
Объединить csv файлы в один linux
Обновлено: 02.07.2024
Я хотел бы прочитать несколько файлов csv из каталога в pandas и объединить их в один большой DataFrame. Однако я не смог понять это. Вот что я до сих пор:
Я думаю, мне нужна помощь в цикле for.
ОТВЕТЫ
Ответ 1
Если у вас одинаковые столбцы во всех ваших csv файлах, вы можете попробовать код ниже. Я добавил header=0 чтобы после прочтения csv первой строке можно было присвоить имена столбцов.
Ответ 2
Ответ 3
Ответ 4
Библиотека Dask может читать данные из нескольких файлов:
Ответ 5
Почти все ответы здесь либо излишне сложны (сопоставление с шаблоном), либо полагаются на дополнительные сторонние библиотеки. Вы можете сделать это в 2 строки, используя все, что уже встроено в Pandas и python (все версии).
Для нескольких файлов - 1 вкладыш:
Для многих файлов:
Эта строка панд, которая устанавливает df, использует 3 вещи:
- Карта Python (функция, итерируемая) отправляет в функцию ( pd.read_csv() ) итерацию (наш список), которая является каждым элементом csv в пути к файлам).
- Функция Panda read_csv() читает в каждом файле CSV как обычно.
- Panda concat() объединяет все это в одну переменную df.
Ответ 6
Я искренне хочу, чтобы кто-то нажал эту страницу, чтобы рассмотреть этот подход, но не хочу прикладывать эту огромную часть кода в качестве комментария и сделать ее менее читаемой.
Вы можете использовать numpy, чтобы действительно ускорить конкатенацию dataframe.
Ответ 7
Если вы хотите выполнить рекурсивный поиск (Python 3.5 или выше), вы можете сделать следующее:
Обратите внимание, что три последние строки могут быть выражены в одной строке:
Вы можете найти документацию ** здесь. Также я использовал iglob вместо glob , так как он возвращает итератор вместо списка.
РЕДАКТИРОВАТЬ: Мультиплатформенная рекурсивная функция:
Вы можете обернуть вышеупомянутое в многоплатформенную функцию (Linux, Windows, Mac), так что вы можете сделать:
Ответ 8
Если несколько CSV файлов заархивированы, вы можете использовать zipfile, чтобы прочитать все и объединить, как показано ниже:
Ответ 9
Импортируйте два или более csv без необходимости составлять список имен.
Ответ 10
Я нашел этот метод довольно элегантным.
Ответ 11
один лайнер, использующий map , но если вы хотите указать дополнительные аргументы, вы можете сделать:
Примечание: map сама по себе не позволяет вводить дополнительные аргументы.
Ответ 12
Еще один on-liner со списком, который позволяет использовать аргументы с read_csv.
Ответ 13
На основании @Sid хороший ответ.
Перед объединением вы можете загрузить CSV файлы в промежуточный словарь, который предоставляет доступ к каждому набору данных на основе имени файла (в форме dict_of_df['filename.csv'] ). Такой словарь может помочь вам выявить проблемы с разнородными форматами данных, например, когда имена столбцов не выровнены.
Импортируйте модули и найдите пути к файлам:
Примечание: OrderedDict не обязательно, но он сохранит порядок файлов, которые могут быть полезны для анализа.
Загрузите CSV файлы в словарь. Затем объедините:
Ключи - это имена файлов f , а значения - содержимое фрейма данных CSV файлов. Вместо использования f в качестве ключа словаря, вы также можете использовать os.path.basename(f) или другие методы os.path, чтобы уменьшить размер ключа в словаре до только меньшей части, которая имеет отношение к делу.
Ответ 14
Альтернатива с использованием библиотеки pathlib (часто предпочтительнее, чем os.path ).
Этот метод позволяет избежать многократного использования панд concat() / apped() .
Из документации панд:
Стоит отметить, что concat() (и, следовательно, append()) создает полную копию данных, и что постоянное повторное использование этой функции может привести к значительному снижению производительности. Если вам нужно использовать операцию над несколькими наборами данных, используйте понимание списка.
У меня есть 14 файлов, которые являются частью одного текста. Я хотел бы объединить их в один. Как это сделать?
Помните, что указанная вами команда, вероятно, будет делать то, что хочет плакат, если они пронумерованы таким образом, что оболочка расширяется * в «естественном» порядке. Если у вас есть «file1.txt . file9.txt . file14.txt», он не будет работать, потому что file1? .Txt будет сортировать между file1.txt и file2.txt. Вам придется переименовать их в «file01.txt . file09.txt . file14.txt». Скажи, echo * если ты не уверен. @Warren: хороший момент (или вы можете использовать zsh и установить его numeric_glob_sort опцию). @ Уоррен-молодой правильный, полезный предупреждающий комментарий. Но в моем случае порядок не имеет значения (поскольку файлы содержат просто простые операторы SQL, вставляющие записи данных, которые не имеют зависимостей). Осторожно, если количество файлов превышает определенный лимит, вы можете запустить с ошибками вроде - / bin / cat: список аргументов слишком длинный @ ARA1307 Только если файл уже существует; в противном случае глобус будет расширен до того, как оболочка откроет файл для записи в него. Хороший момент в этой ситуации, хотяЕсли ваши файлы не находятся в одном каталоге, вы можете использовать команду find до объединения:
Очень полезно, когда ваши файлы уже упорядочены, и вы хотите объединить их, чтобы проанализировать их.
Это может или не может сохранить порядок файлов.
Это путь, если у вас много файлов. Вы избегаете ошибки «список аргументов слишком длинный». Вам нужно -name "* .csv" вместо -name * .csv - без кавычек это не сработает. Потребность в кавычках зависит от версии команды find, особенно в find и awk. Это проблема, когда вы работаете на Mac, версии обеих программ немного устарели. До сих пор на Ubuntu, Fedora, Debian и CentOS все работало без кавычек Я ожидал бы котировочную версию работать , когда нет файлов в текущем каталоге , соответствующих шаблон "*.csv" , так как оболочка будет затем передать литерал * в find .фактически имеет нежелательный побочный эффект включения 'объединенного-файла' в конкатенацию, создавая файл-разборщик. Чтобы обойти это, либо напишите объединенный файл в другой каталог;
или используйте сопоставление с образцом, которое будет игнорировать объединенный файл;
cat * > merged-file работает отлично. Глобы обрабатываются до создания файла. Если он merged-file уже существует, cat (по крайней мере , мой) определит, что это выходной файл, и откажется его читать. Если файл уже существует, и у вас есть перенаправление позже в конвейере, то он, очевидно, не может этого сделать, так что тогда и только тогда вы получите файл побега. cat не может определить, является ли файл выходным. Перенаправление происходит в оболочке; cat только печатает на стандартный вывод.Как и другие здесь говорят . Вы можете использовать cat
Допустим, у вас есть:
И вы только хотите , file01 чтобы file03 и fileA к fileC :
Или, используя расширение скобки:
Или, используя причудливое расширение фигурных скобок:
Или вы можете использовать for цикл:
Обратите внимание, что строка 1 не будет работать в качестве шаблона сглаживания.Вы можете указать pattern файл, а затем объединить их все следующим образом:
Другой вариант - это sed:
Или без перенаправления .
Конечно, вы также можете сократить список файлов с подстановочными знаками. Например, в случае нумерованных файлов, как в приведенных выше примерах, вы можете указать диапазон в фигурных скобках следующим образом:
ребята, у меня здесь есть 200 отдельных csv-файлов с именем от SH (1) до SH (200). Я хочу объединить их в один файл CSV. Как я могу это сделать?
Как сказал ghostdog74, но на этот раз с заголовками:
почему вы не можете просто sed 1d sh*.csv > merged.csv ?
иногда вам даже не нужно использовать python!
использовать принято StackOverflow ответ создать список из CSV-файлов, которые вы хотите добавить, а затем запустить этот код:
и если вы хотите экспортировать его в CSV-файл, используйте этот:
это зависит от того, что вы подразумеваете под "слиянием" - имеют ли они одинаковые столбцы? У них есть заголовки? Например, если все они имеют одинаковые столбцы и нет заголовков, достаточно простой конкатенации (откройте файл назначения для записи, выполните цикл над источниками, открывая каждый для чтения, используйте shutil.copyfileobj из источника open-for-reading в пункт назначения open-for-writing закройте источник, продолжайте цикл-используйте with заявление, чтобы сделать заключение о вашем имя.) Если у них одинаковые столбцы, но и заголовки, вам понадобится readline в каждом исходном файле, кроме первого, после его открытия для чтения перед копированием в пункт назначения, пропустить строку заголовков.
Если CSV-файлы не имеют одинаковых столбцов, вам нужно определить, в каком смысле вы их "объединяете" (например, SQL-соединение? или "горизонтально", если все они имеют одинаковое количество строк? и т. д.) - Нам трудно догадаться, что вы имеете в виду в этом случае.
Я просто собираюсь через другой пример кода в корзине
если объединенный CSV будет использоваться в Python, просто используйте glob чтобы получить список файлов для передачи в fileinput.input() через files аргумент, затем используйте csv модуль, чтобы прочитать все это на одном дыхании.
небольшое изменение кода выше, поскольку он на самом деле работает неправильно.
это должно быть следующим образом.
вы можете импортировать csv затем цикл через все CSV-файлы, читая их в список. Затем запишите список обратно на диск.
вышеизложенное не очень надежно, поскольку оно не имеет обработки ошибок и не закрывает открытые файлы. Это должно работать независимо от того, имеют ли отдельные файлы одну или несколько строк данных CSV в них. Также я не запускал этот код, но он должен дать вам представление о том, что делать.
Команда cat очень полезна в Linux. Она имеет три основные функции связанные с манипулированием текстовыми файлами: создание, отображение и объединение.
Давайте предположим что у вас есть три текстовых файла: file1.txt, file2.txt и file3.txt. Вы хотите объединить их в один текстовый файл содержащий информацию о всех трех в указанном порядке. Вы можете сделать это с помощью команды cat.
Просто откройте терминал и введите следующую команду:
cat file1.txt file2.txt file3.txt
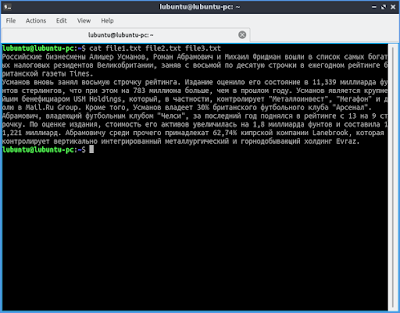
Замените имена файлов в приведенном выше примере своими именами.
Объединенное содержимое трех текстовых файлов появится в вашем терминале.
Вероятно вы захотите объединить эти текстовые файлы в другой текстовый файл а не просто распечатать результаты на экране терминала. Это очень просто. Все что вам нужно сделать это добавить символ > после списка объединяемых файлов а затем указать имя окончательного текстового файла.
cat file1.txt file2.txt file3.txt> file4.txt

Теперь если вы откроете файл file4.txt с помощью команды cat или с помощью выбранного вами текстового редактора вы обнаружите что он содержит текст первых трех текстовых файлов.
Если вы объединяете списки элементов из нескольких файлов и хотите чтобы они были в алфавитном порядке в объединенном файле вы можете отсортировать объединенные элементы в конечном файле. Для этого используйте команду sort. Все строки текста в файле в результате будут отсортированы в алфавитном порядке.
cat file1.txt file2.txt file3.txt | sort > file4.txt
Существует также способ добавления файлов в конец существующего файла. Введите команду cat а затем файл которые вы хотите добавить в конец существующего файла. Затем введите два символа >> и имя конечного файла в который хотите добавить текст.
cat file5.txt >> file4.txt
Если вы хотите добавить немного нового текста в существующий текстовый файл используйте команду cat чтобы сделать это непосредственно из терминала. Введите команду cat за которой следует двойной символ >> и имя файла в который вы хотите добавить текст.
cat >> file4.txt
На следующей строке появится курсор. Начните вводить текст который хотите добавить в файл. Когда закончите нажмите Enter после последней строки а затем нажмите Ctrl + D чтобы скопировать этот текст в конец файла и выйти из cat.
Читайте также: