
Какие методы позволяют предотвратить переполнение приемных буферов коммутаторов или маршрутизаторов
Обновлено: 04.07.2024
Узкие места сетевой подсистемы Linux. Тюнинг сети в Linux. Настройка производительности сети в модели NAPI и с прерываниями.
Создано 22.11.2016 11:53
Узкие места сетевой подсистемы Linux. Тюнинг сети в Linux. Настройка производительности сети в модели NAPI и с прерываниями.
Кольцевой буфер
Кольцевые буферы, совместно используются драйвером устройства и сетевой картой. TX – есть передача данных, а RX – получение данных в кольцевом буфере. Как следует из названия, переполнение буфера просто перезаписывает существующие данные. Есть два способа переместить данные от сетевой карты до ядра: аппаратные прерывания и программные прерывания, названные SoftIRQs.
Кольцевой буфер RX используется, чтобы сохранить входящие пакеты, пока они не могут быть обработаны драйвером устройства. Драйвер устройства опустошает буфер RX, обычно через SoftIRQs, который помещает входящие пакеты в структуру данных ядра, названную sk_buff или «skb», чтобы начать свой путь через ядро и до приложения, которому принадлежит соответствующий сокет. Кольцевой буфер TX используется для хранения исходящих пакетов, которые предназначенные для отправки по проводам.
Эти кольцевые буферы находятся у основания стека и являются критическим моментом, в который может произойти удаление (drop) пакетов, что негативно влияет на производительность сети.
Прерывания и обработчики прерываний
Прерывания от аппаратных средств известны как прерывания «top-half».
Сетевые карты, как правило, работают с кольцевыми буферами (DMA ring buffer) организованными в памяти, разделяемой с процессором. Каждый входящий пакет размещается в следующем доступном буфере кольца. (DMA - Direct Memory Access (Прямой доступ к памяти) — режим обмена данными между устройствами или же между устройством и основной памятью, в котором центральный процессор (ЦП) не участвует). После этого требуется сообщить системе о появлении нового пакета и передать данные дальше, в специально выделенный буфер (Linux выделяет такие буферы для каждого пакета). Для этой цели в Linux используется механизм прерываний: прерывание генерируется всякий раз, когда новый пакет поступает в систему. Чаще используется отложенные прерывания (см. в статье Linux, принципы работы с сетевой подсистемой ). В ядро Linux начиная с версии ядра 2.6 был добавлен так называемый NAPI (New API), в котором метод прерываний сочетается с методом опроса. Сначала сетевая карта работает в режиме прерываний, но как только пакет поступает на сетевой интерфейс, она регистрирует себя в poll-списке и отключает прерывания. Система периодически проверяет список на наличие новых устройств и забирает пакеты для дальнейшей обработки. Как только пакеты обработаны, карта будет удалена из списка, а прерывания включатся снова.
Жесткие прерывания можно увидеть в /proc/interrupts, где у каждой очереди есть vector прерывания в 1-м столбце. Каждой очереди RX и TX присвоен уникальный vector, который сообщает обработчику прерываний, относительно какого NIC/queue пришло прерывание. Столбцы представляют количество входящих прерываний:
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7
45: 28324194 0 0 0 0 0 0 0 PCI-MSI-edge eth1
SoftIRQs
Иизвестны как прерывания «bottom-half», запросы программного прерывания (SoftIRQs), являются подпрограммами ядра, которые планируется запустить в то время, когда другие задачи не должны быть прерваны. Цель SoftIRQ состоит в извлечении данных из кольцевых буферов. Эти подпрограммы, выполненные в форме процессов ksoftirqd/cpu-number и, вызывают специфичные для драйвера функции кода.
После перемещения данных от драйвера к ядру, трафик двигатется вверх к сокету приложения.
SoftIRQs можно контролировать следующим образом. Каждый столбец есть ЦП:
NAPI Polling
Поиск узкого места
Отбрасывание пакетов и переполнени границ (packet drops и overruns) обычно происходит, когда буфер RX сетевой карты не может достаточно быстро опустошиться ядром. Когда скорость, с которой данные поступают из сети превышает скорость, с которой ядро забирает на обработку пакеты, сетевая карта начинает отбрасывать входящие пакеты, т.к. буфер NIC (сетевой карты) полон, и увеличивает счетчик удаления.Соответствующий счетчик можно увидеть в ethtool статистике. Основные критерии здесь - прерывания и SoftIRQs.
Для примера вывод статистики ethtool:
Существуют различные инструменты, доступные для поиска проблемной области. Следует исследовать:
• Уровень встроенного ПО адаптера
- Следим за статистикой ethtool -S ethX
• Уровень драйвера адаптера
• Ядро Linux, IRQs или SoftIRQs
- Проверяем /proc/interrupts и /proc/net/softnet_stat
• Уровни протокола IP, TCP, UDP
- Используем netstat -s и смотрим счетчики ошибок
Вот некоторые типичные примеры узких мест:
- Прерывания (IRQs) неправильно сбалансированы. В некоторых случаях служба irqbalance может работать неправильно или не работает вообще. Проверьте /proc/interrupts и удостоверьтесь, что прерывания распределены на разные ядра ЦП. Обратитесь к irqbalance руководству, или вручную сбалансируйте IRQs. В следующем примере прерывания становятся обработанными только одним процессором:
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5
105: 1430000 0 0 0 0 0 IR-PCI-MSI-edge eth2-rx-0
106: 1200000 0 0 0 0 0 IR-PCI-MSI-edge eth2-rx-1
107: 1399999 0 0 0 0 0 IR-PCI-MSI-edge eth2-rx-2
108: 1350000 0 0 0 0 0 IR-PCI-MSI-edge eth2-rx-3
109: 80000 0 0 0 0 0 IR-PCI-MSI-edge eth2-tx
- Посмотрите, увеличивается ли какая-либо из колонок помимо 1-й колонки в /proc/net/softnet_stat. В следующем примере счетчик большой для CPU0, и budget должен быть увеличен:
0073d76b 00000000 000049ae 00000000 00000000 00000000 00000000 00000000 00000000 00000000
000000d2 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
0000015c 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
- SoftIRQs не может получать достаточное количество процессорного времени для опроса адаптера. Используйте инструменты, такие как sar, mpstat или top, чтобы определить, что отнимает много процессорного времени.
- Используйте ethtool -S ethX, чтобы проверить определенный адаптер:
- Увеличение приемного буфера сокета приложения или использование буфера автоподстройки.
- Использование большого/малого TCP или UDP размера пакетов.
Настройка производительности
SoftIRQ
Если выполнение программных прерываний не выполняются достаточно долго, то темп роста входящих данных может превысить возможность ядра опустошить буфер. В результате буферы NIC переполнятся, и трафик будет потерян. Иногда, необходимо увеличить длительность работы SoftIRQs (программных прерываний) с CPU. За это отвечает netdev_budget. Значение по умолчанию 300. Параметр заставит процесс SoftIRQ обработать 300 пакетов от NIC перед тем как отпустить CPU:
Это значение может быть удвоено, если 3-й столбец в /proc/net/softnet_stat увеличивается, что указывает, на то, что SoftIRQ не получил достаточно процессорного времени. Маленькие инкременты нормальны и не требуют настройки.
0073d76b 00000000 000049ae 00000000 00000000 00000000 00000000 00000000 00000000 00000000
000000d2 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
0000015c 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
0000002a 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
IRQ Balance
Балансировщик прерываний - это сервис, который может автоматически сбалансировать прерывания между ядрами процессора, основанного на реальном времени состояния системы.
Прерывания также можно раскидать по ядрам вручную.
Чтобы это сделать нужно выполнить команду echo N > /proc/irq/X/smp_affinity, где N - маска процессора (определяет какому процессору достанется прерывание), а X - номер прерывания, виден в первом столбце вывода /proc/interrupts. Чтобы определить маску процессора, нужно возвести 2 в степень cpu_N (номер процессора) и перевести в шестнадцатиричную систему. При помощи bc вычисляется так: echo "obase=16; $[2 ** $cpu_N]" | bc. Например:
Для того, чтобы при старте системы прерывания сами настраивались, можно сделать скрипт и настроить его запуск /etc/rc.d/rc.local.
Ethernet flow control
Паузы фреймов - управление потоком уровня Ethernet между адаптером и портом коммутатора. Адаптер передаст “кадры паузы”, когда RX или буферы TX станут полными. Коммутатор остановит поток данных в течение определенного промежутка времени в порядке миллисекунд. Этого времени обычно достаточно, чтобы позволить ядру опустошить интерфейсные буферы, таким образом предотвращая переполнение буфера и последующие пакетные отбрасывания или переполнения. В идеале, коммутатор буферизует входящие данные в течение такой паузы.
Однако, важно понимать, что этот уровень контроля потока только между коммутатором и адаптером. Если пакеты отброшены, более высокие уровни, такие как TCP или приложение в случае UDP и/или многоадресно переданы, должен инициировать восстановление.
Важно! Фреймы паузы и flow control (управление потоком) должны быть включены и на NIC и на порте коммутатора.
Pause parameters for eth3:
Pause parameters for eth3:
Interrupt Coalescence (отложенные прерывания)
Отложенные прерывания рассказывают нам о количестве трафика, который будет получать сетевой интерфейс, или времи, которое проходит после приема трафика, перед выдачей жесткого прерывания. Слишком ранние прерывания или слишком частые приводят к снижению производительности системы, так как ядро останавливается (или «перебивает») запущенное задание для обработки запроса прерывания от аппаратного обеспечения. Слишком поздее прерывание может привести к тому, что пакеты достаточно долго не будут обработаны ядром с сетевой карты. Большие объемы трафика могут переписать предыдущие пакеты трафика, т.е. потеря пакетов.
Самые современные NIC и драйверы поддерживают IC, и многие позволяют драйверу автоматически модерировать количество прерываний, сгенерированных аппаратными средствами. Настройки IC обычно включают два основных компонента, время и количество пакетов. Время в мкс - сколько NIC будет ожидать прежде, чем прервать ядро, а число пакетов – сколько пакетов будет ждать в приемном буфере прежде чем сработает прерывание. Отложенные прерывания NIC можно посмотреть, используя команду ethtool -c ethX и настроить через ethtool -C ethX. Адаптивный режим позволяет карте автомодерировать IC. В адаптивном режиме, драйвер инспектирует трафик и ядро настраивает прерывания на лету, предотвращая потерю пакетов.
Coalesce parameters for eth3:
Adaptive RX: on TX: off
Следующая команда выключает адаптивный IC, и говорит адаптеру о прерывании ядра
сразу после приема любого трафика:
Очередь адаптера (The Adapter Queue)
Netdev_max_backlog - очередь в ядре Linux, где трафик хранится после получения от сетевого адаптера, но перед обработкой с помощью стеков протоколов (IP, TCP, и т.д.). Для каждого ядра процессора существует одна очередь. Очередь может расти автоматически до максимального значения, указанного в netdev_max_backlog. Функция ядра netif_receive_skb () находит соответствующий ЦП для пакета и ставит пакеты в очереди того ЦП. Если очередь для этого процессора будет полна и уже в максимальном размере, пакеты будут отброшены. Для того, чтобы тюнить это место необходимо убедиться что оно реально нужно. В /proc/net/softnet_stat в втором столбце есть счетчик, который увеличивается когда очередь переполняется. Каждая строка файла softnet_stat представляет собой ядро процессора, начиная с CPU0.
1-й столбец - количество кадров, полученных с помощью обработчика прерывания.
2-й столбец - количество фреймов, отброшенных из-за превышения netdev_max_backlog..
3-й столбец - число раз ksoftirqd исчерпал netdev_budget или процессорное время, когда нужно было еще поработать.
0073d76b 00000000 000049ae 00000000 00000000 00000000 00000000 00000000 00000000 00000000
000000d2 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
0000015c 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
0000002a 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
В текущем выводе netdev_max_backlog не нуждается в тюнинге, т.к. очередь не переполняется и нет потерь соответственно. Если же наблюдаются приащения в второй колонке, тогде увеличиваем значение очереди и снова смотрим в этот файл. Если увеличения этого значения мы видим что скорость приращений в втором столбце уменьшается то можно еще увеличить значение backlog. Повторяем этот процесс пока перестанет расти цифры в столбце 2.
Backlog изменить можно такой командой:
Adapter RX and TX Buffer
Буфер адаптера по умолчанию обычно установлен в меньшем размере, чем максимальный. Часто, увеличить размер буфера приема RX вполне достаточно, чтобы предотвратить потери пакетов, так как это может приводит к тому, что у ядра будет немного больше времени, чтобы опустошить буфер. В результате, это может предотвратить возможные потери пакетов.
Буферы можно посмотреть так:
Ring parameters for eth3:
Current hardware settings:
Тут видим что кольцевой буфер RX входящих пакетов равен 1024 дескрипторам в оперативной памяти, и можно увеличить до 8192.
Очередь передачи (Adapter Transmit Queue Length)
Длина очереди передачи определяет количество пакетов, которые могут быть поставлены в очередь перед передачей. Значение по умолчанию 1000 - обычно достаточно для сегодняшней скорости до 10 Гбит/с или даже 40 Гбит/с сетей. Однако, если число ошибок передачи увеличиваются на адаптере, то значение можно удвоить. Используйте ip -slink, чтобы увидеть, если есть какие-то потери на очереди TX для адаптера.
Увеличить длину очереди можно так:
TCP Window Scaling (масштабирование окна TCP)
Масштабирование Окна TCP включено по умолчанию:
TCP буфер
После того, как сетевой трафик обрабатывается от сетевого адаптера, предпринимается попытка приема трафика непосредственно в приложение. Если это не представляется возможным, данные ставятся в очередь на буфер сокета приложения. Есть 3 структуры очереди в сокете:
sk_rmem_alloc – очередь получения
sk_wmem_alloc – очередь передачи
sk_omem_alloc - out-of-order queue
Существует также sk_rcvbuf переменная, которая является пределом, измеренный в байтах, что сокет может получить. В этом случае sk_rcvbuf = 125336.
Из приведенного выше вывода можно вычислить, что очередь получения почти полна. Когда sk_rmem_alloc > sk_rcvbuf то буфер начинает рушится, т.е. наблюдаются потери пакетов. Выполните следующую команду, чтобы определить, происодит это или нет:
17671 packets pruned from receive queue because of socket buffer overrun
18671 packets pruned from receive queue because of socket buffer overrun
Если счетчик обрезки пакетов растет, то требуется тюнинг.
tcp_rmem: У настраиваемой памяти сокета есть три значения, описывающих минимальное, значение по умолчанию и максимальное значения в байтах. Чтобы просмотреть эти настройки и увеличить:
4096 87380 4194304
TCP Listen Backlog: отвечает за размер очереди одновременно ожидающих подключений к сокету, то есть инициированных (SYN - SYN, ACK - ACK), но еще не принятых сервером (established).
Параметр ядра net.core.somaxconn - максимальное число открытых сокетов, ждущих соединения. Изменяем:
UDP Buffer Tuning: UDP является гораздо менее сложным, чем протокол TCP. Поскольку UDP не содержит надежности сеанса, он не несет ответственности за повторную передачу потерянных пакетов. Там не существует понятия размера окна и потерянные данные не восстанавливается протоколом. Единственная доступная настройка включает в себя увеличение размера приемного буфера. Если netstat -us показывает “packet receive errors” , попробуйте увеличить число буферов для приема. Буферы UDP могут быть настроены таким образом:
Сегодня перед специалистами, отвечающими за информационную безопасность корпоративных ресурсов, очень остро стоит проблема атак на сеть путем переполнения буфера. Практически каждую неделю, а иногда и несколько раз в течение одной недели консультанты LiveSecurity (служба сервиса компании WatchGuard) предупреждают о новых уязвимостях, связанных с переполнением буфера.
События, связанные с безопасностью, переполнение буфера, как ни прискорбно встречаются везде, даже в коде, в котором по заверениям разработчиков все потенциальные возможности этой встречи исследованы и устранены. Возможно, вы слышали о таких вариантах переполнения буфера, как формат строки или атаки на хип. В этой статье, используя аналогии из повседневной жизни, я попытаюсь объяснить, как работают эти атаки. Я позаимствую идею, почерпнутую мною из книги Брюса Шнеера Секреты и ложь (Bruce Schneier “Secrets and Lies”), хотя, как типичный хакер, эту идею разовью и обобщу.
Глупый продавец
Шнеер объясняет переполнение буфера, сравнивая компьютерную память с перекидным ежедневником, содержащим инструкции для продавца круглосуточного магазина. На каждой странице написана одна инструкция, например: «Поприветствовать посетителя», «выбить чек», «принять деньги». Предположим, что продавец глуп и может работать, только дослов-но выполняя инструкции.
Все это делает наш магазин уязвимым для простой атаки. Атакующий подходит к стойке и, пока продавец роется в инструкциях, вставляет в них листок, на котором написано: «Взять все деньги из кассы и передать их покупателю». Единственное на что в подобном случае можно надеяться, так это то, что, если продавец точно выполняет все инструкции, то он должен был их запомнить, и, наверное, заметит, что здесь что-то неладно.
По страницам моей памяти…
В отличие от продавцов, компьютеры точно выполняют инструкции и, при этом, вообще лишены чувств. Если атакующий сможет подсунуть компьютеру дополнительные инструкции, он выполнит эти инструкции один в один. Это является основой для нападения, связанного с переполнением буфера.
Существует три разновидности атак, основанных на переполнении буфера: атаки на стек, атаки на формат строки и атаки на хип. Эти разновидности одинаковы по сути, но каждая направлена на разные части памяти компьютера. Для того, чтобы понять различия между этими атаками, я вкратце обрисую как работает компьютерная память.
Когда программа начинает выполняться, операционная система выделяет для нее виртуальную память большого размера. Можно рассмотреть эту память как разграфленную тетрадь, в которой написана программа, начиная со страницы один, где хранятся инструкции и заканчивая данными программы. После того, как программа записана, остается много чистых страниц.
Пустые страницы, находящиеся сразу же за данными программы называются хипом (куча, heap), а те, которые находятся в самом конце тетради, называются стеком. Точно так-же, как если бы вы использовали тетрадь с двух сторон, хип будет расти в сторону конца тетради, а стек – в сторону начала. А тетрадь (то есть виртуальная память) настолько велика, что хип никогда не достигнет стека и наоборот.
Позиции внутри этой виртуальной памяти (страницы в тетради) в программе ли, в стеке, в хипе или между ними, задаются адресами, выраженными в шестнадцатеричном формате. Например, самый старший адрес в памяти размером в два гигабайта будет равным 8FFFFFFF. Небольшие области этого адресного пространства служат для ввода данных в программу. Эти области, которые могут иметь адреса в стеке или хипе, называются буфера-ми. Ага! Мы нашли первую разгадку на пути того, почему атаки называются «переполнения буфера». Если вы услышите, как кто-то говорит «это переполнение буфера в стеке» или «это нападение на стек» или «это переполнение буфера хипа» - это значит, он хочет указать на проблему с памятью, выделенной программе.
Атаки на стек
В стеке хранятся временные данные. Вновь мы можем проиллюстрировать это примером из книги Шнеера. Предположим, что вы пишете заметки по проекту, над которым вы работаете, когда звонит телефон. Звонящий сообщает некую информацию, которую вы у него запрашивали, следовательно, вы берете новый листок бумаги, кладете его поверх первого и записываете эту информацию. Прежде чем вы успеваете завершить разговор, в комнату входит начальник, привлекает ваше внимание и просит вас сделать кое-что по окончании звонка. Вы берете еще один листок бумаги и записываете на него просьбу начальника. Теперь у вас есть небольшая стопка (стек) листков бумаги, с написанными на них инструкциями и данными. Как только вы выполняете очередное задание, вы сминаете листок и бросаете его в мусорную корзину. Вы используете стек таким же образом, как и в случае с атакой, направленной на переполнение буфера.
Если мы будем говорить о компьютерах, то там, конечно, нет листков бумаги, а есть просто память (RAM). Данные действительно добавляются в стек сверху и потом извлекаются. При атаке «переполнение буфера», направленной на стек, нарушитель добавляет в него больше данных, чем предусмотрено, при этом лишняя часть перезаписываются поверх данных, для которых разработчик программы не предусмотрел такой вариант.
Например, давайте пред-положим, что при исполнении программы она дошла то такой стадии, на которой необходимо использовать почтовый индекс из Web формы, заполненной пользователем. Длина даже самого длинного почтового индекса не превышает двенадцати символов. Но в нашем примере Web форму заполняет нарушитель. Вместо того, чтобы ввести почтовый код он 256 раз вводит букву «А», а за ней пишет определенные команды. После того, как программа получает эту сверхдлинную строку, бессмысленные данные переполняют буфер, выделенный для постового индекса (как вы помните, буфер – это область памяти, зарезервированная для ввода данных) и команды атакующего попадают в стек.
Также как и в случае с вором, подсовы-вающим инструкцию «Отдай мне все деньги» в круглосуточном магазине, атака типа «переполнение буфера» подкладывает инструкции, которые программа в обычных условиях не должна выполнять. Будучи дословным исполнителем, компьютер не сможет выполнить неверные инструкции – программа завершится аварийно. Если же инструкции точны - программа слепо выполнит команды атакующего.
В идеале, программисты защищаются от атак, связанных с переполнением буфера путем проверки размерности всех данных, поступающих в программу, и того, что они не превысят тот размер памяти, который для них предусмотрен. (В приведенном выше примере с почтовым индексом, программа должна быть написана так, чтобы не вводить больше двенадцати символов).
На практике же программисты часто забывают о том, что программу могут атаковать или что данные могут поступать из «ненадежных» источников. Чем больше и сложнее становится программа, тем больше вероятность того, что произойдет атака.
Атаки на формат строки
Атаки на формат строки также используют стек, но требуют гораздо меньше изменений, чем переполнение буфера стека, которое мы обсуждали ранее. Форматирование означает подготовку каких-либо данных к отображению или печати. Однако, инструкции форматирования так гибки, что некоторые нарушители нашли способы использовать их для записи в память. Атаки на формат строки обычно добавляют в память адрес, указывающий на другую ссылку, по которой нарушитель добавляет свои исполнимые инструкции.
Используя нашу аналогию с «глупым продавцом», предположим, что его книга с инструкциями содержит 25 страниц. Предположим также, что после страницы с инструкцией, гласящей «возьми у покупателя деньги и открой кассу», вор вставил инструкцию «Перейди на страницу 26». Вор мог подготовить несколько страниц с инструкциями типа «Отдай покупателю все деньги», «Дай ему уйти и не поднимай тревоги» и поместить их в конец книги. Если глупый продавец будет следовать этим указаниям, это будет аналогично программе, которая перешла по указанному адресу в памяти и выполнила все найденные там инструкции.
Кучи проблем
Защита: о жуках и канарейках
Мы уже знаем, что является наилучшей защитой от подобного вида атак – это грамотное программирование. В идеале, каждое поле в каждой программе должно позволять только заданное число символов (концепция, известная как «проверка границ») заданного типа (почему, например, программа должна позволять вводить буквы или метасимволы типа % для телефонного номера). Также мы знаем, что программы несовершенны, они содержат ошибки, а некоторые из этих ошибок позволяют проводить атаки. Поскольку программы несовершенны, программисты придумали схемы защиты от атак, связанных с переполнением буфера.
Простейшая схема основана на том, что в стеке и хипе должны быть только данные, компьютер никогда не должен выполнять найденные там инструкции. Этот подход прекрасно работает во многих UNIX-системах, однако, он не может использоваться в Windows. Более того, эта схема заставляет UNIX-администраторов изменять параметры конфигурации на каждом сервере. Легче всего это сделать на неинтеловских процессорах (например Sun Microsystem\'s Sparc).
Другая популярная схема защищает от переполнения буфера, но, только того, который связан со стеком. Эта защита основана на использовании «канареек». Помните рассказы про шахтеров, которые брали с собой в угольные шахты канареек? В шахтах часто выделяется опасный газ - метан, который не имеет запаха и ядовит. Если шахтеры будут углублять шахту в ту сторону, где выделяется метан, канарейки умрут первыми, чем дадут шахтерам шанс покинуть опасную зону.
«Канарейка» в стеке защищает его будучи помещенной в критические места памяти (около адресов возврата, которые являются критическими местами в стеке, указывая компьютеру какие команды выполнять после завершения текущей функции). Перед использованием адресов возврата программа проверяет в порядке ли «канарейка». Если «канарейка» уничтожена, программа завершает работу, сообщая об ошибке.
«Канарейки», конечно, помогают, но не могут полностью защитить от атак на хип. Атаки на хип совершенно не затрагивают стек и обходят «канареек». Таким образом, программисты должны создавать такой код, который позволяет копировать в буфер только то количество данных, на которое он был рассчитан (или, другими словами, писать программы правильно). Этот способ является наиболее эффективной защитой.
Что вы можете сделать с переполнением буфера
Службы прокси WatchGuard функционируют следующим образом: они аккуратно исследуют протоколы, которые призваны наблюдать. Если пакеты или команды, отличаются от обычных, правомерных, используемых наблюдаемым протоколом, то служба прокси разорвет соединение с источником несоответсвия. При включенной службе обнаружения аномалии протокола, служба прокси сделает больше, чем в обычном случае – она не только разорвет соединение, но и добавит адрес клиента в список блокированных источников. Попытки соединения этого клиента с системой будут игнорироваться, пока не истечёт время автоматического блокирования.
При взаимодействии с DNS сервером, клиент посылает запрос, сервер его выполняет, тем самым отвечая клиенту. Служба DNS прокси следит за тем, чтобы форма запроса была заполнена корректно, проверяя длину запроса. Слишком короткие или чересчур длинные запросы вызывают ошибки переполнения буфера в DNS серверах. Кроме того, DNS прокси удостоверяется в корректности заполнения остальных частей формы.
Служба SMTP прокси проверяет, что бы все строки, полученные при использовании этого протокола, являлись его частью. Служба также следит за тем, чтобы ни одна строка не была длиннее, чем заранее задано. Количество символов можно изменить при помощи WatchGuard Policy Manager, по умолчанию оно равно 1000. По длине адреса документом RFC 2822 рекомендовано ограничение в 256 символов. Чем больше это ограничение, т.е. чем короче адрес, тем сложнее произвести атаку.
Также служба прокси проверяет и содержимое электронного письма на наличие запрещённого содержимого и определенных расширений файлов.
Хочется надеяться на то, что эта маленькая статья помогла вам понять, что такое атаки направленные на переполнение буфера, каковы разновидности этих атак, каковы применяемые контрмеры и почему даже эти контрмеры не всегда работают. Но помните, что вы не беззащитны. Если ваш межсетевой экран поддерживает шлюзы приложений или прокси, используйте их. Когда служба информирования LiveSecurity предупреждает вас о критичных уязвимостях, связанных с переполнением буфера, используйте заплатки для приложений. Используйте эти меры, Ваши новые знания о переполнениях буфера и все будет в порядке.
Механизм управления потоком (Flow Control) позволяет предотвратить потерю данных в случае переполнения буфера принимающего устройства.
Для управления потоком в полудуплексном режиме обычно используется метод обратного давления (Backpressure). Принимающее устройство ( порт коммутатора) в случае переполнения его буфера отправляет искусственно созданный сигнал обнаружения коллизии или отправляет обратно устройству-отправителю его кадры.
Для управления потоком в дуплексном режиме используется стандарт IEEE 802.3х. Согласно этому стандарту управление потоком осуществляется между МАС-уровнями с помощью специального кадра-паузы, который автоматически формируется МАС-уровнем принимающего устройства. В случае переполнения буфера принимающее устройство отправляет кадр -паузу с указанием периода времени, на который требуется остановить передачу данных, либо на уникальный МАС- адрес соответствующей станции, либо на специальный групповой адрес 01-80-C2-00-00-01. Если переполнение буфера будет ликвидировано до истечения периода ожидания, то для восстановления передачи принимающая станция отправляет второй кадр -паузу с нулевым значением времени ожидания.
Общая схема управления потоком показана на рис. 1.22.
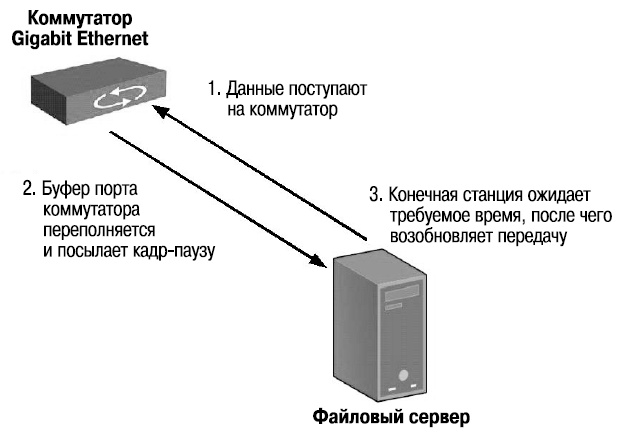
Рис. 1.22. Последовательность управления потоком IEEE 802.3x
Правильно сконфигурированная функция управления потоком на устройствах позволяет повысить общую производительность сети за счет уменьшения потери данных и повторных передач. Управление потоком данных IEEE 802.3х большинства интерфейсных сетевых карт и встроенных сетевых карт включено по умолчанию. Коммутаторы D-Link имеют разные настройки функции IEEE 802.3х по умолчанию:
- неуправляемые коммутаторы — управление потоком IEEE 802.3х включено;
- коммутаторы серии Smart — управление потоком IEEE 802.3х отключено;
- управляемые коммутаторы — управление потоком IEEE 802.3х отключено.
Поэтому для корректной работы функции IEEE 802.3х на порте коммутатора должна быть активизирована функция управления потоком.
Технологии коммутации и модель OSI
Коммутаторы локальных сетей можно классифицировать в соответствии с уровнями модели OSI , на которых они передают, фильтруют и коммутируют кадры. Различают коммутаторы уровня 2 ( Layer 2 (L2) Switch ) и коммутаторы уровня 3 ( Layer 3 (L3) Switch ).
Коммутаторы уровня 2 анализируют входящие кадры, принимают решение об их дальнейшей передаче и передают их пунктам назначения на основе МАС-адресов канального уровня модели OSI . Основное преимущество коммутаторов уровня 2 — прозрачность для протоколов верхнего уровня. Т.к. коммутатор функционирует на 2-м уровне, ему нет необходимости анализировать информацию верхних уровней модели OSI .
Коммутация 2-го уровня — аппаратная. Она обладает высокой производительностью. Передача кадра в коммутаторе может осуществляться специализированным контроллером ASIC . В основном коммутаторы 2-го уровня используются для сегментации сети и объединения рабочих групп.
Несмотря на преимущества коммутации 2-го уровня, она все же имеет некоторые ограничения. Наличие коммутаторов в сети не препятствует распространению широковещательных кадров по всем сегментам сети.
Коммутаторы уровня 3 осуществляют коммутацию и фильтрацию на основе адресов канального (уровень 2) и сетевого (уровень 3) уровней модели OSI . Коммутаторы 3-го уровня выполняют коммутацию в пределах рабочей группы и маршрутизацию между различными подсетями или виртуальными локальными сетями ( VLAN ).
Коммутаторы уровня 3 осуществляют маршрутизацию пакетов аналогично традиционным маршрутизаторам. Они поддерживают протоколы маршрутизации RIP ( Routing Information Protocol ), OSPF ( Open Shortest Path First ), BGP ( Border Gateway Protocol ) для обеспечения связи с другими коммутаторами уровня 3 или маршрутизаторами и построения таблиц маршрутизации, осуществляют маршрутизацию на основе политик, управление многоадресным трафиком.
Существует две разновидности маршрутизации: аппаратная ( коммутация 3 уровня) и программная. При аппаратной реализации пересылка пакетов осуществляется посредством специализированных контроллеров ASIC . При программной реализации для пересылки пакетов устройство использует центральный процессор . Обычно в коммутаторах 3-го уровня и старших моделях маршрутизаторов маршрутизация пакетов аппаратная, что позволяет выполнять ее на скорости канала связи, а в маршрутизаторах общего назначения функция маршрутизации выполняется программно.
Сегодня маршрутизаторы производства Cisco Systems лежат в основе всемирной паутины. Они достаточно часто встречаются в ходе проведения работ по тестированию на проникновение, причем с привилегированным доступом level 15, что позволяет использовать их для дальнейшего развития атак на корпоративные сети и платежные системы. Да, слабые места в Cisco IOS присутствуют, как и в любом другом ПО, но лишь немногие специалисты умеют пользоваться недостатками самого IOS, используя Remote Buffer Overflow.
«Кис-кис-кис», или как обнаружить кошку в Сети

Первая служба, которую я хочу обсудить, это SNMP. Как ни странно, SNMP часто оставляют без присмотра на большом числе маршрутизаторов. Причиной этого может быть общее непонимание того, чем SNMP является на самом деле. Simple Network Management Protocol предоставляет широкий спектр информации в большом наборе систем в стандартном формате. Независимо от того, кто производитель вашего коммутатора или маршрутизатора, почти любой клиент SNMP-мониторинга программного обеспечения будет работать с этим устройством, при условии, что SNMP включен и настроен.
Многие сетевые администраторы не понимают, что SNMP предоставляет слишком широкий спектр информации о работающем устройстве, а записи сообществ SNMP могут быть использованы для получения полного контроля над этим устройством. В случае с Cisco IOS записываемые сообщества SNMP могут быть использованы для выгрузки или загрузки и запуска альтернативной конфигурации устройства, либо изменения его текущей конфигурации.

Маршрутизатор с включенной службой Telnet и с тривиальным паролем может быть угнан почти мгновенно через записи сообщества SNMP. Я обычно ищу кошки при помощи SNMP и старого доброго сканера nmap. Да-да, именно с помощью него Тринити взломала во второй серии Матрицы сеть электростанции, и именно его так любят использовать в АНБ. В дистрибутив nmap включены два интересных сценария для работы с SNMP — это SNMP-sysdescr.nse и snmp-brute.nse.
nmap -sU -n -P0 -v -p 161 --script=snmp-sys.nse -iL my_telecom.txt
- -sU — ведь правда, что служба SNMP работает по UDP протоколу, поэтому мы и задействуем только UDP-сканирование;
- –р 161 — через 161-й порт;
- -v — это я хочу видеть ход процесса на экране;
- -n — не определять имена DNS для найденных хостов (и вправду, сейчас они мне совершенно ни к чему);
- -P0 — не пинговать хосты в процессе сканирования.
Я обычно пользуюсь консольной версией, потому как GUIинтерфейс к ней нещадно зависает при таких объемах сканирования. Просто создай .bat-файл в каталоге, где лежит nmap с этой командной строкой, и запусти его.
Все эти опции заметно убыстряют процесс предварительного сканирования. Итак, в результате мы получим что-то вроде этого:
Киска лакает молоко

msf > msfrpcd –S –U msf –P 123
Сначала находим с помощью SNMP Community Scanner имя readwrite сообщества. Далее для выгрузки конфигурации из горячей киски выбираем конфиг. Далее настраиваем TFTP-сервер. Никакого NAT — сообщенный киске IP-адрес, куда выгружать конфиг, должен быть белым. И, собственно, получаем сам файл конфигурации.

То же самое можно проделать с использованием Metasploit Express и Metasploit Pro — они используют оба эти модуля для автоматического захвата файла конфигурации уязвимых устройств с Cisco IOS. Во время сканирования подбор паролей к SNMP-сообществам запускается в фоновом режиме с небольшим списком слов из общего словаря. Если любой из этих паролей работает, и если хотя бы одно сообщество обнаружено как записываемое, тогда Metasploit Pro настроит локальную службу TFTP и скачает файл конфигурации этого устройства.
Протокол SNMP теперь также интегрирован в средства интеллектуального подбора паролей, компонент которых использует список наиболее популярных имен сообществ в дополнение к динамически генерируемым паролям. Этот список получен в результате исследовательского проекта по изучению паролей веб-форм и встроенных файлов конфигурации. Так, проанализировав результаты, мы определили, какие пароли чаще всего используются, в том числе для SNMP-сообществ. Результаты этого проекта были удивительны: наиболее широко используются пароли «public@ES0» и «private@ES0», как это описано в примере конфигурации в документации Cisco.
Последние два протокола, которые хотелось бы обсудить, это Telnet и SSH. Эти протоколы и обеспечивают доступ к удаленной командной оболочке на целевом устройстве под управлением Cisco IOS (как правило, для непривилегированных пользователей). Наиболее заметным отличием одного протокола от другого является то, что SSH часто требует знания удаленного имени пользователя и пароля, в то время как Telnet обычно запрашивает только пароль для проверки подлинности пользователя. Metasploit Framework содержит модули подбора паролей с использованием этих протоколов и будет автоматически создавать интерактивные сессии до тех пор, пока подходящий пароль не будет найден.
В целом Metasploit Express и Metasploit Pro всегда имели на борту готовые модули тестирования сетевых устройств через Telnet- и SSH-протоколы, но в последней версии стало возможным использовать список наиболее часто используемых паролей, составленный нашими аналитиками. В самом начале списка слов приведены необычные пароли. В целом подбор по словарю очень эффективен, если в качестве пароля для доступа к устройству было использовано реально существующее слово. Не углубляясь слишком далеко, я могу сказать, что некоторые провайдеры часто используют один и тот же пароль для настройки абонентского оборудования.
После того, как был подобран пароль и установлена рабочая сессия через Telnet- или SSH-протоколы устройства Cisco IOS, функция автоматического сбора информации, включенная в Metasploit Express и Metasploit Pro, автоматически считает информацию о версии IOS и список активных пользователей, а затем попытается получить пароль к доступу «enable» путем перебора по списку наиболее распространенных паролей. Если попытка подобрать пароль «enable» увенчается успехом, то автоматически ты получишь дополнительную информацию о системе, в том числе о текущей конфигурации устройства.
В исследованиях, перечисленных выше, нет ничего нового. Новым является лишь простота использования продуктов Metasploit и их способность по цепочке автоматически скомпрометировать уязвимые устройства. По большому счету, эти тесты являются лишь ориентиром для дальнейшего развития исследований безопасности сетевых устройств. И есть еще одна вещь, о которой я не упомянул до сих пор. Что же мы будем делать с полученными файлами конфигурации Cisco IOS после того, как мы их получим в процессе тестирования сетевых устройств? Эти файлы содержат рабочие конфигурации устройств, включающие в себя VTY-пароли, пароли «enable», ключи VPN, SSL-сертификаты и параметры доступа к Wi-Fi. Metasploit будет автоматически обрабатывать эти файлы конфигурации, чтобы выбрать из них конфиденциальные данные и сохранить их как данные аутентификации.
Metasploit Express и Metasploit Pro могут автоматически использовать полномочия, полученные из файлов конфигурации, чтобы получить доступ к другим устройствам этой же сети. Если доступ был получен к одному из устройств Cisco через слабые сообщества SNMP, и было обнаружено, что VTY-пароль — «ciscorules!», то ты можешь использовать профиль подбора паролей «knownonly » для того, чтобы с помощью любого протокола автоматически попробовать этот пароль в отношении любого другого устройства в той же самой сети. После того, как ты получишь доступ к другим устройствам, конфигурационные файлы будут получены на твой компьютер и запустится процесс их анализа. Ты можешь легко применить пароли, взятые из маршрутизаторов Cisco, для входа на сайт интрасети или использовать их для получения доступа к множеству других сетевых устройств.
Переполнение буфера в маршрутизаторе Cisco на основе процессора Motorola
Исследовательская группа по проблемам безопасности Phenoelit когда-то давно создала программу с кодом командного интерпретатора для проведения удаленной атаки на маршрутизатор Cisco 1600 на основе процессора Motorola 68360 QUICC (программа была представлена на азиатской конференции Blackhat аж в 2002 году).
Для этой атаки в векторе вторжения используется переполнение буфера в операционной системе IOS от Cisco и несколько новых методов использования структур управления кучей в IOS. Изменяя структуры кучи, можно внедрить и исполнить вредоносный код. В опубликованном варианте атаки код командного интерпретатора представляет собой созданный вручную код в виде машинных команд Motorola, который открывает потайной ход на маршрутизаторе.
Трафик неравномерно распределяется между выходными портами коммутатора, легко представить ситуацию, когда в какой-либо выходной порт будет направляться трафик с суммарной средней интенсивностью большей, чем протокольный максимум.
На рис. … изображена как раз такая ситуация, когда в порт 3 коммутатора направляется трафик от портов 1,2,4 и 6. Естественно, что когда кадры поступают в буфер порта со скоростью превышающей скорость ухода, то внутренний буфер выходного порта начинает неуклонно заполняться необработанными кадрами. Какой бы ни был объем буфера порта, он в какой-то момент времени обязательно переполнится. Для того чтобы избежать потери кадров необходимо заставить узлы, которые шлют кадры вызывающие переполнение, прекратить их передачу. При этом нельзя менять существующие протоколы работы оборудования на физическом и канальном уровне.
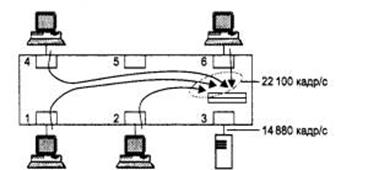
Если порты коммутатора работают в обычном, то есть в полудуплексном режиме, то у коммутатора имеется возможность оказать некоторое воздействие на конечный узел и заставить его приостановить передачу кадров, пока у коммутатора не разгрузятся внутренние буферы. Эта возможность основана на воздействии порта на конечный узел с помощью механизмов алгоритма доступа к среде, который конечный узел обязан отрабатывать. Т.е. каждый входной порт оказывает воздействие на узел находящийся в сегменте, который к нему подключен.
Обычно применяются два основных способа управления потоком кадров — обратное давление на конечный узел и агрессивный захват среды.
Метод обратного давления (backpressure) состоит в создании искусственных коллизий в сегменте, который чересчур интенсивно посылает кадры в коммутатор. Для этого коммутатор обычно использует специальную последовательность (jam-последовательность), отправляемую в выход порта, к которому подключен сегмент (или узел), чтобы приостановить его активность. Т.е. в ответ на передачу узлом своего кадра коммутатор сразу начинает свою передачу, которая вызывает коллизию и тем самым прерывает передачу узла.
Второй метод «торможения» конечного узла в условиях перегрузки внутренних буферов коммутатора основан на так называемом агрессивном поведении порта коммутатора при захвате среды либо после окончания передачи очередного пакета, либо после коллизии. Т.е. коммутатор сам начинает передачу нового кадра после передачи предыдущего, не дожидаясь окончания технологической паузы. Компьютер не может захватить среду, так как он выдерживает стандартную паузу и обнаруживает после этого, что среда уже занята.
Если коммутатор работает в полнодуплексном режиме, то уже не существует возможности воздействовать на узел с помощью механизмов доступа к разделяемой среде, и протокол работы конечных узлов, и его портов должен меняется. В соответствии со стандартом IEEE 802.3x для поддержки полнодуплексного режима работы коммутаторов протоколы взаимодействия узлов были модифицированы, путем встраивания в них явного механизма управления потоком кадров.
Процедура управления потоком кадров в полнодуплексном режиме подразумевает две команды — «Приостановить передачу» и «Возобновить передачу», которые направляются от порта коммутатора узлу. Эти команды реализуются на уровне символов кодов физического уровня, таких как 4В/5В, а не на уровне команд, оформленных в специальные управляющие кадры. (Напомним, что в результате логического кодирования 4В/5В мы получаем 16 «запрещенных» 5 битных символов, которые не могут использоваться для передачи данных, среди этих запрещенных символов и выбираются указанные две команды.) Сетевой адаптер или порт коммутатора поддерживающий стандарт 802.3х и получивший команду «Приостановить передачу», должен прекратить передавать кадры впредь до получения команды «Возобновить передачу».
Читайте также: