
При каких ошибках программа не компилируется
Обновлено: 05.07.2024
Перед написанием нашей первой программы мы еще должны кое-что узнать.
Теория
Во-первых, несмотря на то, что код ваших программ находится в файлах .cpp, эти файлы добавляются в проект. Проект содержит все необходимые файлы вашей программы, а также сохраняет указанные вами настройки вашей IDE. Каждый раз, при открытии проекта, он запускается с того момента, на котором вы остановились в прошлый раз. При компиляции программы, проект говорит компилятору и линкеру, какие файлы нужно скомпилировать, а какие связать. Стоит отметить, что файлы проекта одной IDE не будут работать в другой IDE. Вам придется создать новый проект (в другой IDE).
В-третьих, при создании нового проекта большинство IDE автоматически добавят ваш проект в рабочее пространство. Рабочее пространство — это своеобразный контейнер, который может содержать один или несколько связанных проектов. Несмотря на то, что вы можете добавить несколько проектов в одно рабочее пространство, все же рекомендуется создавать отдельное рабочее пространство для каждой программы. Это намного упрощает работу для новичков.
Традиционно, первой программой на новом языке программирования является всеми известная программа «Hello, world!». Мы не будем нарушать традиции 🙂
Пользователям Visual Studio
Для создания нового проекта в Visual Studio 2019, вам нужно сначала запустить эту IDE, затем выбрать "Файл" > "Создать" > "Проект" :

Дальше появится диалоговое окно, где вам нужно будет выбрать "Консольное приложение Windows" из вкладки "Visual C++" и нажать "ОК" :

Также вы можете указать имя проекта (любое) и его расположение (рекомендую ничего не менять) в соответствующих полях.
В текстовом редакторе вы увидите, что уже есть некоторый текст и код — удалите его, а затем напечатайте или скопируйте следующий код:
GNU Compiler Collection (обычно используется сокращение GCC) — набор компиляторов для различных языков программирования, разработанный в рамках проекта GNU. GCC является свободным программным обеспечением, распространяется фондом свободного программного обеспечения на условиях GNU GPL и GNU LGPL и является ключевым компонентом GNU toolchain. Проект написан на языке C и C++.
Компилятор GCC имеет хорошие встроенные диагностики, помогающие выявлять многие ошибки на этапе компиляции. Естественно, GCC собирается с помощью GCC и, соответственно, может выявлять ошибки в собственном коде. Дополнительно исходный код GCC проверяется с помощью анализатора Coverity. Да и вообще, думаю GCC проверялся энтузиастами с помощью многих анализаторов и других инструментов. Это делает поиск ошибок в GCC большим испытанием для анализатора кода PVS-Studio.
Примечание. Статья задержалась с выходом, и возможно какие-то ошибки уже исправлены. Но это не имеет значения: постоянно появляются новые ошибки, старые исчезают. Главное — статья показывает, что статический анализ может помогать программистам выявлять ошибки после их появления.
Предвидя дискуссию
Как я сказал во введении, я считаю GCC проектом с высоким качеством кода. Уверен, многие захотят поспорить. В качестве примера приведу цитату из Wikipedia на русском языке:
Некоторые разработчики OpenBSD, например Тео де Раадт и Отто Мурбек (Otto Moerbeek), критикуют GCC, называя его «громоздким, глючным, медленным и генерирующим плохой код».
Я считаю такие заявления необоснованными. Да, возможно, код GCC содержит много макросов, которые затрудняют его чтение. Но я никак не могу согласиться с заявлением о его глючности. Если бы GCC глючил, вообще бы нигде ничего не работало. Вы только вспомните, как много программ им компилируется и успешно работает. Создатели GCC делают огромную, сложную работу с большим профессионализмом. Спасибо им. Я рад, что могу протестировать работу PVS-Studio на таком высококачественном проекте.
Для тех, кто скажет, что код компилятора Clang всё равно круче, напомню: в нём PVS-Studio также находил ошибки: 1, 2.
PVS-Studio
Я проверил код GCC с помощью Alpha-версии анализатора PVS-Studio for Linux. Мы планируем начать выдавать заинтересовавшимся программистам Beta-версию анализатора в середине сентября 2016 года. Инструкцию о том, как стать одним из первых, кто сможет попробовать Beta-версию PVS-Studio for Linux на своём проекте, вы найдете в статье "PVS-Studio признаётся в любви к Linux".
Результаты проверки
К сожалению, я не могу выдать разработчикам компилятора полный отчёт. В нем пока слишком много мусора (ложных срабатываний), связанных с тем, что анализатор не полностью готов к встрече с миром Linux. Нужно проделать работу по уменьшению количества ложных предупреждений на типовые используемые конструкции. Попробую пояснить на одном простом примере. Многие диагностики не должны ругаться на выражения, относящиеся к макросам assert. Эти макросы бывают устроены весьма творчески и надо научить анализатор не обращать на них внимание. Но дело в том, что определяется макрос assert очень по-разному, и надо обучить анализатор всем типовым вариантам.
Поэтому разработчиков GCC прошу подождать выхода по крайней мере Beta-версии анализатора. Я не хочу испортить впечатление отчетом, сгенерированным недоделанной версией.
Классика (Copy-Paste)
Начнем мы с самой классической и распространённой ошибки, которая выявляется с помощью диагностики V501. Как правило, такие ошибки появляются из-за невнимательности при Copy-Paste или просто являются опечатками, допускаемыми при наборе нового кода.
Предупреждение анализатора PVS-Studio: V501 There are identical sub-expressions '!strcmp(a->v.val_vms_delta.lbl1, b->v.val_vms_delta.lbl1)' to the left and to the right of the '&&' operator. dwarf2out.c 1428
Быстро увидеть ошибки проблематично и следует внимательно присмотреться. Именно поэтому ошибка и не была выявлена при обзорах кода и рефакторинге.
Функция strcmp дважды сравнивает одни и те же строки. Мне кажется, второй раз следовало сравнивать не члены класса lbl1, а lbl2. Тогда корректный код должен выглядеть так:
Хочу отметить, что код, приведённый в статье, немного отформатирован, чтобы он занимал мало места по оси X. На самом деле, код выглядит так:

Ошибки, возможно, удалось бы избежать, если использовать «табличное» выравнивание кода. Например, ошибку было бы легче заметить, если отформатировать код так:

Подробнее я рассматривал такой подход в электронной книге "Главный вопрос программирования, рефакторинга и всего такого" (см. главу N13: Выравнивайте однотипный код «таблицей»). Рекомендую всем, кто заботится о качестве своего кода, познакомиться с приведённой здесь ссылкой.
Давайте рассмотрим ещё одну ошибку, которая, я уверен, появилась из-за Copy-Paste:
Предупреждение анализатора PVS-Studio: V519 The 'has_avx512vl' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 500, 501. driver-i386.c 501
В переменную has_avx512vl дважды подряд записываются различные значения. Это не имеет смысла. Я изучил код и обнаружил переменную has_avx512ifma. Скорее всего, именно она и должна инициализироваться выражением ebx & bit_AVX512IFMA. Тогда корректный код должен быть таким:
Опечатка
Продолжу испытание вашей внимательности. Посмотрите на код и, не подсматривая ниже, попробуйте найти ошибку.
Предупреждение анализатора PVS-Studio: V528 It is odd that pointer to 'char' type is compared with the '\0' value. Probably meant: *xloc.file == '\0'. ubsan.c 1472
Здесь программист случайно забыл разыменовать указатель в выражении xloc.file == '\0'. В результате указатель просто сравнивается с 0, т.е. с NULL. Никакого эффекта это не имеет, так как ранее такая проверка уже выполнялась: xloc.file == NULL.
Правильный вариант кода:
Хотя, давайте ещё немного улучшим код. Я рекомендую отформатировать выражение так:
Обратите внимание: теперь, если допустить ту же ошибку, шанс её заметить будет чуть-чуть выше:
Потенциальное разыменование нулевого указателя
Ещё этот раздел можно было бы назвать «стотысячный пример, почему макросы — это плохо». Я очень не люблю макросы и всегда призываю поменьше их использовать. Макросы затрудняют чтение кода, провоцируют появление ошибок, усложняют работу статическим анализаторам. Как мне показалось из недолгого общения с кодом GCC, его авторы очень любят макросы. Я замучался изучать, во что раскрывается тот или иной макрос и возможно поэтому пропустил немало интересных ошибок. Признаюсь, я иногда бываю ленив. Но пару ошибок, связанных с макросами, я всё-таки продемонстрирую.
Предупреждение анализатора PVS-Studio: V595 The 'odr_types_ptr' pointer was utilized before it was verified against nullptr. Check lines: 2135, 2139. ipa-devirt.c 2135
Если раскрыть макрос и убрать всё не относящееся к делу, мы получим следующий код:
В начале указатель разыменовывается, а потом проверяется. Приведёт это к беде на практике или нет, сказать сложно. Все зависит от того, может ли возникнуть ситуация, когда указатель действительно будет равен nullptr. Если такая ситуация невозможна, то следует удалить лишнюю проверку, которая будет вводить в заблуждение людей, поддерживающих код и анализатор кода. Если указатель может быть нулевым, то это серьёзная ошибка, которая требует ещё большего внимания и исправления.
Рассмотрим ещё один аналогичный случай:
Предупреждение анализатора PVS-Studio: V595 The 'list' pointer was utilized before it was verified against nullptr. Check lines: 1627, 1629. sched-int.h 1627
Чтобы увидеть ошибку, нам опять потребуется показать устройство макроса:
Раскрываем макрос и получаем:
И сейчас многие воскликнут: «Стоп, стоп! Здесь нет ошибки. Мы ведь просто получаем указатель на член класса. Никакого разыменования нулевого указателя здесь нет. Да, возможно код не аккуратен, но ошибки здесь нет!».
Всё не так просто. Здесь возникает неопределённое поведение. И то, что такой код может работать на практике, это просто везение. На самом деле, так писать нельзя. Например, оптимизирующий компилятор, увидев list->first, может удалить проверку if (list). Раз мы выполняли оператор ->, значит предполагается, что указатель не равен nullptr. Если это так, то проверять указатель не нужно.
Я написал целую статью на эту тему: "Разыменовывание нулевого указателя приводит к неопределённому поведению". Там как раз рассматривается аналогичный случай. Прежде чем спорить, прошу внимательно познакомиться с этой статьёй.
Впрочем, рассмотренная ситуация действительно сложна и неочевидна. Я допускаю, что могу быть всё-таки неправ и ошибки здесь нет. Однако, до сих пор мне никто не смог это доказать. Будет интересно услышать комментарии разработчиков GCC, если они обратят внимание на эту статью. Уж они-то точно должны знать, как работает компилятор и следует ли интерпретировать такой код как ошибочный, или нет.
Использование разрушенного массива
Предупреждение анализатора PVS-Studio: V507 Pointer to local array 'buf' is stored outside the scope of this array. Such a pointer will become invalid. hsa-dump.c 704
Строка формируется во временном буфере buf. Адрес этого временного буфера сохраняется в переменной name и используется далее в теле функции. Ошибка в том, что после записи буфера в переменную name, сам этот буфер будет уничтожен.
Использовать указатель на разрушенный буфер нельзя. Формально мы имеем дело с неопределённым поведением. На практике этот код может вполне успешно работать. Корректная работа программы — это один из вариантов проявления неопределенного поведения.
Выполнение одинаковых действий, независимо от условия
Анализатор выявил участок кода, который однозначно я не могу идентифицировать как ошибочный. Однако, крайне подозрительно выполнить проверку, а потом, независимо от её результата, выполнять одни и те же действия. Конечно, возможно, это задел на будущее и пока всё корректно, но проверить этот участок кода явно стоит.
Предупреждение анализатора PVS-Studio: V523 The 'then' statement is equivalent to the 'else' statement. tree-ssa-threadupdate.c 2596
Избыточное выражение вида (A == 1 || A != 2)
Предупреждение анализатора PVS-Studio: V590 Consider inspecting this expression. The expression is excessive or contains a misprint. gensupport.c 1640
Нас интересует условие: (alt < 2 || *insn_out == '*' || *insn_out != '@')
Его можно сократить до: (alt < 2 || *insn_out != '@')
Рискну предположить, что оператор != следует заменить на ==. Тогда код примет более осмысленный вид:
Обнуление не того указателя
Рассмотрим функцию, занимающуюся освобождением ресурсов:
Предупреждение анализатора PVS-Studio: V519 The 'bb_copy' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 1076, 1078. cfg.c 1078
Обратите внимание на эти 4 строчки кода:
Случайно дважды обнуляется указатель bb_copy. Правильный вариант:
Assert, который ничего не проверят
Неправильное условие, являющееся аргументом макроса gcc_assert не повлияет на корректность работы программы, но усложнит поиск ошибки, если таковая возникнет. Рассмотрим код:
Предупреждение анализатора PVS-Studio: V502 Perhaps the '?:' operator works in a different way than it was expected. The '?:' operator has a lower priority than the '<=' operator. dwarf2out.c 2053
Приоритет тернарного оператора ?: ниже, чем у оператора сравнения <=. Это значит, что мы имеем дело с условием вида:
Таким образом, второй операнд оператора && может принимать значение 0xffff или 0xffffffff. Оба эти значения обозначают истину, поэтому выражение можно упростить до:
Оператор ?: очень коварен и его лучше не использовать в сложных выражениях. Уж очень легко допустить ошибку. У нас собрано большое количество примеров таких ошибок, найденных анализатором PVS-Studio в различных открытых проектах. Подробнее об операторе ?: я писал в уже упомянутой ранее книге (см. главу N4: Бойтесь оператора ?: и заключайте его в круглые скобки).
Кажется, забыли про «cost»
Структура alg_hash_entry объявлена следующим образом:
В функции synth_mult программист решил проверить, тот ли это объект, который ему нужен. Для этого ему требуется сравнить поля структуры. Однако, кажется в этом месте допущена ошибка:
Предупреждение анализатора PVS-Studio: V501 There are identical sub-expressions 'entry_ptr->mode == mode' to the left and to the right of the '&&' operator. expmed.c 2573
Дубликаты присваиваний
Следующие участки кода, на мой взгляд, не представляют опасности и, кажется, дублирующееся присваивание можно просто удалить.
Предупреждение анализатора PVS-Studio: V519 The 'structures' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 842, 845. gengtype.c 845
Предупреждение анализатора PVS-Studio: V519 The 'nargs' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 39951, 39952. i386.c 39952
Последний случай более странный, чем остальные. Возможно, тут есть какая-то ошибка. Переменной steptype значение присваивается 2 или 3 раза. Это подозрительно.
Предупреждение анализатора PVS-Studio: V519 The 'steptype' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 5173, 5174. tree-ssa-loop-ivopts.c 5174
Заключение
Я рад, что написал эту статью. Теперь мне есть что отвечать на комментарии вида «PVS-Studio не нужен, так как все те же предупреждения выдаёт и GCC». Как видите, PVS-Studio очень мощный инструмент и превосходит по диагностическим возможностям GCC. Я не отрицаю, что в GCC реализованы отличные диагностики. Этот компилятор, при должной настройке, действительно выявляет много проблем в коде. Но PVS-Studio — это специализированный и быстро развивающийся инструмент, а это значит, он всегда будет лучше выявлять ошибки в коде, чем это делают компиляторы.
Приглашаю познакомиться с проверками других известных открытых проектов, посетив этот раздел нашего сайта. А также, тем, кто использует Twitter, последовать за мной @Code_Analysis. Я регулярно публикую ссылки на интересные статьи по программированию на языке C и C++, а также рассказываю о новых достижениях нашего анализатора.

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey karpov. Bugs found in GCC with the help of PVS-Studio.
У меня нет ошибок. Почему это? Должны ли быть, по крайней мере, ошибки связи? Обратите внимание, что я просто говорю о компиляции файлов - не запуская их. Запуск дает ошибку сегментации.
спросил(а) 2020-03-19T18:01:15+03:00 1 год, 8 месяцев назадДолжна ли быть ошибка компоновщика?
Краткий ответ на вопрос "Не должно быть, по крайней мере, связывать ошибки?" "Существует никаких гарантий, что будет ошибка связи". Стандарт C не предусматривает этого.
Ответ на языковой барьер заключается в том, что стандарт не требует диагностики для этой ошибки. Практический ответ заключается в том, что C не набирает шрифты с внешней связью, поэтому несоответствие типов не обнаружено.
Одна из причин, по которой С++ имеет тип-безопасную связь, заключается в том, чтобы избежать проблем с кодом, аналогичным этому (хотя основная причина заключается в том, чтобы разрешить перегрузку имен функций - разрешение такой проблемы, возможно, является более побочным эффектом).
В стандарте C говорится:
Связывание выполняется на основе имен внешних определений, а не типов объектов, идентифицируемых именем. Бремя зависит от программиста, чтобы гарантировать, что тип функции или объекта для каждого внешнего определения согласуется с тем, как он используется.
Избежать проблемы
Этот [вопрос] является аргументом в пользу использования заголовков для обеспечения согласованности различных частей программы. Если вы никогда не объявляете внешнюю функцию в исходном файле, а только в заголовках, и используете заголовки везде, где используется или определен соответствующий символ (в данном случае weird ), код не будет компилироваться. Вы можете либо иметь функцию, либо строку, но не обе. У вас будет заголовок weird.h , который содержит либо extern char *weird; , либо extern int weird(int *p); (но не оба), и оба main.c и weird.c будут включать заголовок, и только один из них будет скомпилирован успешно.
Для чего пришел ответ:
Что я могу добавить к этим файлам, чтобы убедиться, что ошибка обнаружена и выбрана при компиляции main.c ?
Вы создали бы 3 исходных файла. Показанный здесь код немного сложнее, чем вы обычно использовали, поскольку он позволяет использовать условную компиляцию для компиляции кода либо с помощью функции, либо с помощью переменной "внешний идентификатор с внешней связью", называемой weird . Как правило, вы выбираете одно преднамеренное представление для weird и только разрешаете его открывать.
weird.h
main.c
weird.c
Допустимые последовательности компиляции
Оба они работают, потому что код скомпилирован для использования функции weird() . Заголовок в обоих случаях гарантирует согласованность компиляций.
Неверная последовательность компиляции
Это в основном то же самое, что и установка в вопросе. Файл weird.c скомпилирован для создания строки с именем weird , но код main.c скомпилирован, ожидая использования функции weird() . Компилятор связывает код, но все происходит катастрофически неправильно, когда вызов функции в main() перенацеливается на "weird" . Скорее всего, память, в которой он хранится, не является исполняемым, и из-за этого выполнение не выполняется. В противном случае строка интерпретируется как машинный код и, вероятно, не делает ничего значимого и приводит к сбою. Не желательно; ни гарантировано - это результат вызова поведения undefined.
Если вы попытались скомпилировать main.c с помощью -DUSE_WEIRD_STRING , компиляция завершится неудачно, потому что заголовок указывает, что weird является char * , и код попытается использовать его как функцию.
Если вы заменили условный код в weird.c либо строкой, либо функцией (безусловно), то:
-
Либо компиляция завершилась неудачно, если файл содержал функцию, а -DUSE_WEIRD_STRING был установлен в командной строке,
Или компиляция завершится неудачно, если файл содержит строку, но вы не установили -DUSE_WEIRD_STRING .
Обычно заголовок будет содержать безусловное объявление для weird либо как функцию, либо как указатель (но без каких-либо условий для выбора между ними во время компиляции).
Ключевым моментом является то, что заголовок включен в оба исходных файла, поэтому, если флаги условной компиляции не изменят, компилятор может проверить код в исходных файлах на согласованность с заголовком, и, следовательно, два объектных файла стоят шанс совместной работы. Если вы отклоните проверку, установив флаги компиляции, чтобы два исходных файла увидели разные объявления в заголовке, вы вернетесь к квадрату.
Таким образом, заголовок объявляет интерфейсы, а исходные файлы проверяются для обеспечения их соответствия интерфейсу. Заголовки - это клей, который удерживает систему вместе. Следовательно, любая функция (или переменная), к которой необходимо получить доступ за пределами исходного файла, должна быть объявлена в заголовке (только один заголовок), и этот заголовок должен использоваться в исходном файле, где определена функция (или переменная), а также в каждом исходном файле, который ссылается на функцию (или переменную). Вы не должны писать extern … weird …; в исходном файле; такие объявления принадлежат заголовку. Все функции (или переменные), которые не указаны вне исходного файла, где они определены, должны быть определены с помощью static . Это дает вам максимальную вероятность обнаружения проблем перед запуском программы.
Вы можете использовать GCC, чтобы помочь вам. Для функций вы можете настаивать на том, что прототипы находятся в области видимости до того, как ссылается или определяется функция (не static ) (и перед ссылкой на функцию static ) вы можете просто определить функцию static до ее ссылки без отдельный прототип). Я использую:
-Wall и -Wextra подразумевают некоторые, но не все, другие параметры -W… , поэтому это не минимальный набор. И не все версии GCC поддерживают параметры -Wold-style-… . Но вместе эти параметры гарантируют, что функции будут иметь полное объявление прототипа перед использованием функции.
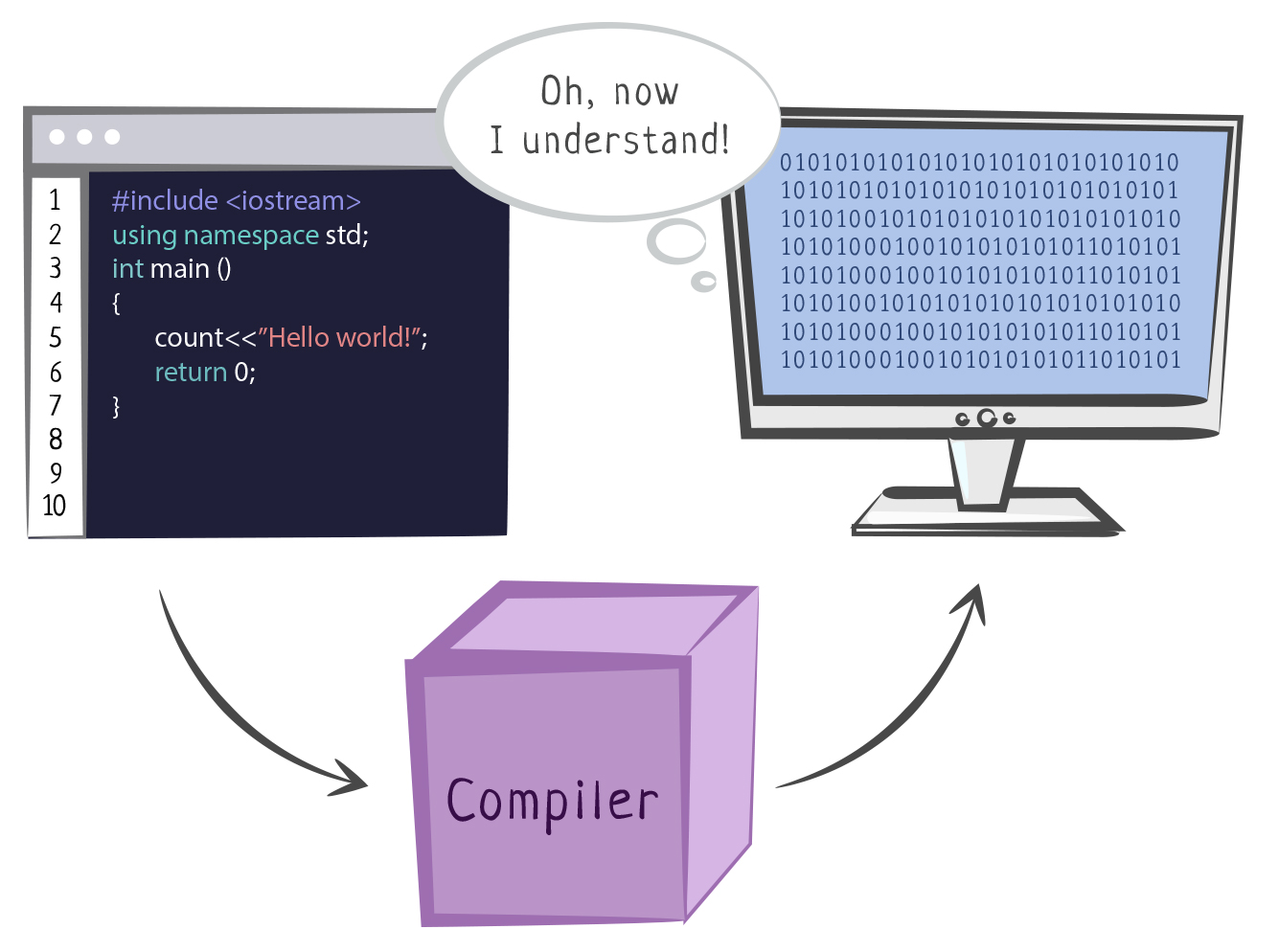
В этом гайде вы узнаете о том, что такое компилятор и как он работает. Мы разберем этапы компиляции и от чего зависит выбор подходящего компилятора. Этот материал поможет лучше понять, как компьютер выполняет программный код и почему иногда код не компилируется.
Зачем нужен компилятор?
Процессор — самая важная часть компьютера. Он обрабатывает информацию, выполняет команды пользователя и следит за работой всех подключенных устройств. Но процессор может разобрать только машинный код — набор 0 и 1, которые записаны в определённом порядке.
Почему именно 0 и 1? В процессор поступают электрические сигналы. Сильный сигнал обозначается цифрой 1, а слабый — 0. Набор таких цифр обозначает какую-то команду. Процессор ее распознает и выполняет.
Программы для первых компьютеров выглядели как огромные наборы 0 и 1. Чтобы записать такую программу, инженеры пользовались гибкими картонными карточками — перфокартами. Цифры на перфокарте записывались поочередно, в несколько строк. Чтобы записать 1, программист делал отверстие в карте. Места без отверстия обозначали 0.

Компьютер считывал перфокарту специальным устройством и выполнял записанную команду. Для одной программы составляли сотни перфокарт.
Писать их было долго и сложно, поэтому инженеры стали создавать языки программирования, обозначая команды словами и знаками. Для того, чтобы процессор понимал, какие команды записаны в программе, программисты создали компилятор — программу, которая преобразует программный код в машинный.
Как работает компилятор?
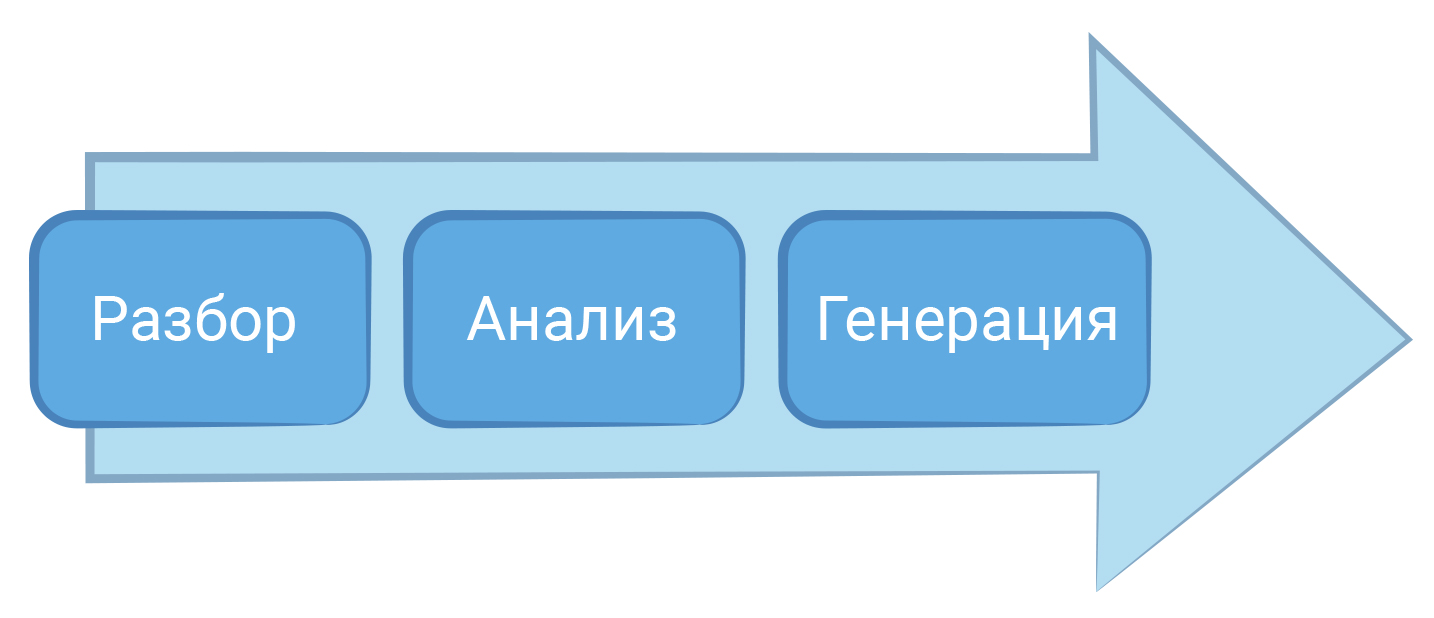
Преобразование программного кода в машинный называется компиляцией. Компиляция только преобразует код. Она не запускает его на исполнение. В этот момент он “статически” (то есть без запуска) транслируется в машинный код. Это сложный процесс, в котором сначала текст программы разбирается на части и анализируется, а затем генерируется код, понятный процессору.
Разберём этапы компиляции на примере вычисления периметра прямоугольника:
После запуска программы компилятору нужно определить, какие команды в ней записаны. Сначала компилятор разделяет программу на слова и знаки — токены, и записывает их в список. Такой процесс называется лексическим анализом. Его главная задача — получить токены.
Затем компилятор читает список и ищет токен-операторы. Это могут быть оператор присваивания( = ), арифметические операторы( + , - , * , / ), оператор вывода( printf() ) и другие операторы языка программирования. Такие операторы работают с числами, текстом и переменными.
Компилятор должен понять, какие токены в списке связаны с токен-оператором. Чтобы сделать это правильно, для каждого оператора строится специальная структура — логическое дерево или дерево разбора.
Так операция P = 2*(a + b) будет преобразована в логическое дерево:
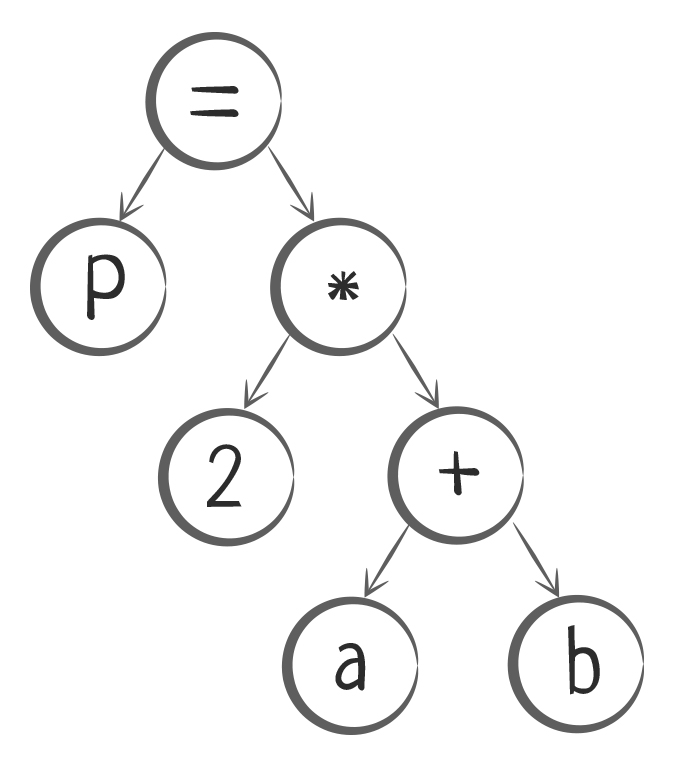
Теперь каждое дерево нужно разобрать на команды, и каждую команду преобразовать в машинный код. Компилятор начинает читать дерево снизу вверх и составляет список команд:
- Взять переменную a , взять переменную b , сложить их
- Взять результат сложения, взять число 2 и найти их произведение
- Результат произведения присвоить (записать) в переменную P
Компилятор еще раз проверяет команды, находит ошибки и старается улучшить код. При успешном завершении этого этапа, компилятор переводит каждую команду в набор 0 и 1. Наборы записываются в файл, который сможет прочитать и выполнить процессор.
На чем написан компилятор?
В 1950-е годы группа разработчиков IBM под руководством Джона Бэкуса разработала первый высокоуровневый язык программирования Fortran, который позволил писать программы на понятном человеку языке. Помимо языка, инженеры работали и над компилятором. Он представлял собой программу с набором исполняемых команд, которая могла компилировать другие программы на Fortran, в том числе и улучшенную версию себя.
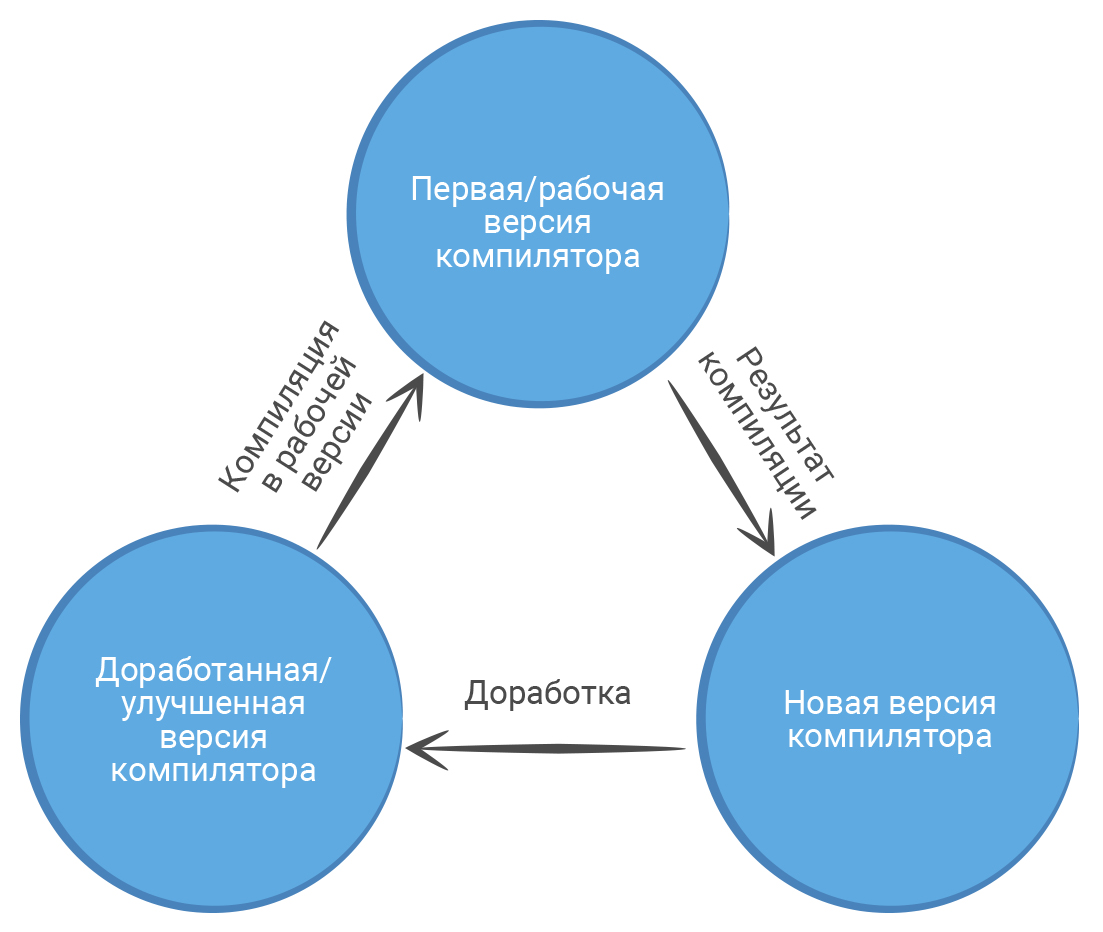
В дальнейшем язык Fortran и его компилятор использовали, чтобы написать компиляторы для новых языков программирования. Такой подход используют программисты и в настоящее время. Писать машинный код долго и неудобно. К тому же, для современных процессоров он может отличаться. Придется писать несколько версий одного и того же компилятора для разных компьютеров. Быстрее и проще написать компилятор на существующем языке программирования. Для этого разработчики выбирают удобный язык и пишут на нем первую версию своего компилятора. Он будет более универсальным для компьютеров и легко скомпилирует улучшенную версию себя.
Какие бывают компиляторы?
Ни один компилируемый язык программирования не обходится без компилятора. Некоторые компиляторы работают с несколькими языками программирования. Но программист должен учитывать еще и параметры компьютера, на котором программа будет запускаться.
Дело в том, что современные процессоры отличаются друг от друга устройством, поэтому машинный код для одного процессора будет понятен, а для другого нет. Это касается и операционных систем: одна и та же программа будет работать на Windows, но не запустится на Linux или MacOS. Поэтому нужно пользоваться тем компилятором, который работает с нужным процессором и операционной системой.
Если программа будет работать на нескольких операционных системах, то нужен кросс-компилятор — компилятор, который преобразует универсальный машинный код. Например, GNU Compiler Collection(сокращенно GCC) поддерживает C++, Objective-C, Java, Фортран, Ada, Go и поддерживает разную архитектуру процессоров.
Начинающие программисты даже не знают о наличии компилятора на компьютере. Они пишут программы в интегрированной среде разработки, в которую встроен компилятор, а иногда и не один. В этом случае, выбор компилятора делает среда, а не программист. Например, MS Visual Studio поддерживает компиляторы для операционных систем Windows, Linux, Android. Выбирая тип проекта, Visual Studio определяет процессор и операционную систему компьютера, и после этого выбирает подходящий компилятор.
Какие ошибки может определить компилятор?
- ошибки объявления переменных или отсутствие их начальных значений
- ошибки несоответствия типов
- ошибки неправильной записи операторов и функций
Иногда компилятор определяет код, который при выполнении дает неправильный результат. Но преобразовать такую программу в машинный код все-таки можно. В этом случае компилятор показывает пользователю предупреждение. Такая реакция компилятора больше похожа на рекомендации, но на них стоит обратить внимание. Программист сам решает оставить код с предупреждением или изменить программу. Анализируя текст программы, компилятор не только ищет ошибки, но еще и упрощает ее код. Такой процесс называется оптимизацией. Во время оптимизации компилятор изменяет программный код, но функции, которые выполняла программа, остаются прежними.
Выводы и рекомендации
Компилятор — переводчик между программистом и процессором. Он преобразует текст программы в машинный код, определяет ряд ошибок в программе и оптимизирует ее работу. Выбирая, где компилировать программу, важно помнить о том, что машинный код для процессоров и операционных систем будет разным, и подобрать правильный компилятор. Чем точнее компилятор определит команды, тем корректнее и быстрее будет работать программа. Для этого следуйте простым рекомендациям:
- использовать простые, понятные команды;
- помнить о соответствии типов данных;
- внимательно набирать код, избегая синтаксических ошибок;
- избегать повторяющихся действий и бесполезных переменных.
Частые вопросы
Чем компилятор отличается от интерпретатора?
Компилятор это программа, которая выполняет преобразование текста программы в другое представление, обычно машинный код, без его запуска, статически. Затем эта программа уже может быть запущена на выполнение. Интерпретатор сразу запускает код и выполняет его в процессе чтения. Промежуточного этапа как в компиляции нет.
Читайте также: