
Telegraf linux что это
Обновлено: 05.07.2024
В этом посте описаны установка и настройка связки технологий, позволяющих быстро и достаточно просто получить работающий сервис мониторинга.
telegraf - агент по сбору данных
InfluxDB - база, предназначенная для хранения временных рядов (time series)
Grafana - для отображения метрик
В заключении приведен скрипт на ansible, позволяющий развернуть все это легким движением руки.
Предусловия
Все дальнейшие действия выполняются на машине с установленным CentOS7/Red Hat 7.
На сайте influxdata - разработчика InfluxDB и Telegraf представлена следующая схема:

Называют они этот стек технологий TICK stack - по первым буквам (Telegraf, Influxdb, Chronograf, Kapacitor).
В рамках этого поста мы упрощаем эту схему и она принимает следующий вид:

Во-первых мы пока убираем Kapacitor - движок для real-time обработки получаемых данных - его рассмотрим отдельно.
Во-вторых вместо предлагаемого influxdata дашборда Chronograf будем использовать более мощную и гибкую Grafana (хотя это по большому счету - дело вкуса).
Установка и настройка InfluxDB
Начнем с базы, в которой будут храниться результаты наших измерений.
Добавим репозиторий в менеджер пакетов YUM:
Установим influxdb и запустим сервис:
Чтобы сервис работал после перезагрузки машины, введем команду:
Проверяем, что все прошло хорошо, выполнив в консоли команду:
Создадим нашу первую базу командой:
Посмотрим что получилось:
Видим список:отать с базой, ее сначала нужно выбрать - для этого выполняем команду:
Попробуем добавить в базу значения. В документации указан такой формат:
В рамках статьи мы рассматриваем общий случай добавления измерений, очень подробный рассказ о всех возможных форматах команды - в документации здесь.
После этого смотрим какие измерения стали доступны:
Документация обещает нам SQL-like синтаксис, пробуем:
На что обращаем внимание: колонка time в таблице сформировалась автоматически - время мы указали только в первом случае, в остальных - добавилось текущее. Каждый тег стал "колонкой" в табличном представлении, результат измерения попал в колонку value.
Новые теги могут добавляться с любого момента, например так:
Используя SQL-like синтаксис легко можем получить выборку по квартире:
И даже посчитать среднюю температуру по больнице:
Также можно добавлять данные через REST API:
И читать данные через REST API в формате JSON:
На этом краткое знакомство с базой InfluxDB можно закончить, очень много подробной информации при необходимости можно найти в документации. А мы пойдем дальше.
Установка и настройка Telegraf
Telegraf - агент для сбора данных, у него есть множество плагинов как для ввода так и для вывода. Yum-репозиторий influxdata мы уже добавили в самом начале, так что сразу установим telegraf.
Далее надо сгенерировать конфигурационный файл. Для этого наберем команду:
Команда означает следующее: ув. телеграф, будь добр - создай нам конфигурационный файл telegraf.conf, в котором задействуй плагины ввода данных cpu, mem и exec (их вообще очень много, можно хоть данные с сервера minecraft собирать), вывода данных - influxdb (можно еще в grafite, elasticsearch и много куда еще).
Встроенные плагины cpu и mem отвечают за сбор данных об активности процессора и памяти соответственно. А вот плагин exec - предоставляет возможность использовать для сбора данных произвольные скрипты.
В сгенерированном файле видим следующее:
В output plugins -> influxdb указываем/изменяем данные для подключения к базе:
Cмотрим пример настроек плагина exec для сбора данных произвольным скриптом:
Попробуем написать свой такой скрипт:
Задача у скрипта простая - пробуем найти в процессах [k]araf.main.Main ([k] - взято в скобки специально, таким образом мы исключим из вывода сам grep), если выходной код 0 - то выводим строку с данными для influxdb.
Добавляем метрику process_status с тегами host и proc и значением working равным 0 или 1 в зависимости от результата проверки.
Сохраняем этот скрипт как /opt/telegraf/check_karaf.sh и редактируем конфиг:
Кладем полученный конфиг в /etc/telegraf/telegraf.conf и запускаем сервис:
Посмотрим в базе - появились ли данные:
Данные пишутся, на этом с telegraf пока закончим, выполнив напоследок следующую команду, чтобы сервис telegraf запускался после каждой перезагрузки:
Установка и настройка Grafana
Почти готово - осталось настроить дашборд для отображения собранных метрик.
Установим и запустим Grafana:

Авторизуемся, используя стандартные логин и пароль: admin / admin.
Если чуда не произошло и на порту 3000 искомого веб-интерфейса мы не увидели, смотрим логи в /var/log/grafana.
В интерфесе первым делом настраиваем источник данных (datasources - add datasource):

Далее создаем свой первый дашборд и следуя подсказкам интерфейса конструируем запрос, например так:

Дальнейший процесс носит скорее творческий, чем технический характер. По большому счету можно и не знать синтаксис SQL, а ориентироваться на настройки, предоставляемые интерфейсом Grafana.
Создав dashboard, мы можем его экспортировать в json-формате и в дальнейшем загрузить на другом хосте. Мы будем активно использовать эту возможность при создании ansible-скрипта.
Ansible-playbook для быстрого деплоя
Ansible - популярный инструмент для управления конфигурациями. В случае, когда надо выполнить описанные выше действия на большом количестве виртуалок, часть из которых периодически умирают и появляются новые, ansible может очень сильно облегчить жизнь.
Ниже привожу код playbook-а, выполняющего описанные в статье действия. Сразу оговорюсь - playbook приведен для примера и не является образцом аккуратности и правильности с т.з. лучших практик ansible. На практик, конечно, лучше выделить отдельные роли и вызывать их и т.д.
На первом шаге плейбука мы добавляем нужные репозитории и устанавливаем telegraf, influxdb, grafana. Далее на втором шаге конфигурируем telegraf, используя шаблон jinja2, затем запускаем все сервисы и создаем источник данных/импортируем дашборд в grafana, используя REST API.

Telegraf is a plugin-driven server agent for collecting and sending metrics and events from databases, systems, and IoT sensors.
Telegraf is written in Go and compiles into a single binary with no external dependencies, and requires a very minimal memory footprint.
Why use Telegraf?
Collect and send all kinds of data:
- Database: Connect to datasources like MongoDB, MySQL, Redis, and others to collect and send metrics.
- Systems: Collect metrics from your modern stack of cloud platforms, containers, and orchestrators.
- IoT sensors: Collect critical stateful data (pressure levels, temp levels, etc.) from IoT sensors and devices.
Agent: Telegraf can collect metrics from a wide array of inputs and write them into a wide array of outputs. It is plugin-driven for both collection and output of data so it is easily extendable. It is written in Go, which means that it is a compiled and standalone binary that can be executed on any system with no need for external dependencies, no npm, pip, gem, or other package management tools required.
Coverage: With 200+ plugins already written by subject matter experts on the data in the community, it is easy to start collecting metrics from your end-points. Even better, the ease of plugin development means you can build your own plugin to fit with your monitoring needs. You can even use Telegraf to parse the input data formats into metrics. These include: InfluxDB Line Protocol, JSON, Graphite, Value, Nagios, and Collectd.
Flexible: The Telegraf plugin architecture supports your processes and does not force you to change your workflows to work with the technology. Whether you need it to sit on the edge, or in a centralized manner, it just fits with your architecture instead of the other way around. Telegraf’s flexibility makes it an easy decision to implement.
Очень долго хотел написать статью, но не хватало времени. Нигде (в том числе на Хабре) не нашёл такой простой альтернативы munin, как описанная в этой статье.

Я backend developer и очень часто на моих проектах не бывает выделенных админов (особенно в самом начале жизни продукта), поэтому я уже давно занимаюсь базовым администрированием серверов (начальная установка-настройка, бекапы, репликация, мониторинг и т.д.). Мне это очень нравится и я всё время узнаю что-то новое в этом направлении.
В большинстве случаев для проекта хватает одного сервера и мне как старшему разработчику (и просто ответственному человеку) всегда нужно было контролировать его ресурсы, чтобы понимать когда мы упрёмся в его ограничения. Для этих целей было достаточно munin.

Munin
Он легко устанавливается и имеет небольшие требования. Он написан на perl и использует кольцевую базу данных (RRDtool).
Выполняем команды:
apt-get install munin munin-node
service munin-node start
Теперь munin-node будет собирать метрики системы и писать их в бд, а munin раз в 5 минут будет генерировать из этой бд html-отчёты и класть их в папку /var/cache/munin/www
Для удобного просмотра этих отчётов можно создать простой конфиг для nginx
Собственно и всё. Уже можно смотреть любые графики использования процессора, памяти, жёсткого диска, сети и многого другого за день/неделю/месяц/год. Чаще всего меня интересовала нагрузка чтения/записи на жёсткий диск, потому что узким местом всегда была база данных.
Я использую такую комбинацию для мониторинга своих домашних проектов на виртуальном сервере.
Стоит ли говорить, что для большего количества серверов это превращается в самый настоящий ад. Может это из-за того, что munin был разработан в 2003 году и изначально не был рассчитан на это.
Альтернативы munin для мониторинга нескольких серверов
- количество метрик не меньше чем у munin (у него их около 30 базовых графиков и ещё около 200 плагинов в комплекте)
- возможность написания собственных плагинов на bash (у меня было два таких плагина)
- иметь небольшие требования к серверу
- возможность вывода метрик с разных серверов на одном графике без правки конфигов
- уведомления на почту, в slack и telegram
- Time Series Database более мощную чем RRDtool
- простая установка
- ничего лишнего
- бесплатно и с открытым исходным кодом
Cacti
Почти тоже самое, что munin только на php. В качестве базы данных можно использовать rrdtool как у munin или mysql. Первый релиз: 2001 год.

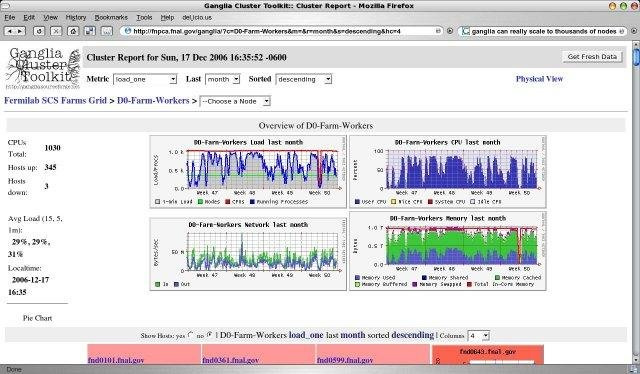
Ganglia
Почти тоже самое, что и предыдущие, написана на php, в качестве базы данных — rrdtool. Первый релиз: 1998 год.
Collectd
Ещё более простая система, чем предыдущие. Написан на c, в качестве базы данных — rrdtool. Первый релиз: 2005 год.

Graphite
Состоит из трёх компонент, написанных на python:
carbon собирает метрики их записывает их в бд
whisper — собственная rrdtool-подобная бд
graphite-web — интерфейс
Первый релиз: 2008 год.

Zabbix
Профессиональная система мониторинга, используется большинством админов. Есть практически всё, включая уведомления на почту (для slack и telegram можно написать простой bash-скрипт). Тяжёлая для пользователя и для сервера. Раньше приходилось пользоваться, впечатления, как будто вернулся с jira на mantis.
Ядро написано на c, веб интерфейс — на php. В качестве базы данных может использовать: MySQL, PostgreSQL, SQLite, Oracle или IBM DB2. Первый релиз: 2001 год.

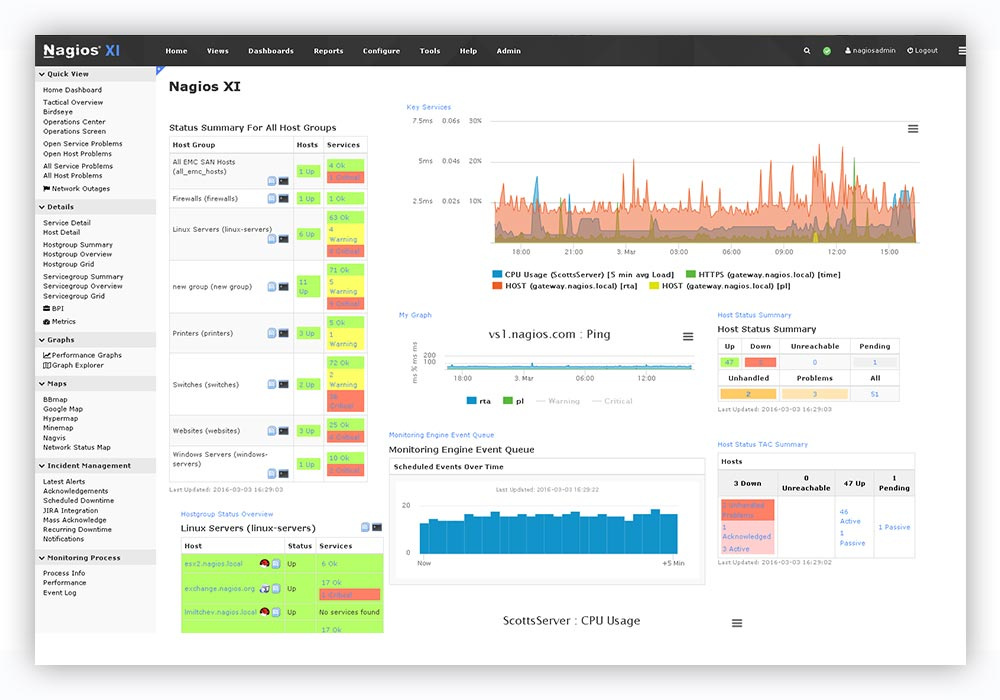
Nagios
Достойная альтернатива Zabbix. Написан на с. Первый релиз: 1999 год.
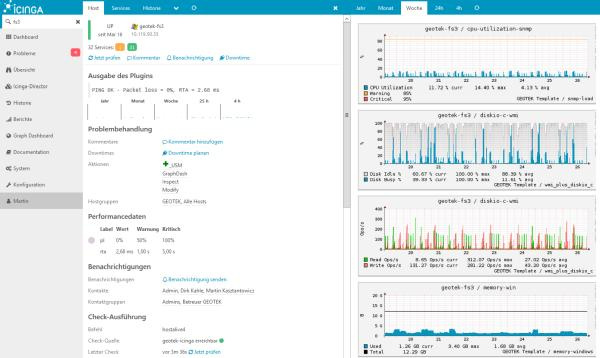
Icinga
Форк Nagios. В качестве бд может использовать: MySQL, Oracle, and PostgreSQL. Первый релиз: 2009 год.
Небольшое отступление
Все вышеперечисленные системы достойны уважения. Они легко устанавливаются из пакетов в большинстве linux-дистрибутивов и уже давно используются в продакшене на многих серверах, поддерживаются, но очень слабо развиваются и имеют устаревший интерфейс.
В половине продуктов используются sql-базы данных, что является не оптимальным для хранения исторических данных (метрик). С одной стороны эти бд универсальны, а с другой — создают большую нагрузку на диски, а данные занимают больше места при хранении.
Для таких задач больше подходят современные бд временных рядов такие как ClickHouse.
Системы мониторинга нового поколения используют базы данных временных рядов, одни из них включают их в свой состав как неотделимую часть, другие используют как отдельную компоненту, а третью могут работать вообще без бд.
Netdata
Вообще не требует базы данных, но может выгружать метрики в Graphite, OpenTSDB, Prometheus, InfluxDB. Написана на c и python. Первый релиз: 2016 год.

Prometheus
Состоит из трёх компонент, написанных на go:
prometheus — ядро, собственная встроенная база данных и веб-интерфейс.
node_exporter — агент, который может быть установлен на другой сервер и пересылать метрики в ядро, работает только с prometheus.
alertmanager — система уведомлений.
Первый релиз: 2014 год.

InfluxData (TICK Stack)
Состоит из четырёх компонент, написанных на go которые могут работать со сторонними продуктами:
telegraf — агент, который может быть установлен на другой сервер и пересылать метрики, а также логи в базы influxdb, elasticsearch, prometheus или graphite, а также в несколько серверов очередей.
influxdb — база данных, которая может принимать данные из telegraf, netdata или collectd.
chronograf — веб интерфейс для визуализации метрик из бд.
kapacitor — система уведомлений.
Первый релиз: 2013 год.

Отдельно хотелось бы упомянуть такой продукт, как grafana, она написана на go и позволяет визуализировать данные из influxdb, elasticsearch, clickhouse, prometheus, graphite, а также отправлять уведомления на почту, в slack и telegram.
Первый релиз: 2014 год.
Выбираем лучшее
В интернете и на Хабре, в том числе, полно примеров использования различных компонент из разных продуктов, чтобы получить то что надо именно тебе.
carbon (агент) -> whisper (бд) -> grafana (интерфейс)
netdata (в качестве агента) -> null / influxdb / elasticsearch / prometheus / graphite (в качестве бд) -> grafana (интерфейс)
node_exporter (агент) -> prometheus (в качестве бд) -> grafana (интерфейс)
collectd (агент) -> influxdb (бд) -> grafana (интерфейс)
zabbix (агент+сервер) -> mysql -> grafana (интерфейс)
telegraf (агент) -> elasticsearch (бд) -> kibana (интерфейс)
… и т.д.
Видел упоминание даже о такой связке:
… (агент) -> clickhouse (бд) -> grafana (интерфейс)
В большинстве случаев в качестве интерфейса использовалась grafana, даже если она была в связке с продуктом, который уже содержал собственный интерфейс (prometheus, graphite-web).
Поэтому (а также в силу её универсальности, простоты и удобства) в качестве интерфейса я остановился на grafana и приступил к выбору базы данных: prometheus отпал потому что не хотелось тянуть весь его функционал вместе с интерфейсом только из-за одной бд, graphite — бд предыдущего десятилетия, переработанная rrdtool-бд предыдущего столетия, ну и собственно я остановился на influxdb и как выяснилось — не один я сделал такой выбор.
Также для себя я решил выбрать telegraf, потому что он удовлетворял моим потребностям (большое количество метрик и возможность написания своих плагинов на bash), а также работает с разными бд, что может быть полезно в будущем.
Итоговая связка у меня получилась такая:
telegraf (агент) -> influxdb (бд) -> grafana (интерфейс+уведомления)
Все компоненты не содержат ничего лишнего и написаны на go. Единственное, чего я боялся — то что эта связку будет трудна в установке и настройке, но как вы сможете видеть ниже — это было зря.
Итак, короткая инструкция по установке TIG:
Telegraf автоматически создаст базу в influxdb с именем «telegraf», логином «telegraf» и паролем «metricsmetricsmetricsmetrics».
Акцент на безопасность
Все порты на ваших серверах должны быть открыты только с тех ip, которым вы доверяете либо в используемых продуктах должна быть включена авторизация и изменены пароли по-умолчанию (я делаю и то и другое).
В influxdb по-умолчанию отключена авторизация и кто угодно может делать что угодно. По-этому если на сервере нет файервола, то крайне рекомендую включить авторизацию:
В настройках источников, нужно указать для influxdb новый логин: «grafana» и пароль «password_for_grafana» из пункта выше.
Также в интерфейсе нужно сменить пароль по-умолчанию для пользователя admin.
Update: добавил пункт к своим критериям «бесплатно и с открытым исходным кодом», забыл его указать с самого начала, а теперь мне советуют кучу платного/условно-бесплатного/триального/закрытого софта. Тут бы с бесплатным разобраться.
2) посмотрел на гитхабе топовые проекты
3) посмотрел, что есть на эту тему на хабре
4) погуглил какие системы сейчас в тренеде
Update2: сейчас группа энтузиастов создаёт таблицу в google docs, сравнивая различные системы мониторинга по ключевым параметрам (Language, Bytes/point, Clustering). Работа кипит, текущий срез под катом.

Update3: ещё одно сравнение Open-Source TSDB в Google Docs. Чуть более проработанное, но систем меньше AnyKey80lvl

У компаний, которым необходимо управлять данными и приложениями на более чем одном сервере, во главу угла поставлена инфраструктура.
Для каждой компании значимой частью рабочего процесса является мониторинг инфраструктурных узлов, особенно при отсутствии прямого доступа для решения возникающих проблем. Более того, интенсивное использование некоторых ресурсов может быть индикатором неисправностей и перегрузок инфраструктуры. Однако мониторинг может использоваться не только для профилактики, но и для оценки возможных последствий использования нового ПО в продакшне. Сейчас для отслеживания потребляемых ресурсов на рынке существует несколько готовых к использованию решений, но с ними, тем не менее, возникают две ключевые проблемы: дороговизна установки и настройки и связанные со сторонним ПО вопросы безопасности.
Первая проблема это вопрос цены: стоимость может варьироваться от десяти евро (потребительские расценки) до нескольких тысяч (корпоративные расценки) в месяц, в зависимости от числа подлежащих мониторингу хостов. Для примера, предположим что мне нужен мониторинг трех узлов в течение одного года. При цене в 10 евро в месяц я потрачу 120 евро, тогда как небольшая компания будет вынуждена раскошелиться на десять-двадцать тысяч, что окажется финансово несостоятельным решением и попросту подорвет весь бюджет.
Вторая проблема это стороннее ПО. Учитывая, что для анализа данные пользователя — будь то частное лицо или компания — должны обрабатываться третьей стороной, возникает вопрос: каким образом третья сторона собирает данные и представляет их пользователю? Обычно для этого на узел устанавливают специальное приложение, через которое и ведется мониторинг, но зачастую такие приложения успевают устареть или оказываются несовместимы с операционной системой клиента. Опыт исследователей в области информационной безопасности проливает свет на проблемы в работе с «проприетарным ПО». Стали бы вы доверять такому ПО? Я — нет.
У меня есть свои узлы как для Tor, так и для некоторых криптовалют, поэтому для мониторинга я предпочитаю бесплатные, легко настраиваемые альтернативы с открытыми исходниками. В этом посте мы рассмотрим три таких инструмента: Grafana, InfluxBD и CollectD.

Мониторинг
Для эффективного анализа каждой метрики нашей инфраструктуры нужно приложение, способное подхватывать статистику с интересующих нас устройств. В этом отношении нам на помощь приходит CollectD: этот демон группирует и собирает («collects», потому и такое имя) все параметры, которые можно хранить на диске или передать по сети.
Данные затем будут переданы инстансу InfluxDB: это база данных временных рядов (time series database, TSBD), которая связывает данные со временем (закодированным в UNIX временную метку) в которое их получил сервер. Таким образом, отправленные CollectD данные поступят уже как последовательность событий.
Наконец, мы воспользуемся Grafana: эта программа свяжется с InfluxDB и отобразит данные на удобных для пользователя цветастых приборных панелях. Благодаря всевозможным графикам и гистограммам мы сможем в реальном времени отслеживать данные CPU, оперативной памяти и так далее.

InfluxDB

Давайте начнем с InfluxDB, свободно распространяемой TSBD для хранения данных в виде последовательности событий. Эта разработанная на Go база данных станет сердцем нашей мониторинговой «системы».
Всякий раз при поступлении данных к ним по умолчанию привязывается UNIX метка. Гибкость такого подхода освобождает пользователя от необходимости хранить переменную «time», что в противном случае оказывается довольно сложным. Давайте представим, что у нас есть несколько расположенных на разных материках устройств. Каким образом мы будем обрабатывать переменную «time»? Станем ли мы привязывать все данные ко времени по Гринвичу, или мы зададим каждому узлу свой часовой пояс? Если данные сохраняются в разных часовых поясах, каким образом нам корректно отобразить их на графиках? Как можно видеть, проблемы возникают одна за другой.
Так как InfluxDB отслеживает время и автоматически проставляет метки на каждое поступление данных, она может синхронно записывать данные в конкретную базу данных. Именно поэтому InfluxDB часто представляют в виде таймлайна: запись данных не влияет на производительность базы данных (что порой случается у MySQL), поскольку запись это всего лишь добавление конкретного события в таймлайн. Поэтому название программы происходит от восприятия времени как бесконечного и неограниченного «потока».
Установка и настройка
Наконец, мы обновим и установим InfluxDB:
Для запуска мы воспользуемся systemctl :
Чтобы к нам не залогинился кто-нибудь с гнусными намерениями, мы создадим пользователя «administrator». Взаимодействовать с базой данных можно через имеющийся в InfluxDB и похожий на SQL язык запросов «InfluxQL». Для создания нового пользователя мы выполним запрос create user .
В том же CLI интерфейсе мы создадим базу данных «metrics», в которой и будем хранить наши метрики.
Затем мы настроим конфигурацию InfluxBD ( /etc/influxdb/influxdb.conf ) таким образом, чтобы интерфейс открывался через порт 24589 (UDP) с прямым соединением к базе данных «metrics» для поддержки CollectD. Также нам надо будет скачать файл types.db и поместить его по адресу /usr/share/collectd/ (или в любую другую папку) для корректного определения данных, которые CollectD передает в родном формате.
Больше про CollectD в конфигурации можно прочесть в документации.
CollectD

CollectD в нашей мониторинговой инфраструктуре будет исполнять роль агрегатора данных, который упрощает передау данных до InfluxDB. По определению CollectD собирает метрики с CPU, оперативной памяти, жестких дисков, сетевых интерфейсов, процессов… Потенциал этой программы безграничен, особенно если учесть широкий выбор как уже доступных плагинов, так и набор запланированных.
Как можно видеть, установка CollectD проста:
Давайте проиллюстрируем работу CollectD упрощенным примером. Допустим, я хочу знать число процессов на моем узле. Для проверки этого CollectD совершит вызов API чтобы узнать число процессов за единицу времени (по определению это 5000 миллисекунд) и ничего более. Как только агрегатор получит данные, он передаст их для настройки в InfluxDB через модуль (под названием «Network»), который нам надо будет настроить.
Откройте нашим редактором файл /etc/collectd.conf , пролистайте до секции Network и отредактируйте его как указано ниже. Обязательно укажите IP по которому находится интерфейс InfluxDB ( INFLUXDB_IP ).
Я предлагаю изменить в файле конфигурации имя хоста, который пересылается InfluxDB (в нашей инфраструктуре это «централизованная» база данных, поскольку она расположена на одном узле). Таким образом, к нам не будут поступать лишние данные и исчезнет риск перезаписи данных другими узлами.

Grafana

Беря во внимание перефразированную цитату, наблюдение за метриками инфраструктуры в режиме реального времени через графики и таблицы дает нам действовать эффективно и своевременно. Для создания и настройки приборной панели наших графиков и таблиц мы воспользуемся Grafana.
Grafana это совместимый с широким набором баз данных (включая InfluxDB) свободно распространяемый инструмент по графическому отображению метрик, в котором пользователь может создавать оповещения об удовлетворении частью данных конкретного условия. Например, если ваш процессор достигает пиковых значений, оповещение может прийти вам в Slack, Mattermost, на почту и так далее. Более того, свои оповещения я настроил так, чтобы активно отслеживать каждый случай, когда кто-то «заходит» в мою инфраструктуру.
Grafana не требует каких-то особых настроек: как мы уже отметили ранее, InfluxDB «сканирует» переменную «time». Сама же интеграция очень проста: мы начнем с импорта публичного ключа чтобы добавить пакет с официального сайта Grafana (он зависит от вашей операционной системы):
Затем запустим его через systemctl:
Теперь, когда мы перейдем в браузере на страницу localhost:3000, мы должны будем увидеть интерфейс входа в Grafana. По определению, зайти можно через логин admin и пароль admin (после первого входа учетные данные рекомендуется сменить).

Давайте перейдем в раздел Sources (Источники) и добавим туда нашу базу данных Influx:


Теперь под надписью New Dashboard виднеется небольшой зеленый прямоугольник. Наведите на него свой курсор и выберите Add Panel (Добавить Панель), а затем Graph (График):

Теперь можно увидеть график с тестовыми данными. Нажмите на заголовок этой диаграммы и нажмите Edit(Изменить). С Grafana можно создавать умные запросы: вам не нужно знать каждое поле в базе, Grafana предложит их вам из списка подходящих для анализа параметров.
Писать запросы еще никогда не было так легко: просто выберите интересующую вас метрику и нажмите Refresh (Обновить). Еще я рекомендую разделить метрики по хостам, чтобы было проще изолировать проблемы. Если вам интересны другие идеи по созданию контрольных панелей, для вдохновения можно посетить сайт Grafana со всевозможными примерами.
Мы заметили, что Grafana это очень легко расширяемый инструмент, и он позволяет нам сравнивать очень разные по сравнению друг с другом данные. Нет ни одной метрики, которую нельзя было бы заполучить, так что вас ограничивает только ваша же изобретательность. Отслеживайте ваши устройства и получайте самый полный обзор вашей инфраструктуры в реальном времени!
Читайте также: