
Результат запроса в excel
Обновлено: 03.07.2024
Вывод результатов запроса SQL в excel: На лист выводится каждая 256 запись
Есть файл excel, в макросе вызывается запрос SQL. Строки сами по себе большие, количество почти.
Экспорт запроса в Excel
Доброе утро, провожу экспорт запроса в эксель DoCmd.OutputTo acOutputQuery, "Состав цена.
Экспорт результата запроса в MS EXcel
Здраствуйте! У меня такая проблема. Надо результат запроса, полученный в ПХП, экспортировать в.
Экспорт запроса oracle в excel
Здравствуйте всем знатокам oracle подскажите пожалуйста. Проблема в том что у меня есть n.
не понравилось
--z не объявлено
--похоже, что переменная (с) то русская, то латинская
--не всегда присваивается в запрос id_users
но ошибки не усмотрела-----влияние выходных
Спасибо, кстати после изменения переменной "c" на латинскую начала снова вылазит ошибка, указывающая на:Загвоздка в том, что рядом на форме есть вывод по году и периоду с отдельной кнопкой, так вот этот вывод работает без проблем, а там где у меня не выводит, конструкция запроса более сложная. чтоле
Я уже отказываюсь понимать, почему не работает) Проблема в MEMO-полях по которым вообще-то нельзя делать группировки. Перепишите запрос с ограничением по мемо-полям и он пойдет. Не уверен, что Вас устроит огрызок поля, но, по крайней мере, Вы знаете откуда ноги растут у ошибки
Спасибо огромное. Вы были правы!Все выводит, как только поменял формат на текстовый. но радость сейчас потихоньку уходит)казус в том что 255 символов ни в какие ворота. слишком мало. Существуют способы обойти это ограничение? с возможностью вывода конечно.
Спасибо еще раз!) С Вордом (да и с отчетами в Аксессе) проходил вариант с дополнительной таблицей, куда записывались записи запроса, и выгрузкой из нее. Попробуйте выгрузить таблицу с полем мемо. Да, разумеется. Вот смотрите выдача в ексель с помощью ДАО-рекордсета и последовательной записи в ячейки. В коде изменения выделены линиями
Добавлено через 34 минуты
ltv_1953 Попробовал встроенным функциями, тоесть макросом. Выводит все в полном размере! Или вывод через макрос работает немного по иному?
начальству смотреть удобнее в НТМ вам обязательно нужен excel-формат?
начальству смотреть удобнее в НТМ Да, любой из отраслевых органов предложенных в базе передает отчеты в Excel формате Вы говорите что легко и не проблема, но я понятия не имею как это реализовать)Тоесть будет 2 действия, сначала в htm, а после в excel. Эти действия только для того чтобы корректно отображалось поле MEMO? Мне просто до сих пор не верится что нельзя обойти эти 255 символов)
P.S Вообще я за любой кипишь, но самостоятельно реализовать сей действия за короткие сроки(как у меня) я увы наверное не успею, хотя именно из за нехватки времени прибег к помощи вашего форума и был очень впечатлён! Всё наверное из за того что я промучился с этим выводом в excel оёёй как долго)
кстати, если будет узкий высокий столбец --ексель тоже может не показывать информацию(максимальная высота 409пунктов, это примерно 12.5-15.0 см)
Если вам часто приходится выгружать данные из базы в файлы excel для их анализа, то обработка "Универсальная выгрузка данных в excel" поможет вам.
Обработка "Универсальная выгрузка данных в excel" позволяет создать неограниченное количество заданий на выгрузку из базы 1С8 в файлы excel. Для выгрузки в excel используется метод для COM объекта с использованием объекта COMSafeArray, что позволяет выгружать данные на существующие листы книги excel и подхватывать данные в с этих листов в формулах на других листах, или в других файлах excel.
Обработка работает в конфигурациях на управляемых формах и добавляется в разделе «Дополнительные отчеты и обработки». При настройке заданий запрос можно вставлять как копированием, так и вызовом конструктора запросов. Результат запроса текущего задания можно тут же просмотреть с помощью встроенной консоли запросов.
В заданиях можно использовать параметры стандартного периода &ДатаНачала и &ДатаОкончания. Если вы хотите использовать другие параметры для дат в запросах, то называйте их по другому. Кроме того можно задать правила вычисления параметров с помощью кода 1С. Таблица заданий сохраняется в файл xml и может быть загружена при дальнейшей работе.
При запуске обработки открывается окно с таблицей заданий для выгрузки. В открывшемся окне заполняем период выгружаемых данных (при необходимости получения данных с отбором по периоду, причем для того, чтобы использовать этот параметры в запросе должны иметь имена &ДатаНачала и &ДатаОкончания), и добавляем новые задания выгрузки (кнопка «Добавить задание»), или загружаем ранее сохраненные задания для выгрузки (кнопка «Загрузить задания для выгрузки»)

При добавлении нового задания нажимаем кнопку «Добавить задание», и в новой строке выбираем файл выгрузки в колонке Полное имя файла

В колонке «Лист» вносим имя листа, на который будут выгружены данные (если не заполнить в начало файла excel будет вставлен лист с именем Выгрузка_dd_MM_yyyy_HH_mm_ss), и в колонке «Запрос» вставляем текст запроса (для открытия конструктора запросов нажимаем кнопку Выбрать в поле запроса, или F4), после чего в поле Параметры будут вставлены параметры из запроса. Для заполнения параметров в колонке «Параметры» нажимаем кнопку Выбрать и, в открывшемся окне, заполняем значения параметров, причем нажав соответствующие галочки мы можем вводить параметры в списке и выбирать тип при вводе параметров составного типа

Параметры запроса можно вносить как непосредственно в виде значений, или списка значений, так и програмно. Для этого открываем список параметров для соответствующего задания и ставим галочку «Вычислять параметры», после чего заполняем код в колонке «Правило вычисления параметра». Заполнение параметров можно проверить нажав кнопку «Вычислить параметры», после чего значение параметра будет заполнено результатом выполнения кода из колонки «Правило вычисления параметра» из переменной ЗначениеПараметра. В дальнейшем, чтобы при выгрузке в excel параметр заполнялся каждый раз програмно ставим галочку в колонке «Вычислять»

Например, для того, чтобы получать продажи за вчерашний день заполняем параметры как на картинке

Для того, чтобы просмотреть результат запроса текущего задания нажимаем кнопку «Выполнить запрос текущего задания», после чего результат запроса отображается в поле «Результат запроса текущего задания».

После заполнения всех строк с заданиями нажимаем кнопку «Выгрузить в excel». В строках, отмеченных галочками, данные запросов выгружаются в выбранные excel-файлы, в выбранные листы, причем если на других листах, или в других книгах есть формулы, связанные с выбранными листами, при открывании они пересчитываются новыми значениями.
Для Сохранения Списка заданий на выгрузку в excel-файлы нажимаем кнопку «Сохранить задания для выгрузки».
Обработка проверена на 1С:Предприятие 8.3 (8.3.18.1483) в конфигурациях 1С:Комплексная автоматизация 2 (2.4.13.209); Бухгалтерия предприятия , редакция 3.0 (3.0.100.16); Управление торговлей 11.4 (11.4.13.271); Зарплата и управление персоналом, редакция 3.1 (3.1.19.48)
В последней версии обработки добавлена простая консоль запросов и возможность вводить код 1С для вычисления параметров запросов.
Совсем недавно мне была поставлена задача, написать сервис, который будет заниматься всего лишь одной, но очень емкой задачей – собирать большой объем данных из базы, агрегировать и заполнять все это в Excel по определенному шаблону. В процессе поиска лучшего решения было опробовано несколько подходов, решены проблемы, связанные с памятью и производительностью. В этой статье я хочу поделиться с вами основными моментами и этапами реализации данной задачи.
1. Постановка задачи
В связи с тем, что мне нельзя разглашать подробности ТЗ, сущности, алгоритмы сбора данных и т. д. Пришлось придумать что-то аналогичное:
У нас есть 3 таблицы:
User. Хранит имя пользователя и его некий рейтинг (не важно откуда он берется и как считается)
Состав колонок будет следующим:

В Excel Заказчик хочет видеть 4 колонки 1) message_date. 2) name. 3) rating. 4) text. Ограничение по количеству строк 1 млн. Надо заполнить этими данными excel, а дальше заказчик уже будет работать с этими данными в екселе самостоятельно.
2. Задача понятна, начнем поиск решения
Так как в компании все стараются придерживаться единого стиля в разработке приложений, то и мне пришлось начать с самого обычного подхода, который используется во всех остальных микросервисах – это Spring + Hibernate для запуска приложения и работы с БД. В качестве БД используется Oracle, хотя использование любой другой СУБД будет плюс минус похожим.
Для старта приложения нам понадобится зависимость spring-boot-starter-data-jpa, которая объединяет в себе сразу Spring Data, Hibernate и JPA, все это нам понадобится для удобства работы с БД и нашими сущностями.
Для тестирования добавим spring-boot-starter-test
И еще нам нужен сам драйвер для подключения к БД
Далее нам нужно добавить некоторые настройки конфигурации. У нас будет один метод, который будет ходить в таблицу TASK, искать задачу в статусе “CREATED” и, если такая задача существует, то запускать генерацию отчета с параметрами. Предполагается, что генерация отчета может быть долгой, поэтому наш метод будет запускаться по расписанию в два потока асинхронными процессами. Так же для Spring Data укажем наш репозиторий для поиска соответствующих сущностей. Класс конфигурации будет выглядеть следующим образом:
Класс генерации отчетов содержит в себе @Scheduled метод, который раз в минуту ищет Task и, если находит, то запускает генерацию отчета с параметрами из этой таски.
Класс стартер приложения не имеет ничего примечательного, весь код можно посмотреть на GitHub.
3. Выборка данных из БД
Т.к. в компании повсеместно используется Hibernate было решено использовать его. Добавлено entity MessageData с необходимым набором полей (id, name, rating, messageDate, test). Первой попыткой выбрать необходимые данные была попытка в лоб – выгрузить все в List<Message> с помощью простого метода:
А дальше уже в цикле создавать объекты MessageData и обогащать их недостающими данными. Было очевидно, что данных подход в корне не верный и выгружать сразу миллион записей в List как минимум медленно. Но для эксперимента и замера скорости работы проверить хотелось, чтобы потом сравнить с другими вариантами. Но в результате данный набор записей выгружался около 30 минут после чего было получено OutOfMemoryError и на этом эксперимент завершился.
Даже если бы пользователь задал узкие рамки в параметрах и нам бы удалось выбрать все в один List, то дальше мы бы столкнулись со следующей проблемой – для заполнения всех необходимых колонок нужно было бы собирать id пользователей, идти снова в базу, получать их имена и рейтинги, и заполнить уже с полными данными. Сложность такого алгоритма вырастала в разы. Было понятно, что выборку надо производить по частям и переложить все возможные действия с данными на сторону бд. Чтобы не выбирать все разом и, чтобы не городить велосипедов, было решено использовать ScrollableResults. Это позволяет нам получить ссылку на курсор и итерироваться по результатам с определенным шагом. Далее пришлось переписать запрос так, чтобы он возвращал сразу все необходимые данные уже после всех джойнов, объединений, группировок и т. д.
Следующий вопрос – где хранить сам текст запроса. Это был не простая ситуация т.к. в действительности количество таблиц, которые участвовали в запросе было около десяти, количество джойнов и всяческих группировок было огромным, в результате чего текст запроса вышел на 200+ строк после ревью всевозможных коллег и утверждении самим тех лидом. Хранить такой запрос в java коде не хотелось, плюс в нем были захардкожены некоторые константы в условиях и светить ими в общем репозитории было бы неправильно. Для решения всех этих вопросов мне на помощь пришла идея использовать view. Весь текст запроса прекрасно туда вписывался, плюс на выходе мы получаем готовую сущность, с которой может работать hibernate как с обычной entity.
По началу все выглядело нормально, запрос на выборку 1 млн таких строк выполнялся за разумные 10 мин. или около того. Немного больше, чем хотелось бы, но заказчика это устраивало. Однако в процессе тестирования обнаружился серьезный минус такого подхода – когда мы выбираем 1 млн записей, запрос выполняется 10 минут, но когда мы хотим отчет по короче и указываем в параметрах границы даты поуже – у нас запрос так же выполняется 10 минут, но в результате мы можем получить хоть 1 запись, хоть миллион. Суть в том, что внутрь запроса view нельзя передавать параметры, мы можем только выполнить статический запрос и уже на результат наложить параметры. Поэтому не важно сколько будет в результате строк, в первую очередь будет выбрано все, что найдется в бд, а только потом будет применены параметры. Заказчику было все равно, его устраивало и то, что отчет с одной строкой будет формироваться практически за такое же время, что и отчет с 1 млн строк. Однако это излишне нагружало бд и было решено отказаться от этого варианта.
Оставался всего один вариант, который нам подходил – это хранимая в бд функция. В нее можно передавать параметры, она может вернуть ссылку на курсор и ее результат можно удобно маппить на нашу entity. Таким образом была описана функция, которая принимала на вход несколько параметров, и возвращала sys_refcursor, весь скрипт занял около 300 строк в реальности, а в упрощенном варианте здесь она выглядит так:
Теперь как ее использовать? Для этого отлично подходит @NamedNativeQuery. Запрос для вызова функции выглядит следующим образом: "< ? = call message_ref(?, ?) >", callable = true дает понять, что запрос представляет собой вызов функции, cacheMode = CacheModeType.IGNORE для указания не использовать кэш, т. к. скорость работы нам не так критична, как затрачиваемая память, ну и в конце resultClass = MessageData.class для маппинга результата на нашу entity. Класс MessageData выглядит следующим образом:
Для того чтобы не использовать кэш было решено выполнять запрос в StatelessSession. Однако есть важная особенность: если попытаться вызвать namedQuery то hibernate при попытке установить CacheMode выдаст UnsupportedOperationException. Чтобы этого избежать необходимо установить два хинта:
В итоге наш метод генерации имеет следующий вид:
4. Запись данных в Excel
На данном этапе вопрос с выборкой данных из БД был решен и возник следующий вопрос – как теперь все это писать в excel так, чтобы это было быстро и не затратно по памяти. Первая попытка была самой очевидной – это использование библиотеки org.apache.poi. Тут все просто: подключаем зависимость
Создаем XSSFWorkbook далее XSSFSheet, из него уже row и так далее. Ничего примечательного, примерный код ниже:
Но такой подход оказался не очень оптимальным. Примерно 3 минуты потребовалось на выборку 1 млн строк из бд и запись их в excel. И в итоге приводил к OutOfMemoryError. Вот пример:
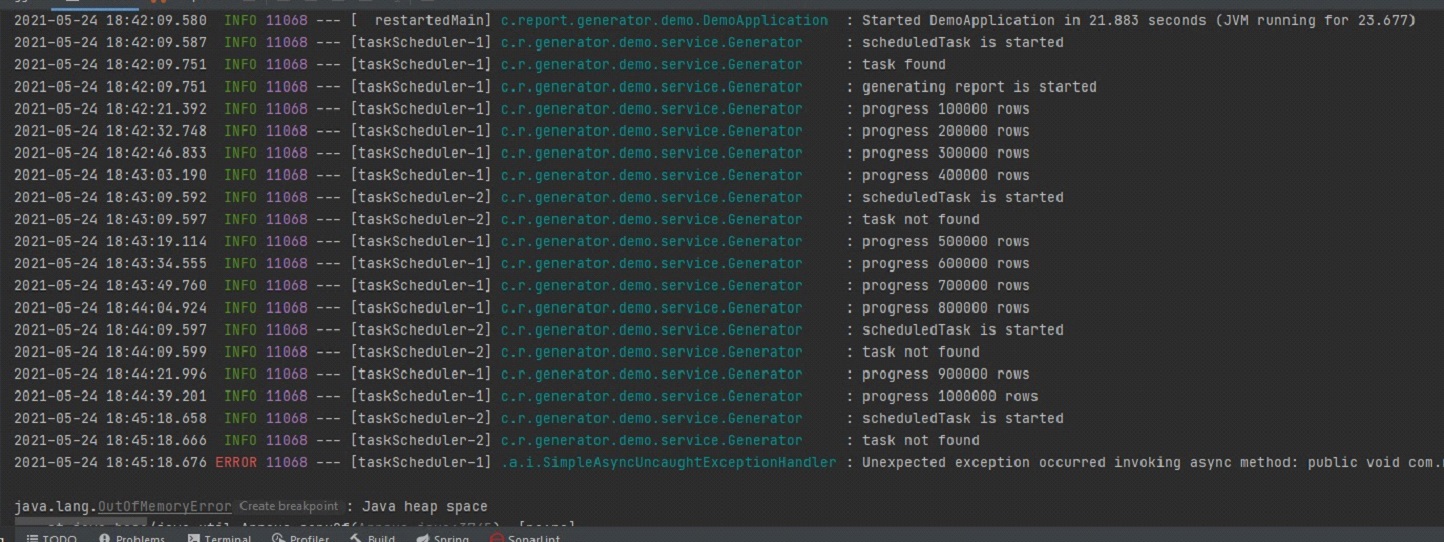
А когда я выполнял его на терминалке с выделенной оперативной памятью в 2Gb, то падал он с OutOfMemoryError примерно на 30% прогресса.
Грузить весь миллион строк в память в excel было так же плохой идеей, как и выгружать весь запрос в List, очевидно, здесь надо было использовать некий stream, но хоть какой-то годный пример google тогда мне не дал. Была попытка написать свое подобие I/O Stream для работы с excel, но мысль о том, что я пишу велосипед не давала мне покоя. В результате я стал изучать библиотеку org.apache.poi пристальней и оказалось, что там уже есть пакет streaming. В этом пакете уже есть весь необходимый набор классов для работы с большим объемом данных в excel. Оставалось только заменить все ключевые классы на аналогичные из пакета streaming и все:
Теперь сравним скорость обработки данных с этой библиотекой:

Вся обработка заняла пол минуты и, самое главное, никаких OutOfMemoryError.

Приветствую всех.
При автоматизации небольших магазинов для хранения данных часто используют PostgreSQL. И часто возникает потребность экспортировать эти данные в Excel. В этой статье я расскажу вам как я решал эту задачу. Естественно, матерые специалисты вряд ли откроют для себя что-то новое. Однако, материал будет интересен тем кто «плавает» в этой теме.
Итак, естественно, самый просто и банальный способ экспортировать данные результатов запросов в csv-файлы, а затем открыть их в Excel. Это выглядит вот так:
- во-первых, вставка данных из PostgreSQL происходит именно на сервере;
- во-вторых, можно конечно заморочиться написать batch-скрипт, который будет удаленно вызывать этот запрос на сервере, затем этот файл скопировать на компьютер пользователя и инициировать открытие в Excel.
1. Идем по ссылке и в зависимости от разрядности компьютера скачиваем установщик ODBC драйвера. Установка его проста и не требует особых знаний.
2. Чтобы пользователи могли со своих компьютеров цепляться к БД не забудьте в файле pg_hba.conf установить параметры для IP-адресов, с которых можно производить подключения:

В данном примере, что все рабочие станции смогут подключаться к серверу с БД:

3. Далее через Excel просто генерируем файл динамического запроса к данным *.dqy. Далее этот файл просто можно менять по своему усмотрению. Можно прям ниже следующий текст взять, скопировать в блокнот и там отредактировать, сохранив файл *.dqy. Вводим имя файла и расширение dqy. Выбираем типа файла ВСЕ(All files):

DATABASE – указывается наименование БД к которой будет производиться подключение;
SERVER – адрес сервера;
PASSWORD – пароль на подключение к БД.
Обратите внимание, что в большом тексте указываются параметры подключения к БД и ваша БД. Также можно еще сконфигурировать множество параметров подключения
В последней строке пишется сам запрос. Далее сохраняем файл. Если на компьютере установлен Microsoft Excel, тогда файл сразу же приобретет пиктограмму:

При запуске файла будет выдано диалоговое окно. Смело нажимаем «Включить»:

И получаем результат запроса из БД:

Теперь можно создать несколько таких файлов и спокойно скопировать их на рабочий стол пользователя:


Кстати, я пошел немного дальше. Откопал старый добрый VB6. Можно так сделать с любым языком программирования. Сделал форму, которая по выбранной дате запрашивает данные из БД, путем генерации этого *.dqy файла:
Затем немного покодил (вот часть кода):
Результат получился тот же — данные из Excel, и пользователю удобно. Да, кстати, в строке:
если речь идет о 64-битном процессоре и драйвере ODBC, установленном для 64 бит, то надо писать:
Ну, и самое главное, несмотря на всю простоту способа, у него есть конечно недостатки: запрос можно писать только в одну строку, т.е. записать строку вот в таком виде не получиться. Нужно только в одну:
— Не сможет обрабатывать на изменение данных типа:
или
Ну и может выводить только результат запроса в виде списка, т.е. красивый документ сделать не получиться. На этом все. Надеюсь данный способ кому-нибудь пригодиться. Буду рад получить ваши рекомендации по усовершенствованию моего метода или альтернативного решения данной проблемы.
Читайте также: