
Сетевые мосты перенаправляют широковещательный трафик а коммутаторы нет
Обновлено: 06.07.2024
Проблемы, с которыми приходится сталкиваться в коммутируемой сетевой среде, мало чем отличаются от сбоев в разделяемой среде передачи.
Поэтому и вопросы, на которые требуется ответить, одинаковые: что случилось? кто это сделал? каков будет ущерб? Принципиальная разница заключается
в том, что в коммутируемой среде ответы должны относиться к конкретному порту, а значит, следует учитывать следующие факторы:
Устанавливая в сети коммутатор, вы фактически создаете отдельный коллизионный домен на каждом порту – именно таков принцип работы коммутаторов. Если к порту подключить концентратор, ресурсы которого используются совместно, то коллизионный домен может увеличиться до максимально допустимого для данного варианта Ethernet размера. Коммутирующее оборудование постоянно дешевеет, поэтому в большинстве современных сетей к каждому порту подключается всего одна рабочая станция, и в этом случае коллизионный домен состоит из единственного кабельного сегмента.
Коммутатор, в целом в свою очередь, является частью отдельного широковещательного домена, причем иногда в домен входят несколько коммутаторов, объединенных в каскад или подключенных параллельно. При использовании функций третьего уровня модели OSI в сети создается большое количество широковещательных доменов — по числу виртуальных сетей VLAN. В предельном случае, если, конечно, коммутатор допускает это, каждый порт может быть сконфигурирован как отдельный широковещательный домен. Такая конфигурация, с полным на то основанием, называется прямой маршрутизацией до рабочего места пользователя.
Если на каждом порту создается собственный широковещательный домен, то возможности диагностики сильно ограничены. Кроме того, организация отдельного широковещательного домена на каждом порту требует от коммутатора выделения для маршрутизации значительной части ресурсов центрального процессора на продвижение всего сетевого трафика. В реальной жизни очень трудно представить себе сеть, где требовалось бы обрабатывать и перенаправлять каждый запрос и отклик по отдельности. При отсутствии очень веских оснований создания именно такой структуры сети следует избегать.
К сожалению, весьма распространена конфигурация, когда в одну подсеть или широковещательный домен помещаются все серверы, а пользователи распределены по некоторому количеству других подсетей или широковещательных доменов. В таком случае практически все запросы должны маршрутизироваться. Если ради удобства обслуживания необходимо разместить все серверы в одном помещении (серверной), то их рекомендуется распределить по нескольким виртуальным сетям VLAN. Пользователей, которые обращаются к конкретному серверу, следует отнести к той же виртуальной сети. В такой конфигурации матрица коммутатора может использовать для обычного трафика мост на втором уровне модели OSI, поэтому маршрутизироваться будут только нетипичные или редкие запросы. Если сервер обслуживает более одного сообщества пользователей, то установите в него дополнительные сетевые карты, чтобы связь осуществлялась на втором уровне модели OSI.
ТОЧНОЕ РАСПОЗНАВАНИЕ ПРОБЛЕМЫ
Чуть ли не единственный по-настоящему эффективный метод диагностики коммутируемых сетей — запрос информации о поведении сети у самого коммутатора. Такие данные обычно запрашиваются с помощью протокола SNMP, либо через консольный порт коммутатора. Разумеется, прямое подключение к консольному порту менее удобно, поскольку администратору придется подходить к каждому коммутатору в сети. Во избежание подобных неудобств можно, конечно, установить терминальные серверы и подключить их к консольным портам, но все-таки предпочтительнее использовать протокол SNMP, поскольку он позволяет отправлять запросы из любой точки сети и для этого не нужно устанавливать дополнительное оборудование.
При наличии системы управления сетью коммутатор можно настроить таким образом, чтобы он сам отправлял незапрашиваемый ответ — уведомление SNMP trap – каждый раз, когда уровень использования, количество ошибок или какой-то другой параметр превышают установленное пороговое значение. Причину можно выяснить позже — с помощью системы управления сетью или инструментов мониторинга. Множество проблем успешно разрешается путем запроса к коммутатору, но есть такие, для которых этот способ непригоден. Запрос может применяться как в качестве профилактики, так и для осуществления мониторинга в случае сбоя.
Другая стратегия – дождаться, пока от пользователей начнут поступать жалобы. Во многих сетях применяется именно такой подход, который не стоит недооценивать из-за внешней простоты – на самом деле, он очень эффективен. Пользователи чутко реагируют на состояние сети, несмотря на то, что представление о ее работе больше основывается на подсознательном восприятии, чем на логических заключениях. Заметив малейшее ухудшение
в работе сети, пользователь обычно тут же обращается с жалобой в отдел ИТ или к системному администратору. Так что работу по поиску и устранению неисправности можно начать с его рабочего места. Такой подход называется реактивным, поскольку предполагает реагирование на уже произошедший сбой.
Напротив, профилактические, проактивные методы направлены на то, чтобы не допустить возникновения сбоя. Для этого проводится регулярный опрос коммутаторов, мониторинг качества трафика на каждом порту коммутатора и в каждом сегменте. Когда проблема уже появилась (поступила жалоба, либо вы сами обнаружили сбой), диагностировать ее можно разными методами, каждый из которых имеет свои плюсы и минусы.
МЕТОДЫ ДИАГНОСТИРОВАНИЯ КОММУТАТОРОВ
Получить информацию о работе коммутатора можно как минимум десятью основными способами. Каждый предполагает свой порядок действий и имеет свои положительные и отрицательные стороны. Как обычно, единого рецепта на все случаи жизни не существует. Выбирать подходящее решение из разных вариантов следует, прежде всего, исходя из доступности ресурсов, опыта специалиста, проводящего работы, и оценки последствий для функционирования сети (приостановка, перерывы в работе) при использовании того или иного метода.
Однако даже сочетание всех методов не позволяет следить за коммутируемой сетью в таких подробностях, как это можно было делать в сетях на базе концентраторов. Увидеть и отследить абсолютно весь трафик и все ошибки, относящиеся к коммутатору, практически невозможно. Большинство диагностических процедур подразумевает, что трафик проходит между рабочей станцией и соответствующим сервером или направляется на магистральный порт. Если две рабочие станции обмениваются данными напрямую через одноранговое (пиринговое) соединение, то трафик не проходит ни через магистральный порт, ни через какой-либо другой порт коммутатора. Такие соединения редко обнаруживаются, если только не искать их специально. Обычно ошибки не распространяются за пределы порта коммутатора, однако для некоторых их типов и определенных настроек коммутаторов возможна и дальнейшая трансляция.
Для простоты представим себе минимальный сегмент сети: сервер, подключенный к коммутатору. В одних случаях мы будем предполагать, что пользователи, испытывающие проблемы, подключены к тому же самому коммутатору, в других — что они будут пытаться получить доступ к серверу через магистральный порт, ведущий либо к другому коммутатору, либо к маршрутизатору. Диагностика начинается в ответ на жалобу о медленной работе сети при обращении к серверу. К сожалению, такое описание проблемы ничего не говорит специалисту ИТ. Если речь идет не об обычном сбое, а взломе системы защиты, причем предполагаются последствия юридического характера, то необходимо принять дополнительные меры, чтобы обеспечить достоверность и юридическую силу собираемых данных.
Информация, относящаяся сразу к нескольким методам, будет приводиться в описании того метода, в котором она раскрывается наиболее полно. Большая часть описаний относится также к методам, отличным от того, которому посвящен конкретный раздел, причем она может иметь как тривиальные, так и фундаментальные последствия для конечного результата.
МЕТОД 1: КОНСОЛЬНЫЙ ДОСТУП К КОММУТАТОРУ
Получить доступ к настройкам коммутатора можно разными способами, включая следующие:
подключиться через последовательный порт коммутатора.Некоторые коммутаторы обладают рядом встроенных диагностических средств, которыми можно воспользоваться, но следует помнить, что их функциональные возможности существенно различаются в зависимости от производителя и модели коммутатора. Расширенные команды операционной системы позволяют провес-ти более глубокий анализ транслируемого трафика, однако имеющийся интерфейс нельзя назвать дружественным к пользователю. Чтобы успешно применить такие функции, надо обладать значительным опытом и глубоким знанием теории сетей.
Плюсы. Консольный доступ – очень эффективный метод диагностики, он широко распространен и используется чаще других. Множество самых разных проблем в сети вызвано именно неправильными настройками коммутаторов и выполняемыми в соответствии с этими настройками действиями.
Получить доступ к консоли управления коммутатором можно всегда — одним из вышеперечисленных способов. Почти повсеместная доступность беспроводных сервисов и услуг передачи данных, предоставляемых мобильной связью, позволяют управлять сетью из любой точки планеты. Настроив систему управления сетью на отправку уведомлений на мобильные устройства, вы сразу узнаете о возникновении сбоя.
Если сбой действительно вызван настройками, то метод консольного доступа, безусловно, позволит устранить его.
Минусы. Старшие системные администраторы и другие ведущие сотрудники отделов ИТ, обладающие паролями для доступа к настройкам коммутаторов, при проведении диагностики уделяют столь повышенное внимание конфигурации, что никакие другие варианты даже не приходят им в голову, пока этот метод себя полностью не исчерпает. Между тем, отказ от прочих подходов может существенно задержать устранение сбоя и дополнительно осложнить ситуацию. С помощью только консольного доступа удается выявить и устранить только часть сетевых проблем.
Обычные команды, подаваемые с помощью консоли, позволяют установить средние уровни использования, но не дают информации о конкретных видах сетевой активности или исходной причине сбоя того или иного протокола. Более того, данные, получаемые с помощью консольного доступа, указывают, скорее, на то, как сеть должна работать, а не сообщают о реальном положении дел, поэтому они мало помогут в случае, например, некорректного функционирования части коммутатора. Просмотр конфигурации не позволяет выявить программные ошибки в операционной системе или неточности и упущения в настройках. Иногда, выведя дамп конфигурации на экран, нельзя узнать настройки по умолчанию, поскольку выдаются только изменения по сравнению с настройками по умолчанию. Между тем, причиной снижения производительности сети вполне могут быть именно эти настройки.
Данные о конфигурации полезны для того, чтобы в общих чертах выяснить, работает ли коммутатор так, как должен. Однако для проверки конфигурации и производительности сети нужно применять иные методы диагностики коммутаторов — возможно, даже не один,
а несколько.
Если речь идет о критически важных сегментах сети, то консольный доступ из удаленных точек может быть либо запрещен, либо разрешен только с конкретной группы жестко фиксированных адресов. Обычно пароли для доступа к коммутаторам не известны рядовому персоналу отделов ИТ и служб технической поддержки, поэтому они не имеют возможности использовать консольный доступ. Инженеры более высокого уровня, располагающие паролями, как правило, не участвуют в ежедневной работе по устранению сбоев в сетях. А теперь представьте, каким образом специалист, в прямые обязанности которого входит постоянное поддержание производительности сети, сможет эффективно работать, если консольный доступ ему запрещен?
О других методах диагностирования коммутаторов мы расскажем в следующих выпусках рубрики.
Случилось у нас в организации, страшное дело – сеть работала, работала и вдруг, вроде без особых на то причин, стала работать нестабильно. Выглядело всё это очень странно (впервые столкнулся с проблемой сабжа) – некоторые компьютеры в сети (их небольшое количество) перестали получать IP-адреса (в логах пишут, что не получен ответ от DHCP), причем с утра одни, с обеда другие – пользователи звонят, волнуются, а мы ничего понять не можем.
Если это аппаратный сбой, то должен он по всем канонам, в каком-то одном месте находится, или хотя бы более массово проявляться (как например, с кольцом в Ethernet), а тут какие-то редкие всплески (примерно 5 из 300), а в целом все работает. Более детальный анализ географии больных компьютеров, показал, что они находятся на коммутаторах 3 и более очереди, от шлюза (рисунок 1).
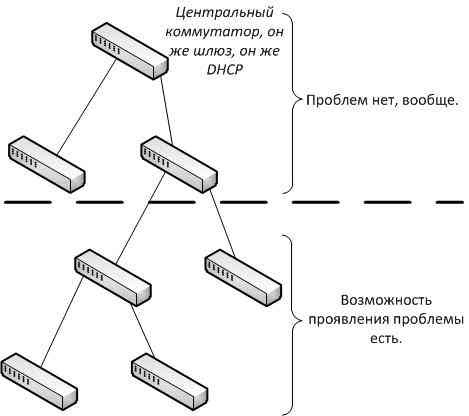
Рисунок 1. География проблемы.
Поиск и выявление
От гипотезы проблемы с железом, отказались не сразу – отключали нижестоящие коммутаторы, и вроде бы получали более-менее кратковременное улучшение, но проблема до конца не исчезала.
Естественно возникла версия, что это некий вирус на ПК – мешает им получать IP-адрес. Она была отвергнута после, того как адрес не получил сетевой принтер. Как оказалось зря (точнее почти зря).
Параллельно с этим пытались анализировать трафик, но из-за неопытности специалистов, анализировался только трафик DHCP.
Итак, первые несколько дней решения проблемы не принесли. Пришлось расширять поле зрение сниффера. И вот в этот момент причина проблемы была обнаружена – при анализе всего широковещательного трафика, обнаружилось, что более 80% запросов ищут, некий сервер – в смысле один и тот же.
Как. позже мы почерпнули из интернета, называется данная проблема широковещательный флуд.
Эх… если бы знать об этом раньше.
Выяснилось, что некая служба под названием «PcounterPrint», очень истерично пытается найти свой сервер, которого как это ни странно нет. Служба ведет аудит печати сотрудников корпорации, и известна в миру под названием FollowMe Printing. Как выяснилось позже – сервер данной службы был успешно выведен из эксплуатации, естественно без какого либо уведомления, вышестоящими корпоративными системными администраторами.
По сути ПК пользователей выступили в качестве ботов, для DDOS-атаки нашего сетевого оборудования.
Дело осталось за малыми задушить эту службу на ПК пользователей.
Массовое удаление
По хорошему, нужно было эту задачу отдать вышеописанным системным администраторам, но ведь и самим интересно и вот, после 25-минутных поисков в интернет рожден скрипт в power-shell:
Переменная $computers получает список компьютеров из файла, скрипт последовательно обходит все ПК из этого списка, и отключает на них злополучную службу.
Далее проверяем широковещательный трафик сниффером, если кто-то остался – корректируем список, и выполняем скрипт повторно, и так делаем несколько итераций, до полного удаления зловредного трафика.
Естественно, после этого сеть заработала стабильно.
Выводы
Как говорится в одном, известном, преферансистском анекдоте: так за это же нужно канделябром по голове…
В общем, административные выводы, я здесь писать не буду, хотя в основном напрашиваются именно они.
С технической точки, зрения, есть несколько мероприятий для профилактики, этой беды:
1. Сегментировать сеть на несколько виртуальных сетей
2. Уменьшить с помощью первого пункта глубину сети
3. Установить более умные коммутаторы
Хотя это конечно мероприятия эти спорны: а надо ли, ведь придется тратить время и деньги, тем более что персонал теперь знаком с данной ситуацией и в последующем, сможет быстро ее победить, хотя как знать…
Боремся с широковещательным штормом
Сегодня у нас - продолжение предыдущей части статьи, посвященной понятию широковещательный шторм. И я расскажу Вам, как мы боролись с этим явлением у себя в рабочей сети.
Итак, продолжим с места "обрыва" :) После того, как сеть практически полностью "легла", я начал идти от ее центра (нашего управляемого коммутатора в серверной) по кабелю, который был подключен к 19-му порту устройства. Структуру сети на работе я, худо-бедно, знаю (иногда, она мне даже снится в тяжелых сновидениях) поэтому через два промежуточных свитча я оказался в одной каморке "папы Карло", возле старенького, но качественно выполненного, 16-ти портового хаба (концентратора) от фирмы «Compex», на котором явно наблюдались коллизии.

Вот - фото более крупным планом, чтобы было хорошо видно, о чем я говорю:

Как видите, индикатор «Collision» постоянно "горит" красным!
Проходя по сети, и находясь в режиме телефонной связи со своим коллегой, который удаленно мониторил центральный коммутатор, я отключал (и включал обратно) каждый свитч, встречавшийся мне на пути. Таки образом, коллега мог видеть, как коллизии пропадают и снова появляются, а я понимал, что причина не в этом сегменте сети и шел дальше.
Добравшись до последнего звена (концентратора), к которому было подключено всего два компьютера, расположенные в соседних помещениях и аплинк, я отключил и его. "Широковещательный шторм пропал" услышал я в трубке голос коллеги. Такс, если я добрался до последнего звена в "ветке" локальной сети и, при его отключении, рассылка широковещательных пакетов прекратилась, то тут, навскидку, - три варианта:
- Проблемы с самим концентратором (хабом)
- Проблемы с одним из его портов (такое тоже бывает)
- Неполадки сетевого адаптера одного из компьютеров, к нему подключенных
Примечание: аплинк (uplink) - порт свитча, подключенный к магистральному кабелю (тому кабелю, который если перерезать, то - капец всему Интернету на работе) :) Также аплинком может называться порт, подключенный кабелем к следующему свитчу, роутеру и т.д. Или - сам кабель, каскадом соединяющий все активное коммутационное оборудование в локальной сети.
Проверить первый вариант, из списка выше, мы можем методом исключения (или нахождения проблемы) в оставшихся двух. Сейчас же - просто начинаем выдергивать из портов по одному сетевому кабелю и смотрим, на каком из них индикатор коллизии погаснет? Все - логично!

Представляете что, в один (очень не прекрасный момент) может случиться, если сеть у нас построена только с использованием подобных бюджетных решений? А это - реальный случай, который произошел на одном из моих предыдущих мест работы. Компьютерная сеть там насчитывала долее четырехсот компьютеров и спроектирована была - самым безобразным образом. Вернее, вот именно момент "проектирования" в ней отсутствовал напрочь (везде - самые дешевые свитчи от разных производителей, никакой кабельной схемы, выполненной хотя бы от руки и т.д.)
Как Вы думаете, что произошло после возникновения (а это - только вопрос времени) первого широковещательного шторма в сети? Правильно! Весь наш IT отдел бегал по этажам и отключал целые ее участки, чтобы выявить тот, который генерирует паразитный трафик, приводящий сеть в нерабочее состояние. В отсутствие управляемых коммутаторов и индикаторов коллизий на свитчах это - единственно возможный вариант развития событий!
Не хотел бы напоминать ворчливого старика, но скажу эту фразу: вот раньше было - совсем по другому! :)
На нормальной сетевой карте вендором устанавливались различные светодиоды, по работе которых можно было с легкостью определить, в каком режиме, на какой скорости работает карта, нет ли с ней проблем и т.д.?
Потом, видимо, - экономить начали:

На фото выше мы видим, что две карты одного класса кардинально отличаются набором светодиодных индикаторов. На верхней их целых четыре:
- G - (Green - зеленый) - Tx (transmit - передача)
- Y - (Yellow - желтый) - Rx (receive - режим получения данных)
- O - (Orange - оранжевый) - Col (collision - коллизия)
- R - (Red - красный) - Pol (polar - перепутана полярность подключения контактов кабеля "витая пара")
На нижней - только стандартный на сегодня Link/Akt (один диод с двумя состояниями). Первое Link (Lnk) - обозначает наличие линка (грубо говоря - подключение сетевого кабеля), при этом индикатор просто постоянно светится. Второе Akt - активность обмена данными по сети (индикатор мигает). Риторический вопрос: много ли полезного можно узнать из подобной "светомузыки"? :)
А вот - еще одно фото, гигабитного сетевого адаптера фирмы «ATI»:

Здесь на каждый режим работы (10, 100 и 1000 мегабит в секунду) - свой индикатор.
Итак, дядя помнит, где он остановился и что хотел сказать, поэтому - продолжаем! :) Выдернув очередной линк (сетевой кабель) из хаба, я увидел что индикатор коллизии погас, а коллега, держащий руку "на пульсе" нашего управляемого коммутатора D-Link, сообщил: "трафик - в норме!".
Мы нашли последнее звено в цепи (тот единственный линк, генерирующий широковещательный трафик). Осталось пройти по нему и оказаться возле компьютера, который и явился причиной всего этого безобразия!
Надо сказать, что компьютер этот вообще редко использовался и, в основном, выступал в роли принт-сервера для находящегося рядом с ним ПК. Первым делом, подойдя к системному блоку, я извлек кабель из его сетевой карты (коллизии прекратились), вставил кабель - начались снова. Как говорит в подобных случаях один мой знакомый байкер: «Счастливый конец найден!» :)
Итак, расследование мы провели, последствия проблемы в полной мере ощутили, теперь бы хотелось ответить на два сокровенных вопроса: "кто виноват?" (причины возникновения широковещательного трафика и коллизий в сети) и "что делать?" (какие существуют меры защиты от этого явления).
Начнем с первого: возможные причины возникновения широковещательного шторма.
- Петли коммутации
- Различные атаки на сеть
- Неисправный сетевой адаптер
Поскольку первый вариант сегодня - не наш, второй - не похоже, остается - третий. Железная логика! :) Иногда случается так, что сетевая карта, вместо того чтобы спокойно "умереть", начинает с максимально доступной ей скоростью рассылать по всей сети широковещательные пакеты.
Это - широковещательный трафик канального уровня, а он имеет свои особенности. Во первых, он распространяется не только в пределах одного домена коллизий, но и в пределах всей сети, построенной с использованием коммутаторов и повторителей (хабов). Принципы работы этих устройств обязывают их передавать кадр с широковещательным адресом (помните: FF-FF-FF-FF-FF-FF) на все порты, кроме того, откуда этот кадр пришел. Что из этого получается, мы рассматривали в предыдущей части статьи.
Вторая особенность, которая и приводит к лавинообразному или постепенному (как повезет) нарастанию мусорного трафика в сети - вплоть до полного ее ступора, состоит в том, что в заголовке пакетов канального уровня (Ethernet) не указано время жизни пакета, как в случае с IP пакетами (уровень сетевой).
Примечание: временем жизни пакета данных называется поле TTL - (time to live), которое уменьшается на единицу с прохождением каждого нового маршрутизатора на пути следования пакета.
Зачем оно нужно? А именно для того, чтобы пакеты, которые не могут найти своего адресата, вечно, как неупокоенные, не блуждали по линиям связи и не занимали их полосу пропускания. Изначально (на выходе кадра из сетевого адаптера компьютера) полю TTL присваивается значение 255 и при каждом "прыжке" (хопе) через новый маршрутизатор из него вычитается единица. Если при продвижении пакета значение TTL уменьшится до ноля, то такой пакет, попросту, отбрасывается на следующем маршрутизаторе (говорят, что его время "жизни" истекло).
Есть даже такой бородатый анекдот:
Мальчик сказал маме: “Я хочу кушать”.
Мама отправила его к папе.
Мальчик сказал папе: “Я хочу кушать”.
Папа отправил его к маме.
Мальчик сказал маме: “Я хочу кушать”.
Мама отправила его к папе.
И бегал так мальчик, пока в один момент не упал.
Что случилось с мальчиком? TTL кончился
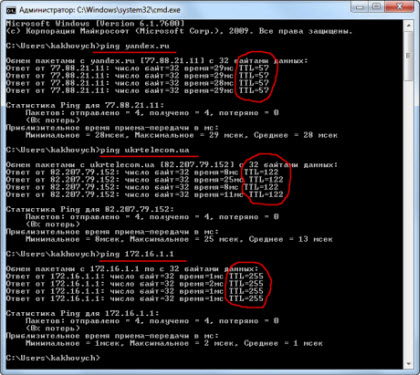
По значению этого поля можно косвенно определить, насколько далеко находится от нас тот или иной удаленный хост. Давайте рассмотрим это на простом примере использования команды «ping». На фото ниже я запустил ее к трем различным серверам в сети: (фото ниже - кликабельно)
Вот еще один пример:
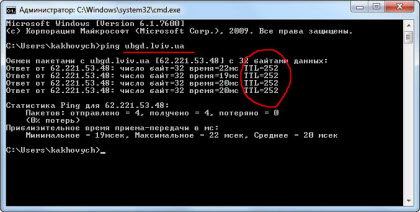
Пингуемый нами сервер находится со мной в одном городе (Львове) и поэтому TTL здесь такой высокий - 252 единицы. Пакет проходит всего три маршрутизатора (учитывая тот, что стоит у меня дома), пока доходит до адресата. Попробуйте протестировать связь с этим сервером от себя (уверен, что время жизни пакета у Вас будет меньше) - ему нужно будет пройти больше узлов на пути следования.
Двигаемся дальше! Поскольку, в нештатной ситуации, широковещательный трафик генерируется сбойным устройством непрерывно и, само по себе, его возникновение - непрогнозируемо, то нужно предпринимать адекватные меры для его подавления или блокирования.
Сразу скажу, что мы свой центральный управляемый коммутатор D-Link DES-3550 изначально не конфигурировали для борьбы с широковещательным штормом (поэтому сеть и "упала"), но после этого случая - предприняли соответствующие меры. Вот сейчас об этом и поговорим!
Разберем более детально одну из секций настроек нашего коммутатора второго уровня. Нас будет интересовать пункт «Traffic Control»: (кликабельно)
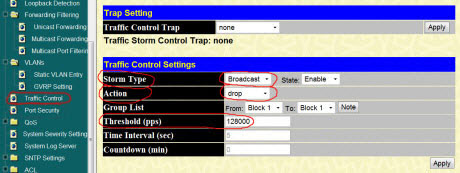
В правой части окна мы видим настройки модуля управления и контроля за трафиком. В частности, здесь мы можем силами самого коммутатора бороться с широковещательным штормом в сети. Мы должны как бы запрограммировать коммутатор на соответствующую реакцию с его стороны при обнаружении широковещательного шторма на любом из портов. Вот давайте это и сделаем!
На фото выше, обратите внимание на строчку «Storm Type» (тип шторма). Здесь из списка выбираем «Broadcast», (широковещательный, там есть еще «Multicast» - групповая рассылка и «Unicast» - однонаправленная передача). В поле «State» (статус) выбираем «Enable» (задействовать).
В следующей строчке «Action» (действие) выбираем что нужно сделать при обнаружении broadcast storm? Здесь - два варианта: «drop» (отбрасывать широковещательные пакеты) и «shutdown» (полностью отключить порт). Для себя мы выбрали первый вариант.
И еще одна важная строка, на которую надо обратить внимание «Treshold (pps)» (порог PPS - packet per second - пакетов в секунду). Это - предельно допустимое значение количества пакетов, которые попадают на порт коммутатора за одну секунду. Здесь по умолчанию установлено число в 128 000 пакетов.
Хотите узнать почему именно это значение? Давайте разбираться вместе! :)
Пропускная способность любого канала локальной сети ограничивается максимальной эффективной пропускной способностью используемого канального протокола. Это - логично! Учитывая все временные задержки, необходимые коммутатору для буферизации, принятии решения о дальнейшем его продвижении (forwarding) и отправке поступившего кадра в сеть, мы имеем точное максимальное значение количества пакетов, приходящихся на один его порт в единицу времени.
- 14 880 пакетов/сек на порт со скоростью работы 10 Мб/с
- 148 800 пакетов/сек на порт со скоростью работы 100 Мб/с
- 1 148 800 пакетов/сек на порт в 1000 Мб/с (1 Гигабит)
Это - предел самой технологии Ethernet, да и свитч, скорее всего, начнет "захлебываться" приходящими с такой интенсивностью пакетами. Учитывая, что наш управляемый коммутатор D-Link это 100 мегабитное устройство (его предел - значение в 148 800), то и цифра, проставленная в поле «Treshold» (порог) теперь выглядит весьма логичной: чуть меньше максимума (128 000).
После того, как мы нажмем кнопку «Apply» (применить), весь входящий трафик, который превысит цифру 128 000 пакетов в секунду будет просто отбрасываться.
Это - необходимая работа на перспективу! А в нашем случае, борьба с широковещательным штормом, причиной которого была неисправная сетевая карта, закончилась тем, чем и должна была - ее заменой. Сейчас график загрузки порта под номером 19 выглядит вот так: (кликабельно)
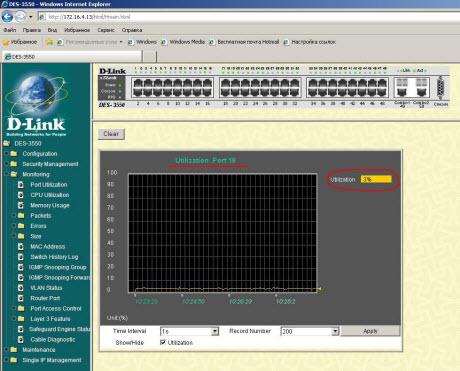
Всего 3% от максимума. Это - его нормальный штатный режим работы.
Как мы могли убедиться, специальные функции коммутаторов ограничивают количество широковещательных пакетов в сети. И каждый вендор (производитель) старается этот функционал всячески расширять, придумывая новые меры борьбы с этой напастью.
Но есть и стандартные алгоритмы, призванные решать те же задачи. Так в 1997-ом году был принят стандарт IEEE 802.3x, для управления потоком данных канального уровня в протоколе Ethernet. Он определяет простую процедуру управления трафиком: наличие двух команд - «приостановить передачу» и «возобновить передачу», которые, при необходимости, передаются конечному узлу.
Причем, команды эти реализуются на уровне кодов физического уровня модели OSI, поэтому "понятны" для любого, даже самого распоследнего, сетевого адаптера :)
К стандартным методам управления трафиком относятся такие приемы как: «Метод обратного давления на узел» (backpressure) и «Метод захвата среды». Давайте коротко их рассмотрим!
У коммутатора всегда есть возможность воздействовать на конечный узел с помощью правила алгоритма доступа к среде, который конечный узел обязан соблюдать (помните про CSMA/CD?). Точнее, воздействие происходит с помощью всяческих, самых бессовестных, нарушений этих правил! :) Конечные узлы (компьютеры) строго соблюдают все предписания, описанные в стандарте алгоритма доступа к среде, а вот коммутаторы - нет!
Метод обратного давления состоит в создании видимости коллизии в сегменте сети, который слишком интенсивно генерирует трафик. Для этого коммутатор, на нужном порте, выводит jam-последовательность (из первой части статьи мы должны помнить, что это такое). По факту - коллизии нет, но подобный трюк позволяет, на некоторое время, "заткнуть рот" конечному компьютеру :) Подобные "фокусы" свитч может выкидывать и тогда, когда находится в режиме, близком к перегрузке и ему нужно время, чтобы разгрузить переполненную очередь внутренних буферов портов.
Второй метод "торможения" хоста основан на так называемом агрессивном поведении порта коммутатора при захвате среды. Давайте, рассмотрим и его!
Например, коммутатор окончил передачу очередного кадра и вместо технологической паузы, положенной по регламенту протоколом, сделал паузу чуть-чуть меньшую (на пару микросекунд) и тут же начал передачу нового кадра. Подключенный к коммутатору ПК, не ожидавший такой "наглости", просто не смог получить доступ к среде, так как он выдержал положенный тайм-аут и обнаружил после этого, что линия уже занята. Коммутатор может пользоваться подобными механизмами управления потоком данных на свое усмотрение, увеличивая степень своей "агрессивности" в зависимости от ситуации.
Что еще нам нужно запомнить напоследок? То, что надежной преградой на пути широковещательного шторма становятся маршрутизаторы (роутеры). Они попросту игнорируют весь широковещательный трафик канального уровня и не передают его в соседнюю сеть или ее сегмент. Но это уже - совсем другая история :)
2.2.1. Назначение широковещательного трафика
Пропускная способность любого канала локальной сети ограничивается максимальной эффективной пропускной способностью используемого канального протокола. Если же часть этой пропускной способности используется не для передачи пользовательских данных, а для передачи служебного трафика, то эффективная пропускная способность сети еще уменьшается. Обычно некоторую часть доступной пропускной способности сети отнимает у пользовательских данных широковещательный служебный трафик, который является неотъемлемой частью практически всех стеков протоколов, работающих в локальных сетях.
Широковещательная рассылка кадров и пакетов используется протоколами для того, чтобы в сети можно было бы находить ресурсы не с помощью запоминания их числовых адресов, а путем использования более удобных для пользователя символьных имен. Еще одним удобным способом поиска ресурсов в сети является их автоматическое сканирование и предоставление пользователю списка обнаруженных ресурсов с символьными именами. Пользователь может просмотреть список текущих ресурсов сети - файл-серверов, серверов баз данных или разделяемых принтеров - и выбрать любой из них для использования.
Оба приведенных способа работы пользователя с ресурсами обычно основываются на том или ином виде широковещательного трафика, когда узел, осуществляющий просмотр сети, отправляет в нее запросы с широковещательным адресом, опрашивающие наличие в сети тех или иных серверов. Получив такой запрос, сервер отвечает запрашивающему узлу направленным пакетом, в котором сообщает свой точный адрес и описывает предоставляемые сервером услуги.
2.2.2. Поддержка широковещательного трафика на канальном уровне
Практически все протоколы, используемые в локальных сетях, поддерживают широковещательные адреса (кроме протоколов АТМ). Адрес, состоящий из всех единиц (111. 1111), имеет один и тот же смысл для протоколов Ethernet, TokenRing, FDDI, FastEthernet, 100VG-AnyLAN: кадр с таким адресом должен быть принят всеми узлами сети. Ввиду особого вида и регулярного характера широковещательного адреса вероятность его генерации в результате ошибочной работы аппаратуры (сетевого адаптера, повторителя, моста, коммутатора или маршрутизатора) оказывается достаточно высокой. Иногда ошибочный широковещательный трафик генерируется в результате неверной работы программного обеспечения, реализующего функции протоколов верхних уровней.
Широковещательный трафик канального уровня распространяется в пределах не только сегмента, образованного пассивной кабельной системой или несколькими повторителями/концентраторами, но и в пределах сети, построенной с использованием мостов и коммутаторов. Принципы работы этих устройств обязывают их передавать кадр с широковещательным адресом на все порты, кроме того, откуда этот кадр пришел. Такой способ обработки широковещательного трафика создает для всех узлов, связанных друг с другом с помощью повторителей, мостов и коммутаторов, эффект общей сети, в которой все клиенты и серверы "видят" друг друга.
2.2.3. Широковещательный шторм
Обычно протоколы проектируются таким образом, что уровень широковещательного трафика составляет небольшую долю общей пропускной способности сети. Считается, что нормальный уровень широковещательного трафика не должен превышать 8% - 10% пропускной способности сети. Однако, уже при достижении порога в 5% считается целесообразным провести анализ узлов, которые генерируют наибольщую долю широковещательного трафика - возможно, они нуждаются в реконфигурации.
Общая интенсивность широковещательного трафика в сети будет определяться двумя факторами - количеством источников такого трафика и средней интенсивностью каждого источника. Протоколы локальных сетей разрабатывались в начале 80-х годов в расчете на сравнительно небольшое число компьютеров, генерирующих широковещательный трафик, а также с учетом большого запаса пропускной способности каналов локальных сетей (10 Мб/c) по сравнению с потребностями файлового сервиса миникомпьютеров и настольных компьютеров того времени. Поэтому стеки протоколов, которые проектировались исключительно для применения в локальных сетях - NovellNetWareIPX/SPX и стек NetBIOS/SMB компаний IBM и Microsoft - широко пользовались широковещательными рассылками для создания максимума удобств для пользователей, которым не нужно было запоминать имена и адреса серверов.
Превышение широковещательным трафиком уровня более 20% называется широковещательным штормом (bradcaststorm). Это явление крайне нежелательно, так как приводит к возрастанию коэффициента использования сети, а, следовательно, и к резкому увеличению времени ожидания доступа.
2.2.4. Поддержка широковещательного трафика на сетевом уровне
Как уже было сказано, мосты и коммутаторы не изолируют сегменты сетей, подключенных к портам, от широковещательного трафика канальных протоколов. Это может создавать проблемы для больших сетей, так как широковещательный шторм будет "затапливать" всю сеть и блокировать нормальную работу узлов. Надежной преградой на пути широковещательного шторма являются маршрутизаторы.
Принципы работы маршрутизатора не требуют от него обязательной передачи кадров с широковещательным адресом через все порты. Маршрутизатор при принятии решения о продвижении кадра руководствуется информацией заголовка не канального уровня, а сетевого. Поэтому широковещательные адреса канального уровня маршрутизаторами просто игнорируются. На сетевом уровне также существует понятие широковещательного адреса, но этот адрес имеет ограниченное действие - пакеты с этим адресом должны быть доставлены всем узлам, но только в пределах одной сети. В силу этого такие адреса называются ограниченными широковещательными адресами (limitedbroadcast). По таким правилам работают наиболее популярные протоколы сетевого уровня IP и IPX.
Однако, для нормальной работы сети часто оказывается желательной возможность широковещательной передачи пакетов некоторого типа в пределах всей составной сети. Например, пакеты протокола объявления сервисов SAP в сетях NetWare требуется передавать и между сетями, соединенными маршрутизаторами, для того, чтобы клиенты могли обращаться к серверам, находящимся в других сетях. Именно так работает программное обеспечение маршрутизации, реализованное компанией Novell в ОС NetWare. Для поддержания этого свойства практически все производители аппаратных маршрутизаторов также обеспечивают широковещательную передачу трафика SAP.
Подобные исключения делаются не только для протокола SAP, но и для многих других служебных протоколов, выполняющих функции автоматического поиска сервисов в сети или же другие не менее полезные функции, упрощающие работу сети.
Ниже описаны наиболее популярные в локальных сетях протоколы, порождающие широковещательный трафик.
2.2.5. Виды широковещательного трафика
2.2.5.1. Широковещательный трафик сетей NetWare
2.2.5.2. Широковещательный трафик сетей TCP/IP
Как уже отмечалось, в сетях TCP/IP широковещательный трафик используется гораздо реже, чем в сетях NetWare. Широковещательный трафик в сетях TCP/IP создают протоколы разрешения IP-адресов ARP и RARP (реверсивный ARP), а также протоколы обмена маршрутной информацией RIPIP и OSPF. Протоколы ARP и RARP используются только в локальных сетях, где широковещательность поддерживается на канальном уровне. Протокол RIPIP принципиально ничем не отличается от протокола RIPIPX, а протокол OSPF является протоколом типа "состояния связей" как и протокол NLSP, поэтому он создает широковещательный трафик гораздо меньшей интенсивности, чем RIP.
2.2.5.3. Широковещательный трафик сетей NetBIOS
Протокол NetBIOS широко используется в небольших сетях, не разделенных маршрутизаторами на части. Этот протокол поддерживается в операционных системах WindowsforWorkgroups и WindowsNT компании Microsoft, в операционной системе OS/2 Warp компании IBM, а также в некоторых версиях Unix. NetBIOS используется не только как коммуникационный протокол, но и как интерфейс к протоколам, выполняющим транспортные функции в сети, например, к протоколам TCP, UDP или IPX. Последняя роль NetBIOS связана с тем, что в ОС, традиционно использовавших NetBIOS в качестве коммуникационного протокола, многие приложения и протоколы прикладного уровня были написаны в расчете на API, предоставляемый протоколом NetBIOS. При замене протокола NetBIOS на другие транспортные протоколы разработчики приложений и ОС захотели оставить свои программные продукты в неизменном виде, поэтому появились реализации интерфейса NetBIOS, оторванные от его функций как коммуникационного протокола, и выполняющие роль некоторой прослойки, транслирующей запросы одного API в другой.
Основным источником широковещательного трафика в сетях, использующих NetBIOS либо в качестве интерфейса, либо в качестве протокола, является служебный протокол разрешения имен, который ставит в соответствие символьному имени компьютера его МАС-адрес. Все компьютеры, поддерживающие NetBIOS, периодически рассылают по сети запросы и ответы NameQuery и NameRequest, с помощью которых это соответствие поддерживается. При большом количестве компьютеров уровень широковещательного трафика может быть весьма высоким.
Маршрутизаторы обычно не пропускают широковещательный трафик NetBIOS между сетями.
Для уменьшения уровня этого трафика необходимо использовать централизованную службу имен, подобную службе WINS компании Microsoft.
2.2.5.4. Широковещательный трафик мостов и коммутаторов, поддерживающих алгоритм SpanningTree
Мосты и коммутаторы используют алгоритм покрывающего дерева SpanningTree для поддержания в сети резервных избыточных связей и перехода на них в случае отказа одной из основных связей. Алгоритм работы мостов и коммутаторов не позволяет использовать избыточные связи в основном режиме работы (при такой топологии связей кадры могут зацикливаться или дублироваться), поэтому основной задачей алгоритма SpanningTree является нахождение топологии дерева, покрывающей исходную топологию сети.
Для создания древовидной конфигурации мосты и коммутаторы, поддерживающие алгоритм SpanningTree постоянно обмениваются специальными служебными кадрами, которые вкладываются в кадры MAC-уровня. Эти кадры рассылаются по всем портам моста/коммутатора, за исключением того, на который они пришли, точно так же, как и пакеты протоколов RIP или OSPF маршрутизаторами. На основании этой служебной информации некоторые порты мостов переводятся в резервное состояние, и тем самым создается топология покрывающего дерева.
После установления этой топологии широковещательный трафик алгоритма SpanningTree не прекращается. Мосты/коммутаторы продолжают распространять по сети кадры протокола SpanningTree для контроля работоспособности связей в сети. Если какой-либо мост/коммутатор перестает периодически получать такие кадры, то он снова активизурует процедуру построения топологии покрывающего дерева.
Уровень широковещательного трафика протокола SpanningTree прямо пропорционален количеству мостов и коммутаторов, установленных в сети.
Маршрутизаторы трафик алгоритма SpanningTree не передают, ограничивая топологию покрывающего дерева одной сетью.
2.2.5.5. Ограничение уровня широковещательного трафика в составных сетях с помощью техники спуфинга
Если уровень широковещательного трафика слишком высок, то уменьшить его можно двумя спсособами. Первый состоит в применении других протоколов, реже пользующихся широковещательностью, например, протоколов стека TCP/IP. Однако, это не всегда возможно, так как приложения или операционные системы могут уметь работать только с определенными протоколами. В этом случае можно воспользоваться другим способом - техника спуфинга.
Эта техника была развита производителями коммуникационного оборудования, объединяющего локальные сети по низкоскоростным глобальным каналам, а именно, производителями удаленных мостов и маршрутизаторов.
Существуют различные реализации спуфинга. Наиболее его простой вариант заключается в простом исключении некоторого количества циклов передачи служебных пакетов между сетями, когда, например, в другую сеть передается только каждый 5-й или 10-й пакет SAP, поступающий из исходной локальной сети.
Спуфинг можно применять и в локальной составной сети для уменьшения уровня широковещательного трафика.
Техника спуфинга может приводить не только к повышению, но и к снижению производительности сети. Это может произойти в том случае, когда пара взаимодействующих в режиме спуфинга маршрутизаторов или мостов имеют различные параметры настройки этого алгоритма. Так, если один маршрутизатор настрен на передачу каждого 10-го пакета SAP, а второй маршрутизатор ждет прихода нового пакета SAP через каждые 5 периодов его нормальной передачи, то второй маршрутизатор будет периодически считать связь с серверами первой сети утерянной и объявлять об этом во второй сети, что приведет к разрыву логических соединений между клиентами и серверами, находящимися в разных сетях, а, значит, и к потере производительности. К такому же результату приведет ситуация, когда один маршрутизатор поддерживает режим спуфинга, а второй - нет.


Несмотря на то, что поддержка функции автосогласования (Auto-Negotiation) скорости порта давно уже стала само собой разумеющейся в сетевых устройствах, иногда пользователи или администраторы сетей сталкиваются с ситуациями, когда что-то пошло не так, и соединение не поднялось или поднялось не на ожидаемой скорости. Что делать в такой ситуации рассмотрим в данной заметке.
1. Возможные причины проблем.
- Физические проблемы соединения – плохие контакты в коннекторах, частичный или полный обрыв проводов в кабеле или коннекторах, неправильная разводка проводов в коннекторах и т.п.
- Программные проблемы – некорректная работа драйвера сетевого адаптера, некорректная работа внутреннего программного обеспечения сетевого устройства (коммутатора, маршрутизатора, точки доступа и т.п.).
- Аппаратные проблемы – физические неисправности сетевого устройства.
2. Методы устранения различных проблем.
Для обнаружения и устранения физических проблем можно сделать следующее:
- заменить патч-корд;
- прозвонить кабель специальным тестером, например, LT -100;

Программные проблемы решаются обновлением драйверов и установкой последних версий Firmware (внутреннее ПО) сетевых устройств (если устройства предполагают их обновление).
Аппаратные проблемы решаются заменой оборудования или же его ремонтом в специализированных сервисных центрах, если есть в этом целесообразность.
3. Если всё вышеперечисленное не помогает.
Если же найти причину проблемы не удалось, а физически всё исправно, то можно попробовать отключить автосогласование и выставить фиксированную скорость на портах с одной или двух сторон, если имеющееся оборудование позволяет это сделать. Иногда это позволяет обойти проблемы совместной несогласованной работы при подключении к сети старых сетевых устройств или устройств «No Name».
Приведу пример настройки на доступном мне коммутаторе D-Link DGS-1100-24 (H/W A1). Настройка производится на порту, к которому подключено проблемное устройство. Например, это 13 порт. Открываем страницу «Port Settings» раздела меню «System» WEB-интерфейса коммутатора, выбираем в выпадающем списке «From Port» нужный порт 13, в списке «ToPort» он выставится автоматически, выбираем нужную скорость в выпадающем списке «Speed» и нажимаем кнопку «Apply».

Скорость на порту зафиксируется и порт, в данной ситуации, поднимается на выбранной скорости.

У других настраиваемых или управляемых коммутаторов настройка будет похожа, главное найти расположение этих настроек в интерфейсе коммутатора.
Читайте также: