
Debian quagga ospf настройка
Обновлено: 02.07.2024
OpenVPN достаточно хорошо документирован и на хабре есть статьи по установке, к примеру:
вот эта.
Но так, чтобы сразу несколько тоннелей, между двумя серверами и автоматической отказоустойчивостью не нашел. В моем случае, серверы на которых будет располагаться OpenVPN и OSPF оба находятся за NATом. Это несколько усложняет решение, но в основном тем, что потребуется управлять трафиком, уходящим с интерфейсов пограничного маршрутизатора.
Два пограничных маршрутизатора Centos 7:
r01:
ens0 1.1.1.1 – провайдер 1
ens1 2.2.2.2 – провайдер 2
ens2 10.0.0.1 – виртуальная сеть между шлюзом и OpenVPN сервером.
r02:
ens0 3.3.3.3 – провайдер 3
ens1 4.4.4.4 – провайдер 4
ens2 10.1.1.1 – виртуальная сеть между шлюзом и OpenVPN сервером.
Два OpenVPN/OSPF сервера Centos 7:
host01:
ens0 10.0.0.2 – SNAT через сеть провайдер 1.
ens0 10.0.0.3 – SNAT через сеть провайдер 2.
ens1 192.168.0.0/23 – локальная сеть.
host02:
ens0 10.1.1.2 – SNAT через сеть провайдер 3.
ens0 10.1.1.3 – SNAT через сеть провайдер 4.
ens1 192.168.4.0/23 – локальная сеть.
Все провайдеры в данной схеме разные, имеют разную скорость, стоимость.
Задача:
Создать 4 тоннеля между host01 и host02 так, чтобы они были всегда активны и в случае падения любого из провайдеров, маршрут должен переключаться на более медленный или дорогой канал. Даже если выйдут из строя оба провайдера (по одному на каждом сервере), канал также должен функционировать. В то же время, если более предпочтительный канал заработает – серверу придется перейти на него.
В этой статье я не буду подробно описывать процесс генерации ключей, установки OpenVPN, Quagga. Скажу лишь, что генерировать ключи для сервера и клиента достаточно один раз, так как можно использовать DH и все прочие ключи и сертификаты для всех инстансов одновременно. Но, конечно, если вы очень озабочены безопасностью – можно сгенерировать по два сертификата под каждый тоннель. В моем случае, был один сертификат на серверные службы и один на клиентские.
Установка:
Система CentOS Linux release 7.4.1708 (Core) / 3.10.0-693.5.2.el7.x86_64.
yum install openvpn easy-rsa quagga
версии ПО, которые были использованы:
Настройка:
Для тоннелей выбраны следующие порты:
udp 1150 – 1.1.1.1-3.3.3.3
udp 1151 – 2.2.2.2-4.4.4.4
udp 1152 – 1.1.1.1-4.4.4.4
udp 1153 – 2.2.2.2-3.3.3.3
Следует обратить внимание, что OpenVPN требует чтобы порт, с которого сервер и клиент отправляют пакеты был таким же как и порт приема пакетов, при использовании NAT порт исходящего пакета может отличаться и тоннель не поднимется с такой ошибкой:
TCP/UDP: Incoming packet rejected from [AF_INET]1.1.1.1:1194[2], expected peer address: [AF_INET]1.1.1.1:2364 (allow this incoming source address/port by removing --remote or adding --float)
Чтобы порт точно был всегда верным надо настроить пограничный маршрутизатор и OpenVPN сервер:
В свою очередь на пограничном маршрутизаторе будет так (r01):
Далее настроим туннели, приведу конфиг одной пары клиент/сервер, остальные настраиваются также, просто меняется порт, адреса и номер tun интерфейса.
Важный параметр в конфигурации тоннеля topology subnet, он позволяет сделать адресацию тоннеля так, чтобы он выглядел как подсеть и не интерфейс точка-точка. Параметр не является параметром по умолчанию и рекомендуется для современных серверов. Без него нет возможности обмениваться широковещательными пакетами внутри тоннеля, тем самым не будет возможности настроить OSPF.
При поднятии тоннеля ifconfig на сервере и клиенте будет выглядеть так:
После того, как все 4 тоннеля подняты, получается такая картина.
udp 1150 – 1.1.1.1-3.3.3.3 – tun1 – 10.10.11.1-10.10.11.2
udp 1151 – 2.2.2.2-4.4.4.4 – tun2 – 10.10.12.1-10.10.12.2
udp 1152 – 1.1.1.1-4.4.4.4 – tun3 – 10.10.15.1-10.10.15.2
udp 1153 – 2.2.2.2-3.3.3.3 – tun4 – 10.10.16.1-10.10.16.2
Никаких дополнительных статических маршрутов добавлять не требуется, кроме добавления правил сетевого экрана:
Отказоустойчивость.
Можно добиться переключения маршрутов и с помощью скриптов, но получилось бы громоздкое и совсем не элегантное решение. Ранее мне не доводилось использовать динамическую маршрутизацию на практике. Протоколов довольно много, остановился я на OSPF, по большому счету, потому, что информации и способов применения нашел больше. Протокол linkstate типа, учитывает состояние каналов, интерфейсов и обменивается ею. Думаю, что вполне можно реализовать подобное на BGP или RIP. С радостью бы посмотрел на BGP версию решения.
Чтобы OSPF мог получать и отправлять служебные пакеты LSA – Link State Advertisement потребуется открыть порты на сетевом экране:
Перейдем к настройке Quagga.
Для начала надо убедиться что папки и файлы, фигурирующие в работе служб Quagga принадлежали пользователю под которым служба запускается:
После этого можно начать конфигурировать OSPF.
В консоль можно попасть двумя способами, telnet или vtysh, я выбрал второе.
Лучше сразу же попробовать сделать write, чтобы проверить права на файлы конфигурации, иначе все команды, которые вы введете не сохранятся, должно получиться так:
Проверьте, все ли ваши интерфейсы доступны для zebra.
Если маршрутизируемые через OSPF сети и все tun интерфейсы на месте, можно продолжать.
Прежде всего, необходимо настроить стоимость туннелей, чем меньше стоимость, тем приоритетнее туннель. Сделать это можно так:
И далее для других tun2 30, tun3 15, tun4 20 в моем случае.
После чего можно запускать маршрутизатор:
В данной конфигурации используется параметр redistribute connected для того, чтобы анонсировать не все маршруты на другой сервер, а только нужные, а параметр route-map LAN позволяет фильтровать сети.
Точно такая же конфигурация должна быть и с другой стороны тоннеля. После активации службы ospfd примерно через 10 секунд на обоих серверах появятся маршруты соседей и тоннель будет выбран согласно стоимости. В случае, если предпочитаемый тоннель перестанет работать, автоматически произойдет переключение на другой тоннель и так далее, пока тоннелей не останется. И также, если более удачный интерфейс снова будет активирован – маршрутизация пойдет по нему.
Примерное время обновления маршрутов 10 секунд, можно варьировать параметры ip ospf hello-interval и ip ospf dead-interval для сокращения этого времени.
Не забудьте добавить все службы в автозагрузку, к примеру мои файлы конфигурации OpenVPN называются srv-1050.conf и cli-1050.conf, в этом случае команды будут выглядеть так:
В продолжение статей про устройство таблицы маршрутизации и про реализацию протокола BGP в Quagga, в настоящей статье я разберу как работает протокол OSPF. Я ограничусь случаем для одной OSPF зоны без редистрибъюции маршрутов из других протоколов маршрутизации.
Как обычно, я не стану подробно описывать работу и настройку протокола OSPF, и сошлюсь где можно более подробно про него почитать. Ограничусь лишь наиболее важными для дальнейшего понимания статьи сведениями.
В отличие от протоколов RIP или BGP, которые сравнивают пришедшие маршруты от разных соседей и выбирают лучшие из них по каким-либо критериям, протокол OSPF строит топологическую карту сети и прокладывает по ней кратчайшие маршруты до соответствующих ip-сетей. Чтобы собрать информацию о топологии сети, маршрутизаторы обмениваются между собой кусочками информации о directly connected сетях и своих соседях OSPF. Данные кусочки топологической информации называются LSA (Link State Advertisement) и из них, как пазл, можно собрать полную топологическую карту сети. Как устроены LSA мы рассмотрим чуть позже, а сейчас перейдем к алгоритму нахождения кратчайшего пути.
Для нахождения кратчайшего пути используется алгоритм Дейкстры, работу которого рассмотрим на следующем примере. У нас имеется пять маршрутизаторов, соединенных между собой линками, как показано на рисунке:

R1 является корневым маршрутизатором, на котором выполняется алгоритм нахождения кратчайшего пути. Цифры на линках показывают стоимость (cost) данного линка. Задача состоит в том, чтобы найти от маршрутизатора R1 до каждого из остальных маршрутизаторов кратчайший путь, т.е. путь у которого суммарная стоимость линков минимальна.
В результате для каждого маршрутизатора мы должны вычислить две вещи:
- Стоимость пути от R1 до данного маршрутизатора.
- Какой next-hop использует R1, чтобы достичь данный маршрутизатор.
Таким образом, на начальном этапе мы имеем кратчайший путь только до самого маршрутизатора R1, равный 0. До остальных маршрутизаторов стоимости равны бесконечности, а next-hop неизвестны.
Сейчас мы будем делать последовательность шагов, каждый из которых будет улучшать стоимость путей до маршрутизаторов, а в конечном счете мы вычислим кратчайшие пути до всех из них.
Шаг 1. Смотрим соседей корневого маршрутизатора.
Соседями корневого маршрутизатора R1 являются маршрутизаторы R2 и R3. Для каждого из них устанавливаем стоимость пути равным стоимости соответствующего линка и next-hop равным самому маршрутизатору R2 или R3, как показано на рисунке:
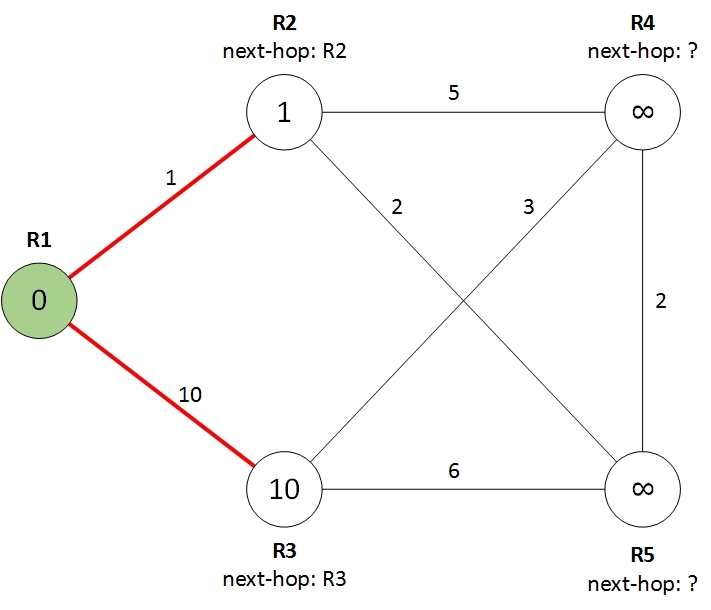
Шаг 2. Выбираем лучшего из оставшихся.
На данном шаге мы смотрим все оставшиеся маршрутизаторы, т.е. маршрутизаторы до которых кратчайший путь еще не найден (белого цвета) и выбираем из них маршрутизатор с наименьшей стоимостью пути до него. В нашем случае это маршрутизатор R2 со стоимостью 1. Этот маршрутизатор мы смело можем перекрасить в зеленый цвет, более короткого пути для него не существует.

На рисунке он покрашен в более темный зеленый цвет, поскольку этот маршрутизатор пригодится нам на шаге 3.
Шаг 3. Смотрим на соседей выбранного маршрутизатора.
Этот шаг похож на шаг 1, только вместо маршрутизатора R1 мы смотрим на соседей выбранного на предыдущем этапе темно-зеленого маршрутизатора. Для каждого соседа мы вычисляем стоимость пути через выбранный маршрутизатор. Если стоимость такого пути получается меньше, чем текущая стоимость, то соседу присваиваем новую стоимость, а next-hop просто копируем от выбранного маршрутизатора. Получается такая картина:

Теперь повторяем шаги 2 и 3 до тех пор, пока все маршрутизаторы не станут зелеными. На этапе 2 у нас один маршрутизатор обязательно зеленеет, так что такой процесс рано или поздно закончится.
Итак, выбираем лучший из оставшихся, перекрашиваем в зеленый цвет (маршрутизатор R5):

Смотрим на соседей выбранного маршрутизатора, улучшаем стоимости, копируем next-hop:

Видно, что у R3 сменился next-hop, который был скопирован от R5. Выбираем лучшего:
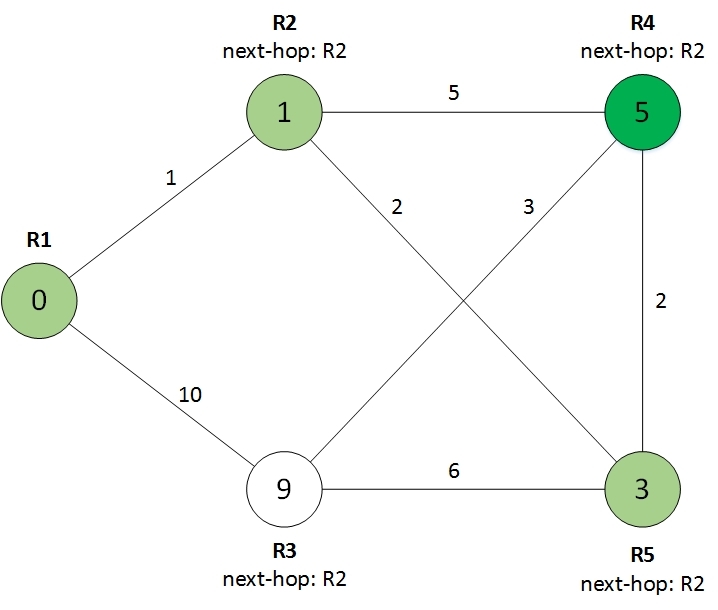
Смотрим на оставшегося соседа:

И получаем окончательный результат:

Теперь у нас есть стоимости путей до каждого из маршрутизаторов, а также какие next-hop использовать на корневом маршрутизаторе для их достижения. Т.е. мы практически готовы составить таблицу маршрутизации. Однако для непосредственного применения в сетях рассмотренный выше алгоритм требует некоторой модернизации.
Вышеописанный алгоритм работает только с линками типа точка-точка, когда каждый линк соединяет два маршрутизатора. Реальные же маршрутизаторы, могут подключаться между собой через сеть Ethernet, которая допускает подключения к одному сегменту более 2-х маршрутизаторов, как показано на рисунке.
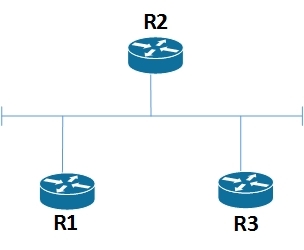
В протоколе OSPF такая сеть называется транзитной. Для решения данной проблемы в OSPF каждая транзитная сеть представляется отдельным узлом в графе. Т.е. при вычислении кратчайшего пути топология будет выглядеть так:

Узел N1 как раз и обозначает транзитную сеть. Теперь у нас каждый линк соединяет только два узла и можно применять алгоритм нахождения кратчайшего пути. При расчете стоимости пути учитывается только стоимость линка от маршрутизатора до транзитной сети, а от транзитной сети до маршрутизатора она считается равной 0.
Поскольку транзитная сеть является логическим объектом, то какой-то из маршрутизаторов должен взять на себя обязанность по созданию необходимой топологической информации, описывающей транзитную сеть. Для этого в OSPF в каждой транзитной сети выбирается Designated Router (DR), который помимо информации о себе также имеет обязанность анонсировать информацию о транзитной сети.
Кроме того, в таблице маршрутизации находятся маршруты не до маршрутизаторов, а до ip-сетей. Вопрос с транзитными сетями решается просто. Поскольку транзитные сети представляются вершинами в графе, то стоимость маршрутов до транзитных сетей вычисляется в процессе работы алгоритма поиска кратчайшего пути. Остальные сети, например, сети к которым подключен только один маршрутизатор OSPF, считаются конечными (stub) сетями и анонсируются маршрутизаторами, к которым они подключены. Зная стоимость кратчайшего пути до каждого маршрутизатора можно легко вычислить и стоимость маршрута до всех подключенных к нему конечных сетей.
Как я уже говорил, для того, чтобы каждый маршрутизатор мог составить топологию сети и применить к ней алгоритм поиска кратчайшего пути, маршрутизаторы обмениваются между собой небольшими кусочками информациями, называемыми Link State Advertisement LSA. LSA бывают разных типов и передают разную информацию. Для нашего случая с единственной зоной важны два типа LSA — LSA тип 1 и LSA тип 2. Каждая LSA тип 1 описывает маршрутизатор. LSA тип 2 описывает транзитную сеть. Если опустить различную служебную информацию, то эти LSA схематично можно представить так:
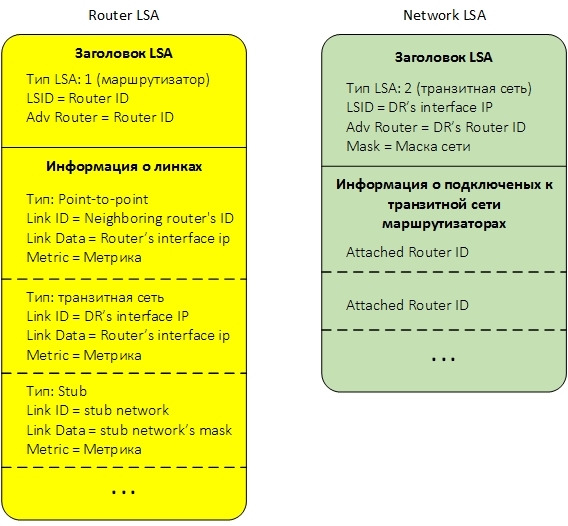
Ниже дано краткое описание полей LSA.
LSA Тип 1 (Router LSA).
В заголовке LSA нам важны три поля:
- Тип. Указывает тип LSA. В нашем случае это тип 1, или Router LSA.
- LSID. Идентификатор LSA. В нашем случае LSID равен Router ID маршрутизатора, который создает LSA.
- Adv Router. Идентификатор маршрутизатора, создавшего LSA. В нашем случае он также равен Router ID маршрутизатора, который создает LSA, т.е. совпадает с LSID.
Транзитная сеть. Для линка данного типа передается следующая информация:
- Link ID — ip-адрес интерфейса Designated Router, подключенного к транзитной сети.
- Link Data — ip-адрес интерфейса самого маршрутизатора, подключенного к транзитной сети.
- Metric — стоимость линка.
- Link ID — ip-адрес интерфейса соседа.
- Link Data — ip-адрес интерфейса самого маршрутизатора.
- Metric — стоимость линка.
- Link ID — собственно ip-адрес сети.
- Link Data — маска сети.
- Metric — стоимость линка.
LSA Тип 2 (Network LSA)
LSA тип 2 передает информацию о транзитной сети и анонсируется специально выбранным для каждой транзитной сети Designated Router.
В заголовке LSA находятся четыре важных поля:
- Тип. В нашем случае это тип 2, или Network LSA.
- LSID. Идентификатор LSA. В нашем случае LSID равен ip-адресу интерфейса Designated Router, подключенного к транзитной сети;
- Adv Router. Идентификатор маршрутизатора, создавшего LSA. В нашем случае он равен Designated Router ID.
- Mask. Маска сети.
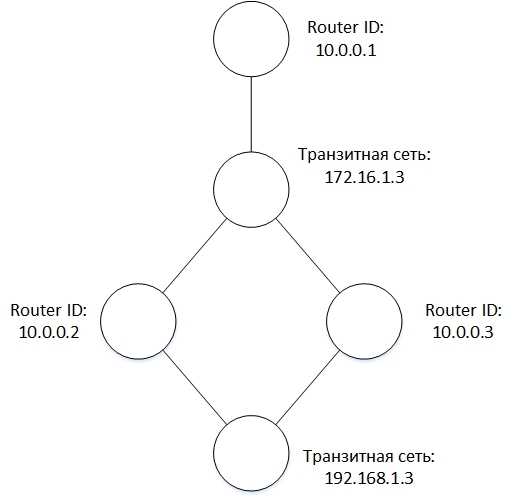
Каждая LSA соответствует узлу графа и, в зависимости от типа, представляет либо маршрутизатор, либо транзитную сеть. Имея все LSA теперь легко создать топологию сети. Для этого достаточно заметить, что Link ID транзитного линка маршрутизатора соответствует LSID транзитной сети, и наоборот, Attached Router ID транзитной сети соответствует LSID подключенного к транзитной сети маршрутизатора.
Для примера на рисунке показана небольшая сеть:
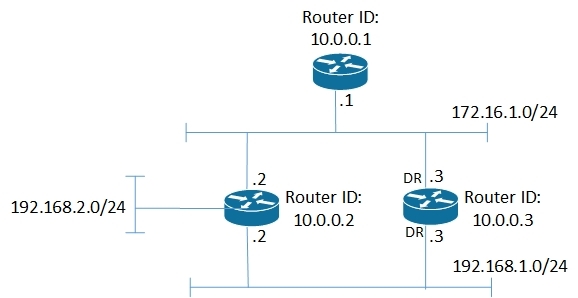
соответствующие ей LSA:
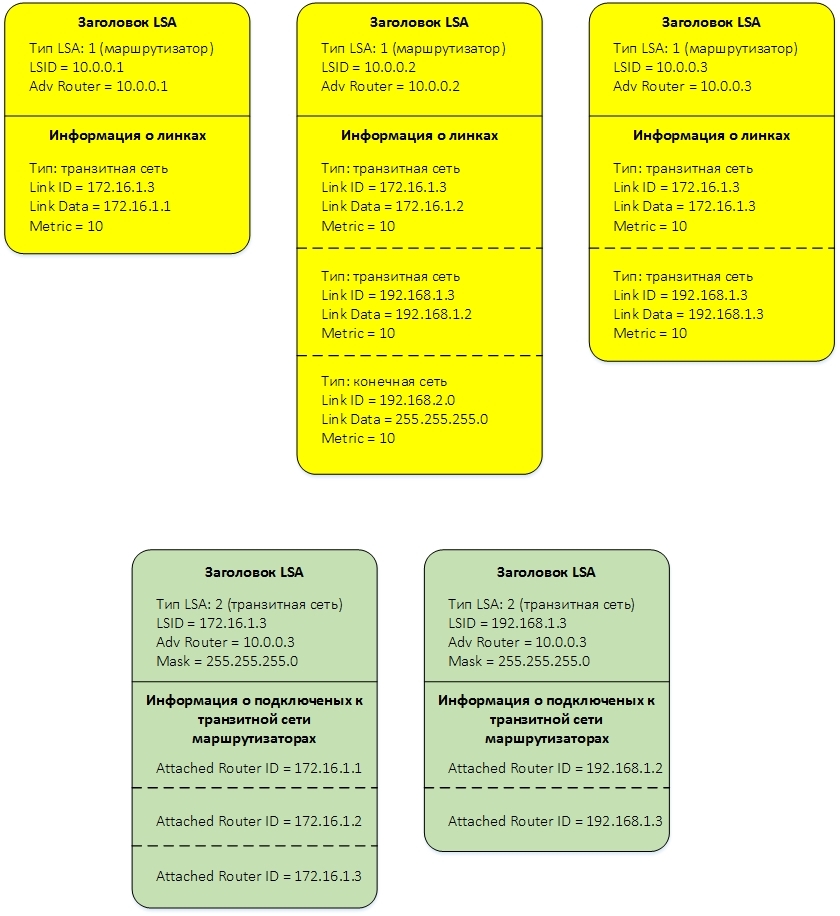
Все созданные и принятые LSA хранятся в базе, называемой LSDB (LSA Database). Основное, что нужно от этой базы – это иметь возможность добавлять в нее LSA, перебирать все LSA определенного типа и искать LSA по ключевым полям из заголовка LSA.
Посмотреть список всех LSA в LSDB и их поля можно при помощи команд show ip ospf database (выводит заголовки всех LSA), show ip ospf database route (выводит полную информацию по LSA тип Router) и show ip ospf database network (выводит полную информацию по LSA тип Network).
В Quagga вся база для хранения LSA (LSDB) разбита на несколько баз, отдельных для каждого типа LSA, как показано на рисунке:

Каждая база для хранения LSA отдельного типа устроена одинаково и хранит содержащиеся в ней LSA в виде описанного в предыдущей статье префиксного дерева. В качестве префикса используется комбинация LSID и Adv Router. Комбинация этих полей уникальна для каждой LSA определенного типа в пределах зоны.
При получении новой LSA данная LSA добавляется в LSDB и запускается процесс вычисления кратчайшего маршрута. Процесс начинается с LSA, соответствующей самому маршрутизатору. На основе содержащейся в ней информации в памяти создается новый узел, соответствующий корневому узлу в топологии. Далее, из LSDB последовательно достаются LSA, соответствующие соседним узлам в топологии, создаются новые узлы и вычисляются кратчайшие пути и next-hop до них, как было описано в алгоритме кратчайшего пути. Параллельно, для обработанных узлов, в таблицу маршрутизации OSPF добавляются маршруты до транзитных сетей.
После окончания построения топологии и вычисления кратчайших путей, просматриваются все узлы, соответствующие маршрутизаторам, и в таблицу маршрутизации OSPF добавляются все их конечные (stub) сети. Маршруты до транзитных сетей в таблицу маршрутизации были уже добавлены ранее.
На последнем этапе все узлы в топологии удаляются из памяти, а маршруты из таблицы маршрутизации OSPF передаются в демон zebra. Схема данного процесса показана на рисунке.

Хочу поделиться удобным способом использования OpenVZ контейнеров. Объект этот очень лёгкий, можно поднимать экземпляр на каждый чих.
По умолчанию для контейнера используется «venet» сетевой интерфейс. Для администратора это выглядит, как просто присвоить контейнеру адрес, и это удобно. Но для того, чтоб контейнер был доступен из сети, следует использовать адреса из той же IP сети, к которой подключён физический сервер (HN). Сервер знает список запущенных на нём контейнеров и отвечает своим MAC-ом на ARP запросы с адресами контейнеров. Но всегда хочется больше удобства в работе, и поможет нам в этом динамическая маршрутизация.
Как именно рассмотрим на примерах, используя Quagga и OSPF.
Для того чтобы такая схема заработала, в сети уже должен работать протокол динамической маршрутизации (OSPF). Однако, если у вас много сетей соединённых более чем одним маршрутизатором, то, скорее всего, динамическая маршрутизация у вас уже настроена.
во-первых, необходимо установить на сервер Quagga: тут всё просто, Quagga входит в стандартную поставку почти всех дистрибутивов,
здесь и далее команды для debian based:
во-вторых, произвести минимальную настройку и запустить:
создать файл /etc/quagga/zebra.conf
создать файл /etc/quagga/ospfd.conf
с такими настройками HN будет искать маршрутизаторы на всех интерфейсах и рассказывать им о всех своих запущеных контейнерах.
проверим, Quagga подключилась к сети и информация о контейнерах распространяется:
если список не пустой, то значит сеседние маршрутизаторы найдены.
Проверим, что информация о контейнерах распространяется кваггой:
получаем два списка с IP адрессами, которые должны совпадать.
Так можно создавать контейнер с любым адресом, и он будет доступен отовсюду.
благодаря этим строчкам, информация будет обновляться быстрее, но нужно соответствующим образом настроить также интерфейсы на маршрутизиторе.
файл /etc/quagga/ospfd.conf:
Информация о контейнерах с адресами из сети в которой находится сервер — не будет распространяться. Действительно, про эту сеть и так всем известно, зачем забивать таблицу маршрутизации лишними записями.
файл /etc/quagga/ospfd.conf:
Какие ещё бонусы можно получить благодаря такой схеме, кроме самомго факта использования любых адресов:
При помощи любого из этих решений можно превратить обычный компьютер в полнофункциональный маршрутизатор. Так как в моем случае установка планировалась на Ubuntu Linux, то OpenBGPD был сразу отброшен. Вариант nx-routed малофункционален и к тому же проект практически заброшен. Остается BIRD и Quagga. В репозитарии Ubuntu Linux доступен лишь второй, но разработчики BIRD предлагают репозитарии и пакеты для Ubuntu/Debian (сборку из исходных текстов конечно же не исключаем). Например, для Ubuntu 9.10 его можно подключить, прописав в /etc/apt/source.list:
Но далее речь пойдет о Quagga.
Установка Quagga в Ubuntu Linux
Проект Quagga основан на коде другого подобного проекта GNU Zebra, который прекратил существование в 2005 году. Нужный пакет доступен в репозитариях большинства дистрибутивов Linux, а также в портах FreeBSD, OpenBSD, NetBSD. Интегрирован Quagga и в OpenSolaris. Чтобы установить Quagga в Ubuntu, достаточно ввести:
После выполнения команды в каталоге /etc/quagga появится два конфигурационных файла. Здесь нужно отметить, что особенностью Quagga является запуск отдельного демона на каждый поддерживаемый протокол, базовое управление осуществляет демон zebra (core daemon), который представляет необходимые API остальным демонам и перестраивает таблицу маршрутизации. Статические маршруты устанавливаются также при помощи демона zebra. Такая схема позволяет при необходимости легко добавить поддержку другого протокола, но наличие нескольких процессов и конфигурационных файлов делает ее менее удобной для управления, ведь изначально команды демонам передаются при помощи telnet. Эту проблему решают при помощи терминала vtysh, который подключаясь к сокету каждого запущенного процесса Quagga выступает в качестве прокси для пользовательских команд.
В файле /etc/quagga/daemons как раз указывается, какие демоны будут загружаться, то есть протоколы будет поддерживать Quagga. По умолчанию все параметры установлены в no, и после установки ничего работать не будет.

Проверяем настройки Quagga
Далее для примера активируем лишь поддержку BGP и OSPF:
Вместо буквенных обозначений предусмотрено и использование цифровых – 0 (отключено), до 1 (высокий приоритет) … 10 (наименьший приоритет).
Список TCP портов, на которых слушают подключения демоны, можно узнать, просмотрев /etc/services:
В Quagga реализовано два способа подачи рабочих параметров демонам – при помощи конфигурационных файлов и напрямую в терминальном режиме (terminal mode), подключившись к нужному порту. Обычно используют оба варианта, загружая начальные параметры при помощи файлов, а при необходимости настройки корректируются на лету. При этом установки в terminal mode также сохраняются в конфигурационные файлы, поэтому при перезагрузке таблица маршрутизации полностью восстанавливается.
Шаблоны файлов настроек демонов находятся в каталоге /usr/share/doc/quagga/examples, переименовываем и копируем их в /etc/quagga:
При установке при помощи пакетов в системе уже создается нужная учетная запись:
Иначе ее необходимо создать вручную. Обязательно изменим владельцев конфигурационных файлов:
Теперь можно запускать Quagga.
Команды “ps aux | grep quagga” и “netstat –ant | grep 260” должны показать, что соответствующие процессы запущены, и демоны слушают свои порты.
Конфигурационные файлы Quagga
Простой конфигурационный файл для настройки BGP выглядит аналогично. Но настройки этого протокола произведем при помощи командной строки.
Управление с консоли
Демоны Quagga поддерживают управление при помощи Cisco подобного синтаксиса. Все команды, введенные в консоли, сохраняются в конфигурационный файл (автоматически и по команде). Подключиться к рабочему демону можно при помощи telnet или vtysh. При использовании консоли vtysh сразу попадаем в режим управления. В случае telnet необходимо два раза ввести пароль.

Список команд виртуальной консоли Quagga
Символ приглашения командной строки должен измениться. Чтобы получить список всех команд, достаточно нажать клавишу со знаком вопроса. Начинаем настройки:
Анонсируем свои сети.
Объявляем соседей, указав IP и номер AS.
Выходим и записываем информацию.
Обратите внимание, что все настройки сохраняются в другой файл, поэтому всегда можно отследить установки сделанные из консоли.
Настройка остальных маршрутизаторов, как по протоколу BGP, так и OSPF производится аналогично. На самом деле параметров можно описать очень много и для каждого протокола будет своя специфика. Так дополнительно можно указать маршруты, которые мы не ходим получать, установить параметры доступа, разные способы анонсирования сетей, community и так далее.
Все команды, вводимые в консоли, вступают сразу в силу, при правке конфигурационных файлов требуется перезапуск Quagga. Теперь можно просмотреть маршруты:
И так далее. Информация в выводе дает возможность разобраться в источнике нового маршрута и используемом при обмене протоколе. Соответственно если отключить один из маршрутизаторов, указание об анонсированных им сетях исчезнет из таблицы.
Таблицу по конкретному протоколу получаем в контексте “show ip”.
Проверяем настройки интерфейсов, конфигурационные данные, статистика использования памяти:
Все довольно просто. Чтобы разобраться, достаточно немного поэкспериментировать.
Проект Quagga в наследство от Zebra получил небольшой CGI скрипт написанный на Perl, реализующий простой веб-интерфейс позволяющий получать информацию о настройках (контекст “show ip”). Найти его можно в каталоге /usr/share/doc/quagga/tools вместе с еще несколькими скриптами. Но все они требуют доработки под свои нужды.
В итоге после относительно небольших настроек при помощи Quagga мы получим сеть маршрутизаторов взаимодействующих между собой строя динамические таблицы маршрутизации и подстраиваясь под изменения в сети. В статье показана очень самая простая схема, достаточная чтобы понять суть настроек. При необходимости ее легко дополнить и развить.
Рис.1 Проверяем настройки Quagga
Рис.2 Список команд виртуальной консоли Quagga

Установим quagga на всех маршрутизаторах:
cd /usr/ports/net/quagga/ make install clean
Перед сборкой появится диалог настройки сборки, для ospf рекомендую не устанавливать дополнительные настройки:
┌────────────────────────────────────────────────────────────────────┐ │ Options for quagga 0.99.10_3 │ │ ┌────────────────────────────────────────────────────────────────┐ │ │ │ [ ] ISISD Enable experimental ISIS daemon │ │ │ │ [ ] PAM PAM authentication for vtysh │ │ │ │ [ ] OSPF_NSSA NSSA support (RFC1587) │ │ │ │ [ ] OSPF_OPAQUE_LSA OSPF Opaque-LSA support (RFC2370) │ │ │ │ [ ] RTADV IPv6 Router Advertisements │ │ │ │ [ ] SNMP SNMP support │ │ │ │ [ ] TCPSOCKETS Use TCP/IP sockets for protocol daemons │ │ │ │ [ ] TCPMD5 Use experimental MD5 patch for BGP │ │ │ │ [ ] DLMALLOC Use dlmalloc (makes bgpd much faster) │ │ ├─└────────────────────────────────────────────────────────────────┘─┤ │ [ OK ] Cancel │ └────────────────────────────────────────────────────────────────────┘
По окончании установки, приступим к настройке, вообще настроить quagga можно двумя способами создать все файлы настроек или подключиться telnet к консоли quagga, которая эмулирует CLI Cisco и настраивать из коммандной строки(я всегда настраиваю именно через telnet):
1. Сначала скопируем дефалтовые файлы настройки, это мы делаем на всех трех маршрутизаторах.
cp /usr/local/share/examples/quagga/zebra.conf.sample /usr/local/etc/quagga/zebra.conf cp /usr/local/share/examples/quagga/ospf.conf.sample /usr/local/etc/quagga/ospfd.conf
2. Теперь в /etc/rc.conf включим автозагрузку quagga, это тоже делаем на всех трех маррутизаторах
и запустить quagga
3.Теперь можно приступать к непосредственной настройке, начнем с первого маршрутизатора Router1:
Подключимся к консоле:
telnet 127.0.0.1 ospfd
Пароль по умолчанию zebra
После того, как мы подключились к консоле вы полняем такую последовательность команд:
enable configure terminal router ospf router-id 192.168.0.1 network 192.168.0.0/24 area 0 neighbor 192.168.0.2 neighbor 192.168.0.3 default-information originate write memory
Теперь переходим ко второму маршрутизатору, здесь последовательность команд будет такая:
enable configure terminal router ospf router-id 192.168.0.2 network 192.168.0.0/24 area 0 neighbor 192.168.0.1 neighbor 192.168.0.3 redistribute connected write memory
Настройки третьего маршрутизатора отличаются от настроек второго, только router-id 192.168.0.3 и neighbor 192.168.0.2 будет вместо neighbor 192.168.0.3.
То есть такая последовательность команд:
enable configure terminal router ospf router-id 192.168.0.3 network 192.168.0.0/24 area 0 neighbor 192.168.0.1 neighbor 192.168.0.2 redistribute connected write memory
На этом настройка закончена. Выйти из режима настройки можно используя комбинацию клавиш Ctrl+z.
Проверить работоспособность можно в консоли quagga с помощью команд:
show ip ospf neighbor
Читайте также: