
Повторяющиеся значения в excel гугл
Обновлено: 08.07.2024
Google Таблицы постепенно становятся для многих выбором электронных таблиц. Легкость, с которой вы можете сотрудничать в Google Таблицах, намного превосходит все другие инструменты для работы с электронными таблицами.
Еще одна причина, по которой Google Таблицы так широко используются, связана с простотой использования. Команда, стоящая за ним, постоянно добавляет новые функции и возможности, которые упрощают и ускоряют работу.
В этом уроке я покажу вам несколько способов удаления дубликатов в Google Таблицах.
Удалите дубликаты с помощью инструмента «Удалить дубликаты»
Предположим, у вас есть набор данных, как показано ниже, и вы хотите удалить все повторяющиеся записи из этого набора данных.

Ниже приведены шаги по удалению дубликатов из набора данных в Google Таблицах:
Вышеупомянутые шаги мгновенно удалят все повторяющиеся записи из набора данных, и вы получите результат, как показано ниже.
Когда вы используете опцию «Удалить дубликаты», чтобы избавиться от повторяющихся записей, это не повлияет на данные вокруг них. Это означает, что при его использовании не удаляются строки и не удаляются ячейки. Он просто удаляет повторяющиеся записи из ячеек (без нарушения ячеек в наборе данных).
Удалите дубликаты с помощью УНИКАЛЬНОЙ функции
В Google Таблицах также есть функция, которую вы можете использовать для удаления повторяющихся значений и сохранения только уникальных значений.
Это УНИКАЛЬНАЯ функция.
Предположим, у вас есть набор данных, как показано ниже, и вы хотите удалить все повторяющиеся записи из этого набора данных:

Приведенная ниже формула удалит все повторяющиеся записи, и вы получите все уникальные:
= УНИКАЛЬНЫЙ (A2: B17)
Приведенная выше формула даст вам результат, начиная с ячейки, в которую вы ввели формулу.
Одним из ограничений использования функции UNIQUE является то, что она будет рассматривать как дубликаты только те записи, где повторяется все содержимое строки. Если вы хотите сохранить только один экземпляр названия страны и удалить все остальные, UNIQUE сделает это только в том случае, если остальные значения столбца для этой записи также совпадают.
Если в ваших данных есть начальные, конечные или дополнительные пробелы, уникальная функция будет рассматривать записи как разные. В таком случае вы можете использовать следующую формулу:
= МассивФормула (УНИКАЛЬНО (ОБРЕЗАТЬ (A2: B17)))
Удалить дубликат с помощью надстройки
Google Таблицы, как правило, поддерживают огромную библиотеку различных надстроек, чтобы решить все мыслимые проблемы или проблемы.
Все надстройки для удаления дубликатов могут использоваться для одной и той же цели. В Выкрутить Дубликаты надстройка по AbleBits является одним из лучших дополнений для удаления повторяющихся записей из набора данных.
Чтобы использовать надстройку, вам сначала нужно добавить ее в свой документ Google Таблиц.
Ниже приведены шаги по добавлению надстройки в документ Google Таблиц:
Вышеупомянутые шаги добавят надстройку Remove Duplicate в ваш документ Google Sheets, и теперь вы можете начать ее использовать.
Ниже приведены шаги по использованию этого дополнения для удаления повторяющихся записей в Google Таблицах:
Вышеупомянутые шаги мгновенно удалят повторяющиеся записи, и у вас останутся только уникальные записи.
При работе с данными в Google Таблицах рано или поздно вы столкнетесь с проблемой дублирования данных. Это могут быть повторяющиеся данные в одном столбце или повторяющиеся строки в наборе данных. Приложив немного условного форматирования, вы можете легко выделить дубликаты в Google Таблицах. После того, как вы их выделите, вы можете решить, сохранить их или удалить.
В этом уроке я покажу вам несколько простых способов выделить дубликаты в Google Таблицах .
Выделите повторяющиеся ячейки в столбце
Например, предположим, что у вас есть набор данных, показанный ниже, где вы хотите выделить все имена, повторяющиеся в столбце A.

Ниже приведены шаги по выделению дубликатов в столбце:
Вышеупомянутые шаги выделят все ячейки с повторяющимися именами указанным цветом.

В условном форматировании замечательно то, что оно динамическое . Это означает, что если вы измените данные в любой из ячеек, форматирование обновится автоматически. Например, если вы удалите одно из имен, у которых есть дубликаты, выделение этого имени (в другой ячейке) исчезнет, поскольку теперь оно стало уникальным.
Как это работает?
При использовании настраиваемой формулы в условном форматировании каждая ячейка проверяется по указанной формуле.
Если формула возвращает значение ИСТИНА для ячейки, она выделяется в указанном формате, а если она возвращает ЛОЖЬ, это не так.
В приведенном выше примере проверяется каждая ячейка, и если имя появляется в диапазоне более одного раза, для формулы СЧЁТЕСЛИ возвращается ИСТИНА, и ячейка выделяется. В остальном он остается без изменений.
Также обратите внимание, что я использовал диапазон $ A $ 2: $ A $ 10 (где перед алфавитом столбца и номером строки стоит знак доллара). Это действительно важно, так как гарантирует, что, когда формула переходит в следующую ячейку (в строке ниже), общий диапазон, который проверяется на количество имен, остается неизменным.
Если вы хотите удалить выделенные ячейки, вам необходимо удалить условное форматирование. Для этого выберите ячейки, к которым применено форматирование, щелкните параметр «Формат», щелкните «Условное форматирование» и удалите правило из панели, которая открывается справа.
Выделите повторяющиеся ячейки в нескольких столбцах
В приведенном выше примере у нас были все имена в одном столбце.
Но что, если имена находятся в нескольких столбцах (как показано ниже).
Вы по-прежнему можете использовать условное форматирование, чтобы выделить повторяющиеся имена (которые могут быть именем, которое встречается более одного раза во всех трех столбцах, вместе взятых.
Ниже приведены шаги по выделению дубликатов в нескольких столбцах:
Вышеупомянутые шаги будут выделять ячейку, если имя появляется более одного раза во всех трех выбранных столбцах вместе.

Как это работает?
Этот тоже работал последним.
В формуле СЧЁТЕСЛИ (COUNTIF) мы охватили все ячейки в трех столбцах. Таким образом, каждая ячейка в диапазоне проверяется с использованием указанной формулы и возвращает либо ИСТИНА, либо ЛОЖЬ.
Если есть имя, которое повторяется в любом из столбцов, оно будет выделено в указанном формате.
Опять же, обратите внимание, что я использовал диапазон $ A $ 2: $ C $ 10 (где перед алфавитом столбца и номером строки стоит знак доллара). Это действительно важно, так как гарантирует, что диапазон остается неизменным, в то время как условное форматирование проверяет количество имени в ячейке.
Выделите повторяющиеся строки / записи
Это немного сложно.
Предположим, у вас есть набор данных, как показано ниже, и вы хотите выделить все повторяющиеся записи.
В этом случае запись будет дубликатом, если она имеет точно такое же значение в каждой ячейке в строке (например, в строках 2 и 7 в приведенном выше примере).
Причина, по которой это немного сложно, заключается в том, что теперь вам не нужно проверять отдельные ячейки. Вы должны проверить всю строку и выделить только те строки, в которых повторяются все ячейки.
Но не волнуйтесь, это не так уж и сложно.
Ниже приведены шаги по выделению повторяющихся строк с использованием условного форматирования:
Вышеупомянутые шаги выделят все записи, которые повторяются в наборе данных (как показано ниже).

Как это работает?
Этот работает так же, как наш первый пример (где мы просто выделили ячейки в столбце, в котором были дубликаты).
Но поскольку есть целая строка, которую нам нужно сравнить со всеми другими строками, мы объединили содержимое всех строк и создали одну строку для каждой строки.
Следующая часть формулы создает массив строк, в котором объединено все содержимое ячеек в строке (выполняется конкатенация с использованием знака амперсанда).
Этот массив используется в формуле Countif, и используемое условие снова представляет собой объединенную строку, которая имеет все значения в строке. Это делается с использованием следующих критериев:
Теперь это преобразовано в простую конструкцию типа столбца, в которой функция COUNTIF проверяет, сколько раз эта объединенная строка повторяется в созданном нами массиве строк.
В результате будут выделены все повторяющиеся записи.
Иногда может случиться так, что вы выполните все вышеперечисленные шаги и используете те же формулы, но Google Таблицы по-прежнему не выделяют дубликаты.
Вот несколько возможных причин, по которым вы можете проверить:
Лишние места в камерах
Есть ли лишние пробелы (начальные или конечные пробелы) в тексте в одной ячейке, а не в другой?
Поскольку мы ищем точное совпадение двух или более ячеек, которые будут считаться дубликатами, если в ячейках есть лишние пробелы, это приведет к несоответствию.
Поэтому, даже если вы видите дубликат, он может не выделиться.
Чтобы избавиться от этого, вы можете использовать функцию TRIM (и функцию CLEAN), чтобы избавиться от всех лишних пробелов.
Неправильная ссылка
В Google Таблицах есть три разных типа ссылок.
Если формула требует одного типа ссылки, а вы в конечном итоге используете другие, у вас, скорее всего, возникнет проблема.
Поэтому проверьте ссылки, чтобы убедиться, что Google Таблицы выделяют дубликаты должным образом.
Таким образом, вы можете выделить дубликаты в Google Таблицах с помощью условного форматирования.
Хорошей новостью является то, что таблицы Google предоставляют вам несколько простых способов, позволяющих быстро находить уникальные значения в ваших данных .
В этом руководстве я покажу вам два простых метода, которые вы можете использовать для быстрого поиска уникальных значений из данных одного столбца или данных нескольких столбцов.
- С помощью встроенного в Google Таблицы инструмента « Удалить дубликаты ».
- Использование функции UNIQUE .
Предположим, у нас есть следующий набор данных, из которого мы хотим удалить повторяющиеся записи:

Обратите внимание, что в строках 2 и 5, а также в строках 6 и 7 есть повторяющиеся записи.

Мы рассмотрим, как использовать два упомянутых метода для удаления этих повторяющихся записей из набора данных.
В этом руководстве я покажу вам, как найти уникальные значения, когда у вас есть несколько столбцов. Вы можете использовать те же методы, если у вас есть данные в одном столбце.
Поиск уникальных значений с помощью инструмента «Удалить дубликаты»
Вот шаги, которые вам необходимо выполнить:
Теперь вы должны обнаружить, что строки 5 и 7 удалены. Это связано с тем, что, когда инструмент «Удалить дубликаты» находит повторяющиеся значения, он сохраняет только первое вхождение значения, удаляя все остальные.

Если вы хотите удалить все строки, содержащие дубликаты имени, вы можете просто снять флажок рядом со столбцом B в диалоговом окне «Удалить дубликаты» (шаг 5).

В этом случае вам придется удалить три повторяющихся строки, поскольку строка, содержащая имя Пола Родригеса, также считается дубликатом.

Тогда ваш результирующий набор данных будет следующим.

Поиск уникальных значений с помощью функции UNIQUE
Инструмент «Удалить дубликаты» работает с исходным набором данных. Поэтому, когда он удаляет дубликаты, он изменяет исходные данные. Если, однако, вы хотите сохранить исходный набор данных, то лучшим вариантом будет использование функции UNIQUE.
Синтаксис функции UNIQUE
Синтаксис функции UNIQUE:
Диапазон может включать в себя либо диапазон имен столбцов, либо диапазон ссылок на ячейки. Функция покажет результат, начиная с ячейки, в которую вы ввели формулу.
Использование уникальной функции для поиска уникальных значений в Google Таблицах
Давайте поработаем с тем же набором данных, чтобы понять, как применяется функция UNIQUE.
Чтобы вы могли легко увидеть различия между исходными и результирующими данными, мы собираемся отобразить результат на том же листе (в соседнем диапазоне ячеек). Однако вы даже можете ввести УНИКАЛЬНУЮ формулу на новом листе и отобразить там уникальные записи.
Вот шаги, которые вам необходимо выполнить, если вы хотите использовать функцию UNIQUE для удаления дубликатов из указанного выше набора данных:

Теперь вы должны увидеть, что набор уникальных записей занимает диапазон от ячейки D1 до E8.
Обратите внимание, что функция UNIQUE позволяет динамически удалять дубликаты, поэтому любые изменения, которые вы вносите в исходный набор данных, автоматически обновляются для вывода функции.
Фактически, основное различие между двумя методами, описанными в этом руководстве, заключается в том, что инструмент «Удалить дубликаты» работает и изменяет исходный диапазон данных.
Функция UNIQUE, с другой стороны, отображает уникальные данные в новом диапазоне данных, тем самым сохраняя исходные данные неизменными.
Если вы хотите сохранить результаты функции UNIQUE (чтобы вы могли выполнять с ней последующие операции), вам необходимо преобразовать результат формулы в статические значения.
Для этого вам нужно выделить ячейки, содержащие результат, и скопировать их. Затем используйте сочетание клавиш CTRL + SHIFT + V (на ПК) или CMD + SHIFT + V (на Mac), чтобы вставить значения скопированных ячеек.
В этом руководстве мы показали вам два способа найти уникальные значения в Google Таблицах , удалив дубликаты. Первый метод использует встроенную функцию «Удаление дубликатов» в Google Таблицах. Вы можете использовать этот метод для удаления дубликатов и замены исходных данных только уникальными записями.
Второй метод использует УНИКАЛЬНЫЙ метод. Этот метод идеален, если вы не хотите вносить какие-либо изменения в исходные данные. Оба метода отлично работают и быстро справляются со своей задачей.
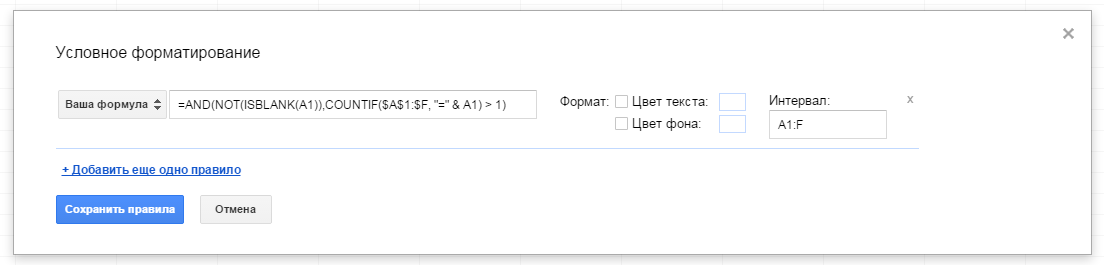

COUNTIF($A$1:$F; " separator" style="clear: both; text-align: left"> Подход будет несколько иным. Необходимо учитывать порядок, в котором форматирование будет накладываться. Если программа будет выполнена на первом условии, то остальные просто не будут проверены. Главное меню Таблицы - Формат - Условное форматирование .

- Получить ссылку
- Электронная почта
- Другие приложения
Комментарии

Отлично, очень рад! Только сегодня добавил новый пример в Таблицу, посмотрие, если интересно.
Круто! Кстати, добавил новый пример в Таблицу.
Спасибо! только вот для одного столбца нужно было, додумывал сам)
Пожалуйста!
Этот вопрос пытался описать в пояснении "сравнивает в диапазоне $A$1:$F". Для одной колонки необходимо изменить диапазон, например, на "$A$1:$A"
А вот интересно, можно ли сравнивать значения с разных листов? Есть второй лист с текстовыми данными. Надо, чтобы в первом листе подсвечивались данные, которые встречаются во втором листе. В первом листе могут быть повторяющиеся значения. Их выделять мне не нужно.
Да, для этого необходимо ссылаться на данные соседнего листа через формулу INDIRECT.
=И(НЕ(ЕПУСТО(A1)), СЧЁТЕСЛИ($A$1:$G, "=" ДВССЫЛ("Чёрныйсписок!"&A1) > 1))
Эта формула выдаёт ошибку. Не пойму что не так.
"сравнивает в диапазоне $A$1:$F количество значений равных A1 с единицей" Вот эту фразу вообще не понял. Что за значения равные А1?
Действительно, что-то запутано. Можете привести пример в Таблице? Я пока вижу две ошибки: (1) запятые, вместо точек с запятой, (2) сложная интерпретация "Чёрныйсписок!"&A1, которая, возможно, посто неверная.
Добрый день, можете пожалуйста привести пример, где сравнение идет с конкретным столбцом на другом листе, а не по всему другому листу?

Присоединюсь к просьбе
Подскажите, пожалуйста, как допилить формулу, чтобы определенные повторяющиеся значения не учитывались и не выделялись?
Например: Есть столбец с номерами договоров и нужно выделить повторяющиеся, но при этом в этом же столбце есть значения "б/н" и "на почту", которые не нужно учитывать при выделении.
Необходимо расширить проверку условия COUNTIF до нескольких параметров. Это можно сделать несколькими способами. Приведите пример Таблицы.
Что то не получается! Точно знаю что есть одно повторения в столбце из 50 ячеек, функция "удалить дубликаты" убирает 1 ячейку и смещает вверх столбец, что тоже скверное решение(((( Почему не работает? Просто окрашивает весь столбец в серый цвет(
Лучше с примером.
Добрый день. Подскажите пожалуйста, например, у меня в ячейке А1 - "Номер 1", а в ячейке В1 - "22.07.2019" (Любая дата). Как сделать подсветку если, и в столбце "А" и в столбце "В" есть совпадения и по Номеру и по Дате (А3 "Номер 1", В3 "22.07.2019? Надеюсь понятно написал)
Спасибо огромное! Очень выручили
И он выделяет их как совпадение ибо есть начальное совпадение. А мне необходимо что бы он сравнивал только то что идет после ID
Заранее спасибо
Я обнаружил, что у вас там было два правила условного форматирования. Первое перекрывало второе.
Формула для колонки отличается от формулы для диапазона. Должно быть =AND(NOT(ISBLANK(D1)); COUNTIF($D$1:$D; "=" &D1) > 1) для колонки D. Поправил у вас в Таблице.
Попробовала, у меня не работает
К сожалению, без вашего примера нет возможности представить, что там пошло не так. Пришлите пример.
Работает. Спасибо большое !
Добрый день. Подскажите как прописать формулу для документа из нескольких листов с текстовыми и цифровыми данными.
Надо, чтобы в любом листе подсвечивались данные, которые встречаются на других листах.
Ваша формула прекрасно работает для одного листа - не получается переписать ее для нескольких листов.
Ага, понятно. Я добавлю этот пример в Таблицу к посту чуть позже. Отпишусь.
Таблицы Google можно использовать для выделения дубликатов в электронной таблице. Отображение повторов полностью настраивается в параметрах стиля форматирования. Это может быть использовано для обозначения конкретных причин, по которым дубликат был выделен, так что это имеет смысл для всех, кто просматривает данные. Например, вы можете выделить всю строку данного столбца, содержащую любые дубликаты. Или, в качестве альтернативы, его также можно отформатировать, чтобы просто выделить любую ячейку со значением, которое встречается в электронной таблице более одного раза.
Простое и краткое руководство ниже покажет вам, как выделить дубликаты в Google Таблицах.
Выделение дубликатов в одном столбце

Чтобы выделить повторяющиеся ячейки с помощью функции условного форматирования, выполните следующие действия.
Выберите диапазон, с которым вы хотите использовать инструмент форматирования. (показано ниже).

В нашем примере это диапазон A1: A12. Диапазон можно выбрать, щелкнув правой кнопкой мыши «Формат» вверху страницы и выбрав «Условное форматирование». (пример показан ниже).
Щелкните правой кнопкой мыши «Форматировать».

Выберите «Условное форматирование».

Этот запрос должен отображаться при выборе «Условное форматирование». Здесь может быть показан диапазон, обозначенный красным прямоугольником. Если у вас уже есть правило условного форматирования, просто выберите «добавить другое правило», прежде чем продолжить. (показано ниже)

Выбор определенного диапазона достигается щелчком по значку «четыре квадрата» в конце поля, содержащего диапазон данных. (показано ниже)

После щелчка по значку, упомянутому выше, вы должны увидеть подсказку с просьбой выбрать диапазон данных, с помощью которого вы хотите отформатировать электронную таблицу. (пример показан ниже)

После отображения вышеупомянутого запроса просто перетащите курсор на данные, о которых идет речь, чтобы выделить их, выбрав нужный диапазон.
В правилах условного форматирования вы также можете указать «стиль форматирования», т.е. использование полужирного или курсивного шрифта или установка определенного цвета для выделения дубликатов. Можно использовать разные цвета для разных индивидуальных правил, чтобы обозначить разные причины выделения. Для этого выберите один из вариантов, отображаемых в разделе «Стиль форматирования». (показано ниже)

Таблицы Google в нужном столбце теперь выделяют цветом, который мы выбрали, дубликаты в нашем случайно отсортированном списке моделей автомобилей курсивом с подчеркиванием.

Выделение дубликатов во всей строке
Чтобы выделить дубликаты во всей строке, как мы делали выше, вам нужно выбрать диапазон, щелкнув правой кнопкой мыши значок с четырьмя квадратами. На этот раз вместо того, чтобы перетаскивать курсор через столбец A, чтобы выделить его, вы вместо этого выделите все столбцы, содержащие строки с дубликатами, которые вы хотите выделить. В нашем примере мы хотим выделить только столбцы A и B. (как показано ниже)

Формула для выделения дубликатов в строке вместо одного столбца получается путем внесения одной небольшой корректировки в исходную формулу. Оригинал =countif($A$1:$A$12,A1)>1 становится =countif($A$1:$A$12,$A1)>1 . Значения в конце круглых скобок изменяются с «, A1» на «, $ A1». Мы просто добавили $ после последней запятой перед A.
Таблицы Google теперь выделяют дубликаты в нашем списке моделей автомобилей и стран их происхождения. (показано ниже)

Я надеюсь, что это руководство помогло вам лучше и эффективнее использовать инструменты условного форматирования в Google Таблицах, и что вы успешно научились выделять дубликаты.
Читайте также: