
Как сделать анализ данных в ворде
Обновлено: 04.07.2024
В условиях недостатка времени на изучение такой темы, как “Базы данных”, для ознакомления учащихся с основными понятиями этой темы можно использовать текстовый редактор Microsoft Word. С этой целью может быть применена возможность редактора, которая называется “слияние данных”.
Напомним основные положения (см. также [1]). При проведении слияния задействованы две части: база данных и документ, а сама операция слияния как раз и позволяет объединить их (в документе используются данные из базы данных). Как правило, слияние применяется для оформления в документе текстового редактора писем, информация для которых (фамилии адресатов, их адреса и т.п.) хранится в базе данных. В статье [1] приведен ряд примеров использования слияния документов при решении задач “школьной” жизни. Возможны и другие примеры.
В простейшем случае в качестве базы данных можно использовать таблицу, оформленную в Microsoft Excel, в которой каждому полю соответствует отдельная колонка 1 .
Итак, пусть имеется лист электронной таблицы Microsoft Excel (см. рис. 1). На нем представлена информация об учениках школы: фамилия, имя, класс, пол и дата рождения, а также для каждого учащегося рассчитано число полных лет в его возрасте и определено, является ли он (она) именинником на текущей неделе. Этот лист и будем рассматривать как базу данных.
Сначала учащимся предлагается простое задание: в текстовом редакторе Microsoft Word напечатать список, скажем, 10а класса.
Задача решается следующим образом.
1. Открывается панель инструментов Слияние (Вид — Панели инструментов — Слияние).
2. Во вкладке Рассылки выбирается пункт Выбрать получателей — Использовать существующий список, после чего следует указать файл Excel со списком учеников (см. рис. 2), а в нем — соответствующий лист.
3. Выбираются (по одному) поля базы данных, которые будут использоваться в основном документе (нужные поля слияния). Для этого предназначена кнопка Вставить поля слияния (см. рис. 3 2 ). После вставки полей в документ между их именами нужно сделать необходимое число пробелов.
Если на этом и закончить работу, то будет отобран список всех учеников в таблице, причем на одном листе будут представлены фамилия, имя и обозначение класса лишь одного ученика. Поэтому для решения поставленной задачи надо воспользоваться фильтром — выбрать Изменить список получателей — Фильтр и в окне Фильтр и сортировка выбрать “Класс”, “равно” и “10а” (см. рис. 4).
4. Для объединения всех отобранных записей в одном документе необходимо выполнить команды Найти и объединить — Изменить отдельные документы — Объединить все.
5. Ну а для того, чтобы все фамилии были на одной странице, следует заменить разрыв раздела на знак абзаца по всему документу (см. рис. 5).
Конечный вид документа представлен на рис. 6.
Фактически мы только что продемонстрировали, как создать простейший запрос к базе данных.
После этого можно предложить ученикам самостоятельно выдать список всех, кто родился в текущем месяце, “невезучих”, родившихся 13-го числа, всех, кто родился в первой половине года, и т.п.
Можно также создавать запросы со сложными условиями. Например, получить список всех девочек, родившихся в феврале, или список всех Маш и Марий, список мальчиков для военкомата (тех, кому исполнилось 16 лет) и т.п.
Несколько более сложные запросы возникают, когда мы хотим получить, например, список всех мальчиков 7-х классов. Очень часто ученики не обращают внимания, что в графе (поле) “Класс” стоит обозначение класса с буквой. Это означает, что в фильтре запроса в списке Сравнение (см. рис. 4) необходимо использовать пункт “содержит”.
Думаем, читателям не составит труда придумать десяток-другой запросов к этой очень понятной базе данных.
Интересным аспектом предложенной методики является обсуждение с учащимися преобразования логических выражений (сложных условий). Рассмотрим следующий запрос: “Требуется выдать список девочек старших классов, у которых в поле “Имя” записано Лена или Елена”.
Здесь мы имеем четыре условия:
1) поле “Имя” равно “Лена” (обозначим его для краткости — Л);
2) поле “Имя” равно “Елена” (Е);
3) поле “Класс” содержит 10 (К10);
4) поле “Класс” содержит 11 (К11).
После обсуждения с учащимися общего условия для отбора значений в список можно получить такое:
(Л ИЛИ Е) И (К10 ИЛИ К11), причем именно со скобками, так как операция конъюнкции выполняется раньше, чем операция дизъюнкции. Однако при работе с фильтром (см. рис. 4) скобки расставить нельзя. Как же быть? Ответ такой — надо раскрыть скобки, не забывая, что конъюнкция (И) — это аналог умножения, а дизъюнкция (ИЛИ) — аналог сложения:
(Л ИЛИ Е) И (К10 ИЛИ К11) = Л И К10 ИЛИ Л И К11 ИЛИ Е И К10 ИЛИ Е И К11.
Таким образом, фильтр будет следующим: Имя равно Лена И Класс содержит 10 ИЛИ Имя равно Лена И Класс содержит 11 ИЛИ Имя равно Елена И Класс содержит 10 ИЛИ Имя равно Елена И Класс содержит 11. Фрагмент окна Фильтр и сортировка с таким условием 3 приведен на рис. 7.
Рис. 7. Фрагмент окна Фильтр и сортировка
Опыт показывает, что при применении описанной методики, во-первых, большинство учеников не испытывают особых трудностей в понимании того, что они должны сделать, а стало быть, осваивают основные понятия баз данных и технику создания запросов. Во-вторых, очевидной является и чисто практическая польза с точки зрения общей компьютерной грамотности.
1. Сенокосов А.И. Слияние документов как лучшее средство от головной боли. / Информатика, № 2/2006.
Примечание редакции. Как отмечалось, при описании методики автор использует версию Microsoft Word 2007. В предыдущих версиях редактора вид панели инструментов Слияние отличается от представленного в статье. В таких версиях:
1) для выбора файла Excel со списком учеников в качестве источника данных следует использовать кнопку (Открыть источник данных);
2) для вставки в документ нужных полей слияния предназначена кнопка (Вставить поля слияния);
3) для отображения имен полей или отобранных значений используется кнопка (Поля/данные);
4) окно Фильтр и сортировка вызывается с помощью кнопки (Получатели). После этого надо щелкнуть на стрелке () рядом с надписью на заголовке столбца и выбрать пункт Дополнительно;
5) объединить все отобранные записи в одном документе можно с помощью кнопки (Слияние в новый документ);
6) замена разрыва раздела на знак абзаца по всему документу осуществляется “обычными” средствами Word (Правка — Заменить, с использованием специальных символов).
1 При создании этой таблицы целесообразно ознакомить учащихся с такими понятиями, как “база данных”, “поле”, “запись” и “запрос”. — Прим. ред.
2 Автор использует версию редактора Word 2007. — Прим. ред.
3 В окне условие представлено не полностью (используется вертикальная полоса прокрутки). — Прим. ред.
Если вы хотите узнать о больших объемах данных , которые есть на вашем сайте или доступны в другом месте, Excel дает вам мощные инструменты.
Советы, которые следует прочитать до начала работы
Позвольте приложению Excel выбрать для вас сводную таблицу Чтобы быстро отбирать данные, которые вы хотите проанализировать в Excel, сначала нужно выбрать с помощью макета Excel для ваших данных.
Анализ данных в нескольких таблицах Вы можете анализировать данные из двух таблиц в отчете Excel, даже если не используете Power Pivot. Функция модели данных встроена в Excel. Просто добавьте данные в несколько таблиц в Excel а затем создайте связи между ними на листе или в таблице Power View. Готово! Теперь у вас есть модель данных, которая добавляет больше энергии для анализа данных.
Наносите данные непосредственно на интерактивную сводную диаграмму В Excel можно создать автономный (автономный) сводная диаграмма, который позволяет взаимодействовать с данными и фильтровать их прямо на диаграмме.
Полный обзор полноте Power Pivot и Power View Если у вас установлен Office профессиональный плюс, воспользуйтесь преимуществами этих полезных надстроек:
Встроенной модели данных может быть достаточно для анализа содержимого нескольких таблиц, однако Power Pivot позволяет создать более сложную модель в отдельном окне Power Pivot. Прежде чем приступать к работе, ознакомьтесь с различиями.
Надстройка Power View позволяет превратить данные Power Pivot (или любую другую информацию в таблице Excel) в многофункциональный интерактивный отчет, имеющий профессиональный вид. Чтобы начать, просто нажмите кнопку Power View на вкладке Вставка.
Создание или создание сводная диаграмма
Принимайте более обоснованные бизнес-решения на основе данных в отчетах сводных таблиц, на которые можно взглянуть под разным углом. Excel поможет вам приступить к работе, порекомендовав модель, оптимальную для имеющихся данных.
Если данные, которые требуется обработать, хранятся в другом файле за пределами Excel (например, в базе данных Access или в файле куба OLAP), вы можете подключиться к этому источнику внешних данных и проанализировать их в отчете сводной таблицы.
Если вы хотите проанализировать данные в нескольких таблицах, это можно сделать в Excel. Узнайте о различных способах создания связей между несколькими таблицами в отчете таблицы для мощного анализа данных. В этом Excel создается модель данных.
Прежде чем приступать к самостоятельной работе, воспользуйтесь инструкциями, приведенными в этом учебнике. Они помогут вам создать в Excel учебную сводную таблицу, которая объединяет информацию из нескольких таблиц в общую модель данных.
Создав сводную таблицу на основе данных листа, внешних данных или информации из нескольких таблиц, воспользуйтесь списком полей, который позволяет добавлять, упорядочивать и удалять поля в отчете сводной таблицы.
Чтобы провести наглядную презентацию, создайте сводную диаграмму с интерактивными элементами фильтрации, позволяющими анализировать отдельные подмножества исходных данных. Приложение Excel даже может порекомендовать вам подходящую сводную диаграмму. Если вам необходима просто интерактивная диаграмма, создавать для этого сводную таблицу не требуется.
Если требуется удалить сводную таблицу, перед нажатием клавиши DELETE необходимо выделить всю таблицу, которая может содержать довольно много данных. В этой статье рассказывается, как быстро выделить всю сводную таблицу.
Изменение формата вашей скайп-формы
После создания сводной таблицы и добавления в нее полей можно изменить макет данных, чтобы информацию было удобнее просматривать и изучать. Чтобы мгновенно сменить макет данных, достаточно выбрать другой макет отчета.
Если вам не нравится, как выглядит созданная вами сводная таблица, попробуйте выбрать другой стиль. Например, если в ней много данных, лучше включить чередование строк или столбцов, чтобы информацию было проще просматривать, либо выделить важные сведения.
Отображение сведений сводной таблицы
Сортировка помогает упорядочивать большие объемы данных в сводных таблицах, чтобы упростить поиск объектов анализа. Данные можно отсортировать в алфавитном порядке, по убыванию или возрастанию.
Чтобы провести более подробный анализ определенного подмножества исходных данных сводной таблицы, их можно отфильтровать. Сделать это можно несколькими способами. Например, можно добавить один или несколько срезов, которые позволяют быстро и эффективно фильтровать информацию.
Группировка позволяет выделить для анализа определенное подмножество данных сводной таблицы.
Переход на разные уровни при больших объемах данных в иерархии сводной таблицы всегда занимал много времени, включая многочисленные операции развертывания, свертывания и фильтрации.
В Excel новая функция "Быстрое изучение" позволяет детализтировать данные в кубе OLAP или иерархии на основе модели данных для анализа данных на разных уровнях. Эта функция позволяет переходить к нужным сведениям и действует как фильтр при их детализации. Соответствующая кнопка отображается при выборе элемента в поле.
Вместо создания фильтров для отображения данных в сводной таблице теперь можно воспользоваться временной шкалой. Ее можно добавить в сводную таблицу, а затем с ее помощью осуществлять фильтрацию по времени и переходить к различным периодам.
Расчет значений сводной таблицы
Промежуточные итоги в сводных таблицах вычисляются автоматически и отображаются по умолчанию. Если итогов не видно, их можно добавить.
Для сведения данных в сводных таблицах предназначены функции расчета суммы, количества и среднего значения. Функции сведения недоступны в сводных таблицах на базе источников данных OLAP.
Изменение и обновление данных сводной таблицы
После создания сводной таблицы может потребоваться изменить исходные данные для анализа (например, добавить или исключить те или иные сведения).
Если сводная таблица подключена к внешним данным, ее необходимо периодически обновлять, чтобы информация в таблице оставалась актуальной.
Использование богатых возможностей Power Pivot
Если у вас уже Office профессиональный плюс, запустите надстройку Power Pivot, которая поставляется вместе с Excel для проведения мощного анализа данных. После этого вы сможете создавать сложные модели данных в окне Power Pivot.
В этом учебнике рассказано, как импортировать сразу несколько таблиц с данными. Во второй его части описывается работа с моделью данных в окне Power Pivot.
Вместо импорта данных или подключения к ним в Excel можно воспользоваться быстрой и эффективной альтернативой: импортом реляционных данных в окне Power Pivot.
Расширить возможности анализа данных помогают связи между таблицами, которые содержат сходную информацию (например, одинаковые поля с идентификаторами). Связи позволяют создавать отчеты сводных таблиц, использующие поля из каждой таблицы, даже если они происходят из разных источников.
Для решения задач, связанных с анализом и моделированием данных в Power Pivot, можно использовать возможности вычисления, такие как функция автосуммирования, вычисляемые столбцы и формулы вычисляемых полей, а также настраиваемые формулы на языке выражений анализа данных (DAX).
С помощью Power Pivot можно создавать ключевые показатели эффективности и добавлять их в сводные таблицы.
В этом учебнике показано, как вносить изменения в модель данных для улучшения отчетов Power View.
Анализ данных с помощью Power View
Надстройка Power View, которая входит в состав Office профессиональный плюс, позволяет создавать интерактивные диаграммы и другие наглядные объекты на отдельных листах Power View, напоминающих панели мониторинга, которые можно представить всем заинтересованным лицам.
В конце учебника Импорт данных в Excel и Создание модели данных вынайдете полезные инструкции по оптимизации Power Pivot данных для Power View.
Из этих видеороликов вы узнаете, каких результатов можно добиться с помощью надстройки Power View, функции которой дополняются возможностями Power Pivot.
Создание сводной таблицы для анализа данных на листе Принимайте более обоснованные бизнес-решения на основе данных в отчетах сводных таблиц, на которые можно взглянуть под разным углом. Excel поможет вам приступить к работе, порекомендовав модель, оптимальную для имеющихся данных.
Создание сводной диаграммы Чтобы провести наглядную презентацию, создайте сводную диаграмму с интерактивными элементами фильтрации, позволяющими анализировать отдельные подмножества исходных данных. Приложение Excel даже может порекомендовать вам подходящую сводную диаграмму. Если вам необходима просто интерактивная диаграмма, создавать для этого сводную таблицу не требуется.
Сортировка данных в сводной таблице Сортировка помогает упорядочивать большие объемы данных в сводных таблицах, чтобы упростить поиск объектов анализа. Данные можно отсортировать в алфавитном порядке, по убыванию или возрастанию.
Фильтрация данных в сводной таблице Чтобы провести более подробный анализ определенного подмножества исходных данных сводной таблицы, их можно отфильтровать. Сделать это можно несколькими способами. Например, можно добавить один или несколько срезов, которые позволяют быстро и эффективно фильтровать информацию.
Создание временной шкалы сводной таблицы для фильтрации дат Вместо создания фильтров для отображения данных в сводной таблице теперь можно воспользоваться временной шкалой. Ее можно добавить в сводную таблицу, а затем с ее помощью осуществлять фильтрацию по времени и переходить к различным периодам.
Показ и скрытие подытогов в pivotTable Промежуточные итоги в сводных таблицах вычисляются автоматически и отображаются по умолчанию. Если итогов не видно, их можно добавить.
Использование внешнего источника данных для использования в совописной После создания сводной таблицы может потребоваться изменить исходные данные для анализа (например, добавить или исключить те или иные сведения).
Базовый инструмент для работы с огромным количеством неструктурированных данных, из которых можно быстро сделать выводы и не возиться с фильтрацией и сортировкой вручную. Сводные таблицы можно создать с помощью нескольких действий и быстро настроить в зависимости от того, как именно вы хотите отобразить результаты.
Полезное дополнение. Вы также можете создавать сводные диаграммы на основе сводных таблиц, которые будут автоматически обновляться при их изменении. Это полезно, если вам, например, нужно регулярно создавать отчёты по одним и тем же параметрам.
Как работать
Исходные данные могут быть любыми: данные по продажам, отгрузкам, доставкам и так далее.
- Откройте файл с таблицей, данные которой надо проанализировать.
- Выделите диапазон данных для анализа.
- Перейдите на вкладку «Вставка» → «Таблица» → «Сводная таблица» (для macOS на вкладке «Данные» в группе «Анализ»).
- Должно появиться диалоговое окно «Создание сводной таблицы».
- Настройте отображение данных, которые есть у вас в таблице.
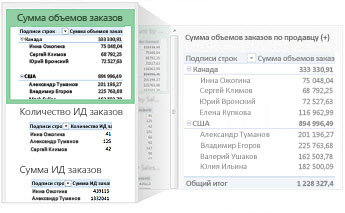
Перед нами таблица с неструктурированными данными. Мы можем их систематизировать и настроить отображение тех данных, которые есть у нас в таблице. «Сумму заказов» отправляем в «Значения», а «Продавцов», «Дату продажи» — в «Строки». По данным разных продавцов за разные годы тут же посчитались суммы. При необходимости можно развернуть каждый год, квартал или месяц — получим более детальную информацию за конкретный период.
Набор опций будет зависеть от количества столбцов. Например, у нас пять столбцов. Их нужно просто правильно расположить и выбрать, что мы хотим показать. Скажем, сумму.
Можно её детализировать, например, по странам. Переносим «Страны».
Можно посмотреть результаты по продавцам. Меняем «Страну» на «Продавцов». По продавцам результаты будут такие.
2. 3D-карты
Этот способ визуализации данных с географической привязкой позволяет анализировать данные, находить закономерности, имеющие региональное происхождение.
Полезное дополнение. Координаты нигде прописывать не нужно — достаточно лишь корректно указать географическое название в таблице.
Как работать
- Откройте файл с таблицей, данные которой нужно визуализировать. Например, с информацией по разным городам и странам.
- Подготовьте данные для отображения на карте: «Главная» → «Форматировать как таблицу».
- Выделите диапазон данных для анализа.
- На вкладке «Вставка» есть кнопка 3D-карта.
Точки на карте — это наши города. Но просто города нам не очень интересны — интересно увидеть информацию, привязанную к этим городам. Например, суммы, которые можно отобразить через высоту столбика. При наведении курсора на столбик показывается сумма.
Также достаточно информативной является круговая диаграмма по годам. Размер круга задаётся суммой.
3. Лист прогнозов
Зачастую в бизнес-процессах наблюдаются сезонные закономерности, которые необходимо учитывать при планировании. Лист прогноза — наиболее точный инструмент для прогнозирования в Excel, чем все функции, которые были до этого и есть сейчас. Его можно использовать для планирования деятельности коммерческих, финансовых, маркетинговых и других служб.
Полезное дополнение. Для расчёта прогноза потребуются данные за более ранние периоды. Точность прогнозирования зависит от количества данных по периодам — лучше не меньше, чем за год. Вам требуются одинаковые интервалы между точками данных (например, месяц или равное количество дней).
Как работать
- Откройте таблицу с данными за период и соответствующими ему показателями, например, от года.
- Выделите два ряда данных.
- На вкладке «Данные» в группе нажмите кнопку «Лист прогноза».
- В окне «Создание листа прогноза» выберите график или гистограмму для визуального представления прогноза.
- Выберите дату окончания прогноза.
В примере ниже у нас есть данные за 2011, 2012 и 2013 годы. Важно указывать не числа, а именно временные периоды (то есть не 5 марта 2013 года, а март 2013-го).
Для прогноза на 2014 год вам потребуются два ряда данных: даты и соответствующие им значения показателей. Выделяем оба ряда данных.
На вкладке «Данные» в группе «Прогноз» нажимаем на «Лист прогноза». В появившемся окне «Создание листа прогноза» выбираем формат представления прогноза — график или гистограмму. В поле «Завершение прогноза» выбираем дату окончания, а затем нажимаем кнопку «Создать». Оранжевая линия — это и есть прогноз.
4. Быстрый анализ
Эта функциональность, пожалуй, первый шаг к тому, что можно назвать бизнес-анализом. Приятно, что эта функциональность реализована наиболее дружественным по отношению к пользователю способом: желаемый результат достигается буквально в несколько кликов. Ничего не нужно считать, не надо записывать никаких формул. Достаточно выделить нужный диапазон и выбрать, какой результат вы хотите получить.
Полезное дополнение. Мгновенно можно создавать различные типы диаграмм или спарклайны (микрографики прямо в ячейке).
Как работать
- Откройте таблицу с данными для анализа.
- Выделите нужный для анализа диапазон.
- При выделении диапазона внизу всегда появляется кнопка «Быстрый анализ». Она сразу предлагает совершить с данными несколько возможных действий. Например, найти итоги. Мы можем узнать суммы, они проставляются внизу.
В быстром анализе также есть несколько вариантов форматирования. Посмотреть, какие значения больше, а какие меньше, можно в самих ячейках гистограммы.
Также можно проставить в ячейках разноцветные значки: зелёные — наибольшие значения, красные — наименьшие.
Надеемся, что эти приёмы помогут ускорить работу с анализом данных в Microsoft Excel и быстрее покорить вершины этого сложного, но такого полезного с точки зрения работы с цифрами приложения.
В своей работе мы часто анализируем большой объем данных. Давайте рассмотрим, как можно автоматизировать процесс анализа документов на примере библиотеки docx (способной обрабатывать документы в формате. docx).
А также расскажем другие возможности, которые предлагает Python: как отделить текст с нужным стилем форматирования? Как извлечь все изображения из документа?
Для установки библиотеки в командной строке необходимо ввести:
После успешной установки библиотеки, её нужно импортировать в Python. Обратите внимание, что несмотря на то, что для установки использовалось название python-docx, при импорте следует называть библиотеку docx:
Как правило, мы обращаемся к автоматизации, когда нам нужно извлечь нужную информацию не из одного, а сразу из многих документов. Чтобы иметь возможность обработать все документы, для начала нужно собрать список таких документов. Здесь сможет помочь библиотека os, с помощью которой можно рекурсивно обойти директории, в которых хранятся документы. Предположим, что все они находятся внутри директории, где расположен скрипт:
import os paths = [] folder = os.getcwd() for root, dirs, files in os.walk(folder): for file in files: if file.endswith('docx') and not file.startswith('Мы прошли по всем директориям и занесли в список paths все файлы с расширением. docx. Файлы, начинавшиеся с тильды, игнорировались (эти временные файлы возникают лишь тогда, когда в Windows открыт какой-либо из документов). Теперь, когда у нас уже есть список всех документов, можно начинать с ними работать:
В блоке выше на каждом шаге цикла в переменную doc записывается экземпляр, представляющий собой весь документ. Мы можем посмотреть основные свойства такого документа:
properties = doc.core_properties print('Автор документа:', properties.author) print('Автор последней правки:', properties.last_modified_by) print('Дата создания документа:', properties.created) print('Дата последней правки:', properties.modified) print('Дата последней печати:', properties.last_printed) print('Количество сохранений:', properties.revision)Из основных свойств можно получить автора документа, основные даты, количество сохранений документа и пр. Обратите внимание, что даты и время будут указаны в часовом поясе UTC+0.
Теперь поговорим о том, как можно проанализировать содержимое документа. Файлы с расширением docx обладают развитой внутренней структурой, которая в библиотеке docx представлена следующими объектами:
Объект Document, представляющий собой весь документ
- Список объектов Paragraph – абзацы документа
* Список объектов Run – фрагменты текста с различными стилями форматирования (курсив, цвет шрифта и т.п.)
- Список объектов Table – таблицы документа
* Список объектов Row – строки таблицы
* Список объектов Cell – ячейки в строке
* Список объектов Column – столбцы таблицы
* Список объектов Cell – ячейки в столбце
- Список объектов InlineShape – иллюстрации документа
Работа с текстом документа
Для начала давайте разберёмся, как работать с текстом документа. В библиотеке docx это возможно через обращение к абзацам документа. Можно получить как сам текст абзаца, так и его характеристики: тип выравнивания, величину отступов и интервалов, положение на странице.
Очень часто стоит задача получить весь текст из документа для дальнейшей обработки. Чтобы это сделать, достаточно лишь перебрать все абзацы документа:
text = [] for paragraph in doc.paragraphs: text.append(paragraph.text) print('\n'.join(text))Как мы видим, для получения текста абзаца нужно просто обратиться к объекту paragraph.text. Но что же делать, если нужно извлечь только абзацы с определёнными характеристиками и далее работать именно с ними? Рассмотрим основные характеристики абзацев, которые можно проанализировать.
В первую очередь, можно получить стиль выравнивания абзацев в документе:
for paragraph in doc.paragraphs: print('Выравнивание абзаца:', paragraph.alignment)Значения alignment будут соответствовать одному из основных стилей выравнивания: LEFT (0), center (1), RIGHT (2) или justify (3). Однако если пользователь не установил стиль выравнивания, значение параметра alignment будет None.
Кроме того, можно получить и значения отступов у абзацев документа:
for paragraph in doc.paragraphs: formatting = paragraph.paragraph_format print('Отступ перед абзацем:', formatting.space_before) print('Отступ после абзаца:', formatting.space_after) print('Отступ слева:', formatting.left_indent) print('Отступ справа:', formatting.right_indent) print('Отступ первой строки абзаца:', formatting.first_line_indent)Как и в предыдущем примере, если отступы не были установлены, значения параметров будут None. В остальных случаях они будут представлены в виде целого числа в формате EMU (английские метрические единицы). Этот формат позволяет конвертировать число как в метрическую, так и в английскую систему мер. Привести полученные числа в привычный формат довольно просто, достаточно просто добавить нужные единицы исчисления после параметра (например, formatting.space_before.cm или formatting.space_before.pt). Главное помнить, что такое преобразование нельзя применять к значениям None.
Наконец, можно посмотреть на положение абзаца на странице. В меню Абзац… на вкладке Положение на странице находятся четыре параметра, значения которых также можно посмотреть при помощи библиотеки docx:
for paragraph in doc.paragraphs: formatting = paragraph.paragraph_format print('Не отрывать от следующего абзаца:', formatting.keep_with_next) print('Не разрывать абзац:', formatting.keep_together) print('Абзац с новой страницы:', formatting.page_break_before) print('Запрет висячих строк:', formatting.widow_control)Параметры будут иметь значение None для случаев, когда пользователь не устанавливал на них галочки, и True, если устанавливал.
Мы рассмотрели основные способы, которыми можно проанализировать абзац в документе. Но бывают ситуации, когда мы точно знаем, что информация, которую нужно извлечь, написана курсивом или выделена определённым цветом. Как быть в таком случае?
Можно получить список фрагментов с различными стилями форматирования (список объектов Run). Попробуем, к примеру, извлечь все фрагменты, написанные курсивом:
Очень просто, не так ли? Посмотрим, какие ещё стили форматирования можно извлечь:
Если пользователь не менял стиль форматирования (отсутствует подчёркивание, используется стандартный шрифт и т.п.), параметры будут иметь значение None. Но если стиль определённого параметра изменялся, то:
- параметры italic, bold, underline, strike будут иметь значение True;
- параметр font.name – наименование шрифта;
- параметр font.color.rgb – код цвета текста в RGB;
- параметр font.highlight_color – наименование цвета заливки текста.
Делая цикл по фрагментам стоит иметь ввиду, что фрагменты с одинаковым форматированием могут быть разбиты на несколько, если в них встречаются символы разных типов (буквенные символы и цифры, кириллица и латиница).
Абзацы и их фрагменты могут быть оформлены в определённом стиле, соответствующем стилям Word (например, Normal, Heading 1, Intense Quote). Чем это может быть полезно? К примеру, обращение к стилям абзаца может пригодиться при выделении нумерованных или маркированных списков. Каждый элемент таких списков считается отдельным абзацев, однако каждому из них приписан особый стиль – List Paragraph. С помощью кода ниже можно извлечь только элементы списков:
for paragraph in doc.paragraphs: if paragraph.style.name == 'List Paragraph': print(paragraph.text)Чтобы закрепить полученные знания, давайте разберём менее тривиальный случай. Предположим, что у нас есть множество документов с похожей структурой, из которых нужно извлечь названия продуктов. Проанализировав документы, мы установили, что продукты встречаются только в абзацах, начинающихся с новой страницы и выровненных по ширине. Притом сами названия написаны с использованием полужирного начертания, шрифт Arial Narrow. Посмотрим, как можно проанализировать документы:
В блоке кода выше последовательно обрабатываются все файлы из списка paths, преобразовываемые в ходе обработки в объект Document. В каждом документе происходит перебор абзацев и выполняются проверки: абзац должен начинаться с новой страницы и быть выровненным по ширине. Если проверки прошли успешно, внутри абзаца происходит уже перебор фрагментов с различными типами форматированием и проверки на начертание и шрифт.
Обратим внимание на переменную is_sequential, которая помогает определить, идут ли фрагменты, прошедшие проверку, друг за другом. Фрагменты с символами разных типов (буквы и числа, кириллица и латиница) разбиваются на несколько, но поскольку в названии продукта одновременно могут встретиться символы всех типов, все последовательно идущие фрагменты соединяются в один. Он и заносится в результирующий список product_names.
Работа с таблицами
Мы рассмотрели способы, которыми можно обрабатывать текст в документах, а теперь давайте перейдём к обработке таблиц. Любую таблицу можно перебирать как по строкам, так и по столбцам. Посмотрим, как можно построчно получить текст каждой ячейки в таблице:
for table in doc.tables: for row in table.rows: for cell in row.cells: print(cell.text)Если же во второй строке заменить rows на columns, то можно будет аналогичным образом прочитать таблицу по столбцам. Текст в ячейках таблицы тоже состоит из абзацев. Если мы захотим проанализировать абзацы или фрагменты внутри ячейки, то можно будет воспользоваться всеми методами объектов Paragraph и Run.
Часто может понадобиться проанализировать только таблицы, содержащие определённые заголовки. Попробуем, например, выделить из документа только таблицы, у которых в строке заголовка присутствуют названия Продукт и Стоимость. Для таких таблиц построчно распечатаем все значения из ячеек:
for table in doc.tables: for index, row in enumerate(table.rows): if index == 0: row_text = list(cell.text for cell in row.cells) if 'Продукт' not in row_text or 'Стоимость' not in row_text: break for cell in row.cells: print(cell.text)Также нам может понадобиться определить, какие из ячеек в таблице являются объединёнными. Стандартной функции для этого нет, однако мы можем воспользоваться тем, что нам доступно положение ячейки от каждого из краев таблицы:
for table in doc.tables: unique, merged = set(), set() for row in table.rows: for cell in row.cells: tc = cell._tc cell_loc = (tc.top, tc.bottom, tc.left, tc.right) if cell_loc in unique: merged.add(cell_loc) else: unique.add(cell_loc) print(merged)Воспользовавшись этим кодом, можно получить все координаты объединённых ячеек для каждой из таблиц документа. Кроме того, разница координат tc.top и tc.bottom показывает, сколько строк в объединённой ячейке, а разница tc.left и tc.right – сколько столбцов.
Наконец, рассмотрим возможность выделения из таблиц ячеек, в которых фон окрашен в определённый цвет. Для этого понадобится с помощью регулярных выражений посмотреть на xml-код ячейки:
Работа с иллюстрациями
В библиотеке docx также реализована возможность работы с иллюстрациями документа. Стандартными способами можно посмотреть только на размеры изображений:
for shape in doc.inline_shapes: print(shape.width, shape.height)Однако при помощи сторонней библиотеки docx2txt и анализа xml-кода абзацев становится возможным не только выгрузить все иллюстрации документов, но и определить, в каком именно абзаце они встречались:
import os import docx import docx2txt for path in paths: splitted = os.path.split(path) folders = [os.path.splitext(splitted[1])[0]] while splitted[0]: splitted = os.path.split(splitted[0]) folders.insert(0, splitted[1]) images_path = os.path.join('images', *folders) os.makedirs(images_path, exist_ok=True) doc = docx.Document(path) docx2txt.process(path, images_path) rels = <> for rel in doc.part.rels.values(): if isinstance(rel._target, docx.parts.image.ImagePart): rels[rel.rId] = os.path.basename(rel._target.partname) for paragraph in doc.paragraphs: if 'Graphic' in paragraph._p.xml: for rId in rels: if rId in paragraph._p.xml: print(os.path.join(images_path, rels[rId])) print(paragraph.text)В этом блоке мы выводим путь к изображению, которое сохранено на диске, и текст параграфа, в котором встретилось изображение. Все изображения находятся внутри директории images, а именно — в поддиректориях, соответствующих расположению исходного файла Word.
Читайте также: