
В процессе обработки программа и данные должны быть загружены в какую память
Обновлено: 07.07.2024
Заречнева Ирина Владимировна,
Николаенко Наталья Александровна,
Кощеева Светлана Михайловна,
Брыксина Елена Николаевна
| « Ноябрь 2021 » | ||||||
| Пн | Вт | Ср | Чт | Пт | Сб | Вс |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | |||||
Урок 10. Программная обработка данных на компьютере
учитель информатики МБОУ Червовская СОШ Николаенко Н.А.
Числовая, текстовая, графическая и звуковая информация может обрабатываться компьютером, если она представлена в двоичной знаковой системе. Информация в двоичном компьютерном коде, т.е. данные, представляет собой последовательность нулей и единиц. Данные обрабатываются компьютером в форме последовательностей электрических импульсов.
В таблице приведены примеры представления человеком и компьютером различных типов данных: числа 5, буквы «А», точки черного цвета и звука максимальной громкости.
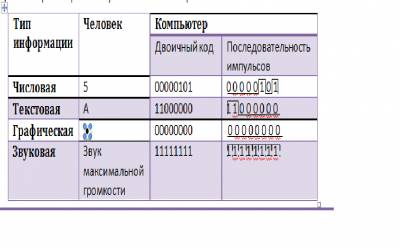
Данные – это информация, которая обрабатывается компьютером в двоичном компьютерном коде.
Для того чтобы компьютер «знал», что ему делать с данными, как их обрабатывать, он должен получить определенную команду (инструкцию). Например: «сложить два числа»; «заменить один символ в тексте на другой.
Обычно решение задачи представляется в формеалгоритма, т.е. определенной последовательности команд. Такая последовательность команд (инструкций), записанная на «понятном» компьютеру языке, называетсяпрограммой
Программа – это последовательность команд, которую выполняет компьютер в процессе обработки данных.
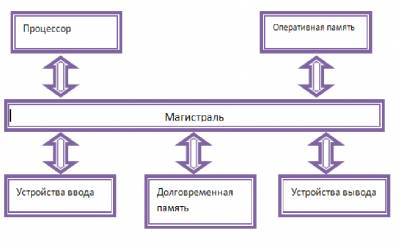
Функциональная схема компьютера.
Центральным устройством компьютера, которое обрабатывает данные в соответствии с заданной программой, является процессор. Процессор обрабатывает данные в двоичном компьютерном коде в форме последовательностей электрических импульсов. Однако пользователь компьютера (человек) очень плохо понимает информацию, представленную в двоичном коде, и вообще не воспринимает ее в виде последовательностей электрических импульсов. Следовательно, в состав компьютера должны входитьустройства ввода и вывода информации. Устройства ввода «переводят» информацию с языка человека на язык компьютера. Устройства вывода, наоборот, «переводят» информацию с двоичного языка компьютера в формы, доступные для человеческого восприятия.
Для того чтобы компьютер мог выполнить обработку данных по программе, программа и данные должны быть загружены в оперативную память. Процессор последовательно считывает команды программы, а также необходимые данные из оперативной памяти, выполняет команды, а затем записывает полученные данные обратно в оперативную память. В процессе выполнения программы процессор может запрашивать данные с устройства ввода и пересылать данные на устройства вывода. Однако при выключении компьютера все данные и программы в оперативной памяти стираются. Для долговременного хранения большого количества различных программ и данных используется долговременная память. Пользователь может запустить программу, хранящуюся в долговременной памяти, она загрузиться в оперативную память и начнет выполняться. Необходимые для выполнения этой программы данные, хранящиеся в долговременной памяти, будут также загружены в оперативную память. В процессе программной обработки данных на компьютере пересылка данных и программ между отдельными устройствами компьютера осуществляется по магистрали.
Закрепление изученного материла
1. Информация, обрабатываемая компьютером в виде двоичного компьютерного кода.
2. Алгоритм,записаный на языке программирования и выполняемый компьютером.
3. Центральное устройство компьютера, которое обрабатывает данные в соответствии с заданной программой
4. Какое устройство служит каналом пересылки данных и программ?
5. В состав компьютера должны входить устройства ввода и … информации
Домашнее задание
п.2.1. Практическая работа 2.2 "Форматирование внешнего накопителя". Описание работы смотрите в учебнике
Управление памятью – одна из главных задач ОС. Она критична как для программирования, так и для системного администрирования. Я постараюсь объяснить, как ОС работает с памятью. Концепции будут общего характера, а примеры я возьму из Linux и Windows на 32-bit x86. Сначала я опишу, как программы располагаются в памяти.
Каждый процесс в многозадачной ОС работает в своей «песочнице» в памяти. Это виртуальное адресное пространство, которое в 32-битном режиме представляет собою 4Гб блок адресов. Эти виртуальные адреса ставятся в соответствие (mapping) физической памяти таблицами страниц, которые поддерживает ядро ОС. У каждого процесса есть свой набор таблиц. Но если мы начинаем использовать виртуальную адресацию, приходится использовать её для всех программ, работающих на компьютере – включая и само ядро. Поэтому часть пространства виртуальных адресов необходимо резервировать под ядро.


Это не значит, что ядро использует так много физической памяти – просто у него в распоряжении находится часть адресного пространства, которое можно поставить в соответствие необходимому количеству физической памяти. Пространство памяти для ядра отмечено в таблицах страниц как эксклюзивно используемое привилегированным кодом, поэтому если какая-то программа пытается получить в него доступ, случается page fault. В Linux пространство памяти для ядра присутствует постоянно, и ставит в соответствие одну и ту же часть физической памяти у всех процессов. Код ядра и данные всегда имеют адреса, и готовы обрабатывать прерывания и системные вызовы в любой момент. Для пользовательских программ, напротив, соответствие виртуальных адресов реальной памяти меняется, когда происходит переключение процессов:
Голубым отмечены виртуальные адреса, соответствующие физической памяти. Белым – пространство, которому не назначены адреса. В нашем примере Firefox использует гораздо больше места в виртуальной памяти из-за своей легендарной прожорливости. Полоски в адресном пространстве соответствуют сегментам памяти таким, как куча, стек и проч. Эти сегменты – всего лишь интервалы адресов памяти, и не имеют ничего общего с сегментами от Intel. Вот стандартная схема сегментов у процесса под Linux:

Когда программирование было белым и пушистым, начальные виртуальные адреса сегментов были одинаковыми для всех процессов. Это позволяло легко удалённо эксплуатировать уязвимости в безопасности. Зловредной программе часто необходимо обращаться к памяти по абсолютным адресам – адресу стека, адресу библиотечной функции, и т.п. Удаленные атаки приходилось делать вслепую, рассчитывая на то, что все адресные пространства остаются на постоянных адресах. В связи с этим получила популярность система выбора случайных адресов. Linux делает случайными стек, сегмент отображения в память и кучу, добавляя смещения к их начальным адресам. К сожалению, в 32-битном адресном пространстве особо не развернёшься, и для назначения случайных адресов остаётся мало места, что делает эту систему не слишком эффективной.
Самый верхний сегмент в адресном пространстве процесса – это стек, в большинстве языков хранящий локальные переменные и аргументы функций. Вызов метода или функции добавляет новый кадр стека (stack frame) к существующему стеку. После возврата из функции кадр уничтожается. Эта простая схема приводит к тому, что для отслеживания содержимого стека не требуется никакой сложной структуры – достаточно всего лишь указателя на начало стека. Добавление и удаление данных становится простым и однозначным процессом. Постоянное повторное использование районов памяти для стека приводит к кэшированию этих частей в CPU, что добавляет скорости. Каждый поток выполнения (thread) в процессе получает свой собственный стек.
Можно прийти к такой ситуации, в которой память, отведённая под стек, заканчивается. Это приводит к ошибке page fault, которая в Linux обрабатывается функцией expand_stack(), которая, в свою очередь, вызывает acct_stack_growth(), чтобы проверить, можно ли ещё нарастить стек. Если его размер не превышает RLIMIT_STACK (обычно это 8 Мб), то стек увеличивается и программа продолжает исполнение, как ни в чём не бывало. Но если максимальный размер стека достигнут, мы получаем переполнение стека (stack overflow) и программе приходит ошибка Segmentation Fault (ошибка сегментации). При этом стек умеет только увеличиваться – подобно государственному бюджету, он не уменьшается обратно.
Динамический рост стека – единственная ситуация, в которой может осуществляться доступ к свободной памяти, которая показана белым на схеме. Все другие попытки доступа к этой памяти вызывают ошибку page fault, приводящую к Segmentation Fault. А некоторые занятые области памяти служат только для чтения, поэтому попытки записи в эти области также приводят к Segmentation Fault.
После стека идёт сегмент отображения в память. Тут ядро размещает содержимое файлов напрямую в памяти. Любое приложение может запросить сделать это через системный вызов mmap() в Linux или CreateFileMapping() / MapViewOfFile() в Windows. Это удобный и быстрый способ организации операций ввода и вывода в файлы, поэтому он используется для подгрузки динамических библиотек. Также возможно создать анонимное место в памяти, не связанное с файлами, которое будет использоваться для данных программы. Если вы сделаете в Linux запрос на большой объём памяти через malloc(), библиотека C создаст такую анонимное отображение вместо использования памяти из кучи. Под «большим» подразумевается объём больший, чем MMAP_THRESHOLD (128 kB по умолчанию, он настраивается через mallopt().)
Если в куче оказывается недостаточно места для выполнения запроса, эту проблему может обработать сама программа без вмешательства ядра. В ином случае куча увеличивается системным вызовом brk(). Управление кучей – дело сложное, оно требует хитроумных алгоритмов, которые стремятся работать быстро и эффективно, чтобы угодить хаотичному методу размещению данных, которым пользуется программа. Время на обработку запроса к куче может варьироваться в широких пределах. В системах реального времени есть специальные инструменты для работы с ней. Кучи тоже бывают фрагментированными:

И вот мы добрались до самой нижней части схемы – BSS, данные и текст программы. BSS и данные хранят статичные (глобальные) переменные в С. Разница в том, что BSS хранит содержимое непроинициализированных статичных переменных, чьи значения не были заданы программистом. Кроме этого, область BSS анонимна, она не соответствует никакому файлу. Если вы пишете static int cntActiveUsers , то содержимое cntActiveUsers живёт в BSS.
Сегмент данных, наоборот, содержит те переменные, которые были проинициализированы в коде. Эта часть памяти соответствует бинарному образу программы, содержащему начальные статические значения, заданные в коде. Если вы пишете static int cntWorkerBees = 10 , то содержимое cntWorkerBees живёт в сегменте данных, и начинает свою жизнь как 10. Но, хотя сегмент данных соответствует файлу программы, это приватное отображение в память (private memory mapping) – а это значит, что обновления памяти не отражаются в соответствующем файле. Иначе изменения значения переменных отражались бы в файле, хранящемся на диске.
Пример данных на диаграмме будет немного сложнее, поскольку он использует указатель. В этом случае содержимое указателя, 4-байтный адрес памяти, живёт в сегменте данных. А строка, на которую он показывает, живёт в сегменте текста, который предназначен только для чтения. Там хранится весь код и разные другие детали, включая строковые литералы. Также он хранит ваш бинарник в памяти. Попытки записи в этот сегмент оканчиваются ошибкой Segmentation Fault. Это предотвращает ошибки, связанные с указателями (хотя не так эффективно, как если бы вы вообще не использовали язык С). На диаграмме показаны эти сегменты и примеры переменных:

Изучить области памяти Linux-процесса можно, прочитав файл /proc/pid_of_process/maps. Учтите, что один сегмент может содержать много областей. К примеру, у каждого файла, сдублированного в память, есть своя область в сегменте mmap, а у динамических библиотек – дополнительные области, напоминающие BSS и данные. Кстати, иногда, когда люди говорят «сегмент данных», они имеют в виду данные + bss + кучу.
Бинарные образы можно изучать при помощи команд nm и objdump – вы увидите символы, их адреса, сегменты, и т.п. Схема виртуальных адресов, описанная в этой статье – это т.н. «гибкая» схема, которая по умолчанию используется уже несколько лет. Она подразумевает, что переменной RLIMIT_STACK присвоено какое-то значение. В противном случае Linux использует «классическую» схему:
Данные. Числовая, текстовая, графическая и звуковая информация может обрабатываться компьютером, если она представлена в двоичной знаковой системе. Информация в двоичном компьютерном коде, т. е. данные, представляет собой последовательность нулей и единиц. Данные обрабатываются компьютером в форме последовательностей электрических импульсов.
В табл. 2.1 приведены примеры представления человеком и компьютером различных типов данных: числа 5, буквы «А», точки черного цвета и звука максимальной громкости.

Данные — это информация, которая обрабатывается компьютером в двоичном компьютерном коде.
Программы. Для того чтобы компьютер «знал», что ему делать с данными, как их обрабатывать, он должен получить определенную команду (инструкцию). Например: «сложить два числа»; «заменить один символ в тексте на другой».
Обычно решение задачи представляется в форме алгоритма, т. е. определенной последовательности команд. Такая последовательность команд (инструкций), записанная на «понятном» компьютеру языке, называется программой.
Программа — это последовательность команд, которую выполняет компьютер в процессе обработки данных.
Функциональная схема компьютера. Центральным устройством компьютера, которое обрабатывает данные в соответствии с заданной программой, является процессор. Процессор обрабатывает данные в двоичном компьютерном коде в форме последовательностей электрических импульсов (нет импульса — «О», есть импульс — «1»).
Однако пользователь компьютера (человек) очень плохо понимает информацию, представленную в двоичном компьютерном коде, и вообще не воспринимает ее в виде последовательностей электрических импульсов. Следовательно, в состав компьютера должны входить устройства ввода и вывода информации. Устройства ввода «переводят» информацию с языка человека на язык компьютера. Устройства вывода, наоборот, «переводят» информацию с двоичного языка компьютера в формы, доступные для человеческого восприятия.
Для того чтобы компьютер мог выполнить обработку данных по программе, программа и данные должны быть загружены в оперативную память. Процессор последовательно считывает команды программы, а также необходимые данные из оперативной памяти, выполняет команды, а затем записывает полученные данные обратно в оперативную память. В процессе выполнения программы процессор может запрашивать данные с устройств ввода и пересылать данные на устройства вывода.
Однако при выключении компьютера все данные и программы в оперативной памяти стираются. Для долговременного хранения большого количества различных программ и данных используется долговременная память. Пользователь может запустить программу, хранящуюся в долговременной памяти, она загрузится в оперативную память и начнет выполняться. Необходимые для выполнения этой программы данные, хранящиеся в долговременной памяти, будут также загружены в оперативную память.
В процессе программной обработки данных на компьютере пересылка данных и программ между отдельными устройствами компьютера осуществляется по магистрали (рис. 2.1).

Контрольные вопросы
- В чем состоит различие между данными и программами?
- Опишите с использованием функциональной схемы компьютера процесс программной обработки данных.
_______________________________________________________________________
В МК используется три основных вида памяти. Память программ представляет собой постоянную память ( ПЗУ ), предназначенную для хранения программного кода ( команд ) и констант. Ее содержимое в ходе выполнения программы не изменяется. Память данных предназначена для хранения переменных в процессе выполнения программы и представляет собой ОЗУ . Регистры МК — этот вид памяти включает в себя внутренние регистры процессора и регистры, которые служат для управления периферийными устройствами (регистры специальных функций).
4.3.1. Память программ
Основным свойством памяти программ является ее энергонезависимость, то есть возможность хранения программы при отсутствии питания. С точки зрения пользователей МК следует различать следующие типы энергонезависимой памяти программ :
- ПЗУ масочного типа — mask-ROM. Содержимое ячеек ПЗУ этого типа заносится при ее изготовлении с помощью масок и не может быть впоследствии заменено или допрограммировано. Поэтому МК с таким типом памяти программ следует использовать только после достаточно длительной опытной эксплуатации. Основным недостатком данной памяти является необходимость значительных затрат на создание нового комплекта фотошаблонов и их внедрение в производство. Обычно такой процесс занимает 2-3 месяца и является экономически выгодным только при выпуске десятков тысяч приборов. ПЗУ масочного типа обеспечивают высокую надежность хранения информации по причине программирования в заводских условиях с последующим контролем результата.
- ПЗУ, программируемые пользователем, с ультрафиолетовым стиранием — EPROM (Erasable Programmable ROM). ПЗУ данного типа программируются электрическими сигналами и стираются с помощью ультрафиолетового облучения. Ячейка памяти EPROM представляет собой МОП-транзистор с "плавающим" затвором, заряд на который переносится с управляющего затвора при подаче соответствующих электрических сигналов. Для стирания содержимого ячейки она облучается ультрафиолетовым светом, который сообщает заряду на плавающем затворе энергию, достаточную для преодоления потенциального барьера и стекания на подложку. Этот процесс может занимать от нескольких секунд до нескольких минут. МК с EPROM допускают многократное программирование и выпускаются в керамическом корпусе с кварцевым окошком для доступа ультрафиолетового света. Такой корпус стоит довольно дорого, что значительно увеличивает стоимость МК . Для уменьшения стоимости МК с EPROM его заключают в корпус без окошка (версия EPROM с однократным программированием).
- ПЗУ, однократно программируемые пользователем, — OTPROM (One-Time Programmable ROM). Представляют собой версию EPROM, выполненную в корпусе без окошка для уменьшения стоимости МК на его основе. Сокращение стоимости при использовании таких корпусов настолько значительно, что в последнее время эти версии EPROM часто используют вместо масочных ПЗУ.
- ПЗУ, программируемые пользователем, с электрическим стиранием — EEPROM (Electrically Erasable Programmable ROM). ПЗУ данного типа можно считать новым поколением EPROM, в которых стирание ячеек памяти производится также электрическими сигналами за счет использования туннельных механизмов. Применение EEPROM позволяет стирать и программировать МК , не снимая его с платы. Таким способом можно производить отладку и модернизацию программного обеспечения. Это дает огромный выигрыш на начальных стадиях разработки микроконтроллерных систем или в процессе их изучения, когда много времени уходит на поиск причин неработоспособности системы и выполнение циклов стирания-программирования памяти программ . По цене EEPROM занимают среднее положение между OTPROM и EPROM. Технология программирования памяти EEPROM допускает побайтовое стирание и программирование ячеек. Несмотря на очевидные преимущества EEPROM, только в редких моделях МК такая память используется для хранения программ. Связано это с тем, что, во-первых, EEPROM имеют ограниченный объем памяти. Во-вторых, почти одновременно с EEPROM появились Flash-ПЗУ, которые при сходных потребительских характеристиках имеют более низкую стоимость;
- ПЗУ с электрическим стиранием типа Flash — Flash-ROM. Функционально Flash-память мало отличается от EEPROM. Основное различие состоит в способе стирания записанной информации. В памяти EEPROM стирание производится отдельно для каждой ячейки, а во Flash-памяти стирать можно только целыми блоками. Если необходимо изменить содержимое одной ячейки Flash-памяти, потребуется перепрограммировать весь блок. Упрощение декодирующих схем по сравнению с EEPROM привело к тому, что МК с Flash-памятью становятся конкурентоспособными по отношению не только к МК с однократно программируемыми ПЗУ, но и с масочными ПЗУ также.
4.3.2. Память данных
Память данных МК выполняется, как правило, на основе статического ОЗУ. Термин "статическое" означает, что содержимое ячеек ОЗУ сохраняется при снижении тактовой частоты МК до сколь угодно малых значений (с целью снижения энергопотребления ). Большинство МК имеют такой параметр, как "напряжение хранения информации" — USTANDBY. При снижении напряжения питания ниже минимально допустимого уровня UDDMIN, но выше уровня USTANDBY работа программы МК выполняться не будет, но информация в ОЗУ сохраняется. При восстановлении напряжения питания можно будет сбросить МК и продолжить выполнение программы без потери данных. Уровень напряжения хранения составляет обычно около 1 В, что позволяет в случае необходимости перевести МК на питание от автономного источника (батареи) и сохранить в этом режиме данные ОЗУ.
Объем памяти данных МК , как правило, невелик и составляет обычно десятки и сотни байт. Это обстоятельство необходимо учитывать при разработке программ для МК . Так, при программировании МК константы, если возможно, не хранятся как переменные, а заносятся в ПЗУ программ. Максимально используются аппаратные возможности МК , в частности, таймеры. Прикладные программы должны ориентироваться на работу без использования больших массивов данных.
4.3.3. Регистры МК
Как и все МПС, МК имеют набор регистров, которые используются для управления его ресурсами. В число этих регистров входят обычно регистры процессора (аккумулятор, регистры состояния, индексные регистры), регистры управления (регистры управления прерываниями, таймером), регистры, обеспечивающие ввод/вывод данных (регистры данных портов, регистры управления параллельным, последовательным или аналоговым вводом/выводом). Обращение к этим регистрам может производиться по-разному.
В МК с RISC-процессором все регистры (часто и аккумулятор) располагаются по явно задаваемым адресам. Это обеспечивает более высокую гибкость при работе процессора.
Одним из важных вопросов является размещение регистров в адресном пространстве МК . В некоторых МК все регистры и память данных располагаются в одном адресном пространстве. Это означает, что память данных совмещена с регистрами. Такой подход называется "отображением ресурсов МК на память".
В других МК адресное пространство устройств ввода/вывода отделено от общего пространства памяти. Отдельное пространство ввода/вывода дает некоторое преимущество процессорам с гарвардской архитектурой, обеспечивая возможность считывать команду во время обращения к регистру ввода/вывода.
4.3.4. Стек МК
В микроконтроллерах ОЗУ данных используется также для организации вызова подпрограмм и обработки прерываний. При этих операциях содержимое программного счетчика и основных регистров (аккумулятор, регистр состояния и другие) сохраняется и затем восстанавливается при возврате к основной программе.
В фон-неймановской архитектуре единая область памяти используется, в том числе, и для реализации стека . При этом снижается производительность устройства, так как одновременный доступ к различным видам памяти невозможен. В частности, при выполнении команды вызова подпрограммы следующая команда выбирается после того, как в стек будет помещено содержимое программного счетчика.
В гарвардской архитектуре стековые операции производятся в специально выделенной для этой цели памяти. Это означает, что при выполнении программы вызова подпрограмм процессор с гарвардской архитектурой производит несколько действий одновременно.
Необходимо помнить, что МК обеих архитектур имеют ограниченную емкость памяти для хранения данных. Если в процессоре имеется отдельный стек и объем записанных в него данных превышает его емкость, то происходит циклическое изменение содержимого указателя стека , и он начинает ссылаться на ранее заполненную ячейку стека . Это означает, что после слишком большого количества вызовов подпрограмм в стеке окажется неправильный адрес возврата. Если МК использует общую область памяти для размещения данных и стека , то существует опасность, что при переполнении стека произойдет запись в область данных либо будет сделана попытка записи загружаемых в стек данных в область ПЗУ.
4.3.5. Внешняя память
Несмотря на существующую тенденцию по переходу к закрытой архитектуре МК , в некоторых случаях возникает необходимость подключения дополнительной внешней памяти (как памяти программ , так и данных).
Если МК содержит специальные аппаратные средства для подключения внешней памяти, то эта операция производится штатным способом (как для МП).
Второй, более универсальный, способ заключается в том, чтобы использовать порты ввода/вывода для подключения внешней памяти и реализовать обращение к памяти программными средствами. Такой способ позволяет задействовать простые устройства ввода/вывода без реализации сложных шинных интерфейсов, однако приводит к снижению быстродействия системы при обращении к внешней памяти.
Читайте также: