Выполнить команду windows jenkins pipeline
Обновлено: 02.07.2024
Многие службы Azure используют подключаемые модули Jenkins. Поддержка некоторых таких подключаемых модулей будет прекращена 29 февраля 2024 г. В настоящее время для интеграции Jenkins со службами Azure рекомендуется использовать Azure CLI. Дополнительные сведения см. в статье Подключаемые модули Jenkins для Azure.
Чтобы автоматизировать этапы создания и тестирования приложения, вы можете использовать конвейер непрерывной интеграции и развертывания (CI/CD). В этом учебнике мы создадим конвейер CI/CD на виртуальной машине Azure, включая следующие задачи:
- Создание виртуальной машины Jenkins
- Установка и настройка Jenkins
- Создание интеграции webhook между GitHub и Jenkins
- Создание и активация заданий сборки Jenkins из фиксаций GitHub
- Создание образа Docker для приложения
- Проверка создания фиксацией GitHub образа Docker и изменения выполняющегося приложения
При работе с этим руководством используется интерфейс командной строки (CLI) в Azure Cloud Shell, который всегда обновлен до последней версии. Чтобы открыть Cloud Shell, выберите Попробовать в верхнем углу любого блока кода.
Если вы решили установить и использовать интерфейс командной строки локально, то для работы с этим руководством вам понадобится Azure CLI 2.0.30 или более поздней версии. Чтобы узнать версию, выполните команду az --version . Если вам необходимо выполнить установку или обновление, см. статью Установка Azure CLI 2.0.
Создание экземпляра Jenkins
В предыдущем руководстве Как настроить виртуальную машину Linux при первой загрузке вы узнали, как автоматизировать настройку виртуальной машины с помощью cloud-init. В этом учебнике используется файл cloud-init для установки Jenkins и Docker на виртуальной машине. Jenkins — это популярный сервер автоматизации с открытым исходным кодом, который легко интегрируется с Azure для обеспечения непрерывной интеграции и непрерывной поставки (CI/CD). Другие руководства по использованию Jenkins см. в документации Jenkins® в Azure.
В текущей оболочке создайте файл cloud-init-jenkins.txt и вставьте в него приведенную ниже конфигурацию. Например, создайте файл в Cloud Shell, не на локальном компьютере. Введите sensible-editor cloud-init-jenkins.txt , чтобы создать файл и просмотреть список доступных редакторов. Убедитесь, что весь файл cloud-init скопирован правильно, особенно первая строка:
Прежде чем создать виртуальную машину, выполните команду az group create, чтобы создать группу ресурсов. В следующем примере создается группа ресурсов с именем myResourceGroupJenkins в расположении eastus.
Теперь создайте виртуальную машину командой az vm create. Используйте параметр --custom-data , чтобы передать файл конфигурации cloud-init. Укажите полный путь к конфигурации cloud-init-jenkins.txt, если этот файл сохранен вне текущего рабочего каталога.
Создание и настройка виртуальной машины может занять несколько минут.
Чтобы разрешить веб-трафик к вашей виртуальной машине, используйте команду az vm open-port для открытия порта 8080 для трафика Jenkins и порта 1337 для приложения Node.js, которое используется для запуска примера приложения:
Настройка Jenkins
Чтобы получить доступ к экземпляру Jenkins, получите общедоступный IP-адрес виртуальной машины:
В целях безопасности для запуска установки Jenkins необходимо ввести первоначальный пароль администратора, хранящийся в текстовом файле на виртуальной машине. Используйте общедоступный IP-адрес, полученный на предыдущем шаге, чтобы настроить подключение SSH для виртуальной машины:
С помощью команды service проверьте, запущен ли сервер Jenkins:
Просмотрите initialAdminPassword для установки Jenkins и скопируйте его:
Если файл еще не доступен, подождите несколько минут, пока файл cloud-init не завершит установку Jenkins и Docker.
- Щелкните Select plugins to install (Выбрать подключаемые модули для установки).
- Выполните поиск по слову GitHub в текстовом поле вверху. Установите флажок для GitHub, а затем выберите Установить.
- Создайте первого администратора. Введите имя пользователя, например admin, а затем укажите безопасный пароль. Наконец введите полное имя и адрес электронной почты.
- Выберите Сохранить и завершить.
- Когда настройка Jenkins будет завершена, щелкните Start using Jenkins (Начать работу с Jenkins).
- Если веб-браузере отображает пустую страницу при запуске Jenkins, перезапустите службу Jenkins. В сеансе SSH введите sudo service jenkins restart , а затем обновите веб-браузера.
Создание объекта webhook GitHub
Чтобы настроить интеграцию с GitHub, откройте пример приложения Node.js Hello World из репозитория примеров Azure. Чтобы создать разветвление репозитория для своей учетной записи GitHub, нажмите кнопку Fork (Разветвление) в правом верхнем углу.
Создание объекта webhook в созданном разветвлении
![Добавление объекта webhook GitHub в разветвление репозитория]()
Создание задания Jenkins
Чтобы система Jenkins реагировала на событие в GitHub, такое как фиксация кода, создайте задание Jenkins. Используйте URL-адреса для собственной вилки GitHub.
На веб-сайте Jenkins щелкните Create new jobs (Создание заданий) на домашней странице.
Тестирование интеграции GitHub
Для проверки интеграции GitHub с Jenkins зафиксируйте изменение в разветвлении.
Вернитесь к веб-интерфейсу пользователя GitHub, выберите разветвление репозитория и щелкните файл index.js. Щелкните значок карандаша и измените этот файл так, чтобы строка 6 выглядела следующим образом.
Чтобы зафиксировать изменения, нажмите кнопку Commit changes (Зафиксировать изменения) внизу.
Определение образа сборки Docker
Чтобы увидеть, как приложение Node.js выполняется в зависимости от фиксаций GitHub, мы создадим образ Docker для выполнения приложения. Образ строится на основе файла Dockerfile, определяющего конфигурацию контейнера, в котором выполняется приложение.
Измените путь SSH-подключения к виртуальной машине, задав каталог рабочей области Jenkins, имя которого соответствует заданию, созданному на предыдущем шаге. В текущем примере это будет HelloWorld.
Создайте файл в этом каталоге рабочей области с sudo sensible-editor Dockerfile и вставьте следующее содержимое. Убедитесь, что весь файл Dockerfile скопирован правильно, особенно первая строка:
Этот файл Dockerfile использует базовый образ Node.js с помощью Alpine Linux, предоставляет порт 1337, по которому выполняется приложение Hello World, а затем копирует файлы приложения и инициализирует его.
Создание правил сборки Jenkins
Вернитесь в экземпляр Jenkins и выберите задание, созданное на предыдущем шаге. Щелкните Configure (Настройка) в левой части и прокрутите страницу вниз до раздела Build (Сборка).
Удалите существующий шаг сборки echo "Test" . Щелкните красный крест в верхнем правом углу поля существующего шага сборки.
Щелкните Add build step (Добавить шаг сборки), а затем выберите Execute shell (Выполнение оболочки).
В поле Command (Команда) введите следующие команды Docker. Затем нажмите кнопку Save (Сохранить):
Шаги сборок Docker создают образ и помечают его номером сборки Jenkins, чтобы вы могли вести журнал образов. Любые существующие контейнеры, выполняющие приложение, будут остановлены, а затем удалены. Затем с помощью образа запускается новый контейнер, который выполняет ваше приложение Node.js в зависимости от последней фиксации в GitHub.
Тестирование конвейера
Чтобы увидеть весь конвейер в действии, снова измените файл index.js в разветвлении репозитория GitHub и нажмите кнопку Commit changes (Зафиксировать изменения). Новое задание запускается Jenkins в зависимости от объекта webhook для GitHub. Создание образа Docker и запуск вашего приложения в новом контейнере занимает несколько секунд.
При необходимости снова получите общедоступный IP-адрес виртуальной машины:
![Запуск приложения Node.js]()
Теперь внесите другое изменение в файл index.js в GitHub и зафиксируйте изменение. Подождите несколько секунд, пока завершится задание в Jenkins, а затем обновите веб-браузер, чтобы увидеть измененную версию приложения, выполняющегося в новом контейнере, следующим образом:
![Запуск приложения Node.js после другой фиксации GitHub]()
Дальнейшие действия
В рамках этого учебника мы настроили GitHub для выполнения задания сборки Jenkins согласно каждой фиксации кода, а затем развернули контейнер Docker для тестирования приложения. Вы ознакомились с выполнением следующих задач:
- Создание виртуальной машины Jenkins
- Установка и настройка Jenkins
- Создание интеграции webhook между GitHub и Jenkins
- Создание и активация заданий сборки Jenkins из фиксаций GitHub
- Создание образа Docker для приложения
- Проверка создания фиксацией GitHub образа Docker и изменения выполняющегося приложения
Перейдите к следующему руководству, чтобы узнать, как интегрировать Jenkins в Azure DevOps Services.
В данной инструкции представлена базовая информация по использованию pipeline в Jenkins. Мы рассмотрим процесс для чайников, начиная с установки плагина, создания задания и перейдем к разбивке процесса обработки кода на стадии.
Установка плагина
При установке Jenkins система по умолчанию предлагает установить плагин pipeline. Вероятно, в нашей системе он есть. Но если плагин не установлен, переходим на стартовой странице веб-интерфейса Jenkins в раздел Настроить Jenkins:
![Переходим к настройкам Jenkins]()
Кликаем по Управление плагинами:
![В настройках Jenkins переходим к управлению плагинами]()
Переходим на вкладку Доступные и ищем нужный нам плагин по слову «pipeline». Мы получим большое количество результатов — нам нужен плагин с названием «Pipeline»:
![Находим плагин pipeline и выбираем его для установки]()
Внизу экрана нажимаем Install without restart:
![Кликаем по кнопке установки плагинов без перезагрузки Jenkins]()
Мы увидим полный список компонентов, которые нужно будет установить для плагина — дожидаемся окончания процесса (мы должны увидеть «Успешно» или «Success»):
![Ждем, пока не установятся все компоненты]()
После завершения установки, можно вернуться на главную страницу, кликнув по одноименной ссылке:
![Возвращаемся на главную страницу Jenkins]()
Наша система готова для создания конвейера.
Создание и настойка задания
На главной странице Jenkins кликаем по Создать Item:
![Переходим к созданию нового элемента в Jenkins]()
Даем название нашей задаче и ниже выбираем Pipeline:
![Даем название элементу и выбираем тип Pipeline]()
Нажимаем кнопку OK:
![Нажимаем OK для создания элемента в Jenkins]()
Прокручиваем страницу вниз до подраздела «Pipeline» — сюда мы пишем скрипт на Groovy:
![Доходим до поля, куда пишем pipeline на Groovy]()
Также у нас есть возможность использовать репозиторий Git в качестве источника файла Jenkinsfile, выбрав в подразделе «Definition» Pipeline script from SCM и Git:
![Возможность использовать Git для загрузки пайплайна]()
. но мы в данной инструкции будем рассматривать написание кода напрямую в Jenkins.
Для начала, напишем приветствие:
pipeline agent any
Существует 2 способа написания pipeline — скриптовый и декларативный. В нашем примере используется последний. Благодаря строгому синтаксису, он проще читается — в декларативном пайплайне обязательно должны быть:
- Директива pipeline. В нее мы оборачиваем наш код.
- Определение агента. В нашем примере пока не задан конкретный (agent any), но ниже мы рассмотрим запуск конвейера в docker.
- Необходима директива stages, в которой, в свою очередь, определены стадии (stage).
- Обязательно указываем steps, в котором и будет наш код.
И нажимаем Сохранить:
![Сохраняем первый pipeline]()
* наш скрипт на Groovy будет сохранен в так называемый Jenkinsfile — это файл, в котором мы описываем этапы выполнения нашего задания с использованием pipeline.
Нас перекинет на страницу задания — слева кликаем по Собрать сейчас:
![Делаем первый запуск нашего Pipeline]()
Конвейер немного поработает и выдаст результат, состоящий из одного шага:
![Наше задание с приветствием успешно завершено]()
Созданное задание работает — попробуем его усложнить.
Разбиваем обработку на этапы
Открываем на редактирование наше задание:
![Переходим к настройкам задания]()
Перемещаемся вниз и пишем следующий код на Groovy:
pipeline agent any
* в данном примере мы выполняем задание в три этапа — сборка, тестирование и развертывания. В рамках нашей инструкции мы не будем выполнять ничего конкретного, поэтому просто выводим на экран текстовую информацию.
Сохраняем изменения и запускаем задачу на выполнение:
![Выполняем задачу, разделенную на этапы]()
После ее завершения мы должны увидеть что-то на подобие:
![Первый результат выполнения задания, разделенного на 3 этапа]()
Попробуем посмотреть чуть подробнее протокол выполнения — кликаем по изображению стрелки справа от названия задания и выбираем Последняя стабильная сборка (или просто Последняя сборка):
![Переходим к последней сборке]()
Кликаем по Console Output:
![Переходим в подробному выводу данных во время сбоки кода]()
Мы должны увидеть вывод всех комментарий и команд, которые выполнялись во время сборки.
Обработка в Docker
Jenkins может выполнять задание внутри Docker. Таким образом, мы можем использовать контейнеры с настроенной средой, необходимой для тестирования и сборки кода и получения необходимых артефактов.
Рассмотрим настройку сервера для возможности использовать Docker и пример кода на Groovy.
Подготовка системы
Мы должны выполнит ряд действий:
- Установку плагина для работы Jenkins с Docker.
- Установку сервиса Docker в системе.
- Настройку привилегий.
1. Начнем с установки плагина. На главной странице Jenkins переходим в настройки:
![Переходим к настройкам для установки плагина docker]()
Кликаем по разделу Управление плагинами:
![Заходим в раздел управления плагинами]()
Среди списка плагинов находим «Docker Pipeline» и отмечаем его для установки:
![Отмечаем для установки плагин по работе с docker из pipeline]()
Переходим к установке:
![Выполняем установку плагина Docker Pipeline]()
. и доживаемся ее окончания.
2. Подключаемся к консоли по SSH и выполняем Установку Docker.
3. Чтобы можно было подключиться к Docker из Jenkins, необходимо, чтобы пользователь jenkins входил в группу docker — для этого выполняем команду:
usermod -a -G docker jenkins
После необходимо перезапустить дженкинс:
systemctl restart jenkins
Среда готова для работы с контейнерами.
Использование агента docker
Переходим к настройке нашего задания или создаем новое и приводим Groovy-код к такому виду:
* обратите внимание, мы изменили агента на docker с указанием образа, в котором будет выполняться обработка — в данном примере, с помощью python (последней версии). Также мы добавили этап Подготовка, в котором просто выведем на экран версию python.
Первый запуск будет выполняться долго, так как необходимо будет загрузить образ. В конечном итоге, мы должны получить, примерно, следующую картину:
![Результат работы Groovy с использованием образа docker с python]()
Для подробного просмотра хода процесса (или решения проблем в случае их возникновения), кликаем по стрелке справа от названия задания и переходим к сборке:
![Переходим к последней сборке для нашего задания]()
Переходим к консоли:
![Кликаем по Console Output для перехода к подробному логу выполнения]()
Если задание выполнено успешно, среди логов мы должны увидеть версию используемого в контейнере Docker python:
Меня зовут Александр Михайлов, я работаю в команде интеграционного тестирования компании ЮMoney.
Наша команда занимается приемочным тестированием. Оно включает в себя прогон и разбор автотестов на критичные бизнес-процессы в тестовой среде, приближенной по конфигурации к продакшену. Еще мы пишем фреймворк, заглушки, сервисы для тестирования — в целом, создаем экосистему для автоматизации тестирования и обучаем ручных тестировщиков автоматизации.
Надеюсь, что эта статья будет интересна как новичкам, так и тем, кто съел собаку в автоматизации тестирования. Мы рассмотрим базовый синтаксис Jenkins Pipeline, разберемся, как создать джобу на основе пайплайна, а также я расскажу про опыт внедрения неочевидной функциональности в CI — запуска и дожатия автотестов по условию.
Запуск автотестов на Jenkins — инструкция
Не новость, что автотесты эффективнее всего проводить после каждого изменения системы. Запускать их можно локально, но мы рекомендуем делать это только при отладке автотестов. Больший профит автотесты принесут при запуске на CI. В качестве CI-сервера у нас в компании используется Jenkins, в качестве тестового фреймворка — JUnit, а для отчетов — Allure Report.
Чтобы запускать тесты на Jenkins, нужно создать и сконфигурировать джобу.
Для этого достаточно выполнить несколько несложных шагов.
1) Нажать «Создать», выбрать задачу со свободной конфигурацией и назвать ее, например, TestJob.
Естественно, для этого у вас должны быть права в Jenkins. Если их нет, нужно обратиться к администратору Jenkins.
2) Указать репозиторий, откуда будет выкачиваться код проекта: URL, credentials и branch, с которого все будет собираться.
3) Добавить нужные параметры, в этом примере — количество потоков (threadsCount) и список тестов для запуска (testList).
Значение “*Test” для JUnit означает «Запустить все тесты».
4) Добавить команду для запуска тестов.
Наш вариант запускается на Gradle: мы указываем таску теста и передаем параметры в тесты.
./gradlew test -PthreadsCount=$threadsCount -PtestList=$testList
Можно выполнить шаг сборки «Выполнить команду shell», либо через Gradle Plugin использовать шаг «Invoke Gradle Script».
Создав джобу и прогнав с ее помощью тестов, мы можем получить такой результат.
На скрине — реальный прогон. По таймлайну видно, как тесты разделяются по потокам и где были падения.
Несложно заметить, что тесты у нас падают.
Почему падают тесты
Падения могут случаться по разным причинам. В нашем случае на это влияют:
ограниченные ресурсы тестового стенда,
большое число микросервисов (
140); если при запуске интеграционных тестов какой-то один микросервис подтормаживает, тесты начинают валиться,
большое число интеграционных тестов (>3000 E2E),
врожденная нестабильность UI-тестов.
В итоге проблемы по этим причинам мультиплицируются, и мы получаем комбинаторный взрыв, проявляющийся ошибками в прогонах тестов. Что делать? Дожимать.
Что такое дожим
Дожим — это перезапуск автотестов в рамках одного прогона. При успешном прохождении автотеста можно считать его пройденным, не учитывая предыдущие падения в прогоне.
«Дожимать? Опасно же!»
Возразите вы и будете полностью правы. Безусловно, дожим автотестов может спровоцировать пропуск дефекта на продакшн. Баг может быть плавающим — при повторном запуске успешно просочиться и попасть на продакшн.
Но мы проанализировали статистику падений автотестов за длительный период и увидели, что большинство падений было связано с нестабильной тестовой средой, тестовыми данными. Поэтому мы взяли на себя риск и стали дожимать тесты. Прошло уже больше года, и не было ни одного дефекта, пропущенного на продакшн по этой причине. Зато стабильность тестов повысилась ощутимо.
Как решать задачу с дожимами
Мы пробовали разные решения: использовали модификацию поведения JUnit 4, JUnit 5, писали обертки на Kotlin. И, к сожалению, каждый раз реализация завязывалась на фичах языка или фреймворка.
Если процесс запускался с помощью JUnit 4 или JUnit 5, возможность перезапустить тесты была только сразу при падении. Тест упал, перезапустили его несколько раз подряд — и если сбоил какой-то микросервис из-за нагрузки, либо настройки тестовой среды были некорректные, то тест все три раза падал.
Это сильно удлиняло прогон, особенно когда проблема была в настройке тестовой среды, что приводило к провалу множества тестов.
Мы взглянули на проблему шире, решили убрать зависимость от тестового фреймворка или языка и реализовали перезапуск на более высоком уровне — на уровне CI. И сделали это с помощью Jenkins Pipeline.
Для этого подходил следующий алгоритм: получаем список упавших тестов и проверяем условия перезапуска. Если упавших тестов нет, завершаем прогон. Если есть, решаем, запускать их повторно или нет. Например, можно реализовать логику, чтобы не перезапускались тесты, если их упало больше какого-то критического числа. Или перед запуском можно сделать проверку доступности тестируемого сервиса.
Что такое Jenkins Pipeline
![]()
Jenkins Pipeline — набор плагинов, позволяющий определить жизненный цикл сборки и доставки приложения как код. Он представляет собой Groovy-скрипт с использованием Jenkins Pipeline DSL и хранится стандартно в системе контроля версий.
Существует два способа описания пайплайнов — скриптовый и декларативный.
Они оба имеют структуру, но в скриптовом она вольная — достаточно указать, на каком слейве запускаться (node), и стадию сборки (stage), а также написать Groovy-код для запуска атомарных степов.
Декларативный пайплайн определен более жестко, и, соответственно, его структура читается лучше.
Рассмотрим подробнее декларативный пайплайн.
В структуре должна быть определена директива pipeline.
Также нужно определить, на каком агенте (agent) будет запущена сборка.
Дальше идет определение stages, которые будут содержаться в пайплайне, и обязательно должен быть конкретный стейдж с названием stage(“name”). Если имени нет, тест упадет в runtime с ошибкой «Добавьте имя стейджа».
Обязательно должна быть директива steps, в которой уже содержатся атомарные шаги сборки. Например, вы можете вывести в консоль «Hello».
Мне нравится декларативный вид пайплайна тем, что он позволяет определить действия после каждого стейджа или, например, после всей сборки. Я рекомендую использовать его при описании пайплайнов на верхнем уровне.
Если сборка и стейдж завершились успешно, можно сохранить артефакты или почистить workspace после сборки. Если же при таких условиях использовался бы скриптовый пайплайн, пришлось бы за этим «флоу» следить самостоятельно, добавляя обработку исключений, условия и т.д.
При написании своего первого пайплайна я, естественно, использовал официальный мануал — там подробное описание синтаксиса и степов.
Сначала я даже растерялся и не знал, с чего начать — настолько там много информации. Если вы первый раз сталкиваетесь с написанием пайплайна, начать лучше со знакомства с генераторами фрагментов пайплайна из UI-интерфейса.
Если к URL вашего веб-интерфейса Jenkins добавить ендпойнт /pipelines-syntax, откроется страница, в которой есть ссылки на документацию и два сниппет-генератора, позволяющие генерировать пайплайн даже без знания его синтаксиса:
Declarative sections generator
Генераторы фрагментов — помощники в мире Jenkins
Для создания пайплайна сначала нужно декларативно его описать, а затем наполнить степами. Давайте посмотрим, как вспомогательные инструменты нам в этом помогут.
Declarative sections generator (JENKINS-URL/directive-generator) — генератор фрагментов для декларативного описания пайплайна.
Для добавления стадии нужно написать ее имя и указать, что будет внутри (steps). После нажатия кнопки «Сгенерировать» будет выведен код, который можно добавлять в пайплайн.
Также нам нужны шаги, в которых будут выполняться различные действия — например, запуск джобы Jenkins с тестами.
Snippet Generator (JENKINS-URL/pipeline-syntax) — поможет сгенерировать фрагменты шагов.
В Sample Step выбрать build: Build a job.
(Дальше функционал подсказывает) — необходимо определить параметры, которые будут переданы в джобу (для примера задано branch, project).
Нажать кнопку «Generate» — в результате сформируется готовый рабочий код.
Изменим параметры джобы на те, которые определили при ее создании.
где threadsCount - кол-во потоков для распараллеливания тестов, testList - список тестов для запуска, runId - идентификатор прогона тестов. Для чего нужны эти параметры, расскажу далее.
Snippet Generator удобен тем, что подсвечивает шаги в зависимости от установленных плагинов. Если у вас есть, например, Allure-report, то плагин сразу покажет наличие расширения и поможет сгенерировать код, который будет работать.
Вставим сгенерированный код степа в пайплайн на следующем шаге.
Запуск тестов с помощью Pipeline — инструкция
Итак, давайте с помощью Declarative sections generator создадим пайплайн. В нем нужно указать директивы: pipeline, agent (агент, на котором будет запускаться пайплайн), а также stages и steps (вставка ранее сгенерированного кода).
Так получится пайплайн, который запустит джобу, созданную на предыдущем шаге через UI.
Напомню, что в параметры для запуска тестов мы передавали количество потоков и список тестов. Теперь к этому добавляем параметр runId (идентификатор прогона тестов) — он понадобится позднее для перезапуска конкретного сьюта тестов.
Чтобы запустить пайплайн, нужно создать проект.
New Item -> Pipeline.
Для этого нужно нажать на кнопку «Создать проект» и выбрать не джобу со свободной конфигурацией, а джобу Pipeline — осталось указать ей имя.
Добавить параметры runId, threadsCount, testList.
Склонировать из Git.
Пайплайн можно описать непосредственно как код и вставить в поле, но для версионирования нужно затягивать пайплайн из Git. Обязательно указываем путь до скрипта с пайплайном.
Готово, джобу можно запускать.
Хотим добавить немного дожатий
На этом этапе у нас уже готова джоба для запуска проекта с автотестами. Но хочу напомнить, что наша задача — не просто запускать тесты, а добавить им стабильности, исключив падения из-за внешних факторов. Для достижения этого результата было принято решение дожать автотесты.
Для реализации нужно:
вынести шаг запуска тестов в библиотечную функцию (shared steps),
получить упавшие тесты из прогона,
добавить условия перезапуска.
Теперь немного подробнее про каждый из этих шагов.
Многократное использование шагов — Shared Steps
В процессе написания пайплайнов я столкнулся с проблемой постоянного дублирования кода (часто используемых степов). Этого хотелось избежать.
Решение нашлось не сразу. Оказывается, для многократного использования кода в Jenkins есть встроенный механизм — shared libraries, который позволяет описать методы один раз и затем применять их во всех пайплайнах.
Существуют два варианта подключения этой библиотеки.
Написанный проект/код подключить через UI Jenkins. Для этого требуются отдельные права на добавление shared libraries или привлечение девопс-специалистов (что не всегда удобно).
Хранить код в отдельном проекте или в проекте с пайплайнами. При использовании этот код подключается как динамическая библиотека и выкачивается каждый раз при запуске пайплайна.
Мы используем второй вариант — размещаем shared steps в проекте с пайплайнами.
Для этого в проекте нужно:
создать папку var,
в ней создать файл с названием метода, который планируется запускать — например, gradlew.groovy,
стандартно определить имя метода (должен называться call), то есть написать «def call» и определить входящие параметры,
в теле метода можно написать произвольный Groovy-код и/или Pipeline-степы.
Вынесение запуска тестов в shared steps в /var
Выносим startTests.groovy в /var.
Во-первых, нужно вынести запуск тестов в отдельный метод. Выглядит это так — создаем файл, называем метод def call, берем кусок кода, который был в пайплайне, и выносим его в этот step.
Для передачи параметров используется Map<String, String>. Почему не передавать каждый параметр отдельно? Это не очень удобно, т.к. в Groovy параметры не обозначены по названиям. При использовании Map синтаксис позволяет указать “key:value“ через двоеточие. В коде (в месте вызова метода) это отображается наглядно.
Структура проекта будет выглядеть так.
Подключение shared steps как внешней библиотеки.
Дальше нужно добавить вынесенные шаги в пайплайн. При динамической подгрузке библиотек (во время запуска пайплайна) эти шаги выкачиваются из репозитория и подключаются на лету.
Сделать это можно с помощью сниппет-генератора — выбираем степ library и указываем ветку, в которую все будет собираться и репозиторий. Дальше нажимаем кнопку «Сгенерировать» и вставляем получившийся пайплайн.
Теперь после подключения shared steps вместо шага запуска тестов build нужно вставить startTest. Не забудьте, что имя метода должно совпадать с именем файла.
Теперь наш пайплайн выглядит так.
Первый шаг реализован, теперь можно многократно запускать тесты в разных местах. Переходим к 2 шагу.
Получение упавших тестов из прогона
Теперь нам нужны упавшие тесты. Каким образом их извлечь?
Установить в Jenkins плагин JUnit Test Result Report и использовать его API.
Взять результаты прогона JUnit (обычно в формате XML), распарсить и извлечь нужные данные.
Запросить список упавших тестов из нужного места.
Добавление условий перезапуска
Отлично, второй шаг выполнен. Осталось добавить ту самую изюминку — условия перезапуска. Но сначала посмотрим, что получается.
Есть запуск тестов и получение результатов прогона. Теперь нужно добавить те самые условия, которые будут говорить: «Если все хорошо, завершай прогон. Если плохо, давай перезапускать».
Условия перезапуска
Какие условия для перезапуска можно реализовать?
Приведу часть условий, которые используем мы.
1) Если нет упавших тестов, прогон завершается.
2) Как я уже писал выше, на тестовой среде ресурсы ограничены, и бывает такое, что ТС захлебывается в большом количестве параллельных тестов. Чтобы на дожатии избежать падений тестов по этой причине, понижаем число потоков на повторном запуске. Именно для этого при создании джобы и в самом пайплайне мы добавили параметр threadsCount.
Если и после уменьшения потоков тесты не дожимаются (количество упавших тестов на предыдущем прогоне равно числу упавших тестов на текущем), тогда считаем, что дело не во влиянии ТС на тесты. Останавливаем прогон для анализа причин падений — и тем самым предотвращаем последующий холостой запуск.
3) Третья и самая простая проверка состоит в том, что если падает большое количество тестов, то дожимать долго. Скорее всего, причина падений какая-то глобальная, и ее нужно изучать.
Для себя мы определили: если тестов > 40, дожимать не автоматически не будем, потому что 40 наших E2E могут проходить порядка 15 минут.
Последние два условия — так называемые fail fast. Они позволяют при глобальных проблемах на тестовом стенде не делать прогоны, которые не приведут к дожиму тестов, но будут занимать ресурсы тестового стенда.
Итоговый pipeline
Итак, все 3 шага реализованы — итоговый пайплайн выглядит так.
Визуализация с Blue Ocean
Как все это выглядит при прогоне в Jenkins? У нас, к примеру, для визуализации в Jenkins установлен плагин Blue Ocean.
На картинке ниже можно увидеть, что:
запустился метод testwith_rerun,
прошел первый запуск,
прошла проверка упавших тестов,
запустился второй прогон,
после успешной проверки джоба завершилась.
Вот так выглядит визуализация нашего настоящего прогона.
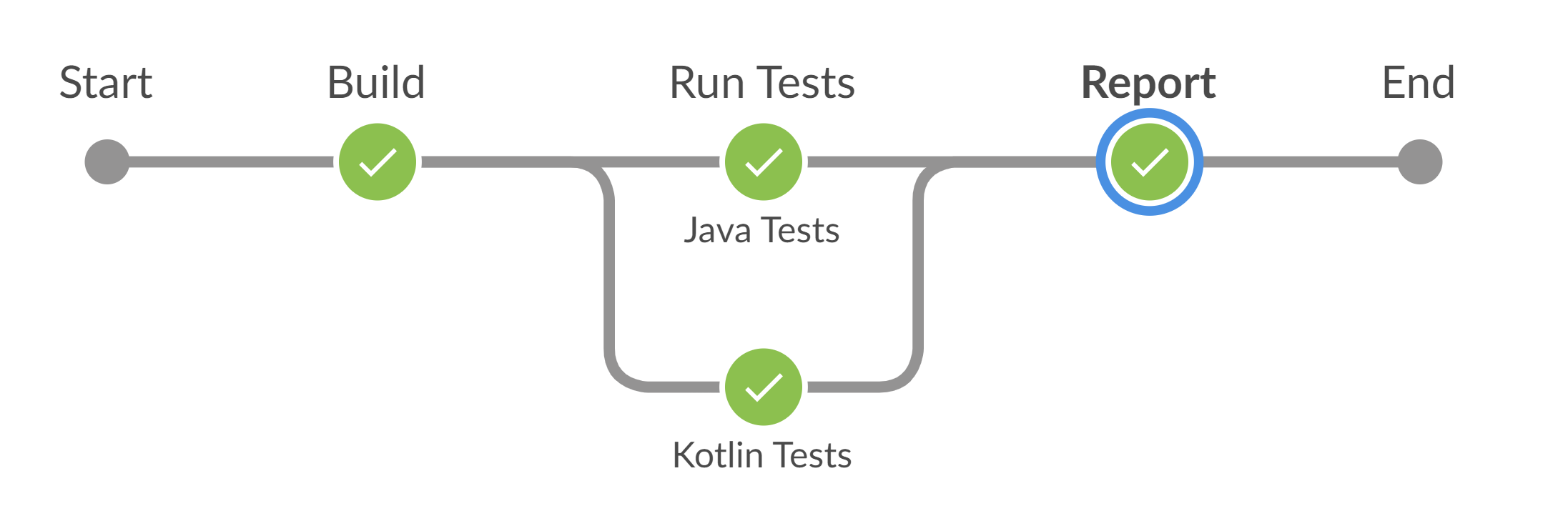
В реальном примере две ветки: мы параллельно запускаем два проекта с тестами (на Java и Kotlin). Можно заметить, что тесты одного проекта прошли с первого раза, а вот тесты другого пришлось дожимать еще раз. Таким образом визуализация помогает найти этап, на котором падают тесты.
А так выглядит реальный timeline приемки релиза.
После первого прогона отправили дожимать упавшие тесты. Во второй раз упавших тестов намного меньше, дожимаем в третий раз — и вуаля, успешный build.
Мы перенесли логику перезапусков упавших тестов из тестового проекта на уровень выше — на CI. Таким образом сделали механизм перезапуска универсальным, более гибким и независимым от стека, на котором написаны автотесты.
Раньше наши тесты дожимались безусловно, по несколько раз, с неизменным количеством параллельных потоков. При перегрузке тестового стенда, некорректных настройках тестового окружения либо каких-то других проблемах — красные тесты перезапускались фиксированное число раз без шансов дожаться. В худшем случае прогоны могли длиться часами. Добавив условия fail fast, мы сократили это время.
При падении тестов инженер, ответственный за приемку, в некоторых ситуациях вручную стартовал джобу перезапуска, выполняя прогон с меньшим числом потоков. На это тоже уходило время. Добавив в условия пайплайна уменьшение числа потоков на перезапуске, мы сократили и это время.
Какой профит мы получили:
уменьшили time-to-market тестируемых изменений,
сократили длительность аренды тестового стенда под приемочное тестирование,
увеличили пропускную способность очереди приемочного тестирования,
не завязаны на тестовый фреймворк («под капотом» может быть что угодно — дожатия будут работать),
поделились знаниями об использовании Jenkins Pipeline.
Примеры кода выложены на GitHub. Если будут вопросы, задавайте — обязательно отвечу.
А еще в нашей компании принято награждать ачивкой за какое-то достижение. Статья получилось достаточно подробной и многословной, а потому вас, дочитавших до конца этот лонгрид, хотелось бы поощрить.
Помимо +100 к опыту и знаниям Jenkins вы получаете ачивку "Ю Academic"! :)
![]()
В DevOps непрерывная интеграция и непрерывная доставка (CI / CD) достигаются с помощью пайплайна Jenkins.
Использование Jenkins Pipeline для CD помогает доставлять программное обеспечение быстрее и чаще. Это помогает включать обратную связь в каждый следующий выпуск.Что такое пайплайн Jenkins?
Пайплайн Jenkins состоит из нескольких состояний или этапов, и они выполняются в последовательности один за другим.
Он содержит код на Groovy Domain Specific Language (DSL), который прост в написании и удобочитаем.
Вы можете запустить JenkinsFile отдельно, либо вы можете запустить этот код из Jenkins Web UI.
Существует два способа создания пайплайна с помощью Jenkins.
Прежде чем мы перейдем к демонстрации всего этого, если вы еще не установили Jenkins, пожалуйста, установите его. Убедитесь, что в вашей системе запущен и работает Jenkins.Создание пайплана Jenkins
Так выглядит пайплаен Jenkins, состоящий из нескольких этапов между разработкой программного обеспечения и программного обеспечения, поставляемое в производство.
![]()
Давайте создадим декларативный пайплайн.
В дашборде Jenkins , нажмите на New Item.
З атем введите имя элемента, например, «First Pipeline» и выберите проект «Pipeline». Затем нажмите ОК.
Нажмите на вкладку Pipeline, как показано на рисунке ниже, и введите свой код JenkinsFile (Groovy Code)![]()
Groovy код, показанный выше, я использую для JenkinsFile. Любой доступный агент получает назначение в pipeline. Затем я определяю этап Build' и выполняю простой шаг echo . Затем я определил стадию Test, где шаг спрашивает, хотите ли вы продолжить или нет. После этого я создал этап Deploy, в котором параллельно работают еще два этапа. Этап Deploy start содержит шаг с командой echo, а в Deploying now теперь есть шаг, который тащит образ узла Nginx на узле.![]()
Наконец, есть стадия Prod с простым шагом echo.
Вышеописанный пайплан имеет этапы, на которых есть простые шаги, чтобы вы могли понять, как он работает.
Как только вы научитесь создавать пайплайны, вы можете добавить больше сложного в этот кода и создавать сложные конвейеры.
Pipeline предоставляет набор расширяемых инструментов для моделирования delivery pipeline , Через Синтаксис конвейерного DSL .
Определение Jenkins Pipeline записывается в файл с именем Jenkinsfile Затем этот файл можно поместить в хранилище управления версиями.
Определение Pipeline может использовать два типа объявлений синтаксиса: Declarative с Scripted
Declarative Это новейшая функция, у нее больше синтаксиса, и ее легче писать и читать.1.1 Используйте переменные среды
Переменные среды, предоставляемые Jenkins Pipeline
Jenkins Pipeline предоставляет некоторые переменные среды через глобальные переменные env ,
Например BUILD_ID , JOB_NAME , JOB_BASE_NAME , JENKINS_URL , JENKINS_NODE_COOKIE , HUDSON_SERVER_COOKIE , JENKINS_SERVER_COOKIE , BUILD_URL , JOB_URL , HUDSON_URL , WORKSPACE ЖдатьПримеры цитирования этих переменных среды:
Установить переменные среды
Динамически устанавливаемые переменные среды
Можно использовать sh , Каждый сценарий может returnStatus Или же returnStdout , Пример:
1.2 Обработка учетных данных
Declarative Pipeline В грамматике есть один credentials() Метод (в environment Используйте) в инструкции, он поддерживает secret text , username and passwd , с secret file Виды Полномочия.
Примечание. Если учетные данные не существуют, будет сообщено об ошибке.
Пример секретного текста
Пример имен пользователей и паролей
Другие типы учетных данных
1.3 Параметры обработки
Declarative Pipeline Поддержка нестандартных (нестандартных) параметров,
пройден директива параметров Настройте параметры, которые пользователи должны указывать при запуске конвейера.
использовать Scripted Pipeline Параметры конфигурации передаются properties step Готово, этот шаг можно в Snippet Generator Нашел в.1.4 Обработка ошибок
Declarative Pipeline Поддержка мощных возможностей обработки ошибок,
пройден post section , Этот раздел позволяет объявлять множество различных "условий публикации" (например, always , unstable , success , failure , and changed ).1.5 Использование нескольких агентов
1.5 Optional step arguments
Конвейер следует соглашению языка Groovy, что позволяет опускать круглые скобки вокруг параметров метода.
Для удобства при вызове шага, который принимает только один параметр (или только один обязательный параметр), имя параметра можно не указывать, например:
1.6 Advanced Scripted Pipeline
Scripted Pipeline основан на Groovy DSL (предметно-ориентированный язык),
большая часть Groovy Грамматику можно использовать для Scripted Pipeline , И изменять не нужно.Параллельное исполнение
Все предыдущие примеры выполняются линейно,
Фактически, мы можем захотеть выполнить некоторые шаги параллельно, например шаги теста и т. д.
Пример ( Scripted Pipeline ):2.1 Caching data for containers
Многие инструменты сборки загружают множество внешних зависимостей и кешируют их локально.
Контейнер начинается с «чистой» файловой системы. Если вы не полагаетесь на кеширование, процесс сборки будет медленным.Pipeline поддерживает добавление настраиваемых параметров при запуске контейнеров Docker, что позволяет пользователям указывать тома, которые необходимо смонтировать, а также возможность кэширования данных.
2.2 Использование нескольких контейнеров
2.3 Использование Dockerfile
4.1 Eclipse Jenkins Editor
Jenkins Editor Плагин
4.2 VisualStudio Code Jenkins Pipeline Linter Connector
Jenkins Pipeline Linter Connector Расширять
5.1 Declarative Pipeline
все Declarative Pipeline Должен содержаться в pipeline В блоке то есть: pipeline
В Declarative Pipeline Эффективные базовые предложения и выражения в Groovy Синтаксис такой же, но со следующими исключениями:
- Конвейер верхнего уровня должен быть блоком, в частности pipeline
- В качестве разделителя операторов точка с запятой не используется, каждая инструкция должна иметь отдельную строку.
- Блок может состоять только из разделов, директив, шагов или операторов присваивания.
- Оператор ссылки на атрибут рассматривается как вызов метода без параметров. Например input Считается input()
5.1.1 Sections
Sections Обычно состоит из одного или нескольких Directives Или же Steps сочинение.
agent section
agent раздел в целом в целом Pipeline Указано в или некоторых Stage Указано в.
agent Должен быть pipeline объявлен в блоке, но в stage Блок не является обязательным.
agent Раздел поддерживает несколько разных типов параметров.
- agent any : Указывает, что конвейер может быть запущен на любом агенте
- agent none : Указывает, что в настоящее время агент не назначен stage Блок должен объявить свой собственный agent
- agent < label 'my-defined-label'>: Указывает на запуск конвейера на узле с указанной меткой.
- agent < node < label 'labelName' >> : Имеет то же значение, что и ярлык, но node Разрешить дополнительные параметры (например, customWorkspace )
- agent < docker < . >> : Примеры:
- agent < dockerfile < . >> : Временно
agent Есть несколько общих опций, они не обязательны.
- метка: может применяться к node docker dockerfile
- customWorkspace: указывает, что настраиваемая рабочая область используется при запуске всего конвейера или определенного этапа. Это может быть относительный путь относительно рабочего каталога рабочей области по умолчанию или абсолютный путь.
может применяться к node docker dockerfile
Пример:
reuseNode: значение по умолчанию - false. Если оно истинно, это означает, что контейнер запускается на узле, указанном на верхнем уровне конвейера, с использованием той же рабочей области, а не на новом узле.
Этот вариант docker с dockerfile Эффективно, и только в одном stage из agent Эффективно.
означает, что только в том же stage середина steps Будет работать на одном узле, на разных stage середина steps Не обязательно.аргументы: можно использовать docker dockerfile
post section
post section Используется для определения одного или нескольких дополнительных steps , На основе всего Pipeline Или же stage Результаты операции.
post Поддерживаются следующие блоки: always , changed , fixed , regression , aborted , failure , success , unstable , unsuccessful , cleanup Указанный порядок также является порядком выполнения этих условных блоков.changed Это означает, что статус текущего результата этого конвейера или этапа отличается от последнего статуса текущего результата.
fixed Относится к текущему состоянию результата этого конвейера или этапа: success , И статус последнего результата выполнения failed Или же unstable
regression Относится к текущему состоянию результата этого конвейера или этапа: failed Или же unstable Или же aborted , И статус последнего результата выполнения success В соответствии с веб-интерфейсом, он неактивен.
aborted Обычно это происходит из-за того, что конвейер прерывается вручную.
failure Обычно это происходит из-за сбоя выполнения, что соответствует веб-интерфейсу и отображается красным цветом.Но будьте осторожны, если вы вручную stage Установить в currentBuild.result = 'FAILURE' И в этом stage Установить в failure post , Тогда он не сработает. Затем он запустит весь конвейер failure post Какие?
unstable Обычно это вызвано ошибками теста, нарушениями кода и т. Д. В соответствии с веб-интерфейсом пользователя он отображается желтым цветом.
unsuccessful Означает все Неудачный положение дел.cleanup Будет в post Каждый условный блок в выполняется после его запуска, независимо от состояния конвейера или этапа.
stages section
Он содержит один или несколько stage directives .
целиком pipeline Должен появиться только один раз.steps
Он состоит из одного или нескольких steps Состав, каждый step Это просто приговор.
Это определено в stage В может появиться не более одного раза.
Пример: см. Пример выше
5.1.2 Directives
environment directive
Эта директива не является обязательной, ее можно определить в pipeline блокировать или stage block
options directive
Эта команда не является обязательной и может быть определена только в pipeline блок и может появиться только один раз.
options Директивы разрешают конфигурацию, специфичную для Pipeline Опции.
Pipeline Предусмотрены многие из этих опций, например buildDiscarder , Но они также могут быть plugins Предоставьте, например, timestamps- buildDiscarder: сохранять артефакты и вывод консоли для определенного количества недавно запущенных конвейеров. Например: options
- checkoutToSubdirectory : Perform the automatic source control checkout in a subdirectory of the workspace. For example: options
- disableConcurrentBuilds : Disallow concurrent executions of the Pipeline. Can be useful for preventing simultaneous accesses to shared resources, etc. For example: options
- newContainerPerStage : Used with docker or dockerfile top-level agent. When specified, each stage will run in a new container instance on the same node, rather than all stages running in the same container instance.
- overrideIndexTriggers : Allows overriding default treatment of branch indexing triggers. If branch indexing triggers are disabled at the multibranch or organization label, options < overrideIndexTriggers(true) >will enable them for this job only. Otherwise, options < overrideIndexTriggers(false) >will disable branch indexing triggers for this job only.
- preserveStashes : .
parameters directive
Эта команда не является обязательной и может быть определена только в pipeline блок и может появиться только один раз.
triggers directive
Эта команда не является обязательной и может быть определена только в pipeline блок и может появиться только один раз.
Эта инструкция используется для синхронизации выполнения, опроса и выполнения, инициированного указанной задачей.
tools directive
Эта директива не является обязательной, ее можно определить в pipeline блокировать или stage block
Эта инструкция используется для определения инструмента, который будет автоматически установлен, и помещения его в PATH в,
Указанное имя инструмента должно быть в Manage Jenkins → Global Tool Configuration Предварительно настроенныйinput directive
input директива, объявленная в stage Середина времени stage Пауза и ожидание ввода пользователя
Пример: (Фактический эксперимент был проведен, и конвейер не продолжил выполнение после нажатия кнопки ОК)
when directive
when директива, объявленная в stage в.
5.1.3 Sequential Stages
Declarative Pipeline середина Stages Может объявить вложенным stages .
заметил один stage Должен содержать только один steps Или же parallel Или же stages5.1.4 Steps
script
script шаг может получить один scripted pipeline параметр блока, а в Declarative Pipeline Выполните это в.
5.2 Scripted Pipeline
Интеллектуальная рекомендация
![]()
WECHAT MILLY WAY POINT CAMENT CARD - СОВРЕМЕННЫЕ СТРАНИЦЫ ПРОГЛЯЮТНОЕ ЗНАЧЕНИЕ (Запрос)
WECHAT Small Pass Pass Value и значение приобретения: 1. Установите способ настройки идентификатора идентифицирует значение параметра, передаваемое после прыжка; 2, используя метод Data-XXXX для идент.
![]()
Текущая задача Узел больше экземпляров
![]()
[Linux] Программирование сетевых сокетов UDP
Что такое протокол UDP Протокол UDP называетсяПротокол пользовательских датаграмм UDP - протокол транспортного уровня Без установления соединения, ненадежная передача, ориентированная на дейтаграмму П.
![]()
![]()
Основная идея обработки больших данных - разделяй и властвуй
Разделяй и властвуй - «разделяй и властвуй» Как мы все знаем, компьютеры очень быстрые и используются людьми. Однако независимо от того, насколько быстрым является компьютер, способность о.
Читайте также: