
Представьте что создана компьютерная программа которая выявляет все возможные ошибкоопасные с точки
Обновлено: 05.07.2024
Задание: Выполните задания и прикрепите ответы в электронном виде.
Выполнить сканирование и лечение локального диска, содержащего зараженные вирусами файлы с помощью не менее чем двух антивирусных программ.
Можно использовать следующие дополнительные утилиты:
Использовать все доступные режимы сканирования этих программ.
Общие характеристики компьютера, на котором выполнялось сканирование, в т.ч. жесткого диска.
Названия и версии антивирусных программ.
Краткое описание режимов работы антивирусных программ.
Сводная таблица результатов сканирования, содержащая следующую информацию для каждого из режимов сканирования:
название режима сканирования,
время сканирования,
количество проверенных объектов,
количество обнаруженных вирусов,
количество зараженных файлов,
количество вылеченных файлов.
![]()
![]()
Антивирус ESET NOD32 представляет собой комплексное решение для защиты компьютера в реальном времени от вирусов, червей, троянов, шпионских программ, фишинга и хакерских атак. Характеризуется эффективным обнаружением вредоносного ПО, наилучшей производительностью и беспрецедентно малым влиянием на системные ресурсы.На сегодняшний день NOD32 – самый быстрый и нетребовательный к ресурсам антивирус. Его работа абсолютно не сказывается на производительности компьютера (воздействие на систему антивирусного монитора составляет всего 6%), а оптимизированный механизм использует менее 20 Мб оперативной памяти. Установка программы занимает… вдохните побольше воздуха… около минуты! Представьте себе, мы тоже очень удивились.
Плюсы NOD32
Незначительное потребление ресурсов. В сравнении с конкурентами, приложение от ESET существенно меньше нагружает систему, при этом, скорость сканирования показывает отличные результаты. Это обусловлено высокой эффективностью взаимодействия с аппаратной частью, благодаря тому что программа написана на низкоуровневом языке программирования Ассемблер.
Кроссплатформенность. Версии NOD32 существуют под все известные платформы: Windows, Linux, OS X и даже для мобильной операционной системы Android. Этот факт доказывает серьезное отношение разработчиков к своему продукту, а у пользователя есть возможность широкого применения.
Технология ThreatSense. На сегодняшний день, когда вирусные угрозы сильно эволюционировали, недостаточно сигнатурного метода обнаружения. ThreatSense является собственной запатентованной технологией компании и основана на эвристическом анализе потенциальных угроз. Как утверждают сами разработчики, она работает на опережение планов вирусописателей. Это не замена основному методу обнаружения, а расширение, которое базируется на совокупности сложных методов и алгоритмов анализа. Данный метод позволяет находить и нейтрализовать угрозы, которых даже нет в базе сигнатур. Приложение осуществляет запуск подозрительного файла в изолированной виртуальной среде и отслеживает его поведение и структуру кода. Если характер действий рассматриваемого объекта несет фатальный характер, антивирус немедленно реагирует, блокируя его, затем уведомляет пользователя и отправляет данные анализа разработчикам.
Система распространения обновлений. Обновления для баз данных сигнатур распространяются достаточно часто, иногда даже несколько раз в день, разработчики «держат руку на пульсе» и стремятся обезопасить пользователей при выявлении новых видов угроз. Пакеты обновлений составляют незначительный объем данных, что упрощает их получение пользователем даже в условиях низкоскоростного и нестабильного подключения к сети интернет. ESET использует систему «зеркальных» серверов, даже если какой-то из них по каким-то причинам выйдет из строя, рассылка обновлений будет осуществляться посредством оставшихся, благодаря чему пользователи в любом случае своевременно получат важные обновления.
Интерфейс. Приложение обладает интуитивно понятным и лаконичным интерфейсом, что упрощает процесс взаимодействия с пользователем. Структура меню настроек позволит с легкостью разобраться даже новичку и настроить антивирус на свое усмотрение.
Глубина сканирования. Специалисты отмечают возможную недостаточность глубины сканирования каталогов с объемной структурой, в результате, некоторые вредоносные объекты могут быть не обнаружены. Для домашнего использования этот недостаток не критичен, так как воссоздать такие условия, когда сканер не сможет проверить все файлы достаточно сложно, к тому же велика вероятность того, что этот недостаток будет устранен разработчиками в будущих релизах.
Ложные срабатывания. Некоторые пользователи замечают ложные срабатывания на файлы, не являющиеся вредоносными. Это происходит достаточно редко и не столь критично, хоть и может вызвать панику у неопытных пользователей.
Ответьте на следующие вопросы.
1. Какие существуют угрозы для информации?
Отрицательное воздействие угроз уменьшается различными методами, направленными с одной стороны на устранение носителей угроз -источников угроз, а с другой на устранение или существенное ослабление факторов их реализации - уязвимостей. Кроме того, эти методы должны быть направлены на устранение последствий реализации угроз.
Среди методов противодействия выделяются следующие основные группы:
При выборе методов парирования угроз (защиты информации) учитываются полученные в ходе анализа коэффициенты опасности каждого источника угроз, уязвимости и коэффициенты групп методов реализации угроз ИБ.
3. Что такое компьютерный вирус? Какими свойствами обладают компьютерные вирусы?
Прежде всего компьютерный вирус — это программа, обладающая способностью к самовоспроизведению. Такая способность является единственным средством, присущим всем типам вирусов.
Вирус не может существовать в «полной изоляции»: нельзя представить себе вирус, который не использует код других программ, информацию о файловой структуре или даже просто имена других программ. Причина понятна: вирус должен каким-нибудь способом обеспечить передачу себе управление.
Компьютерный вирус - специально написанная программа, способная самопроизвольно присоединяться к другим программам, создавать свои копии и внедрять их в файлы, системные области компьютера и в вычислительные сети с целью нарушения работы программ, порчи файлов и каталогов, создания всевозможных помех в работе компьютера.
среде обитания;
способу заражения среды обитания;
воздействию;
особенностям алгоритма.
По способу заражения вирусы делятся на резидентные и нерезидентные. Резидентный вирус при заражении (инфицировании) компьютера оставляет в оперативной памяти свою резидентную часть, которая потом перехватывает обращение операционной системы к объектам заражения (файлам, загрузочным секторам дисков и т. п.) и внедряется в них. Резидентные вирусы находятся в памяти и являются активными вплоть до выключения или перезагрузки компьютера. Нерезидентные вирусы не заражают память компьютера и являются активными ограниченное время.
4.Опишите схему функционирования файлового вируса.
В отличие от загрузочных вирусов, которые практически всегда резидентны, файловые вирусы совсем не обязательно резидентны. Рассмотрим схему функционирования нерезидентного файлового вируса. Пусть у нас имеется инфицированный исполняемый файл. При запуске такого файла вирус получает управление, производит некоторые действия и передает управление "хозяину"
он не обязан менять длину файла
неиспользуемые участки кода
не обязан менять начало файла
Таким образом, при запуске любого файла вирус получает управление (операционная система запускает его сама), резидентно устанавливается в память и передает управление вызванному файлу.
5. Каковы пути проникновения вирусов в компьютер и признаки заражения компьютера вирусом?
Основными путями проникновения вирусов в компьютер являются съемные диски (гибкие и лазерные), а также компьютерные сети. Заражение жесткого диска вирусами может произойти при загрузке программы с дискеты, содержащей вирус. Такое заражение может быть и случайным, например, если дискету не вынули из дисковода и перезагрузили компьютер, при этом дискета может быть и не системной. Заразить дискету гораздо проще. На нее вирус может попасть, даже если дискету просто вставили в дисковод зараженного компьютера и, например, прочитали ее оглавление.
Вирус, как правило, внедряется в рабочую программу таким образом, чтобы при ее запуске управление сначала передалось ему и только после выполнения всех его команд снова вернулось к рабочей программе. Получив доступ к управлению, вирус, прежде всего, переписывает сам себя в другую рабочую программу и заражает ее. После запуска программы, содержащей вирус, становится возможным заражение других файлов.
Наиболее часто вирусом заражаются загрузочный сектор диска и исполняемые файлы, имеющие расширения EXE, COM, SYS, BAT. Крайне редко заражаются текстовые файлы.
После заражения программы вирус может выполнить какую-нибудь диверсию, не слишком серьезную, чтобы не привлечь внимания. И, наконец, не забывает возвратить управление той программе, из которой был запущен. Каждое выполнение зараженной программы переносит вирус в следующую. Таким образом, заразится все программное обеспечение.
![]()
Начинаю серию уроков (мини-курс) о распознавании изображений и обнаружении объектов.
Мини-курс, который я пишу, будет состоять из 8 уроков по приблизительно следующей тематике:
- Распознавание изображений с использованием традиционных методов компьютерного зрения
- Обнаружение объектов с использованием традиционных методов компьютерного зрения
- Как обучить и протестировать собственный детектор объектов OpenCV
- Распознавание изображений с использованием глубокого обучения



Краткая история распознавания изображений и обнаружения объектов
При таком огромном успехе в распознавании изображений обнаружение объектов на основе глубокого обучения было неизбежным. Такие методы, как Faster R-CNN, производят челюсти. Отбрасывание результатов по нескольким классам объектов. Мы узнаем об этом в следующих публикациях, но пока имейте в виду, что если вы не изучили алгоритмы распознавания изображений и обнаружения объектов на основе глубокого обучения для своих приложений, вы можете упустить огромную возможность получить лучшие результаты.
Распознавание изображений (также известное как классификация изображений)
Чтобы упростить задачу, в этом посте мы сосредоточимся только на двухклассовых (бинарных) классификаторах. Вы можете подумать, что это очень ограничивающее предположение, но имейте в виду, что многие популярные детекторы объектов (например, детектор лиц и детектор пешеходов) имеют под капотом бинарный классификатор. Например, внутри детектора лиц находится классификатор изображений, который сообщает, является ли участок изображения лицом или фоном.
Анатомия классификатора изображений

На следующей диаграмме показаны этапы работы традиционного классификатора изображений.
Интересно, что многие традиционные алгоритмы классификации изображений компьютерного зрения следуют этому конвейеру, в то время как алгоритмы, основанные на глубоком обучении, полностью обходят этап извлечения признаков. Давайте рассмотрим эти шаги более подробно.
Шаг 1: предварительная обработка
Обратите внимание, что я не прописываю, какие шаги предварительной обработки являются хорошими. Причина в том, что никто заранее не знает, какой из этих шагов предварительной обработки даст хорошие результаты. Вы пробуете несколько разных, и некоторые из них могут дать немного лучшие результаты. Вот абзац из Далала и Триггса
Мы оценили несколько представлений входных пикселей, включая цветовые пространства в оттенках серого, RGB и LAB, опционально со степенным (гамма) выравниванием. Эти нормализации имеют лишь умеренное влияние на производительность, возможно, потому, что последующая нормализация дескриптора дает аналогичные результаты. Мы используем информацию о цвете, когда она доступна. Цветовые пространства RGB и LAB дают сравнимые результаты, но ограничение оттенками серого снижает производительность на 1,5% при 10–4 кадрах в секунду. Гамма-сжатие с квадратным корнем для каждого цветового канала улучшает производительность при низких значениях FPPW (на 1% при 10–4 кадрах в секунду), но логарифмическое сжатие слишком велико и ухудшает его на 2% при 10–4 кадрах в секунду.
Как вы видете, авторы не знали заранее, какую предварительную обработку использовать. Они делали разумные предположения и использовали метод проб и ошибок.
В рамках предварительной обработки входное изображение или фрагмент изображения также обрезаются и изменяются до фиксированного размера. Это важно, потому что следующий шаг, извлечение признаков, выполняется на изображении фиксированного размера.
Шаг 2: извлечение признаков
В качестве конкретного примера давайте посмотрим на извлечение признаков с помощью гистограммы ориентированных градиентов (HOG).
Histogram of Oriented Gradients (HOG) или гистограмма направленного градиента
Алгоритм извлечения признаков преобразует изображение фиксированного размера в вектор признаков фиксированного размера. В случае обнаружения пешеходов дескриптор объекта HOG вычисляется для фрагмента изображения размером 64 \times 128 и возвращает вектор размером 3780 . Обратите внимание, что исходный размер этого фрагмента изображения был 64 \times 128 \times 3 = 24,576 , который сокращен до 3780 дескриптором HOG.
HOG основан на идее, что внешний вид локального объекта может быть эффективно описан распределением (гистограммой) направлений краев (направленных градиентов). Шаги по вычислению дескриптора HOG для изображения размером 64 × 128 перечислены ниже.
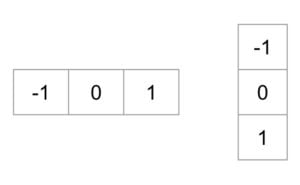
Расчет градиента: вычисление градиентов x и y изображений и, исходя из исходного изображения. Это можно сделать, отфильтровав исходное изображение следующими ядрами.
-
Используя изображения градиента и, можно вычислить величины g_x и g_y направления градиента, используя следующие уравнения:
Шаг 3: алгоритм классификации (подробнее)
В предыдущем разделе мы узнали, как преобразовать изображение в вектор признаков. В этом разделе мы узнаем, как алгоритм классификации принимает этот вектор признаков в качестве входных данных и выводит метку класса (например, кошка или фон).
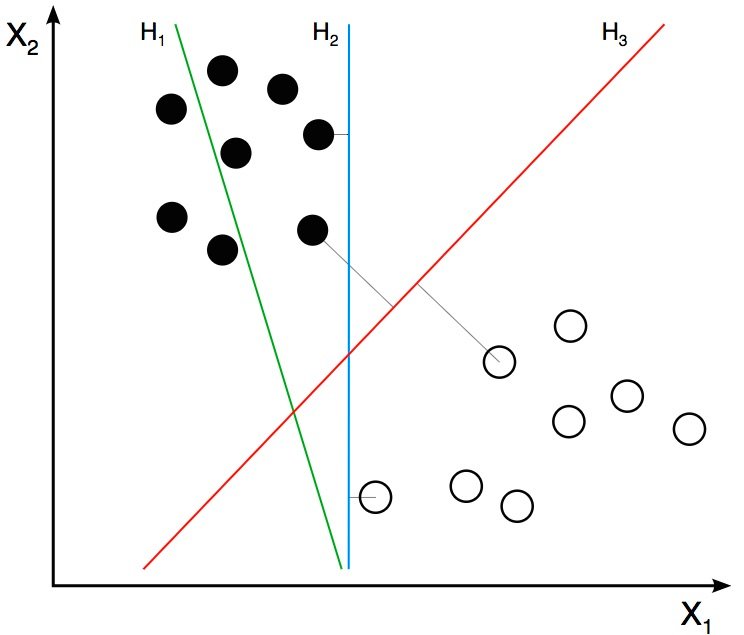
На предыдущем шаге мы узнали, что дескриптор HOG изображения является вектором признаков длиной 3 780. Мы можем думать об этом векторе как о точке в 3 780-мерном пространстве. Визуализировать пространство большого измерения невозможно, поэтому немного упростим ситуацию и представим, что вектор признаков был двухмерным.
Оптимизация SVM
Пока все хорошо, но я знаю, что у вас есть один важный вопрос, на который нет ответа. Что, если объекты, принадлежащие двум классам, нельзя разделить с помощью гиперплоскости? В таких случаях, SVM по-прежнему находит лучшую гиперплоскость, решая задачу оптимизации, которая пытается увеличить расстояние гиперплоскости от двух классов, одновременно пытаясь обеспечить правильную классификацию многих обучающих примеров. Этот компромисс контролируется параметром C. Когда значение C мало, выбирается гиперплоскость с большим запасом за счет большего числа ошибочных классификаций. И наоборот, когда C велико, выбирается гиперплоскость меньшего поля, которая пытается правильно классифицировать гораздо больше примеров.
Теперь вы можете быть сбиты с толку, какое значение выбрать для C. Выберите то значение, которое лучше всего работает на тестовом наборе, которого не было в обучающей выборке.
Читайте также: