
Аналог asio в linux
Обновлено: 08.07.2024
Linux под музыку
Аудиоприложения для Linux: личное мнение
В Linux проблем не меньше, чем в Windows. ОС долгое время в области звука была позади планеты всей. К сожалению, разработчики Linux слишком долго не обращали внимания на аудиоприложения для своей системы. Когда несколько лет назад Линусу Торвалдсу (Linus Torwalds) прислали первые патчи low latency kernel, он вообще послал ребят подальше, сказав, что оптимизация Linux для работы с аудио - bad idea.
dlphilp/linuxsound начал собирать свою знаменитую коллекцию аудиопрограмм под Linux, он смог найти только 30 приложений (сейчас их больше 800). Ядра, драйверы и звуковые серверы с low latency (низкими задержками) появились совсем недавно. Поэтому программ, способных воспользоваться этими новыми возможностями, пока немного. Остановимся поподробней на проблемах и найденных решениях.
Latency
Первая аудиозадача, которую необходимо было решить, - Latency. Некоторые иностранные словари толкуют это слово так: "Latency - это время между тем, когда вы хотите, чтобы что-то случилось, и тем, когда это реально случается". Например, когда вы поете в микрофон или играете на миди-клавиатуре, то звук записывается не сразу, а через определенное время. Это время и есть latency. Задержка, в общем. Для работы со звуком в реальном времени задержки должны быть минимальны. Хотя latency измеряется миллисекундами, задержки в 100 мс вы услышите.
Будет свистеть или щелкать по-взрослому. 10 мс можно не расслышать, но музыканты характеризуют такой звук как "туман". Идеальный результат - 3 мс для аудио и 1 мс для миди. Кстати, большие задержки звука - это проблема не только Linux. Windows и Mac также изначально не проектировались как платформы реального времени. И в прошлом latency в этих ОС были - мама не горюй.
По умолчанию Linux работает с аудиодрайверами OSS/Free. Latency - 150 мс. Как вы понимаете, цифры запредельные и они никого не устраивают. Поэтому и возник проект ALSA (Advanced Linux Sound Architecture). Во все новые дистрибутивы уже включены ALSA-драйверы. Audio latency - не больше 6 мс. Лучше, чем у Windows 2000 с ASIO.
Ради интереса посмотрите тест mambo.peabody.jhu.edu/
karlmac/
publications/latency-icmc2001.pdf . Красивые цифры получаются. На первом месте Mac OS X с родными драйверами (CoreAudio API), на втором Linux 2.4 с ALSA (4,3 мс). Третье место делят Mac OS 9 и Windows 2000 с ASIO. Другие конфигурации Windows и Mac OS далеко позади. Таким образом, можно считать, что проблему с latency в Linux удалось решить.
Аудиосерверы
Еще один тяжелый случай. Проведем эксперимент. Запустим программный синтезатор и какой-нибудь секвенсор, умеющий работать с аудио, например, JAZZ++. Импортируем в секвенсор любой WAVE. Давим на кнопку Play. Что, ничего не работает? Так и должно было случиться. Синтезатор захватил аудиопорт, и секвенсор пытается сделать то же самое. Можно запустить сколько угодно аудиоприложений в одно и тоже время, но только одно из них сможет писать/читать в/из аудиопорт(а).
Ведь у вас только один девайс (dev/dsp). Дабы избежать подобных конфликтов, необходимо, чтобы приложения обращались не к драйверам саундкарты, а к аудиосерверу. Только он, аудиосервер, получает доступ к железу напрямую, а другие программы об аудиодрайверах ничего знать не должны. Теоретически все выглядит славно, и аудиосерверы в Linux есть, и аудиопрогаммы могут работать с их библиотеками. Но на практике не все так шоколадно.
Во-первых, разных серверов слишком много. В KDE - aRts, в Gnome - ESD, в WindowMaker - WMSound. Во-вторых, у них неправильная архитектура и, как следствие, слишком большие задержки (latency). Конечно, хаять проще, чем создавать. Разработчики этих серверов наверняка не согласятся с моей оценкой. Автор aRts, например, утверждает, что его сервер имеет latency меньше 1 мс, да и с архитектурой все OK.
Между прочим, сервер получился замечательный. Быстрый, с маленькими задержками, с удобным интерфейсом для клиентских приложений. Единственный недостаток - программ, умеющих с ним работать, пока слишком мало. Мало, зато какие. Alsaplayer (аудиоплейер), Ardour (аудиорекордер), MusE (секвенсор) - лучшие в своих категориях.
Вообще-то, обработка звука - это способ неестественными средствами добиться естественного звучания. И она необходима, чтобы ваша музыка и ваш голос звучали как можно натуральнее, а не наоборот. Если же хочется петь, как Витас, пусть вас укусит Шура.
Программные и аппаратные средства обработки звука можно условно разделить на две категории: процессоры и эффекты. Процессоры обрабатывают сигнал целиком, а эффекты смешивают обработанный и сухой сигнал. Процессоры - это эквалайзеры, компрессоры/лимитеры, экспандеры/гейты, энхансеры и т. п. Эффекты - линии задержки, ревербераторы, хорусы, фленджеры, pitch shifters (устройства сдвига высоты тона) и т. д. Алгоритмы работы этих приборов - ни для кого не секрет.
И их программные аналоги входят в состав любого уважающего себя аудиоредактора. Однако многие фирмы с успехом продают дополнительные программные модули (плагины). Если программа-хост (аудиоредактор, секвенсор) поддерживает плагин-технологию, то вы можете подключить эти плагины и "оживить" звук. Самые распространенные плагин-форматы: VST (Virtual Studio Technology) от Steinberg и DirectX от Microsoft. Рынок музыкальных плагинов огромен.
Есть Vsi - миди-инструменты (например, какой-нибудь супер орган), есть модули обработки звука (компрессоры, нормализаторы и т. д.). На сегодняшний день без плагинов трудно представить любую виртуальную студию. Так как VST появился намного раньше аналогов от MS, к нему привыкли, накопили большие коллекции плагинов, поэтому для звукорежиссеров VST - профессиональный стандарт.
Поддерживают ли аудиоприложения в Linux VST? И да, и нет. Да, потому что хакеры портировали некоторые VST-плагины для Windows в Linux PC. И если бы Steinberg позволил, то можно было бы создать что-нибудь подобное aviplay, но для звука (aviplay - библиотека, позволяющая использовать в Linux AVI-кодеки под Windows). Однако Linux - это не только РС. Есть еще Alfa, UltraSPARC, Pover ПК.
Поэтому, чтобы решить проблему с VST, нужны исходники. Но алгоритмы обработки звука - это тайна за семью печатями. Раскрыть алгоритм - это понести значительные финансовые потери. Можно, конечно, как Opera, не раскрывая секретов, выпускать бинарники для различных UNIX-платформ. Однако желающих пока нет. Steinberg заявляет, что он не против Linux. Но портировать VST в Linux не хочет и другим не разрешает. Переговоры еще продолжаются, но покамест безрезультатно.
Чтобы не терять времени даром, в Linux, на основе первых спецификаций VST, была создана похожая технология - LADSPA. Все новые аудиоприложения ее поддерживают. Существует еще несколько подобных разработок, но LADSPA пока самая популярная. Понятно, что в отличие от LADSPA, VST и DirectX плагины стоят денег, причем немалых. Иной плагин стоит больше $500.
Почему народ все это покупает, что же там такого интересного? Не что, а как. Возьмем, к примеру, эквалайзер. Прибор нужный - он усиливает либо ослабляет отдельные частоты. Например, уменьшив усиление на частотах 50 и 100 Гц, устраняем шумы сети питания (50 Гц) и "плевки" вокалистов. Так вот, чтобы усилить или уменьшить уровень звука в определенном частотном диапазоне, необходимо эту частоту выделить из общего сигнала.
А КАК это делается - секрет фирмы. Если в реальном времени применить дискретное преобразование Фурье - не хватит мощности компьютера, если использовать упрощенную математику - страдает качество. Или другой пример - компрессор. При записи неопытных певцов компрессор усилит "тонущие" в музыки слова и ослабит слишком громкие. Экспандер делает то же самое, но в точности наоборот, поэтому часто используется для борьбы с шумами.
Хорошо бы объединить эти два прибора, добавить эквалайзер с возможностью графического редактирования АЧХ. Все это реально, такие модули существуют, но качество сильно зависит от мощности компьютера и от математических идей программистов. С эффектами ситуация такая же, только круче.
Там не только высшая математика, там высшая биология и психология. Одни названия чего стоят: Brainwave Synchronizer (синхронизация звучания сэмпла с ритмами головного мозга), Waves MaxxBass (реальный супербас на 100 Гц китайских колонках) и т. д. Как сделать подобные эффекты, в принципе, понятно. Берешь сигнал, выделяешь определенные частоты, добавляешь гармоники, задержки.
Потом, по определенным правилам, мешаешь все это с сухим звуком и получаешь суперзвучание. Но, как и в любом кулинарном блюде, успех - в пропорциях. А это секрет фирмы. Linux - система с открытыми исходниками, поэтому понятно, что фирменных эффектов там нет. А что есть? Есть только инструменты. А что, как и с чем мешать - экспериментируй сам. И потихоньку народ начинает заниматься этим делом. Каждый месяц появляются новые плагины. Похоже, год, два, и встанет вопрос: "А так ли хороши VST-модули?". Возможно, к тому времени в Linux они никому не будут нужны.
Аудиоредакторы
Ardour в реальном времени может записывать одновременно звук с 24 и более каналов с разрешением 32 бит @ 96 кГц (количество виртуальных каналов ограниченно только мощностью компьютера). Судя по всему, разработчики поставили перед собой сверхзадачу - программа должна все делать в реальном времени. Поэтому они ориентируются на самые передовые разработки.
Тут тебе и low-latency kernel, и ALSA-драйверы, и JACK-сервер. Создать быстрый движок - вот, что для автора главное. Такие "мелочи", как звуковые эффекты и синтез звука, отданы на откуп другим производителям. Все это подключается к Ardour через плагины, совместимые с LADSPA. Если переговоры с Steinberg закончатся удачно, то обещается поддержка VST. Для меня главный недостаток программы - это отсутствие стабильной версии.
Пока разработчики предлагают только бета-релиз. А знаете, что это такое в Linux? Лучше вам этого не знать. Одна головная боль, да и только.
Двоякое впечатление. С одной стороны, хочется похвалить. Все основные функции, положенные аудиоредактору, имеются: осциллограммы каналов, спектральный анализатор, врезки, вставки, амплитудные и частотные преобразования, звуковые эффекты, экспорт в MP3 и т. п. Однако при ближайшем рассмотрении оказалось слишком много НО. Начнем по порядку. Во-первых, любой редактор - это не только Cut, Paste, Copy, но и большое количество поисковых функций.
К сожалению, Audacity ничего не знает о таких режимах поиска, как Zero Crossings (определение точки пересечения звуковой волны нулевого уровня), Find Beats (выделение границ тактов), Auto Cut (поиск фраз или долей) и т. п. Во-вторых, если win-версия программы может работать с VST-плагинами, то к Audacity for Linux на момент написания статьи никаких дополнительных модулей обработки звука подключить было нельзя.
Поддержка LADSPA обещается в следующей версии. В-третьих, самое неприятное, даже если ваша аудиокарта поддерживает работу в дуплексном режиме (одновременное воспроизведение и запись звука), воспользоваться этим в Audacity невозможно. Кроме того, не поддерживаются многоканальные профессиональные аудиокарты. Да и разрешение 16 бит @ 48 кГц - это на сегодняшний день очень мало.
У профессиональных звуковых карт оцифровка не меньше, чем 24/48. Не говоря уже о том, что для предотвращения неконтролируемого транкейта (truncate) поддержка звукового разрешения 32 бит не помешает. Про разделение аудиоресурсов я вообще молчу. Причины этих болезней хорошо известны - это OSS/Free-драйверы.
При работе через JACK приложению ничего не надо знать о драйверах, и поддержка этого сервера в Audacity решила бы кучу проблем. Однако в данном случае это не возможно, так как редактор кроссплатформенный, а JACK пока никто не собирается портировать. Я посмотрел бета-релиз Audacity.
Насколько я понял, разработчики решили ориентироваться на PortAudio. Это кроссплатформенная библиотека. Есть реализации для Windows (MME и DirectX), UNIX/OSS, Mac OS 9, Mac OS X, Linux/ALSA. PortAudio позволяет манипулировать аудиоданными, подобно аудиосерверу. Однако какие буду там задержки, я пока не знаю. Как бы там ни было, но стоит признать, что даже с учетом недостатков, для простых юзеров Audacity - хороший выбор.
У них хорошая коллекция rpm, ядер low latency, свежих драйверов и музыкального софта с подробными мануалами. Кроме того, познакомитесь с вузом, который живет за счет аудиоприложений под Linux. Там за деньги (!) обучают студентов и представителей коммерческих фирм работать с аудиоданными в Linux. Так вот, в недрах этого замечательного заведения для создания приложений синтеза и обработки звука был придуман язык программирования - CLM (Common LISP Music). Так как Snd пользуется библиотеками CLM, то его возможности почти безграничны.
Там есть несколько полезных статей по настройке программы. Во всем остальном Snd - стандартный аудиоредактор. Имеется весь джентльменский набор - record/edit/transform/mix. Плюс поддержка LADSPA и других динамически загружаемых модулей (STK, SoX, CLM). Между прочим, вся обработка звука - в реальном времени.
Синтезаторы
Году эдак в 92-м я видел по телевизору занятное выступление симфонического оркестра. К сожалению, сейчас не помню название исполняемого произведения, но никогда не забуду, как я обалдел, когда в середине концерта из оркестра выдвинулся мужчина во фраке с двуручной пилой и стал ею трясти. Это он исполнял партию пилы.
На его примере я хочу рассказать, как подключить к software synthesizer виртуальную клавиатуру или секвенсор. Надеюсь, ALSA-драйверы у вас уже стоят. SpiralSynth работает с OSS-драйверами, поэтому надо организовать эмуляцию OSS и виртуальные МИДИ-порты (ALSA-драйвер - virmidi).
В SuSe такие ссылки можно не делать. Там четыре девайса возникают автоматом - /dev/midi1, /dev/midi2 и т. д.
SpiralSynth, естественно, не единственный программный синтезатор под Linux. Вообще-то, синтез звука - это область мультимедиа в Linux, которая всегда опережала подобные разработки в Windows. Государственные структуры и частные фирмы охотно финансируют научно-исследовательские работы в области акустики и звука. Получить тайные знания о воздействии звука на человека - заветная мечта и первых, и вторых.
Библиотеки звуков
Создание и редактирование библиотек звуков - не такое уж редкое явление. Существует довольно много разных форматов файлов для хранения сэмплов. Про Akai S1000/S3000 я уже упоминал. Банки звуков в формате GIG для GigaStudio (Gigasempler) for Windows - то же не редкость. В старые времена в Linux получили распространение патчи Gravis Ultrasound.
С его помощью можно редактировать или создавать свои собственные SF2-банки. Редактор прекрасно ладит с программным сэмплером iiwusynth, посему можно работать с любой аудиокарточкой, а не только с продукцией Creative.
Принцип действия программы, надеюсь, понятен. Берете встроенную в редактор виртуальную клавиатуру, вешаете на каждую клавишу WAVE, обрабатываете, а потом перегоняете это в SF2. Когда будете обрабатывать, обратите внимание не только не только такие эффекты, как реверберация или хорус, но и на панораму. Орган, да и фортепиано - это все-таки стереоинструмент.
Как и положено современному секвенсору, он может редактировать не только MIDI, но и Audio. JAZZ++ - кроссплатформенная программа. Однако в отличие от Audacity секвенсор поддерживает ALSA-драйверы и вроде бы будет поддерживать JACK. Пока этого нет, одновременная работа с программным синтезатором и аудиоданными не возможна. Если же вы пользуетесь встроенным в вашу саундкарту синтезатором или внешним аппаратом, то эти проблемы вас не должны волновать.
MusE muse.seh.de - секвенсор-фаворит. Интерфейс программы, да и возможности напоминают привычный Sonar. В его дистрибутив входит сэмплер iiwusynth и три программных синтезатора. Так как все это хозяйство работает внутри секвенсора, то проблем с разделением ресурсов и конфликтов между MIDI и audio не наблюдается. Начиная с версии 06, в программу включена поддержка аудиосервера JACK, что есть очень даже хорошо.
MusE - самый продвинутый секвенсор. Авторы внимательно наблюдают за тем, что происходит в Linux. И все самое интересное включают в свой проект. MusE первым из секвенсоров стал поддерживать ALSA-драйверы, LADSPA-плагины и JACK API. Возможность редактирования в секвенсоре звука и включение в программу программных синтезаторов доказывает, что разработчики хотят превратить MusE в полноценную виртуальную студию. А виртуальная студия - это сейчас очень модно. Sonar и Cubase давно движутся в этом направлении. И если MusE уступает им в чем-то, то ненамного.
По-моему, в одном из произведений Салтыкова-Щедрина была фраза: "Обыватели с полной порции перешли на полпорции". Надеюсь, мне удалось показать, что Linux - это не полпорции, а уже полнофункциональная мультимедийная платформа. После решения системных проблем количество аудиоприложений под Linux стремительно растет.
Уже сегодня с помощью описанных выше программ можно создавать фонограммы профессионального качества. А завтра? Перспективы обнадеживающие. Нашлись деньги для разработчиков со стороны Евросоюза. Недавно Европейская Комиссия учредила новый проект - AGNULA (A GNU/Linux Audio distribution). Задача - за два года создать дистрибутив с аудиоприложениями для профессионалов.
Ubuntu Linux
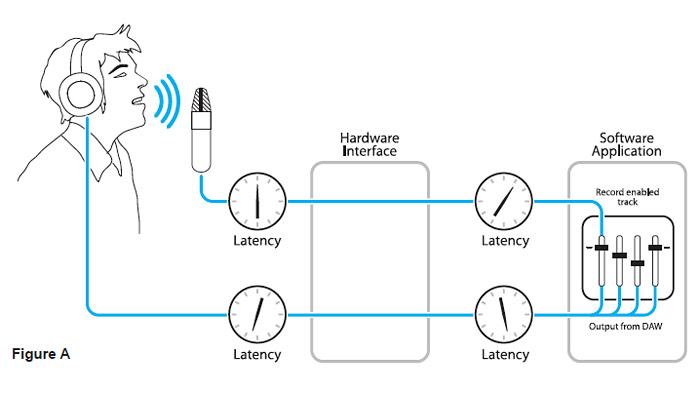
Latency наглядно
Ваша звуковая карта должна иметь поддержку этого протокола и соответствующие драйвера. Иначе есть эмулятор ASIO4ALL. На ASIO я получал до 12-20 мс быстродействия, что вполне достаточно для записи музыкальных инструментов.

Вот что делает ASIO
Linux навевает осеннее настроение

Есть ли вообще bitperfect на Linux уже рассматривалась любителями высококачественного аудио в материале Тест Linux на качество звука, а есть ли BitPerfect , где было успешно доказано его присутствие.
resample-method = copy
Написать
default-sample-format = float32ne;
Если этого не сделать, то хай-рез форматы будут проигрываться с меньшей скоростью (двух-трех-кратной примерно на слух).
А эти строчки
default-sample-rate = 44100
alternate-sample-rate = 192000
Зададут максимальную частоту потока подаваемого на ЦАП.
Можно выбрать только 2 значения, по умолчанию и еще одно, если под умолчание не подпадает. Конечно хотелось бы, что бы можно было задать больше значений, но нет.
В итоге нет особого резона отказываться от pulseaudio, так как через него намного удобнее управлять alsa. Для этого существует специальная графическая утилита pavucontrol.

pavucontrol

ЦАП на PCM1794a
Что удалось услышать.
При использовании ресемплеров (любых):
При использовании pulseaudio в режиме copy получаем:
Острый сочный звук
Стереоэффекты удивительно устойчивые и ясные
Драйвовость и искрометность.
Ясность, каждый инструмент как на ладони, нет аморфной звуковой подложки.

9 Комментарии
Каждый, кто сталкивался с вопросом о качественном воспроизведении звука рано или поздно встречается с аббревиатурой ASIO, как важной и необходимой опцией.
Что это и в чем практический смысл?
Прежде всего, ASIO имеет отношение только к звуковой части записи/воспроизведения с компьютера через звуковую карту или USB-ЦАП под операционными системами семейства Windows. Тем, кто слушает музыку со смартфона или с сетевого проигрывателя с собственной ОС иметь представление ASIO тоже полезно, т.к. знание об этой «опции» позволяет избежать ряд проблем, присутствующих в смартфонах и соответственно позволяющая понять, почему не все платформы для звука одинаково полезны.
ASIO – это программный интерфейс передачи данных от программы, которая воспроизводит или принимает звуковой сигнал напрямую в драйвер звуковой карты, минуя звуковую подсистему ОС.
Необходимость в ASIO возникла исключительно для профессиональных задач. Самой большой проблемой была и остается минимальная задержка для передачи аудио сигнала. Когда мы смотрим фильм, нам не важно, сколько времени требуется системе для старта воспроизведения видео и аудио, доли миллисекунды или пару секунд после нажатия на кнопку «play». Главное, чтобы видео и аудио были синхронны относительно друг друга. В студии же требования очень жесткие, т.к. часто требуется игра вживую на виртуальных инструментах, с которых звук необходимо обрабатывать в реальном времени. Невозможно полноценно играть на midi клавиатуре, если нажатие на клавишу слышишь не сразу, а спустя секунду.
Штатно в ОС семейства Windows задержка составляет от 7 до 300 мс и зависит от текущей загруженности системы. Как несложно догадаться, звуковая система не является приоритетной в Windows и все что от нее требуется, это что бы звук просто не заикался, а для этого аудио данные собираются отдельный буфер и передаются сразу большим куском. Для сверх малых задержек буфер должен быть маленьким и постоянно передаваться небольшими пакетами.

ASIO является альтернативным мостом, который обеспечивает передачу звукового потока от программы до драйвера с фиксированным значением буфера, минуя штатную систему передачи данных ОС. Т.к. ASIO не является разработкой Microsoft (которой, к слову, на звук традиционно положить три кучи), то поддержка вывода и приема в ASIO ложится на плечи производителя ПО и звуковых устройств. Первоначально ASIO был разработан компанией Steinberg под свои продукты в момент перехода от MIDI к виртуальному синтезу и сегодня поддерживается практически всем профессиональным софтом и звуковыми интерфейсами.
Как несложно догадаться, аудиофилам без разницы на то, какая задержка в системе. Но полезно знать, на что ОС тратит свои силы под передачу звука и как это сказывается на качестве.
Как влияет звуковая подсистема ОС на звук

В ОС много программ, которые являются источниками звука, это Skype, ICQ, браузер с музыкой в вКонтакте, системными звуками, видеопроигрывателем и другими приложениями. Все эти звуковые потоки различаются как дискретностью, так и частотой семплирования, а на ЦАП должен придти всего один стерео поток с определенной разрядностью и частотой дискретизации. Соответственно все звуковые потоки необходимо заранее смикшировать. Что бы представить уровень проблемы, представим, что есть несколько фотографий с разными исходными разрешениями, которые нужно одновременно вывести на экран ЖК монитора, при этом каждая фотография должна заполнить весь экран. Если фото вывести пиксель в пиксель и фото займет часть экрана – это будет аналогично тому, что звук будет воспроизводиться медленнее или быстрее.
Если разрешение фотографии 600х480 пикселей, а разрешение монитора 1024х768, то необходимо фотографию предварительно перевести в 1024х768. Четкость фотографии несомненно снизится. Примерно так страдает и звук, который система пересчитывает из 44,100 кГц в 48000 или 96000 кГц. Качество ресемплера в Windows оставляет желать лучшего, т.к. идет максимальная экономия ресурсов.
Возвращаясь к фотографии, у нас есть фото с разрешением в 600х480 пикселей, 1024х768 пикселей и 2048х1536 пикселей и все фотографии надо вывести на 1024х768 пикселей. До сложения необходимо 600х480 и 2048х1536 пересчитать в 1024х768 и после три фотографии просуммировать, накладывая одну картинку на другую.
Обычно только одна программа воспроизводит основной звук, а остальные проигрывают звук периодически (ICQ, Skype) и их можно сравнить с логотипами и надписями поверх основной фотографии. Вполне очевидно, что картинка с исходным разрешением в 1024х768 меньше всего пострадает в качестве и если она будет основной и совпадать с разрешением монитора, то в снизится качество лишь вспомогательных картинок: логотип и надписи.
Так же и в системе можно формально выставить конечную частоту семплирования 44.100 кГц под аудиоплеер и пренебречь качеством системных звуков, которые звучат лишь время от времени.
Однако для наименьших потерь в качестве при микшировании звуковых потоков добавляется специальный шум (диттер) и системе все равно, одна программа воспроизводит звук или несколько. Таким образом, даже при воспроизведении всего одного звукового потока без его конвертирования в другую частоту семплирования, он все равно подвергается обработке и уже не поступит на ЦАП «бит в бит».
Если раньше ОС отслеживала, с какой частотой семплирования поступают на вход данные и автоматически выставляла максимальную поддерживаемую звуковой картой частоту дискретизации к входящим звуковым потокам (например при входящих 22, 44,1 и 48 кГц выставлялась 48 кГц, а при 22 и 44,1 понижалась до 44,1 кГц ), то начиная с Win7 в системе принудительно выставляется общая частота семплирования и автомата опорной частоты нет. Стабильность ОС повысилась, но метод не всех обрадовал.
Описанная ситуация в равной степени справедлива для всех ОС и платформ, которые могут воспроизводить звук одновременно с разных программ. В мобильном телефоне это к примеру воспроизведение телефонного разговора и системный сигнал о севшей батарее.
Условно общая схема выглядит так. При использовании ASIO Звуковой поток направляется сразу в микшер драйвера звуковой карты (Mixer Driver), минуя ресемплер (SRC) и микшер ОС.
Для необходимости воспроизвести звуковой поток «бит-в-бит” есть специальные режимы, в ОС Windows это «Kernel Streaming» (версии до XP) и WASAPI (версии после XP включительно). В таком режиме право передать звуковой поток имеет только одна программа в системе и тут полностью исключается микширование и пересчет данных. Более того, есть поддержка системой автоматического переключения опорной частоты (но при соответствующей поддержке драйвера звуковой карты).
Этот режим не рекомендуется использовать обычному пользователю, т.к. несет за собой разные проблемы. Например, пользователь включает Foobar2000 с WASAPI и после запускает видео ролик с ранее запущенного браузера. Звуковой драйвер не принимает звуковой поток от браузера и происходит крах флеш плагина. Налицо — система порушилась, а это: «печаль, беда и огорченье». Производители ПО крайне редко делают возможность вывода звука в KS/WASAPI, т.к. воинствующие пользователи будут винить в проблемах не свои кривые руки, а программу «из-за которой все порушилось».
Режимы KS/WASAPI можно встретить только в аудиоредакторах, секвенсорах и редких программных плеерах, предназначенных для аудиофилов – под подготовленных пользователей, которые понимают, что будет страдать стабильность работы ОС и кроме плеера/аудиоредактора/секвенсора звука не будет. Продвинутые аудиофилы, отказавшиеся от встроенного звука обычно для музыки используют отдельную звуковую карту, а системные звуки направляют на встроенный звук, что обеспечивает высокую стабильность работы ОС.
Т.е. по сути, KS/WASAPI – это идеальный вариант для вывода звука для аудиофила. Поддерживается в Foobar2000, AIMP, Winamp. Тем, кто хочет и фильмы в качестве слушать – есть плеер Light Alloy.
ASIO или WASAPI?
Профессионалы используют режим ASIO, который передает в драйвер звуковой поток «бит-в-бит» и обеспечивает фиксированный уровень задержки. WASAPI штатными настройками ОС не позволяет управлять задержкой. Уровень задержки в профессиональной работы приоритетнее, а «бит-в-бит» лишь приятный бонус.
Что происходит, когда задействованы одновременно звуковая система ОС и ASIO?
Для звукового драйвера есть два звуковых потока, одни из них приходит из подсистемы ОС, другой из ASIO. Исключительно от того, как был написан драйвер, будет происходить микширование финального потока до ЦАП. В одних случаях, если есть звуковой поток из ASIO, то звук от подсистемы ОС отключается, в других случаях происходит микс потоков из ОС и ASIO и «бит-в-бит» остается только в теории. ASIO, как и WASAPI позволяет лишь избежать алгоритмов SRC (передискретизации) и микширования подсистемы ОС и ничего более. Целостность финального потока будет зависеть от драйвера.
В любом случае, практически всегда звуковая карта работает в том же режиме семплирования, что и поступающий поток из ASIO, что дает некоторое преимущество для ASIO.
Микширование в драйвере может быть программным, а может аппаратным. Особенно забавно выглядят попытки аудиофилов в качестве источника ставить профессиональный интерфейс для «качественной цифры», где цифра выдается после аппаратного микширования. Впрочем, некоторым отмикшированный звук нравится больше оригинального … чище, прозрачнее и душевней…
Если логически просмотреть цепочку, по которой должен пройти звуковой поток, то для идеологии «бит-в-бит» звуковой интерфейс должен поддерживать всего один вариант, либо отключать микширование потоков при работе только одного интерфейса. Только в этом случае шансы получить «бит-в-бит» максимальны.

К примеру, возьмем OPPO HA-1 c поддержкой ASIO. Если запустить одновременно Foobar2000 с WASAPI и AIMP с ASIO, то на выходе мы услышим одновременно оба звуковых потока. Цифровых выходов у OPPO нет и соответственно нет возможности проверить звуковой поток на «бит-в-бит» отдельно для ASIO и WASAPI перед ЦАП.
А вот с ASUS Essence STU ситуация иная. Если AIMP с ASIO играет, то Foobar2000 с WASAPI уже молчит, звуковые потоки не смешиваются, отдавая приоритет для ASIO. Проверить цифровой поток аналогично возможности нет, но шансов, что звуковой поток поступил «бит-в-бит» на порядок больше.
Считается, что USB-ЦАП обязательно должен поддерживать ASIO, но на практике мы получаем дополнительное звено, где должны смешиваться или переключаться потоки из звуковой системы ОС и ASIO. И тут отсутствие ASIO – это отсутствие неизвестного звена, где может быть принудительное микширование, которое нельзя протестировать без цифровых выходов. В тоже время микширование на этом этапе обычно производится в разрядности 24 или 32 бита и соответственно услышать шум диттера маловероятно. Проблема лишь в идеологии «Hi-End».
Является ли ASIO панацеей от всех бед?
Как показывает практика, все зависит от драйвера звукового устройства. Если устройство профессиональное, то обычно стабильности и качеству у производителя ASIO максимум внимания. Если устройство бытовое, то ASIO может работать на порядок хуже режима KS/WASAPI. С практической точки зрения при выборе использования KS/WASAPI и ASIO нужно использовать тот интерфейс, с которым ОС работает более стабильно.
Универсальный драйвер ASIO4ALL
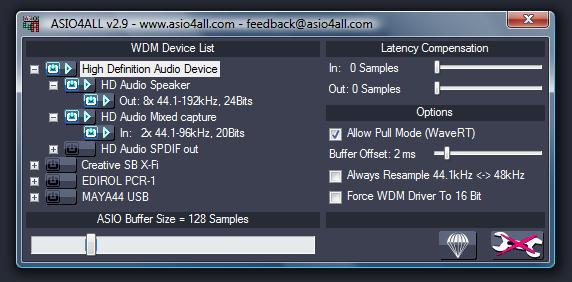
Драйвер ASIO4ALL необычайно популярен, но является при этом мостом между выходом ASIO из программы на вход KS/WASAPI в ОС. Это важно знать, т.к. если у вас звуковая карта не поддерживает ASIO, то после установки ASIO4ALL в том же Foobar2000 у вас выбор, выбрать изначально вывод в KS/WASAPI или ASIO через ASIO4ALL, который направит звуковой поток в тот же KS/WASAPI в ОС.
Ремарка для фанатов ASIO4ALL – да, там есть еще разные настройки, вроде выбора буфера и т.п., но эти возможности нужны лишь в профессиональной работе и ничего полезного не дают аудиофилам, для которых предназначен данный материал.
Что дает право утверждать, что ASIO4ALL доносит данные «бит-в-бит» до KS/WASAPI? Ведь теория и практика зачастую дают противоположные результаты. Для оценки качества работы ASIO4ALL был задействован Audiolab M-DAC с функцией проверки входящего звукового потока на «bit perfect» через воспроизведение специального звукового файла. Тест подтвердил, что данные приходят действительно «бит-в-бит» при воспроизведении из Foobar2000 через ASIO4ALL.
Кстати, приходили утверждения со стороны программистов, что например ASIO драйвер внешних карт E-MU (USB версий) сделан аналогично ASIO4ALL в виде моста и именно это является источником низкой стабильности карт…
Android и «бит-в-бит»
Возвращаясь к плеерам на базе ОС Android. В данной ОС есть аналогичный режим KS/WASAPI, но вот явных настроек под него нет. Единственный программный плеер, в котором есть режим прямого вывода в ЦАП используется в iBasso DX100. Разумеется, собственный программный плеер работает только в DX100 его нельзя скачать и поставить например в плеер Sony.
Проверить работу в Android на «бит-в-бит» очень просто. Запустите любой будильник и плеер. Если поверх звука из плеера вы услышите будильник, то никаких «бит-в-бит» на выходе нет.
ASIO – это возможность передать звуковой поток “бит-в-бит” минуя обработку звука в подсистеме ОС, но помимо ASIO есть и альтернативный вариант KS/WASAPI. Качество и точность передачи в конечном итоге обеспечивает лишь драйвер звукового устройства и порой отсутствие ASIO лишь отдельный плюс.
Наверняка у многих людей при прослушивании их любимого трека или музыкальной композиции хотя бы раз возникало желание сыграть её самому на каком-либо инструменте или же вообще самому записать нечто подобное.
Те, у кого дома есть какой-либо музыкальный инструмент, могли взять его в руки или сеть за него и начать воплощать свою идею в жизнь.
Тем же, у кого дома, либо у друзей, никакого музыкально инструмента нет и достать его в ближайшее время (пока не иссякло вдохновение) не представлялось возможным, оставалось одно — попытать использовать компьютер в качестве музыкального инструмента.
Нет, я не имею в виду то, что по компьютеру начинали стучать молотками или ложками, аккомпанируя стуками по кастрюлям и другим предметам, попавшимся под руку. Я имею в виду то, что у человека, как правило, возникает идея использовать свой компьютер в качестве музыкального синтезатора, установив на него специальную программу для этих целей.
Первым же делом, немного поискав в интернете, люди практически всегда наталкиваются на платный программный синтезатор FL Studio. Он весьма разрекламирован в интернете и его многие считают одним из лучших синтезаторов. С этими утверждениями я спорить не буду, так как не являюсь специалистом в данной области, но зато могу уверено сказать что у FL Studio существую и аналоги, причем как платные, так и бесплатные. Как раз о бесплатном аналоге FL Studio и пойдет речь в данном материале.
Может в чем то FL Studio и превосходит свои аналоги, но если смотреть с точки зрения не профессионала, т.е. с точки зрения обычного пользователя, который захотел заняться музыкой и использовать программный синтезатор, то он в первую очередь задумается о сумме, которую просят за программу или вообще о её бесплатности.
FL Studio в этом плане весьма не дешёвая программа, самая простенькая версия Express стоит на данный момент около $50. Пользоваться ей бесплатно можно только в течении пробного периода, который постоянно сокращают по неизвестным мне причинам, причем в пробном режиме нельзя сохранять свои треки.
Тем, кто не обладает весьма значительным бюджетом обычно скачивают пиратские версии FL Studio и довольствуются ими. Но при этом нужно понимать, что созданные вами треки в пиратской программе вы не сможете нигде использовать официально.
Как раз в такой ситуации и полезно знать, что существует весьма хороший, причем бесплатный аналог – Linux MultiMedia Studio (LMMS).
Linux MultiMedia Studio (LMMS) Logo:
Сравнение Linux MultiMedia Studio (LMMS) и FL Studio
Преимущества LMMS перед FL Studio
1. LMMS бесплатна.
LMMS распространяется под лицензией GNU GPL, которая обязует открывать исходный код программы, а так же распространять программу бесплатно.
FL Studio же является платной программой с закрытым исходным кодом, т.е. проприетарным программным обеспечением. Самая дешевая версия FL Studio и соответственно самая урезанная функционально — версия Express, стоит она около $50, а за самую дорогую версию Signature Bundle просят порядка $300.
2. LMMS обладает официальным переводом на русский язык.
У LMMS есть официальный перевод на русский язык, причем его не нужно скачивать отдельно, он присутствует сразу в стандартном пакете установки.
FL Studio же официальным переводом на русский язык похвастаться не может. Конечно существуют в интернете сторонние переводы от разных сайтов (проектов) или отдельных пользователей, но часто из-за них программа работает не стабильно.
Преимуществом LMMS это является потому, что пользователям, не обладающим хорошими познаниями в английском языке, будет очень трудно самостоятельно осваивать и разбираться в FL Studio. А в LMMS же в этом плане разобраться будет проще, так как практически все меню, за исключением VST плагинов, переведены на родной русский язык.
3. LMMS менее требовательна к ресурсам системы.
При личном ознакомлении с FL Studio и LMMS, я обратил внимание, что LMMS менее требовательна к ресурсам ПК. LMMS быстрее загружается и быстрее считывает собственный набор плагинов. Разница вы быстродействии конечно не особо большая, но она есть. Конечно это преимущество весьма субъективно, так как на другой системе разницы может и не быть, а так же нужно учитывать что пользователь может использовать не самые свежие версии программ (я использовал самые свежие на момент написания статьи стабильные релиз-версии при сравнении — LMMS 0.4.8 и FL Studio 9.1.0).
Недостатки LMMS (в сравнении с FL Studio)
1. В LMMS нет поддержки вывода звука через ASIO
К недостаткам LMMS, в сравнении с FL Studio, можно отнести отсутствие поддержки ASIO, звук выводится через стандартные устройства вывода системы — DirectX и WaveOut, используя библиотеку SDL.
Это объясняется тем, что LMMS изначально разрабатывался под системы на базе Linux. В этих системах нет проблем с задержками сигнала при выводе звука через тот же ALSA, в отличии от Windows, поэтому ASIO системам на базе Linux попросту не нужен.
Но несмотря на то, что LMMS изначально разрабатывался под системы на базе Linux, он может работать и в других системах. Одна из причин этого — использование кроссплатформенных библиотек Qt при написании программы, а так же использование кроссплатформенной библиотеки SDL для вывода звука.
Так же отсутствие поддержки ASIO в LMMS объясняется и тем, что ASIO не распространяется под лицензией GNU GPL и её исходные коды закрыты, что помешало бы открывать исходные коды LMMS.
2. Отсутствие возможности сохранять свои записи в формат MP3. LMMS позволяет сохранять свои записи только в форматы WAV и OGG Vorbis.
Это одни из недостатков LMMS в сравнении с FL Studio — отсутствие возможности конвертировать, т.е. сохранять уже сведенную запись, в MP3. LMMS поддерживает только WAV и OGG Vorbis, FL Studio же поддерживает и OGG Vorbis, и WAV, и MP3.
Вообще лично для меня отсутствие поддержки MP3 абсолютно не критично, так как качество алгоритма сжатия у OGG Vorbis куда лучше, чем у MP3.
Эпилог
Конечно LMMS имеет некоторые видимые недостатки с точки зрения не профессионала по сравнению с FL Studio, но они, на мой взгляд, не столь критичны.
Пример интерфейса LMMS:
Например, с тем же отсутствием ASIO при создании музыки под Windows можно смириться потому, что это доставит некоторые неудобства в основном только тем, кто решил использовать MIDI-клавиатуру — будут ощущаться задержки во времени между нажатием клавиши и выходом звука с колонок. Если же вы не собираетесь использовать какие-то сторонние MIDI-устройства, то вы наверняка и вовсе не ощутите этот недостаток.
Вполне вероятно еще что людям с хорошим музыкальным слухом будет слышна некоторая замыленость звука при его выводе через стандартные устройства Wavе Out и DircetX на Windows Vista/Seven из-за микшерного ядра Windows — KMixer. Но непосредственно на самом треке и качестве записи это никак не отразится, так как в процессе формирования записи, т.е. сведения/сохранения, если позволите так выразится, KMixer никакого участия, к счастью, не принимает.
В любом случае основное преимущество LMMS перед FL Studio все же не отнять — LMMS бесплатна, исходя из этого я думаю, что с некоторыми недостатками можно смерится и не обращать на них внимание. Тем более LMMS может вообще избавиться от них в ближайшем будущем.
Список VST плагинов (инструментов/эффектов и тп), которые можно использовать в LMMS.
Подключение VST-плагинов (VTSi) в LMMS (Смотреть в полном размере):
Читайте также: