
Как создать словарь для брута kali linux
Обновлено: 06.07.2024
Этичный хакинг и тестирование на проникновение, информационная безопасность
Оглавление
В этой статье собраны возможные ситуации генерации словарей, с которыми можно столкнуться на практике, но которые ещё не описаны в других статьях. Некоторые примеры взяты из вопросов в комментариях или на форуме, с некоторыми задачами я сталкивался сам.
Будут рассмотрены не только уже знакомые нам инструменты, но и парочка новых. Для некоторых задач мы будем использовать не только специализированные инструменты - некоторые действия проще сделать с помощью стандартных утилит Linux или собственных скриптов.
Поскольку здесь не будут описываться основы генерации словарей, то начнём с перечня источников, где вы можете прочитать эти самые основы. Рекомендуется прочитать их, если вы ещё не сделали этого.
Азы генерации словарей
Атака на основе правил
Атака на основе правил - изменяет уже существующий словарь по указанному набору правил. Если с помощью атаки на основе правил вы хотите изменить поведение маски, то вначале нужно создать словарь по маске, а затем работать с ним.
Самый простой способ - использовать программу с графическим интерфейсом Mentalist, инструкция: Генерация и модификация словарей по заданным правилам.

Атака на основе правил в John the Ripper намного мощнее чем в hashcat, для данной атаки из этих двух программ рекомендую выбирать именно John: Полное руководство по John the Ripper. Ч.5: атака на основе правил
Генерация словарей на основе информации о человеке
Если пароль составлен на основе данных пользователя, например, комбинация имени, фамилии, даты рождения, именах детей, номера телефона, этих же данных ближайших родственников, то такой пароль можно считать слабым. Рассмотренные выше инструменты не очень подходят для составления подобных словарей, основанных на информации о пользователе - разве что, комбинаторная атака в Hashcat, но она за раз принимает только 2 словаря.
Именно эту проблему решает утилита CUPP.
Установка CUPP в Kali Linux
Установка CUPP в BlackArch
Запустите программу в интерактивном режиме и введите известные данные пользователя:

Пример сгенерированных паролей:

Если вам нужен перевод задаваемых вопросов, то вы найдёте его на странице карточки программы.
Составление списков слов и списков имён пользователей на основе содержимого веб-сайта
Познакомимся с ещё одним инструментом - CeWL. Эта программа обходит указанный сайт (можно указать глубину обхода) и все найденные на страницах сайта слова сортирует в порядке частоты их использования. Зачем нужен такой словарь? Автор предлагает использовать его для брут-форса. К тому же, программа умеет искать e-mail адреса, а также извлекать имена создателей офисных документов - поддерживаются файлы Word и PDF. Эти данные можно использовать для составления списка имён пользователей.
Ещё в комплекте с программой идёт утилита FAB, которая извлекает из уже скаченных документов Word и PDF имена авторов - их тоже можно использовать в качестве имён пользователей для брут-форса.
Установка CeWL в Kali Linux
Программа предустановлена в Kali Linux.
В минимальных версиях программа устанавливается следующим образом:
Установка в BlackArch
В карточке программы описаны дополнительные нюансы установки - рекомендуется ознакомиться.
Примеры запуска CeWL

Запуск FAB, при котором будут проверены все документы *.doc в директории /home/mial/Downloads/, из метаинформации этих документов будет извлечено поле, содержащее имя автора документа, данные будут выведены на экран:

Как создать словарь по маске с переменной длиной
Рассмотрим генерацию списков слов различной длины на примере Hashcat и maskprocessor.
Удлиняющиеся пароли в Hashcat
Для того, чтобы генерировались пароли различной длины, имеются следующие опции:
Опция -i является необязательной. Если она используется, то это означает, что длина кандидатов в пароли не должна быть фиксированной, она должна увеличиваться по количеству символов.
Опция --increment-min также является необязательной. Она определяет минимальную длину кандидатов в пароли. Если используется опция -i, то значением --increment-min по умолчанию является 1.
И опция --increment-max является необязательной. Она определяет максимальную длину кандидатов в пароли. Если указана опция -i, но пропущена опция --increment-max, то её значением по умолчанию является длина маски.
Правила использования опций приращения маски:
- перед использованием --increment-min и --increment-max необходимо указать опцию -i
- значение опции --increment-min может быть меньшим или равным значению опции --increment-max, но не может превышать его
- длина маски может быть большей по числу символов или равной числу символов, установленной опцией --increment-max, НО длина маски не может быть меньше длины символов, установленной --increment-max.
Итак, команда запуска для генерации паролей, которые имеют длину от шести до десяти символов:
hashcat -a 3 -i --increment-min=6 --increment-max=10 --stdout ?l?l?l?l?l?l?l?l?l?l
Удлиняющиеся пароли в maskprocessor
В maskprocessor имеется следующая опция приращения:
Следующая команда составит словарь из чисел от 1 до 9999:
Когда о пароле ничего не известно (все символы)
Про нюансы я уже писал, здесь только примеры команд.
Если нужно запустить полный перебор, когда в пароле могут быть большие и маленькие латинские буквы, а также цифры и длина пароля от 1 до 12, то нужно использовать следующие опции и маску:
Чтобы вывести все кандидаты в пароли или сохранить их в словарь:
и длина пароля от 1 до 12, то нужно использовать следующие опции и маску:
Чтобы вывести все кандидаты в пароли или сохранить их в словарь:
Создание словарей, в которых обязательно используется определённые символы или строки
В комментариях к статьям о генерации паролей по маскам иногда спрашивают, а как создать словарь, содержащий определённые символы или слова, причём они могут быть в любом месте. На самом деле, именно маски для этого подходят плохо. Задачу можно решить с помощью Атаки на основе правил, особенно если речь идёт об отдельных символах или группах символов - выше уже даны ссылки на решение подобных случаев. Но если речь идёт о строках, то Атака на основе правил становится или слишком сложной и запутанной из-за необходимости создавать большое количество правил, или даже просто невозможной.
Рассмотрим несколько примеров.
Предположим, известно, что в пароле, состоящим из любых символов (большие и маленькие буквы, а также цифры), обязательно присутствует слово «Alexey», которое может быть в любом месте пароля и в любом регистре. Для решения этой задачи вместо того, чтобы создавать безумное количество правил, можно создать словарь со всеми вариантами и просто отфильтровать слова, в которых есть искомая строка, например:

На мой взгляд, это оптимальное решение. Оно также подходит, если вы не хотите создавать словарь, а хотите использовать атаку по маске - многие программы для брут-форса способны принимать кандидаты в пароли из стандартного ввода.
Ещё один вариант - искомое слово может быть в любом регистре, но точно расположено в начале пароля:
Кстати, последний пример не особенно удачный - поскольку нам известно, что вначале возможны только 2 символа - „A“ или „a“, то лучше использовать пользовательский набор символов, включающих эти два символа. Аналогично и для других - хотя бы четырёх известных символов (по количеству возможных пользовательских наборов).
Как создать словарь, обязательно содержащий символы «e», «g», «D» и «t»? Для этого используйте команду вида:
В ней вы можете добавлять цепочку из grep и отфильтровывать пароли с любым количеством необходимых символов.
Как создать словарь, в котором пароли в любом месте и в любом регистре содержат слово «Alexey» или слово «MiAl»? Используйте команду вида:
Количество искомых строк может быть любым:
Пример команды, создающий словарь, в котором кандидаты в пароли состоят только из цифр, но в пароле обязательно должна быть последовательность «12345» расположенная в любом месте:
Думаю, идея понятно - вместо того, чтобы пытаться создать невозможную маску, создаём всё возможное и отфильтровываем то, что нам нужно.
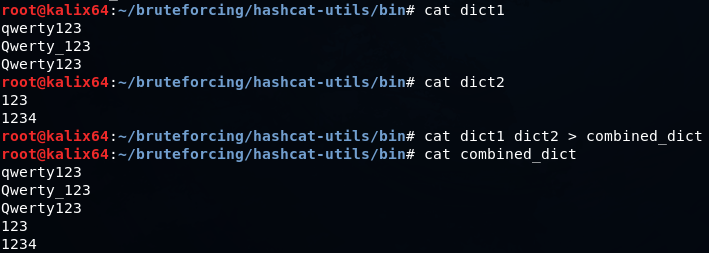
Как создавать комбинированные словари
Комбинированными словарями обычно называют словари, включающие одновременно имя пользователя и пароль, разделённые определённым символом (обычно двоеточие или символ табуляции). Но в данном случае я имею в виду словари, которые составлены из слов разных словарей, путём объединения. Но и к «нормальным» комбинированным словарям мы ещё вернёмся.
Суть в том, что к каждому слову из первого словаря, добавляется каждое слово из второго словаря.
Словарь 1 (dict1.txt)
Словарь 2 (dict2.txt)
Запуск комбинаторной атаки (-a 1):
Мне почему-то казалось, что слова должны объединятся ещё и в обратном порядке (то есть первым идёт слово из второго словаря), но как вы можете убедиться, это не происходит. Поэтому для получения описанного эффекта, нужно запустить атаку ещё раз, поменяв словари местами:
Как комбинировать более двух словарей
Далее показан пример комбинации трёх словарей - суть в том, что каждое новое полученное слово состоит по одному слову из каждого из трёх словарей:
Как комбинировать подобным образом 4 и более словарей? Мне трудно представить, что это может пригодиться в реальной ситуации, но для этого скорее всего придётся писать свой скрипт для автоматизации показанного выше алгоритма. Если вы знаете программы, которые умеют это делать, то пишите в комментариях.
Эта программа умеет комбинировать по 3 указанных словаря, но опять же - если словарь идёт третьим, то слова из него всегда будут в конце.
Чтобы получить все возможные комбинации из трёх слов в любом порядке, то нужно использовать следующие команды:
Как создать все возможные комбинации для короткого списка строк
Утилита combipow создаёт все “уникальные комбинации” из короткого списка ввода. Эта программа также включена в hashcat-utils.
Пример содержимого словаря с именем wordlist:
Запуск combipow с этим словарём:
Даст следующие результаты:
Комбинирование по алгоритму PRINCE
Программа princeprocessor реализует алгоритм PRINCE. Подробнее об этом алгоритме вы можете узнать на странице карточки программы. Там же описана суть работы программы и её опции.
Примеры использования princeprocessor.
Чтобы создать все возможные цепи из содержимого файла dict1.txt:

Используя слова из указанного словаря (dict1.txt) составить цепи минимальной длиной 2 элемента (--elem-cnt-min=2) и максимальной длиной 2 элемента (--elem-cnt-max=2), то есть в каждой цепи будет только по 2 слова:

Гибридная атака - объединение комбинаторной атаки и атаки по маске
Эта атака совмещает атаку по словарю и атаку по маске - она принимает на входе словарь и маску и выдаёт гибридный пароль.
Если ваш example.dict содержит:
генерируют следующие кандидаты в пароли:
Это работает и в противоположную сторону!
генерируют следующие кандидаты в пароли:
Все возможности гибридной атаки можно реализовать с помощью Атаки на основе правил - поэтому если она вам нравится больше, то используйте её.
Как создать комбинированный словарь, содержащий имя пользователя и пароль, разделённые символом
Теперь возвращаемся к комбинированным словарям, содержащим одновременно имя пользователя и пароль.
А это пример комбинированного словаря, в котором имя пользователя и пароль разделены двоеточием:
Чтобы создать комбинированный словарь, используйте команду вида:
- users.txt и passwords.txt - словари, из которых будут взяты имена пользователей и пароли и будут составлены все возможные комбинации.
- РАЗДЕЛИТЕЛЬ - символ, которым будут разделены логин и пароль
Например, в следующей команде разделителем является двоеточие:

Кстати, если в качестве разделителя нужно вставить символ табуляции, то нажмите Ctrl-v + Tab:

Кстати, если вы попытаетесь разобраться в приведённой выше команде hashcat, то выясните, что одновременно используется Комбинаторная атака и добавлено правило из Атаки на основе правил.
Рассмотрим частный случай: как создать файл парный словарь логинов и паролем такого типа: логин всегда постоянный, затем табуляция и пароль.
Конечно, в качестве первого словаря можно создать файл с одним текстовым полем - логином. Но есть и другой вариант с помощью мощнейшей команды sed:
- superadmin — строка, которую нужно вставить перед каждым паролем
- \t — символ табуляции, который будет разделять логин и пароль
- pass.txt — файл, откуда считывать пароли
- login_pass.txt — новый файл, куда будут сохранены пароли
Если не хотите создавать новый файл, а хотите изменить имеющийся, то уберите перенаправление и добавьте опцию -i:
Как извлечь имена пользователей и пароли из комбинированного словаря в обычные словари
Если из комбинированного словаря нам нужно извлечь только имена пользователей и/или только пароли. Для этого мы воспользуемся (тоже мощнейшей) программой awk.
Смотрите также: Уроки по Awk
Для извлечения имён пользователей:
Для извлечения паролей:
В этих командах:
- РАЗДЕЛИТЕЛЬ - это символ, который разделяет логины и пароли. Если вам нужно указать там символ табуляции, то запишите «\t».
- СЛОВАРЬ.txt - комбинированный словарь из которого мы извлекаем списки слов
В принципе, команды только различаются в $1 (первое поле до разделителя) и $2 (второе поле после разделителя).
Как при помощи Hashcat можно сгенерировать словарь хешей MD5 всех шестизначных чисел от 000000 до 999999
Hashcat может делать радужные таблицы, но только для Wi-Fi.
Зато с помощью PHP эту задачу можно решить несколько строк:
Время выполнение — 1-4 секунды. За это время будут сгенерированы все md5 хеши для строк 000000…999999.
Сохраните приведённый выше код в файл md5-rb-gen.php, запускать так:
Чтобы сохранить полученные хеши в файл:
Интересное наблюдение о скорости достижения задачи.
Следующие две команды делают ровно то же самое:
Но на среднем компьютере выполнение команд займёт до часа. PHP оказался быстрее, чем нативные Linux команды…
Удвоение слов
Как создать словарь 12 символьных слов, состоящих только из десятичных цифр (?d) формата abcdefabcdef, т.е шестизначное число написано два раза?
Можно использовать Атаку на основе правил, а можно написать небольшой скрипт Bash (все слова в из файла user.txt пишутся по 2 раза):
Применительно к нашему заданию — удвоение шестизначных чисел, можно использовать следующую команду, которая сгенерирует числа из шести цифр и дважды запишет каждое число:
Как создать словарь со списком дат
Как создать список дат по шаблону ДД-ММ-ГГГГ, то есть соответствущий маске ?d?d-?d?d-?d?d?d?d но чтобы перебор был не в диапазоне 00-99, а 01-31, 01-12 и 1900-2021 соответственно?
Такие словари умеет создавать программа pydictor.
Но ещё проще словарь сделать следующим образом (он будет сохранён в файл dates.txt):
Если хотите обойтись без создания словаря, то передавайте вывод предыдущие команды на стандартный ввод hashcat:
Заключение
Если я что-то пропустил или есть утилиты, которые делают показанные вещи проще или делают возможным то, о чём я написал что это невозможно, то пишите в комментариях - будет интересно узнать об этом и дополнить статью.
Также можете задавать ваши вопросы, связанные с генерацией словарей, учитывающих определённые условия.
Список инструментов для тестирования на проникновение и их описание
Описание Crunch
Crunch — это генератор списка слов, в котором вы можете указать один из стандартных наборов символов (цифры, большие и маленькие буквы) или набор символов по своему выбору. crunch может генерировать все возможные комбинации и перестановки в соответствии с заданными критериями. Данные, которые выводит crunch, могут быть отображены на экране, сохранены в файл или переданы в другую программу.
- crunch генерирует списки слов (словари) как методом комбинации, так и методом перестановки
- он может разбить вывод по количеству строк или размеру файла
- поддерживается возобновление процесса после остановки
- образец (паттерн) поддерживает числа и символы
- образец поддерживает по отдельности символы верхнего и нижнего регистра
- работая с несколькими файлами, выводит отчёт о статусе
- новая опция -l для буквальной поддержки, @,% ^
- новая опция -d для ограничения дублирования символов, смотрите man-файл для деталей
- поддержка unicode
Справка по Crunch
Использование crunch
Простой пример использования:
Ещё один пример:
- @ означает символы в нижнем регистре
- , означает символы в верхнем регистре
- % означает цифры
- ^ означает разные символы, общим количеством 33. Вы можете посмотреть их командой:
Как создать словарь в crunch
Перейдите в Приложения > Kali Linux > Password Attacks > crunch
Или введите в Терминале:
Правила для создания словаря.
- min = минимальное количество символов в паролях словаря
- max = максимальное количество символов в паролях словаря
- charset = символы, которые хотите добавить в пароли в словаре. Например: abcd или 123455
- pattern = образец пароля. Например хотите создать словарь вида 98*******, т.е. первые две цифры будут статические и последние цифры — переменными.
Например, я хочу создать словарь из минимум 10 цифр, максимум 10 цифр, с символами abcd987 и образцом abc@@@@@@@ с последующим сохранением файла словаря на рабочем столе.
Вводим в терминале:
это создаст 823543 комбинаций пароля.
Руководство по Crunch
ОПИСАНИЕ. ОБЯЗАТЕЛЬНЫЕ ОПЦИИ
Crunch может создавать словарь, основанный на указанных вами критериях. Вывод из crunch может быть отправлен на экран, файл или в другую программу. Требуемыми параметрами являются:
минимальная-длинна
Минимальная длина строки, с которой вы хотите чтобы crunch начал. Эта опция требуется даже для параметров, которые не будут использовать эту величину.
максимальная-длинна
Максимальная длина строки, с которой вы хотите чтобы crunch начал. Эта опция требуется даже для параметров, которые не будут использовать эту величину.
строка набор-символов
Вы можете указать в командной строке набор символов для использования в crunch или оставить его пустым, чтобы crunch использовал набор символов по умолчанию. Символы ДОЛЖНЫ указываться в следующем порядке: буквы нижнего регистра, буквы верхнего регистра, цифры, а затем символы. Если вы не будете следовать этому порядку, то вы не получите результата который хотите. Вы ДОЛЖНЫ указать или величины для типа символов или знак плюс.
ПРИМЕЧАНИЕ: Если вы хотите включить символ пробела в ваш набор символов, вы должны экранировать его символом \ или заключить ваш набор символов в кавычки, например, "abc ". Смотрите примеры 3, 11, 12 и 13 для большего понимания.
НЕОБЯЗАТЕЛЬНЫЕ ОПЦИИ
-b число[тип]
Определяет размер файла вывода, работает только если используется -o START, например: 60MB.
Имена выводных файлов будут в формате «начальные буквы-конечные буквы», пример:
сгенерирует 4 файла: aaaa-gvfed.txt, gvfee-ombqy.txt, ombqz-wcydt.txt, wcydu-zzzzz.txt.
Валидными величинами для типов являются kb, mb, gb, kib, mib, and gib. Первые три типа основываются на 1000, а последние три типа основываются на 1024.
ПРИМЕЧАНИЕ: между цифрой и типом нет пробела. Например, 500mb — это правильно, а 500 mb — это НЕ правильно.
-c число
Задаёт число строк для записи в файл вывода, работает только если используется -o START, пример: 60.
Имена выводных файлов будут в формате «начальные буквы-конечные буквы», например:
-d числосимволы
Ограничивает количество повторяющихся одинаковых символов. -d 2@ ограничивает вывод для символов нижнего регистра, к примеру в выводе будут слова от aab до aac. aaa не будет сгенерировано, поскольку имеет три последовательных буквы a. Формат: число, а за ним символ, где число — это максимальное количество последовательных символов, а символ — это тот символ из набора знаков, который вы хотите ограничить, к примеру @,%^. Смотрите примеры 17-19.
-e строка
Указывает, когда crunch должен остановиться досрочно. При генерации этой строки (пароля) программа прекращает свою работу.
-f /путь/до/набора/символов.lst имя-набора-символов
Указывает набор символов из charset.lst. В Kali Linux этот файл размещён здесь: /usr/share/crunch/charset.lst.
-i
Инвертирует вывод, т. е. вместо aaa,aab,aac,aad и т. д., вы получите aaa,baa,caa,daa,aba,bba и т.д.
-l
Когда вы используете опцию -t, эта опция говорит crunch какой символ нужно обрабатывать буквально. Это позволит вам использовать буквы в качестве заполнителей в паттернах. Опция -l должна быть такой же длины как опция -t. Смотрите пример 15.
Объединена с -p. Пожалуйста, вместо неё используйте -p.
-o wordlist.txt
Указывает файл для записи вывода, например: wordlist.txt
Говорит crunch генерировать слова, которые не имеют повторяющихся символов. По умолчанию crunch будет генерировать словарь, размер которого можно посчитать по формуле: (количество символов в наборе символов) в степени (максимальная длина слов). Вместо этого эта опция будет генерировать количество слов равное факториалу количества символов в наборе символов. Например, набор символов abc и максимальная длина — 4. По умолчанию Crunch создаст 3^4 = 81 слов. При использовании этой опции будет сгенерировано 3! = 3x2x1 = 6 слов (abc, acb, bac, bca, cab, cba). ОНА ДОЛЖНА БЫТЬ ПОСЛЕДНЕЙ ОПЦИЕЙ! Эта опция НЕ МОЖЕТ использоваться с -s и она игнорирует максимальную и минимальную длину паролей, при этом вам всё равно нужно указывать эти два числа.
-q имя_файла.txt
Говорит crunch прочитать имя_файла.txt и перемешать то, что прочитано. Это похоже на опцию -p, но разница в том, что вывод берётся из имя_файла.txt.
-r
Говорит crunch возобновить генерацию слов с того места, где она была прервана. -r работает только если вы используете -o. Вы должны использовать ту же команду как используется оригинальная команда для генерации слов. Единственное исключение — это опция -s. Если ваша оригинальная команда использует опцию -s, вы ДОЛЖНЫ удалить её перед возобновлением сессии. Просто добавьте -r в конец оригинальной команды.
-s начало_блока
Указывает начало строки, например: 03god22fs
-t @,%^
Определяет паттерны (образцы), например @@god@@@@ где будут изменяться только @, ,[запятая], % и ^.
- @ вставит буквы нижнего регистра
- , вставит буквы верхнего регистра
- % вставит цифры
- ^ вставит символы
-u
Опция -u отключает поток печати процентов. Она должна быть последней опцией.
-z gzip, bzip2, lzma, и 7z
Сжимают вывод из опции -o. Валидными параметрами являются gzip, bzip2, lzma и 7z.
gzip — самый быстрый, но сжатие минимальное. bzip2 помедленнее чем gzip но имеет улучшенную компрессию. 7z самый медленный, но имеет наилучшее сжатие.
ПЕРЕНАПРАВЛЕНИЕ
Вы можете использовать вывод crunch и перенаправлять его по трубе (|) в другие программы. Двумя наиболее популярными программами для принятия вывода из crunch являются aircrack-ng и airolib-ng. Синтаксис следующий:
ПРИМЕЧАНИЯ
Это обычно объясняется тем, что у вас закончилось место на диске. Если вы перепроверили, что у вас предостаточно дискового пространства, значит наиболее вероятно, что проблема в имени файла, которое начинается с точки. В Linux имена файлы, имена которых начинаются с точки, являются скрытыми. Чтобы их увидеть сделайте так ls -l .*
- Crunch говорит, что максимальная и минимальная длины должны быть такого же размера, как и ваш паттерн, при этом длина установлена правильно.
Символом экранирования в bash является \. Поэтому паттерны, которые содержат & и * должны выглядеть примерно так:
Альтернатива экранирования символов — это обёртывание строки кавычками. Например:
Если вы хотите использовать " в вашем паттерне, вам нужно экранировать его примерно так:
Пожалуйста помните, что различные терминалы имеют различные символы экранирования и, возможно, имеют различные символы которые вы должны экранировать. Пожалуйста, проверьте страницу man для вашего терминала для поиска информации о символах экранирования и о тех символах, которые нужно экранировать.
- Когда используете опцию -z 7z, 7z не удаляет оригинальный файл. Вам нужно будет удалить его вручную.
Примеры запуска Crunch
Примеры использования crunch
Пример 1
crunch отобразит список слов, который начинается с a и заканчивается на zzzzzzzz
Пример 2
crunch отобразит список слов, в паролях которого используется набор abcdefg который начинается на a и заканчивается gggggg
Пример 3
В конце строки есть символ пробела. Чтобы crunch мог использовать пробел, вам нужно экранировать его, поставив перед ним символ \. В этом примере вы можете также использовать кавычки вокруг букв тогда вам не нужен \, например "abcdefg ". Crunch отобразит список слов, использующих набор символов abcdefg , который начинается на a, а заканчивается на шесть пробелов.
Пример 4
crunch будет использовать набор символов mixalpha-numeric-all-space из charset.lst и выведет сгенерированные пароли в файл с названием wordlist.txt. Этот файл начнётся с a и закончится на " "
Пример 5
crunch сгенерирует восьмисимвольный список слов, используя набор символов mixalpha-number-all-space из charset.lst и запишет список паролей в файл wordlist.txt. Файл начнётся с cbdogaaa и закончится на " dog "
Пример 6
crunch начнёт генерировать словарь с BB и закончит на ZZZ. Это полезно если вы должны остановить посередине генерацию словаря. Просто сделайте завершающий словарь и установите параметр -s на следующее слово в последовательности. Убедитесь, что переименовали оригинальный словарь ДО того, как вы начали, иначе crunch перезапишет существующий словарь.
Пример 7
Номера не обрабатываются, но необходимы.
crunch сгенерирует abc, acb, bac, bca, cab, cba.
Пример 8
Номера не обрабатываются, но необходимы.
crunch сгенерирует birdcatdog, birddogcat, catbirddog, catdogbird, dogbirdcat, dogcatbird.
Пример 9
crunch сгенерирует сжатые в bzip2 файлы, каждый из которых содержит по 6000 слова. Имена сжатых файлов будут в формате «первое_слово-последнее-слово.txt.bz2».
Пример 10
сгенерирует 4 файла: aaaa-gvfed.txt, gvfee-ombqy.txt, ombqz-wcydt.txt, wcydu-zzzzz.txt. Первые три файла по 20 мегабайт и последний файл — 11 мегабайт.
Пример 11
Пример 12
Пример 13
знак плюс (+) - это заполнитель, таким образом вы можете указать пользовательский набор символов для наборов любого типа. crunch будет использовать конкретный тип набора символов по умолчанию когда встречает знак плюс (+) в командной строке. Вы должны либо указать значения каждого типа наборов символов или использовать знак плюс. Т.е., если вы имеете два типа наборов символов вы ДОЛЖНЫ либо указать значения для каждого типа или использовать знак плюс. Т.е. в этом примере будут использоваться следующие наборы символов:
на конце вышеприведённой строки есть пробел, вывод начнётся с 11a! и закончится за "33z ". Кавычки показывают пробел на конце строки.
Пример 14
любые символы отличные от @,%^ являются заполнителями для слов которые нужно переставлять. Символы @,%^ имеют ту же функцию, что и с -t. Если вы хотите использовать @,%^ в вашем выводе вы можете использовать опцию -l для указания, какие символы crunch должен воспринимать буквально.
Пример 15
crunch теперь будет обрабатывать символ @ как буквальный символ и не будет заменять символом буквы в верхнем регистре
будет сгенерировано следующее
Пример 16
Пример 17
crunch сгенерирует пятисимвольные строки начиная с aab00 и кончая на zzy99. Обратите внимание, что присутствуют aaa и zzz.
Пример 18
crunch сгенерирует строки из 10 символов, начиная с aab!0001!! и заканчивая на zzy 9998. Вывод будет записан в файлы по 20 мегабайт.
Пример 19
crunch сгенерирует восьмисимвольные слова, в которых ограничено двумя количество одинаковых последовательных букв в нижнем регистре. Crunch начнёт с aabaabaa и закончит на zzyzzyzz.
Пример 20
crunch загрузить некоторые японские символы из файла набора символов unicode_test. Вы вод начнётся с @日00 и закончится в @語99.
Установка Crunch
Установка в Kali Linux
Программа предустановлена в Kali Linux.
Установка в BlackArch
Установка Crunch в Linux
Это же можно сделать из командйно строки (будет загружена самая последняя версия):

Использование подходящих словарей во время проведения тестирования на проникновение во многом определяет успех подбора учетных данных. В данной публикации я расскажу, какие современные инструменты можно использовать для создания словарей, их оптимизации для конкретного случая и как не тратить время на перебор тысяч заведомо ложных комбинации.
Инструменты
Пожалуй, один из самых известных инструментов для быстрого создания словарей. Он по умолчанию входит в популярный дистрибутив для проведения пентеста Kali Linux.
Инструмент работает в нескольких режимах:
Создание словаря, состоящего из перечисленных символов, например чисел
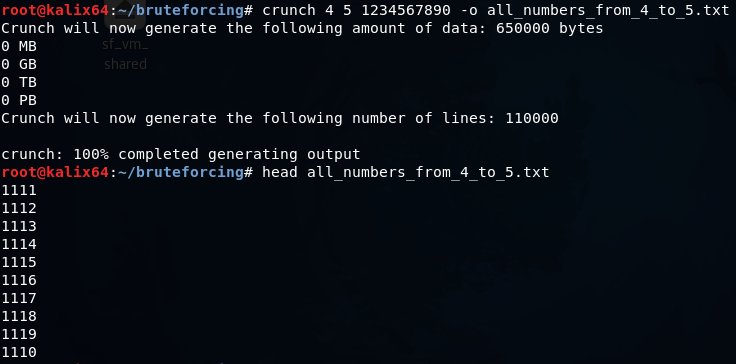
Создается словарь длиной от четырех до пяти цифр.
Создание словаря по шаблону

Сперва указывается длина пароля — 10 символов. Затем перечисляются наборы символов: буквы в нижнем регистре, буквы в верхнем регистре, цифры и спецсимволы. Ключ -t задает шаблон, где
- ^ — спецсимволы
- @ — буквы в нижнем регистре
- , — буквы в верхнем регистре
- % — цифры
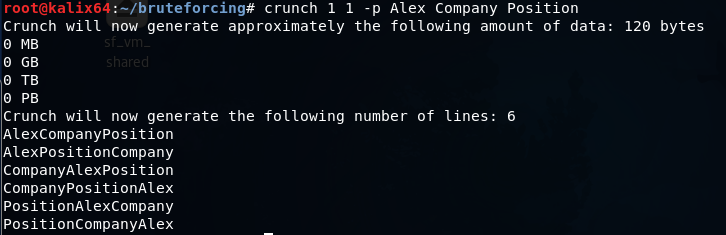
Словарь состоит из всех возможных комбинаций слов Alex, Company и Position.
Подробнее изучить инструмент можно через стандартные man страницы, они достаточно подробные.
maskprocessor
Вы можете задать до четырех собственных наборов символов и использовать готовые наборы
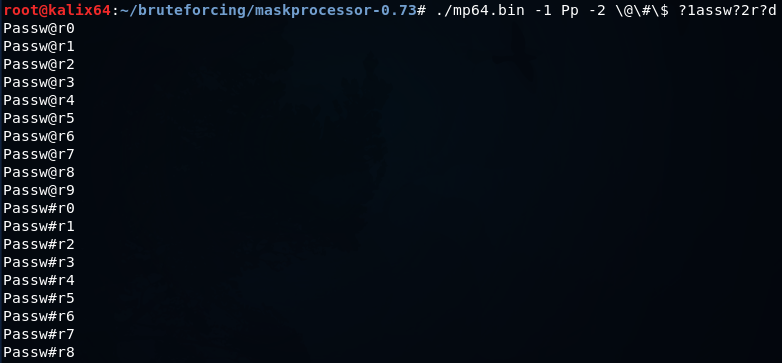
Или можно задать набор из цифр, но добавить к нему еще несколько спецсимволов так
Получаем такой результат
John the Ripper
Популярный брутфорсер John the Ripper (JTR) тоже позволяет генерировать словари на основе правил. Делается это при помощи ключа --rules, а сами правила описываются в файле john.conf
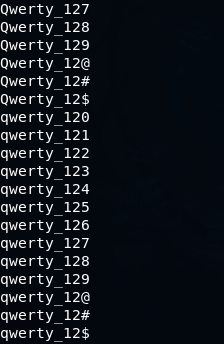
Вот так выглядит стандартное правило, используемое для взлома NTLM хэша
В первой строчке сказано, что нужно изменить регистр символа на нулевой позиции (T0), символ Q позволяет не допустить дубликатов в результирующем словаре. Во второй строке символ на первой позиции меняет свой регистр, затем скобки задают препроцессор, чтобы были сгенерированы пароли и с измененным нулевым символом и так далее.
Предположим, вы успешно провели брутфорс LM хэша и получили значение QWERTY123, так как для LM регистр не важен.
Но для авторизации вам нужно провести брутфорс NTLM хэша, где регистр имеет значение. Воспользовавшись правилом, описанным выше, можно получить следующий словарь
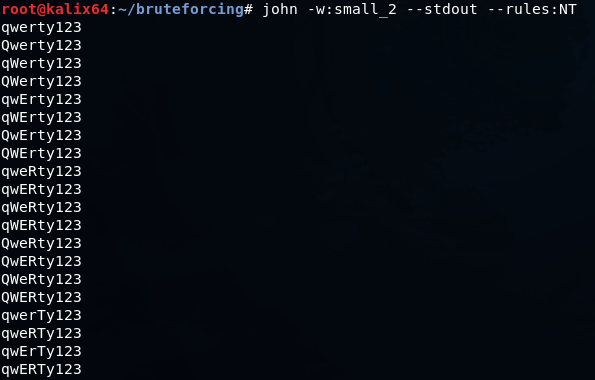
JTR по умолчанию содержит множество готовых правил, но можно написать и свои, либо взять за основу уже написанное и скорректировать под текущую ситуацию.
Подробно про синтаксис правил можно почитать здесь.
hashcat-tools
Еще одним полезным инструментом является набор утилит от популярного брутфорсера hashcat.
Рассмотрим некоторые их них. Описания всех утилит на английском языке можно найти тут.
combinanor.bin — позволяет генерировать словарь из слов, входящих в два других словаря.
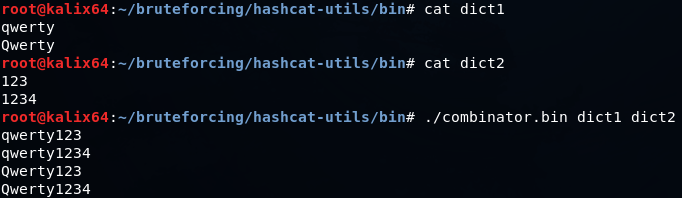
combinanor3.bin делает то же самое, но на вход принимает три файла, вместо двух.
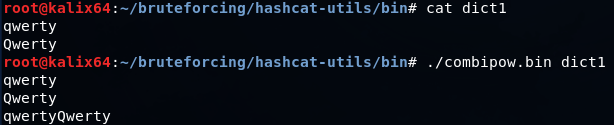
combipow.bin — создает все возможные комбинации из слов, перечисленных в файле (похоже на ключ -p в crunch)
cutb.bin — обрезает слова в словаре до указанной длины. Можно указывать смещение (offset)

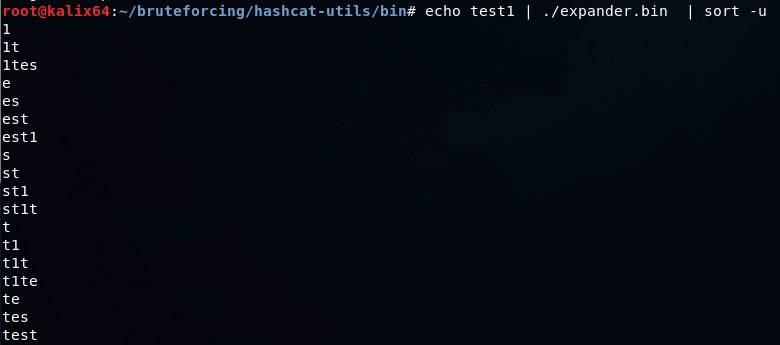
expander.bin — получает на ввод слова, разбирает их на символы, комбинирует и отправляет в STDOUT
permute.bin — создает словарь, который используется hashcat при атаке типа Permutation attack. Перед использованием словарь нужно пропустить через утилиту prepare.
gate.bin — разбивает словарь на несколько частей для параллельной обработки несколькими ядрами или несколькими машинами. В примере ниже мы разбиваем стандартный словарь JTR на две части. В первую часть попадают слова под номером 0, 2, 4, 6,…. Во вторую 1, 3, 5, 7,…
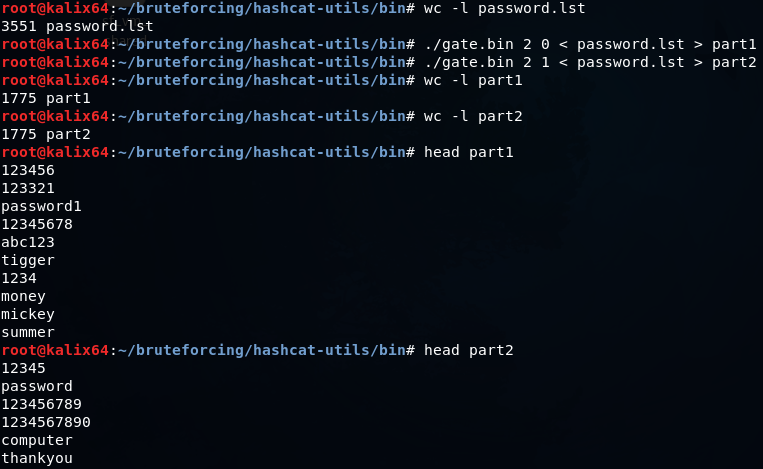
len.bin — оставляет в словаре только слова определенной длины от min до max
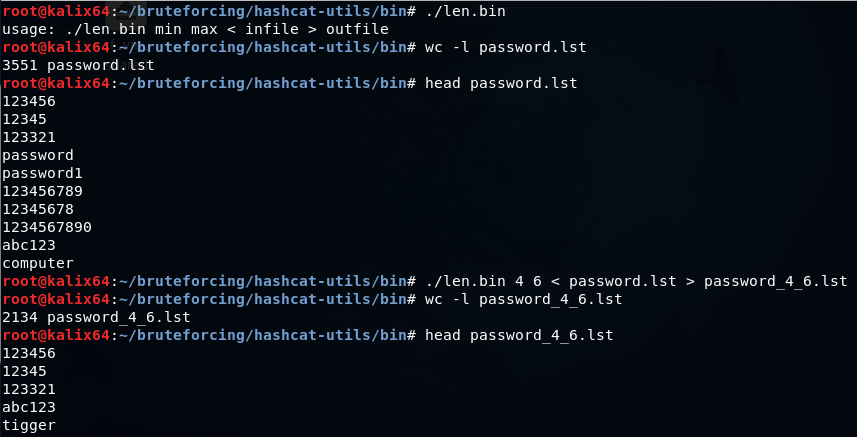
mli2.bin — объединяет два словаря.
req-include.bin — крайне полезный инструмент, который убирает из словаря все, что не подходит под заданные правила. Например, вы знаете, что по парольной политике в пароле обязательно присутствует буква в верхнем регистре, цифра и спецсимвол.

Число выбрано исходя из таблицы

Если таким образом нормализовать известный словарь rockyou, то можно сократить его размер в 270 раз! и не тратить ресурсы на заведомо ложные комбинации.

req-exclude.bin делает то же самое, что req-include, но с точностью до наоборот.
rli.bin — эта утилита удаляет значения из первого словаря, если они встречаются во втором. Полезно использовать, если вы создаете один словарь из нескольких.
Когда под рукой нет утилит
Может оказаться так, что воспользоваться набором hashcat-utils или crunch нет возможности, а нужно срочно создать словарь или нормализовать его. Некоторые алгоритмы довольно сложны в реализации, но базовые операции можно выполнить просто в командной строке.
Простой словарь с датами можно создать серией подобных команд
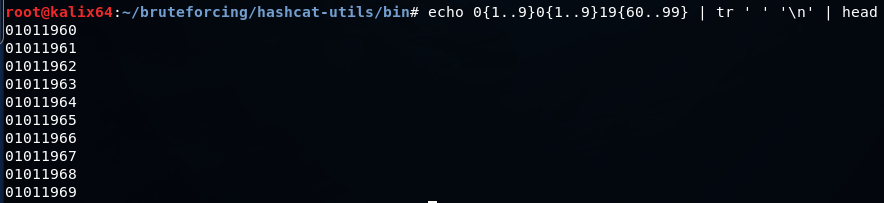
Если нужно разбить словарь на части для параллельной обработки, можно воспользоваться командой split
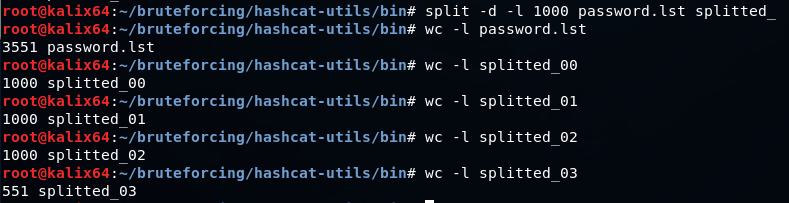
Быстро объединить два словаря можно так
Чтобы сделать заглавной первую или последнюю буквы в каждом слове, нужно выполнить, соответственно, команды
Для перевода регистра в нижний нужно заметить «u» на «l»
Дописать что-то в начало каждого слова из словаря можно так
А так можно дописать слово в конец
Следующей командой можно добавить в начало число от 0 до 99 к каждому слову в словаре
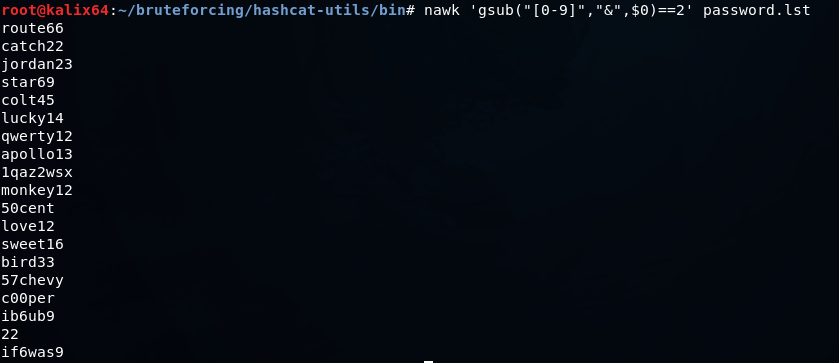
Можно очистить словарь от значений, в которых не присутствует хотя бы 2 числа так
Это лишь некоторые примеры. Можно писать более сложные обработки на Python и других скриптовых языках. Но всегда нужно помнить, что создание качественного словаря и его нормализация под целевой протокол — важный этап при проведении тестирования на проникновение.
Словарь с пользователями мы взяли небольшой и записали в него 4 пользователя.

Для составления словаря используется Crunch, как встроенное средство. Инструмент гибкий и может составить словарь по определенной маске. Если есть вероятность того, что пользователь может использовать словарный пароль, то лучше воспользоваться уже готовыми решениями, тем более, что, как показывает практика, самый популярный пароль – 123456.
Генерировать словарь будем на 5 символов по маске. Данный метод подходит для случаев, когда мы имеем представление о структуре пароля пользователя.
crunch 5 5 qwe ASD 1234567890 -t @@,%@ -o /root/wordlist.txt
5 – минимальное и максимальное количество символов;
qwe, ASD, 1234567890 – используемые символы;
-t – ключ, после которого указывается маска для составления пароля;
@ – нижний регистр;
, – верхний регистр;
% – цифры.
Сразу отметим, что на первых этапах мы будем для каждого инструмента описывать используемые ключи, но далее те же самые ключи уже не будут рассматриваться подробно, поскольку они крайне похожи друг на друга, а значит, имеют аналогичный синтаксис.
Patator
Все инструменты мы тестируем с количеством потоков по умолчанию, никаким образом их количество не изменяем.
Patator справился ровно за 7 минут 37 секунд, перебрав 2235 вариантов.

Hydra
hydra -f -L /root/username -P /root/wordlist.txt ssh://192.168.60.50
-f – остановка перебора после успешного подбора пары логин/пароль;
-L/-P – путь до словаря с пользователями/паролями;
ssh://IP-адрес – указание сервиса и IP-адреса жертвы.
Hydra затратила на перебор 9 минут 11 секунд.

Medusa
medusa -h 192.168.60.50 -U /root/username -P /root/wordlist.txt -M ssh
-h – IP-адрес целевой машины;
-U/-P – путь к словарям логинов/паролей;
-М – выбор нужного модуля.
Medusa за 25 минут обработала только 715 комбинаций логин/пароль, поэтому данный инструмент не лучший выбор в случае с брутфорсом SSH.
Metasploit
Произведем поиск инструмента для проведения brute-force атаки по SSH:
search ssh_login
Задействуем модуль:
use auxiliary/scanner/ssh/ssh_login
По умолчанию Metasploit использует 1 поток, поэтому и скорость перебора с использованием этого модуля очень низкая. За 25 минут так и не удалось подобрать пароль.
Patator
imap_login – используемый модуль;
-x – параметр, который помогает фильтровать ответы от Patator. В данном случае игнорируем ответы с кодом 1.
Параметр х является уникальным для каждого конкретного случая, поэтому рекомендуется сначала запустить инструмент без него и посмотреть какие ответы в основном приходят, чтобы затем их игнорировать.
В итоге Patator смог подобрать пароль за 9 минут 28 секунд, что является практически тем же самым показателем, что и в случае с SSH.

Hydra
hydra -f imap://192.168.60.50 -L /root/username -P /root/wordlist.txt
Hydra справилась за 10 минут 47 секунд, что довольно неплохо.

Medusa

Metasploit
В Metasploit не удалось подобрать подходящий модуль для брутфорса IMAP.
Patator
При использовании Patator появилось большое количество ложных срабатываний.
Hydra
hydra -L /root/username -P /root/wordlist.txt 192.168.60.50 smb
Благодаря своим алгоритмам Hydra справилась с задачей всего за 5 секунд.

Medusa
medusa -h 192.168.60.50 -U /root/username -P /root/wordlist.txt -M smbnt
Запуская перебор, я ожидал результатов, схожих с предыдущими, но на этот раз Medusa меня приятно удивила, отработав за считанные секунды.

Metasploit
С помощью поиска search smb_login находим нужный модуль scanner/smb/smb_login и применяем его.
Необходимо указать параметры:
RHOSTS – IP-адрес жертвы;
USER_FILE – словарь с пользователями;
PASS_FILE – словарь с паролями;
STOP_ON_SUCCESS – остановка после подобранной пары логин/пароль.
Metasploit справился с задачей за 1 минуту.

Patator
К сожалению, на данный момент из тестируемых инструментов только Patator может подбирать логин/пароль для RDP-протокола. При этом, даже если Patator и справился с поставленной задачей, в выводе дополнительно появилось ложное срабатывание.

Patator
Учитывая ответы веб-приложения на тестовые запросы, составим команду для запуска Patator:

Hydra
hydra -f -L /root/username -P /root/wordlist.txt http-post-form://site.test.lan -m "/wp-login.php:log=^USER^&pwd=^PASS^&wp-submit=Log+In&redirect_to=http%3A%2F%2Fsite.test.lan%2Fwp-admin%2F&testcookie=1:S=302"
Успех ожидал нас уже через 3 минуты 15 секунд.

Medusa
medusa -h site.test.lan -U /root/username -P /root/wordlist.txt -M web-form -m FORM:"/wp-login.php" -m FORM-DATA:"post?log=&pwd=&wp-submit=Log+In&redirect_to=http%3A%2F%2Fsite.test.lan%2Fwp-admin%2F&testcookie=1"

Metasploit

Patator
В данном модуле Patator работает уже медленнее, чем с Web-формами, а пароль был подобран за 11 минут 20 секунд.

Hydra
hydra -f -L /root/username -P /root/wordlist.txt ftp://192.168.60.50
Работая по умолчанию в 16 потоков, Hydra смогла перебрать пароли за 7 минут 55 секунд.

Metasploit, Medusa
В Metasploit используем модуль auxiliary/scanner/ftp/ftp_login
В случае с Medusa запрос выглядит следующим образом:
medusa -f -M ftp -U /root/username -P /root/wordlist.txt -h 192.168.60.50
Все параметры стандартные, указываем путь до словарей и обязательно ставим завершение перебора после найденной пары логин/пароль.
С этим протоколом, как и c SSH, Metasploit и Medusa плохо справляются при стандартном количестве потоков. Поэтому если есть желание использовать именно эти инструменты, то необходимо вручную увеличивать количество потоков. Но и тут не все так просто. В однопоточном режиме FTP-сервер при использовании этих инструментов, сбросил соединение, чего не наблюдалось при использовании Patator или Hydra. Поэтому есть вероятность, что увеличение количества потоков не изменит ситуацию.
Читайте также: