
Проверка состояния raid centos
Обновлено: 05.07.2024
Некоторые поставщики выделенных серверов дают нам возможность использовать программный RAID для использования предлагаемого выделенного сервера.
Проблема, часто также в использовании выделенного сервера, на котором настроен только RAID 1, но нет возможности отслеживать состояние диска, на котором он работает.
RAID полезен, только если мы знаем о возможных повреждениях дисков.
Итак, как настроить параметры, чтобы следить за состоянием здоровья жесткого диска в RAID?
Прежде всего, начните с редактирования следующего файла:
На Centos:
В Debian / Ubuntu:
Убедитесь, что в файле конфигурации есть следующая строка. Если нет, скопируйте и вставьте её туда:
Также добавьте в этот файл адрес электронной почты, на который вы хотели бы получать уведомления:
А затем сохраните файл и выйдите.
Далее мы запустим процесс и убедимся, что он работает без ошибок.
Если всё работает правильно, нам нужно убедиться, что эта команда выполняется во время загрузки. Отредактируйте следующий файл:
Скопируйте и вставьте строку в конец файла:
ВНИМАНИЕ: Последняя строка в /etc/rc.local для Debian (и, возможно, установки Ubuntu) - это «exit 0», поэтому вам нужно убедиться, что указанная выше команда идет ДО этой строки, иначе она никогда не запустится.
Наконец, если вы хотите проверить, правильно ли отправляются электронные письма, вы можете выполнить следующую команду:
Это отправит вам электронное письмо о текущем статусе ваших рейд-массивов.
Обязательно внесите эти электронные письма в белый список, чтобы при поступлении настоящего рейдового оповещения ваш провайдер электронной почты не отправлял их в ящик для спама!
Устранение неполадок при тестировании
После того, как мы сделаем пошаговые настройки, указанные выше, при попытке запустить тест на нашем сервере появится следующее предупреждение;
Это происходит потому, что может быть только один запущенный процесс mdadm, поэтому мы сначала закрываем все запущенные процессы mdadm с помощью команды killall mdadm. После этого мы запускаем команду для вышеуказанного теста.



mdadm – утилита для работы с программными RAID-массивами в Linux. В статье мы рассмотрим, как работать с утилитой mdadm (multiple disks admin) для создания массива, добавления дисков, управления дисками, добавление hot-spare и много другой полезной информации.
Чтобы установить утилиту mdadm, запустите команду установки:
- Для Centos/Red Hat используется yum/dnf: yum install mdadm
- Для Ubuntu/Debian: apt-get install mdadm
В резульатте в системе будет установлена сама утилита mdadm и необходимые библиотеки:
Создание RAID из 2-х дисков
У меня на сервере установлены два дополнительных диска и я хочу содать на низ програмное зеркало (RAID1). Диски пустые, данные на них не писались. Для начала, нужно занулить все суперблоки на дисках, которые мы будем добавлять в RAID-массив:

У меня два есть два чистых диска vdb и vdc.
Данный листинг означает, что ни один из дисков ранее не был добавлен в массив.
Чтобы собрать программный RAID1 из двух дисков в устройстве /dev/md0, используйтк команду:
Если нужно создать RAID0 в режиме страйп (stripe) для увеличения скорости чтения/записи данных за счет распараллеливания команд между несколькими физическими дисками, используйте команду:RAID 5 из трех или более дисков:
После запуска команды, нужно подтвердить действия и массив будет создан:

Теперь при просмотре информации о дисках, мы видим наш массив:
Создание файловой системы на RAID, монтирование
Чтобы создать файловую систему ext4 на нашем RAID1 массиве из двух дисков, используйте команду:

Создадим директорию backup и примонтируем к ней RAID устройство:
Массив смонтировался без ошибок. Чтобы не монтировать устройство каждый раз вручную, внесем изменения в fstab:

Просмотр состояния, проверка целостности RAID массива
Чтобы проверить целостность данных в массиве, используйте команду:
После чего, нужно посмотреть вывод файла:
Если в результате вы получаете 0, то с вашим массивом все в порядке:

Чтобы остановить проверку, используйте команду:
Чтобы проверить состояние всех RAID -массивов доступны на сервере, используйте команду:
В листинге команды, видим информацию о нашем ранее созданном raid.
Более подробную информацию о конкретном raid-массиве, можно посмотреть командой:

Разберем основные пункты листинга команды:
Краткую информацию можно посмотреть с помощью утилиты fdisk:
Восстановление RAID при сбое, замена диска
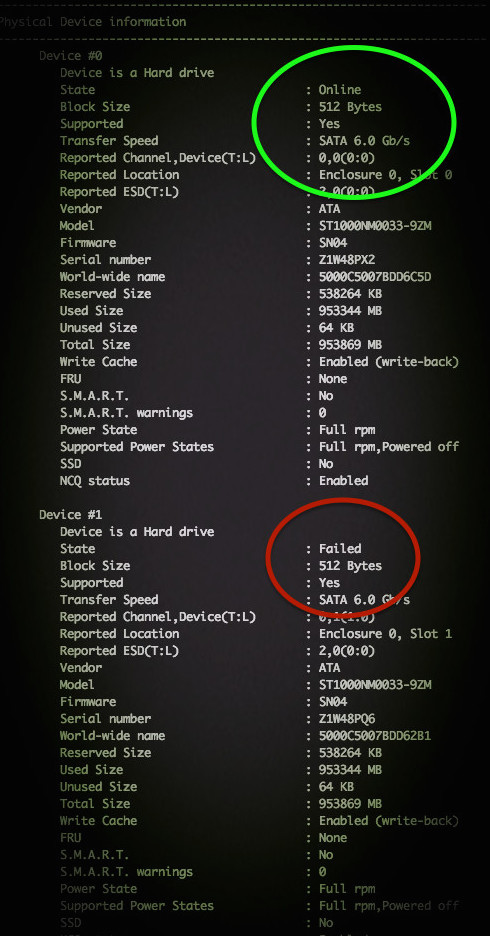
Если у вас вышел из строя или повредился один из дисков в RAID-массиве, его можно заменить другим. Для начала определим, поврежден ли диск и какой диск нам следует менять.
Из листинга команды, вы видим, что только один диск активен. Так же о проблеме говорит [U_]. Когда оба диска рабочие, вывод будет [UU].
Подробная информация о RAID-массиве также показывает, что естт проблемы:
State : clean, degraded – данная строка указывает на то, что диск в raid-массиве поврежден.
В нашем случае нужно заменить неисправный диск /dev/vdc. Для восстановления массива, нужно удалить нерабочий диск и добавить новый.
Удаляем неиспраный диск:
Добавляем в массив новый диск :
Восстановление диска запустится автоматически после добавления нового диска:
rebuild Status : 69% complete — показывает текущее состояние восстановления массива.
spare rebuilding /dev/vdd — показывает какой диск добавляется к массиву.
После восстановления массива, листинг по дискам выглядит так:
Добавление и удаление дисков в RAID массив на Linux
Чтобы разобрать ранее созданный массив, нужно отмонтировать его :
И выполнить команду:
После разбора массива, он не должен определяться как устройство:
Чтобы собрать массив, который мы ранее разобрали вручную, запустите команду:

Данная команда просканирует диски из разобранного или развалившегося RAID массива и по метаданным попробует собрать из них RAID.
Если вам нужно удалить рабочий диск из массива и заменить его на другой, нужно для начала пометить рабочий диск как нерабочий:
После чего диск можно будет удалить командой::
Добавляется новый диск, так же как и в случае с нерабочим диском:
Добавление Hot-Spare диска в RAID массив
Вы можете добавит в массив hot-spare диск для горячей замены при выходе из строя одного из активных дисков. Добавьте свободный диск в нужный массив:

После чего при проверке статуса массива, будет видно, что началась пересборка массива:

Диск /dev/vdb помечен как нерабочий, а hot-spare диск стал одним из активных дисков RAID и запустился процесс восстановления.
Чтобы добавить дополнительный рабочий диск в RAID, нужно выполнить два шага.
Добавить пустой диск массиву:
Теперь данный диск будет отображаться как hot-spare, чтобы сделать его рабочим, расширим raid-массив:
После чего запустится процесс пересборки массива:

После выполнения пересборки, все диски стали активны:
Удаление массива
Если вы хотите безвозвратно удалить raid-массив, используйте следующую схему:
После чего очищаем все суперблоки на дисках, из которых он был собран:
Mdmonitor: Мониторинг состояния RAID и email оповещения
Для мониторинга состояния RAID массива можно использовать службу mdmonitor. Сначала нужно создать файл /etc/mdadm.conf с конфигурацией текущего массива:
Конфигурационный файл mdadm.conf не создается автоматически. Его нужно создавать и актуализировать вручную.В конце файла /etc/mdadm.conf добавьте email адрес администратора, на который нужно слать оповещения о проблемах с RAID:
Останолось перезапустить службу mdmonitor через systemctl:
После этого система будет оповещать вас по email об ошибках в mdadm и неисправных дисках.
RAID массив в состоянии inactive
При сбоях оборудования или аварийного выключения по питанию, массив может перейти в состояние inactive. Все диски помечаются как неактивные, но ошибок на дисках нет.
В этом случае нужно остановить массив командой:
И пересобрать его:
Если массив прописан в /etc/fstab, нужно перемонтировать его командой:
Утилита mdadm упрощает работу с raid-массивами в Linux. В данной статье я описал основные моменты работы с данной утилитой, а также затронул самые частые вопросы, которые возникают при работе с raid-массивами через утилиту mdadm.
Команду «smartctl -d ata -a /dev/sdb» можно использовать для проверки жесткого диска и текущего состояния его соединения с системой. Но как с помощью команд smartctl проверить SAS или SCSI диски, спрятанные за RAID контроллером Adaptec в системах под управлением Linux ОС? Для этого необходимо использовать последовательные синтаксисы проверки SAS или SATA. Как правило — это логические диски для каждого массива физических накопителей в операционной системы. Команду /dev/sgX возможно использовать в качестве перехода через контроллеры ввода/вывода, которые обеспечиваюь прямой доступ к каждому физическому диску, подключенному к RAID контроллеру Adaptec.

Распознает ли Linux контроллер Adaptec RAID?
Для проверки Вы можете использовать следующую команду:
В результате выполнения команды получите следующее:
Загрузка и установка Adaptec Storage Manager для Linux
Необходимо установить Adaptec Storage Manager в соответсвии собранному дисковому массиву.
Проверяем состояния SATA диска
Команда для сканирования накопителя выглядит довольно просто:
В результате у Вас должно получится следующее:
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg . Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
Для SAS диск используют следующий синтаксис:
В результате получим что то похожее на:
А вот команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
Проверить жесткий диск можно с помощью следующих команд:
Использование Adaptec Storage Manager
Другие простые команды для проверки базового состояния выглядят следующим образом:
Обратите внимание на то, что более новая версия arcconf расположена в архиве /usr/Adaptec_Event_Monitor. Таким образом, весь путь должен выглядеть так:
Вы можете самостоятельно проверить состояние массива Adaptec RAID на Linux с помощью ввода простой команды:
Или (более поздняя версия):
Примерный результат на фото:
По традиции, немного рекламы в подвале, где она никому не помешает. Напоминаем, что в связи с тем, что общая емкость сети нидерландского дата-центра, в котором мы предоставляем услуги, достигла значения 5 Тбит / с (58 точек присутствия, включения в 36 точек обмена, более, чем в 20 странах и 4213 пиринговых включений), мы предлагаем выделенные серверы в аренду по невероятно низким ценам, только неделю!.
Программный RAID проще и безопаснее, т. к. если что-то выйдет из строя, то RAID достаточно просто восстановить, а если выйдет из строя аппаратный RAID контроллер, то проблем будет больше.
Выбор дисков для RAID массивов
Для отображения подключенных дисков выполним команду:

Создание RAID1 массива
Выполним следующие команды для создания массивов для БД и логов:
На вопрос Continue creating array? отвечаем y.
Проверим результат выполнения команд:

Настройка RAID массивов
Разметим пространство. В качестве файловой системы выберем ext4:
Создадим конфигурационный файл для утилиты mdadm:
Монтируем созданные RAID массивы в каталог /raid:
Для автоматического монтирования RAID массивов при загрузке системы выполним команду:
в открывшемся файле добавим строчки:
/dev/md0 /raid200 ext4 defaults 1 2
/dev/md1 /raid120 ext4 defaults 1 2
Примеры использования mdadm
Пометка диска как сбойного
Удаление сбойного диска
Добавление нового диска
Сборка существующего массива
Расширение массива
Проверяем, что диск (раздел) добавился:
Если раздел действительно добавился, мы можем расширить массив:
Рекомендуется задать файл бэкапа на случай прерывания перестроения массива, например добавить:
При необходимости, можно регулировать скорость процесса расширения массива, указав нужное значение в файлах
Убедитесь, что массив расширился:
Нужно обновить конфигурационный файл с учётом сделанных изменений:
Переименование массива
Для начала отмонтируйте и остановите массив:
Затем необходимо пересобрать как md5 каждый из разделов sd[abcdefghijk]1
Удаление массива
Для начала отмонтируйте и остановите массив:
Затем необходимо затереть superblock каждого из составляющих массива:
Если действие выше не помогло, то затираем так:
Заключение
В итоге мы получили два программных RAID массива уровня 1, которые будем использовать для баз данных 1С:Предприятие 8.3
Читайте также: