
Linux как посмотреть планировщик ввода вывода
Обновлено: 03.07.2024
Настройка Linux I / O Scheduler для твердотельных накопителей
Я собираюсь поговорить о настройке планировщика ввода-вывода Linux для увеличения пропускной способности и уменьшения задержки на SSD. Я также затрону еще одну интересную тему о настройке производительности NuoDB, указав хранилище для архива и каталогов журналов.
Настройка планировщика ввода-вывода Linux
Linux дает вам возможность выбрать планировщик ввода / вывода. Планировщик также может быть изменен без перезагрузки! В этот момент вы можете спросить: «Зачем мне вообще менять планировщик ввода-вывода?» Изменение планировщика имеет смысл, когда затраты на оптимизацию ввода-вывода (переупорядочение запросов ввода-вывода) не нужны и дороги. Этот параметр должен быть точно настроен для каждого устройства хранения. Лучшая настройка для SSD не будет хорошей настройкой для HDD.
Текущий планировщик ввода / вывода можно просмотреть, введя следующую команду:
Текущий планировщик ввода / вывода (в скобках) для / dev / sda на этом компьютере — CFQ , полностью честная очередь. Этот параметр стал стандартным в ядре 2.6.18 и хорошо работает для жестких дисков. Однако твердотельные накопители не имеют вращающихся пластин или магнитных головок. Алгоритмы оптимизации ввода / вывода в CFQ не применяются к твердотельным накопителям. Для твердотельных накопителей планировщик ввода-вывода NOOP может уменьшить задержку ввода-вывода и увеличить пропускную способность, а также исключить время ЦП, затрачиваемое на переупорядочение запросов ввода-вывода. Этот планировщик обычно хорошо работает на SAN, SSD, виртуальных машинах и даже на модных картах ввода-вывода Fusion. В этот момент вы, вероятно, думаете: «Хорошо, я продан! Как мне уже изменить планировщик?» Вы можете использовать команду echo, как показано ниже:
Чтобы увидеть изменения, просто перезапустите планировщик.
$ cat /sys/block/sda/queue/scheduler [noop] anticipatory deadline cfq
Обратите внимание, что noop теперь выбран в скобках. Это изменение носит временный характер и будет сброшено к планировщику по умолчанию, в данном случае CFQ, когда машина перезагрузится. Вам нужно отредактировать конфигурацию Grub, чтобы сохранить настройки навсегда. Однако это изменит планировщик ввода-вывода для всех блочных устройств. Проблема в том, что NOOP не является хорошим выбором для HDD. Я бы только навсегда изменил настройку, если бы на машине были только SSD.
На этом этапе вы изменили планировщик ввода-вывода на NOOP. Как вы знаете, если это имеет значение? Вы можете запустить сравнительный тест и сравнить числа (просто не забудьте очистить кэш файловой системы). Другой способ — взглянуть на вывод iostat. Запросы ввода-вывода проводят меньше времени в очереди с планировщиком ввода-вывода NOOP. Это можно увидеть в поле «await» от iostat. Вот пример более крупной операции записи с NOOP.
| Прибор: | SDA |
| rrqm / с | 0,00 |
| wrqm / с | 143819,00 |
| R / S | 6,00 |
| ж / с | 2881,00 |
| RKB / с | 24,00 |
| ВКБ / с | 586800,00 |
| avgrq-SZ | 406,53 |
| avgqu-SZ | 0,94 |
| Ждите | 0,33 |
| r_await | 3,33 |
| w_await | 0,32 |
| svctm | 0,11 |
| % Util | 31,00 |
Настройка производительности NuoDB
Чтобы настроить этот параметр, нам нужно создать каталог nuodb на SSD:
SSD в этом примере имеет точку монтирования / ssd на этом компьютере. Легко, правда? Я предполагаю, что вы уже установили планировщик ввода-вывода Linux для SSD на NOOP. Следующим шагом является настройка NuoDB для использования этого пути при создании каталога журнала. Журнал имеет прямую корреляцию с пропускной способностью транзакции, поскольку журнал должен завершить запись на диск, прежде чем SM отправит ACK для подтверждения транзакции в TE. Как насчет архива? Архив отделен от фиксации транзакции, атомы останутся в памяти и постепенно попадут на диск. Это будет очень мало влиять на TPS базы данных. В результате каталог архива можно разместить только на обычном жестком диске. Краткое руководство по настройке производительности — поместить журнал на SSD, а архив можно поместить на жесткий диск.
Важным моментом этой настроенной конфигурации является то, что только журнал находится на SSD. В результате твердотельный накопитель не обязательно должен быть одним из этих огромных дисков с ТБ. Стоимость твердотельных накопителей значительно упала в цене, и для данных журнала достаточно одного твердотельного накопителя емкостью 128 или 256 ГБ. Эта конфигурация должна соперничать с локальной эффективностью фиксации, которая является потрясающей, учитывая, что это самый высокий уровень долговечности! Я призываю вас попробовать и задать несколько вопросов.
Не так давно появилась информация, что планировщик BFQ разработчики подготавливают к внесению в основную ветку ядра. В связи с этим я решил сделать обзор планировщиков и провести бенчмарки, чтобы понять, в каких ситуациях выгоднее использовать тот или иной из них.
Введение
Для начала вспомним, что такое планировщик ввода/вывода. Он отвечает за распределение дисковых операций по процессам. В ранних ядрах Linux (как минимум в ядре 2.4) существовал только один планировщик — Linus Elevator. Он был слишком примитивным, и поэтому в ядре 2.6 появились еще три планировщика, часть из которых ныне уже ушла в небытие. Таким образом, сейчас в ядре существует три планировщика, а в ближайшее время, возможно, прибавится еще и четвертый:
- NOOP — наиболее простой планировщик. Он банально помещает все запросы в очередь FIFO и исполняет их вне зависимости от того, пытаются ли приложения читать или писать. Планировщик этот, тем не менее, пытается объединять однотипные запросы для сокращения операций ввода/вывода.
- CFQ был разработан в 2003 году. Заключается его алгоритм в следующем. Каждому процессу назначается своя очередь запросов ввода/вывода. Каждой очереди затем присваивается квант времени. Планировщик же циклически обходит все процессы и обслуживает каждый из них, пока не закончится очередь либо не истечет заданный квант времени. Если очередь закончилась раньше, чем истек выделенный для нее квант времени, планировщик подождет (по умолчанию 10 мс) и, в случае напрасного ожидания, перейдет к следующей очереди. Отмечу, что в рамках каждой очереди чтение имеет приоритет над записью.
- Deadline в настоящее время является стандартным планировщиком, был разработан в 2002 году. В основе его работы, как это ясно из названия, лежит предельный срок выполнения — то есть планировщик пытается выполнить запрос в указанное время. В дополнение к обычной отсортированной очереди, которая появилась еще в Linus Elevator, в нем есть еще две очереди — на чтение и на запись. Чтение опять же более приоритетно, чем запись. Кроме того, запросы объединяются в пакеты. Пакетом называется последовательность запросов на чтение либо на запись, которая идет в сторону б?льших секторов («алгоритм лифта»). После его обработки планировщик смотрит, есть ли запросы на запись, которые не обслуживались длительное время, и в зависимости от этого решает, создавать ли пакет на чтение либо же на запись.
- BFQ (Budget Fair Queueing) — относительно новый планировщик. Базируется на CFQ. Если не вдаваться в технические подробности, каждой очереди (которая, как и в CFQ, назначается попроцессно) выделяется свой «бюджет», и, если процесс интенсивно работает с диском, данный «бюджет» увеличивается.
Но, как говорится, не все грибочки одинаково полезны — планировщик для домашнего компьютера (который мы и попытаемся выбрать в статье) отличается от планировщика для сервера.
В FreeBSD имеется фреймворк (GEOM scheduler framework), позволяющий создавать планировщики ввода/вывода. На текущий момент, однако, на нем базируется только планировщик rr.
Подготовка
Первым делом скачаем ядро и наложим патч BFQ (на момент написания статьи существовал для ядер по версию 3.13 включительно):
Затем включим этот планировщик в Enable the block layer -> IO Schedulers (планировщик по умолчанию можно оставить стандартный — все равно их можно переключать как во время работы, так и используя опции ядра) и скомпилируем ядро:
Перед этим нужно убедиться, что в файле /etc/kernel-pkg.conf стоит многопоточная сборка (параметр CONCURRENCY_LEVEL в идеале должен быть равен количеству ядер процессора плюс один).

Включение планировщика BFQ в menuconfig
Следом же устанавливаем получившиеся пакеты:
Помимо ядра, нужно установить некоторые пакеты для собственно бенчмаркинга:
Наконец можно приступать к тестированию.

Установка Bonnie++
Тюнинг планировщиков
Как правило, планировщики не требуют тонкой подстройки. Однако если тебе захочется поэкспериментировать — такая возможность у нас есть. Рассмотрим некоторые параметры подстройки BFQ, находящиеся (в моем случае) в каталоге /sys/block/sda/queue/iosched:
- slice_idle — время ожидания поступления запросов (в миллисекундах). По умолчанию 8;
- quantum — число запросов ввода/вывода, передаваемых дисковому контроллеру за один раз (тем самым ограничивая длину очереди). Нужно соблюдать осторожность при его увеличении, поскольку при высокой нагрузке система может начать тормозить. По умолчанию 4;
- low_latency — для интерактивных процессов и процессов мягкого реального времени при значении по умолчанию пытается дать меньшую задержку, чем для других процессов. Процессы эти определяются эвристически;
- max_budget — максимальный бюджет для очереди, измеряющийся в секторах. Разумеется, этот бюджет применяется для очереди с учетом всех временных лимитов. Значение по умолчанию равно нулю и включает автоматическую подстройку данного параметра.
Тестирование
Прежде чем приступить к проведению бенчмарков, нужно рассказать о тестовом стенде. Железо: материнская плата ASUS Sabertooth 990FX R2.0, 16 Гб RAM, Seagate ST3000DM001-1CH166. ПО: Xubuntu 13.10 x64 с ядром 3.13.7. Также в моем случае имело смысл создать отдельный раздел как минимум вдвое большего объема, чем вся доступная оперативная память, что я и сделал, создав таковой в размере 35 Гб с файловой системой ext4. Сначала удостоверимся, что текущий планировщик для диска — Deadline, для чего наберем следующую команду:
Текущий планировщик выделяется квадратными скобками.
Первый бенчмарк, который я проведу, будет тест чтения с помощью утилиты hdparm — хотя предназначена она для тонкой подстройки параметров HDD, в ней есть и бенчмарк.
Для более точного результата лучше запускать эту команду три — пять раз.
Следующим бенчмарком будет тест с помощью команды dd. Этот тест тоже достаточно полезен для оценки производительности ввода/вывода, хоть и кажется примитивным.
Затем нужно будет очистить кеш, записав цифру 3 в файл /proc/sys/vm/drop_caches. Запись этой цифры в данный файл очищает как страничный кеш, так и кеш инод с dentry. Лишь после очистки можно будет запустить вторую часть теста:
Как и в случае с hdparm, обе части теста лучше запустить несколько раз.
Переходим к очередному тесту — им у нас будет распаковка архива с ядром. Скачиваем его и запускаем распаковку (опять же три — пять раз):
Следующий тест будет сделан с помощью утилиты Bonnie++, о которой стоит рассказать подробнее. Это крайне гибкий набор бенчмарков для тестирования производительности ввода/вывода. Операции с файлами, к сожалению, не сводятся только к последовательному чтению/записи одного файла или к распаковке архива, поэтому приведенные тесты не дают однозначного результата для всех ситуаций. Bonnie++ же, хоть и является синтетическим тестом, более реалистично симулирует обращения к подсистеме ввода/вывода. Так, в число тестов входит симуляция работы СУБД — в данном случае создается файл (либо файлы, если указан размер больший, чем 1 Гб) и производится как последовательное, так и рандомное чтение/запись, при этом чтение в несколько потоков. Помимо этого теста есть еще тест на создание/изменение/удаление тысяч маленьких файлов. Опции у данного приложения следующие:
- -d — каталог для работы программы;
- -s — размер файла в мегабайтах для первого теста (симуляция работы СУБД). Как я уже сказал, если размер будет указан больший, чем 1 Гб, файлов будет больше одного;
- -n — количество файлов для второго теста (симуляция работы Squid или какого-нибудь сервера электронной почты, использующего для хранения писем файлы). Формат аргумента таков: num:max_size:min_size:num_dirs, где num — количество файлов, кратное 1024, max_size и min_size — соответственно, максимальный и минимальный размер в байтах для создаваемых файлов (по умолчанию оба этих размера равны нулю, если же их установить, размер файлов будет задаваться рандомно), а num_dirs — количество каталогов, в которых файлы будут размещаться;
- -x — количество проходов тестов;
- -q — «тихий» режим. Кроме результатов теста и ошибок, ничего не выводится;
- -u — пользователь, под которым запускать тесты. Поскольку они сильно нагружают, пользователь root не рекомендуется — во избежание всяческих ошибок.
Итоговые команды будут следующими:
То есть запускаем пять проходов тестов в текущей директории с количеством файлов 115*1024, максимальным размером 25 381 байт, количеством каталогов 27 в «тихом» режиме. Затем нужно преобразовать этот самый CSV в удобочитаемый вид, для чего в составе пакета есть утилиты — можно преобразовывать как в txt, так и в HTML:
Напомню, что данные тесты нужно проводить на всех планировщиках, а не только на текущем. Для их переключения есть два способа. Первый способ — использовать параметр загрузки ядра elevator. При этом нужно будет редактировать файл /etc/default/grub и обновлять загрузочный конфиг GRUB. Второй способ не требует перезагрузки и состоит в указании планировщика через sysfs. Например, для указания планировщика CFQ на устройстве /dev/sda достаточно следующей команды:
Лично мне в конечном итоге оказалось проще написать скрипт, который запускает по пять проходов каждого теста (за исключением Bonnie++ — в нем указывается параметр -x) для каждого планировщика. Посмотрим же, что у нас получилось.

Скрипт для бенчмарка
Немного о процессе добавления BFQ в основную ветку ядра
Я начал работу над BFQ вместе с Фабио Чеккони (Fabio Checconi) в 2008 году. Фабио написал первую версию кода. Затем мы протестировали его, исправили ошибки и немного улучшили функционал. Мы думали, что этого будет достаточно для добавления в ядро:
Однако BFQ не приняли в основную ветку ядра, несмотря на позитивный отклик общественности. Причиной тому послужили замечания Дженса Аксбо (Jens Axboe). С одной стороны, он был обеспокоен сложностью движка планировщика, сетовал на то, что эта сложность обернется проблемами с поддержкой кода, если его добавят в ядро. С другой — он был убежден, что в Linux должен быть только один главный планировщик ввода/вывода. Им был (и есть) CFQ.
Хотя BFQ не вошел в ядро, некоторые продвинутые пользователи стали скачивать его с нашего сайта. BFQ также был включен в некоторые модифицированные ядра, например Zen Kernel.
Тем временем я наткнулся на одну занимательную ветку LKML по теме ввода/вывода. В ней обсуждалось время старта некоторых популярных приложений, таких как Firefox и терминал. Я был поражен, насколько оно может быть мало. По сути, такое время достигалось только при последовательном чтении соответствующего бинарного файла. Я вдохновился этой идеей и придумал новую фичу для планировщика: необходимо определять и давать привилегии интерактивным приложениям. После добавления этого и некоторых других незначительных улучшений я представил BFQ-v1 в июле 2010-го.
С этого момента BFQ начал набирать обороты: за прошедшие годы некоторые модифицированные Linux-ядра, Android-ядра, дистрибутивы Linux приняли BFQ в качестве планировщика по умолчанию или дополнительного планировщика (pf-kernel, многие ядра для Android, CyanogenMod, Sabayon, Gentoo Linux, Arch Linux, OpenMandriva, Rosa, ныне Manjaro). Кроме того, по моим данным, в течение последних нескольких лет каждый день планировщик скачивают несколько десятков пользователей разных дистрибутивов.
Между тем я продолжал добавлять новые функции и усовершенствования, например эвристические методы распознавания интерактивных приложений. Я добавил поддержку новых характеристик жестких дисков, например NCQ, а также оптимизировал работу с SSD. К счастью, в этой работе мне помогали такие хорошие люди, как Франческо Аллертсен (Francesco Allertsen), Мауро Андреолини (Mauro Andreolini) и особенно Арианна Аванцини (Arianna Avanzini). За несколько лет она внесла большой вклад в проект BFQ, разработала новые решения и подготовила патчи для множеств версий ядра.
Все расширения для правильной обработки новых устройств, которые Арианна и я добавили в BFQ, были до этого добавлены и в CFQ. Вместе с этим в CFQ появлялись некоторые другие полезные функции. Мы не только портируем все эти функции в BFQ, но и по возможности дорабатываем их для улучшения пропускной способности, времени отклика и быстроты исполнения. Так, нами был разработан унифицированный механизм обработки ввода/вывода QEMU для достижения высоких показателей пропускной способности.
Поддерживать такую высокую скорость разработки совсем не легко. Без поддержки Арианны проект, скорее всего, пришлось бы закрыть. Однако с выходом версии v7r3 мы в конце концов сделали это: теперь BFQ поддерживает весь спектр популярных устройств для хранения информации. Кроме этого, весь функционал, который я планировал реализовать, теперь работает стабильно. Наконец-то код выглядит зрелым и достаточно стройным.
Вот почему я думаю, что сейчас BFQ готов для представления в LKML. С этой целью мы уже подготовили патчсет для ревью. Но, прежде чем приступить к добавлению в основную ветку, нам нужно закончить тестирование версии v7r3 и выпустить релиз. Надеюсь, мы сможем это сделать в ближайшую неделю.
Паоло Валенте (Paolo Valente), основатель планировщика BFQ
Анализ результатов тестирования
Поскольку написание статьи связано с планировщиком BFQ, сосредоточимся именно на нем.
Запись с помощью dd у меня заняла в среднем 137,71 с, что, конечно, немного больше, чем при использовании планировщика Deadline (в среднем 136,89 с), но меньше, чем при использовании других планировщиков, — например, при сравнении с CFQ BFQ опережает его почти на 4 с.
Чтение же с помощью dd столь значительной разницы не показало. Тем не менее в этом тесте BFQ впереди планеты всей, а CFQ опять аутсайдер.
Тесты с помощью hdparm (чтение как из кеша, так и из дискового буфера) по неизвестным причинам вывели на первое место планировщик Deadline. Впрочем, полагаться на результат именно этого теста особого смысла нет — выглядит он слишком уж синтетическим.
Замер общего времени выполнения распаковки ядра с помощью команды time снова вывел BFQ на второе место — хотя и этот тест выглядит не менее синтетическим, чем предыдущий.
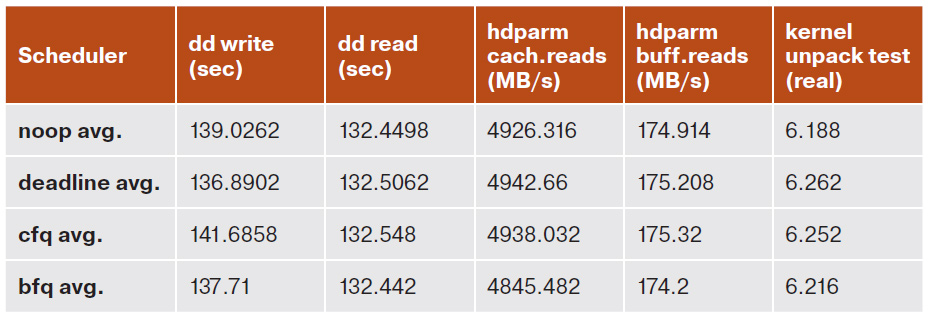
Таблица результатов моих собственных тестов
А теперь перейдем к результатам Bonnie++. Результатов там много, но я покажу только самые основные. Рассматривать я буду исключительно максимальную задержку для одной операции (опять же усредненную). При использовании функции putc() задержка у нашего кандидата на включение в ядро составляет 12 901 мкс, что выводит его на первое место. То же самое можно сказать и про запись блока — при данном тесте BFQ вырывается далеко вперед. А вот при чтении блока выигрывает CFQ с его 9082,6 мкс, BFQ же в этом тесте (как и в тесте на перезапись блока) стоит на втором месте. В тесте последовательного создания файлов BFQ на втором месте, зато в тестах рандомного создания/удаления он вновь лидирует.
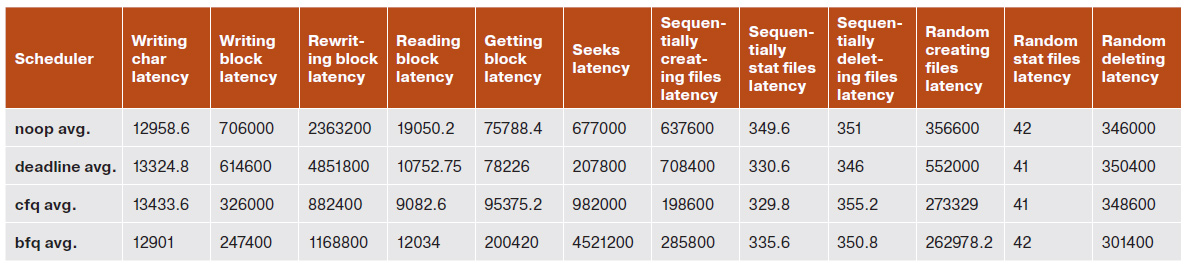
Таблица результатов (среднее значение задержки) для Bonnie++
Как видим, в среднем BFQ уверенно занимает первое-второе место. К сожалению, у меня нет возможности проверить SSD-накопители, так что трудно сказать, какой из планировщиков подходит в случае их использования, но для жестких дисков BFQ определенно неплох, так что его можно смело включать в качестве планировщика по умолчанию на большинстве домашних компьютеров.
Введение
Наверняка всем известно, что ядро Linux является очень сложным. Оно может работать на широком спектре имеющегося оборудования: во встраиваемых устройствах (в том числе и тех, которые нуждаются в операционных системах реального времени), портативных устройствах, ноутбуках, рабочих станциях, серверах общего назначения, серверах баз данных, видео-серверах, DNS-серверах, на суперкомпьютерах различного масштаба, и т.д. Системы разного назначения предъявляют к ядру системы самые разные и порой противоречивые требования. Некоторые из них требуют, что система должна быть отзывчивой на все действия пользователя, не прерывая музыку, видео или работу прочих приложений, требующих внимания пользователя. В то же время, обязательно существуют требования к хорошей производительности системы ввода-вывода и для некоторых сфер применения эти требования очень высокие. Для обеспечения сбалансированного распределения ресурсов между пользователями и разными процессами, в ядре Linux используется концепция планировщиков.
Планировщики предназначены именно для того, о чем говорит их название - они планируют различные операции внутри ядра системы. Поскольку в данной статье мы рассматриваем только ввод-вывод, то и под термином «планировщик» далее будет пониматься только планировщик ввода-вывода. Далее будет рассмотрена общая концепция планировщиков ввода-вывода и возможные их параметры.
Основные идеи, заложенные в планирование ввода-вывода
Практически все приложения на Linux используют какие-либо операции ввода-вывода. Даже такое с виду простое занятие как веб-серфинг производит большое количество маленьких файлов, которые записываются на диск. Без планировщик, каждый раз когда происходит запрос на ввод-вывод, происходило бы взаимодействие с ядром и такие операции бы выполнялись немедленно. Более того, может возникнуть такая ситуация, когда вы можете получить огромное количество запросов на ввод-вывод, которое (чтобы удовлетворить все запросы пользователя) заставит головки диска буквально метаться по нему стороны в сторону. Еще важнее то, что со временем разница между производительностью жестких дисков и остальной системы выросла очень быстро, что означает предъявление ещё больших требований к вводу-выводу для обеспечения общей высокой производительности системы. Так, когда ядро должно обслужить прерывание — приостанавливается работа всех остальных приложений. Поэтому, со стороны это может выглядеть как снижение отзывчивости системы или даже как замедление ее работы.
Так каким же образом следует спланировать обслуживание запросов на ввод-вывод, чтобы при этом обеспечить высокую скорость и не жертвовать отзывчивостью системы? Ответ на данный вопрос, как и большинство других вещей, зависит от общей загрузки и назначения системы. В одних случаях было бы здорово производить операции ввода-вывода параллельно с другими. В других случаях, необходимо производить ввод-вывод как можно быстрее. Концепция планирования ввода-вывода (на самом деле это довольно старая концепция) и появилась для того, чтобы найти баланс между этими двумя крайними состояниями таким образом, чтобы одна операция не прерывала другую (по крайней мере, до тех пор пока это явно не будет нужно вам).
Планирование событий ввода-вывода несет в себе необходимость решения многих вопросов. К примеру, планировщику необходимо хранить поступившие запросы в специальной очереди. Каким образом он будет хранить эти события, возможно ли будет изменить порядок событий, сколько времени будут хранится эти события, будут ли выполняться все сохранённые события по достижению определенных условий или с какой-то периодичностью - все это очень важные аспекты работы планировщика. От того как именно реализованы перечисленные аспекты работы планировщика зависит общая производительность работы системы ввода-вывода и то, как воспринимается эта система пользователями.
Самое главное с чего следует начать при рассмотрении архитектуры планировщика или настройки существующих планировщиков — это определение назначения, функций и роли системы. Например, целевая система — рабочая станция, которая используется в основном для веб-серфинга, иногда для просмотра видео и/или прослушивания музыки, и может быть даже игр. Задача кажется простой, но тем не менее имеет свои подводные камни. Например, если вы смотрите видео, слушаете музыку или играете в игру, вы скорее всего не хотите, чтобы при этом возникали какие-то задержки или пропадали какие-то кадры, видео бы постоянно прерывалось и показывалось бы рывками. Или, как только вы приготовитесь снести голову какому-нибудь зомби-мутанту, система подвиснет как раз в момент вашего выстрела и когда она снова возобновит работу, вдруг окажется, что зомби уже опередил вас и ваш герой убит. И хотя «заикание» во время воспроизведения какой-нибудь музыки вполне может быть частью жанра, в большинстве случаев это сильно раздражает. Поэтому, если ваша целевая система представляет собой рабочую станцию, Вы возможно захотите как можно меньше задержек в ее работе и это имеет огромное влияние на алгоритм работы планировщика.
Одним из важных преимуществ, которое планирование ввода-вывода дает системе — является хранение различных событий в очереди и даже возможность ее (очереди) изменения для совершения отдельных операций ввода-вывода быстрее других. Поскольку скорость операций ввода-вывода может оказаться значительно медленнее, чем в других частей системы, перераспределение запросов на обращение к диску таким образом, чтобы минимизировать перемещение головок диска может повысить общую производительность работы системы. Новые файловые системы тоже могут работать с учетом некоторых из этих концепций, поэтому они вполне могут сами оптимизировать операции ввода-вывода с точки зрения скорости работы устройства хранения данных. Вы даже можете путем настройки самого планировщика эффективнее адаптировать систему к необычным свойствам SSD (твердотельные накопители не имеют головок чтения-записи по сравнению с традиционными жесткими дисками — прим. перев.).
Есть несколько типичных методов, которые используются планировщиками ввода-вывода:
Слияние запросов: в рамках этой техники, запросы на чтение-запись схожего назначения объединяются для сокращения количества дисковых операций и увеличение длительности системных вызовов ввода-вывода (что, как правило, приводит к повышению производительности самого ввода-вывода).
«Алгоритм лифта»: Запросы ввода-вывода упорядочиваются исходя из физического размещения данных на диске таким образом, чтобы головки диска как можно больше перемещались в одном направлении и как можно более упорядоченно.
Переупорядочение запросов: Эта техника переупорядочивает запросы на основе их приоритета. Алгоритм реализации данной техники зависит от конкретного планировщика.
Кроме того, почти все планировщики ввода-вывода учитывают фактор «ресурсного голодания», поэтому в итоге (рано или поздно) будут обслужены все запросы (имеется ввиду, что планировщик следит за тем, чтобы запрос на ввод-вывод слишком долго не находился в очереди, т.е. не «голодал» бы — прим.перев.).
- NOOP
- Anticipatory
- Deadline
- CFQ (Completely Fair Queuing — алгоритм полностью честной очереди)
Deadline IO Scheduler (планировщик предельных сроков)
Deadline IO Scheduler был написан Дженсом Аксбо (Jens Axboe), широко известным разработчиком ядра. Основополагающим принципом его работы является гарантированное время запуска запросов ввода-вывода на обслуживание. Он сочетает в себе такие возможности как слияние запросов, однонаправленный алгоритм лифта и устанавливает предельный срок на обслуживание всех запросов (отсюда и такое название). Он поддерживает две специальные «очереди сроков выполнения» (deadline queues) в дополнение к двум отдельным «отсортированным очередям» на чтение и запись (sorted queues). Задания в очереди сроков выполнения сортируются по времени исполнения запросов по принципу «меньшее время — более раннее обслуживание — ближе к началу очереди». Очереди на чтение и запись сортируются на основе запрашиваемого ими номера сектора (алгоритм лифта).
Данный планировщик действительно помогает пропускной способности в случаях чтения с секторов с большим номером блока (на внешних областях диска — прим.перев.). Операции чтения могут иногда заблокировать приложения, поскольку пока они выполняются, приложения ждут их завершения. С другой стороны, операции записи могут выполняться гораздо быстрее, поскольку они производятся в дисковый кэш (если только вы не отключили его использование). Более медленные операции чтения с внешних областей диска перемещаются к концу очереди, а более быстрые операции чтения с более близких областей поступят на обслуживание раньше. Такой алгоритм планировщика позволяет быстрее обслужить все запросы на чтение-запись, даже если существуют запросы на чтение с дальних областей диска.
Схема работы планировщика достаточно прямолинейна. Планировщик сначала решает какую очередь использовать первой. Более высокий приоритет установлен для операций чтения, поскольку, как уже упоминалось, приложения обычно блокируются при запросах на чтение. Затем он проверяет истекло ли время исполнения первого запроса. Если так — данный запрос сразу же обслуживается. В противном случае, планировщик обслуживает пакет запросов из отсортированной очереди. В обоих случаях, планировщик также обслуживает пакет запросов следующий за выбранным в отсортированной очереди.
Deadline scheduler очень полезен для некоторых приложений. В частности, в системах реального времени используется данный планировщик, поскольку в большинстве случаев, он сохраняет низкое время отклика (все запросы обслуживаются в короткий временной период). Также было отмечено, что он также хорошо подходит для систем баз данных, которые имеют диски без поддержки TCQ.
CFQ IO Scheduler (планировщик с полностью честной очередью)
CFQ (Completely Fair Queue — планировщик с полностью честной очередью) IO scheduler в настоящее время является планировщиком по умолчанию в ядре Linux. Он использует и слияние запросов и алгоритм лифта. При работе CFQ синхронно размещает запросы на ввод-вывод от процессов в ряд очередей на каждый процесс (per-process queues). Затем он выделяет отрезки времени (timeslices) для каждой очереди на доступ к диску. Длина отрезков времени и количество запросов в очереди, которые будут обслужены, зависит от приоритета ввода-вывода конкретного процесса. Асинхронные запросы от всех процессов объединяются в несколько очередей по одной на каждый приоритет.
Дженс Эксбо (Jens Axboe) является автором планировщика CFQ и включает то, что Дженс называет "алгоритмом лифта Линуса". Добавление данной возможности произошло при необходимости внесения функций для предотвращения «голодания процессов» в наиболее неблагоприятной ситуации, которая может произойти при чтении со внешних дорожек диска. Также приведенная ссылка указывает на хорошую дискуссию по разработке планировщика CFQ и сложностях его дизайна (также в нем обсуждается дизайн deadline scheduler — очень рекомендую это прочесть).
CFQ предоставляет пользователям (процессам) конкретного устройства хранения данных необходимое количество запросов ввода-вывода для определённого промежутка времени. Это сделано для многопользовательских систем, так как все пользователи в таких системах получат один и тот же уровень отклика. Более того, CFQ достигает некоторых из характеристик anticipatory scheduler по хорошей пропускной способности, поскольку позволяет обслуживаемой очереди простаивать какое-то время по завершению выполнения запроса на ввод-вывод в ожидании запроса, который может оказаться близким к только что выполненному запросу (и к тому же позволяет настройку своих параметров — прим. перев.).
Переключение планировщиков
Ядра Linux версии 2.6 фактически позволяют вам изменять планировщик ввода-вывода несколькими способами. Например, вы можете изменить планировщик по умолчанию для системы в целом используя опцию "elevator elevator=deadline” в строку, которая начинается словом «kernel».
Второй способ изменить планировщик позволяет менять его «на лету» для конкретных устройств. Например, вы можете определить, какой планировщик ввода-вывода используется, посмотрев содержимое файла ”/sys/block/[device]/queue/schedule
r”, где [device] — имя соответствующего устройства. Например, на моем ноутбуке:
Обратите внимание, что текущий планировщик - CFQ. Вы можете изменить планировщик командой echo передав ей имя желаемого планировщика и переадресовав ее вывод в соответствующий файл устройства - "/sys/block/[device]/queue/schedule r”. Например, я могу изменить планировщик на моем ноутбуке следующим образом:
Обратите внимание, теперь планировщик изменился на deadline. Когда мы меняем планировщик, «старый» планировщик выполняет все поступившие запросы, а затем ядро переключается на новый (правда же Linux великолепен?).
Заключение
Эта статья всего лишь краткое обозрение планировщиков ввода-вывода в Linux. Современные системы могут иметь большое число пользователей, интенсивную нагрузку на подсистему ввода-вывода, требовать высокий уровень отзывчивости, требования реального времени, плюс большое количество дисков и/или файловых систем. Именно здесь на помощь приходит планировщик ввода-вывода.
Планировщик ввода-вывода не является новой идеей, но тем не менее он очень важен. Эти планировщики могут быть разработаны для работы с системой ввода-вывода так как пожелаете вы. В настоящее время в ядре Linux существует четыре планировщика ввода-вывода: NOOP, deadline, anticipatory и CFQ. Различные аспекты их работы были обсуждены в этой статье на достаточно высоком уровне.
В этой статье не рассматривалась настройка различных планировщиков под конкретную нагрузку. Для ознакомления с этой темой вы можете изучить документацию, которая поставляется с исходниками текущего ядра. Например, на моем ноутбуке, документацию можно найти в каталоге /usr/src/linux-source-2.6.27/Documentati on/block. Кроме того, по настройке планировщиков в Интернет существует большое количество статей.
Одна простая вещь, которую вы можете сделать — это попробовать поменять планировщик ввода-вывода, связанный с определенным устройством (было рассмотрено выше). Это довольно легко сделать и может привести к некоторым интересным результатам (прозрачный намек ;) ).
Функционально сегодняшнее ядро Linux унифицировано, и при необходимости выставим нужные параметры собрать его как для рабочей станции, так и для суперкомпьютера или встроенного девайса. Многие требования у этих систем отличаются и причем весьма существенно. Наверное поэтому разработчики предлагают альтернативные варианты различных компонентов ядра. Сегодня разберемся с планировщиами ввода/вывода.
О чем собственно речь.
Вообще в любой системе можно выделить два типа планировщиков выполняющих свои задачи: планировщик процессорного времени и планировщик ввода/вывода. И хотя сегодня идет настоящая битва между разработчиками, предложившими за 2,5 года более 300 вариантов планировщиков CPU , а в ядре 2.6.23 стандартный O (1) проработавший 15 лет, будет (наконец то. ) заменен на более интерактивный CFS (Completely Fair Scheduler, абсолютно справедливый планировщик), трогать мы их пока не будем. Нас интересуют последние. Так планировщики ввода/вывода (I/O scheduler) являются прослойкой между блочными устройствами и драйверами низкого уровня, его задача планировщика оптимальным образом обеспечить доступ процесса к запрашиваемому дисковому устройству. Не смотря на всю кажущуюся простоту вопроса, это сложная и противоречивая задача. Работа с дисками относится к очень медленным операциям, имеющая к тому же долгое время поиска нужной информации, а процессов терпеливо ожидающих своей очереди может быть очень много. Поэтому алгоритм I/O scheduler должен с одной стороны уметь уменьшать время поиска информации на диске, ведь частое переключение между задачами приведет к тому, что головка диска будет большую часть времени будет просто переходить на разные позиции. Также I/O scheduler должен уметь выдавать информацию в соответствии с приоритетом и гарантировать получение данных приложению за определенное время и в нужном количестве.
Чтобы решить эти проблемы, в последнее время используются так называемые конвейерные (elevator) механизмы, в которых данные считываются не в порядке поступления запроса (FIFO, LIFO и других), а по возможности с ближайших секторов.
Планировщики I / O ядра 2.6
Планировщик ввода/вывода ядра 2.4 использует один сложный конвейер общего назначения. Хотя он и имеет достаточное количество параметров позволяющих управлять временем ожидания запроса в очереди, его возможностей все равно не хватает для более тонкой настройки под специфические задачи. После многочисленных дискуссий и экспериментов из всего многообразия предложенных разработчиками, в ядро 2.6 было включено уже 4 разных планировщика ввода/вывода, а пользователь может подобрать себе наиболее оптимальный исходя из планируемых задач. Узнать какие планировщики I/O включены в ядро, очень просто достаточно ввести команду:
$ dmesg | grep scheduler
[ 1.348000] io scheduler noop registered
[ 1.348000] io scheduler anticipatory registered
[ 1.348000] io scheduler deadline registered
[ 1.348000] io scheduler cfq registered (default)
В KUbuntu 7.10, как и в любом современном дистрибутиве включены все четыре. Алгоритм CFQ отмечен как default то есть используется по умолчанию, причем так обстоят дела практически во всех в современных дистрибутивах с ядром старше 2.6.18.
Чтобы увидеть все эти планировщики в новом ядре при самостоятельной его пересборке необходимо включить следующие параметры:
$ grep IOSCHED .config
Как вы понимаете последний параметр определяет алгоритм, который будет использоваться по умолчанию.

Кратко о планировщиках
Планировщик NOOP самый простой планировщик, обладает минимальными возможностями и выполняет только простые операции объединения и сортировки, но зато и потребляет минимум ресурсов. Он представляет собой очередь FIFO (First In, First Out) то есть он, просто выставляет запросы в очередь в том порядке, в котором они пришли. Предназначен NOOP в основном для работы с не дисковыми устройствами (ОЗУ или флэшдиск) или со специализированными решениями которые уже имеют свой собственный планировщик I/O. В этом случае его простота имеет преимущество перед остальными алгоритмами.
Планировщик Anticipatory (упреждающий конвейер) основан на Deadline, его алгоритм позволяет минимизировать перемещение головки по диску. Для этого перед запросом вводится некая управляемая задержка, при помощи которой достигается переупорядочение и объединение операций обращения к диску. Поэтому есть вероятность того, что предыдущий запрос успеет получить нужные данные, до того как головка диска будет вынуждена перейти на новый сектор. Хотя результатом работы Anticipatory может быть увеличение времени задержки выполнения операций ввода/вывода, поэтому его лучше всего использовать на клиентских машинах с медленной дисковой подсистемой, для которых более важна интерактивность работы, чем задержки ввода/вывода. Этот алгоритм использовался по умолчанию в ядрах 2.6.0 – 2.6.17.
И наконец CFQ (Completely Fair Queuing) появился как расширение к сетевому планировщику SFQ (stochastic fair queuing) предназначенного, который в свою очередь был одной из альтернатив упреждающего конвейера. Этот алгоритм был включен в ядро 2.6.6 в апреле 2004. В CFQ для каждого процесса поддерживается своя очередь ввода/вывода, а задача планировщика состоит в том, чтобы как можно равномерней распределять доступную полосу пропускания между всеми запросами. В последних применен принцип time slice, аналогичный используемому в планировщике процессов, поэтому он несколько стал похож на Anticipatory. Время выдаваемое каждому процессу на работу с устройством и число запросов зависит теперь и от приоритета. Поэтому CFQ идеально подходит для случаев, когда множество программ могут потребовать доступ к диску и для многопроцессорных систем, которым требуется сбалансированная работа подсистемы ввода/вывода с различными устройствами. За период развития ядра 2.6 алгоритм CFQ несколько раз совершенствовался и сегодня уже известна четвертая версия.
Изменение планировщика
noop anticipatory deadline [cfq]
Изменим cfq например на anticipatory :
$ sudo echo anticipatory > /sys/block/sda/queue/scheduler
Стоит помнить, что выбранный планировщик вступит в действие не сразу, а лишь через некоторое время. С выходом CFQ v3 в Linux 2.6.13 появилась возможность выставлять приоритеты использования дисковой подсистемы для процессов, чего раньше не хватало. Подобно утилите nice, которая используется для назначения приоритетов использования процессора, приоритеты ввода/вывода указываются при помощи ionice. В Ubuntu она входит в пакет schedutils. Синтаксис команды прост:
ionice -c класс -n приоритет -p PID
Приоритет число от 0 до 7 (меньшее соответствует большему приоритету). В позиции класс возможны три значения:
Вместо PID можно указывать имя процесса:
Небольшой эксперимент
Попробуем провести несколько тестов. Для начала запустим программу для тестирования dbench c имитацией работы 50 клиентов “dbench -t 60 50”. Получаем Cfg – 88,02 Мб/с, anticipatory – 81,14 Мб/с, Deadline – 134,66 Мб/с, noop – 63,15 Мб/с. Естественно все это прогонялось несколько раз, полученный результат усреднялся. Теперь другая утилита iostat (в Ubuntu требуется установить пакет sysstat), которая умеет показывать сколько блоков было прочитано и записано на диск. Запускаем:

$ time dd if=/dev/zero of=test bs=1024 count=1024000
Компьютер с Athlon X 2 и SATA диском показывал результаты, отличающиеся приблизитительно на 2-3 Мб/с, что можно отнести к погрешности измерения. Поэтому был взят старый системный блок с 633 Целероном и ATA диском. Здесь уже результаты интересней и говорят сами за себя. При Anticipatory файл был создан (вообще то скопирован) со скоростью 9,2 Мб/с, а при запущенном видео уже за 5,0 Мб/с. Выбрав NOOP я устал ждать, так как скорость составила 1,0 Мб/с, а с видео – 973 кб/с. При этом практически прекратилось воспроизведение фильма. Идем далее Deadline результат 8,9 и 7,5 Мб/с, и CFQ – 9,7 и 8,1 Мб/с
Результаты вроде понятны и без комментариев, но вообще однозначно сказать какой алгоритм лучше тяжело. В любом случае следует подбирать планировщик изходя из конкретных условий. Например, хотя Deadline и обогнал все остальные в первом тесте, но попытка запустить Amarok или сохранить файл, приведет к тому, что некоторое время придется подождать. А вообще выбор это всегда хорошо . Linux forever!

Главное меню » Linux » Как и когда менять планировщик ввода-вывода в Linux

Зачем использовать планировщик:
Так и есть, поскольку стандартные вращающиеся диски записывают информацию в зависимости от места на вращающемся диске. При доступе к данным с вращающегося диска фактический привод должен повернуть пластины в определенное положение, чтобы можно было прочитать информацию. Это называется «поиском», потому что это может занять гораздо больше времени с точки зрения вычислений. Планировщики ввода-вывода призваны помочь вам максимально эффективно использовать права доступа к диску. Мы делали то же самое, комбинируя транзакции ввода-вывода и отправляя их в соседние места на диске. Приводу даже не нужно так много «искать», когда запросы группируются в смежных частях диска, что улучшает среднее время отклика для операций с диском. В текущих архитектурах Linux доступно множество планировщиков ввода-вывода. У любого из них есть своя система для организации запросов доступа к диску.
Типы планировщиков:
Кажется, есть 3 типа планировщиков на выбор, каждый из которых имеет свой набор преимуществ в операционной системе Linux. Итак, вот список и объяснение каждого планировщика:
- CFQ (cfq): стандартный планировщик для многих дистрибутивов Linux; он объединяет одновременные запросы, сделанные операциями, в серию пулов для каждого процесса перед выделением временных интервалов для использования диска для каждой очереди.
- Планировщик Noop (noop): это самый простой планировщик ввода-вывода для ядра Linux, основанный на принципе пула FIFO. Этот планировщик хорошо работает с твердотельными накопителями.
- Планировщик крайнего срока (deadline): этот планировщик пытается обеспечить период начала обслуживания запроса.
Проверить текущий планировщик:
Прежде чем двигаться дальше, вы должны знать о планировщике ввода-вывода, настроенном в вашей текущей системе Linux. Во время реализации мы использовали систему Ubuntu 20.04 Linux, поэтому наш планировщик будет. Возможно, в вашей системе Linux может быть настроен другой планировщик ввода-вывода. Итак, войдите в свою текущую систему Linux, чтобы попробовать ее проверить. Теперь запустите оболочку терминала, используя простую комбинацию клавиш «Ctrl+Alt+T». Вы можете попробовать открыть оболочку терминала, используя область панели действий на рабочем столе Linux. Теперь терминал командной оболочки открыт, мы можем приступить к работе над ним. Прежде всего, мы должны войти в систему как пользователь sudo из терминала, чтобы работать эффективно и без перебоев. Итак, введите команду «su» в терминале для входа в систему. Она попросит вас ввести пароль вашей учетной записи sudo для входа с нее.
Теперь пора проверить и определить планировщик ввода-вывода в нашей системе Linux. Как вы знаете, в настоящее время мы работаем над системой Ubuntu 20.04 Linux, чтобы соответствовать ей, и мы должны проверить это, прочитав файл планировщика по его пути. Итак, мы должны опробовать приведенную ниже инструкцию cat в терминале оболочки вместе с указанием местоположения файла по пути и нажать кнопку «Enter» на пишущей машинке вашего компьютера.
Измените планировщик ввода-вывода:
Если пользователь системы Linux хочет изменить свой планировщик ввода-вывода на «Kyber», он должен сначала установить пакет «kyber» в свою систему Linux, выполнив два следующих шага. Необходимо выполнить приведенную ниже команду sudo с ключевым словом «modprobe» с именем планировщика «kyber-iosched».
Читать 12 вещей, которые нужно сделать после установки Linux-сервераТеперь «kyber» успешно настроен. Теперь вы можете включить «kyber», используя приведенную ниже команду планировщика «echo» вместе с ключевыми словами «sudo» и «tee», к которым привязан путь к планировщику. Выходное изображение представляет включенный планировщик «kyber».
Результат ниже показывает, что «kyber» установлен по умолчанию.
Чтобы изменить планировщик на планировщик «bfq», установите его с помощью следующей команды.
Теперь запустите ту же команду «cat».
Теперь, когда «bfq» установлен, включите его с помощью той же команды echo.
Проверьте планировщик по умолчанию «bfq» с помощью команды cat.
Заключение:
В этой обучающей статье описан простой способ изменить планировщик ввода-вывода с помощью двух разных планировщиков. Мы обсудили, почему система хочет изменить свой планировщик, надеясь, что это сработает для вас.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Читайте также: