, то есть диаграммы, в которых высота столбиков равна 1 (100%) вне зависимости от общего числа случаев в той или иной категории. На рис. 13 представлен пример такой диаграммы (ось ординат охватывает значения от 0% до 100%, просто, масштаб диаграммы выбран таким образом, что отражается лишь часть этой области). Четко видна закономерность: доля трафика google выросла летом – осенью 2012 г. с 40 до 55%, а затем вновь упала до 40% (для меня остается загадкой, с чем это связано :)).
[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 124–138
[2] Любопытно, что авторы книги такую закономерность (на тех же исходных данных) увидели 🙂
Критерий независимости хи-квадрат используется для определения связи между двумя категориальными переменными. Примерами пар категориальных переменных являются: Семейное положение vs. Уровень занятости респондента; Порода собак vs. Профессия хозяина, Уровень з/п vs. Специализация инженера и др. При вычислении критерия независимости проверяется гипотеза о том, что между переменными связи нет. Вычисления будем производить с помощью функции MS EXCEL 2010 ХИ2.ТЕСТ() и обычными формулами.
Предположим у нас есть выборка данных, представляющая результат опроса 500 человек. Людям задавалось 2 вопроса: про их семейное положение (женаты, гражданский брак, не состоят в отношениях) и их уровень занятости (полный рабочий день, частичная занятость, временно не работает, на домохозяйстве, на пенсии, учеба). Все ответы поместили в таблицу:

Данная таблица называется таблицей сопряжённости признаков (или факторной таблицей, англ. Contingency table). Элементы на пересечении строк и столбцов таблицы обычно обозначают O ij (от англ. Observed, т.е. наблюденные, фактические частоты).
Нас интересует вопрос «Влияет ли Семейное положение на Занятость?», т.е. существует ли зависимость между двумя методами классификации выборки ?
При проверке гипотез такого вида обычно принимают, что нулевая гипотеза утверждает об отсутствии зависимости способов классификации.
Рассмотрим предельные случаи. Примером полной зависимости двух категориальных переменных является вот такой результат опроса:

В этом случае семейное положение однозначно определяет занятость (см. файл примера лист Пояснение ). И наоборот, примером полной независимости является другой результат опроса:

Обратите внимание, что процент занятости в этом случае не зависит от семейного положения (одинаков для женатых и не женатых). Это как раз совпадает с формулировкой нулевой гипотезы . Если нулевая гипотеза справедлива, то результаты опроса должны были бы так распределиться в таблице, что процент занятых был бы одинаковым независимо от семейного положения. Используя это, вычислим результаты опроса, которые соответствуют нулевой гипотезе (см. файл примера лист Пример ).
Сначала вычислим оценку вероятности, того, что элемент выборки будет иметь определенную занятость (см. столбец u i ):

где с – количество столбцов (columns), равное количеству уровней переменной «Семейное положение».
Затем вычислим оценку вероятности, того, что элемент выборки будет иметь определенное семейное положение (см. строку v j ).

где r – количество строк (rows), равное количеству уровней переменной «Занятость».
Теоретическая частота для каждой ячейки E ij (от англ. Expected, т.е. ожидаемая частота) в случае независимости переменных вычисляется по формуле: E ij =n* u i * v j

Известно, что статистика Х 2 0 при больших n имеет приблизительно ХИ2-распределение с (r-1)(c-1) степенями свободы (df – degrees of freedom):

Примечание : Вышеуказанная статистика при с=1 используется для вычисления критерия согласия Пирсона ХИ-квадрат (см. статью Проверка гипотез критерием хи-квадрат Пирсона в MS EXCEL ).
Если вычисленное на основе выборки значение этой статистики «слишком большое» (больше порогового), то нулевая гипотеза отвергается. Пороговое значение вычисляется на основании уровня значимости , например с помощью формулы =ХИ2.ОБР.ПХ(0,05; df) .
Примечание : Уровень значимости обычно принимается равным 0,1; 0,05; 0,01.
При проверке гипотезы также удобно вычислять p-значение , которое мы сравниваем с уровнем значимости . p -значение рассчитывается с использованием ХИ2-распределения с (r-1)*(c-1)=df степеней свободы.
Если вероятность, того что случайная величина имеющая ХИ2-распределение с (r-1)(c-1) степенями свободы примет значение больше вычисленной статистики Х 2 0 , т.е. P (r-1)*(c-1) >Х 2 0 >, меньше уровня значимости , то нулевая гипотеза отклоняется.
В MS EXCEL p-значение можно вычислить с помощью формулы =ХИ2.РАСП.ПХ(Х 2 0 ;df) , конечно, вычислив непосредственно перед этим значение статистики Х 2 0 (это сделано в файле примера ). Однако, удобнее всего воспользоваться функцией ХИ2.ТЕСТ() . В качестве аргументов этой функции указываются ссылки на диапазоны содержащие фактические (Observed) и вычисленные теоретические частоты (Expected).
Если уровень значимости > p -значения , то означает это фактические и теоретические частоты, вычисленные из предположения справедливости нулевой гипотезы , серьезно отличаются. Поэтому, нулевую гипотезу нужно отклонить.
Использование функции ХИ2.ТЕСТ() позволяет ускорить процедуру проверки гипотез , т.к. не нужно вычислять значение статистики . Теперь достаточно сравнить результат функции ХИ2.ТЕСТ() с заданным уровнем значимости .
Примечание : Функция ХИ2.ТЕСТ() , английское название CHISQ.TEST, появилась в MS EXCEL 2010. Ее более ранняя версия ХИ2ТЕСТ() , доступная в MS EXCEL 2007 имеет тот же функционал. Но, как и для ХИ2.ТЕСТ() , теоретические частоты нужно вычислить самостоятельно.
СОВЕТ : О проверке других видов гипотез см. статью Проверка статистических гипотез в MS EXCEL .
Коэффициент корреляции ( критерий корреляции Пирсона, англ. Pearson Product Moment correlation coefficient) определяет степень линейной взаимосвязи между случайными величинами.

где Е[…] – оператор математического ожидания , μ и σ – среднее случайной величины и ее стандартное отклонение .
Как следует из определения, для вычисления коэффициента корреляции требуется знать распределение случайных величин Х и Y. Если распределения неизвестны, то для оценки коэффициента корреляции используется выборочный коэффициент корреляции r ( еще он обозначается как R xy или r xy ) :

Как видно из формулы для расчета корреляции , знаменатель (произведение стандартных отклонений с точностью до безразмерного множителя) просто нормирует числитель таким образом, что корреляция оказывается безразмерным числом от -1 до 1. Корреляция и ковариация предоставляют одну и туже информацию, но корреляцией удобнее пользоваться, т.к. она является безразмерной величиной.
Рассчитать коэффициент корреляции и ковариацию выборки в MS EXCEL не представляет труда, так как для этого имеются специальные функции КОРРЕЛ() и КОВАР() . Гораздо сложнее разобраться, как интерпретировать полученные значения, большая часть статьи посвящена именно этому.
Теоретическое отступление
Напомним, что корреляционной связью называют статистическую связь, состоящую в том, что различным значениям одной переменной соответствуют различные средние значения другой (с изменением значения Х среднее значение Y изменяется закономерным образом). Предполагается, что обе переменные Х и Y являются случайными величинами и имеют некий случайный разброс относительно их среднего значения .
Примечание . Если случайную природу имеет только одна переменная, например, Y, а значения другой являются детерминированными (задаваемыми исследователем), то можно говорить только о регрессии.
Таким образом, например, при исследовании зависимости среднегодовой температуры нельзя говорить о корреляции температуры и года наблюдения и, соответственно, применять показатели корреляции с соответствующей их интерпретацией.
Корреляционная связь между переменными может возникнуть несколькими путями:
- Наличие причинной зависимости между переменными. Например, количество инвестиций в научные исследования (переменная Х) и количество полученных патентов (Y). Первая переменная выступает как независимая переменная (фактор) , вторая - зависимая переменная (результат) . Необходимо помнить, что зависимость величин обуславливает наличие корреляционной связи между ними, но не наоборот.
- Наличие сопряженности (общей причины). Например, с ростом организации растет фонд оплаты труда (ФОТ) и затраты на аренду помещений. Очевидно, что неправильно предполагать, что аренда помещений зависит от ФОТ. Обе этих переменных во многих случаях линейно зависят от количества персонала.
- Взаимовлияние переменных (при изменении одной, вторая переменная изменяется, и наоборот). При таком подходе допустимы две постановки задачи; любая переменная может выступать как в роли независимой переменной и в роли зависимой.
Таким образом, показатель корреляции показывает, насколько сильна линейная взаимосвязь между двумя факторами (если она есть), а регрессия позволяет прогнозировать один фактор на основе другого.
Корреляция , как и любой другой статистический показатель, при правильном применении может быть полезной, но она также имеет и ограничения по использованию. Если диаграмма рассеяния показывает четко выраженную линейную зависимость или полное отсутствие взаимосвязи, то корреляция замечательно это отразит. Но, если данные показывают нелинейную взаимосвязь (например, квадратичную), наличие отдельных групп значений или выбросов, то вычисленное значение коэффициента корреляции может ввести в заблуждение (см. файл примера ).
Корреляция близкая к 1 или -1 (т.е. близкая по модулю к 1) показывает сильную линейную взаимосвязь переменных, значение близкое к 0 показывает отсутствие взаимосвязи. Положительная корреляция означает, что с ростом одного показателя другой в среднем увеличивается, а при отрицательной – уменьшается.
Для вычисления коэффициента корреляции требуется, чтобы сопоставляемые переменные удовлетворяли следующим условиям:
- количество переменных должно быть равно двум;
- переменные должны быть количественными (например, частота, вес, цена). Вычисленное среднее значение этих переменных имеет понятный смысл: средняя цена или средний вес пациента. В отличие от количественных, качественные (номинальные) переменные принимают значения лишь из конечного набора категорий (например, пол или группа крови). Этим значениям условно сопоставлены числовые значения (например, женский пол – 1, а мужской – 2). Понятно, что в этом случае вычисление среднего значения , которое требуется для нахождения корреляции , некорректно, а значит некорректно и вычисление самой корреляции ;
- переменные должны быть случайными величинами и иметь нормальное распределение.
Двумерные данные могут иметь различную структуру. Для работы с некоторыми из них требуются определенные подходы:
- Для данных с нелинейной связью корреляцию нужно использовать с осторожностью. Для некоторых задач бывает полезно преобразовать одну или обе переменных так, чтобы получить линейную взаимосвязь (для этого требуется сделать предположение о виде нелинейной связи, чтобы предложить нужный тип преобразования).
- С помощью диаграммы рассеяния у некоторых данных можно наблюдать неравную вариацию (разброс). Проблема неодинаковой вариации состоит в том, что места с высокой вариацией не только предоставляют наименее точную информацию, но и оказывают наибольшее влияние при расчете статистических показателей. Эту проблему также часто решают с помощью преобразования данных, например, с помощью логарифмирования.
- У некоторых данных можно наблюдать разделение на группы (clustering), что может свидетельствовать о необходимости разделения совокупности на части.
- Выброс (резко отклоняющееся значение) может исказить вычисленное значение коэффициента корреляции. Выброс может быть причиной случайности, ошибки при сборе данных или могут действительно отражать некую особенность взаимосвязи. Так как выброс сильно отклоняется от среднего значения, то он вносит большой вклад при расчете показателя. Часто расчет статистических показателей производят с и без учета выбросов.
Использование MS EXCEL для расчета корреляции
В качестве примера возьмем 2 переменные Х и Y и, соответственно, выборку состоящую из нескольких пар значений (Х i ; Y i ). Для наглядности построим диаграмму рассеяния .

Примечание : Подробнее о построении диаграмм см. статью Основы построения диаграмм . В файле примера для построения диаграммы рассеяния использована диаграмма График , т.к. мы здесь отступили от требования случайности переменной Х (это упрощает генерацию различных типов взаимосвязей: построение трендов и заданный разброс). В случае реальных данных необходимо использовать диаграмму типа Точечная (см. ниже).
Расчеты корреляции проведем для различных случаев взаимосвязи между переменными: линейной, квадратичной и при отсутствии связи .
Примечание : В файле примера можно задать параметры линейного тренда (наклон, пересечение с осью Y) и степень разброса относительно этой линии тренда. Также можно настроить параметры квадратичной зависимости.
В файле примера для построения диаграммы рассеяния в случае отсутствия зависимости переменных использована диаграмма типа Точечная. В этом случае точки на диаграмме располагаются в виде облака.

Примечание : Обратите внимание, что изменяя масштаб диаграммы по вертикальной или горизонтальной оси, облаку точек можно придать вид вертикальной или горизонтальной линии. Понятно, что при этом переменные останутся независимыми.
Как было сказано выше, для расчета коэффициента корреляции в MS EXCEL существует функций КОРРЕЛ() . Также можно воспользоваться аналогичной функцией PEARSON() , которая возвращает тот же результат.
Для того, чтобы удостовериться, что вычисления корреляции производятся функцией КОРРЕЛ() по вышеуказанным формулам, в файле примера приведено вычисление корреляции с помощью более подробных формул:
Примечание : Квадрат коэффициента корреляции r равен коэффициенту детерминации R2, который вычисляется при построении линии регрессии с помощью функции КВПИРСОН() . Значение R2 также можно вывести на диаграмме рассеяния , построив линейный тренд с помощью стандартного функционала MS EXCEL (выделите диаграмму, выберите вкладку Макет , затем в группе Анализ нажмите кнопку Линия тренда и выберите Линейное приближение ). Подробнее о построении линии тренда см., например, в статье о методе наименьших квадратов .

Использование MS EXCEL для расчета ковариации
Ковариация близка по смыслу с дисперсией (также является мерой разброса) с тем отличием, что она определена для 2-х переменных, а дисперсия - для одной. Поэтому, cov(x;x)=VAR(x).

Для вычисления ковариации в MS EXCEL (начиная с версии 2010 года) используются функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() . В первом случае формула для вычисления аналогична вышеуказанной (окончание .Г обозначает Генеральная совокупность ), во втором – вместо множителя 1/n используется 1/(n-1), т.е. окончание .В обозначает Выборка .
Примечание : Функция КОВАР() , которая присутствует в MS EXCEL более ранних версий, аналогична функции КОВАРИАЦИЯ.Г() .
Примечание : Функции КОРРЕЛ() и КОВАР() в английской версии представлены как CORREL и COVAR. Функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() как COVARIANCE.P и COVARIANCE.S.
Дополнительные формулы для расчета ковариации :
Эти формулы используют свойство ковариации :

Если переменные x и y независимые, то их ковариация равна 0. Если переменные не являются независимыми, то дисперсия их суммы равна:
VAR(x+y)= VAR(x)+ VAR(y)+2COV(x;y)
А дисперсия их разности равна
VAR(x-y)= VAR(x)+ VAR(y)-2COV(x;y)
Оценка статистической значимости коэффициента корреляции
При проверке значимости коэффициента корреляции нулевая гипотеза состоит в том, что коэффициент корреляции равен нулю, альтернативная - не равен нулю (про проверку гипотез см. статью Проверка гипотез ).
Для того чтобы проверить гипотезу, мы должны знать распределение случайной величины, т.е. коэффициента корреляции r. Обычно, проверку гипотезы осуществляют не для r, а для случайной величины t r :

которая имеет распределение Стьюдента с n-2 степенями свободы.
Если вычисленное значение случайной величины |t r | больше, чем критическое значение t α,n-2 (α- заданный уровень значимости ), то нулевую гипотезу отклоняют (взаимосвязь величин является статистически значимой).

Надстройка Пакет анализа
В надстройке Пакет анализа для вычисления ковариации и корреляции имеются одноименные инструменты анализа .

После вызова инструмента появляется диалоговое окно, которое содержит следующие поля:

Надстройка возвращает вычисленные значения корреляции и ковариации (для ковариации также вычисляются дисперсии обоих случайных величин).
Excel – это эффективный инструмент для статистической обработки данных. И определение корреляций является очень важной составляющей этого процесса. Программа имеет весь необходимый инструментарий для осуществления расчетов такого плана. Сегодня мы более детально разберемся, что нам нужно для осуществления анализа этого типа.
Что представляет собой корреляционный анализ
Простыми словами, корреляция – это связь между двумя явлениями. В свою очередь, под корреляционным анализом подразумевают выявление этой связи. Очень частое утверждение гласит, что корреляция – это зависимость между разными объектами, но на деле это неточное определение. Ведь существует множество изображений, которые показывают связь между явлениями, которые никак не могут быть зависимы друг от друга или одного третьего фактора, который влияет на них.
Для определения зависимости используется другой тип анализа, который называется регрессионным.
Величина, определяющая степень выраженности взаимосвязи, называется коэффициентом корреляции. Это единственная величина, которая рассчитывается корреляционным анализом по сравнению с регрессионным. Возможные вариации коэффициента корреляции могут быть в пределах от -1 до 1. Если это число положительное, взаимосвязь между динамикой изменения значений прямая. Если же отрицательное, то увеличение числа 1 приводит к аналогичному уменьшению числа 2. Если число меньше единицы по модулю, то корреляция неполная. Например, увеличение числа 1 на единицу приводит к увеличению числа 2 на 0,5. В таком случае коэффициент корреляции составляет 0,5. Если же коэффициент корреляции составляет 0, то взаимосвязи между двумя переменными нет.
Интересный факт: корреляции делятся на истинные и ложные. То есть, иногда то, что графики идут в одинаковом направлении, может быть чистой случайностью, а не закономерным следствием воздействия одной переменной на другую или влияния общего фактора на обе переменные. В узких кругах довольно популярны картинки, где коррелируют между собой абсолютно не связанные явления. Вот некоторые примеры:
- Количество человек, которые стали утопленниками в бассейнах, четко коррелирует с количеством фильмов, в которых Николас Кейдж был актером.
- Количество съеденной моцареллы и количество человек, которые получили докторскую степень, также коррелирует на протяжении 2000-2009 годов. Наверно, действительно, моцарелла как-то влияет на мозг и стимулирует желание совершать научные открытия.
- Почти во всех случаях средний возраст женщин, которые получили статус «Мисс Америка» коррелирует с количеством людей, которые погибли от нахождения в горячем паре.
- Число людей, которое погибло в результате дорожно-транспортного происшествия, четко коррелирует с количеством сметаны, которое съедают люди.
- Мало кто знает, что чем больше курятины человек ест, тем больше сырой нефти импортируется в мире. Правда, это тоже пример ложной корреляции. Кстати, импорт сырой нефти родом из Норвегии тесно связано с количеством людей, которые погибли в результате столкновения автомобиля с поездом. Причем в этом случае корреляция почти 100 процентов.
- А еще маргарин негативно влияет на статистику разводов. Чем больше людей, которые проживали в штате Мэн, потребляли маргарина, тем выше была частота разводов. Правда, здесь еще может быть рациональное зерно. Ведь частота потребления маргарина имеет обратную корреляцию с экономическим положением в семье. В свою очередь, плохое экономическое положение в семье имеет непосредственную связь с количеством разводов. И это уже доказано научно. Так что кто знает, может, эта корреляция и не является такой ложной. Правда, никто этого не перепроверял.
- Количество денег, которое правительство США тратит на развитие науки, космоса и технологий, имеет тесную связь с количеством самоубийств, проведенных в форме повешения или удушения.
Ну и наконец, еще один пример ложной корреляции – чем больше сыра люди едят, тем больше людей умирает из-за того, что они запутываются в своих простынях.
Поэтому несмотря на то, что корреляция является эффективным статистическим инструментом, нужно учиться отфильтровывать истинные взаимосвязи между явлениями и ложные. Иначе исследование может получить такие интересные результаты. А теперь переходим непосредственно к тому, как проводить корреляционный анализ в Excel.
Вычисление коэффициента корреляции осуществляется двумя способами. Первый – это использование Мастера функций, который позволяет ввести формулу КОРРЕЛ. Второй инструмент – это пакет анализа, требующий отдельной активации.
Как рассчитать коэффициент корреляции
Давайте продемонстрируем механизм получения коэффициента корреляции на реальном кейсе. Допустим, у нас есть таблица с информацией о суммах продаж и рекламу. Нам нужно понять, в какой степени количество продаж и количество денег, которые были использованы на продвижение, взаимосвязаны.
Способ 1. Определение корреляции с помощью Мастера Функций
Функция КОРРЕЛ – один из самых простых методов, как можно реализовать поставленную задачу. В своем общем виде этот оператор имеет следующий вид: КОРРЕЛ(массив1;массив2). Как же ее ввести? Для этого нужно осуществлять следующие действия:
- С помощью левой кнопки мыши выделяем ту ячейку, в которой будет находиться получившийся коэффициент корреляции. После этого находим слева от строки формул кнопку fx, которая откроет инструмент ввода функций.
- Далее выбираем категорию «Полный алфавитный перечень», в котором ищем функцию КОРРЕЛ. Как видно из названия категории, все названия функций располагаются в алфавитном порядке.
- Далее открывается окно ввода параметров функции. У нас два основных аргумента, каждый из которых являет собой массив данных, которые сравниваются между собой. В поле «Массив 1» указываем координаты первого диапазона, а в поле «Массив 2» – адрес второго диапазона. Для ввода данных массива, используемого для расчета, достаточно выделить нажать левой кнопкой мыши по соответствующему полю и выделить правильный диапазон.
- После того, как мы введем данные в аргументы, нажимаем кнопку «ОК», чем подтверждаем совершенные действия.

После выполнения описанных выше шагов мы видим в ячейке, выбранной нами на первом этапе, коэффициент корреляции. В нашем примере он составляет 0,97, что указывает на очень сильно выраженную взаимосвязь между данными двух диапазонов.
Способ 2. Вычисление корреляции с помощью пакета анализа
Также довольно неплохой инструмент для определения корреляции между двумя диапазонами – пакет анализа. Но перед тем, как его использовать, нам надо его включить. Для этого выполняем следующие действия:

Все, теперь наша надстройка включена. Теперь мы во вкладке «Данные» можем увидеть кнопку «Анализ данных». Если она появилась, то мы все сделали правильно. Нажимаем на нее.

Появляется перечень с выбором разных способов анализа информации. Нам следует выбрать пункт «Корреляция» и нажать на «ОК».
Затем нам нужно ввести настройки. Основное отличие этого метода от предыдущего заключается в том, что нам нужно вводить полностью диапазон, а не разрывать его на две части. В нашем случае, это информация, указанная в двух столбцах «Затраты на рекламу» и «Величина продаж».
Не вносим никаких изменений в параметр «Группирование». По умолчанию выставлен пункт «По столбцам», и он правильный. Эта настройка определяет, каким образом программа будет разбивать данные. Если же наши данные были бы представлены в двух рядах, то надо было бы изменить этот пункт на «По строкам».
В настройках вывода уже стоит пункт «Новый рабочий лист». То есть, информация о корреляции будет располагаться на отдельном листе. Пользователь может настроить место самостоятельно с помощью соответствующего переключателя – на текущий лист или в отдельный файл. Проверяем, все ли настройки были введены правильно. Если да, подтверждаем свои действия нажатием на клавишу «ОК».


Поскольку мы оставили поле с данными о том, куда будут выводиться результаты, таким, каким оно было, мы переходим на новый лист. На нем можно найти коэффициент корреляции. Конечно, он такой же самый, как был в предыдущем методе – 0,97. Причина этого в том, что вычисления производятся одинаковые, исходные данные мы также не меняли. Просто разными методами, но не более.
Таким образом, Эксель дает сразу два метода осуществления корреляционного анализа. Как вы уже понимаете, в результате вычислений итог получится таким же. Но каждый пользователь может выбрать тот метод расчета, который ему больше всего подходит.
Как построить поле корреляции в Excel

Итак, давайте теперь разберемся, как построить поле корреляции. Для начала нужно разобраться, что это вообще такое. Под корреляционным полем подразумевается фактически график корреляции. Главное требование к такой диаграмме – каждая точка должна соответствовать единице совокупности. Поле корреляции поможет установить более глубокие связи и проанализировать данные более качественно. Для начала нам нужно найти коэффициент корреляции между двумя диапазонами, используя функцию КОРРЕЛ.
После того, как мы это сделали, мы теперь можем сделать поле корреляции. Для этого выполняем следующие действия:
Этот график можно построить не только на основе корреляции, определенной через функцию КОРРЕЛ.
Диаграмма рассеивания. Поле корреляции
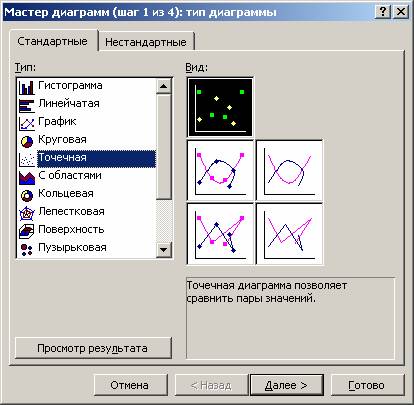
До сих пор часть пользователей сидит на старой версии Word. Как построить корреляционное поле в этом случае? Для этого существует специальный инструмент, который называется мастером диаграмм. Найти его можно на панели инструментов по специфическому изображению диаграммы. Если навести на эту иконку мышкой, то появится всплывающая подсказка, которая поможет нам убедиться в том, что это действительно мастер диаграмм.
После этого появится диалоговое окно, в котором нам надо выбрать точечный тип диаграммы. Видим, что логика действий в старых версиях офисного пакета в целом остается той же самой, просто немного другой интерфейс. Немного правее мы можем увидеть, как будет выглядеть точечная диаграмма и выбрать подходящий вид, а также прочитать описание этого типа диаграммы. После этого нажимаем на кнопку «Далее».
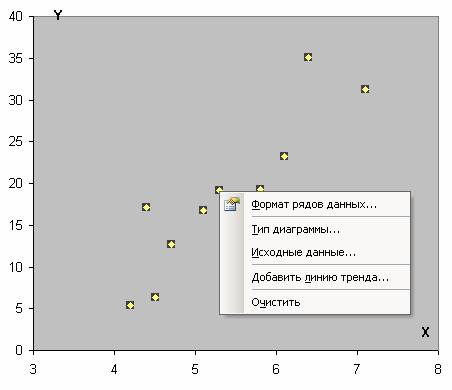
Затем выбираем диапазон данных, и наша линия появляется. После этого можно добавить линию регрессии к графику. Для этого необходимо сделать клик правой кнопкой мыши по одной из точек и в появившемся перечне найти «Добавить линию тренда» и сделать клик по этому пункту.
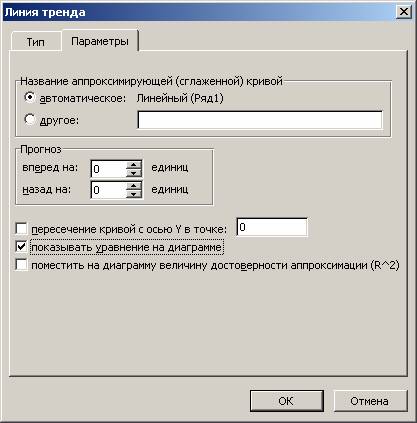
Далее выставляем настройки. Нас интересует тип «Линейная», а в окне параметров нужно поставить флажок «Показывать уравнение на диаграмме».
После подтверждения действий у нас появится что-то типа такого графика.
Как видим, возможных вариантов построения может быть огромное количество.
Читайте также: