
Python не видит модуль linux
Обновлено: 03.07.2024
Мы пытались без каких-либо успехов импортировать модули из одной папки в другую, например:
Что дает результат:
Мы попытались добавить свой путь к переменной sys.path, но без успеха.
Мы также пытались использовать os.walk для вставки всех путей в переменную PATH, но при этом мы получаем ту же ошибку, хотя мы проверили, что PATH содержит путь для поиска модулей.
Мы используем Python 2.7 для Linux Ubuntu 13.10.
Есть ли что-то, что мы можем делать неправильно?
Получение прав импорта при запуске script, который живет внутри пакета, является сложным. Вы можете прочитать этот раздел (печально отложенный) PEP 395 для описания нескольких способов, которые не работают для запуска такого script.
Дайте иерархию файловой системы, например:
Есть только несколько способов сделать работу my_script.py правильной.
Первым было бы поместить папку top_level в переменную среды PYTHONPATH или использовать файл .pth для достижения того же самого. Или, как только интерпретатор запущен, вставьте эту папку в sys.path (но это может стать уродливым).
Обратите внимание, что вы добавляете top_level к пути, а не my_package ! Я подозреваю, что это то, что вы перепутали в своих текущих попытках этого решения. Его очень легко ошибиться.
Тогда абсолютный импорт, такой как import my_package.sub_package.module_a , будет работать в основном. (Просто не пытайтесь импортировать package.scripts.my_script сам, пока он работает как модуль __main__ , или вы получите странную дублируемую копию модуля.)
Тем не менее, абсолютный импорт всегда будет более подробным, чем относительный импорт, поскольку вам всегда нужно указывать полный путь, даже если вы импортируете модуль sibling (или "племенной" модуль, например module_c из module_a ). При абсолютном импорте способ получить module_c всегда является большим, уродливым языком кода from my_package.sub_package.sub_sub_package import module_c , независимо от того, какой модуль выполняет импорт.
По этой причине использование относительного импорта часто более изящно. Увы, им трудно работать с script. Единственные способы:
Запустите my_script из папки top_level с флагом -m (например, python -m my_package.scripts.my_script ) и никогда не будет по имени файла.
Он не будет работать, если вы находитесь в другой папке, или если вы используете другой метод для запуска script (например, нажатие F5 в среде IDE). Это несколько негибко, но на самом деле нет способа облегчить его (пока PEP 395 не будет отменен и не будет реализован).
Настройте sys.path как для абсолютного импорта (например, добавьте top_level в PYTHONPATH или что-то еще), затем используйте PEP 366 __package__ , чтобы сообщить Python, что такое ожидаемый пакет вашего script. То есть, в my_script.py вы хотели бы добавить что-то подобное выше всех ваших относительных импорта:
Это потребует обновления, если вы реорганизуете свою файловую организацию и переместите script в другой пакет (но это, вероятно, меньше работает, чем обновление большого количества абсолютных импортов).
После того, как вы внедрили один из этих юнитов, ваш импорт может стать проще. Импорт module_c из module_a становится from .sub_sub_package import module_c . В my_script относительный импорт, такой как from ..subpackage import module_a , будет работать.
Существует следующий путь до папки: E:ProgrammingPython_projectsMyModulesECG_class В папке ECG_class имеется два файла:
В файле ecg.py есть класс ECG(), который нужно импортировать.
В переменных среды PATH добавил путь: E:ProgrammingPython_projectsMyModulesECG_class
Импортировал следующим образом:

2 ответа 2
Проверил то, что вроде вы делаете. Добавил в PATH директорию. Положил туда py -файл. Затем открыл консоль python .
Если у вас не получается и нужно наверняка, то добавьте в переменную окружения PYTHONPATH свой каталог.
Также вы можете добавить сразу в скрипте:
В Python 3 существует несколько способов импорта: абсолютный и относительный.
При абсолютном импорте поиск модуля выполняется из путей из списка os.path
При таком иморте поиск будет идти по этим путям:
Если нужно испортировать модуль, который находится внутри текущего то нужно импортировать по отностиельному пути:
Когда запускажю python3 manage.py makemigrations , выдает в конце:
В файле _django.py находяться настройки проекта. Подскажите пожалуйста почему его не видно из файла __init__.py , почему не импортирует, может что то не дописал. PyCharm не ругается, он видит норм. Может у кого то было такое, подскажите. Заранее спасибо.
1 Ответы
Чтобы джанго импортировал модуль правильно, нужно явно указать ему путь от текущего модуля. В вашем случае это from [name_project].settings._django import * , как указал в комментарии @andreymal. Для импорта модулей есть два исключения: если импортируемая библиотека находится в той же директории, что и скрипт, в который вы её загружаете, либо если она находится в стандартном пути импорта модулей (например, в виртуальном окруженииLibsite-packages), то путь можно не указывать. В ссылке, которую вы привели, это описывается в разделе «Куда поместить модуль?»:
Edit: у меня 2 версии питона - 2.7.10 (из исходников) и 2.7.3. Поможет если удалить один из них?
Edit 2: причина найдена, дальше здесь
788 2 2 золотых знака 6 6 серебряных знаков 17 17 бронзовых знаков А python ставился из репозитория или из исходников? Во втором случае, вполне закономерно, что используется site-packages вместо dist-packages - "What is the difference between dist-packages and site-packages?". Попробуйте воспользоваться этим ответом: "How to globally modify the default PYTHONPATH (sys.path)?". Также есть вариант поставить пакет в site-packages . Насчет того, чтобы удалять один из них - сами смотрите. Если Вам нужен именно 2.7.10, то проще настроить sys.path . Либо же, можно запускать скрипт с указанием интерпритатора питона (посмотрите в дректории bin какие именно исполняемые файлы за какую версию питона отвечают). Дак как ставили - так и сносите, в чём проблема то? Вы ведь даже не написали ни дистрибутив, ни откуда исходники взяли, ни чем собирали, собирали ли пакет, выполнили checkinstal или make install. От этого же много зависит. Если checkinstall - у вас пакет и удаляйте его менеджером пакетов, если make install - он равномерно размазался у вас по системе вне менеджера пакетов - т.е. либо скрипт удаления, если таковой есть, либо ручками идёте собирать по системе эти самые размазанные файлы. Поподробнее расскажите чего вы там наустанавливали из исходников. @SmitJohnth: как мне снести старую версию — правильнее всего будет задать новый вопрос по этому поводу.Согласно Debian Python Wiki, директория dist-packages используется, если Вы ставили Python из репозитория. Если Вы собирали Python из исходников, вместо dist-packages будет использоваться директория site-packages , чтобы нивелировать возможные конфликты между версиями Python. Оригинальная цитата:
dist-packages instead of site-packages . Third party Python software installed from Debian packages goes into dist-packages , not site-packages . This is to reduce conflict between the system Python, and any from-source Python build you might install manually.
Я уже часов семь пытаюсь как-то сделать, чтобы он его увидел: и разные версии питона ставил и переменные среды прописывал (PATH, PYTHONHOME и PYTHONPATH), и в общем-то никуда не сдвинулся.
__________________Помощь в написании контрольных, курсовых и дипломных работ здесь

После установки компонента, делфи не видит его классы
requires rtl, vcl; Устанавливаю, всё нормально устанавливается, но не вылезает окно с.
Установить модуль msgpack через pip
У меня возникла такая проблема: пакет msgpack установлен (pip list отображает пакет версией 0.5.6).
Модуль Wi-Fi не видит сети после его смены. Не могу установить драйвера
Поменяли модуль Wi-Fi, после этого нетбук ASUS 1005 PXD не видит сети и не работает Bluetooth.
Установить модуль selenium через pip на Windows
Привет программисты питон. есть проблема с установкой библиотеки селениум. версия питона 3.4.1.
Добавлено через 4 минуты
ещё надо попробовать установить модуль через pycharm, иногда помогает.
Добавлено через 4 минуты
Вероятно, вы установили библиотеку для другого интерпретатора. Для того, чтобы поставилось к нужному интерпретатору, попробуйте запустить pip следующим образом:
python -m pip install <lib>
Так pip точно будет запущен от нужного интерпретатора.
Добавлено через 2 минуты
на сайте который автомодерируется есть ответы на 99% вопросов это stack overflow но надо искать в гугле на англ - англ использует 97% всего населения земли
Добавлено через 3 минуты
windows 10 использует power shell вместо cmd вроде
Не работает после установки WIN 7x64 разъем ddr2 , либо просто его не видит комп (
Во общем ребят такая вот проблема,не видит компьютер один слот DDR 2,до переустановки win такого не.
Pip install pyinstaller
В чем проблема, форумчане? CMD с правами админа F:\Python>pip install pyinstaller Collecting.
Pip install Из директории Не работает
Подскажите что не так. Скачал дистрибутив selenium распаковал его и пытаюсь запустить в проект.
В начале моего пути к программированию появилась необходимость установить библиотеку requests. Установил её, но PowerShell всё равно ругается, что такой библиотеки нет. Попробовал PyCarm, тоже не видит. Посмотрел путь куда устанавливается библиотека и там всё хорошо, библиотека есть.
Вот этот путь я проверял:
```
PS C:\Windows\system32> python -m pip install requests
После продолжнительных мучений с поиском проблемы оказалось,
в powershell запускается из папки . python38 ,
а в pycharm вообще папка . python37 )
В pycharm путь правится в настройках
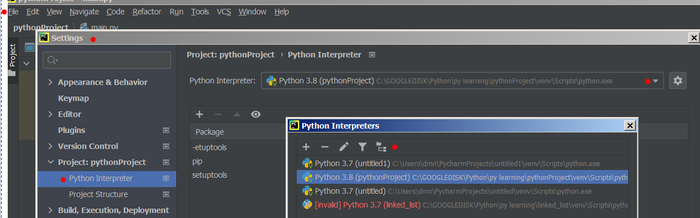
Для powershell неохбходимо в "переменные среды" менять пути на python38
windows 7 python v3.8
в пичерме создавай проекты через venv
и через консоль внутри пичарма пип-ом и пользуйся

Карантин -- самое время подтянуть навыки программирования. Практика программирования с использованием Python, Хирьянов Т.Ф, лекция 9
Вот уже на протяжении нескольких лет Тимофей, преподаватель кафедры информатики МФТИ, выкладывает свои лекции по программированию на своём Youtube канале с открытым доступом.


Разработка системы заметок с нуля. Часть 2: REST API для RESTful API Service + JWT + Swagger
Продолжаем серию материалов про создание системы заметок. В этой части мы спроектируем и разработаем RESTful API Service на Go cо Swagger и авторизацией. Будет много кода, ещё больше рефакторинга и даже немного интеграционных тестов.
В первой части мы спроектировали систему и посмотрели, какие сервисы требуются для построения микросервисной архитектуры.
Подробности в видео и текстовой расшифровке под ним.
Прототипирование
Начнём с макетов интерфейса. Нам нужно понять, какие ручки будут у нашего API и какой состав данных он должен отдавать. Макеты мы будем делать, чтобы понять, какие сущности, поля и эндпоинты нам нужны. Используем для этого онлайн-сервис NinjaMock. Он подходит, если макет надо сделать быстро и без лишних действий.
После входа в приложение пользователь увидит список заметок, который будет выглядеть примерно так:
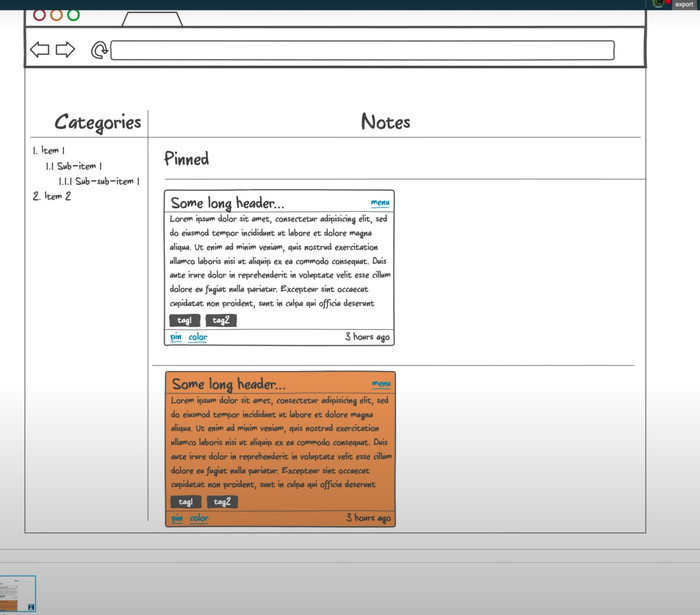
Интерфейс, который будет у нашего веб-приложения:
- Слева — список категорий любой вложенности.
- Справа — список заметок в виде карточек, который делится на два списка: прикреплённые и обычные карточки.
- Каждая карточка состоит из заголовка, который урезается, если он очень длинный.
- Справа указано, сколько секунд/минут/часов/дней назад была создана заметка.
- Тело заголовка — отрендеренный Markdown.
- Панель инструментов. Через неё можно изменить цвет, прикрепить или удалить заметку.
Тут важно отметить, что файлы заметки мы не отображаем и не будем запрашивать у API для списка заметок.
Полная карточка открывается по клику на заметку. Тут можно сразу отобразить полностью длинный заголовок. Высота заметки зависит от количества текста. Для файлов появляется отдельная секция. Мы их будем получать отдельным асинхронным запросом, который не помешает пользователю редактировать заметку. Файлы можно скачать по ссылке, также есть отдельная кнопка на добавление файлов.
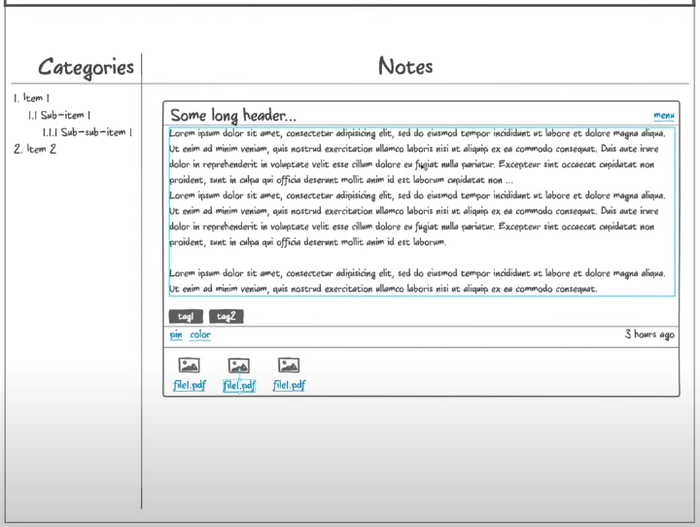
Так будет выглядеть открытая заметка
В ходе прототипирования стало понятно, что в первой части мы забыли добавить еще один микросервис — TagsService. Он будет управлять тегами.
Определение эндпоинтов
Для страниц авторизации и регистрации нам нужны эндпоинты аутентификации и регистрации соответственно. В качестве аутентификации и сессий пользователя мы будем использовать JWT. Что это такое и как работает, разберём чуть позднее. Пока просто запомните эти 3 буквы.
Для страницы списка заметок нам нужны эндпоинты /api/categories для получения древовидного списка категорий и /api/notes?category_id=? для получения списка заметок текущей категории. Перемещаясь по другим категориям, мы будем отдельно запрашивать заметки для выбранной категории, а на фронтенде сделаем кэш на клиенте. В ходе работы с заметками нам нужно уметь создавать новую категорию. Это будет метод POST на URL /api/categories. Также мы будем создавать новый тег при помощи метода POST на URL /api/tags.

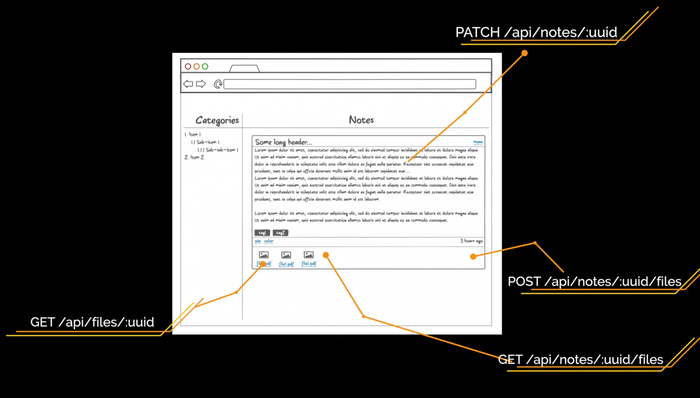
Структура репозитория системы
Ещё немного общей информации. Структура репозитория всей системы будет выглядеть следующим образом:
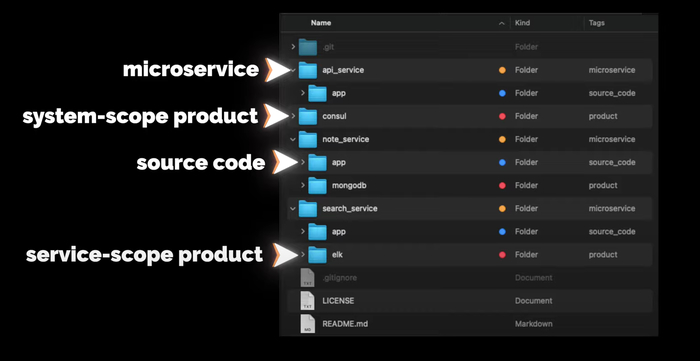
В директории app будет исходный код сервиса (если он будет). На уровне с app будут другие директории других продуктов, которые используются с этим сервисом, например, MongoDB или ELK. Продукты, которые будут использоваться на уровне всей системы, например, Consul, будут в отдельных директориях на уровне с сервисами.
Разработка сервиса
Писать будем на Go
- Идём на официальный сайт.
- Копируем ссылку до архива, скачиваем, проверяем хеш-сумму.
- Распаковываем и добавляем в переменную PATH путь до бинарников Go
- Пишем небольшой тест проверки работоспособности, собираем бинарник и запускаем.
Установка завершена, всё работает
Теперь создаём проект. Структура стандартная:
- build — для сборок,
- cmd — точка входа в приложение,
- internal — внутренняя бизнес-логика приложения,
- pkg — для кода, который можно переиспользовать из проекта в проект.
Я очень люблю логировать ход работы приложения, поэтому перенесу свою обёртку над логером logrus из другого проекта. Основная функция здесь Init, которая создает логер, папку logs и в ней файл all.log со всеми логами. Кроме файла логи будут выводиться в STDOUT. Также в пакете реализована поддержка логирования в разные файлы с разным уровнем логирования, но в текущем проекте мы это использовать не будем.
APIService будет работать на сокете. Создаём роутер, затем файл с сокетом и начинаем его слушать. Также мы хотим перехватывать от системы сигналы завершения работы. Например, если кто-то пошлёт приложению сигнал SIGHUP, приложение должно корректно завершиться, закрыв все текущие соединения и сессии. Хотел перехватывать все сигналы, но линтер предупреждает, что os.Kill и SIGSTOP перехватить не получится, поэтому их удаляем из этого списка.
Теперь давайте добавим сразу стандартный handler для метрик. Я его копирую в директорию pkg, далее добавляю в роутер. Все последующие роутеры будем добавлять так же.
Далее создаём точку входа в приложение. В директории cmd создаём директорию main, а в ней — файл app.go. В нём мы создаём функцию main, в которой инициализируем и создаём логер. Роутер создаём через ключевое слово defer, чтобы метод Init у роутера вызвался только тогда, когда завершится функция main. Таким образом можно выполнять очистку ресурсов, закрытие контекстов и отложенный запуск методов. Запускаем, проверяем логи и сокет, всё работает.
Но для разработки нам нужно запускать приложение на порту, а не на сокете. Поэтому давайте добавим запуск приложения на порту в наш роутер. Определять, как запускать приложение, мы будем с помощью конфига.
Создадим для приложения контекст. Сделаем его синглтоном при помощи механизма sync.Once. Пока что в нём будет только конфиг. Контекст в виде синглтона создаю исключительно в учебных целях, впоследствии он будет выпилен. В большинстве случаев синглтоны — необходимое зло, в нашем проекте они не нужны. Далее создаём конфиг. Это будет YAML-файл, который мы будем парсить в структуру.
В роутере мы вытаскиваем из контекста конфиг и на основании listen.type либо создаем сокет, либо вешаем приложение на порт. Код graceful shutdown выделяем в отдельный пакет и передаём на вход список сигналов и список интерфейсов io.Close, которые надо закрывать. Запускаем приложение и проверяем наш эндпоинт heartbeat. Всё работает. Давайте и конфиг сделаем синглтоном через механизм sync.Once, чтобы потом безболезненно удалить контекст, который создавался в учебных целях.
Теперь переходим к API. Создаём эндпоинты, полученные при анализе прототипов интерфейса. Тут важно отметить, что у нас все данные привязаны к пользователю. На первый взгляд, все ручки должны начинаться с пользователя и его идентификатора /api/users/:uuid. Но у нас будет авторизация, иначе любой пользователь сможет программно запросить заметки любого другого пользователя. Авторизацию можно сделать следующим образом: Basic Auth, Digest Auth, JSON Web Token, сессии и OAuth2. У всех способов есть свои плюсы и минусы. Для этого проекта мы возьмём JSON Web Token.
Работа с JSON Web Token
JSON Web Token (JWT) — это JSON-объект, который определён в открытом стандарте RFC 7519. Он считается одним из безопасных способов передачи информации между двумя участниками. Для его создания необходимо определить заголовок (header) с общей информацией по токену, полезные данные (payload), такие как id пользователя, его роль и т.д., а также подписи (signature).
JWT использует преимущества подхода цифровой подписи JWS (Signature) и кодирования JWE (Encrypting). Подпись не даёт кому-то подделать токен без информации о секретном ключе, а кодирование защищает от прочтения данных третьими лицами. Давайте разберёмся, как они могут нам помочь для аутентификации и авторизации пользователя.
Аутентификация — процедура проверки подлинности. Мы проверяем, есть ли пользователь с полученной связкой логин-пароль в нашей системе.
Авторизация — предоставление пользователю прав на выполнение определённых действий, а также процесс проверки (подтверждения) данных прав при попытке выполнения этих действий.
Другими словами, аутентификация проверяет легальность пользователя. Пользователь становится авторизированным, если может выполнять разрешённые действия.
Важно понимать, что использование JWT не скрывает и не маскирует данные автоматически. Причина использования JWT — проверка, что отправленные данные были действительно отправлены авторизованным источником. Данные внутри JWT закодированы и подписаны, но не зашифрованы. Цель кодирования данных — преобразование структуры. Подписанные данные позволяют получателю данных проверить аутентификацию источника данных.
Реализация JWT в нашем APIService:
- Создаём директории middleware и jwt, а также файл jwt.go.
- Описываем кастомные UserClaims и сам middlware.
- Получаем заголовок Authorization, оттуда берём токен.
- Берём секрет из конфига.
- Создаём верификатор HMAC.
- Парсим и проверяем токен.
- Анмаршалим полученные данные в модель UserClaims.
- Проверяем, что токен валидный на текущий момент.
При любой ошибке отдаём ответ с кодом 401 Unauthorized. Если ошибок не было, в контекст сохраняем ID пользователя в параметр user_id, чтобы во всех хендлерах его можно было получить. Теперь надо этот токен сгенерировать. Это будет делать хендлер авторизации с методом POST и эндпоинтом /api/auth. Он получает входные данные в виде полей username и password, которые мы описываем отдельной структурой user. Здесь также будет взаимодействие с UserService, нам надо там искать пользователя по полученным данным. Если такой пользователь есть, то создаём для него UserClaims, в которых указываем все нужные для нас данные. Определяем время жизни токена при помощи переменной ExpiresAt — берём текущее время и добавляем 15 секунд. Билдим токен и отдаём в виде JSON в параметре token. Клиента к UserService у нас пока нет, поэтому делаем заглушку.
Добавим в хендлер с heartbeat еще один тестовый хендлер, чтобы проверить работу аутентификации. Пишем небольшой тест. Для этого используем инструмент sketch, встроенный в IDE. Делаем POST-запрос на /api/auth, получаем токен и подставляем его в следующий запрос. Получаем ответ от эндпоинта /api/heartbeat, по истечении 5 секунд мы начнём получать ошибку с кодом 401 Unauthorized.
Наш токен действителен очень ограниченное время. Сейчас это 15 секунд, а будет минут 30. Но этого всё равно мало. Когда токен протухнет, пользователю необходимо будет заново авторизовываться в системе. Это сделано для того, чтобы защитить пользовательские данные. Если злоумышленник украдет токен авторизации, который будет действовать очень большой промежуток времени или вообще бессрочно, то это будет провал.
Чтобы этого избежать, прикрутим refresh-токен. Он позволит пересоздать основной токен доступа без запроса данных авторизации пользователя. Такие токены живут очень долго или вообще бессрочно. После того как только старый JWT истекает мы больше не можем обратиться к API. Тогда отправляем refresh-токен. Нам приходит новая пара токена доступа и refresh-токена.
Хранить refresh-токены на сервере мы будем в кэше. В качестве реализации возьмём FreeCache. Я использую свою обёртку над кэшем из другого проекта, которая позволяет заменить реализацию FreeCache на любую другую, так как отдает интерфейс Repository с методами, которые никак не связаны с библиотекой.
Пока рассуждал про кэш, решил зарефакторить существующий код, чтобы было удобней прокидывать объекты без dependency injection и синглтонов. Обернул хендлеры и роутер в структуры. В хендлерах сделал интерфейс с методом Register, которые регистрируют его в роутере. Все объекты теперь инициализируются в main, весь роутер переехал в мейн. Старт приложения выделили в отдельную функцию также в main-файле. Теперь, если хендлеру нужен какой-то объект, я его просто буду добавлять в конструктор структуры хендлера, а инициализировать в main. Плюс появилась возможность прокидывать всем хендлерам свой логер. Это будет удобно когда надо будет добавлять поле trace_id от Zipkin в строчку лога.
Вернемся к refresh_token. Теперь при создании токена доступа создадим refresh_token и отдадим его вместе с основным. Сделаем обработку метода PUT для эндпоинта /api/auth, а в теле запроса будем ожидать параметр refresh_token, чтобы сгенерировать новую пару токена доступа и refresh-токена. Refresh-токен мы кладём в кэш в качестве ключа. Значением будет user_id, чтобы по нему можно было запросить данные пользователя у UserService и сгенерировать новый токен доступа. Refresh-токен одноразовый, поэтому сразу после получения токена из кэша удаляем его.
Описание API
Для описания нашего API будем использовать спецификацию OpenAPI 3.0 и Swagger — YAML-файл, который описывает все схемы данных и все эндпоинты. По нему очень легко ориентироваться, у него приятный интерфейс. Но описывать вручную всё очень муторно, поэтому лучше генерировать его кодом.
- Создаём эндпоинты /api/auth с методами POST и PUT для получения токена по юзернейму и паролю и по Refresh-токену соответственно.
- Добавляем схемы объектов Token и User.
- Создаём эндпоинты /api/users с методом POST для регистрации нового пользователя. Для него создаём схему CreateUser.
У нас есть подсказка в виде Swagger-файла. На его основе создаём все нужные хендлеры. Там, где вызов микросервисов, будем проставлять комментарий с TODO.
Создаём хендлер для категорий, определяем URL в константах. Далее создаём структуры. Опираемся на Swagger-файл, который создали ранее. Далее создаём сам хендлер и реализуем метод Register, который регистрирует его в роутере. Затем создаём методы с логикой работы и сразу пишем тест API на этот метод. Проверяем, находим ошибки в сваггере. Таким образом мы создаём все методы по работе с категориями: получение и создание.
Далее создаём таким же образом хендлер для заметок. Понимаем, что забыли методы частичного обновления и удаления как для заметок, так и для категорий. Дописываем их в Swagger и реализуем методы в коде. Также обязательно тестируем Swagger в онлайн-редакторе.
Здесь надо обратить внимание на то, что методы создания сущности возвращают код ответа 201 и заголовок Location, в котором находится URL для получения сущности. Оттуда можно вытащить идентификатор созданной сущности.
В третьей части мы познакомимся с графовой базой данных Neo4j, а также будем работать над микросервисами CategoryService и APIService.
Читайте также: