
Как запустить logstash в windows
Обновлено: 05.07.2024
Что такое ELK?
Elasticsearch
Elasticsearch - это поисковый сервер и хранилище документов основанное на Lucene, использующее RESTful интерфейс и JSON-схему для документов.
Logstash
Logstash – это утилита для управления событиями и логами. Имеет богатый функционал для их получения, парсинга и перенаправления\хранения.
Kibana
Kibana – это веб-приложение для визуализации и поиска логов и прочих данных имеющих отметку времени.
Установка Ubuntu 14.04
Дабы не повторяться с установкой дистрибутива Ubuntu 14.04 приведу ссылку на статью моего коллеги по блогу, Алексея Максимова - Настройка прокси сервера Squid 3.3 на Ubuntu Server 14.04 LTS. Часть 1. Установка ОС на ВМ Hyper-V Gen2 . Все действия по настройке можно проделать аналогичные, за исключением установки минимального UI и настройки второго сетевого интерфейса – его можно исключить на стадии создания виртуальной машины, ведь сервер будет находиться внутри периметра вашей сети.
Установка JAVA 7
Так как два из трех используемых продуктов написаны на JAVA нам придется его установить. Устанавливать будем Oracle Java 7, так как Elasticsearch рекомендует устанавливать именно его.
Добавляем Oracle Java PPA в apt:
И устанавливаем последнюю стабильную версию Oracle Java 7:
Проверить версию Java можно набрав команду
Установка Elasticsearch
Хотя документация по Logstash рекомендует использовать Elasticsearch версии 1.1.1, он прекрасно работает и с последней стабильной версией 1.3.1. Именно ее мы и установим.
Добавляем публичный GPG ключ в apt:
Создаем source list apt:
И устанавливаем Elasticsearch 1.3.1:
Базовая конфигурация Elasticsearch очень простая, нам нужно указать в файле конфигурации всего два параметра – имя кластера и имя ноды.
Открываем elasticsearch.yml:
И раcкомментируем строки “cluster.name: elasticsearch” и “node.name: "Franz Kafka"”. Вместо значений по умолчанию можно указать свои.
Создаем скрипты автозапуска elasticsearch:
Перед стартом сервера я рекомендую установить еще два плагина к elasticsearch – head и paramedic. Первый позволяет управлять сервером поиска и индексами документов, второй следит за “здоровьем” пациента, выводя графики с различной полезной информацией.
Плагины к elasticsearch устанавливаются с помощью команды plugin прямо из github:
После чего можно запускать сам сервер:
Установка Kibana
Так как Kibana это веб-приложение, перед его установкой нужно установить веб-сервер. Я воспользовался простейшим nginx.
Создаем папку www для будущего приложения:
Даем nginx права на папку:
Скачиваем последний архив с файлами Kibana (на настоящий момент это kibana-3.1.0.tar.gz):
И копируем его содержимое в папку /var/www:
Скачиваем файл конфигурации для работы Kibana под nginx:
Открываем его в редакторе nano и указываем в какой папке лежат файлы Kibana:
Заменяем строку
root /usr/share/kibana3;
на строку
root /var/www;
Копируем данный файл как файл по умолчанию для nginx:
И перезапускаем nginx:
Для этого нужно заменить файл дашборда по умолчанию на файл дашборда Logstash:
Основные настройки Kibana находятся в файле config.js по адресу /var/www/config.js, однако “из коробки” все работает замечательно.
Установка Logstash
Добавляем source list Logstash в apt:
И устанавливаем Logstash:
Для текущей задачи, мною была написана следующая простая конфигурация:
Создадим файл в папке конфигураций Logstash
И поместим туда следующую конфигурацию
Разберем по порядку:
В разделе input
tcp <> - открывает tcp порт и слушает его
type => “eventlog” говорит Logstash что на входе будут данные типа eventlog (известный формат полей для Logstash)
port => 3515 – номер потра
format => ‘json’ – говорит Logstash о том, что данные придут “обернутые” в JSON
Никаких манипуляций с логами я не совершаю, потому раздел filter у меня пустой. Хотя если Вам будет необходимо, к примеру, привести дату к нужному формату, или убрать из лога одно или несколько полей, то в данном разделе можно эти манипуляции описать.
В разделе output
elasticsearch <> – оправляет данные в elasticsearch
cluster => “elasticsearch” – указывает на имя кластера, что мы указывали при конфигурировании Elasticsearch
node_name => “Franz Kafka” – указывает на имя ноды.
Сохраняем файл и запускаем Logstash
Можно проверить что порт tcp 3515 слушается командой:
Установка nxlog
Устанавливаем на нужной Windows машине данный клиент. Настройки он хранит в файле nxlog.conf по адресу по умолчанию “c:\Program Files (x86)\nxlog\conf\” (для 32-битной версии “c:\Program Files\nxlog\conf\”).
Для решения данной задачи я написал конфигурационный файл следующего содержания:
В разделе Output указывается модуль om_tcp для отправки данных по протоколу tcp, указывается хост и порт подключения.
Раздел Route служит для указания порядка выполнения действий, так как клиент nxlog умеет читать из множества источников и отсылать во множество приемников. Все это можно подчерпнуть из документации к продукту.
Настроив конфигурационный файл не забудьте его сохранить и можно запускать клиент через оснастку Службы (Services) или через командную строку:
Использование
Открыв в браузере Kibana (и перейдя на дашборд Logstash, если он у Вас не по умолчанию) мы увидим после всего проделанного следующую картину.

Центральный график на дашборде отражает количество записей в единицу времени. Сверху находится строка запроса и панель управления дашбордом. В нижней части таблица с данными.
Обратив свое внимание на таблицу данных мы увидим что данные показаны в “сыром” виде, однако слева от таблицы есть список полей. Щелкнув последовательно по чекбоксам с полями EventID, EventTime, EventType, Hostname, Sevirity, Message, Channel, мы получим уже более читабельный вид таблицы:

Просмотрев логи я вижу что в основном это логи из раздела Security, хочется понять какие приложения создают данные записи. Изучив список полей я нахожу поле ProcessName, если по нему кликнуть мышкой, то откроется интересное меню микроанализа по полю в котором будет перечислен TOP10 по количеству записей от процесса с их именами.

Если кликнуть по символу лупы рядом с именем процесса, то создастся фильтр по этому имени.

А данные в таблице отобразятся в соответствии с фильтрами.
Кликнув в таблице по любой записи можно развернуть ее в детальный вид, где будет видно все поля записи. Например так:

Ну и наконец если я просто хочу поискать по всем полям словосочетание “System Center” в поле запроса я пишу “System Center”. В случае поиска по конкретному полю можно воспользоваться конструкцией FieldName:”SearchQuery”, например ProcessName:"System Center". Что бы исключить из выборки данные найденные с помощью конструкции можно воспользоваться оператором “-“, например -ProcessName:"System Center" или -“System Center”. Так же работают операторы OR и AND.
Этот мануал конечно не является исчерпывающим, но является достаточным для первоначальной установки и настройки рабочего лог-сервера elasticsearch+logtash+kibana4+beats (windows\linux-агенты).
Подробная информация, дополнительные возможности, а также «реал кунг-фу» доступны в официальной документации.
Будем собирать и склеивать
- Logstash-2.2.0 — обработка входящих логов
- Elasticsearch-2.2.0 — хранение логов
- Kibana-4.2.2 — web-интерфейс
- Topbeat 1.1.0 — Получение данных об инфраструктуре Linux-систем
- Filebeat 1.1.0 — Отображение логов в режиме real-time Linux-систем
- Packetbeat 1.1.0 — Анализ пакетных данных в сети Linux-систем
- Winlogbeat 1.1.0 — Анализ журналов Windows-систем.
- Операционная система — Ubuntu Server 14.04 (trusty) x86_x64
Подготовка
Редактируем hosts и hostname:
Устанавливаем Java 8:
Создаём каталоги, которые нам понадобятся для фасовки пакетов:
Редактируем конфиг /etc/elasticsearch/elasticsearch.yml:
Раскомментируем и отредактируем стоки cluster.name и node.name:
(вместо «elk-server.ss.lu» и «mynodename» можете вставьте свои значения)
Должно получится так:
cluster.name: elk-server.ss.lu
node.name: mynodename
Добавляем в автозагрузку:
Создаём INPUT-файл для «битсов»…
… и копируем туда код:
Это будет означать что logstash начнёт слушать порт 5044. Данный порт является по умолчанию для этой версии и будет прописан по умолчанию в битсах. Можете задать любой другой.
… и копируем туда код для связи с elasticsearch:
Проверяем конфиг на ошибки, запускаем, и вносим в автозапуск:
Пример успешной работы:
Скачиваем и устанавливаем публичный ключ:
Обновляем репозиторий и устанавливаем:

Нас просят создать первый индекс, но мы пока оставляем всё как есть и переходим к настройке клиентов.
Ставим на клиенты. Для начала, на сервер скачаем и поставим несколько готовых дашбордов Kibana с индексами Beats:
И видим что были добавлены дашборды Kibana с индексами Beats:
Получение данных об инфраструктуре сервера.
Передаёт информацию о работе процессора, использованию памяти. Для каждого процесса отображается информации о родители, pid, состояние и т.д. Также Topbeat позволяет просматривать информацию о файловой системе — состояние дисков, объём свободного пространства и т.д.
Установка (на клиенте):
На сервер нужно добавить шаблоны индексов Topbeat чтобы Elasticsearch стал правильно анализировать информацию на входе:
При успешной загрузки мы должны увидеть:
Файл topbeat.template.json создаётся при установке Topbeat и имеет расположение по умолчанию /etc/topbeat/topbeat.template.json. Поэтомоу если на сервере ELK мы по каким то причинам не будем устанавливать клиенты Beats, то нам необходимо будет скопировать этот шаблон с клиента на сервер, либо создать этот файл на сервере и скопировать туда его содержимое (с клиента). И далее его загрузить curl -XPUT 'адрес_сервер_elk:9200/_template/topbeat' -d@/PATH/topbeat.template.json.
Но будем считать что Битсы установлены на сервер и имеют следующее месторасположение /etc/topbeat/topbeat.template.json.
Редактируем конфиг (на клиенте):
В блоке output нужно за комментировать обращение к elasticsearch, т.к мы будем использоватеть logstash:
Раскомментируем блок с Logstash, укажем его IP-адресс и порт:
Важно: не используйте табуляцию для передвижения курсора в конфиге! Только пробелы. Иначе получите ошибку:
Если сервер Logstash находится во внешней сети, то на фаерволле удалённого сервера нужно настроить форвардиг порта, в данном случаем 5044 (tcp/udp).
Дополнительные опции логирования хорошо описаны в конфигах.
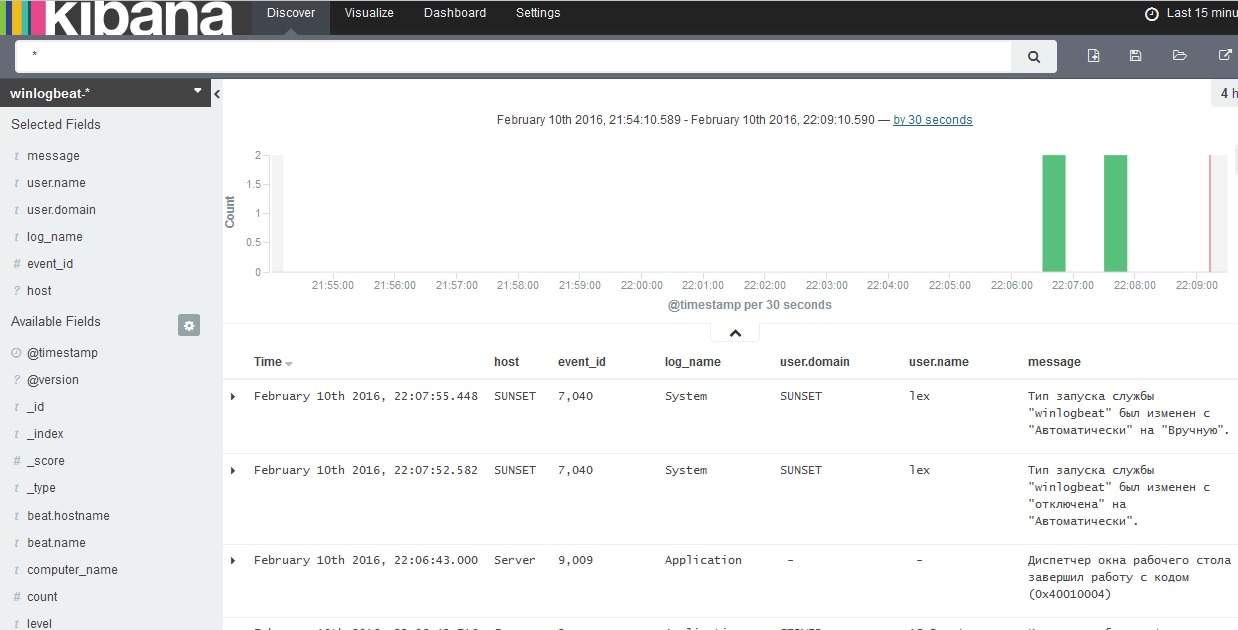
Открываем интерфейс Kibana и наблюдаем поступающую информацию:

Транслирует на сервер информацию из динамических файлов, которые мы будем указывать:
Добавим индексы на сервере (по аналогии с как мы настраивали Topbeat. Т.е. если на сервере шаблон отсутствует — мы его создаём):
Указываем из каких файлов будем забирать информацию (по умолчанию стоят все файлы из /var/log c расширение .log):
Указываем то, что нужно нам на данном клиенте, например:
Помните про отсутствие табуляции в коде!
Мы также будем использовать logstash для обработки индексов:
Смотрим информацию от Filebeat:

Настраивается по той же аналогии что и Topbeat/Filebeat:
Редактируем кофиг (комментируем Elasticsearch и настраиваем Logstash)
output:
Идём на сервер и добавляем индекс для Packetbeat:
Перед стартом сервиса правим в конфиге — C:\Winlogbeat\winlogbeat.yml.
В блоку event_logs перечислены основные журналы системы, которые нужно транспортировать на Logstash:
В event_logs можно добавить и другие журналы, список которых можно посмотреть так:
Если система выше Vista, то можно указать каналы:
Далее нам нужно загрузить на сервер индексы для winlogbeat как мы это делали для topbeat, filebeat, packetbeat. Это можно сделать удалённо:
Есть есть проблемы такого метода, то можно сделать следующее:
Создаём на сервере файл индекса winlogbeat.template.json
sudo vi
/ELK/releases/beats/winlogbeat/winlogbeat.template.json. На клиенте Windows открываем файл C:\winlogbeat\winlogbeat.template.json и копируем его содержимое в файл
Далее (на сервере) загружаем этот индекс на elasticsearch, для того чтобы он смог верно проанализировать информацию и предоставить её привычном формате:
Переходим в каталог где у нас лежит созданный файл winlogbeat.template.json.
На выходе должно быть:
Идём на клиент и запускаем сервис winlogbeat. После это начинаем мониторить данные через Kibana, определяя представление по загруженным индексам:

Удаление всех индексов:
Вместо * можно указать неугодный индекс, например:
curl -XDELETE 'localhost:9200/winlogbeat-2016.02.10'
Для удаление старых логов не обходимо установить «питоновский» модуль:
Если pip не установлен, то устанавливаем:
Посмотерть статус работы Elasticsearch:
Этого достаточно чтобы запустить полноценный лог-сервер, раскидать на клиенты транспортёры и понять принципы.
Дополнительные настройки (оптимизация, настройки geoip и т.д.) описаны в официальной документации и конфигах.
Учебное пособие по созданию платформы управления журналами ELKF (2) - механизм сбора данных в режиме реального времени (Logstash)
Эта статья является учебным пособием по созданию платформы управления журналами ELKF (2) - Механизм сбора данных в реальном времени (Logstash). Чтобы следовать предыдущей статье, нажмите на портал:
В предыдущей статье мы представили инструмент передачи журналов Filebeat и указали вывод Filebeat на Logstash 192.168.3.203:5044, поэтому нам нужно настроить Logstash на этом компьютере 192.168.3.203:5044 для сбора журналов, передаваемых Filebeat в режиме реального времени. информация. Кто-то спросил меня, что и Logstash, и Filebeat выполняют сбор журналов. В чем разница между ними? Есть несколько моментов: Filebeat более легкий, чем Logstash, занимает меньше ресурсов ЦП, а Logstash имеет функцию фильтрации журналов, поэтому обычно при кластеризации мы настраиваем Filebeat на каждом компьютере для сбора данных. Затем перенесите его в Logstash для фильтрации журналов (Logstash также можно использовать для конфигурации кластера), и отфильтрованный журнал передается в ElasticSearch для сохранения. Затем Kibana получает журналы, которые не могут быть модульными, запрашивая разные индексы в другом ElasticSearch. информация.
I. Введение в Logstash
Logstash - это механизм сбора данных с открытым исходным кодом с возможностью конвейерной работы в реальном времени. Logstash может динамически унифицировать данные из разных источников данных и стандартизировать данные по выбранному вами месту назначения.
Схема приложения Logstash выглядит следующим образом:

Данные часто существуют во многих системах в различных формах, распределенных или централизованно. Logstash поддерживает множество вариантов ввода для одновременного захвата событий из многих общих источников. Возможность легко собирать данные из ваших журналов, метрик, веб-приложений, хранилищ данных и различных сервисов AWS в непрерывном потоке.
Во-вторых, подготовить к работе
Сначала подготовьте Filebeat, встроенный в предыдущую статью, затем перейдите на официальный сайт, чтобы загрузить установочный пакет Logstash и загрузить его на сервер.
Этот столбец основан на последней версии официального сайта. Версия Logstash - 7.1.1, как показано на рисунке:

Развертывание Logstash
Я загрузил установочный пакет Logstash в / usr / local, как показано ниже:
Что такое ELK?
Elasticsearch
Elasticsearch — это поисковый сервер и хранилище документов основанное на Lucene, использующее RESTful интерфейс и JSON-схему для документов.
Logstash
Logstash – это утилита для управления событиями и логами. Имеет богатый функционал для их получения, парсинга и перенаправления\хранения.
Kibana
Kibana – это веб-приложение для визуализации и поиска логов и прочих данных имеющих отметку времени.
Установка Ubuntu 14.04
Дабы не повторяться с установкой дистрибутива Ubuntu 14.04 приведу ссылку на статью моего коллеги по блогу, Алексея Максимова — Настройка прокси сервера Squid 3.3 на Ubuntu Server 14.04 LTS. Часть 1. Установка ОС на ВМ Hyper-V Gen2 . Все действия по настройке можно проделать аналогичные, за исключением установки минимального UI и настройки второго сетевого интерфейса – его можно исключить на стадии создания виртуальной машины, ведь сервер будет находиться внутри периметра вашей сети.
Установка JAVA 7
Так как два из трех используемых продуктов написаны на JAVA нам придется его установить. Устанавливать будем Oracle Java 7, так как Elasticsearch рекомендует устанавливать именно его.
Добавляем Oracle Java PPA в apt:
И устанавливаем последнюю стабильную версию Oracle Java 7:
Проверить версию Java можно набрав команду
Установка Elasticsearch
Хотя документация по Logstash рекомендует использовать Elasticsearch версии 1.1.1, он прекрасно работает и с последней стабильной версией 1.3.1. Именно ее мы и установим.
Добавляем публичный GPG ключ в apt:
Создаем source list apt:
И устанавливаем Elasticsearch 1.3.1:
Базовая конфигурация Elasticsearch очень простая, нам нужно указать в файле конфигурации всего два параметра – имя кластера и имя ноды.
Открываем elasticsearch.yml:
И раcкомментируем строки “cluster.name: elasticsearch” и “node.name: «Franz Kafka»”. Вместо значений по умолчанию можно указать свои.
Создаем скрипты автозапуска elasticsearch:
Перед стартом сервера я рекомендую установить еще два плагина к elasticsearch – head и paramedic. Первый позволяет управлять сервером поиска и индексами документов, второй следит за “здоровьем” пациента, выводя графики с различной полезной информацией.
Плагины к elasticsearch устанавливаются с помощью команды plugin прямо из github:
После чего можно запускать сам сервер:
Установка Kibana
Так как Kibana это веб-приложение, перед его установкой нужно установить веб-сервер. Я воспользовался простейшим nginx.
Создаем папку www для будущего приложения:
Даем nginx права на папку:
Скачиваем последний архив с файлами Kibana (на настоящий момент это kibana-3.1.0.tar.gz):
И копируем его содержимое в папку /var/www:
Скачиваем файл конфигурации для работы Kibana под nginx:
Открываем его в редакторе nano и указываем в какой папке лежат файлы Kibana:
Заменяем строку
root /usr/share/kibana3;
на строку
root /var/www;
Копируем данный файл как файл по умолчанию для nginx:
И перезапускаем nginx:
Для этого нужно заменить файл дашборда по умолчанию на файл дашборда Logstash:
Основные настройки Kibana находятся в файле config.js по адресу /var/www/config.js, однако “из коробки” все работает замечательно.
Установка Logstash
Добавляем source list Logstash в apt:
И устанавливаем Logstash:
Для текущей задачи, мною была написана следующая простая конфигурация:
Создадим файл в папке конфигураций Logstash
И поместим туда следующую конфигурацию
output elasticsearch cluster => "elasticsearch"
node_name => "Franz Kafka"
>
>
Разберем по порядку:
В разделе input
tcp <> — открывает tcp порт и слушает его
type => “eventlog” говорит Logstash что на входе будут данные типа eventlog (известный формат полей для Logstash)
port => 3515 – номер потра
format => ‘json’ – говорит Logstash о том, что данные придут “обернутые” в JSON
Никаких манипуляций с логами я не совершаю, потому раздел filter у меня пустой. Хотя если Вам будет необходимо, к примеру, привести дату к нужному формату, или убрать из лога одно или несколько полей, то в данном разделе можно эти манипуляции описать.
В разделе output
elasticsearch <> – оправляет данные в elasticsearch
cluster => “elasticsearch” – указывает на имя кластера, что мы указывали при конфигурировании Elasticsearch
node_name => “Franz Kafka” – указывает на имя ноды.
Сохраняем файл и запускаем Logstash
Можно проверить что порт tcp 3515 слушается командой:
Установка nxlog
Устанавливаем на нужной Windows машине данный клиент. Настройки он хранит в файле nxlog.conf по адресу по умолчанию “c:\Program Files (x86)\nxlog\conf\” (для 32-битной версии “c:\Program Files\nxlog\conf\”).
Для решения данной задачи я написал конфигурационный файл следующего содержания:
Moduledir %ROOT%\modules
CacheDir %ROOT%\data
Pidfile %ROOT%\data\nxlog.pid
SpoolDir %ROOT%\data
LogFile %ROOT%\data\nxlog.log
<Extension json>
Module xm_json
</Extension>
<Output out>
Module om_tcp
Host 10.0.2.8
Port 3515
</Output>
В разделе Output указывается модуль om_tcp для отправки данных по протоколу tcp, указывается хост и порт подключения.
Раздел Route служит для указания порядка выполнения действий, так как клиент nxlog умеет читать из множества источников и отсылать во множество приемников. Все это можно подчерпнуть из документации к продукту.
Настроив конфигурационный файл не забудьте его сохранить и можно запускать клиент через оснастку Службы (Services) или через командную строку:
Использование
Открыв в браузере Kibana (и перейдя на дашборд Logstash, если он у Вас не по умолчанию) мы увидим после всего проделанного следующую картину.

Центральный график на дашборде отражает количество записей в единицу времени. Сверху находится строка запроса и панель управления дашбордом. В нижней части таблица с данными.
Обратив свое внимание на таблицу данных мы увидим что данные показаны в “сыром” виде, однако слева от таблицы есть список полей. Щелкнув последовательно по чекбоксам с полями EventID, EventTime, EventType, Hostname, Sevirity, Message, Channel, мы получим уже более читабельный вид таблицы:

Просмотрев логи я вижу что в основном это логи из раздела Security, хочется понять какие приложения создают данные записи. Изучив список полей я нахожу поле ProcessName, если по нему кликнуть мышкой, то откроется интересное меню микроанализа по полю в котором будет перечислен TOP10 по количеству записей от процесса с их именами.

Если кликнуть по символу лупы рядом с именем процесса, то создастся фильтр по этому имени.

А данные в таблице отобразятся в соответствии с фильтрами.
Кликнув в таблице по любой записи можно развернуть ее в детальный вид, где будет видно все поля записи. Например так:

Ну и наконец если я просто хочу поискать по всем полям словосочетание “System Center” в поле запроса я пишу “System Center”. В случае поиска по конкретному полю можно воспользоваться конструкцией FieldName:”SearchQuery”, например ProcessName:»System Center». Что бы исключить из выборки данные найденные с помощью конструкции можно воспользоваться оператором “-“, например -ProcessName:»System Center» или -“System Center”. Так же работают операторы OR и AND.
Существует множество хороших средств централизованного ведения журналов, которые изменяются по затратам от бесплатных средств с открытым исходным кодом до более дорогостоящих вариантов. Во многих случаях бесплатные инструменты должны быть как или более надежными, чем оплаченные предложения. Одним из таких инструментов является сочетание трех компонентов с открытым исходным кодом: Эластичный Поиск, Logstash и Kibana.
Вместе эти средства называются стеком эластичных баз данных или ELK.
Эластичный стек
Эластичный стек — это мощный вариант для сбора информации из кластера Kubernetes. Kubernetes поддерживает отправку журналов в конечную точку Elasticsearch, и в большинстве случаеввсе, что необходимо для начала работы, — задать переменные среды, как показано на рис. 7-5:
Рис. 7-5. Переменные конфигурации для Kubernetes
Этот шаг устанавливает Elasticsearch в кластере и целевой объект, отправляя в него все журналы кластера.

рис. 7-6. Пример панели мониторинга Kibana, в которой показаны результаты запроса к журналам, принимаемым из Kubernetes
Каковы преимущества эластичного стека?
Эластичный стек обеспечивает централизованное ведение журналов с экономичным, масштабируемым и облачным способом. Его пользовательский интерфейс упрощает анализ данных, позволяя тратить время на получение ценных сведений из данных вместо борьбы с интерфейсом неуклюжим. Он поддерживает широкий спектр входных данных, так как распределенное приложение охватывает больше и разных типов служб, поэтому вы можете продолжать работать с данными журналов и метрик в системе. Эластичный стек также поддерживает быстрый поиск даже в больших наборах данных, что делает возможным даже для больших приложений запись подробных данных в журнал и по-прежнему иметь возможность видеть их в удобном для себя виде.
Logstash
Logstash будет использовать конфигурацию, подобную показанной на рис. 7-8.
Рис. 7-8. Конфигурация Logstash для использования журналов из Serilog
Для сценариев, в которых не требуется много операций с журналами, существует альтернатива Logstash, известного какнезначительное. Ритм — это семейство средств, которое может собирать разнообразные данные из журналов в данные сети и сведения о времени работы. Многие приложения будут использовать как Logstash, так и ритмы.
После того, как журналы собраны с помощью Logstash, им нужно поместить их в любое место. Хотя Logstash поддерживает множество различных выходов, одна из самых интересных — эластичный Поиск.
Эластичный поиск
Эластичный Поиск — это мощная поисковая система, которая может индексировать журналы по мере их поступления. Он позволяет быстро выполнять запросы к журналам. Эластичный Поиск может обрабатывать огромные объемы журналов, и в крайних случаях их можно масштабировать на нескольких узлах.
Рис. 7-9. Запрос Elasticsearch для поиска 10 ведущих страниц, посещенных пользователем
Визуализация информации с помощью веб-панелей мониторинга Kibana
Последним компонентом стека является Kibana. Это средство используется для предоставления интерактивных визуализаций на веб-панели мониторинга. Панели мониторинга могут создаваться даже пользователями, которые не являются техническими. Большинство данных, находящихся в Elasticsearch индексе, могут быть добавлены на панели мониторинга Kibana. Отдельные пользователи могут иметь разную панель мониторинга, и Kibana обеспечивает эту настройку, позволяя пользователям просматривать панели мониторинга.
Установка эластичного стека в Azure
Эластичный стек можно установить в Azure множеством способов. Как всегда, можно подготавливать виртуальные машины и устанавливать эластичный стек на них напрямую. Этот вариант является предпочтительным для некоторых опытных пользователей, так как он обеспечивает наивысшую степень настройки. При развертывании на основе инфраструктуры в качестве службы вы узнаете о значительных затратах на управление, которые применяют этот путь, чтобы стать владельцем всех задач, связанных с инфраструктурой, таких как обеспечение безопасности компьютеров и обновление исправлений.
Параметр с меньшими издержками заключается в использовании одного из многих контейнеров DOCKER, для которых уже настроен эластичный стек. Эти контейнеры можно удалить в существующий кластер Kubernetes и запустить вместе с кодом приложения. Контейнер себп/Elk — это хорошо документированный и протестированный контейнер эластичного стека.
Читайте также: