
Аналог strace для windows
Обновлено: 04.07.2024
За последние два года я представил вам достаточно большое количество утилит для системного администрирования. Мы узнали, как правильно анализировать круг проблем путем тщательного исследования симптомов и выявления причин. Мы изучили strace и lsof , которые являются достаточно мощными инструментами. Мы сфокусировались на профилировании и аудите системы. Мы поклонялись всемогущему отладчику GNU Debugger (gdb) . Теперь пришло время объединить мощь всех этих программ в одном мега-руководстве.
Сегодня мы будем использовать все эти утилиты плюс некоторое количество приемов и советов, изложенных в моих руководствах по хакингу, чтобы попробовать попытаться решить казалось бы неразрешимые проблемы. Мы рассмотрим вопрос с нескольких точек зрения, каждый раз используя разные инструменты и показывая новые грани проблемы, пока не разрешим ее. Это будет нелегко, однако это, вероятно, будет уникальным многоцелевым руководством по системному администрированию и отладке среди тех, которые вы прочитали за очень долгое время.
Имеющаяся проблема
Итак, предположим, что у нас медленно происходит загрузка приложений. Вам приходится ждать 5 - 10 секунд, пока появится окно программы. Иногда все работает быстро, но вы не можете понять, почему. Обычно проблема возникает после выхода из сеанса или перезагрузки. Самое неприятное то, что если вы запускаете те же программы с помощью sudo или как or root, никаких задержек не наблюдается и все, кажется, работает нормально. Как же диагностировать такую проблему?
Правила!
Если вы хотите стать компетентным системным наладчиком, есть несколько желательных к исполнению правил, которым вы должны следовать, когда пытаетесь решить трудную задачу. Хорошо, если вопрос тривиальный и решается за пару минут. Однако если вы и ваши коллеги не можете разрешить проблему в течение часа, необходимо подумать и решать ее методически.
Будьте методичным
Имея стереотипный подход, вы можете выглядеть как нуб - или как очень компетентный человек. Вам выбирать. Вы можете обладать универсальной стратегией, применимой к решению любой проблемы, будь то ремонт самолета или взлом ядра операционной системы.
Всегда начинаем с простого
Теоретически, вы можете попробовать решить любую проблему сразу с помощью gdb, но вряд ли это будет рациональным использованием вашего интеллекта и времени. Вы должны всегда начинать с простых вещей. Проверьте системные логи на наличие странных ошибок. Запустите top, чтобы проверить загрузку процессора и потребление памяти.
Сравнение с исправно работающей системой
Это не всегда возможно, но если у вас есть машина с идентичным железом и таким же набором программного обеспечения, на которой не проявляется данная проблема, либо одинаковые сценарии нагрузки дают разные результаты, вы можете попробовать сравнить их между собой, чтобы найти причину неполадок. Это будет нелегко сделать, однако поиск - это наиболее мощный инструмент в такого рода ситуациях, и он применим как к механическим, так и к программным проблемам.
Теперь мы готовы копнуть глубже.
Симптомы
Нормально работающая система загружает xclock (простая графическая утилита, которую мы использовали в качестве теста) менее чем за секунду. При наличии проблем ее загрузка может занять до 10 секунд. Теперь мы знаем, что проблема имеется, но не знаем, в чем она заключается.
Strace
На данном этапе хорошей идеей будет использование strace. Прежде чем отслеживать каждый системный вызов в бесконечных логах, мы может оценить ситуацию в целом, запустив программу с флагом -c и посмотреть ее вывод.
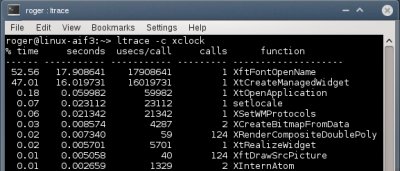
Лог strace в нормально работающей системе
Вот что мы видим в данном случае:
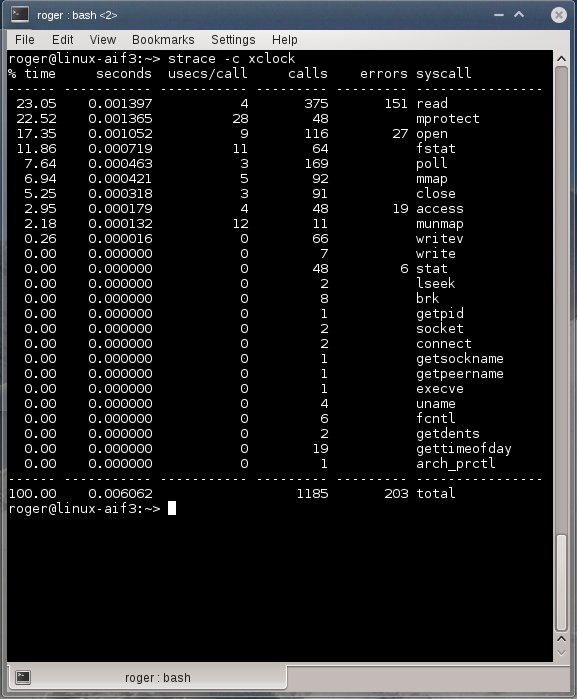
Лог strace в проблемной системе
То же самое при наличии ошибок:
Сопоставление данных strace
Я привел рядом два результата strace. Видно, что поведение системы в двух вышеописанных случаях кардинально отличается.
В нормально работающей системе четыре верхних системных вызова - это read, mprotect, open и fstat. Всего у нас от нескольких десятков до нескольких сотен вызовов, среди которых имеется некоторое количество ошибок, связанных, вероятно, с поиском файлов в $PATH. Еще один важный элемент - время выполнения, которое составляет 1-2 милисекунды на каждый из четырех вызовов.
В проблемной системе лидируют open, munmap, mmap и stat. Более того, количество вызовов теперь измеряется тысячами, а время выполнения в 10-20 раз больше, чем было в нормальной системе.

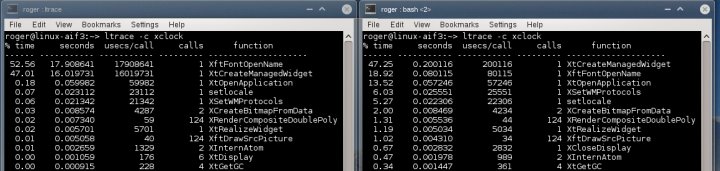
Ltrace
Теперь мы воспользуемся ltrace и возможно узнаем что-то еще. Налицо значительная разница в поведении системных выводов, но мы не знаем, что является причиной проблемы. Возможно мы сможем это выяснить, изучив поведение библиотек, для чего и предназначена ltrace. Мы снова будем использовать флаг -c, чтобы увидеть конечный результат.
Лог ltrace в нормально работающей системе
Здесь целый пласт новой информации. Самая затратная функция библиотеки - создание виджета xclock, которая занимает 20 милисекунд, что составляет почти 40% от всего времени выполнения. На втором месте XftFontOpenName.
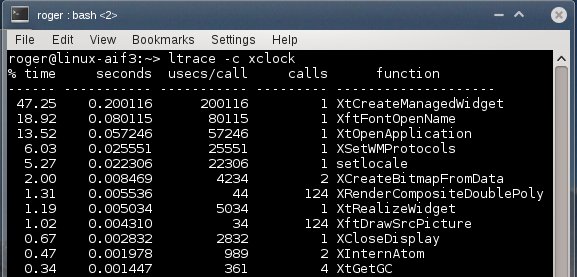
Лог ltrace в проблемной системе
Здесь мы видим кое-что другое. Лидирует функция The XftFontOpenName, которая выполняется в течение 18 секунд. На втором месте создание виджета с не менее впечатляющими 16 секундами. Больше ничего заслуживающего внимания не обнаруживается.
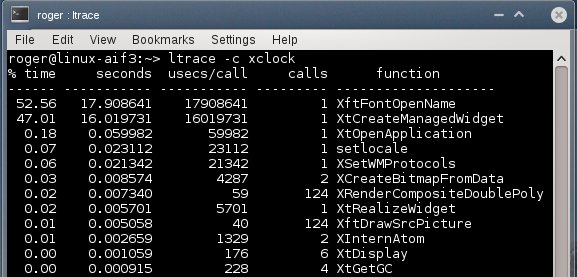
Сопоставление данных ltrace
Мы можем определенно сказать, что с шрифтами что-то не так. В нормальной системе вызов соответствующей библиотеки происходит практически мгновенно, в то время как в проблемной он длится почти 20 секунд. Сопоставляя логи, мы можем теперь прояснить картину. Большая длительность вызова функции, отвечающей за создание виджета, объясняет столь медленное появление окна программы. Более того, это прекрасно совмещается с огромным количеством системных вызовов и ошибок. Теперь у нас есть ключ к решению проблемы.
Дополнительный анализ с помощью vmstat
Некоторые могут сказать, что у нас уже достаточно информации - проблема в шрифтах. Но если вы не уверены на все 100%, можно попробовать узнать еще больше с помощью vmstat.
Нормально работающая система
vmstat выдает полезную информацию об использовании памяти и CPU. Мы уже говорили об этой утилите ранее, поэтому я не буду повторяться. Сегодня нас интересуют поля метрик CPU в последних пяти столбцах вывода программы, особенно два из них, помеченные как us и sy, а также поля cs и in в разделе system.
Поля us и sy показывают степень использования процессора пользователем и системой соответственно. Поля cs и in относятся к переключениям контекста и прерываниям. Первая метрика показывает примерно, как часто запущенный процесс отказывается от своего места в очереди запросов в пользу другого ожидающего процесса. Другими словами, это переключение контекста между процессами. Прерывания показывают, сколько раз работающие процессы получали доступ к оборудованию, например доступ к диску для чтения данных из файловой системы, опрос экрана или клавиатуры и т.д.
Давайте посмотрим, что происходит, когда мы запускаем программу xclock. Игнорируем первую строку, так как в ней показаны средние значения с момента последнего запуска системы. Мы можем видеть краткий всплеск нагрузки на процессор, который хорошо соотносится с большим количеством прерываний и переключений контекста. Время запуска xclock показано в четвертой строке.
Проблемная система
Здесь ситуация несколько отличается. Мы можем видеть значительное увеличение нагрузки на процессор в течение почти 5 - 7 секунд. Однако у нас намного меньше переключений контекста и намного больше прерываний. О чем это говорит? Мы видим, что xclock, который является интерактивным приложением и поэтому должен обрабатываться как интерактивный процесс, при запуске ведет себя как вычислительный (пакетный) процесс.
От интерактивных процессов мы ждем как можно большей отзывчивости, что подразумевает множество переключений контекста и низкую активность процессора, так что мы получаем от планировщика динамический приоритет и тратим как можно меньше времени на вычисления, отдавая контроль пользователю. Однако в нашем случае процесс имеет намного меньше переключений контекста и намного сильнее нагружает процессор, что типично для пакетных процессов. Это означает, что производится намного больше вычислений: наша система читает шрифты и создает кэш, в то время как мы ждем запуска xclock. Это также объясняет повышение активности системы ввода/вывода, так как данные операции выполняются в нашей локальной файловой системе.
Сейчас важно подчеркнуть, что вышеприведенный анализ будет совершенно бесполезен, если вы не знаете, как работает ваш процесс и что он должен делать. Однако, если у вас есть хотя бы намек на идею, даже скучный список чисел в выводе vmstat может дать вам огромное количество информации.
Решение проблемы
Я полагаю, мы получили достаточно информации, чтобы решить ее. Что-то не то со шрифтами. Факт столь долгого запуска приложения говорит о том, что кэш шрифтов создается каждый раз заново, что, в свою очередь, свидетельствует о том, что запущенная пользователем программа не имеет доступа к системному кэшу шрифтов. Это также объясняет, почему при запуске программы с правами root подобной проблемы не наблюдается.
Приложение работает медленно. Логи strace показывают открытые ошибки. Теперь мы можем запустить полную сессию strace и найти точные пути этих ошибок. Мы будем использовать флаг -e для открытых системных вызовов, чтобы сократить вывод, и мы будем увеличивать длину строки используя флаг -s, чтобы получить всю информацию о потерянных путях. Мы хотим узнать о шрифтах, недоступных для чтения пользователем.
Но нам не нужно этого делать, так как эту информацию мы уже получили с помощью ltrace, которая показала, что проблема кроется в чтении шрифтов. Этот библиотечный вызов блокирует создание виджета, поэтому приложение запускается медленно. vmstat обеспечил нас дополнительной информацией, которая помогла сузить круг поиска.
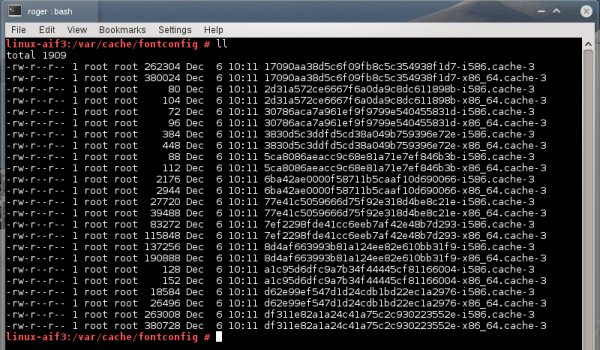
Если мы проверим системный кэш шрифтов, расположенный в /var/cache/fontconfig, мы увидим, что эти шрифты созданы с правами доступа 600, то есть они доступны для чтения только root. Если мы сменим права на 644, мы решим проблему и все наши программы будут запускаться быстро. Кроме того, тем самым мы сэкономим дисковое пространство, так как не будет необходимости создания своей копии шрифтов для каждого пользователя в своей домашней директории.
Использование lsof для отладки системы
Теперь я хотел бы кратко описать другую проблему. Она полностью отличается от предыдущего примера. Более того, в данном случае strace и ltrace полностью бесполезны, так как процесс завис. Мы на самом деле не понимаем, что происходит, но все утилиты, описанные выше, помочь нам не могут. Встречайте lsof.
Итак, у нас есть процесс Java, который завис и не отвечает. Java всегда выглядела непривлекательно и поставлялась с отвратительным механизмом обработки исключений, но мы должны отследить ошибку, а все обычные инструменты не могут дать нам никакой полезной информации. Вот, что мы видим в выводе strace:
Но если вы проверите этот процесс с помощью lsof, то увидите что-то вроде этого:
Мы можем видеть, что Java использует два порта IPv4 для внутренней коммуникации. Она отправляет пакет с одного порта в другой, инициализируя TCP-соединение. По каким-то причинам сервер, прослушивающий порт 22122, не отвечает.
На этом этапе вы можете проверить, почему пакет не принимается сервером. Нет ли проблем с маршрутизацией? К локальной машине это, вероятно, не относится, но, возможно, место назначения пакета находится в другом месте? Нет ли проблем с файерволом? Можете ли вы подключиться к соответствующей машине и порту с использованием telnet? На этой стадии у вас еще нет всех инструментов для исправления ошибки, но вы уже знаете, что является причиной проблем с Java. Поэтому для всех практических целей можно считать, что проблема решена.
Заключение
Я уверен, что вам понравилось это руководство. Я постарался объединить в этой статье все - рациональное мышление, методический подход к решению проблемы, разнообразное использование отладочных утилит для выявления причин проблемы, включая сравнение системных вызовов и библиотечных функций между нормально работающей и проблемной системами, использование vmstat для понимания поведения процессов, и так далее. В качестве бонуса мы изучили использование lsof для ошибок, связанных с сетевыми функциями.
Теперь вы сможете изменить подход к администрированию системы. Возможно, решение сложных проблем упростится, если вы будете придерживаться дисциплины последовательного продвижения к решению с использованием описанных методов и утилит. Если вы встретите затруднения, то всегда можете обратиться к моим руководствам, в которых описано более тридцати утилит и скриптов, которые могут помочь вам в путешествии в самое сердце системы. На этом все.

Моя основная работа — это, по большей части, развертывание систем ПО, то есть уйму времени я трачу, пытаясь ответить на такие вот вопросы:
- У разработчика это ПО работает, а у меня нет. Почему?
- Вчера это ПО у меня работало, а сегодня нет. Почему?
Это — своего рода отладка, которая немного отличается от обычной отладки ПО. Обычная отладка — это про логику кода, а вот отладка развертывания — это про взаимодействие кода и среды. Даже если корень проблемы — логическая ошибка, тот факт, что на одной машине все работает, а на другой — нет, означает, что дело неким образом в среде.
Поэтому вместо обычных инструментов для отладки вроде gdb у меня есть другой набор инструментов для отладки развертывания. И мой любимый инструмент для борьбы с проблемой типа "Почему это ПО у меня не пашет?" называется strace.
Что же такое strace?
strace — это инструмент для "трассировки системного вызова". Изначально создавался под Linux, но те же фишки по отладке можно проворачивать и с инструментами для других систем (DTrace или ktrace).
Основное применение очень просто. Надо лишь запустить strace c любой командой и он отправит в дамп все системные вызовы (правда, сперва, наверное, придется установить сам strace):
Что это за системные вызовы? Это нечто вроде API для ядра операционной системы. Давным-давно у ПО был прямой доступ к "железу", на котором оно работало. Если, например, нужно было отобразить что-нибудь на экране, оно играло с портами и\или отображаемыми в память регистрами для видео-устройств. Когда стали популярны многозадачные компьютерные системы, воцарился хаос, потому что различные приложения дрались за "железо". Ошибки в одном приложении могли обрушить работу прочих, если не всю систему целиком. Тогда в ЦПУ появились режимы привилегий (или "кольцевая защита"). Самым привилегированным становилось ядро: оно получало полный доступ к "железу", плодя менее привилегированные приложения, которым уже приходилось запрашивать доступ у ядра для взаимодействия с "железом" — через системные вызовы.
На бинарном уровне системный вызов немного отличается от простого вызова функции, однако большинство программ используют обертку в стандартной библиотеке. Т.е. стандартная библиотека POSIX C содержит вызов функции write(), которая содержит весь зависящий от архитектуры код для системного вызова write.

Если вкратце, то любое взаимодействие приложения со своей средой (компьютерными системами) осуществляется через системные вызовы. Поэтому когда ПО на одно машине работает, а на другой нет, хорошо бы заглянуть в результаты трассировки системных вызовов. Если же конкретнее, то вот вам список типичных моментов, которые можно проанализировать при помощи трассировки системного вызова:
- Консольный ввод-вывод
- Сетевой ввод-вывод
- Доступ к файловой системе и файловый ввод-вывод
- Управление сроком жизни процесса\потока
- Низкоуровневое управление памятью
- Доступ к драйверам особых устройств
Когда использовать strace?
В теории, strace используется с любыми программами в пользовательском пространстве, ведь любая программа в пользовательском пространстве должна делать системные вызовы. Он эффективнее работает с компилируемыми, низкоуровневыми программами, но и с высокоуровневыми языками вроде Python тоже работает, если получится продраться через дополнительный шум от среды исполнения и интерпретатора.
Для примера берем работу на изолированном сервере, но трассировку системных вызовов зачастую можно выполнить и на более сложных платформах развертывания. Просто надо подобрать подходящий инструментарий.
Пример простой отладки
Скажем, хотите вы запустить потрясающее серверное приложение foo, а получается вот что:
Если есть доступ к исходному коду, можно прочесть его и все выяснить. Хороший запасной план, но не самое быстрое решение. Можно прибегнуть к пошаговому отладчику вроде gdb и посмотреть, что делает программа, но куда эффективнее использовать инструмент, который специально спроектирован показывать взаимодействие со средой: strace.
Это был просто пример, но я бы сказал, что 90% времени, что я пользуюсь strace, ничего сильно сложнее этого выполнять и не приходится. Ниже — полное пошаговое руководство по отладке:
Весьма вероятно, что системный вызов в 4-м шаге покажет, что пошло не так.
Подсказки
Прежде чем показать пример более сложной отладки, открою вам несколько приемов для эффективного использования strace:
man — ваш друг
На многих *nix системах полный список системных вызовов к ядру можно получить, запустив man syscalls. Вы увидите вещи вроде brk(2), а значит, больше информации можно получить, запустив man 2 brk.
Небольшие грабли: man 2 fork показывает мне страницу для оболочки fork() в GNU libc, которая, оказывается, которая реализована с помощью вызова clone(). Семантика вызова fork остается той же, если написать программу, использующую fork(), и запустить трассировку — я не найду вызовов fork, вместо них будут clone(). Такие вот грабли только путают, если начать сравнивать исходник с выводом strace.
Используйте -о, чтобы сохранить вывод в файл
strace может сгенерировать обширный вывод, так что зачастую полезно хранить результаты трассировки в отдельных файлах (как в приведенном выше примере). А еще это помогает не спутать программный вывод с выводом strace в консоли.
Используйте -s, чтобы просмотреть больше данных аргумента
-у облегчает отслеживание файлов\сокетов\и проч.
"Все — файл" означает, что *nix системы выполняют все вводы-выводы, используя файловые дескрипторы, применимо ли именно к файлу или сети, или межпроцессным каналам. Это удобно для программирования, но мешает следить за тем, что происходит на самом деле, когда видите общие read и write в результатах трассировки системного вызова.
Добавив оператор -у, вы заставите strace аннотировать каждый файловый дескриптор в выводе с примечанием, на что он указывает.
Прикрепите к уже запущенному процессу с -p**
Как будет видно из приведенного ниже примера, иногда нужно производить трассировку программы, которая уже запущена. Если известно, что она запущена как процесс 1337 (скажем, из выводов ps), то можно осуществить трассировку ее вот так:
Возможно, вам нужны root-права.
Используйте -f, чтобы следить за дочерними процессами
strace по умолчанию трассирует всего один процесс. Если же этот процесс порождает дочерние процессы, то можно увидеть системный вызов для порождения дочернего процесса, но системные вызовы дочернего процесса не будут отображены.
Фильтруйте трассировку при помощи -e
Как видите, результат трассировки — реальная куча всех возможных системных вызовов. Флагом -e можно отфильтровать трассировку (см. руководство по strace). Главное преимущество в том, что запускать трассировку с фильтрацией быстрее, чем делать полную трассировку, а потом grep`ать. Если честно, то мне почти всегда пофиг.
Не все ошибки плохи
Простой и распространенный пример — программа, ищущая файл сразу в нескольких местах, вроде оболочки, ищущей, в которой корзине\каталоге содержится исполняемый файл:
Понять системные вызовы хорошо помогают руководства по программированию на языке С
Стандартные вызовы к библиотекам С — не системные вызовы, но лишь тонкий поверхностный слой. Так что, если вы хоть немного понимаете, как и что делать в С, вам будет легче разобраться в результатах трассировки системного вызова. Например, у вас беда с отладкой вызовов к сетевым системам, просмотрите то же классическое "Руководство по сетевому программированию" Биджа.
Пример отладки посложнее
Я уже говорил, что пример простой отладки — это пример того, с чем мне, по большей части, приходится иметь дело в работе со strace. Однако порой требуется настоящее расследование, так что вот вам реальный пример отладки посложнее.
bcron — планировщик обработки задач, еще одна реализация демона *nix cron. Он установлен на сервере, но когда кто-то пытается редактировать расписание, происходит вот что:
Ладненько, значит, bcron попытался написать некий файл, но у него не вышло, и он не признается почему. Расчехляем strace:
Если посмотреть на man 2 read, то можно увидеть, что первый аргумент (3) — это файловый дескриптор, который *nix и использует для всех обработок ввода-вывода. Как узнать, что представляет файловый дескриптор 3? В данном конкретном случае можно запустить strace с оператором -у (см. выше), и он автоматически расскажет, однако, чтобы вычислять подобные штуки, полезно знать, как читать и анализировать результаты трассировки.
Источником файлового дескриптора может быть один из многих системных вызовов (все зависит от того, для чего дескриптор — для консоли, сетевого сокета, собственно файла или чего-то иного), но как бы там ни было, вызовы мы ищем, возвращая 3 (т.е. ищем "= 3" в результатах трассировки). В этом результате их 2: openat в самом верху и socket в середине. openat открывает файл, но close(3) после этого покажет, что он закрывается снова. (Грабли: файловые дескрипторы могут использоваться заново, когда их открывают и закрывают). Вызов socket() подходит, поскольку он последний перед read(), и получается, что bcrontab работает с чем-то через сокет. Следующая строка показывает, что файловый дескриптор связан с unix domain socket по пути /var/run/bcron-spool.
Итак, надо найти процесс, привязанный к unix socket с другой стороны. Для этой цели есть парочка изящных трюков, и оба пригодятся для отладки серверных развертываний. Первый — использовать netstat или более новый ss (socket status). Обе команды показывают активные сетевые соединения системы и берут оператор -l для описания слушающих сокетов, а также оператор -p для отображения программ, подключенных к сокету в качестве клиента. (Полезных опций намного больше, но для этой задачи достаточно и этих двух.)
Это говорит о том, что слушающий — это команда inixserver, работающая с ID процесса 20629. (И, по совпадению, она использует файловый дескриптор 3 в качестве сокета.)
Второй реально полезный инструмент для нахождения той же информации называется lsof. Он перечисляет все октрытые файлы (или файловые дескрипторы) в системе. Или же можно получить информацию об одном конкретном файле:
Процесс 20629 — это долгоживущий сервер, так что можно прикрепить к нему strace при помощи чего-то вроде strace -o /tmp/trace -p 20629. Если редактировать задание cron в другом терминале — получим вывод результатов трассировки с возникающей ошибкой. А вот и результат:
Вот, это уже кое-что. Процесс 21470 получает ошибку "отказано в доступе" при попытке создать файл по пути tmp/spool.21470.1573692319.854640 (относящийся к текущему рабочему каталогу). Если бы мы просто знали текущий рабочий каталог, мы бы знали и полный путь и смогли выяснили, почему процесс не может создать в нем свой временный файл. К несчастью, процесс уже вышел, поэтому не получится просто использовать lsof -p 21470 для того, чтобы найти текущий каталог, но можно поработать в обратную сторону — поискать системные вызовы PID 21470, меняющие каталог. (Если таких нет, PID 21470, должно быть, унаследовали их от родителя, и это уже через lsof -p не выяснить.) Этот системный вызов — chdir (что несложно выяснить при помощи современных сетевых поисковых движков). А вот и результат обратных поисков по результатам трассировки, до самого сервера PID 20629:
(Если теряетесь, то вам, возможно, стоит прочесть мой предыдущий пост об управлении процессом *nix и оболочках.) Итак, сервер PID 20629 не получил разрешения создать файл по пути /var/spool/cron/tmp/spool.21470.1573692319.854640. Вероятнее всего, причиной тому — классические настройки разрешений файловой системы. Проверим:
Итого
Начинающему в результатах трассировки системных вызовов можно утонуть, но я, надеюсь, показал, что они — быстрый способ отладки целого класса распространенных проблем с развертыванием. Представьте, как пытаетесь отладить многопроцессный bcron, используя пошаговый отладчик.
Разбор результатов трассировки в обратном порядке вдоль цепочки системных вызовов требует навыка, но как я уже говорил, почти всегда, пользуясь strace, я просто получаю результат трассировки и ищу ошибки, начиная с конца. В любом случае, strace помогает мне сэкономить уйму времени на отладке. Надеюсь, и вам он тоже будет полезен.
Программы Linux просят ядро сделать за них кое-что. Команда strace показывает эти системные вызовы. Вы можете использовать их, чтобы понять, как работают программы и почему иногда нет.
Ядро и системные вызовы
Возможность видеть системные вызовы, выполненные программой, и их ответы может помочь вам понять внутреннюю работу программ, которые вас интересуют или которые вы написали. Это что делает Strace. Это может помочь в устранении неполадок и поиске узких мест.
Это не то же самое, что отладка приложения с помощью такого инструмента, как gdb. Программа отладки позволяет вам исследовать внутреннюю работу программы во время ее выполнения. Он позволяет вам выполнять логику вашей программы и проверять память и значения переменных. Для сравнения, strace собирает информацию о системных вызовах во время работы программы. Когда отслеживаемая программа завершается, strace выводит информацию о системном вызове в окно терминала.
Системные вызовы предоставляют всевозможные низкоуровневые функции, такие как операции чтения и записи в файлах, завершающие процессы и т. Д. Есть список из сотен системных вызовов на страница руководства по системным вызовам.
Установка strace
Если strace еще не установлен на вашем компьютере, вы можете легко установить его.
В Ubuntu используйте эту команду:
sudo apt install strace

В Fedora введите эту команду:
sudo dnf установить strace

На Манджаро команда:
sudo pacman -Sy strace

Первые шаги со strace
Мы воспользуемся небольшой программой, чтобы продемонстрировать strace. Он мало что делает: открывает файл и записывает в него строку текста, и в нем нет проверки на ошибки. Это просто быстрый взлом, чтобы у нас было что использовать со strace.
Мы сохранили это в файле под названием «file-io.c» и скомпилировали его с помощью gcc в исполняемый файл под названием stex, названный в честь «strace example».
gcc -o stex файл-io.c
Мы вызовем strace из командной строки и передадим ему имя нашего нового исполняемого файла в качестве процесса, который мы хотим отслеживать. Мы могли так же легко отследить любую команду Linux или любой другой исполняемый файл. Мы используем нашу крошечную программу по двум причинам.
Первая причина в том, что strace многословен. Выхода может быть много. Это здорово, когда вы используете strace в гневе, но поначалу это может ошеломить. Наша крошечная программа имеет ограниченный вывод strace. Вторая причина в том, что наша программа имеет ограниченную функциональность, а исходный код краток и понятен. Это упрощает определение того, какие разделы вывода относятся к различным частям внутренней работы программы.

Мы ясно видим, как системный вызов write отправляет текст «Write this to the file» в наш открытый файл и системный вызов exit_group. Это завершает все потоки в приложении и отправляет возвращаемое значение обратно в оболочку.

Фильтрация вывода
Даже с нашей простой демонстрационной программой получается довольно много результатов. Мы можем использовать параметр -e (выражение). Мы передадим имя системного вызова, который хотим видеть.
strace -e написать ./stex

Вы можете сообщить о нескольких системных вызовах, добавив их в виде списка, разделенного запятыми. Не включайте пробелы в список системных вызовов.
strace -e закрыть, написать ./stex

Отправка вывода в файл
Преимуществом фильтрации вывода является также проблема с фильтрацией вывода. Вы видите то, что просили увидеть, но больше ничего не видите. И некоторые из этих других результатов могут быть для вас более полезны, чем то, что вы просили показать.
Иногда удобнее фиксировать все, искать и прокручивать весь набор результатов. Так вы случайно не исключите ничего важного. Параметр -o (вывод) позволяет отправлять вывод из сеанса strace в текстовый файл.
strace -o трассировка-output.txt ./stex


Теперь вы можете использовать все возможности поиска less для исследования результатов.

Добавление меток времени
Вы можете добавить к выводу несколько разных отметок времени. Параметр -r (относительные отметки времени) добавляет отметки времени, которые показывают разницу во времени между началом каждого последующего системного вызова. Обратите внимание, что эти значения времени будут включать время, потраченное на предыдущий системный вызов, и все остальное, что программа делала до следующего системного вызова.

Метки времени отображаются в начале каждой строки вывода.

Чтобы увидеть количество времени, затраченного на каждый системный вызов, используйте параметр -T (syscall-times). Это показывает продолжительность времени, проведенного внутри каждого системного вызова.

Продолжительность времени отображается в конце каждой строки системного вызова.

Чтобы увидеть время, в которое был вызван каждый системный вызов, используйте параметр -tt (абсолютные отметки времени). Это показывает время «настенных часов» с разрешением в микросекунды.

Время отображается в начале каждой строки.

Отслеживание запущенного процесса
Если процесс, который вы хотите отследить, уже запущен, вы все равно можете прикрепить к нему strace. Для этого вам нужно знать идентификатор процесса. Вы можете использовать ps с grep, чтобы найти это. У нас работает Firefox. Чтобы узнать идентификатор процесса firefox, мы можем использовать ps и передать его через grep.
ps -e | grep firefox

sudo strace -p 8483

Вы увидите уведомление о том, что strace подключился к процессу, а затем вызовы системной трассировки будут отображаться в окне терминала, как обычно.

Создание отчета
Параметр -c (только сводка) заставляет strace печатать отчет. Он генерирует таблицу для информации о системных вызовах, сделанных отслеживаемой программой.

- % времени: процент времени выполнения, затраченный на каждый системный вызов.
- секунды: общее время, выраженное в секундах и микросекундах, затраченное на каждый системный вызов.
- usecs / call: среднее время в микросекундах, затраченное на каждый системный вызов.
- calls: количество раз, когда был выполнен каждый системный вызов.
- ошибки: количество сбоев для каждого системного вызова.
- syscall: имя системного вызова.
В этих значениях будут отображаться нули для тривиальных программ, которые быстро выполняются и завершаются. Реальные значения показаны для программ, которые делают что-то более значимое, чем наше демонстрационное приложение.
Глубокое понимание, легко
Вывод strace может показать вам, какие системные вызовы выполняются, какие выполняются повторно, и сколько времени выполняется внутри кода на стороне ядра. Это отличная информация. Часто, когда вы пытаетесь понять, что происходит внутри вашего кода, легко забыть, что ваш двоичный файл почти безостановочно взаимодействует с ядром для выполнения многих его функций.
До сих пор я представлял вам некий код и инструкции, как его скомпилировать и выполнить. Вероятно, до этого момента вам нужны были только редактор (emacs, vi, …) и компилятор (gcc). Тем не менее, существует ещё множество других утилит, облегчающих разработку кода (ведь разработка это не только набор исходного когда, а также компиляция, тестирование, и прочее). Есть даже IDE (интегрированные среды разработки), комбинирующие некоторые из этих утилит в красивый графический интерфейс (например CDT для Eclipse, kdevelop, Code::blocks, anjuta, и другие), но, по моему мнению, начинающий программист должен иметь представление о том, как они работают, изнутри, прежде чем он начнёт использовать горячие клавиши. Несмотря на существование большого количества утилит, покрывающих множество категорий, в этой статье мы сфокусируемся на поиске и устранении ошибок в коде/приложении.
strace and ltrace
strace - один из моих лучших друзей. ltrace - также отличный инструмент, но я нечасто им пользуюсь. Вы можете установить их, набрав:
который показан на Схеме 1, то увидим во время выполнения несколько интересных частей:
Разве это не прекрасно? Мы изучили внутреннее устройство приложения, не взглянув ни на одну строчку кода; тут же мы узнали где оно хранит свои файлы конфигурации, один из которых не существует, и как оно перевело запись DNS в ip-адрес. ltrace работает подобным образом, но, вместо трассировки системных вызовов, показывает, какие функции вызывались и какие из них находятся в динамически связанных библиотеках (Схема 3):
ldd говорит нам, что wget использует среди прочих libssl (безопасные соединения), libpthread (для создания потоков), libz (сжатие), и libc. Libc по существу является основой вашей системы. Она реализует основные функции С, такие как printf(), malloc(), и free(), часто связывая их с системными вызовами (например, printf() с write()). Теперь ltrace расскажет нам, где наше приложение использует функции, предоставляемые библиотеками. Итак, если мы рассмотрим вывод:
Valgrind
Valgrind можно установить, набрав:
Листинг 1:
Посмотрите на листинг 1. Это пример плохого кода. Происходит вызов функции leak() (строки 3-7) 10 раз, которая выделяет 10 байтов и не освобождает их. Затем выделяется некоторое количество памяти в функции main, и выполнение переходит в бесконечный цикл. Во-первых, я хочу, чтобы перед запуском кода вы заменили цикл for на while(1), и malloc(10) на malloc(1000). Запустив приложение, вы увидите что произойдёт с вашей системой. Ваша физическая память заполнится, затем будет заполнен своп, и, в конечном счёте, oom_killer (служба завершения процессов, пожирающих всю память) закроет раздобревший процесс. Такие вещи являются разрушительными для системы и для её производительности. Вы только что наблюдали эффект утечки памяти. Проблемная особенность динамического запроса памяти - память всегда нужно возвращать обратно! Это пример утечки памяти «в ускоренном воспроизведении». Некоторые приложения, которые теряют несколько байт в час, могут идеально работать годами - прежде чем всё упадет к чёртовой бабушке. Вот почему valgrind очень полезен. Вот вывод Листинга 1 на моей системе после компиляции:
Вывод на Схеме 4:
Когда я прерываю цикл while(1) нажав ctrl+c, он мне сообщает сколько вызовов malloc() я сделал, сколько памяти я получил, и сколько вернул обратно. В итоге делается вывод, что я потерял 100 байт памяти в 10 блоках. Это значит, что я запрашивал память, которая теперь мне недоступна, потому что у меня нет на неё указателя (в выводе: «definitely lost”), а также, что я получил 15 байт в одном блоке, который, на момент завершения, всё ещё могу освободить, потому что у меня есть на него указатель. Вот почему я написал цикл while(1). Если бы я этого не сделал, valgrind сообщил бы, что я потерял 115 байт в 11 блоках (проверьте это!), потому что valgrind ведёт учёт того, что в действительности произошло; он не смотрит в будущее для того, чтобы узнать, что может произойти в системе. Ещё одна вещь, о которой стоит упомянуть: я говорил, что cкомпилировал код с ключом »-g«, который добавляет отладочную информацию в исполняемый файл. Вот откуда valgrind знает, в каком файле и на какой строке произошла ошибка. Если скомпилировать следующим образом:
то вывод будет выглядеть так:
Он по-прежнему говорит нам, что происходит утечка памяти, но уже не сообщает, в каком файле и в какой строке что-то идёт не так. Итак, хорошая новость - valgrind сообщает нам, есть утечки памяти или нет. Плохая новость - нам нужен исполняемый файл с отладочной информацией, если мы хотим локализовать утечку. Мы можем перекомпилировать исполняемый файл для поиска и устранения неисправностей - для этого нам нужен исходный код!
Выводы
В этой статье я рассказал об утилитах, позволяющих легко найти и устранить неисправности в исполняемых файлах, без необходимости иметь их исходники или дополнительные знания о файлах. В следующий раз мы попытаемся немножко углубиться и затем посмотрим на настоящий отладчик.
Читайте также: