
Megacli centos 7 команды
Обновлено: 07.07.2024
Пакетов для дебиан не нашел, поэтому придется распаковывать и устанавливать из rpm:
Создаем каталог:
mkdir -p /opt/MegaRAID/MegaCli
И копируем в него распакованные файлы:
cp ./opt/MegaRAID/MegaCli/* /opt/MegaRAID/MegaCli/
Копируем распакованную библиотеку в /usr/lib/ :
cp ./opt/MegaRAID/MegaCli/libstorelibir-2.so.14.07-0 /usr/lib/
Даем права на запуск:
cd /opt/MegaRAID/MegaCli/
chmod 755 MegaCli
chmod 755 MegaCli64
Создаем символическую ссылку:
ln -s /opt/MegaRAID/MegaCli/MegaCli64 /usr/bin/MegaCli
Проверяем установку:
MegaCli -v
Intel(R) RAID Command Line Utilities Version 2
Ver 8.07.14 Dec 16, 2013
(c)Copyright 2013, LSI Corporation, All Rights Reserved.
Информация о состоянии RAID
Состояние RAID можно получить следующей командой (отобразить все логические устройства всех контроллеров)
MegaCli -LDInfo -Lall -Aall
Вывод более краткой информации состояния дисков:
MegaCli -PDList -aAll | egrep "Enclosure Device ID:|Slot Number:|Inquiry Data:|Error Count:|state"
Enclosure Device ID: N/A
Slot Number: 0
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 000B6SJ81PKF
Enclosure Device ID: N/A
Slot Number: 1
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 000B6SJ85JKR
Enclosure Device ID: N/A
Slot Number: 2
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 000B6SJ85MBY
Enclosure Device ID: N/A
Slot Number: 4
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 000B6SJ81PJE
Enclosure Device ID: N/A
Slot Number: 5
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 000B6SJ81PH6
Enclosure Device ID: N/A
Slot Number: 6
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 000B6SJ81PJQ
Все хорошо если все диски Firmware state: Online .
Заменяем сбойный диск в массиве
Вытягиваем сбойный (номер слота сбойного диска можно определить командой MegaCli -PDList -aAll | egrep "Enclosure Device ID:|Slot Number:|Inquiry Data:|Error Count:|state"), вставляем новый.
Статус нового диска должен быть "Unconfigured (good)".
MegaCli -PDList -aAll | egrep "Enclosure Device ID:|Slot Number:|Inquiry Data:|Error Count:|state"
Enclosure Device ID: N/A
Slot Number: 0
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 000B6SJ81PKF
Enclosure Device ID: N/A
Slot Number: 1
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 000B6SJ85JKR
Enclosure Device ID: N/A
Slot Number: 2
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 000B6SJ85MBY
Enclosure Device ID: N/A
Slot Number: 4
Media Error Count: 0
Other Error Count: 0
Firmware state: Unconfigured(bad)
Inquiry Data: SEAGATE ST3300657SS 000B6SJ81PJE
Enclosure Device ID: N/A
Slot Number: 5
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 000B6SJ81PH6
Enclosure Device ID: N/A
Slot Number: 6
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 000B6SJ81PJQ
Если нет, как в нашем случае, статус диска "Unconfigured (bad)", то его надо сначала сделать пригодным для использования.
Проверяем метаинформацию другого, чужого RAID-массива (если диск раньше использовался) и удаляем ее.
MegaCli -CfgForeign -Scan -a0
где -a0 идентификатор рейд-железки.
MegaCli -CfgForeign -Clear -a0
Помечаем диск как "good":
MegaCli -PDMakeGood -PhysDrv [:4] -a0
где PhysDrv [E:S]:
E - Enclosure Device ID(можно посмотреть командой MegaCli -PDList -aAll | egrep "Enclosure Device ID:|Slot Number:|Inquiry Data:|Error Count:|state"). В моем случае он "N/A", значение пустое;
S - Slot Number, увидеть можно той же командой что и Enclosure Device ID;
Проверяем статус диска командой:
MegaCli -PDList -aAll | egrep "Enclosure Device ID:|Slot Number:|Inquiry Data:|Error Count:|state"
Статус должен измениться на Unconfigured(good), Spun Up
Теперь очищаем диск:
MegaCli -PDClear -Start -PhysDrv [:4] -a0
Смотрим статус очистки, ждем завершения:
watch MegaCli -PDClear -ShowProg -PhysDrv [:4] -a0
Clear Progress on Device at Enclosure N/A, Slot 4 Completed 17% in 4 Minutes.
Теперь даем команду замены диска в массиве:
MegaCli -PdReplaceMissing -PhysDrv[:4] -array1 -row1 -a0
где -array1 -row1 рейд массив №1(нумерация с нуля) и место №1(нумерация с нуля) которые можно узнать командой:
MegaCli -CfgDsply -a0 | more
Если диск отсутствует в массиве, запись "Physical Disk:" будет показана, но без дополнительно информации:
.
DISK GROUP: 1
.
(пустая строка)
Physical Disk: 1
(пустая строка)
.
И запускаем rebilding:
MegaCli -PDRbld -Start -PhysDrv [:4] -a0
Started rebuild progress on device(Encl-N/A Slot-4)
Exit Code: 0x00
Ждем окончания, смотря прогресс командой:
watch MegaCli -PDRbld -ShowProg -PhysDrv [:4] -a0
Rebuild Progress on Device at Enclosure N/A, Slot 4 Completed 9% in 2 Minutes.
Exit Code: 0x00
И еще немного о megacli.
И приоритет ребилдинга рейда (от 30 до 100):
Посмотреть:
MegaCli -AdpGetProp RebuildRate -a0
Adapter 0: Rebuild Rate = 30%
Exit Code: 0x00
Изменить:
MegaCli -AdpSetProp RebuildRate 75 -a0
Adapter 0: Set rebuild rate to 75% success.
Exit Code: 0x00
Всем привет сегодня хочу сделать для себя шпаргалку по синтаксису MegaCli. Напомню MegaCli это утилита командной строки для настройки RAID, на контроллерах LSI/Avago. Конечно большинство вещей можно делать с помощью MSM, но бывает очень полезно выполнить через консоль, особенно когда у вас какой-нибудь CentOS 7.6 или ESXI. Давайте изучать синтаксис утилиты.
Список команд MegaCli
-aN
Параметр -aN - ID адаптера, начинается с 0. Если у вас всего один контроллер вы можете использовать ALL.
-PhysDrv [E:S]
Используется для оперирования одним или несколькими жёсткими дисками. Где E - ID жёсткого диска, S - номер слота (начинается с 0).
Параметр -Lx используется для указания виртуального диска (Virtual Drive). Где x номер массива, нумерация с 0.
Получение информации
MegaCli -AdpAllInfo -aALL
MegaCli -CfgDsply -aALL
MegaCli -adpeventlog -getevents -f lsi-events.log -a0 -nolog
MegaCli -PDList -aALL
MegaCli -PDInfo -PhysDrv [E:S] -aALL
Check Battery backup warning on boot. If this is enabled on an MSP, it will require manual intervention every time the system boots
MegaCli -AdpGetProp BatWarnDsbl -a0
Управление контроллером
MegaCli -AdpSetProp AlarmSilence -aALL
MegaCli -AdpSetProp AlarmDsbl -aALL
MegaCli -AdpSetProp AlarmEnbl -aALL
- Disable battery backup warning on system boot
MegaCli -AdpSetProp BatWarnDsbl -a0
Virtual drive management
MegaCli -CfgSpanAdd -r10 -Array0[E:S,E:S] -Array1[E:S,E:S] -aN
Physical drive management
MegaCli -PDMarkMissing -PhysDrv [E:S] -aN
MegaCli -PdReplaceMissing -PhysDrv [E:S] -ArrayN -rowN -aN
The number N of the array parameter is the Span Reference you get using MegaCli -CfgDsply -aALL and the number N of the row parameter is the Physical Disk in that span or array starting with zero (it’s not the physical disk’s slot!).
- Rebuild drive - Drive status should be "Firmware state: Rebuild"
MegaCli -PDRbld -Start -PhysDrv [E:S] -aN
MegaCli -PDRbld -Stop -PhysDrv [E:S] -aN
MegaCli -PDRbld -ShowProg -PhysDrv [E:S] -aN
MegaCli -PDRbld -ProgDsply -physdrv [E:S] -aN
MegaCli -PDClear -Start -PhysDrv [E:S] -aN
MegaCli -PDClear -Stop -PhysDrv [E:S] -aN
MegaCli -PDClear -ShowProg -PhysDrv [E:S] -aN
MegaCli -PDHSP -Set -Dedicated -ArrayN,M. -PhysDrv [E:S] -aN
Walkthrough: Rebuild a Drive that is marked 'Foreign' when Inserted:
MegaCli -PDMakeGood -PhysDrv [E:S] -aALL
Set the drive offline, if it is not already offline due to an error
MegaCli -PDMarkMissing -PhysDrv [E:S] -aN
If you’re using hot spares then the replaced drive should become your new hot spare drive
In case you’re not working with hot spares, you must re-add the new drive to your RAID virtual drive and start the rebuilding
MegaCli -PdReplaceMissing -PhysDrv [E:S] -ArrayN -rowN -aN
MegaCli -PDRbld -Start -PhysDrv [E:S] -aN
Gathering Standard logs
On every instance of a hard drive problem with an MSP server, we need to run the following commands to have any information about the problem:
Довелось понастраивать сервер DELL T610 с рейд контроллером PERC H700 на борту. Все как обычно, кроме одного нюанса. Решил проверить, как оперативно выполнить замену сбойного диска. На сервер была установлена стандартная утилита mеgacli для управления всеми контроллерами с драйвером MegaRAID, к коим относится и упомянутый выше. Такая тривиальная задача оказалась не совсем тривиальной и пришлось поковыряться с документацией.
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужно пройти .У меня был сервер на Debian 8 с 3 рейдами, raid1, raid1, raid10. Я вытаскивал диск из raid10 и заменял его новым.
Обращаю внимание, это важно. Я вставлял обратно не тот же самый диск, как часто делают, а другой. Это принципиально разные события. Если вынуть диск, а потом его же поставить на место, то ребилд пойдет автоматом и делать ничего дополнительно не надо. Если же вы другой физический диск ставите, то нужно будет проделать все то, что я сейчас опишу.Сначала проверим состояние наших массивов:
Чувствуете хардкор? Еще нет? Тогда поехали дальше. Обращаю внимание, что последний массив помечен как Degraded, из него вынут диск. Это raid10. К сожалению, я так и не понял, как через megacli посмотреть тип массива. Где тут указано, что в массиве raid10, я не понял. Теперь посмотрим на список дисков:
Нас интересует последний диск. В Firmware state указано Unconfigured(good). Это я уже воткнул новый пустой диск, вместо старого. Если с диском будут какие-то проблемы, то его состояние будет Failed. Дальше вам важно запомнить следующие значения этого диска:
- Enclosure Device ID: 32
- Slot Number: 7
- DiskGroup: 2
Первые два - ID и номер слота жесткого диска. Они нам нужны в дальнейших командах для обозначения диска. Последнее, судя по всему, принадлежность к номеру DiskGroup в описании массива. Я не уверен в этом на 100%, но в моем случае эти данные для всех дисков и массивов показывали полное совпадение. Скорее всего это так. Проверьте по этой цифре, точно ли сбойный диск принадлежит к тому массиву, о котором вы думаете.
Я немного забежал вперед и поторопился с заменой диска. Я вытащил диск, загрузил сервер, убедился, что он работает без диска и что массив понимает, что он находится в состоянии Degraded. После этого мне нужно было бы выполнить следующие команды.
Отключить сбойный диск:
Пометить его как отключенный:
Я это не сделал, а просто выключил сервер и установил новый диск. После включения убедился, что новый диск присутствует в списке дисков и его статус Unconfigured(good). После этого я указываю контроллеру, что диск заменен:
Над этой командой я долго ломал голову. Расскажу по порядку, что тут к чему.
Array3. Откуда взялась цифра 3? Вот описание:
"The number N of the Array parameter is from the "Span Reference:" line you get using MegaCli -CfgDsply -aALL, minus the 0x0 part."
Выполняем команду просмотра конфигурации:
Получается такая простыня, которую очень трудно читать и анализировать. Грепаю вывод, чтобы разобраться, что тут вообще выходит:
Вижу, что у меня 4 конфигурации, хотя массива только 3. Рассуждаю логически. Так как последний массив это RAID10, то наверно он отображается как 2 RAID1. Проверил внимательно вывод конфигурации, убедился, что так оно и есть. Первые 2 рейда обозначены как DISK GROUP: 0 и 1, а raid10 как SPANNED DISK GROUP: 0, в котором соответственно SPAN: 0 и 1. Один из SPAN имеет статус Degraded и параметр Span Reference: 0x03. Судя по документации, мне надо взять это число 0x03 и отбросить 0x0. Получается цифра 3 и параметр Array3 в команде.
Дальше следует параметр row. Я очень старался понять что это такое :) Описание:
"The number N of the row parameter is the Physical Disk in that span or array starting with zero (it can be but is not always the physical disk’s slot!)".
Только сейчас, когда пишу статью, легко понимаю, откуда берется эта цифра. А когда тестировал сильно тупил и никак не мог сообразить. Сильно мешает очень объемный вывод команд. Я устал глазами бегать по простыням. В общем, это номер диска в сбойном SPAN. В моем случае это второй диск в SPAN, то есть цифра 1, так как отсчет идет с нуля. Таким образом получился параметр row1. Еще раз напоминаю команду замены сбойного диска:
Пока мы только указали, что заменили диск. Теперь нам надо запустить его ребил:
Статус ребилда смотрим командой:
После окончания ребилда снова смотрим вывод информации по массивам и дискам. Массив должен стать Optimal, а диск Online, Spun Up. На этом забываем про megacli как страшный сон и вспоминаем про приятный и удобный mdadm.
Я всегда тестирую выход из строя жесткого диска и его замену. Делаю на всех массивах, железных и софтовых. На железных, чтобы вот таких сюрпризов не было, а была рабочая инструкция. А в софтовых, в основном, чтобы убедиться, что загрузчик стоит на всех нужных дисках и система поднимется в случае чего. По надежности и замене дисков у меня к mdadm вопросов нет. Там все понятно и просто.
Навожу короткую инструкция по мониторингу физических дисков под хардварным LSI 2108 RAID контроллером. Так же эта инструкция может пригодиться для мониторинга дисков под HP/Compaq Smart Array Controller, Areca SATA[/SAS] RAID controller и другими, используя инструмент smart в сочетании с специализированными программами. Перечень контроллеров, за которыми можно мониторить физические диски используя smartctl наведен здесь.
Немного о HDD интерфейсах

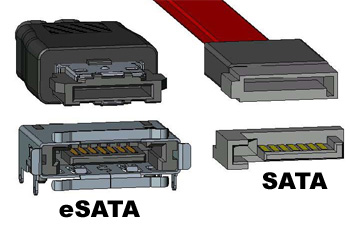

С интерфейсами все понятно, переходим к практике.
Мониторинг дисков используя megacli
Смотрим какие у нас есть диски.
Как видим, у нас LSI SAS MegaRAID контроллер, диски которого можно мониторить используя smartctl или же используя специализированную утилиту megacli. Для начала присмотримся к megacli. В стандартных репозиториях ее нет, но можно скачать с официального сайта и собрать с исходников. Но я рекомендую использовать специальный репозиторий (за который хочу сказать ОГРОМНОЕ спасибо) в котором есть почти весь набор специализированных утилиты под любой тип аппаратных рейдов.
Перечень всех доступных в репозитории утилит наведен здесь
Проверяем на ошибки физический диск megaraid используя megacli.
Теперь напишем маленький скрипт для мониторинга всех нужных параметров включая BBU.
Как видим у нас проблема с батареей (BBU) и ее нужно заменить.
По роботе с magacli есть целая книга-руководство.
Из полезных команд:
Мониторинг дисков используя smartctl
Для этого нам понадобиться тот же megacli, используя который, мы узнаем ID физических дисков и соответствующие им логические носители. Начнем.
Узнаем ID всех физических дисков за мегарейд контроллером ну и номера соответствующих логических дисков.
Расшифрую эту команду:
Теперь видно, что у нас три логических(виртуальных) диска в которые входят по несколько физических дисков с соответствующими ID. Посмотрим на сервере, сколько у нас есть дисков:
Все верно, у нас три логических диска в системе. Проводим аналогию с выводом команды megacli:
-
Virtual Drive: 0 == /dev/sda и в него входит 4 физических диска с Drive: 1 == /dev/sdb и в него входит 2 физических диска с Drive: 2 == /dev/sdc и в него входит 6 физических дисков с >Теперь нам осталось запустить SMART проверку по каждому с дисков используя собранные данные.
К примеру возьмем первый диск.
Каждая из ошибок имеет различные коды. Оригинал описания кодов взято из мануала по SCSI Seagate дискам:
Gigabytes processed [Total bytes processed: 05h]. This parameter code specifies the counter that counts the total number of bytes either successfully or unsuccessfully read, written or verified (depending on the log page) from the drive. If a transfer terminates early because of an unrecoverable error, only the logical blocks up to and including the one with the uncorrected data are counted. [smartmontools divides this counter by 10^9 before displaying it with three digits to the right of the decimal point. This makes this 64 bit counter easier to read.]
Total uncorrected errors [Total uncorrected errors: 06h]. This parameter code specifies the counter that contains the total number of blocks for which an uncorrected data error has occurred.
С всего этого нас интересует параметр Total uncorrected errors который показывает количество не исправленных ошибок. Если это число велико, то нужно запускать long тест и проверить, дополнительно, параметры физического диска в Megaraid контроллере.
Мониторинг дисков используя smartd
Читайте также: