
Word document 8 что это
Обновлено: 07.07.2024
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями xml и rels
- медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
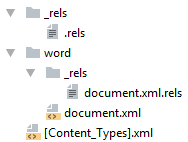
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
word/document.xml
- <w:document> — сам документ
- <w:body> — тело документа
- <w:p> — параграф
- <w:r> — run (фрагмент) текста
- <w:t> — сам текст
- <w:sectPr> — описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test .
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml . Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels . Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
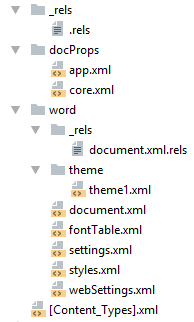
Вот что в них содержится:
- docProps/core.xml — основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].
- docProps/app.xml — общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.
- word/settings.xml — настройки относящиеся к текущему документу.
- word/styles.xml — стили применимые к документу. Отделяют данные от представления.
- word/webSettings.xml — настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.
- word/fontTable.xml — список шрифтов используемых в документе.
- word/theme1.xml — тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux: apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
- unpack file dir — распаковывает документ file в папку dir и форматирует xml
- pack dir file — запаковывает папку dir в документ file
Использование под Linux аналогично, только ./unpack.sh вместо unpack , а pack становится ./pack.sh .
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью unpack в новую папку.
- Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ bold.docx с обычным (не жирным) текстом Test.
- Распаковываем его: unpack bold.docx bold . .
- Выделяем текст Test жирным.
- Распаковываем unpack bold.docx bold .
- Изначально diff выглядел следующим образом:
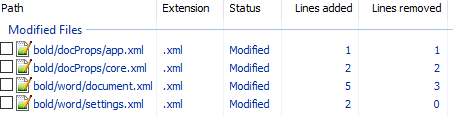
Рассмотрим его подробно:
docProps/app.xml
Изменение времени нам не нужно.
docProps/core.xml
Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/> ) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
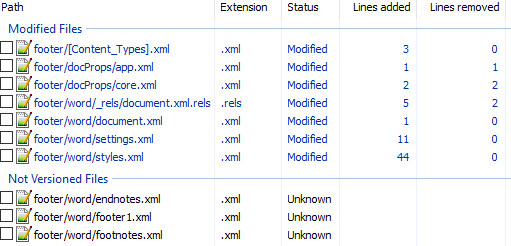
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:

Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
word/footer1.xml
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В [Content_Types].xml надо добавить footer
- В word/_rels/document.xml.rels надо добавить ссылку на footer
- В word/document.xml в тег <w:sectPr> надо добавить <w:footerReference>
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в [Content_Types].xml и word/_rels/document.xml.rels .
- В word/document.xml в тег <w:sectPr> добавляем тег <w:footerReference> или заменяем в нём ссылку на наш нижний колонтитул.
- Запаковываем документ.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
В результате получится файл нижнего колонтитула footer0.xml :
Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels :
Прописываем ссылки в документе
Далее надо в каждый тег <w:sectPr> добавить тег <w:footerReference> или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега <w:sectPr> может быть 3 тега <w:footerReference> — для первой страницы, четных страниц и всего остального:
Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml :
В результате
Весь код опубликован. Работает он так:
- in.docx — исходный документ
- out.docx — выходящий документ
- TEST — текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
О сложности и жуткости вордовских файлов давно ходили легенды. Известно было, что формат этот крайне запутанный, а к тому же еще и полностью засекреченный, так что о половине тамошних полей можно было только догадываться.
Не скрою, что и меня эти файлы интересовали, но дальше первой страницы описания я так продвинуться и не смог. Однако незакрытый гештальт остался.
А теперь вот жизнь заставила (или подкинула возможность) все-таки разобраться во внутренностях всем хорошо известных документов, тем более, что в Штирлица теперь играть не обязательно, достаточно скачать с сайта «Майкрософта» официальные спецификации.
Что тут можно сказать? Невольно вспоминается старый пошлый анекдот: ну ужас. Ну просто ужас, но ведь не ужас-ужас-ужас.
Слава богу, что я разбирал эти файлы на Перле, а не на каком-нибудь автокоде Си. Высокий уровень языка и куча готовых библиотек (например, для чтения разных кодовых страниц) — это дар божий.
Так что работа в совокупности заняла неделю, и самым сложным было понять внутренний формат. Конечно, понимание это не совсем полное, потому что моей задачей было вытащить из документа одни тексты без всякого форматирования, но уж это я сделал тщательно.
Итак, как же устроены вордовские файлы?
Контейнер
Начнем с того, что это совсем не вордовские файлы, а некий универсальный контейнер, в который упакованы собственно документы. В такой контейнер засунуты все файлы Офиса, а, может быть, и еще что-нибудь.
Формат контейнера называется по-разному — docfile, ole storage, compound document file. Уже сам разнобой в названиях намекает на то, что он не сильно-то и нужен, поскольку действительно полезная вещь обычно имеет одно и четкое название. Основная его идея — иметь возможность запихать в один файл несколько других. Самым разумным было бы (как и сделали в OpenOffice) упаковать все в архив ZIP (можно без архивации, если она не нужна). Формат известен огромному множеству программ, компактен, легко разбирается. Но в «Майкрософте», очевидно, процветает синдром «Not invented here». Главное — изобрести велосипед, пусть и трехколесный, но собственный.
В принципе, формат OLE Storage достаточно разумен и не производит впечатление чего-то совсем идиотского. Но… он совершенно не нужен. Фактически, это что-то типа файловой системы FAT16, засунутой внутрь отдельного файла. Это не то что стрельба из пушки по воробьям, а истребление этих самых воробьев ядерными торпедами. В документе, внутри которого лежит несколько файлов, не нужна файловая система, находящаяся не менее чем на уровне ФС времен ДОС.
Итак, файлы CDF (как их называет юниксовская утилитка file) начинаются с заголовка. В заголовке отведено место под первую сотню записей ТРФ (таблицы размещения файлов, в просторечии — ФАТ). ФАТ там самый натуральный, очень похож на то, что можно найти на досовских дискетках. Остальные записи ТРФ лежат в отдельных секторах, соединенных связанным списком. Дополнительные сектора бывают только в больших (>7мб) файлах.
По табличке ФАТ/ТРФ можно собрать содержимое любого внутреннего файла (в терминологии МС он называется потоком, но это только запутывает дело), если знать, с какого блока он начинается. Начальные блоки разных структур написаны, естественно, в заголовке. Дальше из таблицы можно вытянуть всю цепочку секторов, в котором записано содержимое этого псевдофайла.
В частности, у CDF есть корневой каталог, физически размазанный по куче секторов. Это самый настоящий каталог, опять-таки, очень напоминающий старый досовский. Правда, для эффективности (или для выпендрежа) он выполнен не просто линейным списком, а сбалансированным двоичным деревом. Это значит, что в него без потери эффективности поиска можно записывать десятки тысяч отдельных записей. Зачем это нужно в файле, в котором записей бывает обычно штук пять, ну иногда, двадцать, ну максимум сто штук (презентация с огромным количество картинок) — знают только в Редмонде. Кстати, имена файлов в каталоге хранятся в UTF16 — тоже на всякий случай.
По каталогу можно определить начальный сектор любого файла и с помощью ТРФ вытянуть всю его цепочку размещения.
Но это еще не все.
Поскольку размер блока немаленький (обычно 512 байт, по спецификации возможно также 4096), то при хранении мелких псевдофайлов, теоретически можно потерять много свободного места. Поэтому существует отдельное хранилище, поделенное на блочки по 64 байта. Хранилище опять-таки вытягивается по цепочке ФАТ.
Чтобы указать, какие блочки какому файлу принадлежат, существует отдельная табличка ФАТ или, вернее сказать, миниФАТ.
Итак, чтобы добраться до вордовского документа, надо сделать следующее:
1. Прочитать заголовок CDF
2. Загрузить в память ФАТ — таблицу размещения файлов, собрав ее по цепочке секторов.
3. Загрузить табличку МиниФАТ, собрав ее по цепочке ТРФ
4. Загрузить хранилище блочков, собрав ее по цепочке ТРФ
5. Загрузить корневой каталог, собрав ее по цепочке ТРФ
6. Разобрать каталог и преобразовать его во что-то читаемое
7. Найти в каталоге запись WordDocument
8. Если это маленький файл, то собрать его с помощью миниТРФ из хранилища для блочков.
9. Если большой, то вытянуть с диска сектора по цепочке ТРФ.
Каждый шаг сам по себе не особенно сложен, но в совокупности они вызывают исключительно недоумение. Зачем такие сложности? Почему нельзя было разместить после заголовка обыкновенный линейный каталог, а после него непрерывно, друг за другом записывать внутренние файлы?
Единственное, что можно предположить — все это сделано для того, чтобы была возможность дописывать подфайлы, не трогая начало основного файла. Надо заметить, что, во-первых, это не сильно востребованная операция, поскольку все программы обычно записывают документы от начала до конца в один проход. Исключение составляет только MS Word и то только в пресловутом режиме быстрого сохранения, проклятом пользователями. А во-вторых, даже в этих условиях все равно не получится не трогать начало основного файла, поскольку надо обновлять каталоги, ТРФ и заголовки.
В общем, «Майкрософт» в своем амплуа. Зачем делать просто, если можно сложно и запутанно?
WordDocument
Формат CDF при всей своей монструозности хотя бы логичен и не очень сложен (если сравнивать с остальным содержимым вордовского документа). Его описание занимает всего каких-то двадцать страниц — тьфу по сравнению с 300 страницами формата Ворда.
Формат документа сложно даже назвать форматом, гораздо больше к нему подойдет определение каменной летописи. Представьте себе такой каменный обрыв, на котором отпечаталось пятьдесят миллионов лет истории планеты. Вот мезозойский слой, вот кайнозойский, вот отпечаток крыла птеродактиля, а сверху уже третичные отложения. Примерно так же выглядит и документ изнутри.
Достаточно посмотреть на заголовок, который занимает чуть ли не треть файла. Заголовков целых три. Сначала идет один небольшой, в котором половина записей зияет дырами «Reserved» или «Not used». Раньше, в мезозое, там явно что-то лежало, но потом было выкинуто на свалку истории. Здесь же имеется версия записавшей программы, по которой в коде, похоже, выполняется огромный switch/case.
Затем идет второй заголовок, состоящий из шестнадцатибитовых слов. В нем нет вообще ничего полезного. В его начале прописан размер явно с таким расчетом, что здесь будут в будущем откладываться панцири простейших.
После этого идет третий заголовок, на этот раз современный, из длинных слов (32 бита). Он немерянной длины, в начале тоже указывает количество записей с прицелом на дальнейшее расширение, и в основном представляет собой список, где искать различные таблицы и куски файла — пары начало/размер. Сами таблицы, кстати, лежат не здесь, а в отдельном псевдофайле CDF под названием 0Table или 1Table (возможны варианты).
В первом заголовке написана длина самого текста и его начало. Очевидно, что во времена царя Гороха именно так его и можно было прочитать. Текст лежал одним большим куском. Забавно, что можно читать его так и сейчас, но… не всегда! На десять читаемых файлов найдется такой, у которого в середине окажутся невразумительные куски, в конце — сноски, которых там быть не должно, а в самом начале — большой кусок текста, который стерли в прошлом году. Кроме того, половина файла окажется написана китайскими иероглифами. Прискорбно заметить, что известная утилита catdoc Витуса Вагнера в некоторых случаях именно такие результаты и дает, из чего можно сделать вывод, что формат она разбирает недокорректно.
Жизнь на самом деле гораздо сложнее. Когда-то в файлах действительно был только текст, однако со временем под давлением пользователей и маркетинга накапливались различные «фичи». Под них отвели отдельные потоки — под простые сноски, под сноски концевые, под колонтитулы, под какие-то textbox (то еще извращение — на вид текст, но не текст. Назначение толком не ясно).
Начала этих потоков указаны в специальных местах заголовка, но самый первый заголовок почему-то показывает общую длину — не самого текста, а текста плюс все этих извращений. Вот и первая причина, почему в вывод многих утилит попадают надписи типа Page 1.
Где-то в архее в редактор добавили быстрое сохранение. Смысл его в том, что файл целиком не переписывается, а добавления и изменения просто дописываются в его конец, что теоретически должно быть быстрее. Предполагалось радовать этим пользователей, но фактически они остались недовольны. Особой разницы в скорости записи при этом не получается, но в файле образуется много мусора, причем из кусков, которые теоретически уже стерты. Если там была какая-нибудь секретная информация, то простым просмотром дампа файла ее можно легко обнаружить.
Для поддержки быстрого сохранения была заведена особая таблица огрызков (piece table), в которую записывается начало каждого куска и его адрес в файле. Длины нет, но ее можно высчитать, вычтя начало текущего куска из начала следующего. Однако тут тоже надо быть осторожным, поскольку огрызки перечисляются из всех потоков. Слава богу, что они идут в определенном порядке, поэтому, зная общую длину текста, легко вовремя остановиться.
Теоретически, этот сложный формат задействован только, если в заголовке установлен специальный флажок fComplex. Но… Вот на этом очередном «но» тоже прокалываются многие конверторы.
Уже в наше время в документы добавили возможность записи в Юникоде. При этом встала проблема (как по мне, надуманная): а ведь файлы получаются ровно в два раза длиннее. Поскольку ПО разрабатывают американцы, которые в душе вообще не верят в существование других азбук, и тайно считают, что всякие странные буквы бывают только в диссертациях про Древнюю Грецию, да и там встречаются только иногда, первое, что пришло им на ум — отделить чистые символы ASCII от грязных юникодовских. Первые писать по байту на символ, вторые — как получится.
Из этой идеи возникла, например, элегантная кодировка UTF-8, где двухбайтовые символы кодируются хитрыми последовательностями в духе кодирования Хаффмана. В «Майкрософте» сделали то же самое, только не так красиво. Раз уж у нас есть таблица огрызков, то запишем туда заодно и какие куски текста написаны в чистом ASCII (на самом деле сp1252), а какие — на всякого рода невразумительных алфавитах, требующих Юникода и, соответственно два байта на символ. Поэтому нынешние файлы всегда нужно разбирать с помощью таблицы кусков, невзирая на всякие там флажки. Юникодовские фрагменты там берутся как есть, только надо учитывать, что количество читаемых байтов должно быть в два раза больше количества читаемых символов. Однобайтовые фрагменты отмечаются в адресе установленным вторым слева старшим битом (почему не первым?). Чтобы узнать настоящий адрес, нужно этот бит сбросить, а адрес разделить на два (!).
Если учесть, что сама эта таблица огрызков тоже занимает место, а еще больше места в файле занимают разные двоичные деревья и таблички цепочек секторов от формата CDF, то размеры экономии текста на символах Юникода не поразят воображения даже в древнегреческих диссертациях. О файлах на великом и могучем языке и говорить нечего. Положили бы все в UTF-16 и не страдали. Ну заархивировали бы поток, раз уж так жаба давит.
После героических усилий по чтению текста, в нем самом, как ни странно, нет ничего сложного. Обычный текст (с поправкой на кодировку), кое-какие коды ниже пробела играют служебную роль. Например, 0х9 обозначает, как и положено, табуляцию, 0хА — конец страницы, 0х7 — конец ячейки таблицы и т.д. Единственная тонкость связана с полями. Начало содержимого поля обозначается как 0х13, конец поля — 0х15, имя и параметры поля отделяются символом 0х14 от того, что, собственно, видно в тексте пользователю. Но… Вторая часть может иметь в себе вложенное поле, чего многие программы не учитывают. В результате в тексте остаются огрызки вроде INCLUDEPICTURE или PAGEREF *.
Впрочем, есть еще одна мелкая пакость. Некоторые символы могут означать что-нибудь совсем другое, вроде текущей даты. Чтобы понять, простой это символ или нет, надо разбирать таблицы свойств символов, о которых ниже. Каюсь, я просто вырезал все символы с кодом ниже пробела, что не совсем достаточно, но дешево, быстро и практично.
Выдрав текст, дальше в формат я углубляться не стал. Это уже занятие для молодых и сильных духом — разобрать все эти таблицы с такими многообещающими названиями как CHP, PAPX, SHST, PLCF и все в том же духе. Занятие совсем уже для титанов — вопроизвести форматирование в точности, как это делает сам Ворд.
Кратко изложу только, что все хранится в специальных таблицах, входом в которые служит адрес символа с начала потока. Стили лежат в длинных списках, изменения в стилях — в специальных списках исключений. Локальные изменения стиля, например, при редактировании абзаца или символа хранятся в таблицах как специальные команды по изменению родительских таблиц стилей. Сами команды очень напоминают команды виртуальной машины от типичной игры-квеста.
Осталось только подвести мораль, а она банальна: что один человек придумал, то другой завсегда поломать может. Что не делает формат Ворда менее позорным, уродливым и совершенно неприспособленным для задач массового обмена информацией в гетерогенных системах.
Думаю, что «Майкрософт» столько лет его не открывала не потому, что боялась конкуренции, а просто потому что было… стыдно.

Всем привет!
Этой статьей мы открываем цикл, посвященный исследованию безопасности компонентов Microsoft Office. Речь в материале пойдет о форматах данных, шифровании и получении символов.
Когда в компании Microsoft задумывался и разрабатывался масштабный пакет офисных программ Microsoft Office, вероятно, создатели надеялись на успех. Сложно сказать, могли ли они рассчитывать на его триумфальное шествие по миру впоследствии, на то, что продукт станет фактическим стандартом, а существование его растянется на десятилетия. Однако можно уверенно утверждать, что массивность приложений, количество человеко-часов, затраченных на создание, развитие, поддержку обратной совместимости компонентов продукта способствовали появлению «тяжелого наследия» в виде устаревшего, написанного десятилетия назад программного кода, составляющего ядро приложений даже в последних версиях пакета. Требования, которые предъявлялись к коду двадцать лет назад, изменились. Сегодня во главу угла ставится кроссплатформенность, масштабируемость и безопасность. При этом, расходы на значительные изменения в продукте таковы, что Microsoft предпочитает подход «не сломано – не трогай», и старательно обеспечивает обратную совместимость с самыми древними форматами документов. Не обходится и без определенного давления со стороны коммерческих и государственных структур, которые также медленно и неохотно обновляют свои технологические парки, предпочитая привычные средства в ущерб развитию и безопасности.
Покопавшись в дебрях обработчиков файлов Microsoft Office, мы готовы представить вам это небольшое исследование.
Component Object Model и хранение данных

Так может выглядеть использование приложением-контейнером разнородных компонетов независимо от их местоположения
На практике обычно подразумевается не столько сам стандарт, сколько его реализация в ОС семейства Windows. Первые версии COM были разработаны еще для 16-разрядных Windows в качестве основания для OLE (оно же теперь ActiveX). Изначальной целью разработки этих подсистем была возможность создания (!) составных документов Word и Excel для Windows 3.x, и они были выпущено на свет около 1991 года (в разных источниках даты расходятся).

Работая с приложением, пользователь изменяет изображение, содержимое окна браузера и строки в полях ввода. Само приложение взаимодействует с компонентами, вызывая их методы и устанавливая их свойства, иными словами, изменяя внутреннее состояние объектов, о внутреннем устройстве которых не имеет представления.
В один прекрасный момент пользователь решает сохранить проделанную работу и нажимает кнопку «Save». Перед нашим приложением стоит грандиозная задача — записать на диск набор данных в совершенно разных форматах, о большей части которых (и данных, и форматов) приложению ничего не известно, да и находятся они для него в недосягаемости! Именно для решения этой задачи специалисты Microsoft и разработали одновременно с COM и «родной» для Component Object Model формат файла Compound File Binary Format, а вместе с ним систему интерфейсов для взаимодействия с этим форматом и их реализаций, объединяемых под именем Structured Storage.
Структурированное Хранилище COM
Для универсального доступа приложений и компонентов к сложному, к тому же закрытому, формату CFBF, для прозрачной как для контейнера, так и для компонентов замены одного формата другим, были разработаны библиотечные интерфейсы IStorage и IStream и соответствующие API. Виртуальная структура данных, к которой получает доступ приложение посредством этих интерфейсов, представлена системой вложенных каталогов – Хранилищ (Storages), каждый из которых может содержать некоторое число последовательностей байтов – Потоков (Streams), в которых и хранятся данные.
Виртуальное представление формата CFBF (StructuredStorage)
Информация в потоках может храниться в любом удобном виде, включая текст, изображение в любом формате, зашифрованные или сжатые данные, или даже другие файлы CFBF. Не составляет труда поместить в поток и исполняемый код (в т.ч. вредоносный).
Используя соответствующие API (см. Structured Storage Reference в MSDN), приложение может создать файл-хранилище и предоставить каждому компоненту хранилище второго (третьего и т.д.) уровня или поток (несколько потоков) для сохранения состояния в любом формате. Контейнеру нет необходимости знать, в каком виде компонент запишет свои данные, а о размещении информации в файле позаботится стандартная библиотека. Когда необходимо загрузить сохраненное состояние, контейнер открывает хранилище и предоставляет загруженным компонентам возможность считать потоки по мере надобности.
- исключение необходимости для приложений сохранять многочисленные отдельные файлы для разных типов данных, в том числе, для экономии места на диске
- создание унифицированного интерфейса для работы с данными, облегчающего создание приложений, и, в особенности, COM-компонентов, работающих с составными документами
- возможность сохранять текущее состояние элемента данных в любой момент времени
- ускорение доступа к данным
Последний пункт требует отдельного рассмотрения. Разработка Структурированного Хранилища велась на заре развития COM (начало 90х годов), когда существующие аппаратные ресурсы предъявляли повышенные требования к быстродействию сложных систем, в том числе при чтении и записи дисковых файлов. Поэтому система хранения данных должна была быть максимально оптимизирована для быстродействия. Это исключало использование, к примеру, текстовых форматов, требующих значительной предварительной обработки. Напротив, двоичные форматы, позволяющие копировать данные в память с минимальными модификациями, имели преимущество.
Результатом стала дисковая реализация Структурированного Хранилища – формат составных двоичных файлов Microsoft (Compound File Binary Format). Долгое время формат оставался закрытым, спецификации были опубликованы производителем в 2006 году.
Формат CFBF представляет собой «файловую систему внутри файла» и имеет таблицу размещения файлов (FAT), таблицу секторов, директории и «потоки» — аналог дисковых файлов.

Техническое представление формата CFBF
- Ярлыки и списки быстрого доступа
- Кэш изображений и результатов поиска
- Файлы установки (msi и msp)
- «Заметки» Windows
Формат Compound Binary File в приложениях пакета Microsoft Office
Формат документов, используемый Microsoft Office, изначально также представлял собой CFBF.

Документ Word, открытый утилитой для просмотра Structured Storage
Современные версии пакета в качестве основного используют открытый, основанный на XML, формат OfficeOpen XML, однако поддержка CFBF не прекращается с целью поддержания совместимости. Необходимо заметить, что значительная масса кода, отвечающего за работу со старыми форматами документов, была разработана давно (около 20 лет назад).
| Word | .doc | Legacy Word document; Microsoft Office refers to them as «Microsoft Word 97 2003 Document» |
| .dot | Legacy Word templates; officially designated «Microsoft Word 97 2003 Template» | |
| .wbk | Legacy Word document backup; referred as «Microsoft Word Backup Document» | |
| Excel | .xls | Legacy Excel worksheets; officially designated «Microsoft Excel 97-2003 Worksheet» |
| .xlt | Legacy Excel templates; officially designated «Microsoft Excel 97-2003 Template» | |
| .xlm | Legacy Excel macro | |
| PowerPoint | .ppt | Legacy PowerPoint presentation |
| .pot | Legacy PowerPoint template | |
| .pps | Legacy PowerPoint slideshow | |
| Publisher | .pub | Microsoft Publisher publication |
Примеры устаревших, по-прежнему поддерживаемых форматов Office
Простой поиск по сайтам государственных структур и предприятий РФ (госзакупки, сайты административных единиц) обнаруживает обескураживающе большое количество официальной документации, выложенной в CFBF, зачастую созданной в древних версиях Office, например, 2003 года. Предоставим читателю провести этот опыт самостоятельно.

двоичный файл формата CFBF внутри документа OfficeOpenXML
Несмотря на то, что документы различных приложений Office основаны на CFBF, каждое хранилище состояний элементов OLE/ActiveX будет иметь свой собственный дополнительный формат. Нужно иметь ввиду, что они во многом сложились исторически и были оптимизированы для максимального быстродействия на слабых компьютерах.
Поддержка Хранилищ OLE форматом RTF
OLE-компонент отображения формул Microsoft EQUATION
Примером уязвимости, связанной с технологией COM Structured Storage, может служить CVE-2017-11882.

Уязвимость была обнаружена в компоненте Microsoft Office настолько древнем, что производителем были утрачены исходные коды компонента.
Для сохранения состояния элементы Редактора Формул (Microsoft Equation Editor) использовали потоки структурированного хранилища. Нарушение целостности данных в потоках приводило к многочисленным уязвимостям, первой обнаруженной из которых была CVE-2017-11882, найденная специалистами Embedi.

Поток структурированного хранилища элемента EquationEditor
Некоторые другие унаследованные двоичные форматы, используемые в пакете Microsoft Office
Графический фильтр EPS
Графический фильтр EPS представляет собой компонент Office, который отвечает за редактирование EPS-изображений. Они являются векторными и строятся при помощи интерпретации внутреннего языка Encapsulated PostScript (версия обычного PostScript с некоторыми ограничениями).
В силу своих особенностей этот язык поддерживает самые разнообразные конструкции и возможности. Благодаря чему уязвимости повреждения памяти в графическом фильтре EPS эксплуатируются достаточно легко. Богатство языка делает возможным использование техник HeapSpray (например, возможность использования циклов) и HeapFengShui (предсказуемость выделения памяти интерпретатором). Даже несмотря на то, что рендеринг изображения происходит на виртуальном принтере, а само исполнение программы «EPS» происходит в рамках изолированного интерпретатора, наличие благоприятных возможностей эксплуатации уязвимостей и старая кодовая база сделали EPS едва ли не самым распространенным вектором атаки офисных приложений.
Ввиду того, что модуль был изначально разработан компанией Access Softek, а затем передан компании Microsoft, в этом компоненте найдено и успешно эксплуатируется существенное число «неизвестных» уязвимостей. Например, в апреле 2017 года компанией FireEye Inc. были найдены уязвимости CVE-2017-0261 и CVE-2017-0262. Эти две уязвимости повреждения памяти позволили злоумышленникам построить READ/WRITE-примитивы, с помощью которых они и добились выполнения своего кода за пределами изолированного процесса («песочницы») интерпретатора PostScript. Злоумышленники могут читать и записывать произвольные участки памяти в адресном пространстве уязвимого процесса, а также могут выполнить, например, поиск необходимых ROP гаджетов для построения ROP-цепочки, делающей остальной шелл-код исполняемым.
В обоих случаях атакующие добивались исполнения произвольного кода похожим образом: создавали объект в памяти с контролируемым содержимым (это было возможно сделать при помощи R/W примитивов) и вызывали один из его методов при помощи функции PostScript.
Данные уязвимости в графическом фильтре «EPS» стали популярным вектором атаки. Причем настолько, что компания Microsoft в апреле 2017 разработала обновление, которое полностью отключает графический фильтр. Однако, патч применим только для версии MsOffice 2010 SP2 и выше.
Базы данных Access
- использование макросов VBA в качестве некоторых триггеров и хранимых процедур;
- возможность использования ссылок на другие базы данных;
- закрытость формата БД препятствует использованию существующих баз в других окружениях.
Первый недостаток весьма серьезный, поскольку VBA-макросы по своим возможностям равносильны обычным исполняемым файлам. По этой причине использование Access может стать проблемой для безопасности.
Пользователь должен доверять БД, с которой работает, и быть уверенным, что в ней не содержится вредоносный код, внесенный злоумышленником. В противном случае запрет исполнения макросов существенно сокращает функциональность приложения для работы с данными в таблицах и представлениями.
Файлы Личных Папок Outlook
Спецификация .ost не была опубликована, и формально доступ к файлу Offline Storage Table может осуществляться только посредством MAPI. На деле эти форматы очень схожи и редактирование .ost также возможно. Необходимо иметь ввиду, что синхронизация отредактированного содержимого файла Offline Storage Table с данными на сервере Exchange может привести к необратимой порче данных и утере значимой информации.
Файл владельца/OwnerFile
Проблема совместной работы над документами Office, расположенными в сетевых хранилищах, была когда-то решена при помощи временных файлов простого формата, так называемых OwnerFile. Если файл в данный момент заблокирован для редактирования, приложение ищет в той же директории файл с коротким именем формата «
$name.doc». Файл содержит имя пользователя, открывшего документ в ASCII и Unicode форматах, в обоих случаях под имя отведен фиксированный размер массива. При создании файла неиспользуемые байты массива заполняются мусорными значениями из памяти приложения, что потенциально может привести к раскрытию чувствительной информации (в целом, из-за размера файла вероятность этого невелика). Имя пользователя в файле владельца также легко подделывается.
Механизм шифрования офисных документов
Механизм парольной защиты документов впервые появился в пакете Office 95. В то время стойкости используемых алгоритмов шифрования уделялось мало внимания, как следствие, применялись алгоритмы, на которые существовали практически применимые атаки. Этот факт стал толчком к изменению механизма в последующих версиях офисных пакетов.
В таблице приведены в хронологическом порядке наиболее распространенные в данное время офисные пакеты и используемые в них по умолчанию алгоритмы шифрования.
Публикация - своего р ода памятка, содержащая примеры кода для:
1. заполнение шаблона Word данными из 1С;
2. заполнение колонтитулов Word данными из 1С;
3. заполнение таблицы в Word данными из 1С;
Начало работы
В большинстве случаев перед нами ставится следующая задача:
Нужно открыть документ Word, заполненный данными из 1С.
Для этого нам нужно подготовить шаблон документа Word. Не путайте это с Word Template, специальные файлы Word, которые содержат настройки документов для многократного использования. Нам нужен обычный вордовский документ с расширениеми *.docx или *.doc. А далее поместить этот документ в макет с двоичными данными.
Читатель может справедливо заметить, что используется модальный вызов, и погрозить автору пальцем. И будет прав.
Далее я обычно создаю структуру полей, которые будут заполняться в шаблоне. Такой подход позволяет унифицировать процедуру заполнения шаблона, а также упростить последующее его изменение.
Углубимся немножко в принципы работы Word.
Каждый документ Word разделен на разделы, которые состоят из страниц.
Для каждого раздела есть возможность создавать свою нумерацию элементов, уникальные колонтитулы и настройки параметров страницы. Так, например, чтобы повернуть одну из страниц (вывести на печать как альбомную), нужно создать под неё отдельный раздел.
Каждая страница Word разделена на несколько областей:
- Верхний колонтитул
- Основной текст
- Нижний колонтитул
Нужно заметить, что в каждом разделе может быть уникальный колонтитул для первой страницы.
Заполнение пользовательских параметров
При обращении к этим коллекциям мы можем выполнять в них поиск и получать встроенные объекты, например, таблицы.
Теперь мы более-менее поняли, как обращаться к областям Word, можем в них пошуровать и выполнить замену наших параметров:
Рассмотри подробнее метод Execute. Его параметры идентичны диалоговуму окну при замене/поиске непоседресвенно из MS Word:
А вот и основные параметры (вольный перевод справки MSDN):
- Искомый текст - Строка - Текст для замены. Текст может содержать специальные параметры. Например, ^p - абзац, ^t - табуляция
- Чувствительность к регистру - Булево - Если истина, то поиск будет осуществляться с учетом регистра
- Слова целиком - Булево - Если истина, то ищутся слова целиком. Вхождение слов не учитываются. Например, при поиске слова дом будет пропущено слово домашний
- Использовать подстановочные знаки - Булево - Если истина, то используются встроенные регулярные выражения.
- Искать похожие - Булево - Если истина, то результат поиска будет содержать похожие слова
- Искать все формы - Булево - Если истина, то результат поиска будет содержать различные формы слов.
- Поиск сначала - Булево - Если истина, то будет осуществляться с начала до конца документа
- Охват - WdFindWrap - Опредяляет направление поиска
- Формат - Format - Формат искомого текста
- Строка замены - Строка - Строка, на которую будет заменен исходный текст
- Количество замен - WdReplace - Определяет сколько раз выполнять замену
- и т.д.
WdReplace - Constant Value:
wdReplaceAll 2
wdReplaceNone 0
wdReplaceOne 1
Данный метод не позволяет получить "Строка замены" как выделенную область, но он работает где-то в 10 раз медленнее. Для получения выделенной области можно воспользоваться немножко откорректированной типовой функцией:
Уже получив выделенную область можно отредактировать стиль текста, шрифт и т.д.
Также есть второй подход, использующий такой объект Word, как поля. Мне он не очень нравится, т.к. в больших документах, порядка 100 страниц, эти поля начинают глючить (исчезать, не подставлять нужные значения) и прочая ерунда. Ну по крайней мере в Word 2007. Но я его все равно приведу:
При подготовке шаблона в тело документа необходимо навставлять полей с типом DOCVARIABLE (можно вставлять горячими клавишими Ctrl+F9).
Доступ к таким полям можно получить следующим нехитрым образом:
Заполнение таблиц по шаблону
Итак, мы заполнили параметры в основном тексте документа, заменили параметры в колонтитулах, но у нас еще есть одна неприятность - нужно заполнить таблицу.
Подход, описанный ниже, годится только для таблиц с заранее известным форматом. Т.е. мы можем как угодно отформатировать таблицу и её строки изначально. Но потом изменять довольно-таки проблематично.
К таблицам можно получить доступ через области документа.
Далее, получив таблицу, мы работаем с ней по привычной схеме - строки, столбцы.
Для задания форматирования легче в шаблоне создать таблицу с пустой первой строкой, которую мы в последующем удалим.
Вот, в принципе, и все. Основные вопросы, возникающие при работе с Word, я постарался осветить. Надеюсь, данный обзор поможет вам в работе =)
Спасибо за советы и комментарии:
v3rter, monkbest
Критика только приветствуется. Чем больше замечаний, тем лучше будет гайд =)
Читайте также: