
Математические модели описания статистических характеристик ошибок в программах
Обновлено: 07.07.2024
В общем случае под программной ошибкой подразумевается непредвиденное искажение работы программы, причем исходными эталонами для любого ПО являются спецификации требований заказчика, предъявляемых к сопровождаемым программам. Подобные документы устанавливают состав, содержание и значения результатов, которые должен получать пользователь при определенных условиях и исходных данных. Любое отклонение результатов функционирования программы от предъявляемых к ней требований и сформированных по ним эталонов-тестов следует квалифицировать как ошибку в программе, наносящую некоторый ущерб.
Источниками ошибок в работе сложных программных комплексов (СПК) могут быть и сами программисты с их индивидуальными особенностями, квалификацией, талантом и опытом.
Анализируя характеристики модификаций СПК, связанные с достижением корректности, безопасности и надежности их функционирования, можно:
· оценивать реальное состояние проекта, планировать трудоемкость и сроки его завершения;
· выбирать наиболее эффективные методы и средства устранения определенных видов дефектов, адекватные текущему состоянию СПК;
· выбирать средства защиты от потенциальных дефектов и ошибок;
· оценивать требуемые ресурсы ПЭВМ по расширению памяти и производительности с учетом затрат на реализацию контрмер при модификации и устранении ошибок.
Важной особенностью процесса выявления ошибок в программах является отсутствие полностью определенной программы-эталона, которой должны соответствовать текст и результаты функционирования разрабатываемой программы. Поэтому установить наличие и локализовать дефект непосредственным сравнением с программой без ошибок в большинстве случаев невозможно.
По уровням ошибки подразделяют на:
Последние, так называемые ошибки с высоким влиянием, останавливают выпуск версии программного продукта.
Различия интенсивностей устранения первичных ошибок на основе их вторичных проявлений и внесения первичных ошибок при корректировках программ определяют скорость достижения заданного качества модификаций версий ПО.
Первичные ошибки в программах проектов можно анализировать с разной степенью детализации и в зависимости от различных факторов.
Практический опыт показал, что наиболее существенными факторами, влияющими на характеристики обнаруживаемых ошибок, являются:
· методология, технология и уровень автоматизации системного и структурного проектирования СПК и программирования ее компонентов;
· длительность отладки сопровождения и модификации СПК;
· класс СПК, размер и типы компонентов, в которых обнаруживаются ошибки;
· методы, виды и уровень автоматизации тестирования, их адекватность характеристикам отлаживаемых компонентов и имеющимся в них ошибкам;
· достоверность эталонов, которые используются для обнаружения ошибок.
Первичные ошибки в ПО в порядке уменьшения их влияния на сложность обнаружения и масштабы корректировок можно подразделить на следующие группы:
· ошибки вследствие большого масштаба — размера СПК и высоких требований к его качеству;
· ошибки планирования и корректности требований модификаций СПК;
· ошибки проектирования СПК;
· системные ошибки из-за отклонений функционирования модулей в составе СПК от предполагавшегося функционирования при их проектировании;
· алгоритмические ошибки, связанные с неполной и (или) некорректной постановкой задач модификаций СПК;
· ошибки в документации и технологические ошибки подготовки физических носителей, ввода программ в память ЭВМ и вывода результатов на средства отображения.
Небольшими ошибками называют такие, на которые средний пользователь не обратит внимания при применении программного продукта вследствие отсутствия их проявления и последствия которых обычно так и не обнаруживаются. По десятибалльной шкале рисков небольшие ошибки находятся в пределах от 1-го до 3-го приоритета.
Умеренные ошибки влияют на конечного пользователя, но имеются слабые последствия или обходные пути, позволяющие сохранить достаточную функциональность программного продукта. По десятибалльной шкале умеренные ошибки находятся в диапазоне от 4-го до 7-го приоритета.
Критические ошибки имеют уровень приоритета 10.
Какие математические модели ошибок ПО вам известны?
Модели имеют вероятностный характер, и достоверность прогнозов в значительной степени зависит от точности исходных данных и глубины прогнозирования по времени. Эти математические модели предназначены для оценки:
· надежности работы ПО в процессе отладки, испытаний и эксплуатации;
· числа ошибок, оставшихся не выявленными в анализируемых программах;
· времени, требующегося для обнаружения следующей ошибки в функционирующей программе;
· времени, необходимого для поиска всех ошибок с заданной вероятностью.
· суммарным числом первичных ошибок в комплексе программ (n0) или вероятностью ошибки в каждой команде программы (p0);
Наиболее доступно для измерения количество вторичных ошибок в программе, выявляемых в единицу времени в процессе отладки. Известны несколько математических моделей, основой которых являются различные гипотезы о характере проявления вторичных ошибок в программах. Эти гипотезы в той или иной степени апробированы при обработке данных реальных разработок, и их можно подразделить на три группы.
В первую группу входят очевидные допущения, статистическая проверка которых невозможна и нецелесообразна. Эта группа включает в себя предположение о наблюдаемости искажений данных, программ или вычислительного процесса, обусловленных первичными ошибками в программах. Вторую группу составляют допущения, определяющие специфические характеристики модели и требующие статистической проверки и обоснования на базе экспериментальных исследований. В третью группу включены второстепенные допущения, расширяющие и уточняющие возможности применения модели и частично доступные экспериментальной проверке.
Вторая группа допущений при построении математических моделей ошибок является основной и проверена интегрально по обобщенным характеристикам частности обнаружения ошибок и дифференцирование путем анализа правомерности каждого допущения.
Интервалы времени между обнаруживаемыми искажениями результатов предполагаются статистически независимыми. Время измеряется по фактической наработке длительностей исполнения программ без учета дополнительных затрат календарного времени на локализацию, диагностику и исправление ошибок.
Каждая обнаруженная ошибка подлежит исправлению, поэтому предполагается, что частота исправления ошибок пропорциональна частоте их обнаружения. Однако некоторые исправления, в свою очередь, содержат ошибки. Кроме того, некоторые ошибки являются связанными, и при обнаружении проявления одной ошибки следует исправление нескольких первичных ошибок. Из-за этого частота обнаружения ошибок и частота их исправления не равны, а должны быть связаны некоторым коэффициентом пропорциональности. Коэффициенты корреляции для исследованных комплексов программ довольно высокие — от 0,52 до 0,82 при среднем значении около 0,68, т. е. достаточно хорошо подтверждают гипотезу.
Третья группа допущений детализирует использование ресурсов на корректировку программ и повышение их качества.
Таким образом, интенсивность обнаружения ошибок в программе и абсолютное число устраненных первичных ошибок связываются уравнением.
Наработка между проявлениями ошибок, которые рассматриваются как обнаруживаемые искажения программ, данных или вычислительного процесса, равна величине, обратной интенсивности обнаружения ошибок.
Если известны все моменты обнаружения ошибок ti и каждый раз в эти моменты обнаруживается и достоверно устраняется одна первичная ошибка, то, используя метод максимального правдоподобия.
Необходимые для расчетов К и N0 экспериментальные значения ti определяются в процессе отладки данного или аналогичных комплексов программ, созданных тем же коллективом разработчиков и при такой же технологии. В результате можно рассчитать число оставшихся в программе первичных ошибок и среднюю наработку Т до обнаружения следующей ошибки.
Математические модели позволяют оценивать характеристики ошибок в программах и прогнозировать их надёжность при проектировании и эксплуатации. Модели имеют вероятностный характер, и достоверность прогнозов зависит от точности исходных данных и глубины прогнозирования по времени. Эти математические модели предназначены для оценки:
- показателей надёжности комплексов программ в процессе отладки;
- количества ошибок, оставшихся не выявленными;
- времени, необходимого для обнаружения следующей ошибки в функционирующей программе;
- времени, необходимого для выявления всех ошибок с заданной вероятностью.
Использование моделей позволяет эффективно и целеустремлённо проводить отладку и испытания комплексов программ, помогает принять рациональное решение о времени прекращения отладочных работ.
В настоящее время предложен ряд математических моделей, основными из которых являются:
- экспоненциальная модель изменения ошибок в зависимости от времени отладки;
- модель, учитывающая дискретно - понижающуюся частоту появления ошибок как линейную функцию времени тестирования и испытаний;
- модель, базирующаяся на распределении Вейбула;
- модель, основанная на дискретном гипергеометрическом распределении.
При обосновании математических моделей выдвигаются некоторые гипотезы о характере проявления ошибок в комплексе программ. Наиболее обоснованными представляются предположения, на которых базируется первая Экспоненциальная модель изменения ошибок в процессе отладки и которые заключаются в следующем:
1. Любые ошибки в программе являются независимыми и проявляются в случайные моменты времени.
2. Время работы между ошибками определяется средним временем выполнения команды на данной ЭВМ и средним числом команд, исполняемым между ошибками. Это означает, что интенсивность проявления ошибок при реальном функционировании программы зависит от среднего быстродействия ЭВМ.
3. Выбор отладочных тестов должен быть представительным и случайным, с тем чтобы исключить концентрацию необнаруженных ошибок для некоторых реальных условий функционирования программы.
4. Ошибка, являющаяся причиной искажения результатов, фиксируется и исправляется после завершения тестирования либо вообще не обнаруживается.
Из этих свойств следует, что при нормальных условиях эксплуатации количество ошибок, проявляющихся в некотором интервале времени, распределено по закону Пуассона. В результате длительность непрерывной работы между искажениями распределена экспоненциально.
Предположим, что в начале отладки комплекса программ при t = 0 в нём содержалось Ошибок. После отладки в течении времени t осталось Ошибок и устранено n ошибок (+ n = ). При этом время t соответствует длительности исполнения программ на вычислительной системе (ВС) для обнаружения ошибок и не учитывает простои машины, необходимые для анализа результатов и проведения корректировок.
Интенсивность обнаружения ошибок в программе dn/dt и абсолютное количество устранённых ошибок связываются уравнением
где k - коэффициент.
Если предположить, что в начале отладки при t = 0 отсутствуют обнаруженные ошибки, то решение уравнения имеет вид
Количество оставшихся ошибок в комплексе программ
Пропорционально интенсивности обнаружения dn/dt с точностью до коэффициента k.
Время безотказной работы программ до отказа T или наработка на отказ, который рассматривается как обнаруживаемое искажение программ, данных или вычислительного процесса, нарушающее работоспособность, равно величине, обратной интенсивности обнаружения отказов (ошибок):
Если учесть, что до начала тестирования в комплексе программ содержалось Ошибок и этому соответствовала наработка на отказ , то функцию наработки на отказ от длительности проверок можно представить в следующем виде:
Если известны моменты обнаружения ошибок и каждый раз в эти моменты обнаруживается и достоверно устраняется одна ошибка, то, используя метод максимального правдоподобия, можно получить уравнение для определения значения начального числа ошибок :
а также выражение для расчёта коэффициента пропорциональности
В результате можно рассчитать число оставшихся в программе ошибок и среднюю наработку на отказ Tср = 1/l, т. е. получить оценку времени до обнаружения следующей ошибки.
В процессе отладки и испытаний программ, для повышения наработки на отказ от До , необходимо обнаружить и устранить Dn ошибок. Величина Dn определяется соотношением:
Выражение для определения затрат времени Dt на проведение отладки, которые позволяют устранить Dn ошибок и соответственно повысить наработку на отказ от значения До, имеет вид:
Вторая модель построена на основе гипотезы о том, что частота проявления ошибок (интенсивность отказов) линейно зависит от времени испытания между моментами обнаружения последовательных i - й и (i - 1) - й ошибок.
Где - начальное количество ошибок; K - коэффициент пропорциональности, обеспечивающий равенство единице площади под кривой вероятности обнаружения ошибок.
Для оценки наработки на отказ получается выражение, соответствующее распределению Релея:
Отсюда плотность распределения времени наработки на отказ
Использовав функцию максимального правдоподобия, получим оценку для общего количества ошибок И коэффициента K.
Особенностью Третьей модели является учёт ступенчатого характера изменения надёжности при устранении очередной ошибки. В качестве основной функции рассматривается распределение времени наработки на отказ P(t). Если ошибки не устраняются, то интенсивность отказов является постоянной, что приводит к экспоненциальной модели для распределения:
Отсюда плотность распределения наработки на отказ T определяется выражением:
где t > 0, l > 0 и 1/l - среднее время наработки на отказ, т. е. Тср=1/l. Здесь Тср - среднее время наработки на отказ.
Для аппроксимации изменения интенсивности от времени при обнаружении и устранении ошибок используется функция следующего вида:
Если 0 < b < 1, то интенсивность отказов снижается по мере отладки или в процессе эксплуатации. При таком виде функции l(t) плотность функции распределения наработки на отказ описывается двухпараметрическим распределением Вейбулла:
Распределение Вейбулла достаточно хорошо отражает реальные зависимости при расчёте функции наработки на отказ.
Сколько ошибок в программе? Это вопрос, который волнует каждого программиста. Особую актуальность придает ему принцип кучкования ошибок, согласно которому нахождение в некотором модуле ошибки увеличивает вероятность того, что в этом модуле есть и другие ошибки. Точного ответа на вопрос о количестве ошибок в программе очень часто дать невозможно, а вот построить некоторую оценку — можно. Для этого существуют несколько статических моделей. Рассмотрим одну из них: Модель Миллса.
В 1972 г. суперпрограммист фирмы IBM Харлан Миллс предложил следущий способ оценки количества ошибок в программе. Пусть у нас есть программа. Предположим, что в ней N ошибок. Назовем их естественными. Внесем в нее дополнительно M искусственных ошибок. Проведём тестирование программы. Пусть в ходе тестирования было обнаружено n естественных ошибок и m искусственных. Предположим, что вероятность обнаружения для естественных и искусственных ошибок одинакова. Тогда выполняется соотношение:
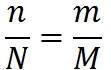
Мы нашли один и тот же процент естественных и искусственных ошибок. Отсюда количество ошибок в программе:

Количество необнаруженных ошибок равно (N-n).
Например, пусть в программу внесено 20 искусственных ошибок, в ходе тестирования было обнаружено 12 искусственных и 7 естественных ошибок. Получим следущую оценку количества ошибок в программе:

Количество необнаруженных ошибок равно (N-n) = 12 — 7 = 5.
Легко заметить, что в описанном выше способе Миллса есть один существенный недостаток. Если мы найдем 100% искусственных ошибок, это будут означать, что и естественных ошибок мы нашли 100%. Но чем меньше мы внесем искусственных ошибок, тем больше вероятность того, что мы найдём их все. Внесем единственную исскуственную ошибку, найдем ее, и на этом основании объявим, что нашли все естесственные ошибки! Для решение такой проблемы Миллс добавил вторую часть модели, предназначенную для проверки гипотезы о величине N:
Предположим, что в программе N естественных ошибок. Внесём в неё M искусственных ошибок. Будем тестировать программу до тех пор, пока не найдем все искусственные ошибки. Пусть к этому моменту найдено n естественных ошибок. На основании этих чисел вычислим величину C:
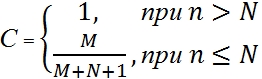
Величина C выражает меру доверия к модели. Это вероятность того, что модель будет правильно отклонять ложное предположение. Например, пусть мы считаем, что естественных ошибок в программе нет (N=0). Внесем в программу 4 искусственные ошибки. Будем тестировать программу, пока не обнаружим все искусственные ошибки. Пусть при это мы не обнаружим ни одной естественной ошибки. В этом случае мера доверия нашему предположению (об отсутствии ошибок в программе) будет равна 80% (4 / (4+0+1)). Для того чтобы довести ее до 90% количество искусственных ошибок придется поднять до 9. Следущие 5% уверенности в отсутствии естественных ошибок обойдутся нам в 10 дополнительных искусственных ошибок. M придется довести до 19.
Если мы предположим, что в программе не более 3-х естественных ошибок (N=3), внесем в нее 6 искусственных (M=6), найдем все искусственные и одну, две или три (но не больше!) естественных, то мера доверия к модели будет 60% (6 / (6+3+1)).
Значения функции С для различных значений N и M, в процентах:
Таблица 1 — с шагом 1;
Таблица 2 — с шагом 5;
Из формул для вычисления меры доверия легко получить формулу для вычисления количества искусственных ошибок, которые необходимо внести в программу для получения нужной уверенности в полученной оценке:

Количество исскуственных ошибок, которые необходимо внести в программу, для достижения нужной меры доверия, для различных значений N:
Таблица 3 — с шагом 1;
Таблица 4 — с шагом 5;
Модель Миллса достаточно проста. Ее слабое место — предположение о равновероятности нахождения ошибок. Чтобы это предположение оправдалось, процедура внесения искусственных ошибок должна обладать определенной степенью «интеллекта». Ещё одно слабое место — это требование второй части миллсовой модели отыскать непременно все искусственные ошибки. А этого может не произойти долго, может быть, и никогда.
Из всех областей программной инженерии надежность ПС является самой исследованной областью. Ей предшествовала разработка теории надежности технических средств, оказавшая влияние на развитие надежности ПС. Вопросами надежности ПС занимались разработчики ПС, пытаясь разными системными средствами обеспечить надежность , удовлетворяющую заказчика, а также теоретики, которые, изучая природу функционирования ПС, создали математические модели надежности, учитывающие разные аспекты работы ПС (возникновение ошибок, сбоев, отказов и др.) и позволяющие оценить реальную надежность . В результате надежность ПС сформировалась как самостоятельная теоретическая и прикладная наука [10.5-10.10, 10.16-10.24].
Надежность сложных ПС существенным образом отличается от надежности аппаратуры. Носители данных (файлы, сервер и т.п.) обладают высокой надежностью, записи на них могут храниться длительное время без разрушения, поскольку физическому разрушению они не подвергаются.
С точки зрения прикладной науки надежность - это способность ПС сохранять свои свойства ( безотказность , устойчивость и др.), преобразовывать исходные данные в результаты в течение определенного промежутка времени при определенных условиях эксплуатации. Снижение надежности ПС происходит из-за ошибок в требованиях, проектировании и выполнении. Отказы и ошибки зависят от способа производства продукта и появляются в программах при их исполнении на некотором промежутке времени.
Для многих систем (программ и данных) надежность - главная целевая функция реализации. К некоторым типам систем (реального времени, радарные системы, системы безопасности, медицинскоеоборудование со встроенными программами и др.) предъявляются высокие требования к надежности, такие, как отсутствие ошибок, достоверность , безопасность и др.
Таким образом, оценка надежности ПС зависит от числа оставшихся и не устраненных ошибок в программах. В ходе эксплуатации ПС ошибки обнаруживаются и устраняются. Если при исправлении ошибок не вносятся новые или, по крайней мере, новых ошибок вносится меньше, чем устраняется, то в ходе эксплуатации надежность ПС непрерывно возрастает. Чем интенсивнее проводится эксплуатация , тем интенсивнее выявляются ошибки и быстрее растет надежность системы и соответственно ее качество.
Надежность является функцией от ошибок, оставшихся в ПС после ввода его в эксплуатацию. ПС без ошибок является абсолютно надежным. Но для больших программ абсолютная надежность практически недостижима. Оставшиеся необнаруженные ошибки проявляют себя время от времени при определенных условиях (например, при некоторой совокупности исходных данных) сопровождения и эксплуатации системы.
Для оценки надежности ПС используются такие статистические показатели, как вероятность и время безотказной работы, возможность отказа и частота ( интенсивность) отказов . Поскольку в качестве причин отказов рассматриваются только ошибки в программе, которые не могут самоустраниться, то ПС следует относить к классу невосстанавливаемых систем.
При каждом проявлении новой ошибки, как правило, проводится ее локализация и исправление. Строго говоря, набранная до этого статистика об отказах теряет свое значение , так как после внесения изменений программа , по существу, является новой программой в отличие от той, которая до этого испытывалась.
В связи с исправлением ошибок в ПС надежность , т.е. ее отдельные атрибуты, будут все время изменяться, как правило, в сторону улучшения. Следовательно, их оценка будет носить временный и приближенный характер. Поэтому возникает необходимость в использовании новых свойств, адекватных реальному процессу измерения надежности, таких, как зависимость интенсивности обнаруженных ошибок от числа прогонов программы и зависимость отказов от времени функционирования ПС и т.п.
К факторам гарантии надежности относятся:
- риск как совокупность угроз, приводящих к неблагоприятным последствиям и ущербу системы или среды;
- угроза как проявление неустойчивости, нарушающей безопасность системы;
- анализ риска - изучение угрозы или риска, их частота и последствия;
- целостность - способность системы сохранять устойчивость работы и не иметь риска;
Риск преобразует и уменьшает свойства надежности, так как обнаруженные ошибки могут привести к угрозе, если отказы носят частотный характер.
10.2.1. Основные понятия в проблематике надежности ПС
Формально модели оценки надежности ПС базируются на теории надежности и математическом аппарате с допущением некоторых ограничений, влияющих на эту оценку. Главным источником информации, используемой в моделях надежности, является процесс тестирования, эксплуатации ПС и разного вида ситуации, возникающие в них. Ситуации порождаются возникновением ошибок в ПС, требуют их устранения для продолжения тестирования.
Базовыми понятиями, которые используются в моделях надежности ПС, являются [10.5-10.10].
Отказ ПC (failure) - это переход ПС из работающего состояния в нерабочее или когда получаются результаты, которые не соответствуют заданным допустимым значениям. Отказ может быть вызван внешними факторами (изменениями элементов среды эксплуатации) и внутренними - дефектами в самой ПС.
Дефект (fault) в ПС - это последствие использования элемента программы, который может привести к некоторому событию, например, в результате неверной интерпретации этого элемента компьютером (как ошибка (fault) в программе) или человеком (ошибка (error) исполнителя). Дефект является следствием ошибок разработчика на любом из процессов разработки - в описании спецификаций требований, начальных или проектных спецификациях, эксплуатационной документации и т.п. Дефекты в программе, не выявленные в результате проверок, являются источником потенциальных ошибок и отказов ПС. Проявление дефекта в виде отказа зависит от того, какой путь будет выполнять специалист, чтобы найти ошибку в коде или во входных данных. Однако не каждый дефект ПС может вызвать отказ или может быть связан с дефектом в ПС или среды. Любой отказ может вызвать аномалию от проявления внешних ошибок и дефектов.
Ошибка (error) может быть следствием недостатка в одном из процессов разработки ПС, который приводит к неправильной интерпретации промежуточной информации, заданной разработчиком или при принятии им неверных решений.
Интенсивность отказов - это частота появления отказов или дефектов в ПС при ее тестировании или эксплуатации.
При выявлении отклонения результатов выполнения от ожидаемых во время тестирования или сопровождения осуществляется поиск, выяснение причин отклонений и исправление связанных с этим ошибок.
Модели оценки надежности ПС в качестве входных параметров используют сведения об ошибках, отказах, их интенсивности, собранных в процессе тестирования и эксплуатации.
10.2.2. Классификация моделей надежности
Как известно, на данный момент времени разработано большое количество моделей надежности ПС и их модификаций. Каждая из этих моделей определяет функцию надежности, которую можно вычислить при задании ей соответствующих данных, собранных во время функционирования ПС. Основными данными являются отказы и время. Другие дополнительные параметры связаны с типом ПС, условиями среды и данных.
Ввиду большого разнообразия моделей надежности разработано несколько подходов к классификации этих моделей. Такие подходы в целом основываются на истории ошибок в проверяемой и тестируемой ПС на этапах ЖЦ. Одной из классификаций моделей надежности ПО является классификация Хетча [10.10]. В ней предлагается разделение моделей на прогнозирующие, измерительные и оценочные (рис. 10.4).
Прогнозирующие модели надежности основаны на измерении технических характеристик создаваемой программы: длина, сложность, число циклов и степень их вложенности, количество ошибок на страницу операторов программы и др.
Например, модель Мотли-Брукса основывается на длине и сложности структуры программы (количество ветвей, циклов, вложенность циклов), количестве и типах переменных, а также интерфейсов. В этих моделях длина программы служит для прогнозирования количества ошибок, например, для 100 операторов программы можно смоделировать интенсивность отказов .
Модель Холстеда прогнозирует количество ошибок в программе в зависимости от ее объема и таких данных, как число операций ( " />
) и операндов ( " />
), а также их общее число ( ,N_" />
).
Время программирования программы предлагается вычислять по следующей формуле:


где - число Страуда (Холстед принял равным 18 - число умственных операций в единицу времени).
Объем вычисляется по формуле:


- максимальное число различных операций.
Измерительные модели предназначены для измерения надежности программного обеспечения, работающего с заданной внешней средой. Они имеют следующие ограничения:
- программное обеспечение не модифицируется во время периода измерений свойств надежности;
- обнаруженные ошибки не исправляются;
- измерение надежности проводится для зафиксированной конфигурации программного обеспечения.
Типичным примером таких моделей являются модели Нельсона и РамамуртиБастани и др.Модель оценки надежности Нельсона основывается на выполнении k-прогонов программы при тестировании и позволяет определить надежность
![R(k) = exp [-\sum<\nabla t_<j></p>
\lambda(t)>],](https://intuit.ru/sites/default/files/tex_cache/b49eac2e774618b741148f322ba28c63.jpg)
где " />
- время выполнения -прогона, )\nablaj]" />
и при \le 1" />
она интерпретируется как интенсивность отказов .

прогонах оценка надежности вычисляется по формуле


где - число прогонов программы.
Таким образом, данная модель рассматривает полученные количественные данные о проведенных прогонах.
Оценочные модели основываются на серии тестовых прогонов и проводятся на этапах тестирования ПC. В тестовой среде определяется вероятность отказа программы при ее выполнении или тестировании.
Эти типы моделей могут применяться на этапах ЖЦ. Кроме того, результаты прогнозирующих моделей могут использоваться как входные данные для оценочной модели. Имеются модели (например, модель Муссы), которые можно рассматривать как оценочную и в то же время как измерительную модель [10.16, 10.17].
Другой вид классификации моделей предложил Гоэл [10.18, 10.19], согласно которой модели надежности базируются на отказах и разбиваются на четыре класса моделей:
- без подсчета ошибок;
- с подсчетом отказов;
- с подсевом ошибок;
- модели с выбором областей входных значений.
Модели без подсчета ошибок основаны на измерении интервала времени между отказами и позволяют спрогнозировать количество ошибок, оставшихся в программе. После каждого отказа оценивается надежность и определяется среднее время до следующего отказа. К таким моделям относятся модели Джелински и Моранды, Шика Вулвертона и Литвуда-Вералла [10.20, 10.21].
Модели с подсчетом отказов базируются на количестве ошибок, обнаруженных на заданных интервалах времени. Возникновение отказов в зависимости от времени является стохастическим процессом с непрерывной интенсивностью, а количество отказов является случайной величиной. Обнаруженные ошибки, как правило, устраняются и поэтому количество ошибок в единицу времени уменьшается. К этому классу моделей относятся модели Шумана, Шика- Вулвертона, Пуассоновская модель и др. [10.21-10.24].
Модели с подсевом ошибок основаны на количестве устраненных ошибок и подсеве, внесенном в программу искусственных ошибок, тип и количество которых заранее известны. Затем определяется соотношение числа оставшихся прогнозируемых ошибок к числу искусственных ошибок, которое сравнивается с соотношением числа обнаруженных действительных ошибок к числу обнаруженных искусственных ошибок. Результат сравнения используется для оценки надежности и качества программы. При внесении изменений в программу проводится повторное тестирование и оценка надежности. Этот подход к организации тестирования отличается громоздкостью и редко используется из-за дополнительного объема работ, связанных с подбором, выполнением и устранением искусственных ошибок.
Модели с выбором области входных значений основываются на генерации множества тестовых выборок из входного распределения, и оценка надежности проводится по полученным отказам на основе тестовых выборок из входной области. К этому типу моделей относится модель Нельсона и др.
Таким образом, классификация моделей роста надежности относительно процесса выявления отказов, фактически разделена на две группы:
- модели, которые рассматривают количество отказов как марковский процесс;
- модели, которые рассматривают интенсивность отказов как пуассоновский процесс.
Фактор распределения интенсивности отказов разделяет модели на экспоненциальные, логарифмические, геометрические, байесовские и др.
Читайте также: