
Сменить кодировку в консоли linux
Обновлено: 29.06.2024
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или --mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
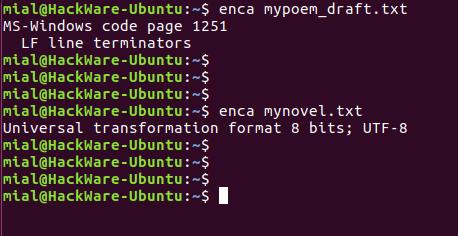
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
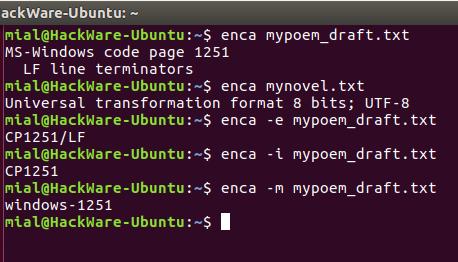
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.

то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или --from-code означает кодировку исходного файла -t или --to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
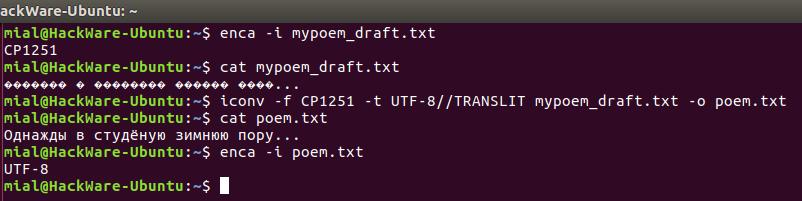
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Если у вас в один прекрасный день в консоли вместо русских букв появились всякие не понятные символы, как например квадратики, не переживайте, так как это легко исправляется. Кстати, такие символы на сленге называются - кракозябры.
Кракозя́бры (крякозя́бры) — жаргонизм, обозначающий бессмысленный с точки зрения читателя набор символов, чаще всего получаемый на компьютере в результате неправильного перекодирования осмысленного текста. В единственном числе — вообще любой компьютерный символ, для которого в русском языке нет общеизвестного названия, например, значок @. Чаще всего кракозябры образуются на выводе программ по причине неправильно настроенной кодировки символов, а также из-за использования неподходящего шрифта.
Пара примеров из того же Wiki:
А теперь перейдём к решению.
Для редактирования отображения симвлов в консоли существует специальный конфигуратор который запускается такой командой:
Далее все действия производятся в консольном графическом конфигураторе простым выбором необходимых пунктов с помощью кнопок вверх, вниз и “Enter”.
Выбираем кодировку - UTF-8 :

Выбираем таблицу символов - Кирилица - славянские языки (5 пункт):

Выбираем шрифт - Fixed или TerminusBold :

Выбираем размер шрифта - 8x16 :

Для того, чтобы наша настройка не слетела после перезагрузки нужно проделать следующее:
В открывшемся текстовом файле находим exit 0 и над этой строкой пишем:
Если эта статья помогла вам, пожалуйста, оставьте комментарий
Спасибо за прочтение!

Локаль (locale или локализация) в Linux определяет, какой язык и какой набор символов (кодировку), пользователь видит в терминале. Посмотрим, как проверить текущие настройки языка и кодировки, как получить список всех доступных локалей, как сменить язык и кодировку для текущей сессии или установить их постоянно.
Для тех, кому лень читать всю статью до конца — чаще всего для локализации консоли достаточно повторно сконфигурировать пакет locales :
Сначала будут созданы нужные локали (их выбрать на первом экране), потом установлена локаль по умолчанию (ее выбрать на втором экране).
Текущие настройки языка
Посмотрим информацию о текущем языковом окружении:
Список доступных локалей
Теперь посмотрим список всех установленных языков и кодировок:
Есть только системная локаль C.UTF-8 , которая присутствует всегда. А нам надо добавить еще две локали — en_US.UTF-8 и ru_RU.UTF-8 .
Добавить новую локаль
Смотрим список всех поддерживаемых (доступных для установки) локалей:
Устанавливаем нужные локали — en_US.UTF-8 и ru_RU.UTF-8 :
Второй способ установить локали — расскомментровать нужные строки в файле /etc/locale.gen
И просто выполнить команду locale-gen без указания локалей:
Подробная информация о локалях
Более подробную информацию об установленных в системе локалях можно посмотреть так:
Часть локалей размещена в архиве /usr/lib/locale/locale-archive , а часть — в директориях внутри /usr/lib/locale/ .
Локаль по-умолчанию
Хорошо, нужные локали у нас теперь есть, осталось только задать локаль по умолчанию:
Эта команда запишет в файл /etc/default/locale строку:
После этого надо будет перезайти в систему. И проверяем информацию о языковом окружении:
Теперь все правильно, так что запишем эту информацию в файл /etc/default/locale :
Быстрая локализация
До сих пор мы все делали ручками, но если лень — можно просто повторно сконфигурировать пакет locales . Сначала будут созданы нужные локали (их нужно выбрать на первом экране), потом установлена локаль по умолчанию (ее нужно выбрать на втором экране).


Удалить лишние локали
После установки (генерации) локали, она помещается в архив /usr/lib/locale/locale-archive . Файл архива — это файл, отображаемый в память, который содержит все локали системы; он используется всеми локализованными программами. Посмотреть список локалей в архиве можно с помощью команды:
Удалить заданную локаль из файла архива:
Обратите внимание на название локали — ru_UA.utf8 , а не ru_UA.UTF-8 . Если неправильно указать локаль — она не будет удалена из архива:
В случае, если утилита locale-gen была вызвана с опцией --no-archive , надо удалить соответствующую директорию в /usr/lib/locale :
Переводы для системных программ
Локализация для текущей сессии
Достаточно временно установить переменную окружения LANG в текущей сессии терминала:
Или даже так — передать переменную LANG конкретной программе:
Файлы конфигурации шрифта и клавиатуры
Настройки можно найти в файлах конфигурации /etc/default/console-setup и /etc/default/keyboard :
Это системные настройки, пользователь может создать свои в файлах
Настройка шрифта и клавиатуры
Чтобы сформировать файлы конфигурации /etc/default/console-setup и /etc/default/keyboard можно использовать команды:

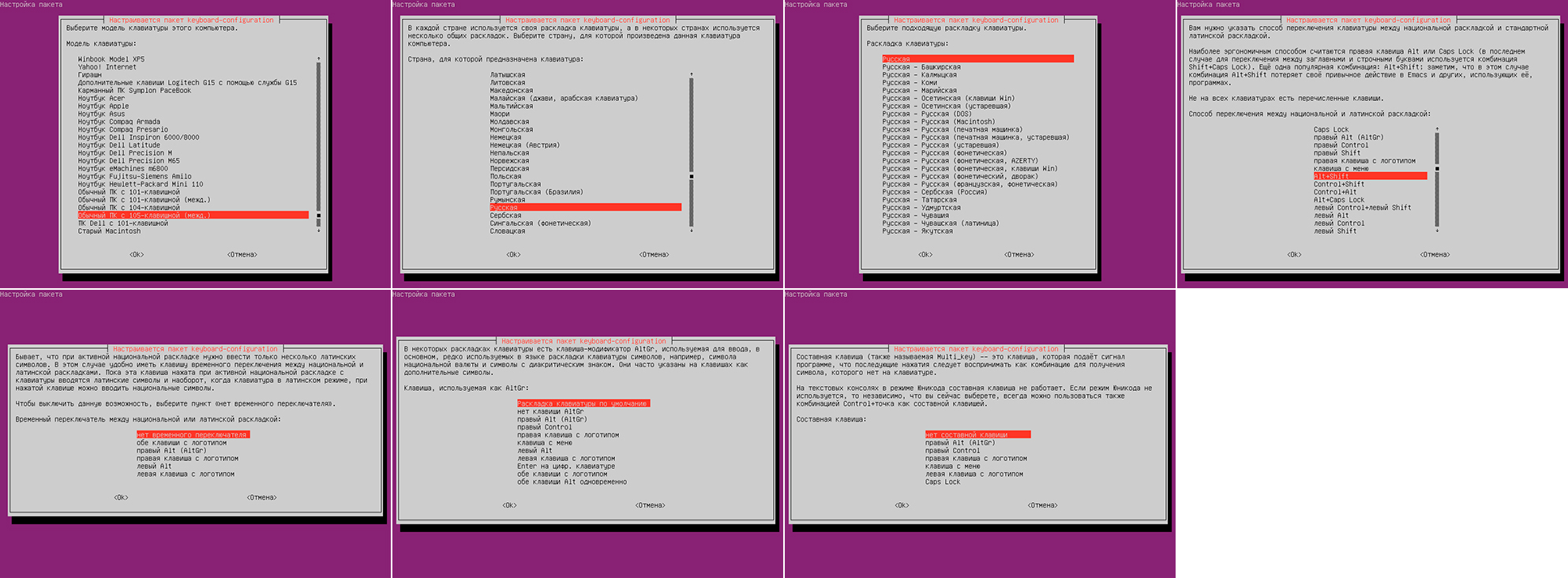
После того, как файлы конфигурации будут сформированы, нужно выполнить команду setupcon без аргументов или перезагрузить систему.
До тех пор, пока мы не вносим каких-либо «поправок» в проинициализировавшуюся систему ввода-вывода и используем только оператор print с unicode строками, всё идёт более-менее нормально вне зависимости от ОС.
Теоретический экскурс
- Кодировка по-умолчанию модуля sys — sys.getdefaultencoding()
- Предпочитаемая кодировка для текущей локали — locale.getpreferredencoding()
- Кодировка стандартных потоков sys.stdout, sys.stderr
- Кое-какую смуту вносит и кодировка самого файла, но договоримся, что у нас всё унифицировано и все файлы в utf-8 и содержат корректный заголовок
- «Бонусом» идёт любовь стандартных потоков выдавать исключения, если, даже при корректно установленной кодировке, не найдётся нужного символа при печати unicode строки
Ищем решение
Очевидно, чтобы избавиться от всех этих проблем, надо как-то привести их к единообразию.
И вот тут начинается самое интересное:
Ага! Оказывается «система» у нас живёт вообще в ASCII. Как следствие — попытка по-простому работать с вводом/выводом заканчивается «любимым» исключением UnicodeEncodeError/UnicodeDecodeError .
Кроме того, как замечательно видно из примера, если в linux у нас везде utf-8, то в Windows — две разных кодировки — так называемая ANSI, она же cp1251, используемая для графической части и OEM, она же cp866, для вывода текста в консоли. OEM кодировка пришла к нам со времён DOS-а и, теоретически, может быть также перенастроена специальными командами, но на практике никто этого давно не делает.
И это, в общем-то, работало. Работало до тех пор, пока пользовался print -ом. При переходе к выводу на экран через logging всё сломалось.
Угу, подумал я, раз «оно» использует кодировку по-умолчанию, — выставлю-ка я ту же кодировку, что в консоли:
Этот код позволяет убить двух зайцев — выставить нужную кодировку и защититься от исключений при печати всяких умляутов и прочей типографики, отсутствующей в 255 символах cp866.
Осталось сделать этот код универсальным — откуда мне знать OEM кодировку на произвольном сферическом компе? Гугление на предмет готовой поддержки ANSI/OEM кодировок в python ничего разумного не дало, посему пришлось немного вспомнить WinAPI
… и собрать всё вместе:
Задача вторая. Раскрашиваем вывод
Насмотревшись на отладочный вывод Джанги в связке с werkzeug, захотелось чего-то подобного для себя. Гугление выдаёт несколько проектов разной степени проработки и удобности — от простейшего наследника logging.StreamHandler , до некоего набора, при импорте автоматически подменяющего стандартный StreamHandler.
Попробовав несколько из них, я, в итоге, воспользовался простейшим наследником StreamHandler, приведённом в одном из комментов на Stack Overflow и пока вполне доволен:
Однако, в Windows всё это работать, разумеется, отказалось. И если раньше можно было «включить» поддержку ansi-кодов в консоли добавлением «магического» ansi.dll из проекта symfony куда-то в недра системных папок винды, то, начиная (кажется) с Windows 7 данная возможность окончательно «выпилена» из системы. Да и заставлять юзера копировать какую-то dll в системную папку тоже как-то «не кошерно».
Снова обращаемся к гуглу и, снова, получаем несколько вариантов решения. Все варианты так или иначе сводятся к подмене вывода ANSI escape-последовательностей вызовом WinAPI для управления атрибутами консоли.
Побродив некоторое время по ссылкам, набрёл на проект colorama. Он как-то понравился мне больше остального. К плюсам именно этого проекта ст́оит отнести, что подменяется весь консольный вывод — можно выводить раскрашенный текст простым print u"\x1b[31;40mЧто-то красное на чёрном\x1b[0m" если вдруг захочется поизвращаться.
Сразу замечу, что текущая версия 0.1.18 содержит досадный баг, ломающий вывод unicode строк. Но простейшее решение я привёл там же при создании issue.
Собственно осталось объединить оба пожелания и начать пользоваться вместо традиционных «костылей»:
Дальше в своём проекте, в запускаемом файле пользуемся:
На этом всё. Из потенциальных доработок осталось проверить работоспособность под win64 python и, возможно, добаботать ColoredHandler чтобы проверял себя на isatty, как в более сложных примерах на том же StackOverflow.
Читайте также: