
Метод главных компонент в excel
Обновлено: 06.07.2024
Анализ главных компонент – это метод понижения размерности Датасета (Dataset), который преобразует больший набор переменных в меньший с минимальными потерями информативности.
Уменьшение количества переменных в наборе данных происходит в ущерб точности, но хитрость здесь заключается в том, чтобы потерять немного в точности, но обрести простоту. Поскольку меньшие наборы данных легче исследовать и визуализировать, анализ данных становится намного проще и быстрее для Алгоритмов (Algorithm) Машинного обучения (ML).
Идея PCA проста: уменьшить количество переменных в наборе данных, сохранив при этом как можно больше информации.
Шаг первый. Стандартизация
Мы осуществляем Стандартизацию (Standartization) исходных переменных, чтобы каждая из них вносила равный вклад в анализ. Почему так важно выполнить стандартизацию до PCA? Метод очень чувствителен к Дисперсиям (Variance) исходных Признаков (Feature). Если есть больши́е различия между диапазонами исходных переменных, те переменные с бо́льшими диапазонами будут преобладать над остальными (например, переменная, которая находится в диапазоне от 0 до 100, будет преобладать над переменной, которая находится в диапазоне от 0 до 1), что приведет к необъективным результатам. Преобразование данных в сопоставимые масштабы может предотвратить эту ситуацию.
Математически это можно сделать путем вычитания Среднего значения (Mean) из каждого значения и деления полученной разности на Стандартное отклонение (Standard Deviation). После стандартизации все переменные будут преобразованы в исходные значения.
Шаг второй. Матрица ковариации
Цель этого шага – понять, как переменные отличаются от среднего по отношению друг к другу, или, другими словами, увидеть, есть ли между ними какая-либо связь. Порой переменные сильно коррелированы и содержат избыточную информацию, и чтобы идентифицировать эти взаимосвязи, мы вычисляем Ковариационную матрицу (Covariance Matrix).
Ковариационная матрица представляет собой симметричную матрицу размера p × p (где p – количество измерений), где в качестве ячеек пребывают коэффициенты ковариации, связанные со всеми возможными парами исходных переменных. Например, для трехмерного набора данных с 3 переменными x, y и z ковариационная матрица представляет собой следующее:

Окрашенные голубым треугольники симметрично равны друг другу
Поскольку ковариация переменной с самой собой – это ее дисперсия, на главной диагонали (от верхней левой ячейки к нижней правой), у нас фактически есть дисперсии каждой исходной переменной. А поскольку ковариация коммутативна (в ячейке XY значение равно YX), элементы матрицы симметричны относительно главной диагонали.
Что коэффициенты ковариации говорят нам о корреляциях между переменными? На самом деле, имеет значение знак ковариации. Если коэффициент – это:
- положительное число, то две переменные прямо пропорциональны, то есть второй увеличивается или уменьшается вместе с первым.
- отрицательное число, то переменные обратно пропорциональны, то есть второй увеличивается, когда первый уменьшается, и наоборот.
Теперь, когда мы знаем, что ковариационная матрица – это не более чем таблица, которая отображает корреляции между всеми возможными парами переменных, давайте перейдем к следующему шагу.
Шаг третий. Вычисление собственных векторов
Собственные векторы (Eigenvector) и Собственные значения (Eigenvalues) – это понятия из области Линейной алгебры (Linear Algebra), которые нам нужно экстраполировать из ковариационной матрицы, чтобы определить так называемые главные компоненты данных. Давайте сначала поймем, что мы подразумеваем под этим термином.
Главная компонента – это новая переменная, смесь исходных. Эти комбинации выполняются таким образом, что новые переменные (то есть главные компоненты) не коррелированы, и большая часть информации в исходных переменных помещается в первых компонентах. Итак, идея состоит в том, что 10-мерный датасет дает нам 10 главных компонент, но PCA пытается поместить максимум возможной информации в первый, затем максимум оставшейся информации во второй и так далее, пока не появится что-то вроде того, что показано на графике ниже:

Объясненная вариация
Такая организация информации в главных компонентах позволит нам уменьшить размерность без потери большого количества информации за счет отбрасывания компонент с низкой информативностью.
Здесь важно понимать, что главные компоненты менее интерпретируемы и не имеют никакого реального значения, поскольку они построены как линейные комбинации исходных переменных.
С геометрической точки зрения, главные компоненты представляют собой Векторы (Vector) данных, которые объясняют максимальное количество отклонений. Главные компоненты – новые оси, которые обеспечивают лучший угол для оценки данных, чтобы различия между наблюдениями были лучше видны.
Поскольку существует столько главных компонент, сколько переменных в наборе, главные компоненты строятся таким образом, что первый из них учитывает наибольшую возможную дисперсию в наборе данных. Например, предположим, что диаграмма рассеяния нашего набора данных выглядит так:
Подбор собственного вектора
Можем ли мы проецировать первый главный компонент? Да, это линия, которая соответствует фиолетовым отметкам, потому что она проходит через начало координат, и проекции точек на компонент наиболее короткие. Говоря математически, это линия, которая максимизирует дисперсию (среднее квадратов расстояний от проецируемых красных точек до начала координат).
Второй главный компонент рассчитывается таким же образом, при условии, что он не коррелирован (т.е. перпендикулярен) первому главному компоненту и учитывает следующую по величине дисперсию. Это продолжается до тех пор, пока не будет вычислено p главных компонент, равное исходному количеству переменных.
Теперь, когда мы поняли, что подразумевается под главными компонентами, давайте вернемся к собственным векторам и собственным значениям. Прежде всего, нам нужно знать, что они всегда "ходят парами", то есть каждый собственный вектор имеет собственное значение. И их количество равно количеству измерений данных. Например, для 3-мерного набора данных есть 3 переменных, следовательно, есть 3 собственных вектора с 3 соответствующими собственными значениями.
За всей магией, описанной выше, стоят собственные векторы и собственные значения, потому что собственные векторы матрицы ковариации на самом деле являются направлениями осей, где наблюдается наибольшая дисперсия (большая часть информации) и которые мы называем главными компонентами. А собственные значения – это просто коэффициенты, прикрепленные к собственным векторам, которые дают величину дисперсии, переносимую в каждом основном компоненте.
Ранжируя собственные векторы в порядке от наибольшего к наименьшему, мы получаем главные компоненты в порядке значимости.
Шаг четвертый. Вектор признака
Как мы видели на предыдущем шаге, вычисляя собственные векторы и упорядочивая их по собственным значениям в в порядке убывания, мы можем ранжировать основные компоненты в порядке значимости. На этом этапе мы выбираем, оставить ли все эти компоненты или отбросить те, которые имеют меньшее значение, и сформировать с оставшимися матрицу векторов, которую мы называем Вектором признака (Feature Vector).
Итак, вектор признаков – это просто матрица, в столбцах которой есть собственные векторы компонент, которые мы решили оставить. Это первый шаг к уменьшению размерности, потому что, если мы решим оставить только p собственных векторов (компонент) из n, окончательный набор данных будет иметь только p измерений.
Шаг 5. Трансформирование данных по осям главных компонент
На предыдущих шагах, помимо стандартизации, мы не вносили никаких изменений в данные, а просто выбирали основные компоненты и формировали вектор признаков, но исходной набор данных всегда остается.
На этом последнем этапе цель состоит в переориентации данных с исходных осей на оси, представленные главными компонентами (отсюда и название «Анализ главных компонент»). Это можно сделать, перемножив транспонированный исходный набор данных на транспонированный вектор признаков.
PCA и Scikit-learn
PCA можно реализовать с помощью SkLearn. Для начала импортируем необходимые библиотеки:
Мы будем использовать датасет банка, автоматизирующего выдачу кредитных продуктов своим клиентам:
Создадим список признаков, подлежащих уменьшению. Это макроэкономические показатели с невысоким уровнем важности, которые почти не попали в список выше. Выберем сокращаемые и Целевую переменные (Target Variable):
Выберем cамые важные признаки с помощью функции SelectKBest, которая использует критерий Хи-квадрат (Chi Square):
Создадим объект dfscores , куда отправим, соответственно, очки важности всех признаков датасета:
Создадим для коэффициентов отдельный объект, соединив названия столбцов и очки, и отобразим пять признаков, набравших наибольшее количество очков:
Неожиданно, но самыми важными признаками оказались количество сотрудников в компании и порядковый номер рекламной кампании, в которой участвует клиент:
Создадим список признаков, подлежащих понижению. Это макроэкономические показатели с невысоким уровнем важности, которые почти не попали в список выше:
Выполним стандартизацию объекта X. StandardScaler() на месте заменяет данные на их стандартизированную версию, и мы получаем признаки, где все значения как бы центрированы относительно нуля. Такое преобразование необходимо, чтобы правильно объединить признаки между собой.
Результат выглядит следующим образом:

Мы хотим получить один главный компонент. Передадим функции обучающие данные:
Мы получили вот такой главный компонент:

Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.

Метод главных компонентов (английский - principal component analysis, PCA) упрощает сложность высокоразмерных данных, сохраняя тенденции и шаблоны. Он делает это, преобразуя данные в меньшие размеры, которые действуют, как резюме функций. Такие данные очень распространены в разных отраслях науки и техники, и возникают, когда для каждого образца измеряются несколько признаков, например, таких как экспрессия многих видов. Подобный тип данных представляет проблемы, вызванные повышенной частотой ошибок из-за множественной коррекции данных.
Метод похож на кластеризацию - находит шаблоны без ссылок и анализирует их, проверяя, взяты ли образцы из разных групп исследования, и имеют ли они существенные различия. Как и во всех статистических методах, его можно применить неправильно. Масштабирование переменных может привести к разным результатам анализа, и очень важно, чтобы оно не корректировалось, на предмет соответствия предыдущему значению данных.
Цели анализа компонентов
Основная цель метода - обнаружить и уменьшить размерность набора данных, определить новые значимые базовые переменные. Для этого предлагается использовать специальные инструменты, например, собрать многомерные данные в матрице данных TableOfReal, в которой строки связаны со случаями и столбцами переменных. Поэтому TableOfReal интерпретируется как векторы данных numberOfRows, каждый вектор которых имеет число элементов Columns.
Традиционно метод главных компонентов выполняется по ковариационной матрице или по корреляционной матрице, которые можно вычислить из матрицы данных. Ковариационная матрица содержит масштабированные суммы квадратов и кросс-произведений. Корреляционная матрица подобна ковариационной матрице, но в ней сначала переменные, то есть столбцы, были стандартизованы. Вначале придется стандартизировать данные, если дисперсии или единицы измерения переменных сильно отличаются. Чтобы выполнить анализ, выбирают матрицу данных TabelOfReal в списке объектов и даже нажимают перейти.
Это приведет к появлению нового объекта в списке объектов по методу главных компонент. Теперь можно составить график кривых собственных значений, чтобы получить представление о важности каждого. И также программа может предложить действие: получить долю дисперсии или проверить равенство числа собственных значений и получить их равенство. Поскольку компоненты получены путем решения конкретной задачи оптимизации, у них есть некоторые «встроенные» свойства, например, максимальная изменчивость. Кроме того, существует ряд других их свойств, которые могут обеспечить факторный анализ:
- дисперсию каждого, при этом доля полной дисперсии исходных переменных задается собственными значениями;
- вычисления оценки, которые иллюстрируют значение каждого компонента при наблюдении;
- получение нагрузок, которые описывают корреляцию между каждым компонентом и каждой переменной;
- корреляцию между исходными переменными, воспроизведенными с помощью р–компонента;
- воспроизведения исходных данных могут быть воспроизведены с р–компонентов;
- «поворот» компонентов, чтобы повысить их интерпретируемость.
Выбор количества точек хранения
Существует два способа выбрать необходимое количество компонентов для хранения. Оба метода основаны на отношениях между собственными значениями. Для этого рекомендуется построить график значений. Если точки на графике имеют тенденцию выравниваться и достаточно близки к нулю, то их можно игнорировать. Ограничивают количество компонентов до числа, на которое приходится определенная доля общей дисперсии. Например, если пользователя удовлетворяет 95% от общей дисперсии - получают количество компонентов (VAF) 0.95.
Основные компоненты получают проектированием многомерного статистического анализа метода главных компонентов datavectors на пространстве собственных векторов. Это можно сделать двумя способами - непосредственно из TableOfReal без предварительного формирования PCA объекта и затем можно отобразить конфигурацию или ее номера. Выбрать объект и TableOfReal вместе и «Конфигурация», таким образом, выполняется анализ в собственном окружении компонентов.
Если стартовая точка оказывается симметричной матрицей, например, ковариационной, сначала выполняют сокращение до формы, а затем алгоритм QL с неявными сдвигами. Если же наоборот и отправная точка является матрица данных, то нельзя формировать матрицу с суммами квадратов. Вместо этого, переходят от численно более стабильного способа, и образуют разложения по сингулярным значениям. Тогда матрица будет содержать собственные векторы, а квадратные диагональные элементы - собственные значения.
Виды линейных комбинаций
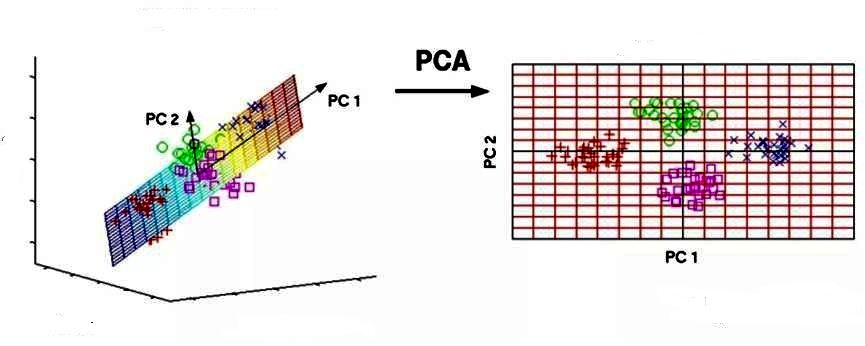
Основным компонентом является нормализованная линейная комбинация исходных предикторов в наборе данных по методу главных компонент для чайников. На изображении выше PC1 и PC2 являются основными компонентами. Допустим, есть ряд предикторов, как X1, X2. Xp.
Основной компонент можно записать в виде: Z1 = 11X1 + 21X2 + 31X3 + . + p1Xp
- Z1 - является первым главным компонентом;
- p1 - является вектором нагрузки, состоящим из нагрузок (1, 2.) первого основного компонента.
Нагрузки ограничены суммой квадрата равного 1. Это связано с тем, что большая величина нагрузок может привести к большой дисперсии. Он также определяет направление основной компоненты (Z1), по которой данные больше всего различаются. Это приводит к тому, что линия в пространстве р-мер, ближе всего к n-наблюдениям.
Близость измеряется с использованием среднеквадратичного евклидова расстояния. X1..Xp являются нормированными предикторами. Нормализованные предикторы имеют среднее значение, равное нулю, а стандартное отклонение равно единице. Следовательно, первый главный компонент - это линейная комбинация исходных предикторных переменных, которая фиксирует максимальную дисперсию в наборе данных. Он определяет направление наибольшей изменчивости в данных. Чем больше изменчивость, зафиксированная в первом компоненте, тем больше информация, полученная им. Ни один другой не может иметь изменчивость выше первого основного.
Первый основной компонент приводит к строке, которая ближе всего к данным и сводит к минимуму сумму квадрата расстояния между точкой данных и линией. Второй главный компонент (Z2) также представляет собой линейную комбинацию исходных предикторов, которая фиксирует оставшуюся дисперсию в наборе данных и некоррелирована Z1. Другими словами, корреляция между первым и вторым компонентами должна равняться нулю. Он может быть представлен как: Z2 = 12X1 + 22X2 + 32X3 + . + p2Xp.
Если они некоррелированы, их направления должны быть ортогональными.
Процесс прогнозирования тестовых данных
После того как вычислены главные компоненты начинают процесс прогнозирования тестовых данных с их использованием. Процесс метода главных компонент для чайников прост.

Например, необходимо сделать преобразование в тестовый набор, включая функцию центра и масштабирования в языке R (вер.3.4.2) и его библиотеке rvest. R - свободный язык программирования для статистических вычислений и графики. Он был реконструирован в 1992 году для решения статистических задач пользователями. Это полный процесс моделирования после извлечения PCA.
Набор данных Python:

Для реализации PCA в python импортируют данные из библиотеки sklearn. Интерпретация остается такой же, как и пользователей R. Только набор данных, используемый для Python, представляет собой очищенную версию, в которой отсутствуют вмененные недостающие значения, а категориальные переменные преобразуются в числовые. Процесс моделирования остается таким же, как описано выше для пользователей R. Метод главных компонент, пример расчета:

Спектральное разложение
Идея метода основного компонента заключается в приближении этого выражения для выполнения факторного анализа. Вместо суммирования от 1 до p теперь суммируются от 1 до m, игнорируя последние p-m членов в сумме и получая третье выражение. Можно переписать это, как показано в выражении, которое используется для определения матрицы факторных нагрузок L, что дает окончательное выражение в матричной нотации. Если используются стандартизованные измерения, заменяют S на матрицу корреляционной выборки R.

Это формирует матрицу L фактор-нагрузки в факторном анализе и сопровождается транспонированной L. Для оценки конкретных дисперсий фактор-модель для матрицы дисперсии-ковариации.
Теперь будет равна матрице дисперсии-ковариации минус LL ' .
Основные компоненты определяются по формуле
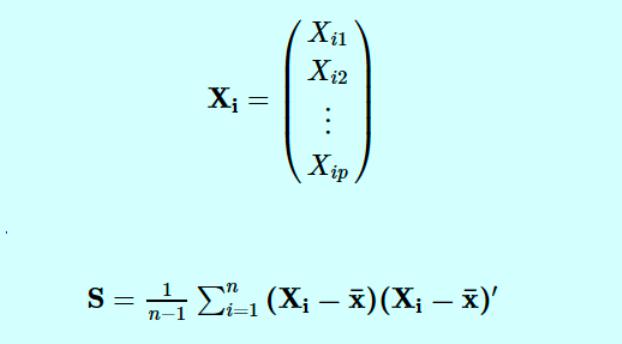
- Xi - вектор наблюдений для i-го субъекта.
- S обозначает нашу выборочную дисперсионно-ковариационную матрицу.
Тогда p собственные значения для этой матрицы ковариации дисперсии, а также соответствующих собственных векторов для этой матрицы.
Собственные векторы S:е^1, e^2, . , e^п.
Анализ Excel в биоинформатике
Анализ PCA - это мощный и популярный метод многомерного анализа, который позволяет исследовать многомерные наборы данных с количественными переменными. По этой методике широко используется метод главных компонент в биоинформатике, маркетинге, социологии и многих других областях. XLSTAT предоставляет полную и гибкую функцию для изучения данных непосредственно в Excel и предлагает несколько стандартных и расширенных опций, которые позволят получить глубокое представление о пользовательских данных.
Можно запустить программу на необработанных данных или на матрицах различий, добавить дополнительные переменные или наблюдения, отфильтровать переменные в соответствии с различными критериями для оптимизации чтения карт. Кроме того, можно выполнять повороты. Легко настраивать корреляционный круг, график наблюдений в качестве стандартных диаграмм Excel. Достаточно перенести данные из отчета о результатах, чтобы использовать их в анализе.
XLSTAT предлагает несколько методов обработки данных, которые будут использоваться на входных данных до вычислений основного компонента:
- Pearson, классический PCA, который автоматически стандартизирует данные для вычислений, чтобы избежать раздутого влияния переменных с большими отклонениями от результата.
- Ковариация, которая работает с нестандартными отклонениями.
- Полихорические, для порядковых данных.
Примеры анализа данных размерностей
Можно рассмотреть метод главных компонентов на примере выполнения симметричной корреляционной или ковариационной матрицы. Это означает, что матрица должна быть числовой и иметь стандартизованные данные. Допустим, есть набор данных размерностью 300 (n) × 50 (p). Где n - представляет количество наблюдений, а p - число предикторов.
Поскольку имеется большой p = 50, может быть p(p-1)/2 диаграмма рассеяния. В этом случае было бы хорошим подходом выбрать подмножество предиктора p (p<< 50), который фиксирует количество информации. Затем следует составление графика наблюдения в полученном низкоразмерном пространстве. Не следует забывать, что каждое измерение является линейной комбинацией р-функций.
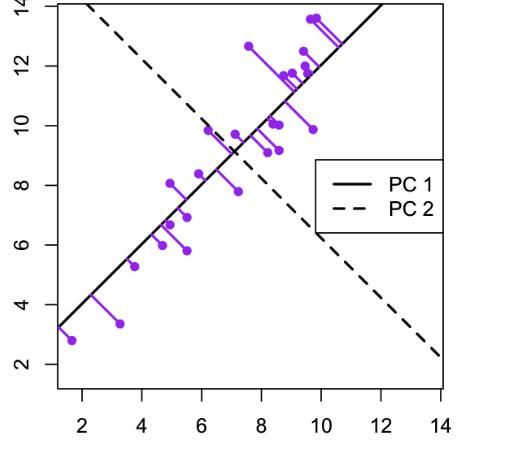
Пример для матрицы с двумя переменными. В этом примере метода главных компонентов создается набор данных с двумя переменными (большая длина и диагональная длина) с использованием искусственных данных Дэвиса.
Компоненты можно нарисовать на диаграмме рассеяния следующим образом.
Этот график иллюстрирует идею первого или главного компонента, обеспечивающего оптимальную сводку данных - никакая другая линия, нарисованная на таком графике рассеяния, не создаст набор прогнозируемых значений точек данных на линии с меньшей дисперсией.
Первый компонент также имеет приложение в регрессии с уменьшенной главной осью (RMA), в которой предполагается, что как x-, так и y-переменные имеют ошибки или неопределенности или, где нет четкого различия между предсказателем и ответом.
Эконометрические модели прогнозирования
Метод главных компонентов в эконометрике - это анализ переменных, таких как ВНП, инфляция, обменные курсы и т. д. Их уравнения затем оцениваются по имеющимся данным, главным образом совокупным временным рядам. Однако эконометрические модели могут использоваться для многих приложений, а не для макроэкономических. Таким образом, эконометрика означает экономическое измерение.
Применение статистических методов к соответствующей эконометрике данных показывает взаимосвязь между экономическими переменными. Простой пример эконометрической модели. Предполагается, что ежемесячные расходы потребителей линейно зависят от доходов потребителей в предыдущем месяце. Тогда модель будет состоять из уравнения

Задачей эконометрика является получение оценок параметров a и b. Эти оценочные значения параметров, если они используются в уравнении модели, позволяют прогнозировать будущие значения потребления, которые будут зависеть от дохода предыдущего месяца. При разработке этих видов моделей необходимо учитывать несколько моментов:
- характер вероятностного процесса, который генерирует данные;
- уровень знаний об этом;
- размер системы;
- форма анализа;
- горизонт прогноза;
- математическая сложность системы.
Все эти предпосылки важны, потому что от них зависят источники ошибок, вытекающих из модели. Кроме того, для решения этих проблем необходимо определить метод прогнозирования. Его можно привести к линейной модели, даже если имеется только небольшая выборка. Этот тип является одним из самых общих, для которого можно создать прогнозный анализ.
Непараметрическая статистика
Метод главных компонент для непараметрических данных относится к методам измерения, в которых данные извлекаются из определенного распределения. Непараметрические статистические методы широко используются в различных типах исследований. На практике, когда предположение о нормальности измерений не выполняется, параметрические статистические методы могут приводить к вводящим в заблуждение результатам. Напротив, непараметрические методы делают гораздо менее строгие предположения о распределении по измерениям.
Они являются достоверными независимо от лежащих в их основе распределений наблюдений. Из-за этого привлекательного преимущества для анализа различных типов экспериментальных конструкций было разработано много разных типов непараметрических тестов. Такие проекты охватывают дизайн с одной выборкой, дизайн с двумя образцами, дизайн рандомизированных блоков. В настоящее время непараметрический байесовский подход с применением метода главных компонентов используется для упрощения анализа надежности железнодорожных систем.
Железнодорожная система представляет собой типичную крупномасштабную сложную систему с взаимосвязанными подсистемами, которые содержат многочисленные компоненты. Надежность системы сохраняется за счет соответствующих мер по техническому обслуживанию, а экономичное управление активами требует точной оценки надежности на самом низком уровне. Однако данные реальной надежности на уровне компонентов железнодорожной системы не всегда доступны на практике, не говоря уже о завершении. Распределение жизненных циклов компонентов от производителей часто скрывается и усложняется фактическим использованием и рабочей средой. Таким образом, анализ надежности требует подходящей методологии для оценки времени жизни компонента в условиях отсутствия данных об отказах.
Метод главных компонент в общественных науках используется для выполнения двух главных задач:
- анализа по данным социологических исследований;
- построения моделей общественных явлений.
Алгоритмы расчета моделей
Алгоритмы метода главных компонент дают другое представление о структуре модели и ее интерпретации. Они являются отражением того, как PCA используется в разных дисциплинах. Алгоритм нелинейного итеративного частичного наименьшего квадрата NIPALS представляет собой последовательный метод вычисления компонентов. Вычисление может быть прекращено досрочно, когда пользователь считает, что их достаточно. Большинство компьютерных пакетов имеют тенденцию использовать алгоритм NIPALS, поскольку он имеет два основных преимущества:
- он обрабатывает отсутствующие данные;
- последовательно вычисляет компоненты.
Цель рассмотрения этого алгоритма:
- дает дополнительное представление о том, что означают нагрузки и оценки;
- показывает, как каждый компонент не зависит ортогонально от других компонентов;
- показывает, как алгоритм может обрабатывать недостающие данные.
Алгоритм последовательно извлекает каждый компонент, начиная с первого направления наибольшей дисперсии, а затем второго и т. д. NIPALS вычисляет один компонент за раз. Вычисленный первый эквивалентен t1t1, а также p1p1 векторов, которые были бы найдены из собственного значения или разложения по сингулярным значениям, может обрабатывать недостающие данные в XX. Он всегда сходится, но сходимость иногда может быть медленной. И также известен, как алгоритм мощности для вычисления собственных векторов и собственных значений и отлично работает для очень больших наборов данных. Google использовал этот алгоритм для ранних версий своей поисковой системы.
Алгоритм NIPALS показан на фото ниже.

Оценки коэффициента матрицы Т затем вычисляется как T=XW и в частичной мере коэффициентов регрессии квадратов B из Y на X, вычисляются, как B = WQ. Альтернативный метод оценки для частей регрессии частичных наименьших квадратов можно описать следующим образом.

Метод главных компонентов - это инструмент для определения основных осей дисперсии в наборе данных и позволяет легко исследовать ключевые переменные данных. Правильно примененный метод является одним из самых мощных в наборе инструментов анализа данных.
Помогите доразобраться с методом главных компонент (PCA)
Помогите доразобраться с методом главных компонент (PCA)| Последний раз редактировалось AKM 27.10.2011, 17:24, всего редактировалось 1 раз. |
| Красный цвет зарезервирован для модераторства. Заменил. |
Пытаюсь реализовать метод главных компонент программно. В математике разбираюсь плохо,а математическая литература дается с большим трудом. Программная реализация практически готова. Однако есть несколько нюансов. Мне нужно до понять сам алгоритм и быть уверенным, что он правильный.


3. теперь нужно найти собственные значения матрицы. находим:
2,2588028617938E-11
3,00974370200233E-10
1,60828710075361
2,39171289892283
все полученные числа всегда будут вещественными (комплексных быть не может), так как матрица симметричная (?)
4. теперь нужно расположить все собственные значения в порядке убывания (?) и высчитать собственные векторы. получается:
для 2,39171289892283:
0,552 \\ 0,417 \\ 0,557 \\ 0,459 \\ \end$" />
и для 1,60828710075361:
0,410 \\ 0,603 \\ -0,400 \\ -0,555 \\ \end$" />
остальные собственные значения отбрасываем (. ) так как они очень близки к нулю
5. А вот дальше что делать я не совсем понимаю. Знаю что нужно как то преобразовать исходные данные относительно полученных векторов.
Собственно, в этом и заключается вопрос. Что делать после получения собственных векторов?
И хотелось бы получить комментарии относительно того, правильно ли я все делаю (верен ли алгоритм). сомнительные места подсвечены оранжевым
4. Да, в порядке убывания.
5. Домножаем собственный вектор на корень из соответствующего собственного значения, получаем коэффициенты при главных компонентах. остальные собственные значения отбрасываем (. ) так как они очень близки к нулю
Это мое неверное утверждение. Собственные значения отбрасываются, к примеру, "по правилу сломанной трости" или "по правилу Кайзера".
3. Более того, они будут неотрицательны, поскольку это матрицы Грама.4. Да, в порядке убывания.
5. Домножаем собственный вектор на корень из соответствующего собственного значения, получаем коэффициенты при главных компонентах.
Большое спасибо за ответ. Коэффициенты при главных компонентах я нахожу. А дальше как? Нужно ведь каким-то образом получить окончательную статистику (относительно исходной матрицы и полученных коэфициентов главных компонент). Домножаем собственный вектор на корень из соответствующего собственного значения, получаем коэффициенты при главных компонентах
как понимаю, это получается так называемая "Матрица нагрузок (Loadings)"?
а как правильно получить "Матрицу счетов (Scores)"?
Последний раз редактировалось wizardofnothing 31.10.2011, 13:29, всего редактировалось 1 раз.


Вот только не могу понять, как рассчитывается этот результат. Кто знает, разъясните пожалуста. заранее спасибо
нужно непосредственно понять, как высчитывается матрица счетов
Последний раз редактировалось Евгений Машеров 31.10.2011, 18:35, всего редактировалось 3 раз(а).
Проще всего вести объяснение через сингулярное разложение.где
а матрица сингулярных чисел диагональная.
Такое разложение есть у любой матрицы Х (предполагается, что строк не меньше, чем столбцов)
Тогда корреляционная матрица (полагая, что строки матрицы центрированы и нормированы, если выполнено только первое условие, то это будет ковариационная, если даже не центрированы - то непонятно что, специального названия нет, в смысле употребительного в статистике, вообще-то это будет матрица Грама)
Очевидно, это эквивалентно разложению по собственным значениям, причём собственные числа есть квадраты сингулярных.
То есть если мы умеем разлагать на с.з. и с.в. корреляционную матрицу - мы уже нашли представление Х в виде
где
А это и есть наши "факторные нагрузки" А.
Если мы берём их все, то матрицу Х воспроизведём точно. Но мы используем лишь часть их, желая выразить Х через меньшее число "сущностей". Величина сингулярного числа показывает вклад соответствующей матрицы ранга 1 в матрицу Х, так что есть смысл брать самые большие, тогда мы получим наилучшее приближение к Х при малом числе слагаемых.
Остаётся ответить на вопрос, откуда взять "scores" (значения компонент) S.
Из равенства следует, что
$" />
спасибо. я полностью, очень внимательно, несколько раз перечитал ваш ответ
понял объяснение через сингулярное разложение
однако все равно не понимаю главного - как получить значения компонент (scores)
что иммеется ввиду под ?
- это ковариационная матрица?
собственно, как я понял, для получения матрицы S нужно:
1. матрицу исходных данных перемножить на ковариационную матрицу (полученную из исходных данных)
2. полученный результат перемножить на обратную матрицу сингулярных значений (сингулярными значениями являются корни из собственных значений)
но резутата, приведенного на пост выше, не удалось добиться все равно. блин. что опять не так делаю?
или это сосбтвенные вектора корреляционной\ковариационной матрицы?тогда все вроде бы логично:
матрицу исходных данных перемножаем на матрицу собственных векторов (записанных по порядку в столбик) и результат умножаем на обратную матрицу $" />
, составленную из корней собственных значений (диагональная матрица, в главной диагонали которой вписаны собственные значения)
однако все равно результат не сходится. в чем может быть ошибка?
Последний раз редактировалось wizardofnothing 01.11.2011, 10:17, всего редактировалось 2 раз(а).
еще заметил, что равняется диагональной матрице, в диагонали которой лежат собственные значения
- количество записей (объектов) в исходной таблице

я разобрался как находить: корреляционную матрицу, собственные значения корреляционной матрицы, собственные вектора, матрицу нагрузок, разобрался как выбирать только значимые компоненты.
Однако так и не могу понять алгоритм получения . Подскажите пожалуйста буквально на словах, что на что разделить\умножить надо, чтобы найти scores?
Умножаем Х на матрицу, транспонированную к С, затем делим на корни из с.з.
Что не так выходит?
Последний раз редактировалось wizardofnothing 01.11.2011, 14:10, всего редактировалось 2 раз(а).
3)находим собственные значения
2,2588028617938E-11
3,00974370200233E-10
1,60828710075361
2,39171289892283
4) правилом Кайзера или правилом "сломанной трости" отбираем только значимые собственные значения и расставляем их в порядке убывания
2,39171289892283
1,60828710075361
5)находим собственные вектора
0,552 \\ 0,417 \\ 0,557 \\ 0,459 \\ \end$" />
0,410 \\ 0,603 \\ -0,400 \\ -0,555 \\ \end$" />
6) находим факторные нагрузки (loadings), перемножив каждый собственный вектор на корень из соответствующего собственного значения

7) остается найти scores.
Итак:
Умножаем исходную матрицу на транспонированную к матрице собственных векторов ()
Это ()
1.2 & 2.3 & 7 & 10 \\ 2 & 5 & 4.2 & 1.4 \\ 3 & 6 & 9 & 12 \end $" />
умножаем на ()
0,552 & 0,410 \\ 0,417 & 0,603 \\ 0,557 & -0,400 \\ 0,459 & -0,555\\ \end$" />
получаем такую матрицу :
10,1105 & -6,4711 \\ 6,171 & 1,378 \\ 14,679 & -5,412 \\ \end$" />
теперь ее надо разделить на матрицу корней из с.з., то есть домножить на обратную матрицу $" />
матрица корней с.з. , как понимаю, имеет следующий вид
1,547 & 0 \\ 0 & 1,268 \\ \end$" />
обратная ей $" />
:
0,646 & 0 \\ 0 & 0,789 \\ \end$" />
теперь перемножаем на $" />
получается
6,531383 & -5,1056979 \\ 3,986466 & 1,087242 \\ 9,482634 & -4,270068 \\ \end$" />
это и есть scores?
просто дело в том, что я запускаю PCA анализ через плагин к excel (xlstats), который выводит совсем другую матрицу счетов scores
-0,924 & -1,626 \\ -1,255 & 1,469 \\ 2,179 & 0,157 \\ \end $" />
в настройках анализа можно задавать PCA type: pearson(n),pearson(n-1),spearman,covariance(n),covariance(n-1) и т.д.
я выбираю pearson(n). и я не могу понять откуда там берутся такие значения, как такое подсчиталось
ПРИЧЕМ! абсолютно все предыдущие пункты (корреляционная матрицы, с.з, с.в.,матрица нагрузок) высчитываются аналогично - все значения полностью совпадают с моими рассчетами. а аналогичную матрицу счетов я получить никак не могу.
Ответ который выводит xlstats явно верный, так как если поулченную из него матрицу транспонировать () и умножить на нетранспонированную (), а затем разделить каждый полученный элемент на n (n=3, так как в исходных данных 3 строки), то у нас получается диагональная матрица собственных значений, как и должно быть по формулам.
это значит, что я что-то делаю неверно

Содержание

Пусть имеется $n$ числовых признаков $f_j(x), j = 1, . , n$. Объекты обучающей выборки будем отождествлять с их признаковыми описаниями: $x_i \equiv (f_1(x_i), . f_n(x_i)), i = 1, . l$. Рассмотрим матрицу $F$, строки которой соответствуют признаковым описаниям обучающих объектов: $$F_ = \begin f_1(x_1) & . & f_n(x_1)\\ . & . & . \\ f_1(x_l) & . & f_n(x_l) \end = \begin x_1\\ . \\ x_l \end.$$
Обозначим через $z_i = (g_1(x_i), . g_m(x_i))$ признаковые описания тех же объектов в новом пространстве $Z = \mathbb^$ меньшей размерности, $m < n$:
Потребуем, чтобы исходные признаковые описания можно было восстановить по новым описаниям с помощью некоторого линейного преобразования, определяемого матрицей $U = (u_)_$:
$$\hat_j(x) = \sum_^ g_s(x)u_, \; j = 1, . n, \; x \in X,$$
или в векторной записи: $\hat = z U^T$. Восстановленное описание $\hat$ не обязано в точности совпадать с исходным описанием $x$, но их отличие на объектах обучающей выборки должно быть как можно меньше при выбранной размерности $m$. Будем искать одновременно и матрицу новых признаковых описаний $G$, и матрицу линейного преобразования $U$, при которых суммарная невязка $\Delta^2(G, U)$ восстановленных описаний минимальна:
$$\Delta^2(G, U) = \sum_^ \| \hat_i - x_i \|^2 = \sum_^ \| z_i U^T - x_i \|^2 = \| GU^T - F \|^2 \to \mathop_,$$
где все нормы евклидовы.
Будем предполагать, что матрицы $G$ и $U$ невырождены: $rank \, G = rank \, U = m$. Иначе существовало бы представление $\bar \bar^T = G U^T$ с числом столбцов в матрице $\bar$, меньшим $m$. Поэтому интересны лишь случаи, когда $m \leq rank \, F$.
Исчерпывающее решение сформулированной задачи даёт следующая теорема.
Если [math]m \leq rank \, F[/math] , то минимум [math]\Delta^2(G, U)[/math] достигается, когда столбцы матрицы [math]U[/math] есть собственные векторы [math]F^T F[/math] , соответствующие [math]m[/math] максимальным собственным значениям. При этом [math]G = F U[/math] , матрицы [math]U[/math] и [math]G[/math] ортогональны.Запишем необходимые условия минимума:
Поскольку искомые матрицы $G$ и $U$ невырождены, отсюда следует:
[math] \begin G = F U (U^T U)^;\\ U = F^T G (G^T G)^. \end [/math]
Функционал $\Delta^2(G, U)$ зависит только от произведения матриц $G U^T$, поэтому решение задачи $\Delta^2(G, U) \to \mathop_$ определено с точностью до произвольного невырожденного преобразования $R: G U^T = (G R) (R^ U^T)$. Распорядимся свободой выбора $R$ так, чтобы матрицы $U^T U$ и $G^T G$ оказались диагональными. Покажем, что это всегда возможно.
Пусть $\tilde \tilde^T$ — произвольное решение задачи.
Матрица $\tilde^T \tilde$ симметричная, невырожденная, положительно определенная, поэтому существует невырожденная матрица $S_$ такая, что $S^ \tilde^T \tilde (S^)^T = I_m$.
Матрица $S^T \tilde^T \tilde S$ симметричная и невырожденная, поэтому существует ортогональная матрица $T_$ такая, что $T^T (S^T \tilde^T \tilde S) T = diag(\lambda_1, . \lambda_m) \equiv \Lambda$ — диагональная матрица. По определению ортогональности $T^T T = I_m$.
Преобразование $R = S T$ невырождено. Положим $G = \tilde R$, $U^T = R^ \tilde^T$. Тогда
[math]G^T G = T^T (S^T \tilde^T \tilde S) T = \Lambda;\\ U^T U = T^ (S^ \tilde^T \tilde (S^)^T) (T^)^T = (T^T T)^ = I_m.[/math]
В силу $G U^T = \tilde \tilde^T$ матрицы $G$ и $U$ являются решением задачи $\Delta^2(G, U) \to \mathop_$ и удовлетворяют необходимому условию минимума. Подставим матрицы $G$ и $U$ в
[math] G = F U (U^T U)^;\\ U = F^T G (G^T G)^. [/math]
Благодаря диагональности $G^T G$ и $U^T U$ соотношения существенно упростятся:
[math] \begin G = F U;\\ U \Lambda = F^T G. \end [/math]
Подставим первое соотношение во второе, получим $U \Lambda = F^T F U$. Это означает, что столбцы матрицы $U$ обязаны быть собственными векторами матрицы $F^T F$, а диагональные элементы $\lambda_1, . \lambda_m$ - соответствующими им собственными значениями.
Аналогично, подставив второе соотношение в первое, получим $G \Lambda = F F^T G$, то есть столбцы матрицы $G$ являются собственными векторами $F F^T$, соответствующими тем же самым собственным значениям.
Подставляя $G$ и $U$ в функционал $\Delta^2(G, U)$, находим:
[math]\Delta^2(G, U)[/math] = [math]\| F - G U^T \|^2[/math] = [math]tr \, (F^T - U G^t)(F - G U^T)[/math] = [math]tr \, F^T (F - G U^T)[/math] = [math]tr \, F^T F - tr \, F^T G U^T[/math] = [math]\| F \|^2 - tr \, U \Lambda U^T[/math] = [math]\| F \|^2 - tr \, \Lambda[/math] = [math]\sum_^ \lambda_j - \sum_^ \lambda_j - \sum_^ \lambda_j,[/math]
где $\lambda_1 , . \lambda_n$ - все собственные значения матрицы $F^T F$. Минимум $\Delta^2$ достигается, когда $\lambda_1, . \lambda_m$ — наибольшие $m$ из $n$ собственных значений.
Если $m = n$, то $\Delta^2(G, U) = 0$. В этом случае представление $F = G U^T$ является точным и совпадает с сингулярным разложением: $F = G U^T = V D U^T$, если положить $G = V D$ и $\Lambda = D^2$. При этом матрица $V$ ортогональна: $V^T V = I_m$.
Если $m < n$, то представление $F \approx G U^T$ является приближённым. Сингулярное разложение матрицы $G U^T$ получается из сингулярного разложения матрицы $F$ путём отбрасывания (обнуления) $n - m$ минимальных собственных значений.
Диагональность матрицы $G^T G = \Lambda$ означает, что новые признаки $g_1, . g_m$ не коррелируют на объектах из обучающей выборки. Ортогональное преобразование $U$ называют декоррелирующим или преобразованием Карунена–Лоэва. Если $m = n$, то о прямое и обратное преобразование вычисляются с помощью одной и той же матрицы $U: F = G U^T$ и $G = F U$.
Главные компоненты содержат основную информацию о матрице $F$. Число главных компонент $m$ называют также эффективной размерностью задачи. На практике её определяют следующим образом. Все собственные значения матрицы $F^T F$ упорядочиваются по убыванию: $\lambda_1 \geq . \geq \lambda_n \geq 0$. Задаётся пороговое значение $\epsilon \in [0, 1]$, достаточно близкое к нулю, и определяется наименьшее целое $m$, при котором относительная погрешность приближения матрицы $F$ не превышает $\epsilon$:
Величина $E(m)$ показывает, какая доля информации теряется при замене исходных признаковых описаний длины $n$ на более короткие описания длины $m$. Метод главных компонент особенно эффективен в тех случаях, когда $E(m)$ оказывается малым уже при малых значениях $m$. Если задать число $\epsilon$ из априорных соображений не представляется возможным, прибегают к критерию «крутого обрыва». На графике $E(m)$ отмечается то значение $m$, при котором происходит резкий скачок: $E(m - 1) \gg E(m)$, при условии, что $E(m)$ уже достаточно мало.

Метод главных компонент применим всегда. Распространённое утверждение о том, что он применим только к нормально распределённым данным (или для распределений, близких к нормальным) неверно: в исходной формулировке К. Пирсона ставится задача об аппроксимации конечного множества данных и отсутствует даже гипотеза о их статистическом порождении, не говоря уж о распределении.
Однако метод не всегда эффективно снижает размерность при заданных ограничениях на точность $E(m)$. Прямые и плоскости не всегда обеспечивают хорошую аппроксимацию. Например, данные могут с хорошей точностью следовать какой-нибудь кривой, а эта кривая может быть сложно расположена в пространстве данных. В этом случае метод главных компонент для приемлемой точности потребует нескольких компонент (вместо одной), или вообще не даст снижения размерности при приемлемой точности.
Читайте также: