
Настройка kubernetes centos 7
Обновлено: 03.07.2024
Kubernetes – это система управления контейнерами. Первоначально разработанный компанией Google на основе опыта работы с контейнерами в среде производства, Kubernetes распространяется с открытым исходным кодом и активно развивается сообществом по всему миру.
Kubeadm автоматизирует установку и настройку компонентов Kubernetes, таких как сервер API, менеджер контроллеров и Kube DNS. Однако он не создает пользователей и не обрабатывает установку и конфигурацию зависимостей на уровне операционной системы. Для этих задач можно использовать инструмент управления конфигурацией, например Ansible или SaltStack. Эти инструменты позволяют создавать новые или воссоздавать существующие кластеры намного быстрее и с меньшим количеством ошибок.
Этот мануал поможет создать новый кластер Kubernetes с помощью Ansible и Kubeadm и развернуть в нем контейнеризованное приложение Nginx.
Для этого нужна одна главная и две рабочих ноды.
Примечание: В терминологии Kubernetes нода – это сервер.
Главная нода отвечает за управление состоянием кластера. Она запускает Etcd, где хранятся данные кластера, а также управляет компонентами, которые планируют рабочие нагрузки остальных нод.
Рабочие ноды – это серверы, на которых будут выполняться рабочие нагрузки (например, контейнеризованные приложения и сервисы). Рабочая нода будет обрабатывать присвоенную ей рабочую нагрузку, даже если главная нода прекратит работу после планирования. Мощность кластера можно увеличить за счет добавления новых рабочих нод.
Выполнив этот мануал, вы получите кластер, готовый запускать контейнеризованные приложения (при условии, что серверы в кластере имеют достаточно CPU и RAM для работы приложений). Почти любое традиционное приложение Unix, включая веб-приложения, базы данных, демоны и инструменты командной строки, можно контейнеризировать и запустить в кластере. Сам кластер будет потреблять около 300-500 МБ памяти и 10% CPU каждой ноды.
После создания кластера вы сможете развернуть веб-сервер Nginx, чтобы убедиться, что рабочая нагрузка распределяется правильно.
Требования
- Пара ключей SSH на локальной машине Linux/macOS/BSD.
- Три сервера CentOS 7 с 1GB RAM минимум. У вас должна быть возможность подключиться к каждому серверу по SSH как root. Также нужно добавить открытый ключ в аккаунт пользователя centos на главной ноде (читайте мануал Установка SSH-ключей в CentOS 7).
- Экземпляр Ansible на локальной машине (инструкции можно найти в официальной документации).
- Базовые навыки работы с плейбуками Ansible (читайте Создание плейбука Ansible).
- Базовые знания Docker (можно ознакомиться с мануалом Установка и использование Docker в CentOS 7).
1: Настройка рабочего пространства и инвентаря Ansible
Сначала нужно создать на локальной машине каталог, который будет служить рабочим пространством. Также нужно настроить локальный экземпляр Ansible, чтобы он мог взаимодействовать с командами на удаленных серверах и выполнять их. Для этого создайте файл hosts, содержащий информацию об инвентаре (IP-адреса серверов и группы, к которым принадлежит каждый сервер).
Примечание: В этом мануале используется условный IP-адрес главной ноды master_ip и адреса рабочих нод worker_1_ip и worker_2_ip.
На локальной машине в домашнем каталоге создайте каталог
Этот каталог будет вашим рабочим местом в течение всего мануала, где будут находиться все плейбуки Ansible. Также внутри этого каталога вы будете запускать все локальные команды.
Нажмите i, чтобы вставить в файл следующий текст, в котором будут сведения о логической структуре кластера:
[masters] master ansible_host=master_ip ansible_user=root
[workers] worker1 ansible_host=worker_1_ip ansible_user=root
worker2 ansible_host=worker_2_ip ansible_user=root
Нажмите ESC и :wq, чтобы сохранить и закрыть файл.
Возможно, вы помните, что файлы инвентаря в Ansible используются для указания информации о сервере (это IP-адреса, удаленные пользователи и группы серверов, которые позволяют объединять ноды в единый блок для выполнения команд). Файл
/kube-cluster/hosts будет этим файлом инвентаря, сейчас в нем есть две группы Ansible (masters и workers), в которых указывается логическая структура кластера.
В группе masters есть запись сервера master, которая содержит IP-адрес главной ноды (master_ip) и указывает, что Ansible должен запускать удаленные команды в качестве пользователя root.
Точно так же в группе workers есть две записи о рабочих нодах, где указаны их адреса (worker_1_ip и worker_2_ip). Также здесь указано, что ansible_user – это пользователь root.
2: Установка зависимостей Kubernetes
Теперь нужно установить общесистемные пакеты, необходимые Kubernetes. Это можно сделать с помощью менеджера пакетов yum. Вам нужно установить:
- Docker – система управления контейнерами. Она и будет запускать ваши контейнеры в кластере. Поддержка других подобных систем (например rkt) активно разрабатывается командой Kubernetes.
- kubeadm – инструмент CLI, который позволяет стандартным образом установить и настроить множество различных компонентов кластера.
- kubelet – системный сервис, который запускает все ноды и управляет операциями на уровне нод.
- kubectl – инструмент CLI для запуска команд в кластере через сервер API.
В своем рабочем пространстве создайте файл
Добавьте в него следующий плейбук, который установит все нужные пакеты на серверы:
Первый плей в плейбуке делает следующее:
- Устанавливает Docker.
- Запускает сервис Docker.
- Отключает SELinux, поскольку он еще не полностью поддерживается Kubernetes.
- Устанавливает несколько значений sysctl, связанных с netfilter и необходимых для работы в сети. Это позволит Kubernetes устанавливать правила iptables для получения нодами сетевого трафика IPv4 и IPv6.
- Добавляет YUM репозиторий Kubernetes в списки репозиториев удаленных серверов.
- Устанавливает kubelet и kubeadm.
Второй плей состоит из одной задачи, которая устанавливает kubectl на главную ноду.
ansible-playbook -i hosts
Вы увидите такой вывод:
PLAY [all] ****
TASK [Gathering Facts] ****
ok: [worker1] ok: [worker2] ok: [master] TASK [install Docker] ****
changed: [master] changed: [worker1] changed: [worker2] TASK [disable SELinux] ****
changed: [master] changed: [worker1] changed: [worker2] TASK [disable SELinux on reboot] ****
changed: [master] changed: [worker1] changed: [worker2] TASK [ensure net.bridge.bridge-nf-call-ip6tables is set to 1] ****
changed: [master] changed: [worker1] changed: [worker2] TASK [ensure net.bridge.bridge-nf-call-iptables is set to 1] ****
changed: [master] changed: [worker1] changed: [worker2] TASK [start Docker] ****
changed: [master] changed: [worker1] changed: [worker2] TASK [add Kubernetes' YUM repository] *****
changed: [master] changed: [worker1] changed: [worker2] TASK [install kubelet] *****
changed: [master] changed: [worker1] changed: [worker2] TASK [install kubeadm] *****
changed: [master] changed: [worker1] changed: [worker2] TASK [start kubelet] ****
changed: [master] changed: [worker1] changed: [worker2] PLAY [master] *****
TASK [Gathering Facts] *****
ok: [master] TASK [install kubectl] ******
ok: [master] PLAY RECAP ****
master : ok=9 changed=5 unreachable=0 failed=0
worker1 : ok=7 changed=5 unreachable=0 failed=0
worker2 : ok=7 changed=5 unreachable=0 failed=0
После выполнения плейбука Docker, kubeadm и kubelet будут установлены на всех удаленных серверах. kubectl не является обязательным компонентом и необходим только для выполнения команд кластера. Устанавливать его только на главной ноде в этом контексте имеет смысл, так как вы будете запускать команды kubectl только с этого сервера. Однако обратите внимание, что команды kubectl можно запускать с любого из рабочих серверов или с любого компьютера, на котором он установлен и настроен (если он направлен на кластер).
3: Настройка главной ноды
Теперь нужно настроить главную ноду. Прежде чем приступить к созданию плейбука, нужно рассмотреть такие понятия как поды и сетевые плагины Kubernetes.
Под – это базовый элемент, который управляет одним или несколькими контейнерами. Эти контейнеры совместно используют ресурсы, такие как тома файлов и сетевые интерфейсы. Под – это основная единица планирования в Kubernetes: все контейнеры в поде работают на той же ноде, на которой запланирована работа пода.
Каждый под имеет свой собственный IP-адрес; под одной ноды должен иметь доступ к поду на другой ноде по IP-адресу. Контейнеры на одном узле могут легко связываться через локальный интерфейс. Однако связь между контейнерами сложнее, и для этого требуется отдельный сетевой компонент, который может легко маршрутизировать трафик пода на одной ноде к поду на другой.
Эту функцию выполняют сетевые плагины. Один из них, Flannel, будет использоваться в этом кластере.
Создайте плейбук master.yml на локальной машине.
Добавьте в файл такой код, чтобы инициализировать кластер и установить Flannel:
Этот файл делает следующее:
- Первая задача инициализирует кластер, запустив kubeadm init. Аргумент —pod-network-cidr=10.244.0.0/16 указывает частную подсеть, из которой будут назначаться IP-адреса. Flannel использует указанную выше подсеть по умолчанию; теперь kubeadm тоже будет использовать эту подсеть.
- Вторая задача создает каталог .kube в /home/centos. В нем будут храниться детали конфигурации (ключи админов, необходимые для подключения к кластеру, и API-адрес кластера).
- Третья задача копирует файл /etc/kubernetes/admin.conf, сгенерированный командой kubeadm init, в домашний каталог не-root пользователя. Это позволяет использовать kubectl для доступа к кластеру.
- Последняя задача запускает kubectl apply, чтобы установить Flannel. Синтаксис kubectl apply -f descriptor.[yml|json] позволяет kubectl создавать объекты, описанные в файле descriptor.[yml|json]. Файл kube-flannel.yml содержит описание объектов, необходимых для настройки Flannel в кластере.
Сохраните и закройте файл.
Запустите плейбук локально:
ansible-playbook -i hosts
Вы получите такой вывод:
PLAY [master] ****
TASK [Gathering Facts] ****
ok: [master] TASK [initialize the cluster] ****
changed: [master] TASK [create .kube directory] ****
changed: [master] TASK *****
changed: [master] TASK [install Pod network] *****
changed: [master] PLAY RECAP ****
master : ok=5 changed=4 unreachable=0 failed=0
Чтобы проверить состояние мастер-ноды, подключитесь к ней по SSH.
Затем выполните команду:
kubectl get nodes
Вы должны увидеть:
NAME STATUS ROLES AGE VERSION
master Ready master 1d v1.10.1
В выводе указано, что мастер-нода выполнила все задачи инициализации и находится в состоянии Ready, то есть может принимать рабочие ноды и выполнять задачи, отправленные на сервер API. Теперь вы можете добавить рабочие ноды.
4: Настройка рабочих нод
Чтобы добавить рабочие ноды, нужно выполнить на каждой из них одну команду. Эта команда включает в себя необходимую информацию о кластере (IP-адрес, порт сервера API-интерфейса мастера и токен). Только ноды, которые могут пройти токен, будут добавлены в кластер.
В рабочем пространстве создайте плейбук workers.yml:
Добавьте в него следующий код, чтобы подключить рабочие ноды к кластеру:
- hosts: master
become: yes
gather_facts: false
tasks:
- name: get join command
shell: kubeadm token create --print-join-command
register: join_command_raw
- name: set join command
set_fact:
join_command: ">"
- hosts: workers
become: yes
tasks:
- name: join cluster
shell: "> >> node_joined.txt"
args:
chdir: $HOME
creates: node_joined.txt
Этот плейбук делает следующее:
- Первый плей получает команду join, которая должна выполняться на рабочих нодах. Эта команда будет в следующем формате: kubeadm join —token <token> <master-ip>:<master-port> —discovery-token-ca-cert-hash sha256:<hash>. Как только он получит команду с соответствующими значениями токена и хэша, следующий плей сможет получить доступ к этой информации.
- Второй плей содержит одну задачу, которая запускает команду join на всех рабочих нодах. В результате две ноды станут частью кластера.
Сохраните и закройте файл.
Выполните плейбук локально:
ansible-playbook -i hosts
PLAY [master] ****
TASK [get join command] ****
changed: [master] TASK [set join command] *****
ok: [master] PLAY [workers] *****
TASK [Gathering Facts] *****
ok: [worker1] ok: [worker2] TASK [join cluster] *****
changed: [worker1] changed: [worker2] PLAY RECAP *****
master : ok=2 changed=1 unreachable=0 failed=0
worker1 : ok=2 changed=1 unreachable=0 failed=0
worker2 : ok=2 changed=1 unreachable=0 failed=0
После добавления рабочих нод кластер будет полностью настроен, а рабочие ноды будут готовы к обработке нагрузок. Прежде чем планировать приложения, нужно убедиться, что кластер работает должным образом.
5: Тестирование кластера
Иногда кластер может выходить из строя во время настройки, потому что нода отключена или сетевое соединение между мастером и рабочей нодой установлено неправильно. Протестируйте кластер и убедитесь, что все ноды работают верно.
Вам нужно будет проверить текущее состояние кластера с мастер-ноды, чтобы убедиться, что все ноды готовы. Если вы отключились от мастер-ноды, вы можете создать новое подключение SSH с помощью следующей команды:
Выполните эту команду:
kubectl get nodes
Вы получите такой результат:
NAME STATUS ROLES AGE VERSION
master Ready master 1d v1.10.1
worker1 Ready <none> 1d v1.10.1
worker2 Ready <none> 1d v1.10.1
Если все ноды имеют значение Ready в столбце STATUS, это означает, что они являются частью кластера и готовы к обслуживанию рабочих нагрузок.
Однако если некоторые из нод имеют статус NotReady, это может означать, что рабочие ноды еще не завершили свою настройку. Подождите около пяти-десяти минут, а затем попробуйте перезапустить kubectl get node. Если несколько нод все еще имеют статус NotReady, возможно, вам придется проверить и повторно запустить команды в предыдущих разделах.
Теперь можно попробовать запустить приложение Nginx в кластере.
6: Запуск приложения в кластере
Теперь в своем кластере вы можете развернуть любое контейнеризованное приложение. Для примера можно попробовать развернуть Nginx с помощью развертываний и сервисов. Вы также можете использовать приведенные ниже команды для развертывания других приложений (для этого также измените имя образа Docker и все соответствующие флаги (например, ports и volumes)).
Оставаясь на мастере, запустите следующую команду, чтобы создать развертывание nginx:
kubectl run nginx --image=nginx --port 80
Развертывание – это объект Kubernetes, который гарантирует, что на определенном шаблоне всегда будет работать определенное минимальное количество подов (даже если под повреждается во время работы кластера). Вышеупомянутое развертывание создаст под с одним контейнером из образа Nginx Docker.
Затем запустите следующую команду, чтобы создать сервис nginx, который откроет приложению доступ к сети. Это будет сделано через NodePort, схему, которая сделает под доступным через произвольный порт, открытый на каждой ноде кластера:
kubectl expose deploy nginx --port 80 --target-port 80 --type NodePort
Сервисы – это еще один тип объектов Kubernetes, который раскрывает внутренние сервисы кластера для клиентов, как внутренних, так и внешних. Они также способны выполнять балансировку нагрузки на несколько подов и являются неотъемлемым компонентом Kubernetes, поскольку часто взаимодействуют с другими компонентами.
kubectl get services
Вы получите примерно такой вывод:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
nginx NodePort 10.109.228.209 <none> 80:nginx_port/TCP 40m
В третьей строке вывода вы можете увидеть порт, на котором работает Nginx. Kubernetes автоматически присваивает случайный порт выше 30000, проверяя, что порт не занят другим сервисом.
Чтобы убедиться, что все работает, откройте на локальной машине в браузере:
Вы увидите стандартное приветствие Nginx.
Чтобы удалить приложение Nginx, сначала удалите сервис nginx с мастер-ноды.
kubectl delete service nginx
Запустите следующую команду, чтобы убедиться, что сервис удален:
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
После удалите развертывание:
kubectl delete deployment nginx
Чтобы убедиться, что оно удалилось, введите:
kubectl get deployments
No resources found.
Заключение
Если вы не знаете, что делать с кластером дальше, когда он настроен, попробуйте развернуть в нем свои приложения и сервисы. Вот список ссылок, которые могут помочь вам в этом процессе:
- На сайте Docker можно найти примеры, подробно описывающие, как контейнеризировать приложения. подробно описывает, как работают поды, и объясняет их связь с другими объектами Kubernetes. расскажет вам о развертываниях в Kubernetes. Понимать, как работают развертывания, очень важно, поскольку они часто используются для масштабирования и автоматического восстановления приложений.
- По этой ссылке вы найдете обзор сервисов.
Kubernetes поддерживает много хороших функций. Официальная документация Kubernetes – лучшее место для изучения понятий, поиска руководств по конкретным задачам и ссылок API для различных объектов.
Сегодня открываю новый цикл статей, которые будут иметь непосредственное отношение к Devops и всему, что с этим связано. Начну с того, что расскажу, как установить и запустить кластер Kubernetes на собственном железе. Буду использовать установку через Kubespray с использованием ingress контроллера в кластере.
Цели статьи
- Коротко рассказать о том, что такое Kubernetes и для чего он нужен.
- Перечислить основные системные требования для разворачивания своего кластера Kubernetes.
- Выполнить непосредственно установку кластера на свое железо.
Введение
Хочу сразу обратить внимание на важный момент. У меня нет опыта промышленной эксплуатации кластера Kubernetes. Я нахожусь в состоянии обучения и исследования этого инструмента. Я прошел обучение Слёрм, это дало базовые знания и понимание принципов работы. Дальше стал разворачивать свои кластера и исследовать их. Изначально я не хотел писать статьи по этой теме до тех пор, пока не накопится достаточного опыта, но сейчас поменял свое мнение.
В рунете очень мало материалов по kubernetes с конкретикой и практикой, по которым можно было бы учиться. Думаю, что даже те знания, что есть сейчас у меня, будут многим полезны и интересны. Плюс, когда пишешь статьи, систематизируешь свои знания, запоминаешь и получаешь обратную связь. Ускоряется процесс обучения. Так что статьям по kubernetes и devops в целом быть. Думаю, что в ближайшее время я сфокусируюсь именно на этом.
Могу однозначно сказать, что если у вас есть необходимость в продакшене использовать Kubernetes, не тяните время и не откладывайте. Идите учиться на курсы. Самостоятельно вы не освоите в достаточном объеме материал, чтобы можно было переносить рабочую нагрузку в свой кластер. Очень много нюансов и подводных камней. Вы потратите больше времени, нервов и денег на самостоятельное освоение, если будете сами все с нуля изучать.
Лично у меня сейчас нет цели становиться администратором Kubernetes. Мой формат занятости не подразумевает обслуживание таких крупных систем и в планах этого тоже пока нет. Мне просто любопытно его исследовать, узнавать что-то новое, поэтому я этим занимаюсь. Знания карман не тянут, особенно современные и востребованные.
Kubernetes простыми словами
Попробую рассказать своими словами, что такое кластер Kubernetes для чайников, без отсылок к описаниям и документации. По своей сути это кластер для обслуживания docker контейнеров. Я слышал, что он может управлять не только докером, но практически ничего про это не знаю. Все в основном используют Kubernetes в связке с Docker.
В Kubernetes все крутится вокруг докер контейнеров. Это инструмент для их запуска, поднятия в случае падения, распределения ресурсов и т.д. Под капотом никакой магии. Там обычный docker, iptables, etcd, nat, dns, ceph, nfs и т.д. Просто все собрано в одном месте для решения конкретных задач. Таким образом, для эффективного управления кластером кубера нужен хороший бэкграунд классического linux админа. Без этих знаний будет трудно.
Есть много способов разворачивания кластера, так как он модульный. Не всем и не всегда нужны все его компоненты. К примеру, есть ingress контроллер для распределения входящих запросов по сервисам. Под капотом там обычный nginx в режиме proxy_pass, интегрированный в инфраструктуру кластера. Реализация сети в кластере тоже может быть разной - на уровне l2 или l3 с помощью тех или иных технологий. То же самое с файловыми хранилищами - локальные хранилища серверов, nfs хранилища, ceph и т.д.
В зависимости от того, какой функционал вам нужен, выбирается способ установки кластера kubernetes. Мы можете его установить полностью вручную, добавляя один компонент за другим. А можно использовать готовое средство, к примеру Kubespray, где весь необходимый для установки функционал реализуется с помощью ролей ansible. На Слёрме нас учили ставить кластер, используя свой форк компании southbridge. Они там немного изменили функционал под свои потребности. Я ставил и по их форку, и по оригинальному Kubespray. Основное отличие от классического Kubespray в том, что не используется kubeadm и сертификаты для общения компонентов кластера сразу выпускаются то ли на 10, то ли на 100 лет, не помню точно. В Kubespray сертификаты выписываются только на год и надо отдельно следить за их актуальности и своевременно обновлять.
Подведу итог о том, что же такое Kubernetes. Кубернетис - средство оркестрации (управления) контейнерами Docker. Это удобный инструмент для их автоматического запуска, выделения ресурсов, контроля состояния, обновления.
Кому нужен Kubernetes
Теперь порассуждаем о том, кому может пригодиться Kubernetes. В первую очередь это крупные компании со своими разработками в ИТ и командами программистов, для которых нужна большая производственная среда. Кластер Кубера добавляет серьезные накладные расходы на свое содержание, поэтому в небольших проектах выгоды от него не будет. Нет смысла объединить 5 маленьких виртуалок в кластер и эксплуатировать его. Если только для тестов. Или если вы точно уверены, что у проекта будет серьезный рост в ближайшее время. Под небольшую структуру и нагрузки лучше подыскать решения попроще, чем кубернетис.
Kubernetes накладывает серьезные требования к приложениям, которые в нем работают. Они должны быть изначально спроектированы и написаны по принципу микросервисов. У вас не получится взять и перенести в кластер сайт на wordpress или bitrix, даже если они очень большие и нагруженные. Вернее, перенести то вы их сможете, но вряд ли вам от этого будет проще и удобнее. Основное преимущество кластера - гибкость в разработке, деплое приложения, а так же в распределении ресурсов.
Примерная схема работы с кластером кубернетис на пальцах будет такая:
- Разработчики какого-то одного сервиса проекта выпускают обновление, запушив его в репозиторий.
- Система сборки формирует докер контейнер с этими изменениями и кладет в registry.
- Контейнер уезжает на тесты и если все в порядке, выкатывается в продакшн кластер kubernetes.
Это я очень просто и условно описал. Все процессы после пуша кода в репозиторий могут быть автоматизированы. Команд разработчиков, как и микросервисов, может быть десятки. Они могут условно независимо друг от друга выкатывать обновления. У каждого сервиса могут быть свои языки программирования, свои системные требования, свои файловые хранилища и базы данных. Все эти сущности отдельно описываются в конфигурациях кластера. Каждый микросервис получает то, что ему нужно для работы.
Теперь смотрим на Bitrix или WordPress. Они являются монолитными приложениями, написанными на php с использованием базы Mysql. В них нет микросервисов. Вам нужно либо как-то разбивать их на части, либо постоянно выкатывать все целиком. Но в этом случае смысл кластера кубернетис теряется, его гибкость настроек и выделения ресурсов под потребности не используются. Вам проще поставить обычный балансер на вход, сделать несколько нод для обработки php и за ними кластер БД.
Резюмируя все сказанное. Kubernetes - нишевое решение под конкретные проекты. Оно подходит далеко не всем и не надо его пихать туда, где от него не будет толку. Думаю, находятся люди, которые так делают. Сужу по тому, что мне в комментариях к некоторым статьям, например, про установку zabbix, пишут, а почему вы не в докере его ставите. Люди не понимают, что такое докер, для чего он нужен и какие проблемы решает. Смысла в использовании zabbix в docker нет никакого вообще. Docker создан для удобной разработки и деплоя приложений в продакшн. Этакий расширенный пакетный менеджер. В первую очередь он инструмент разработчиков.
Системные требования
Как таковых жестких системных требований у Kubernetes нет. Он с очень маленьких установок расширяется до огромных кластеров. Для того, чтобы его просто попробовать и посмотреть, достаточно следующих виртуальных машин:
- 2-3 мастер ноды с 2 cpu и 4 gb ram
- ingress нода с 1 cpu и 2 gb ram
- рабочие ноды для контейнеров от 2 cpu и 4 gb ram
Для того, чтобы просто запустить кластер, достаточно буквально двух виртуальных машин, которые одновременно будут и мастер и рабочими нодами. Но я рекомендую сразу планировать более ли менее полную структуру, которую можно брать за основу для последующего превращения в рабочий кластер. Я буду разворачивать кластер на следующих виртуальных машинах.
| Название | IP | CPU | RAM | HDD |
| kub-master-1 | 10.1.4.36 | 2 | 4G | 50G |
| kub-master-2 | 10.1.4.37 | 2 | 4G | 50G |
| kub-master-3 | 10.1.4.38 | 2 | 4G | 50G |
| kub-ingress-1 | 10.1.4.39 | 2 | 4G | 50G |
| kub-node-1 | 10.1.4.32 | 2 | 4G | 50G |
| kub-node-2 | 10.1.4.33 | 2 | 4G | 50G |
В моем случае это виртуальные машины на двух гипервизорах Hyper-V. Как я уже сказал в системных требованиях, для теста ресурсов можно и чуть меньше дать, но у меня есть запас, поэтому я такие ресурсы выделил для кластера Kubernetes. Перед установкой кластера рекомендую сделать снепшоты чистых систем, чтобы можно было оперативно вернуться к исходному состоянию, если что-то пойдет не так. Вручную готовить и переустанавливать виртуалки хлопотно.
По гипервизорам виртуальные машины распределил следующим образом.


Упомяну про еще одну рекомендацию. Мастер ноды с etcd дают приличную нагрузку на диск. Их рекомендуется размещать на быстрых ssd дисках. Чем больше кластер - тем больше нагрузка. В наших тестах сойдет и hdd диск под мастер. Но если будете использовать в продакшене с учетом расширения и роста, лучше сразу планируйте быстрые диски под мастера.
Подготовка к установке
Кластер Kubernetes я буду разворачивать на виртуальных машинах Centos 7. На них она установлена в минимальной конфигурации. Напоминаю, что установка будет проходить с помощью Kubespray. Я рекомендую склонировать к себе репозиторий, чтобы у вас сохранилась версия kubespray, с которой вы устанавливали кластер. Это позволит без проблем создавать копию кластера для тестов, дебага, обновления и т.д. Я для этого использую свой сервер Gitlab. Рекомендую озаботиться его наличием. Он нам очень пригодится и дальше в процессе знакомства и изучения кластера.
На виртуальных машинах нужно отключить следующие сущности:
- SELinux (привет любителям безопасности, считающим, что selinux отключают только дилетанты).
- Swap.
- FirewallD, либо любой другой firewall.
На все сервера должен быть разрешен доступ пользователя root по ssh с одним и тем же паролем.
Установка кластера Kubernetes
Я буду устанавливать кластер Kubernetes с сервера kub-master-1. Установим на него некоторые пакеты, которые нам понадобятся в дальнейшем.
Теперь клонируем себе локально репозиторий kubespray.
Устанавливаем зависимости kubespray через pip, которые перечислены в файле requirements.txt.
Теперь нам нужно заполнить инвентарь ansible, исходя из нашего набора серверов. Для этого скопируем стандартный инвентарь sample и будем редактировать его.
Приводим файл inventory.ini к следующему виду.
В принципе, тут все понятно, если вы знакомы с работой ansible. Мы распределили хосты по ролям. Обращаю внимание, что сервер ingress по сути является обычной нодой, только с дополнительным функционалом, поэтому он присутствует в том числе в группе kube-node. Далее вы можете его использовать и как ingress, и как обычную ноду одновременно.
Теперь редактируем некоторые параметры. Для удобства восприятия, я их прокомментировал прямо тут, рядом со значениями. Переносить комментарии в реальные конфиги не надо. Они только для инфомрации на сайте. Начнем с файла
/kubespray/inventory/dev/group_vars/all/all.yml. Добавляем туда параметры:
Я буду использовать сетевой плагин flannel и iptables. Это хорошо проверенное и полностью готовое к production решение. Никаких особых настроек не требует, кроме пары параметров. Добавляем их в файл
В данном случае 10\\.1\\.4\\.\\d это регулярное выражение, которое описывает подсеть 10.1.4.0/24, в которой у меня размещены виртуальные машины под кластер. Если у вас подсеть машин для кластера, к примеру, 192.168.55.0, то регулярка будет 192\\.168\\.55\\.\\d
Теперь настроим ingress. Добавляем параметры в
/kubespray/inventory/dev/group_vars/kube-ingress.yml и добавляем параметры:
Трудно кратко и понятно описать настройки ingress, так как тут используются не тривиальные возможности kubernetes в виде taints и tolerations. Общий смысл в том, что мы задаем метку для ingress и поведение на основе этой метки. На ноды в группе kube-ingress ставится ограничение NoSchedule (не распределять поды на ноду) с помощью taints. Это ограничение могут преодолевать только только те, у кого в tolerations прописана метка ingress. Таким образом, на нодах ingress, кроме самого ингресса ничего запускаться не будет.
Вот и все. Мы готовы к тому, чтобы начать установку кластера Kubernetes. Запускаем ее с помощью ansible-playbook. Рекмоендую делать это в screen, чтобы не прерывался процесс из-за обрыва связи.
Процесс обычно длится 15-20 минут. У меня сервера старые, на hdd, длилось 30 минут. В конце вы должны увидеть примерно такую картину.

Ошибок быть не должно. Если есть ошибки, внимательно ищите их в выводе ansible и исправляйте. Основные ошибки возникают из-за неправильно заполненного инвентаря, из-за неправильной маски ip в свойствах flannel, из-за ошибок загрузки докер образов в процессе установки. После исправления ошибки можно запускать этот же плейбкук снова. Чаще всего все будет нормально донастроено.
Проверить состояние кластера можно командой:

Для сервера ingress смотрите сами, хотите вы на него дополнительно вешать роль node или оставите только в качестве ingress контроллера. В продакшене лучше оставить его отдельно. Если у вас тестовый кластер, то можете объединить эти роли на одном сервере.
Если же вы захотите убрать какую-то роль, то команда будет такой.
Мы убрали роль node на сервере kub-ingress-1. Проверяем снова состояние кластера.
Посмотреть подробную информацию о ноде можно командой.

Рекомендую запомнить эту команду. Она очень пригодится в процессе эксплуатации кластера и дебага. Особое внимание на раздел Events. Именно он будет очень полезен при разборе ошибок на нодах.
Посмотрим список всех запущенных подов.

Они все должны быть в состоянии Running. Если это не так, то у вас какие-то ошибки, с которыми надо разбираться. В общем случае ошибок быть не должно, если вы все сделали правильно на моменте подготовки инвентаря.
На этом непосредственно установка кластера Kubernetes закончена. Он готов к эксплуатации. Если вы только знакомитесь с ним, то, думаю, вам совсем не понятно, что делать дальше и как его эксплуатировать. Об этом будут мои последующие статьи. Следите за обновлениями.
Проблема с сертификатами
Сразу обращаю внимание на очень важный момент. Необходимо тем или иным способом настроить мониторинг сертификатов, которые установил и настроил kubespray для обмена информацией мастеров. Сертификатов много и у них срок действия 1 год. Пока сертификаты не просрочились, их относительно легко обновлять. Если упустить этот момент, то все становится сложнее.
Я до конца не понял и не проработал вопрос обновления сертификатов, но это нужно будет сделать. Пока просто покажу, как за ними можно следить.
Сертификат api-server, порт 6443
Сертификат controller manager, порт 10257.
Сертификат scheduler, порт 10259.
Это все разные сертификаты и они выпущены на год. Их надо будет не забыть обновить. А вот сертификат для etcd. Он выпущен на 100 лет.
Я не понял, почему этого не сделали для всех сервисов, а оставили такой головняк на потом. Если у кого-то есть информация о том, как корректно и безпроблемно обновлять сертификаты, прошу поделиться. Я пока видел только вариант с полуручным обновлением и раскидыванием этих сертификатов по мастерам.
Заключение
На этом начальную статью по Kubernetes заканчиваю. На выходе у нас получился рабочий кластер из трех мастер нод, двух рабочих нод и ingress контроллера. В последующих статьях я расскажу об основных сущностях kubernetes, как деплоить приложения в кластер с помощью Helm, как добавлять различные стореджи, как мониторить кластер и т.д. Да и в целом, хочу много о чем написать, но не знаю, как со временем будет.
В планах и git, и ansible, и prometeus, и teamcity, и кластер elasticsearch. К сожалению, доход с сайта не оправдывает временных затрат на написание статей, поэтому приходится писать их либо редко, либо поверхностно. Основное время уходит на текущие задачи по настройке и сопровождению.

Ранее мы уже писали о том, что такое Kubernetes, разбирали архитектуру фреймворка и принцип работы. Основные составляющие системы кластеризации: главный сервер (master server) и рабочие ноды.
Kubernetes инсталлируется с помощью таких утилит:
- Minikube (кластер, состоящий из единой ноды);
- Kops (настройка нескольких узлов Kubernetes в AWS);
- Kubeadm (кластер на своих мощностях).
В статье на примере покажем, как установить Kubernetes 1.7 на CentOS 7/RHEL 7 c утилитой Kubeadm, развернуть кластер, состоящий из главного сервера и двух нод.

Компоненты, которые будут установлены на мастер-сервере:
- API сервер;
- Scheduler;
- Controller Manager;
- etcd;
- Kubectl utility.
На рабочих машинах установим:
Приступаем к установке.
- Отключение SELinux и настройка правил Firewall
Подключаемся к главному серверу, задаем имя хоста и отключаем SELinux, используя такие команды
Устанавливаем следующие правила Firewall
В случае, если нет собственного DNS-сервера, нужно обновить файл /etc/hosts на главном сервере и рабочих узлах.
Kubernetes не включен по умолчанию в CentOS 7 и RHEL 7, поэтому нам нужно скачать репозитории.
Когда репозитории будут установлены, скачиваем Kubeadm
Для запуска загрузки мастера вводим команду
Чтобы использовать кластер под root`ом, вводим команды
Для запуска кластера и контейнеров выполним
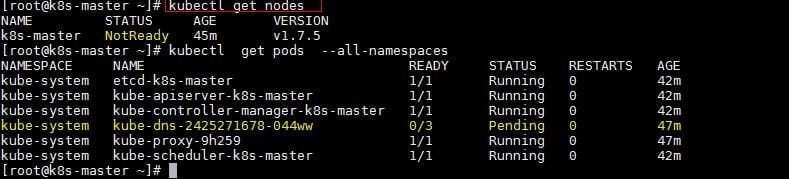
Далее запускаем команду для развертывания сети
Для проверки статуса прописываем
Теперь добавляем рабочие ноды.
- Отключение SELinux и настройка правил Firewall для подчиненных серверов
Перед тем, как отключить SELinux, задаем имя хостов на обоих узлах – «worker node1» и «worker node2» соответственно.
- Скачивание репозитория Кubernetes и установка на серверах
- Установка Kubeadm и Docker на серверы
Сначала скачиваем Kubeadm
- Объединение мастер сервера с рабочими нодами
Для присоединения рабочих нод к главному серверу нам необходим токен. При каждом запуске мастера мы получаем команду и токен, которые выглядят примерно так. Скопируем их и запустим сначала на первом узле
В итоге получаем что-то наподобие этого

Затем на втором
Проверяем статус нод, используя команду kubectl
Главный сервер и рабочие узлы готовы к работе. Это значит, что установка и настройка kubernetes 1.7 прошла успешно. Мы подключили две ноды к мастеру, теперь можно создавать сервисы и pod-ы.
Возникли вопросы с Kubernetes? Разбираем эту утилиту на нашем авторском курсе «L3-DevOps с точки зрения системного администрирования»!
Kenernetes используется фондом Wikimedia Foundation, инфраструктура которого мигрировала на это приложение с самостоятельно разработанного ПО для организации кластеров.
Установка Kubernetes кластера в Unix/Linux
Кластерная диаграмма кубернетес кластера, выглядит следующим образом:

- Мастер отвечает за управление кластером. Master узлы будут координировать всю деятельность, происходящую в вашем кластере, например, приложения для планирования, сохранение желаемого состояния, масштабирование приложений и обновление апликейщенов.
- Узел (node) представляет собой виртуальную машину или физический компьютер, который используется в качестве рабочего компьютера в кластере Kubernetes. Каждый узел из кластера управляется мастером. На типичном узле вы будете иметь инструменты для обработки операций с контейнерами (например, Docker, rkt) и Kubelet, агента для управления узлом. Кластер Kubernetes, который обрабатывает ПРОД, должен иметь минимум три узла в кластере.
Хватит теории, перейдем к установке и настройке самого кластера!
Установка kubernetes-master-1 на CentOS 7
Т.к у меня нет DNS-сервера (я строю кластер локально, на виртуальных машинах), то нужно прописать:
Это поможет резолвить ноды между собой.
Не забываем выключить SELinux, а то он может наломать вам дров:
Добавим репозиторий с kubernetes:
Собственно, выполняем установку докера и кубика:
Добавялем докер-службу в автозагрузку ОС и запускаем сервис:
Some users on RHEL/CentOS 7 have reported issues with traffic being routed incorrectly due to iptables being bypassed. You should ensure net.bridge.bridge-nf-call-iptables is set to 1 in your sysctl config, e.g.
Насчет etcd, я не уверен что нужно сувать его в автозагрузку ОС. Но можно это сделать вот так:
Добавялем кубернетес-службу в автозагрузку ОС и запускаем сервис:
Так же, незабываем сохранить команду для добавления нод в мастер, у меня это:
Смотрим что вышло:
PS: Можно получить следующую ошибку:
Установка kubernetes-worker-1 на Debian 8
Т.к у меня нет DNS-сервера (я строю кластер локально, на виртуальных машинах), то нужно прописать:
Это поможет резолвить ноды между собой.
Ставим нужные зависимости:
Добавляем докер в автозагрузку ОС, запускаем его и смотрим статус:
Сейчас, ставим кубик:
Добавляем kubelet в автозагрузку ОС, запускаем его и смотрим статус:
Все готово, можно добавлять ноду в кластер:
Потом, открываем файл:
Немного о cgroups:
И потом, можно запускать (добавляем воркер к мастеру):
На kubernetes-master-1, запускаем:
Установка kubernetes-worker-2 на Debian 8
Аналогичные действия, проделываю и для kubernetes-worker-2. Но только с другим хостнеймом.
Установка kubernetes-worker-n на CenOS 7/Redhat 7
Можно добавлять другие воркеры по аналогии как я описывал ранее для kubernetes-master-1, но без инициализации мастера (что логично, не правдали?).
Деплой Kubernetes кластера в Unix/Linux
Приведу наглядный скриншот того, как выглядит развертывание первого приложения на Kubernetes:

Когда все ноды будут добавлены в кластер, должно получится что-то типа:
-=== СПОСОБ 1 ===-
Смотрим какие деплойменты имеются:
Можно получить дополнительную инфу, выполнив:
Получаем что-то типа:
Делаем контейнер доступным в интернете:
Проверяем работу контейнеров:
Можно посмотреть сколько реплик имеется:
Чтобы проверить поды, выполняем:
Ролбэк Kubernetes кластера в Unix/Linux
Можно выполнять ролбэки:
Можно проверить хистори всех ролбеков:
Теперь я выполню откат к предыдущей версии:
Масштабирование Kubernetes кластера в Unix/Linux
Можно выводить много полезной инфы вот так:
Мониторинг Kubernetes кластера в Unix/Linux
Но об этом немного позже. Я дополню эту часть, обязательно!
Удаление Kubernetes кластера в Unix/Linux
Чтобы удалить ноду с кластера, на мастере, выполните:
Для удаления деплоймента, используйте:
Читайте также: